17 KiB
Regresi logistik untuk memprediksi kategori-kategori
Infografik oleh Dasani Madipalli
Kuis pra-ceramah
Pembukaan
Dalam pelajaran regresi terakhir, salah satu teknik ML klasik dan sederhana adalah regresi logistik. Teknik ini digunakan untuk mengemukakan pola-pola untuk memprediksi kategori binari. Apa ini sebuah permen coklat atau tidak? Apa penyakit ini menular tidak? Apa pelanggan ini akan memilih produk ini tidak?
Dalam pelajaran ini, kamu akan belajar:
- Sebuah library baru untuk pemvisualisasian data
- Teknik-teknik untuk regresi logistik
✅ Perdalamkan pemahamanmu dalam bekerja dengan regresi jenis ini dalam modul pembelajaran ini
Prasyarat
Setelah bekerja dengan data labu, kita sekarang sudah terbiasa dengannya untuk menyadari bahwa adapula sebuah kategori binari yang kita dapat menggunakan: Color (warna).
Mari membangun sebuah model regresi logistik untuk memprediksi kemungkinannya labu ini warnanya apa berdasarkan beberapa variabel (oranye 🎃 atau putih 👻).
Mengapa kita berbicara tentang klasifikasi binary dalam seri pelajaran tentang regresi? Hanya untuk kemudahan linguistik, regresi logistik juga sebenarnya sebuah metode klasifikasi, namun satu yang berdasarkan garis linear. Pelajari lebih lanjut tentang cara-cara lain untuk mengklasifikasi data dalam seri pelajaran berikutnya.
Tentukan pertanyaannya
Untuk keperluan kita, kita akan mengekspresikannya sebagai pilihan binari 'Orange' atau 'Not Orange' (oranye atau bukan oranye). Adapula kategori 'striped' (belang-belang) dalam dataset kita, tetapi tidak banyak titik datanya, jadi kita tidak akan menggunakannya. Lagipula, kategori itu hilang begitu kita buang nilai-nilai nil (null) dari datasetnya.
🎃 Tahukah tidak? Kita kadangkali memanggil labu putih labu 'hantu'. Mereka tidak mudah diukir, jadi mereka tidak sepopuler yang oranye pada Halloween. Tetapi mereka keren juga ya!
Tentang regresi logistik
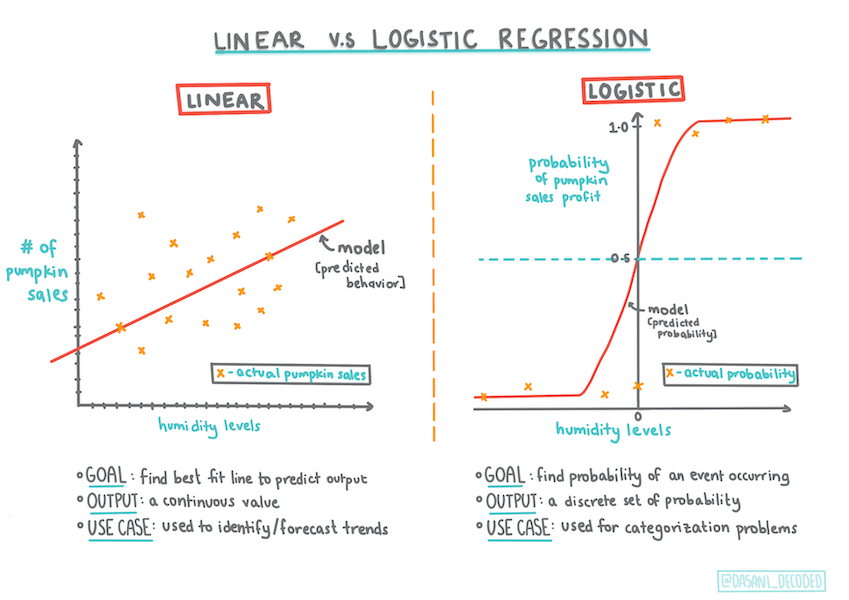
Regresi logistik berbeda dari regresi linear, jenis regresi yang kamu pelajari sebelumnya, dalam beberapa askpek penting.
Klasifikasi binari
Regresi logistik tidak mempunyai beberapa fitur regresi linear. Regresi logistik menyediakan sebuah prediksi tentang sebuah kategori binari (seperti "oranye atau bukan oranye"), sedangkan yang lainnya dapat memprediksi nilai-nilai kontinu. Contohnya, dengan mengetahui dari mana labu ini dan kapan dipanennya, regresi linear dapat memprediksi berapa harganya akan naik, namun regresi logistik tidak bisa.
Infografik oleh Dasani Madipalli
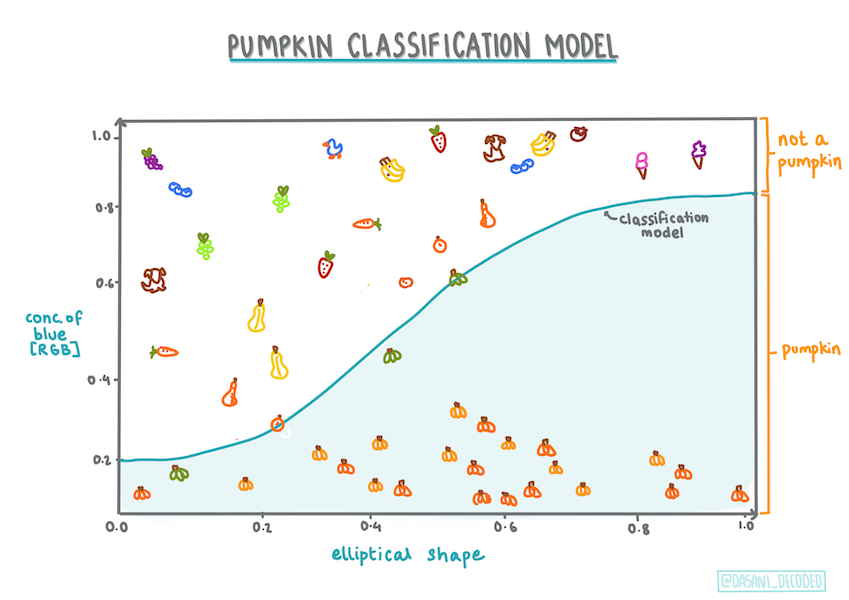
Klasifikasi lain
Ditambah itu, ada banyak jenis regresi logistik, termasuk jenis multinomial dan ordinal:
- Multinomial memperlibatkan lebih dari satu kategori - "Oranye, Putih, dan Belang-belang".
- Ordinal memperlibatkan kategori-kategori berurut. Biasanya berguna jika kita inging mengurutkan hasil kita secara logikal, seperti labu-useful if we wanted to order our outcomes logically, like our pumpkins that are ordered by a finite number of sizes (mini,sm,med,lg,xl,xxl).

Infographic by Dasani Madipalli
Eh, masih linear ya?
Walaupun jenis regresi ini semuanya tentang 'prediksi kategori', jenis ini masih paling efektif jika ada hubungan linear antara variabel dependen (warna) dan independen (sisa dataset-nya, seperti kota dan ukuran). Jadi baik juga untuk mencari tahu dahulu apa ada hubungan linear antara variabel-variabel ini.
Variabel-variabel TIDAK HARUS berkorelasi
Ingat bagaimana regresi linear bekerja lebih baik dengan variabel berkorelasi? Regresi logistik itu kebalikannya: variabel-variabelnya tidak harus berjejer menjadi garis. Artinya, regresi ini bekerja untuk data ini yang korelasinya lumayan lemah.
Perlu banyak data rapi
Regresi logistik akan memberi hasil lebih akurat jika kamu menggunakan data lebih banyak; dataset kecil kita tidak optimal untuk tugas ini, ingatlah itu.
✅ Pikirkan tentang jenis-jenis data yang akan bekerja baik dengan regresi logistik
Latihan - rapikan data
Pertama, rapikanlah datanya sedikit. Buanglah nilai-nilai nil (null) dan pilihlah beberapa kolom:
-
Tambahlah kode di bawah ini:
from sklearn.preprocessing import LabelEncoder new_columns = ['Color','Origin','Item Size','Variety','City Name','Package'] new_pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1) new_pumpkins.dropna(inplace=True) new_pumpkins = new_pumpkins.apply(LabelEncoder().fit_transform)Kamu selalu bisa mengintip kedalam dataframe-mu:
new_pumpkins.info
Visualisasi - grid berdampingan (side-by-side grid)
Sekarang kamu sudah memuat notebook starter dengan data labunya sekali lagi dan merapikannya untuk mempertahankan sebuah dataset dengan beberapa variabel, termasuk Color. Mari memvisualisasi dataframe-nya dengan library yang beda: Seaborn yang dibangun di atas Matplotlib yang kita gunakan sebelumnya.
Seaborn menyediakan beberapa cara keren untuk memvisualisasi datamu. Contohnya, kamu bisa membandungkan distribusi datanya untuk setiap titik data dalam sebuah grid berdampingan.
-
Buatlah sebuah grid dengan meng-instantiate sebuah
PairGridmenggunakan data labu kitanew_pumpkinsdiikuti memanggil fungsimap():import seaborn as sns g = sns.PairGrid(new_pumpkins) g.map(sns.scatterplot)
Dengan mengobservasi datanya secara berdampingan, kamu bisa lihat bagaimana data warnanya berhubungan dengan kolom-kolom lainnya.
✅ Dengan petak sebar ini, pendalaman menarik apa saja yang kamu bisa membayangkan?
Gunakan sebuah bagan kawanan (swarm plot)
Karena warna adalah sebuah kategori binari (oranye atau bukan oranye), warna disebut 'data kategorikal' dan memerlukan 'sebuah pendekatan khusus untuk memvisualisasi'. Ada beberapa cara lain untuk memvisualisasi hubungan antara kategori ini dengan variabel-variabel lainnya.
Kamu bisa memvisualisasikan variabel-variabel secara berdampingan dengan bagan-bagan Seaborn.
-
Cobalah sebuah bagan kawanan untuk menunjukkan distribusi nilai:
sns.swarmplot(x="Color", y="Item Size", data=new_pumpkins)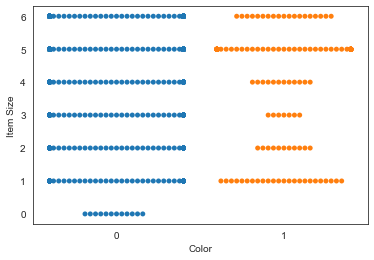
Bagan biola
Sebuah bagan 'biola' itu berguna sebab kamu bisa memvisualisasi bagaimana data dalam kedua kategori itu terdistribusi dengan mudah. Bagan viola tidak efektif dengan dataset yang lebih kecil sebab distribusinya ditampilkan sebagai lebih 'mulus'.
-
Gunakan fungsi
catplot()dengan parameterx=Colordankind="violin":sns.catplot(x="Color", y="Item Size", kind="violin", data=new_pumpkins)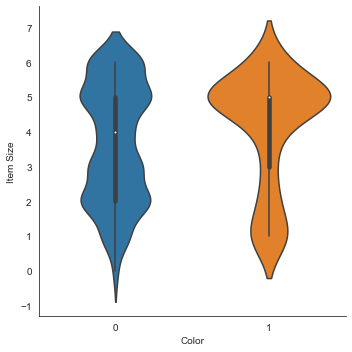
✅ Cobalah membuat bagan ini dan jenis-jenis bagan Seaborn lainnya dengan variabel-variabel lainnya.
Sekarang kita sudah dapat bayangan hubungan antara kedua kategori binary warna dan ukuran. Ayo menjelajahi regresi logistik untuk memprediksi warna sebuah labu tertentu.
🧮 Perlihatkanlah Matematikanya Kepada Saya
Ingat bagaiaman regresi linear seringkali menggunakan metode kuadrat terkecil untuk tiba pada sebuah nilai? Regresi logistik tergantung pada konsep 'kemungkinan terbesar' menggunakan fungsi sigmoid. Sebuah 'fungsi Sigmoid' terlihat seperti huruf 'S' dalam sistem koordinat Kartesius. Fungsi ini mengambil sebuah nilai dan 'mencorongkannya' menjadi sebuah nomor antara 0 dan 1. Kurva ini juga dipanggil sebuah 'kurva logistik'. Formulanya seperti ini:
Titik tengah sigmoidnya terletak di sumbu X. L adalah nilai maksimum kurvanya. k adalah terjalnya kurvanya. Jika hasil fungsinya lebih dari 0.5, nilai yang diberikan kepada fungsi tersebut akan diklasifikasikan sebagai '1'. Kalau tidak, nilai itu akan diklasifikasikan sebagai '0'.
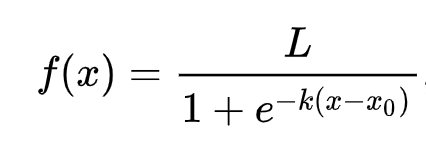
Bangunlah modelmu
Scikit-learn membuat membangun model klasifikasi binary sangat mudah.
-
Pilihlah variabel-variabel yang kamu ingin gunakan dalam model klasifikasimu dan bagilah datanya menjadi set latihan dan set ujian dengan fungsi
train_test_split():from sklearn.model_selection import train_test_split Selected_features = ['Origin','Item Size','Variety','City Name','Package'] X = new_pumpkins[Selected_features] y = new_pumpkins['Color'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) -
Sekarang kamu bisa melatihkan modelmu dengan fungsi
fit()dengan data latihanmu. Print hasilnya:from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, classification_report from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_train, y_train) predictions = model.predict(X_test) print(classification_report(y_test, predictions)) print('Predicted labels: ', predictions) print('Accuracy: ', accuracy_score(y_test, predictions))Lihatlah scoreboard modelmu. Tidak buruk, apalagi hanya dengan 1000 baris data:
precision recall f1-score support 0 0.85 0.95 0.90 166 1 0.38 0.15 0.22 33 accuracy 0.82 199 macro avg 0.62 0.55 0.56 199 weighted avg 0.77 0.82 0.78 199 Predicted labels: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0 1 0]
Pemahaman lebih baik via sebuah 'matriks kebingungan'
Walaupun kamu bisa membuat sebuah scoreboard melaporkan istilah-istilah dengan mem-print yang di atas, kamu mungkin bisa memahami modelmu dengan lebih mudah dengan sebuah matriks kebingungan untuk membantu kita lebih paham akan performa modelnya.
🎓 Sebuah 'matriks kebingungan' (atau 'matriks kesalahan') adalah sebuah tabel yang mengekspresikan positif benar vs. positif palsu modelmu sehingga mengukur akurasi prediksi=prediksinya.
-
Untuk menggunakan sebuah matriks kebingungan, gunakan fungsi
confusin_matrix():from sklearn.metrics import confusion_matrix confusion_matrix(y_test, predictions)Lihatlah matriks kebingungan modelmu:
array([[162, 4], [ 33, 0]])
Apa yang sedang terjadi di sini? Mari kita asumsi dulu bahwa model kita ditanyakan untuk mengklasifikasi antara dua kategori binari: 'labu' dan 'bukan labu'.
- Kalau modelmu memprediksi sesuatu sebagai sebuah labu dan memang benar sesuatu itu adalah sebuah labu, itu disebut positif benar yang diindikasi angka di pojok kiri atas.
- Kalau modelmu memprediksi sesuatu sebagai bukan sebuah labu tetapi sesuatu itu sebenarnya sebuah labu, itu disebut positif palsu yang diindikasi angka di pojok kanan atas.
- Kalau modelmu memprediksi sesuati sebagai sebuah labu tetapi sebenarnya bukan sebuah labu, itu disebut negatif palsu yang diindikasi angka di pojok kiri bawah.
- Kalau modelmu memprediksi sesuati sebagai bukan sebuah labu dan memang benar sesuatu itu bukan sebuah labu, itu disebut negatif benar yang diindikasi angka di pojok kanan bawah.
Sebagaimana kamu mungkin sudah pikirkan, lebih baik dapat banyak positif benar dan negatif benar dan sedikit positif palsu dan negatif palsu. Implikasinya adalah performa modelnya bagus.
✅ Pertanyaan: Berdasarkan matriks kebingungan, modelnya baik tidak? Jawaban: Tidak buruk; ada banyak positif benar dan sedikit negatif palsu.
Mari kita lihat kembali istilah-istilah yang kita lihat tadi dengan bantuan matriks kebingungan:
PB: Positif benar PP: Positif palsu NB: Negatif benar NP: Negatif palsu
🎓 Presisi: PB/(PB + PP) Rasio titik data relevan antara semua titik data (seperti data mana yang benar dilabelkannya)
🎓 Recall: PB/(PB + NP) Rasio titk data relevan yang digunakan, maupun labelnya benar atau tidak.
🎓 f1-score: (2 * Presisi * Recall)/(Presisi + Recall) Sebuah rata-rata tertimbang antara presisi dan recall. 1 itu baik dan 0 itu buruk.
🎓 Dukungan: Jumlah kejadian per label
🎓 Akurasi: (PB + NB)/(PB + PS + NB + NS) Persentase label yang diprediksi dengan benar untuk sebuah sampel.
🎓 Rata-rata Makro: Hitungan rata-rata sederhana (non-tertimbang) metrik setiap label tanpa menghiraukan ketidakseimbangan label.
🎓 Rata-rata Tertimbang: Hitungan rata-rata metrik setiap label dengan mempertimbangkan ketidakseimbangan label. Rata-ratanya tertimbang nilai Dukungan (jumlah kejadian dalam realita) setiap label.
✅ Apa kamu bisa tebak metrik apa yang harus dipantau untuk mengurangi jumlah negatif palsu modelmu?
Visualisasikan kurva ROC model ini
Ini bukanlah sebuah model buruk. Akurasinya sekitar 80%, jadi sebenarnya bisa digunakan untuk memprediksi warna sebuah labu berdasarkan beberapa variabel.
Mari kita memvisualisasikan datanya sekali lagi untuk melihat nilai ROC ini:
from sklearn.metrics import roc_curve, roc_auc_score
y_scores = model.predict_proba(X_test)
# calculate ROC curve
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:,1])
sns.lineplot([0, 1], [0, 1])
sns.lineplot(fpr, tpr)
Menggunakan Seaborn lagi, gambarlah Receiving Operating Characteristic (ROC) model ini. Kurva ROC seringkali digunakan untuk menunjukkan output sebuah pembuat klasifikasi berdasarkan jumlah positif benar dan positif palsunya. "Kurva ROC biasanya menetapkan persentase positif benar di sumbu Y dan positif palsunya di sumbu X" (diterjemahkan). Maka, terjalnya kurva ini dan ruang antara garis titik tengah dan kurvanya penting: kamu mau sebuah kurva yang naik ke atas garisnya secepat mungkin. Dalam kasus ini, ada positif palsu di awal, terus kurvanya naik di atas garisnya dengan benar:
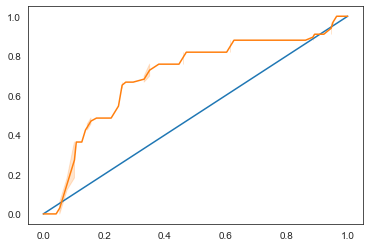
Akhirnya, gunakanlah API roc_auc_score Scikit-learn untuk menghitung 'Area Di Bawah Kurva'-nya (ADBK) secara persis:
auc = roc_auc_score(y_test,y_scores[:,1])
print(auc)
Hasilnya adalah 0.6976998904709748. Mengingat bahwa ADBK itu antara 0 dan 1, lebih besar ADBK-nya lebih baik sebab ADBK model yang 100% benar terus adalah 1; dalam kasus ini, modelnya lumayan bagus.
Nanti dalam pelajaran lebih lanjut tentang klasifikasi, kamu akan belajar bagaimana mengulang untuk membuat nilai-nilai modelmu lebih baik. Tetapi sekian dulu. Selamat! Kamu selesai pelajaran-pelajaran regresi ini!
🚀 Tantangan
Masih ada banyak tentang regresi logistik! Tetapi cara paling baik adalah untuk bereksperimen. Carilah sebuah dataset yang bisa diteliti seperti ini dan bangunlah sebuah model darinya. Apa yang kamu pelajari? Petunjuk: Coba Kaggle untuk dataset-dataset menarik.
Kuis pasca-ceramah
Review & Pembelajaran mandiri
Bacalah beberapa halaman pertama makalah ini dari Stanford tentang beberapa penggunaan praktis regresi logistik. Pikirkan tentang tugas-tugas yang lebih baik untuk suatu jenis regresi atau jenis-jenis lainnya yang kita telah pelajari sampai kini. Apa yang akan bekerja paling baik?