|
|
2 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 2 years ago | |
| README.id.md | 2 years ago | |
| README.it.md | 2 years ago | |
| README.ja.md | 2 years ago | |
| README.ko.md | 2 years ago | |
| README.pt-br.md | 2 years ago | |
| README.pt.md | 2 years ago | |
| README.zh-cn.md | 2 years ago | |
| README.zh-tw.md | 2 years ago | |
| assignment.es.md | 3 years ago | |
| assignment.it.md | 4 years ago | |
| assignment.ja.md | 4 years ago | |
| assignment.ko.md | 3 years ago | |
| assignment.pt-br.md | 3 years ago | |
| assignment.pt.md | 3 years ago | |
| assignment.zh-cn.md | 3 years ago | |
| assignment.zh-tw.md | 3 years ago | |
README.zh-tw.md
邏輯回歸預測分類
課前測
介紹
在關於回歸的最後一課中,我們將學習邏輯回歸,這是經典的基本技術之一。你可以使用此技術來發現預測二元分類的模式。這是不是巧克力糖?這種病會傳染嗎?這個顧客會選擇這個產品嗎?
在本課中,你將學習:
- 用於數據可視化的新庫
- 邏輯回歸技術
✅ 在此學習模塊 中加深你對使用此類回歸的理解
前提
使用南瓜數據後,我們現在對它已經足夠熟悉了,可以意識到我們可以使用一個二元類別:Color。
讓我們建立一個邏輯回歸模型來預測,給定一些變量,給定的南瓜可能是什麽顏色(橙色🎃或白色👻)。
為什麽我們在關於回歸的課程分組中談論二元分類? 只是為了語言上的方便,因為邏輯回歸真的是一種分類方法,盡管是基於線性的。我們將在在下一課組中了解對數據進行分類的其他方法。
定義問題
出於我們的目的,我們將其表示為二進製:「橙色」或「非橙色」。我們的數據集中還有一個「條紋」類別,但它的實例很少,所以我們不會使用它。無論如何,一旦我們從數據集中刪除空值,它就會消失。
🎃 有趣的是,我們有時稱白南瓜為鬼南瓜。他們不是很容易雕刻,所以它們不像橙色的那麽受歡迎,但它們看起來很酷!
關於邏輯回歸
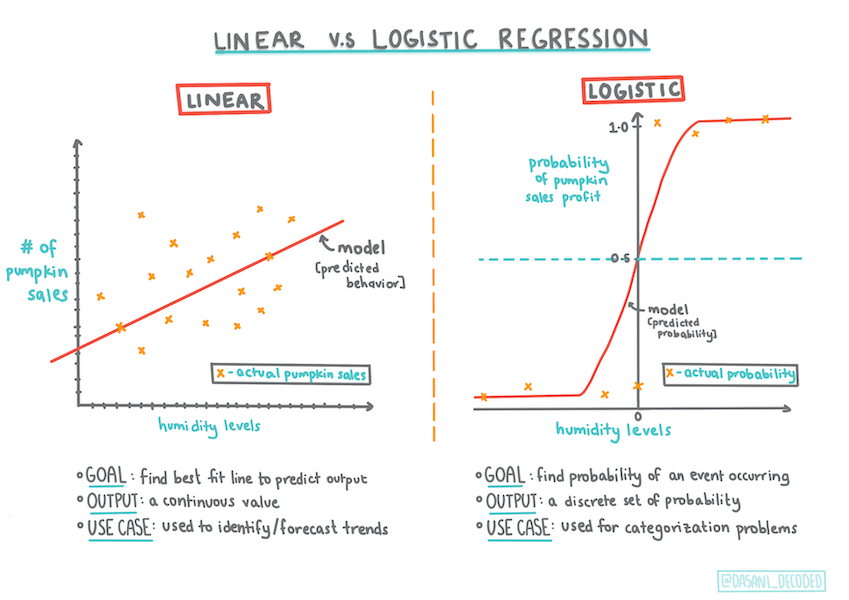
邏輯回歸在一些重要方面與你之前了解的線性回歸不同。
二元分類
邏輯回歸不提供與線性回歸相同的功能。前者提供關於二元類別(「橙色或非橙色」)的預測,而後者能夠預測連續值,例如,給定南瓜的起源和收獲時間,其價格將上漲多少。
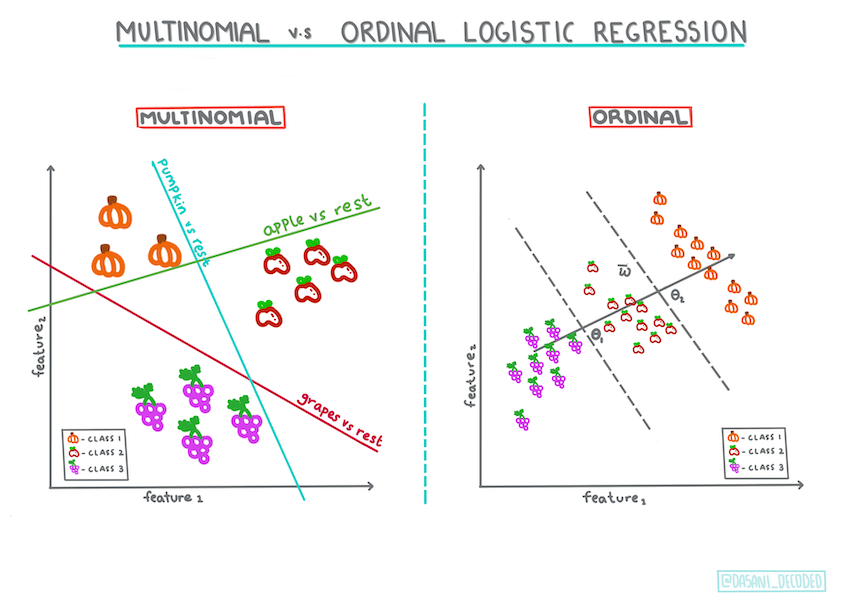
其他分類
還有其他類型的邏輯回歸,包括多項和有序:
- 多項,涉及多個類別 - 「橙色、白色和條紋」。
- 有序,涉及有序類別,如果我們想對我們的結果進行邏輯排序非常有用,例如我們的南瓜按有限數量的大小(mini、sm、med、lg、xl、xxl)排序。
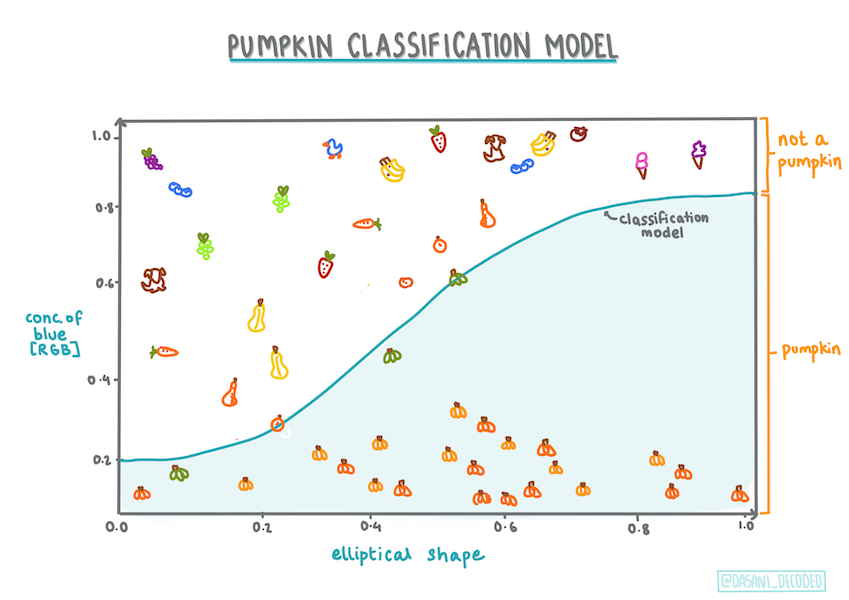
仍然是線性的
盡管這種類型的回歸都是關於「類別預測」的,但當因變量(顏色)和其他自變量(數據集的其余部分,如城市名稱和大小)之間存在明顯的線性關系時,它仍然效果最好。最好了解一下這些變量是否存在線性劃分。
變量不必相關
還記得線性回歸如何更好地處理更多相關變量嗎?邏輯回歸是相反的——變量不必對齊。這適用於相關性較弱的數據。
你需要大量幹凈的數據
如果使用更多數據,邏輯回歸將給出更準確的結果;我們的小數據集對於這項任務不是最佳的,請記住這一點。
✅ 考慮適合邏輯回歸的數據類型
練習 - 整理數據
首先,稍微清理一下數據,刪除空值並僅選擇其中一些列:
-
添加以下代碼:
from sklearn.preprocessing import LabelEncoder new_columns = ['Color','Origin','Item Size','Variety','City Name','Package'] new_pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1) new_pumpkins.dropna(inplace=True) new_pumpkins = new_pumpkins.apply(LabelEncoder().fit_transform)你可以隨時查看新的數據幀:
new_pumpkins.info
可視化 - 並列網格
到現在為止,你已經再次使用南瓜數據加載了 starter notebook 並對其進行了清理,以保留包含一些變量(包括 Color)的數據集。讓我們使用不同的庫來可視化 notebook 中的數據幀:Seaborn,它是基於我們之前使用的 Matplotlib 構建的。
Seaborn 提供了一些巧妙的方法來可視化你的數據。例如,你可以比較並列網格中每個點的數據分布。
-
通過實例化一個
PairGrid,使用我們的南瓜數據new_pumpkins,然後調用map()來創建這樣一個網格:import seaborn as sns g = sns.PairGrid(new_pumpkins) g.map(sns.scatterplot)
通過並列觀察數據,你可以看到顏色數據與其他列的關系。
✅ 鑒於此散點圖網格,你可以設想哪些有趣的探索?
使用分類散點圖
由於顏色是一個二元類別(橙色或非橙色),它被稱為「分類數據」,需要一種更專業的方法來可視化。還有其他方法可以可視化此類別與其他變量的關系。
你可以使用 Seaborn 圖並列可視化變量。
-
嘗試使用「分類散點」圖來顯示值的分布:
sns.swarmplot(x="Color", y="Item Size", data=new_pumpkins)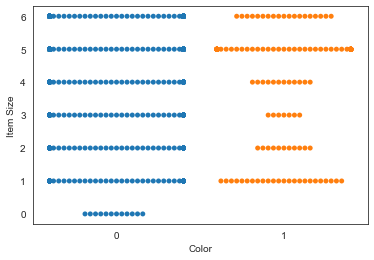
小提琴圖
「小提琴」類型的圖很有用,因為你可以輕松地可視化兩個類別中數據的分布方式。小提琴圖不適用於較小的數據集,因為分布顯示得更「平滑」。
-
作為參數
x=Color、kind="violin"並調用catplot():sns.catplot(x="Color", y="Item Size", kind="violin", data=new_pumpkins)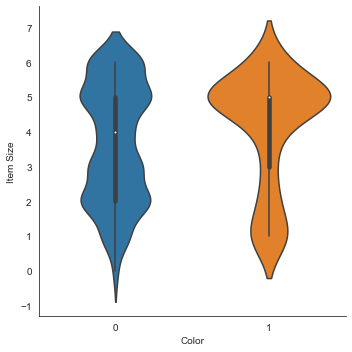
✅ 嘗試使用其他變量創建此圖和其他 Seaborn 圖。
現在我們已經了解了顏色的二元類別與更大的尺寸組之間的關系,讓我們探索邏輯回歸來確定給定南瓜的可能顏色。
🧮 數學知識
還記得線性回歸如何經常使用普通最小二乘法來得出一個值嗎?邏輯回歸依賴於使用sigmoid 函數 的「最大似然」概念。繪圖上的「Sigmoid 函數」看起來像「S」形。它接受一個值並將其映射到0和1之間的某個位置。它的曲線也稱為「邏輯曲線」。它的公式如下所示:
其中 sigmoid 的中點位於 x 的 0 點,L 是曲線的最大值,k 是曲線的陡度。如果函數的結果大於 0.5,則所討論的標簽將被賦予二進製選擇的類「1」。否則,它將被分類為「0」。
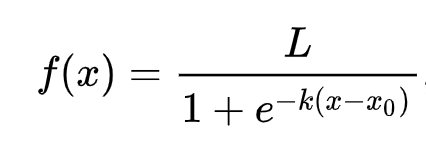
建立你的模型
在 Scikit-learn 中構建模型來查找這些二元分類非常簡單。
-
選擇要在分類模型中使用的變量,並調用
train_test_split()拆分訓練集和測試集:from sklearn.model_selection import train_test_split Selected_features = ['Origin','Item Size','Variety','City Name','Package'] X = new_pumpkins[Selected_features] y = new_pumpkins['Color'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) -
現在你可以訓練你的模型,用你的訓練數據調用
fit(),並打印出它的結果:from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, classification_report from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_train, y_train) predictions = model.predict(X_test) print(classification_report(y_test, predictions)) print('Predicted labels: ', predictions) print('Accuracy: ', accuracy_score(y_test, predictions))看看你的模型的記分板。考慮到你只有大約 1000 行數據,這還不錯:
precision recall f1-score support 0 0.85 0.95 0.90 166 1 0.38 0.15 0.22 33 accuracy 0.82 199 macro avg 0.62 0.55 0.56 199 weighted avg 0.77 0.82 0.78 199 Predicted labels: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0 1 0]
通過混淆矩陣更好地理解
雖然你可以通過獲得記分板報告條目把上面的項目打印出來,通過使用混淆矩陣可以更容易地理解你的模型,幫助我們了解模型的性能。
🎓 「混淆矩陣」(或「誤差矩陣」)是一個表格,用於表示模型的真假陽性和假陰性,從而衡量預測的準確性。
-
要使用混淆指標,請調用
confusin_matrix():from sklearn.metrics import confusion_matrix confusion_matrix(y_test, predictions)看看你的模型的混淆矩陣:
array([[162, 4], [ 33, 0]])
這裏發生了什麽?假設我們的模型被要求對兩個二元類別之間的項目進行分類,即類別「南瓜」和類別「非南瓜」。
- 如果你的模型將某物預測為南瓜並且它實際上屬於「南瓜」類別,我們將其稱為真陽性,由左上角的數字顯示。
- 如果你的模型預測某物不是南瓜,並且它實際上屬於「南瓜」類別,我們將其稱為假陽性,如右上角的數字所示。
- 如果你的模型將某物預測為南瓜並且它實際上屬於「非南瓜」類別,我們將其稱為假陰性,由左下角的數字顯示。
- 如果你的模型預測某物不是南瓜,並且它實際上屬於「非南瓜」類別,我們將其稱為真陰性,如右下角的數字所示。
正如你可能已經猜到的那樣,最好有更多的真陽性和真陰性以及較少的假陽性和假陰性,這意味著模型性能更好。
✅ Q:根據混淆矩陣,模型怎麽樣? A:還不錯;有很多真陽性,但也有一些假陰性。
讓我們借助混淆矩陣對TP/TN和FP/FN的映射,重新審視一下我們之前看到的術語:
🎓 準確率:TP/(TP + FP) 檢索實例中相關實例的分數(例如,哪些標簽標記得很好)
🎓 召回率: TP/(TP + FN) 檢索到的相關實例的比例,無論是否標記良好
🎓 F1分數: (2 * 準確率 * 召回率)/(準確率 + 召回率) 準確率和召回率的加權平均值,最好為1,最差為0
🎓 Support:檢索到的每個標簽的出現次數
🎓 準確度:(TP + TN)/(TP + TN + FP + FN) 為樣本準確預測的標簽百分比。
🎓 宏平均值: 計算每個標簽的未加權平均指標,不考慮標簽不平衡。
🎓 加權平均值:計算每個標簽的平均指標,通過按支持度(每個標簽的真實實例數)加權來考慮標簽不平衡。
✅ 如果你想讓你的模型減少假陰性的數量,你能想出應該關註哪個指標嗎?
可視化該模型的 ROC 曲線
這不是一個糟糕的模型;它的準確率在 80% 範圍內,因此理想情況下,你可以使用它來預測給定一組變量的南瓜顏色。
讓我們再做一個可視化來查看所謂的「ROC」分數
from sklearn.metrics import roc_curve, roc_auc_score
y_scores = model.predict_proba(X_test)
# calculate ROC curve
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:,1])
sns.lineplot([0, 1], [0, 1])
sns.lineplot(fpr, tpr)
再次使用 Seaborn,繪製模型的接收操作特性或 ROC。 ROC 曲線通常用於根據分類器的真假陽性來了解分類器的輸出。「ROC 曲線通常具有 Y 軸上的真陽性率和 X 軸上的假陽性率。」 因此,曲線的陡度以及中點線與曲線之間的空間很重要:你需要一條快速向上並越過直線的曲線。在我們的例子中,一開始就有誤報,然後這條線正確地向上和重復:
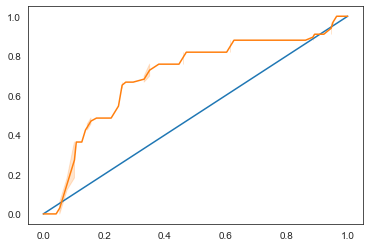
最後,使用 Scikit-learn 的roc_auc_score API 來計算實際「曲線下面積」(AUC):
auc = roc_auc_score(y_test,y_scores[:,1])
print(auc)
結果是 0.6976998904709748。 鑒於 AUC 的範圍從 0 到 1,你需要一個高分,因為預測 100% 正確的模型的 AUC 為 1;在這種情況下,模型_相當不錯_。
在以後的分類課程中,你將學習如何叠代以提高模型的分數。但是現在,恭喜!你已經完成了這些回歸課程!
🚀挑戰
關於邏輯回歸,還有很多東西需要解開!但最好的學習方法是實驗。找到適合此類分析的數據集並用它構建模型。你學到了什麽?小貼士:嘗試 Kaggle 獲取有趣的數據集。
課後測
復習與自學
閱讀斯坦福大學的這篇論文的前幾頁關於邏輯回歸的一些實際應用。想想那些更適合於我們目前所研究的一種或另一種類型的回歸任務的任務。什麽最有效?