Translated files (#392)
parent
08517c7efb
commit
4631e0e6c1
@ -0,0 +1,214 @@
|
||||
# Começar com Python e Scikit-learn para modelos de regressão
|
||||
|
||||

|
||||
|
||||
> Sketchnote by [Tomomi Imura](https://www.twitter.com/girlie_mac)
|
||||
|
||||
## [Questionário pré-palestra](https://white-water-09ec41f0f.azurestaticapps.net/quiz/9/)
|
||||
|
||||
> ### [Esta lição está disponível em R!](./solution/R/lesson_1-R.ipynb)
|
||||
|
||||
## Introdução
|
||||
|
||||
Nestas quatro lições, você vai descobrir como construir modelos de regressão. Discutiremos para que são em breve. Mas antes de fazer qualquer coisa, certifique-se de ter as ferramentas certas para iniciar o processo!
|
||||
|
||||
Nesta lição, aprenderá a:
|
||||
|
||||
- Configurar o seu computador para tarefas locais de aprendizagem automática.
|
||||
- Trabalhe com cadernos Jupyter.
|
||||
- Utilize scikit-learn, incluindo a instalação.
|
||||
- Explore a regressão linear com um exercício prático.
|
||||
|
||||
## Instalações e configurações
|
||||
|
||||
[](https://youtu.be/yyQM70vi7V8 "Configurar Python com código de estúdio visual
|
||||
")
|
||||
|
||||
> 🎥 Clique na imagem acima para um vídeo: utilizando Python dentro do Código VS.
|
||||
|
||||
1. **Instalar Python**. Certifique-se de que [Python](https://www.python.org/downloads/) está instalado no seu computador. Você usará Python para muitas tarefas de ciência de dados e machine learning. A maioria dos sistemas informáticos já inclui uma instalação Python. Há úteis [Python Pacotes de codificação](https://code.visualstudio.com/learn/educators/installers?WT.mc_id=academic-15963-cxa) disponível também, para facilitar a configuração para alguns utilizadores.
|
||||
|
||||
Alguns usos de Python, no entanto, requerem uma versão do software, enquanto outros requerem uma versão diferente. Por esta razão, é útil trabalhar dentro de um [ambiente virtual](https://docs.python.org/3/library/venv.html).
|
||||
|
||||
2. **Instalar código de estúdio visual**. Certifique-se de que tem o Código do Estúdio Visual instalado no seu computador. Siga estas instruções para
|
||||
[instalar Código do Estúdio Visual](https://code.visualstudio.com/) para a instalação básica. Você vai usar Python em Código estúdio visual neste curso, então você pode querer relembrá-lo [configurar código de estúdio visual](https://docs.microsoft.com/learn/modules/python-install-vscode?WT.mc_id=academic-15963-cxa) para o desenvolvimento de Python.
|
||||
|
||||
> Fique confortável com python trabalhando através desta coleção de [Aprender módulos](https://docs.microsoft.com/users/jenlooper-2911/collections/mp1pagggd5qrq7?WT.mc_id=academic-15963-cxa)
|
||||
|
||||
3. **Instale Scikit-learn**, seguindo [estas instruções]
|
||||
(https://scikit-learn.org/stable/install.html). Uma vez que precisa de garantir que utiliza o Python 3, recomenda-se que utilize um ambiente virtual. Note que se estiver a instalar esta biblioteca num Mac M1, existem instruções especiais na página acima ligada.
|
||||
|
||||
1. **Instale o Caderno Jupyter**. Você precisará [instalar o pacote Jupyter](https://pypi.org/project/jupyter/).
|
||||
|
||||
## O seu ambiente de autoria ML
|
||||
Você vai usar **cadernos** para desenvolver o seu código Python e criar modelos de aprendizagem automática. Este tipo de ficheiro é uma ferramenta comum para cientistas de dados, e podem ser identificados pelo seu sufixo ou extensão `.ipynb`.
|
||||
|
||||
Os cadernos são um ambiente interativo que permite ao desenvolvedor codificar e adicionar notas e escrever documentação em torno do código que é bastante útil para projetos experimentais ou orientados para a investigação.
|
||||
|
||||
## Exercício - trabalhe com um caderno
|
||||
|
||||
Nesta pasta, encontrará o ficheiro _notebook.ipynb_.
|
||||
|
||||
1. Abra _notebook.ipynb_ em Código de Estúdio Visual.
|
||||
|
||||
Um servidor Jupyter começará com o Python 3+ iniciado. Encontrará áreas do caderno que podem ser `executadas`, peças de código. Pode executar um bloco de código, selecionando o ícone que parece um botão de reprodução.
|
||||
|
||||
2. Selecione o ícone `md` e adicione um pouco de marcação, e o seguinte texto **# Bem-vindo ao seu caderno**.
|
||||
|
||||
Em seguida, adicione um pouco de código Python.
|
||||
|
||||
5. Escreva **print ('olá caderno')** no bloco de código.
|
||||
|
||||
6. Selecione a seta para executar o código.
|
||||
|
||||
Deve ver a declaração impressa:
|
||||
|
||||
```saída
|
||||
Olá caderno
|
||||
```
|
||||

|
||||
|
||||
Pode interligar o seu código com comentários para auto-documentar o caderno.
|
||||
|
||||
✅ Pense por um minuto como o ambiente de trabalho de um web developer é diferente do de um cientista de dados.
|
||||
|
||||
## Em funcionamento com Scikit-learn
|
||||
|
||||
Agora que python está montado no seu ambiente local, e você está confortável com os cadernos jupyter, vamos ficar igualmente confortáveis com Scikit-learn (pronunciá-lo 'sci' como em 'ciência'). Scikit-learn fornece uma [API extensiva](https://scikit-learn.org/stable/modules/classes.html#api-ref) para ajudá-lo a executar tarefas ML.
|
||||
|
||||
De acordo com o seu [site](https://scikit-learn.org/stable/getting_started.html), "O Scikit-learn é uma biblioteca de aprendizagem automática de código aberto que suporta a aprendizagem supervisionada e sem supervisão. Também fornece várias ferramentas para a montagem de modelos, pré-processamento de dados, seleção e avaliação de modelos, e muitas outras utilidades."
|
||||
|
||||
Neste curso, você usará scikit-learn e outras ferramentas para construir modelos de machine learning para executar o que chamamos de tarefas tradicionais de aprendizagem automática. Evitámos deliberadamente redes neurais e aprendizagem profunda, uma vez que estão melhor cobertas no nosso próximo currículo de IA para principiantes.
|
||||
|
||||
|
||||
|
||||
O scikit-learn torna simples construir modelos e avaliá-los para uso. Está focado principalmente na utilização de dados numéricos e contém vários conjuntos de dados prontos para uso como ferramentas de aprendizagem. Também inclui modelos pré-construídos para os alunos experimentarem. Vamos explorar o processo de carregamento de dados pré-embalados e usar um modelo ml incorporado no estimador com o Scikit-learn com alguns dados básicos.
|
||||
|
||||
## Exercício - o seu primeiro caderno Scikit-learn
|
||||
|
||||
> Este tutorial foi inspirado no exemplo [de regressão linear](https://scikit-learn.org/stable/auto_examples/linear_model/plot_ols.html#sphx-glr-auto-examples-linear-model-plot-ols-py) no site da Scikit-learn.
|
||||
|
||||
No ficheiro _notebook.ipynb_ associado a esta lição, limpe todas as células premindo o ícone 'caixote do lixo'.
|
||||
|
||||
Nesta secção, você vai trabalhar com um pequeno conjunto de dados sobre diabetes que é incorporado em Scikit-learn para fins de aprendizagem. Imagine que queria testar um tratamento para pacientes diabéticos. Os modelos de Machine Learning podem ajudá-lo a determinar quais os pacientes que responderiam melhor ao tratamento, com base em combinações de variáveis. Mesmo um modelo de regressão muito básico, quando visualizado, pode mostrar informações sobre variáveis que o ajudariam a organizar os seus ensaios clínicos teóricos.
|
||||
|
||||
✅ There are many types of regression methods, and which one you pick depends on the answer you're looking for. If you want to predict the probable height for a person of a given age, you'd use linear regression, as you're seeking a **numeric value**. If you're interested in discovering whether a type of cuisine should be considered vegan or not, you're looking for a **category assignment** so you would use logistic regression. You'll learn more about logistic regression later. Think a bit about some questions you can ask of data, and which of these methods would be more appropriate.
|
||||
|
||||
Vamos começar com esta tarefa.
|
||||
|
||||
### Bibliotecas de importação
|
||||
|
||||
Para esta tarefa importaremos algumas bibliotecas:
|
||||
|
||||
- **matplotlib**. É uma ferramenta útil [de grafimento](https://matplotlib.org/) e vamos usá-lo para criar um enredo de linha.
|
||||
- **numpy**. [numpy](https://numpy.org/doc/stable/user/whatisnumpy.html) é uma biblioteca útil para o tratamento de dados numéricos em Python.
|
||||
- **sklearn**. Este é o [Scikit-learn](https://scikit-learn.org/stable/user_guide.html) biblioteca.
|
||||
|
||||
Importe algumas bibliotecas para ajudar nas suas tarefas.
|
||||
|
||||
1. Adicione as importações digitando o seguinte código:
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
from sklearn import datasets, linear_model, model_selection
|
||||
```
|
||||
|
||||
Acima está a importar `matplottlib`, `numpy` e está a importar `datasets`, `linear_model` e `model_selection` de `sklearn`. É utilizado `model_selection` para dividir dados em conjuntos de treino e teste.
|
||||
|
||||
## O conjunto de dados da diabetes
|
||||
O conjunto de dados incorporado [diabetes](https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset) Inclui 442 amostras de dados em torno da diabetes, com 10 variáveis de características, algumas das quais incluem:
|
||||
|
||||
- idade: idade em anos
|
||||
- bmi: índice de massa corporal
|
||||
- bp: pressão arterial média
|
||||
- s1 tc: T-Cells (um tipo de glóbulos brancos)
|
||||
|
||||
✅ Este conjunto de dados inclui o conceito de 'sexo' como uma variável de característica importante para a investigação em torno da diabetes. Muitos conjuntos de dados médicos incluem este tipo de classificação binária. Pense um pouco sobre como categorizações como esta podem excluir certas partes de uma população de tratamentos.
|
||||
|
||||
Agora, carregue os dados X e Y.
|
||||
|
||||
> 🎓 Lembre-se, isto é aprendizagem supervisionada, e precisamos de um alvo chamado "y".
|
||||
|
||||
Numa nova célula de código, carregue o conjunto de dados da diabetes chamando `load_diabetes()` A entrada `return_X_y=True` indica que `X` será uma matriz de dados, e `y` será o alvo de regressão.
|
||||
|
||||
1. Adicione alguns comandos de impressão para mostrar a forma da matriz de dados e o seu primeiro elemento:
|
||||
|
||||
```python
|
||||
X, y = datasets.load_diabetes(return_X_y=True)
|
||||
print(X.shape)
|
||||
print(X[0])
|
||||
```
|
||||
|
||||
O que estás a receber como resposta, é um tuple. O que está a fazer é atribuir os dois primeiros valores da tuple para `X` and `y` respectivamente. Saiba mais [sobre tuples](https://wikipedia.org/wiki/Tuple).
|
||||
|
||||
Pode ver que estes dados têm 442 itens moldados em matrizes de 10 elementos:
|
||||
|
||||
```text
|
||||
(442, 10)
|
||||
[ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076
|
||||
-0.04340085 -0.00259226 0.01990842 -0.01764613]
|
||||
```
|
||||
|
||||
✅ Pense um pouco sobre a relação entre os dados e o alvo de regressão. A regressão linear prevê relações entre a característica X e a variável alvo. Pode encontrar o [alvo](https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset) para o conjunto de dados da diabetes na documentação? O que é que este conjunto de dados está a demonstrar, tendo em conta esse objetivo?
|
||||
|
||||
2. Em seguida, selecione uma parte deste conjunto de dados para traçar, organizando-o numa nova matriz usando a função `newaxis` da Numpy. Vamos usar a regressão linear para gerar uma linha entre valores nestes dados, de acordo com um padrão que determina.
|
||||
|
||||
```python
|
||||
X = X[:, np.newaxis, 2]
|
||||
```
|
||||
|
||||
✅ A qualquer momento, imprima os dados para verificar a sua forma.
|
||||
|
||||
3. Agora que tem dados prontos a serem traçados, pode ver se uma máquina pode ajudar a determinar uma divisão lógica entre os números deste conjunto de dados. Para isso, é necessário dividir os dados (X) e o alvo (y) em conjuntos de teste e treino. O Scikit-learn tem uma forma simples de o fazer; pode dividir os seus dados de teste num dado momento.
|
||||
|
||||
```python
|
||||
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33)
|
||||
```
|
||||
|
||||
4. Agora está pronto para treinar o seu modelo! Carregue o modelo linear de regressão e treine-o com os seus conjuntos de treinamento X e y usando `modelo.fit()`:
|
||||
|
||||
```python
|
||||
model = linear_model.LinearRegression()
|
||||
model.fit(X_train, y_train)
|
||||
```
|
||||
|
||||
✅ `modelo.fit()` é uma função que você verá em muitas bibliotecas ML, como TensorFlow
|
||||
|
||||
5. Em seguida, crie uma previsão utilizando dados de teste, utilizando a função `predict()`. Isto será usado para traçar a linha entre grupos de dados
|
||||
```python
|
||||
y_pred = model.predict(X_test)
|
||||
```
|
||||
|
||||
6. Agora é hora de mostrar os dados num enredo. Matplotlib é uma ferramenta muito útil para esta tarefa. Crie uma dispersão de todos os dados de teste X e y, e use a previsão para traçar uma linha no local mais apropriado, entre os agrupamentos de dados do modelo.
|
||||
|
||||
```python
|
||||
plt.scatter(X_test, y_test, color='black')
|
||||
plt.plot(X_test, y_pred, color='blue', linewidth=3)
|
||||
plt.xlabel('Scaled BMIs')
|
||||
plt.ylabel('Disease Progression')
|
||||
plt.title('A Graph Plot Showing Diabetes Progression Against BMI')
|
||||
plt.show()
|
||||
```
|
||||
|
||||

|
||||
|
||||
✅ Pense um pouco sobre o que está acontecendo aqui. Uma linha reta está a passar por muitos pequenos pontos de dados, mas o que está a fazer exatamente? Consegue ver como deve ser capaz de usar esta linha para prever onde um novo ponto de dados invisível se deve encaixar em relação ao eixo y do enredo? Tente colocar em palavras o uso prático deste modelo.
|
||||
|
||||
Parabéns, construíste o teu primeiro modelo linear de regressão, criaste uma previsão com ele, e exibiste-o num enredo!
|
||||
---
|
||||
## 🚀Challenge
|
||||
|
||||
Defina uma variável diferente deste conjunto de dados. Dica: edite esta linha:`X = X[:, np.newaxis, 2]`. Tendo em conta o objetivo deste conjunto de dados, o que é que consegue descobrir sobre a progressão da diabetes como uma doença?
|
||||
## [Questionário pós-palestra](https://white-water-09ec41f0f.azurestaticapps.net/quiz/10/)
|
||||
|
||||
## Review & Self Study
|
||||
|
||||
Neste tutorial, trabalhou com uma simples regressão linear, em vez de univariado ou regressão linear múltipla. Leia um pouco sobre as diferenças entre estes métodos, ou dê uma olhada[este vídeo](https://www.coursera.org/lecture/quantifying-relationships-regression-models/linear-vs-nonlinear-categorical-variables-ai2Ef)
|
||||
|
||||
Leia mais sobre o conceito de regressão e pense sobre que tipo de perguntas podem ser respondidas por esta técnica. Tome este [tutorial](https://docs.microsoft.com/learn/modules/train-evaluate-regression-models?WT.mc_id=academic-15963-cxa) para aprofundar a sua compreensão.
|
||||
## Missão
|
||||
|
||||
[Um conjunto de dados diferente](assignment.md)
|
||||
@ -0,0 +1,13 @@
|
||||
# Regressão com Scikit-learn
|
||||
|
||||
## Instruções
|
||||
|
||||
Dê uma olhada no conjunto de [dados Linnerud](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_linnerud.html#sklearn.datasets.load_linnerud) em Scikit-learn. Este conjunto de dados tem vários [alvos](https://scikit-learn.org/stable/datasets/toy_dataset.html#linnerrud-dataset): 'Consiste em três variáveis de exercício (dados) e três variáveis fisiológicas (alvo) recolhidas de vinte homens de meia-idade num clube de fitness'
|
||||
|
||||
Nas suas próprias palavras, descreva como criar um modelo de Regressão que traçaria a relação entre a cintura e quantos situps são realizados. Faça o mesmo para os outros pontos de dados neste conjunto de dados.
|
||||
|
||||
## Rubrica
|
||||
|
||||
| Critérios | exemplares | Adequado | Necessidades de Melhoria |
|
||||
| ------------------------------ | ----------------------------------- | ----------------------------- | -------------------------- |
|
||||
| Enviar um parágrafo descritivo | Parágrafo bem escrito é submetido | Algumas frases são submetidas | Nenhuma descrição é fornecida |
|
||||
@ -0,0 +1,207 @@
|
||||
# Crie um modelo de regressão usando o Scikit-learn: preparar e visualizar dados
|
||||
|
||||

|
||||
|
||||
Infographic by [Dasani Madipalli](https://twitter.com/dasani_decoded)
|
||||
|
||||
## [Teste de pré-aula](https://white-water-09ec41f0f.azurestaticapps.net/quiz/11/)
|
||||
|
||||
> ### [Esta lição está disponível em R!](./solution/R/lesson_2-R.ipynb)
|
||||
|
||||
## Introdução
|
||||
|
||||
Agora que você está configurado com as ferramentas necessárias para começar a lidar com a construção de modelos de aprendizagem automática com o Scikit-learn, você está pronto para começar a fazer perguntas sobre seus dados. Como você trabalha com dados e aplica soluções ML, é muito importante entender como fazer a pergunta certa para desbloquear adequadamente os potenciais de seu conjunto de dados.
|
||||
|
||||
Nesta lição, você aprenderá:
|
||||
|
||||
- Como preparar seus dados para a criação de modelos.
|
||||
- Como usar Matplotlib para visualização de dados.
|
||||
|
||||
[](https://youtu.be/11AnOn_OAcE "Preparando e Visualizando vídeo de dados - Clique para Assistir!")
|
||||
> 🎥 Clique na imagem acima para ver um vídeo que aborda os principais aspectos desta lição
|
||||
|
||||
|
||||
## Fazendo a pergunta certa sobre seus dados
|
||||
|
||||
A pergunta que você precisa responder determinará que tipo de algoritmos de ML você utilizará. E a qualidade da resposta que você recebe de volta será fortemente dependente da natureza de seus dados.
|
||||
|
||||
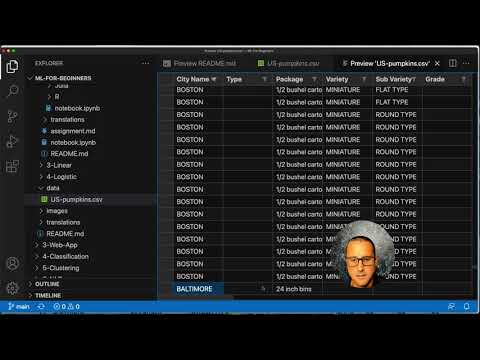
Dê uma olhada nos [dados](../data/US-pumpkins.csv) fornecidos para esta lição. Você pode abrir este arquivo .csv no Código VS. Um skim rápido imediatamente mostra que há espaços em branco e uma mistura de strings e dados numéricos. Há também uma coluna estranha chamada 'Package' onde os dados são uma mistura entre 'sacks', 'bins' e outros valores. Os dados, de fato, são um pouco confusos.
|
||||
|
||||
Na verdade, não é muito comum ser dotado de um conjunto de dados que está completamente pronto para usar para criar um modelo ML pronto para uso. Nesta lição, você aprenderá como preparar um conjunto de dados bruto usando bibliotecas Python padrão. Você também aprenderá várias técnicas para visualizar os dados.
|
||||
|
||||
## Estudo de caso: "mercado da abóbora"
|
||||
|
||||
Nesta pasta você encontrará um arquivo .csv na pasta raiz `data` chamada [US-pumpkins.csv](../data/US-pumpkins.csv) que inclui 1757 linhas de dados sobre o mercado de abóboras, classificadas em agrupamentos por cidade. Estes são dados brutos extraídos dos [Specialty Crops Terminal Markets Standard Reports](https://www.marketnews.usda.gov/mnp/fv-report-config-step1?type=termPrice) distribuídos pelo Departamento de Agricultura dos Estados Unidos.
|
||||
|
||||
### Preparando dados
|
||||
|
||||
Estes dados são do domínio público. Ele pode ser baixado em muitos arquivos separados, por cidade, a partir do site USDA. Para evitar muitos arquivos separados, nós concatenamos todos os dados da cidade em uma planilha, assim nós já _preparamos_ os dados um pouco. A seguir, vamos dar uma olhada nos dados.
|
||||
|
||||
### Os dados da abóbora - primeiras conclusões
|
||||
|
||||
O que você nota sobre esses dados? Vocês já viram que há uma mistura de strings, números, espaços em branco e valores estranhos que você precisa entender.
|
||||
|
||||
Que pergunta você pode fazer sobre esses dados, usando uma técnica de Regressão? E quanto a "Prever o preço de uma abóbora à venda durante um determinado mês". Observando novamente os dados, há algumas alterações que você precisa fazer para criar a estrutura de dados necessária para a tarefa.
|
||||
## Exercício - analisar os dados da abóbora
|
||||
|
||||
Vamos usar [Pandas](https://pandas.pydata.org/), (o nome significa `Python Data Analysis`) uma ferramenta muito útil para moldar dados, para analisar e preparar esses dados de abóbora.
|
||||
|
||||
### Primeiro, verifique se há datas ausentes
|
||||
|
||||
Primeiro, você precisará seguir as etapas para verificar se há datas ausentes:
|
||||
|
||||
1. Converta as datas em um formato de mês (essas são datas americanas, portanto o formato é `MM/DD/AAAA`).
|
||||
2. Extraia o mês para uma nova coluna.
|
||||
|
||||
Abra o arquivo _notebook.ipynb_ no Visual Studio Code e importe a planilha para um novo quadro de dados do Pandas.
|
||||
|
||||
1. Use a função `head()` para exibir as cinco primeiras linhas.
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
pumpkins = pd.read_csv('../data/US-pumpkins.csv')
|
||||
pumpkins.head()
|
||||
```
|
||||
|
||||
Qual função você usaria para exibir as últimas cinco linhas?
|
||||
|
||||
1. Verifique se há dados ausentes no banco de dados atual:
|
||||
|
||||
```python
|
||||
pumpkins.isnull().sum()
|
||||
```
|
||||
|
||||
Faltam dados, mas talvez não seja importante para a tarefa em questão.
|
||||
|
||||
1. Para facilitar o trabalho com seu banco de dados, solte várias de suas colunas, usando `drop()`, mantendo apenas as colunas necessárias:
|
||||
|
||||
```python
|
||||
new_columns = ['Package', 'Month', 'Low Price', 'High Price', 'Date']
|
||||
pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
|
||||
```
|
||||
|
||||
### Segundo, determinar o preço médio da abóbora
|
||||
|
||||
Pense sobre como determinar o preço médio de uma abóbora em um determinado mês. Que colunas você escolheria para esta tarefa? Dica: você precisará de 3 colunas.
|
||||
|
||||
Solução: utilize a média das colunas `Preço Baixo` e Preço Alto` para preencher a nova coluna Preço e converta a coluna Data para mostrar apenas o mês. Felizmente, de acordo com a verificação acima, não há dados ausentes para datas ou preços.
|
||||
|
||||
1. Para calcular a média, adicione o seguinte código:
|
||||
2.
|
||||
```python
|
||||
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2
|
||||
|
||||
month = pd.DatetimeIndex(pumpkins['Date']).month
|
||||
|
||||
```
|
||||
|
||||
✅Sinta-se à vontade para imprimir quaisquer dados que você gostaria de verificar usando `print(month)`.
|
||||
|
||||
3. Agora, copie seus dados convertidos em um novo dataframe Pandas:
|
||||
|
||||
```python
|
||||
new_pumpkins = pd.DataFrame({'Month': month, 'Package': pumpkins['Package'], 'Low Price': pumpkins['Low Price'],'High Price': pumpkins['High Price'], 'Price': price})
|
||||
```
|
||||
|
||||
A impressão do seu dataframe mostrará um conjunto de dados limpo e organizado no qual você pode construir seu novo modelo de regressão.
|
||||
|
||||
### Mas espere! Há algo estranho aqui
|
||||
|
||||
Se você observar a coluna `Package`, as abóboras são vendidas em várias configurações diferentes. Algumas são vendidas em medidas de "1 1/9 bushel", e algumas em medidas de "1/2 bushel", algumas por abóbora, algumas por libra, e algumas em caixas grandes com larguras variadas.
|
||||
|
||||
> Abóboras parecem muito difíceis de pesar consistentemente
|
||||
|
||||
Analisando os dados originais, é interessante que qualquer coisa com `Unidade de Venda` igual a 'CADA' ou 'POR CAIXA' também tenha o tipo `Pacote` por polegada, por caixa ou 'cada'. As abóboras parecem ser muito difíceis de pesar consistentemente, então vamos filtrá-las selecionando apenas as abóboras com a cadeia "bushel" na coluna `Pacote`.
|
||||
|
||||
1. Adicione um filtro na parte superior do arquivo, sob a importação .csv inicial:
|
||||
|
||||
```python
|
||||
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]
|
||||
```
|
||||
|
||||
Se você imprimir os dados agora, você pode ver que você está apenas recebendo as 415 ou mais linhas de dados contendo abóboras pelo bushel.
|
||||
|
||||
### Mas espere! Há mais uma coisa a fazer
|
||||
|
||||
Você notou que o montante de bushel varia por linha? Você precisa normalizar o preço para que você mostre o preço por bushel, então faça algumas contas para padronizá-lo.
|
||||
|
||||
1. Adicione estas linhas após o bloco criar o dataframe new_pumpkins:
|
||||
|
||||
```python
|
||||
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/(1 + 1/9)
|
||||
|
||||
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price/(1/2)
|
||||
```
|
||||
|
||||
✅ De acordo com [O Spruce Eats](https://www.thespruceeats.com/how-much-is-a-bushel-1389308), o peso de um bushel depende do tipo de produto, pois é uma medida de volume. "Um bushel de tomates, por exemplo, deve pesar 56 libras... Folhas e verdes ocupam mais espaço com menos peso, então um alqueire de espinafre pesa apenas 20 libras." É tudo muito complicado! Não nos preocupemos em fazer uma conversão bushel-to-pound, e em vez disso o preço pelo bushel. Todo este estudo de bushels de abóboras, no entanto, vai para mostrar como é muito importante entender a natureza dos seus dados!
|
||||
|
||||
Agora, você pode analisar o preço por unidade com base em sua medição de bushel. Se você imprimir os dados mais uma vez, poderá ver como eles são padronizados.
|
||||
|
||||
Você notou que as abóboras vendidas pela metade do bushel são muito caras? Você pode descobrir por quê? Dica: abóboras pequenas são muito mais caras do que as grandes, provavelmente porque há muito mais delas por bushel, dado o espaço não utilizado tomado por uma grande abóbora de torta oca.
|
||||
|
||||
## Estratégias de visualização
|
||||
|
||||
Parte do papel do cientista de dados é demonstrar a qualidade e a natureza dos dados com os quais eles estão trabalhando. Para fazer isso, muitas vezes criam visualizações interessantes, ou gráficos, gráficos e gráficos, mostrando diferentes aspectos dos dados. Dessa forma, eles são capazes de mostrar visualmente relacionamentos e lacunas que de outra forma são difíceis de descobrir.
|
||||
|
||||
Visualizações também podem ajudar a determinar a técnica de aprendizado de máquina mais apropriada para os dados. Um gráfico de dispersão que parece seguir uma linha, por exemplo, indica que os dados são um bom candidato para um exercício de regressão linear.
|
||||
|
||||
Uma biblioteca de visualização de dados que funciona bem em notebooks Jupyter é [Matplotlib](https://matplotlib.org/) (que você também viu na lição anterior).
|
||||
|
||||
> Obtenha mais experiência com visualização de dados em [estes tutoriais](https://docs.microsoft.com/learn/modules/explore-analyze-data-with-python?WT.mc_id=university-15963-cxa).
|
||||
|
||||
## Exercício - experimente com Matplotlib
|
||||
|
||||
Tente criar alguns gráficos básicos para exibir o novo banco de dados que você acabou de criar. O que um gráfico de linha básica mostraria?
|
||||
|
||||
1. Importar Matplotlib no topo do arquivo, sob a importação Pandas:
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
```
|
||||
|
||||
1. Execute novamente todo o bloco de anotações para atualizar.
|
||||
1. Na parte inferior do notebook, adicione uma célula para plotar os dados como uma caixa:
|
||||
|
||||
```python
|
||||
price = new_pumpkins.Price
|
||||
month = new_pumpkins.Month
|
||||
plt.scatter(price, month)
|
||||
plt.show()
|
||||
```
|
||||
|
||||

|
||||
|
||||
Será isto um enredo útil? Alguma coisa sobre isso o surpreende?
|
||||
|
||||
Não é particularmente útil, uma vez que tudo o que apresenta nos seus dados como uma distribuição de pontos num determinado mês.
|
||||
|
||||
### Tornar útil
|
||||
|
||||
Para que os gráficos apresentem dados úteis, normalmente é necessário agrupar os dados de alguma forma. Vamos tentar criar um desenho onde o eixo Y mostre os meses e os dados demonstram a distribuição de dados.
|
||||
|
||||
1. Adicionar uma célula para criar um gráfico de barras agrupado:
|
||||
|
||||
```python
|
||||
new_pumpkins.groupby(['Month'])['Price'].mean().plot(kind='bar')
|
||||
plt.ylabel("Pumpkin Price")
|
||||
```
|
||||
|
||||

|
||||
|
||||
Esta é uma visualização de dados mais útil! Parece indicar que o preço mais alto para as abrigas ocorre em setembro e outubro. Isso atende às suas expetativas? Porque ou porque não?
|
||||
|
||||
—
|
||||
|
||||
## 🚀 desafio
|
||||
|
||||
Explore os diferentes tipos de visualização que o Matplotlib oferece. Que tipos são mais apropriados para problemas de regressão?
|
||||
|
||||
## [Questionário pós-palestra](https://white-water-09ec41f0f.azurestaticapps.net/quiz/12/)
|
||||
|
||||
## Revisão e Estudo Automático
|
||||
|
||||
Dê uma vista de olhos às muitas formas de visualizar dados. Disponibilize uma lista das várias bibliotecas e anote quais as melhores para determinados tipos de tarefas, por exemplo, visualizações 2D vs. visualizações 3D. O que você descobre?
|
||||
|
||||
## Atribuição
|
||||
|
||||
[A explorar visualização](assignment.md)
|
||||
@ -0,0 +1,9 @@
|
||||
# Exploração de Visualizações
|
||||
|
||||
Existem várias bibliotecas diferentes que estão disponíveis para visualização de dados. Crie algumas visualizações utilizando os dados da Abóbora nesta lição com matplotlib e nascidos num caderno de amostras. Com que bibliotecas é mais fácil de trabalhar?
|
||||
|
||||
## Rubrica
|
||||
|
||||
Critérios | exemplares | Adequado | Necessidades de Melhoria |
|
||||
| -------- | --------- | -------- | ----------------- |
|
||||
| | Um caderno é submetido com duas explorações/visualizações| Um caderno é submetido com uma exploração/visualizações | Um caderno não é submetido |
|
||||
@ -0,0 +1,11 @@
|
||||
# Criar um modelo de regressão
|
||||
|
||||
## Instruções
|
||||
|
||||
Nesta lição foi-lhe mostrado como construir um modelo usando a Regressão Linear e Polinomial. Utilizando este conhecimento, encontre um conjunto de dados ou use um dos conjuntos incorporados da Scikit-learn para construir um novo modelo. Explique no seu caderno porque escolheu a técnica que escolheu e demonstre a precisão do seu modelo. Se não for preciso, explique porquê.
|
||||
|
||||
## Rubrica
|
||||
|
||||
| Critérios | exemplares | Adequado | Necessidades de Melhoria |
|
||||
| -------- | ------------------------------------------------------------ | -------------------------- | ------------------------------- |
|
||||
| | apresenta um caderno completo com uma solução bem documentada | a solução está incompleta| a solução é imperfeita ou buggy |
|
||||
@ -0,0 +1,302 @@
|
||||
# Regressão logística para prever categorias
|
||||
|
||||

|
||||
> Infographic by [Dasani Madipalli](https://twitter.com/dasani_decoded)
|
||||
## [Questionário pré-palestra](https://white-water-09ec41f0f.azurestaticapps.net/quiz/15/)
|
||||
|
||||
> ### [Esta lição está disponível em R!](./solution/R/lesson_4-R.ipynb)
|
||||
|
||||
## Introdução
|
||||
|
||||
Nesta lição final sobre Regressão, uma das técnicas básicas _classic_ ML, vamos dar uma olhada na Regressão Logística. Usaria esta técnica para descobrir padrões para prever categorias binárias. Isto é chocolate doce ou não? Esta doença é contagiosa ou não? Este cliente escolherá este produto ou não?
|
||||
|
||||
Nesta lição, aprenderá:
|
||||
- Uma nova biblioteca para visualização de dados
|
||||
- Técnicas de regressão logística
|
||||
|
||||
✅ aprofundar a sua compreensão de trabalhar com este tipo de regressão neste [módulo Aprender](https://docs.microsoft.com/learn/modules/train-evaluate-classification-models?WT.mc_id=academic-15963-cxa)
|
||||
## Pré-requisito
|
||||
|
||||
Tendo trabalhado com os dados da abóbora, estamos agora familiarizados o suficiente para perceber que há uma categoria binária com a qual podemos trabalhar:` Cor`.
|
||||
|
||||
Vamos construir um modelo de regressão logística para prever que, dadas algumas variáveis, _what cor de uma dada abóbora é provável que be_ (🎃 laranja ou 👻 branco).
|
||||
|
||||
> Porque estamos a falar de classificação binária num agrupamento de aulas sobre regressão? Apenas para conveniência linguística, uma vez que a regressão logística é [realmente um método de classificação](https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression),embora um linear baseado. Saiba mais sobre outras formas de classificar os dados no próximo grupo de aulas.
|
||||
|
||||
## Definir a pergunta
|
||||
Para os nossos propósitos, vamos expressar isto como um binário: "Laranja" ou "Não Laranja". Existe também uma categoria de "listrado" no nosso conjunto de dados, mas há poucos casos dele, pelo que não a utilizaremos. Desaparece assim que removemos os valores nulos do conjunto de dados, de qualquer forma.
|
||||
|
||||
> 🎃 facto divertido, às vezes chamamos abóboras brancas de abóboras "fantasma". Não são muito fáceis de esculpir, por isso não são tão populares como os laranjas, mas são fixes!
|
||||
|
||||
## About logistic regression
|
||||
|
||||
A regressão logística difere da regressão linear, que aprendeu anteriormente, de algumas formas importantes.
|
||||
### Classificação binária
|
||||
|
||||
A regressão logística não oferece as mesmas características que a regressão linear. O primeiro oferece uma previsão sobre uma categoria binária ("laranja ou não laranja"),) enquanto esta é capaz de prever valores contínuos, por exemplo dada a origem de uma abóbora e a hora da colheita, _how muito o seu preço irá rise_.
|
||||
|
||||

|
||||
> Infographic by [Dasani Madipalli](https://twitter.com/dasani_decoded)
|
||||
### Outras classificações
|
||||
|
||||
Existem outros tipos de regressão logística, incluindo multinóia e ordinária:
|
||||
- **Multinomial**, que envolve ter mais de uma categoria - "Laranja, Branco e Listrado".
|
||||
- **Ordinal**, que envolve categorias ordenadas, úteis se quiséssemos encomendar os nossos resultados logicamente, como as nossas abóboras que são encomendadas por um número finito de tamanhos (mini,sm,med,lg,xl,xxl).
|
||||
|
||||

|
||||
> Infographic by [Dasani Madipalli](https://twitter.com/dasani_decoded)
|
||||
### Ainda é linear
|
||||
|
||||
Embora este tipo de Regressão seja tudo sobre "previsões de categoria", ainda funciona melhor quando há uma relação linear clara entre a variável dependente (cor) e as outras variáveis independentes (o resto do conjunto de dados, como o nome e o tamanho da cidade). É bom ter uma ideia de se há alguma linearidade dividindo estas variáveis ou não.
|
||||
|
||||
### Variáveis NÃO têm que correlacionar
|
||||
Lembras-te de como a regressão linear funcionou melhor com variáveis mais correlacionadas? A regressão logística é o oposto - as variáveis não têm que se alinhar. Isso funciona para estes dados que têm correlações um pouco fracas.
|
||||
|
||||
### Precisa de muitos dados limpos
|
||||
|
||||
A regressão logística dará resultados mais precisos se utilizar mais dados; nosso pequeno conjunto de dados não é o ideal para esta tarefa, por isso tenha isso em mente.
|
||||
|
||||
✅ Pense nos tipos de dados que se emprestariam bem à regressão logística
|
||||
|
||||
## Exercício - arrumar os dados
|
||||
|
||||
Primeiro, limpe um pouco os dados, baixando os valores nulos e selecionando apenas algumas das colunas:
|
||||
|
||||
1. Adicione o seguinte código:
|
||||
|
||||
```python
|
||||
from sklearn.preprocessing import LabelEncoder
|
||||
|
||||
new_columns = ['Color','Origin','Item Size','Variety','City Name','Package']
|
||||
|
||||
new_pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
|
||||
|
||||
new_pumpkins.dropna(inplace=True)
|
||||
|
||||
new_pumpkins = new_pumpkins.apply(LabelEncoder().fit_transform)
|
||||
```
|
||||
|
||||
Pode sempre dar uma olhada no seu novo dataframe:
|
||||
|
||||
```python
|
||||
new_pumpkins.info
|
||||
```
|
||||
|
||||
### Visualização - grelha lado a lado
|
||||
|
||||
Por esta altura já já carregou o [caderno de entrada](./notebook.ipynb) com dados de abóbora mais uma vez e limpou-os de modo a preservar um conjunto de dados contendo algumas variáveis, incluindo `Color`. Vamos visualizar o quadro de dados no caderno usando uma biblioteca diferente: [Seaborn](https://seaborn.pydata.org/index.html), que é construída em Matplotlib que usamos anteriormente.
|
||||
|
||||
Seaborn oferece algumas maneiras limpas de visualizar os seus dados. Por exemplo, pode comparar distribuições dos dados por cada ponto numa grelha lado a lado.
|
||||
|
||||
1. Crie tal rede através da instantânea `PairGrid`, utilizando os nossos dados de abóbora `new_pumpkins`, seguidos de `map()`:
|
||||
|
||||
```python
|
||||
import seaborn as sns
|
||||
|
||||
g = sns.PairGrid(new_pumpkins)
|
||||
g.map(sns.scatterplot)
|
||||
```
|
||||
|
||||

|
||||
|
||||
Ao observar dados lado a lado, pode ver como os dados de Cor se relacionam com as outras colunas.
|
||||
|
||||
✅ Dada esta grelha de dispersão, quais são algumas explorações interessantes que podes imaginar?
|
||||
|
||||
### Use um enredo de enxame
|
||||
Uma vez que a Cor é uma categoria binária (Laranja ou Não), chama-se "dados categóricos" e precisa de "uma abordagem mais [especializada](https://seaborn.pydata.org/tutorial/categorical.html?highlight=bar) à visualização". Há outras formas de visualizar a relação desta categoria com outras variáveis.
|
||||
|
||||
Você pode visualizar variáveis lado a lado com parcelas seaborn.
|
||||
|
||||
1. Experimente um plano de 'enxame' para mostrar a distribuição de valores:
|
||||
|
||||
```python
|
||||
sns.swarmplot(x="Color", y="Item Size", data=new_pumpkins)
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Enredo de violino
|
||||
|
||||
Um gráfico de tipo 'violino' é útil, pois você pode visualizar facilmente a forma como os dados nas duas categorias são distribuídos. Os gráficos de violino não funcionam tão bem com conjuntos de dados menores, pois a distribuição é exibida mais 'suavemente'.
|
||||
|
||||
1. Como parâmetros `x=Color`, `kind="violin"` e chamada `catplot()`:
|
||||
|
||||
```python
|
||||
sns.catplot(x="Color", y="Item Size",
|
||||
kind="violin", data=new_pumpkins)
|
||||
```
|
||||
|
||||

|
||||
|
||||
✅ Tente criar este enredo, e outros enredos de Seaborn, usando outras variáveis.
|
||||
|
||||
Agora que temos uma ideia da relação entre as categorias binárias de cor e o grupo maior de tamanhos, vamos explorar a regressão logística para determinar a cor provável de uma dada abóbora.
|
||||
|
||||
> **🧮 Mostre-Me A Matemática**
|
||||
>
|
||||
> Lembram-se como a regressão linear frequentemente usava mínimos quadrados ordinários para chegar a um valor? A regressão logística baseia-se no conceito de "máxima verossimilhança" utilizando [funções sigmoides](https://wikipedia.org/wiki/Sigmoid_function). Uma 'Função Sigmoide' em uma trama se parece com uma forma 'S'. Ele pega um valor e o mapeia para algum lugar entre 0 e 1. Sua curva também é chamada de "curva logística". Sua fórmula é assim:
|
||||
>
|
||||
> 
|
||||
>
|
||||
> onde o ponto médio do sigmoide se encontra no ponto 0 de x, L é o valor máximo da curva, e k é a inclinação da curva. Se o resultado da função for maior que 0,5, o rótulo em questão receberá a classe '1' da escolha binária. Caso contrário, será classificado como "0".
|
||||
|
||||
## Crie o seu modelo
|
||||
|
||||
Construir um modelo para encontrar essas classificações binárias é surpreendentemente simples no Scikit-learn.
|
||||
|
||||
1. Selecione as variáveis que deseja utilizar no seu modelo de classificação e divida os conjuntos de treino e teste que chamam `train_test_split()`:
|
||||
|
||||
```python
|
||||
from sklearn.model_selection import train_test_split
|
||||
|
||||
Selected_features = ['Origin','Item Size','Variety','City Name','Package']
|
||||
|
||||
X = new_pumpkins[Selected_features]
|
||||
y = new_pumpkins['Color']
|
||||
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
|
||||
|
||||
```
|
||||
|
||||
1. Agora você pode treinar seu modelo, chamando `fit()` com seus dados de treinamento e imprimir o resultado:
|
||||
|
||||
```python
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.metrics import accuracy_score, classification_report
|
||||
from sklearn.linear_model import LogisticRegression
|
||||
|
||||
model = LogisticRegression()
|
||||
model.fit(X_train, y_train)
|
||||
predictions = model.predict(X_test)
|
||||
|
||||
print(classification_report(y_test, predictions))
|
||||
print('Predicted labels: ', predictions)
|
||||
print('Accuracy: ', accuracy_score(y_test, predictions))
|
||||
```
|
||||
|
||||
Dê uma olhada no placar do seu modelo. Não é tão ruim, considerando que você tem apenas cerca de 1000 linhas de dados:
|
||||
|
||||
```output
|
||||
precision recall f1-score support
|
||||
|
||||
0 0.85 0.95 0.90 166
|
||||
1 0.38 0.15 0.22 33
|
||||
|
||||
accuracy 0.82 199
|
||||
macro avg 0.62 0.55 0.56 199
|
||||
weighted avg 0.77 0.82 0.78 199
|
||||
|
||||
Predicted labels: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
|
||||
0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
||||
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1
|
||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1
|
||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
||||
0 0 0 1 0 1 0 0 1 0 0 0 1 0]
|
||||
```
|
||||
|
||||
## Melhor compreensão através de uma matriz de confusão
|
||||
|
||||
Enquanto você pode obter um relatório de placar [termos](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html?highlight=classification_report#sklearn.metrics.classification_report) imprimindo os itens acima, você pode ser capaz de entender seu modelo mais facilmente usando uma [matriz confusão](https://scikit-learn.org/stable/modules/model_evaluation.html#confusion-matrix) para nos ajudar a entender como o modelo está se saindo.
|
||||
|
||||
> 🎓 A '[matriz de confusão](https://wikipedia.org/wiki/Confusion_matrix)' (ou 'matriz de erros') é uma tabela que expressa os verdadeiros versus falsos positivos e negativos do seu modelo, avaliando assim a precisão das previsões.
|
||||
|
||||
1. Para usar uma métrica de confusão, chame`confusion_matrix()`:
|
||||
|
||||
```python
|
||||
from sklearn.metrics import confusion_matrix
|
||||
confusion_matrix(y_test, predictions)
|
||||
```
|
||||
|
||||
Dê uma olhada na matriz de confusão do seu modelo:
|
||||
|
||||
```output
|
||||
array([[162, 4],
|
||||
[ 33, 0]])
|
||||
```
|
||||
|
||||
No Scikit-learn, matrizes de confusão Linhas (eixo 0) são rótulos reais e colunas (eixo 1) são rótulos previstos.
|
||||
|
||||
| | 0 | 1 |
|
||||
| :---: | :---: | :---: |
|
||||
| 0 | TN | FP |
|
||||
| 1 | FN | TP |
|
||||
|
||||
O que está acontecendo aqui? Digamos que nosso modelo é solicitado a classificar abóboras entre duas categorias binárias, categoria 'laranja' e categoria 'não-laranja'.
|
||||
|
||||
- Se o seu modelo prevê uma abóbora como não laranja e pertence à categoria 'não-laranja' na realidade chamamos-lhe um verdadeiro negativo, mostrado pelo número superior esquerdo.
|
||||
- Se o seu modelo prevê uma abóbora como laranja e pertence à categoria 'não-laranja' na realidade chamamos-lhe um falso negativo, mostrado pelo número inferior esquerdo.
|
||||
- Se o seu modelo prevê uma abóbora como não laranja e pertence à categoria 'laranja' na realidade chamamos-lhe um falso positivo, mostrado pelo número superior direito.
|
||||
- Se o seu modelo prevê uma abóbora como laranja e ela pertence à categoria 'laranja' na realidade nós chamamos de um verdadeiro positivo, mostrado pelo número inferior direito.
|
||||
|
||||
Como vocês devem ter adivinhado, é preferível ter um número maior de verdadeiros positivos e verdadeiros negativos e um número menor de falsos positivos e falsos negativos, o que implica que o modelo tem melhor desempenho.
|
||||
|
||||
Como a matriz de confusão se relaciona com precisão e evocação? Lembre-se, o relatório de classificação impresso acima mostrou precisão (0,83) e recuperação (0,98).
|
||||
|
||||
Precision = tp / (tp + fp) = 162 / (162 + 33) = 0.8307692307692308
|
||||
|
||||
Recall = tp / (tp + fn) = 162 / (162 + 4) = 0.9759036144578314
|
||||
|
||||
✅ Q: De acordo com a matriz de confusão, como foi o modelo? A: Nada mal. há um bom número de verdadeiros negativos, mas também vários falsos negativos.
|
||||
|
||||
Vamos revisitar os termos que vimos anteriormente com a ajuda do mapeamento da matriz confusão de TP/TN e FP/FN:
|
||||
|
||||
🎓 precisão: TP/(TP + FP) A fração de instâncias relevantes entre as instâncias recuperadas (por exemplo, quais rótulos estavam bem rotulados)
|
||||
|
||||
🎓 Chamada: TP/(TP + FN) A fração de instâncias relevantes que foram recuperadas, sejam bem rotuladas ou não
|
||||
|
||||
🎓 f1- score: (2 * precisão * recolha)/(precisão + recolha) Uma média ponderada da precisão e recolha, sendo a melhor 1 e a pior 0
|
||||
|
||||
Suporte 🎓: O número de ocorrências de cada rótulo recuperado
|
||||
|
||||
🎓 precisão: (TP + TN)/(TP + TN + FP + FN) A percentagem de rótulos previstos com precisão para uma amostra.
|
||||
|
||||
🎓 Méd. de Macro: O cálculo das métricas médias não ponderadas para cada rótulo, sem levar em conta o desequilíbrio do rótulo.
|
||||
|
||||
🎓 Média Ponderada: O cálculo das métricas médias para cada label, levando em conta o desequilíbrio de label ponderando-as pelo suporte (o número de instâncias verdadeiras para cada label).
|
||||
|
||||
Consegue pensar qual métrica deve observar se quiser que o seu modelo reduza o número de falsos negativos?
|
||||
|
||||
## Visualizar a curva de ROC deste modelo
|
||||
|
||||
Este não é um mau modelo; sua precisão está na faixa de 80%, então idealmente você poderia usá-lo para prever a cor de uma abóbora dado um conjunto de variáveis.
|
||||
|
||||
Vamos fazer mais uma visualização para ver a chamada pontuação 'ROC':
|
||||
|
||||
```python
|
||||
from sklearn.metrics import roc_curve, roc_auc_score
|
||||
|
||||
y_scores = model.predict_proba(X_test)
|
||||
# calculate ROC curve
|
||||
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:,1])
|
||||
sns.lineplot([0, 1], [0, 1])
|
||||
sns.lineplot(fpr, tpr)
|
||||
```
|
||||
Usando Seaborn novamente, plote a [Característica de operação de recepção](https://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html?highlight=roc) ou ROC do modelo. Curvas ROC são frequentemente usadas para obter uma visão da saída de um classificador em termos de seus verdadeiros versus falsos positivos. "As curvas ROC geralmente apresentam taxa positiva verdadeira no eixo Y e taxa positiva falsa no eixo X." Assim, a inclinação da curva e o espaço entre a linha do ponto médio e a matéria da curva: você quer uma curva que rapidamente se encaminha para cima e sobre a linha. No nosso caso, há falsos positivos para começar, e então a linha se encaminha para cima e para cima corretamente:
|
||||
|
||||

|
||||
|
||||
Finalmente, use o Scikit-learn [`roc_auc_score` API](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html?highlight=roc_auc#sklearn.metrics.roc_auc_score) para calcular a 'Área sob a curva' (AUC) real:
|
||||
|
||||
```python
|
||||
auc = roc_auc_score(y_test,y_scores[:,1])
|
||||
print(auc)
|
||||
```
|
||||
O resultado é `0,6976998904709748`. Dado que a AUC varia de 0 a 1, você quer uma grande pontuação, uma vez que um modelo que é 100% correto em suas previsões terá uma AUC de 1; nesse caso, o modelo é _muito bom_.
|
||||
|
||||
Em lições futuras sobre classificações, você aprenderá a iterar para melhorar as pontuações do seu modelo. Mas por enquanto, parabéns! Você completou essas lições de regressão!
|
||||
|
||||
---
|
||||
## 🚀Desafio
|
||||
|
||||
Há muito mais a desempacotar em relação à regressão logística! Mas a melhor maneira de aprender é experimentar. Encontre um conjunto de dados que se preste a esse tipo de análise e construa um modelo com ele. O que você aprende? dica: tente [Kaggle](https://www.kaggle.com/search?q=logistic+regression+datasets) para obter conjuntos de dados interessantes.
|
||||
|
||||
## [Teste pós-aula](https://white-water-09ec41f0f.azurestaticapps.net/quiz/16/)
|
||||
|
||||
## Análise e autoestudo
|
||||
|
||||
Leia as primeiras páginas de [este artigo de Stanford](https://web.stanford.edu/~jurafsky/slp3/5.pdf) sobre alguns usos práticos para regressão logística. Pense em tarefas que são mais adequadas para um ou outro tipo de tarefas de regressão que estudamos até agora. O que funcionaria melhor?
|
||||
|
||||
## Atribuição
|
||||
|
||||
[Repetindo esta regressão](assignment.md)
|
||||
@ -0,0 +1,11 @@
|
||||
## Retrying alguma regressão
|
||||
|
||||
## Instruções
|
||||
|
||||
Na lição, usaste um subconjunto dos dados da abóbora. Agora, volte aos dados originais e tente usá-lo todo, limpo e padronizado, para construir uma Regressão Logística model.
|
||||
|
||||
## Rubrica
|
||||
|
||||
| Critérios | exemplares | Adequado | Necessidades de Melhoria |
|
||||
| -------- | ----------------------------------------------------------------------- | ------------------------------------------------------------ | ----------------------------------------------------------- |
|
||||
| | Um caderno é apresentado com um modelo bem explicado e bem-adundo | Um caderno é apresentado com um modelo que funciona minimamente | Um caderno é apresentado com um modelo de sub-desempenho ou nenhum|
|
||||
@ -0,0 +1,38 @@
|
||||
# Modelos de regressão para aprendizagem automática
|
||||
## Tópico regional: Modelos de regressão para preços de abóbora na América do Norte 🎃
|
||||
|
||||
Na América do Norte, as abóboras são muitas vezes esculpidas em rostos assustadores para o Halloween. Vamos descobrir mais sobre estes fascinantes vegetais!
|
||||
|
||||

|
||||
> Photo by <a href="https://unsplash.com/@teutschmann?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Beth Teutschmann</a> on <a href="https://unsplash.com/s/photos/jack-o-lanterns?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
|
||||
|
||||
## O que vai aprender
|
||||
|
||||
[](https://youtu.be/5QnJtDad4iQ "Regressão Vídeo de introdução - Clique para ver
|
||||
!")
|
||||
> 🎥 Clique na imagem acima para obter um vídeo de introdução rápida a esta lição
|
||||
|
||||
As lições nesta secção abrangem tipos de regressão no contexto da aprendizagem automática. Os modelos de regressão podem ajudar a determinar a _relação_ entre variáveis. Este tipo de modelo pode prever valores como comprimento, temperatura ou idade, descobrindo assim relações entre variáveis à medida que analisa pontos de dados.
|
||||
|
||||
Nesta série de lições, você vai descobrir a diferença entre regressão logística linear vs. e quando você deve usar uma ou outra.
|
||||
|
||||
Neste grupo de lições, você será configurado para iniciar tarefas de machine learning, incluindo configurar o Código do Estúdio Visual para gerir cadernos, o ambiente comum para cientistas de dados. Você vai descobrir Scikit-learn, uma biblioteca para machine learning, e você vai construir seus primeiros modelos, focando-se em modelos de Regressão neste capítulo.
|
||||
|
||||
> Existem ferramentas de baixo código úteis que podem ajudá-lo a aprender sobre trabalhar com modelos de regressão. Tente
|
||||
[Azure ML for this task](https://docs.microsoft.com/learn/modules/create-regression-model-azure-machine-learning-designer/?WT.mc_id=academic-15963-cxa)
|
||||
|
||||
### Lessons
|
||||
|
||||
1. [Ferramentas do comércio](1-Tools/README.md)
|
||||
2. [Gestão de dados](2-Data/README.md)
|
||||
3. [Linear and polynomial regression](3-Linear/README.md)
|
||||
4. [Logistic regression](4-Logistic/README.md)
|
||||
|
||||
---
|
||||
### Credits
|
||||
|
||||
"ML com regressão" foi escrito com ♥️ por[Jen Looper](https://twitter.com/jenlooper)
|
||||
|
||||
♥️ Os colaboradores do quiz incluem:[Muhammad Sakib Khan Inan](https://twitter.com/Sakibinan) e [Ornella Altunyan](https://twitter.com/ornelladotcom)
|
||||
|
||||
O conjunto de dados de abóbora é sugerido por [este projeto em Kaggle](https://www.kaggle.com/usda/a-year-of-pumpkin-prices) e os seus dados são obtidos a partir do [Relatórios padrão dos mercados de terminais de culturas especiais](https://www.marketnews.usda.gov/mnp/fv-report-config-step1?type=termPrice) distribuído pelo Departamento de Agricultura dos Estados Unidos. Adicionámos alguns pontos em torno da cor com base na variedade para normalizar a distribuição. Estes dados estão no domínio público.
|
||||
Loading…
Reference in new issue