Add pt-BR translation to Regression lesson (#394)
* start pt-br translation on regression section * add pt-br translation on tools section of regression lesson * add pt-br translation on data section of regression lesson * add pt-br translation on linear section of regression lesson * add pt-br translation on logistic section of regression lesson * add syntax and others types of fixes on regression lesson * add url fixes on regression lesson * add syntax fixes on regression lesson * add syntax fixes on regression lessonpull/396/head
parent
4631e0e6c1
commit
ad1656d884
@ -0,0 +1,213 @@
|
||||
# Primeiros passos com Python e Scikit-learn para modelos de regressão
|
||||
|
||||

|
||||
|
||||
> _Sketchnote_ por [Tomomi Imura](https://www.twitter.com/girlie_mac)
|
||||
|
||||
## [Questionário inicial](https://white-water-09ec41f0f.azurestaticapps.net/quiz/9?loc=br)
|
||||
|
||||
> ### [Esta lição está disponível em R!](../solution/R/lesson_1-R.ipynb)
|
||||
|
||||
## Introdução
|
||||
|
||||
Nestas quatro lições, você irá descobrir como construir modelos de regressão. Discutiremos o que eles são daqui a pouco. Antes de mais nada, certifique-se que tem as ferramentas de que precisa para começar!
|
||||
|
||||
Nesta lição, você aprenderá como:
|
||||
|
||||
- Configurar seu computador para tarefas de _machine learning_.
|
||||
- Trabalhar com Jupyter notebooks.
|
||||
- Usar Scikit-learn, incluindo como fazer sua instalação.
|
||||
- Explorar regressão linear com exercícios práticos.
|
||||
|
||||
## Instalação e configuração
|
||||
|
||||
[](https://youtu.be/yyQM70vi7V8 "Configurar Python no Visual Studio Code")
|
||||
|
||||
> 🎥 Clique na imagem acima para assistir o vídeo: usando Python no VS Code (vídeo em inglês).
|
||||
|
||||
1. **Instale Python**. Verifique se você já instalou [Python](https://www.python.org/downloads/) em seu computador. Você usará Python para muitas tarefas de _data science_ (ciência de dados) e _machine learning_. A maioria dos sistemas de computador já possui Python instalado. Existem [Pacotes de Código em Python](https://code.visualstudio.com/learn/educators/installers?WT.mc_id=academic-15963-cxa) disponíveis para ajudar na instalação.
|
||||
|
||||
Algumas aplicações em Python exigem versões diferentes da linguagem. Portanto, será útil trabalhar com [ambiente virtual](https://docs.python.org/3/library/venv.html).
|
||||
|
||||
2. **Instale o Visual Studio Code**. Verifique se já existe o Visual Studio Code instalado em seu computador. Siga essas instruções para [instalar o Visual Studio Code](https://code.visualstudio.com/) com uma instalação básica. Você usará Python no Visual Studio Code neste curso e precisará [configurar o Visual Studio Code](https://docs.microsoft.com/learn/modules/python-install-vscode?WT.mc_id=academic-15963-cxa) para isso.
|
||||
|
||||
> Fique mais confortável em usar Python trabalhando nessa coleção de [módulos de aprendizagem](https://docs.microsoft.com/users/jenlooper-2911/collections/mp1pagggd5qrq7?WT.mc_id=academic-15963-cxa).
|
||||
|
||||
3. **Instale a Scikit-learn**, seguindo [estas instruções](https://scikit-learn.org/stable/install.html). Visto que você precisa ter certeza que está usando o Python 3, é recomendável usar um ambiente virtual. Note que se você estiver usando essa biblioteca em um M1 Mac, há instruções específicas na página linkada acima.
|
||||
|
||||
1. **Instale o Jupyter Notebook**. Você precisará [instalar o pacote Jupyter](https://pypi.org/project/jupyter/).
|
||||
|
||||
## Seu ambiente de ML
|
||||
|
||||
Você irá usar **_notebooks_** para desenvolver código em Python e criar modelos de _machine learning_. Esse tipo de arquivo é uma ferramenta comum para _data scientists_, e pode ser identificado pelo sufixo ou extensão `.ipynb`.
|
||||
|
||||
_Notebooks_ são ambientes interativos que permitem a construção de código de programação e notas de _markdown_ para documentá-lo, o que pode ser muito útil para
|
||||
projetos experimentais ou de pesquisa.
|
||||
|
||||
### Exercício - Trabalhando com um **_notebook_**
|
||||
|
||||
Nesta pasta, você encontrará o arquivo _notebook.ipynb_.
|
||||
|
||||
1. Abra _notebook.ipynb_ no Visual Studio Code.
|
||||
|
||||
Um servidor Jupyter será iniciado com Python 3+ carregado. Você encontrará áreas do _notebook_ que podem ser executadas (`run`). Para executar uma célula de código, basta clicar no ícone que parece um botão _play_ ▶.
|
||||
|
||||
1. Adicione uma célula de _markdown_ (ícone `md`) e escreva o texto: "**# Boas-vindas ao seu notebook**" (Welcome to your Notebook).
|
||||
|
||||
Em seguida, adicionaremos algum código em Python.
|
||||
|
||||
1. Crie e escreva **print('hello notebook')** numa célula de código.
|
||||
1. Clique no ícone ▶ para executar o código.
|
||||
|
||||
O resultado ficará assim:
|
||||
|
||||
```output
|
||||
hello notebook
|
||||
```
|
||||
|
||||

|
||||
|
||||
Você pode adicionar comentários para documentar seu _notebook_.
|
||||
|
||||
✅ Pense por um momento em como o ambiente de uma pessoa desenvolvedora _web_ difere do ambiente para _data scientists_.
|
||||
|
||||
## Scikit-learn instalado e funcionando
|
||||
|
||||
Agora que Python está funcionando em seu ambiente local e você está mais confortável com Jupyter notebooks, vamos nos familizar com a Scikit-learn (a pronúncia de `sci` é a mesma do verbo sair conjugado na forma `sai`). Scikit-learn fornece uma [API abrangente](https://scikit-learn.org/stable/modules/classes.html#api-ref) para te ajudar com tarefas de ML.
|
||||
|
||||
De acordo com o seu [website](https://scikit-learn.org/stable/getting_started.html), "Scikit-learn é uma bibilioteca de código aberto para _machine learning_ que suporta aprendizado supervisionado e não supervisionado. Também fornece várias ferramentas para ajuste de modelo, processamento de dados, seleção e validação de modelo, etc."
|
||||
|
||||
Nesse curso, você irá usar a Scikit-learn e outras ferramentas para construir modelos de _machine learning_ para fazer as chamadas tarefas "tradicionais" de _machine learning_. Nós evitamos usar _neural networks_ (redes neurais) e _deep learning_ (aprendizagem profunda) por que serão abordadas de uma forma mais completa no curso de "AI para iniciantes".
|
||||
|
||||
Scikit-learn facilita a construção e validação de modelos. O foco principal é no uso de dados numéricos mas também contém vários conjuntos de dados prontos para serem usados como ferramenta de estudo. Também possui modelos pré-construídos para os alunos experimentarem. Vamos explorar o processo de carregar dados predefinidos e usar um modelo com estimador integrado com a Scikit-learn e alguns dados básicos.
|
||||
|
||||
## Exercício - Seu primeiro notebook Scikit-learn
|
||||
|
||||
> Este tutorial foi inspirado pelo [exemplo de regressão linear](https://scikit-learn.org/stable/auto_examples/linear_model/plot_ols.html#sphx-glr-auto-examples-linear-model-plot-ols-py) do site da Scikit-learn.
|
||||
|
||||
No arquivo _notebook.ipynb_, limpe todas as células clicando no ícone que parece uma lata de lixo 🗑️.
|
||||
|
||||
Nesta seção, você irá trabalhar com um pequeno conjunto de dados sobre diabetes que foi produzido para a Scikit-learn com fins de aprendizagem. Imagine que você queira testar um tratamento para pessoas diabéticas. Modelos de _machine learning_ podem te ajudar a escolher quais pacientes irão responder melhor ao tratamento, baseado em combinações de variáveis. Mesmo um modelo de regressão simples, quando visualizado, pode mostrar informações sobre variáveis que ajudarão a organizar ensaios clínicos teóricos.
|
||||
|
||||
✅ Existem muitos tipos de métodos de regressão, e a escolha dentre eles dependerá da resposta que você procura. Se você quer prever a altura provável de uma pessoa de uma determinada idade, você deve usar a regressão linear, pois está sendo usado um **valor numérico**. Se você quer descobrir se um tipo de cozinha pode ser considerado vegano ou não, isso está relacionado a uma **atribuição de categoria**, então usa-se a regressão logística. Você irá aprender mais sobre regressão logística em breve. Pense um pouco nas questões que aparecem com os dados que você tem e qual desses métodos seria mais apropriado usar.
|
||||
|
||||
Vamos começar a tarefa.
|
||||
|
||||
### Importe as bibliotecas
|
||||
|
||||
Para esta tarefa nós importaremos algumas bibliotecas:
|
||||
|
||||
- **matplotlib**. É uma [ferramenta gráfica](https://matplotlib.org/) que usaremos para criar um gráfico de linha.
|
||||
- **numpy**. [Numpy](https://numpy.org/doc/stable/user/whatisnumpy.html) é uma biblioteca útil que lida com dados numéricos em Python.
|
||||
- **sklearn**. Essa é a bilioteca [Scikit-learn](https://scikit-learn.org/stable/user_guide.html).
|
||||
|
||||
Importe essas bibliotecas pois te ajudarão na tarefa.
|
||||
|
||||
1. Para importar você pode usar o código abaixo:
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
from sklearn import datasets, linear_model, model_selection
|
||||
```
|
||||
|
||||
Acima, você está importando `matplottlib`, `numpy` e também `datasets`, `linear_model` e `model_selection` da `sklearn`. A função `model_selection` é usada para dividir os dados em conjuntos de dados de treinamento e teste.
|
||||
|
||||
### O conjunto de dados sobre diabetes
|
||||
|
||||
O [conjunto de dados sobre diabetes](https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset) inclui 442 exemplos de dados sobre diabetes, com 10 variáveis de características, algumas delas incluem:
|
||||
|
||||
- age: idade em anos
|
||||
- bmi (body mass index): índice de massa corporal
|
||||
- bp (blood pressure): média de pressão sanguínea
|
||||
- s1 tc: Células T (um tipo de glóbulo branco)
|
||||
|
||||
✅ Esse conjunto de dados inclui o conceito de "sexo" como variável de característica importante no contexto de diabetes. Muitos conjuntos de dados médicos incluem tipos de classificação binária. Pense um pouco sobre como categorizações como essa podem excluir partes de uma população dos tratamentos.
|
||||
|
||||
Agora, carregue os dados X e y.
|
||||
|
||||
> 🎓 Lembre-se que esse é um processo de aprendizado supervisionado, portanto, precisamos de um alvo 'y'.
|
||||
|
||||
Em uma célula de código, carregue o conjunto de dados sobre diabetes chamando a função `load_diabetes()`. O parâmetro `return_X_y=True` indica que `X` será uma matriz de dados e `y` é o alvo da regressão.
|
||||
|
||||
1. Adicione alguns comandos _print_ para mostrar a forma da matriz e seu primeiro elemento:
|
||||
|
||||
```python
|
||||
X, y = datasets.load_diabetes(return_X_y=True)
|
||||
print(X.shape)
|
||||
print(X[0])
|
||||
```
|
||||
|
||||
A função retorna uma estrutura chamada tupla. Na primeira linha, os dois primeiros valores da tupla são atribuidos a `X` e `y`, respectivamente. Saiba mais [sobre tuplas](https://wikipedia.org/wiki/Tuple).
|
||||
|
||||
Você pode observar que os dados possuem 442 elementos divididos em matrizes de 10 elementos:
|
||||
|
||||
```text
|
||||
(442, 10)
|
||||
[ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076
|
||||
-0.04340085 -0.00259226 0.01990842 -0.01764613]
|
||||
```
|
||||
|
||||
✅ Pense sobre a relação entre os dados e o alvo da regressão. Regressão linear sugere a relação entre a característica X e a característica alvo y. Você pode achar o [alvo](https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset) para o conjunto de dados sobre diabetes na documentação? Conhecendo o alvo, o que este conjunto de dados demonstra?
|
||||
|
||||
2. Em seguida, selecione uma parte do conjunto de dados para plotar em um gráfico, colocando-o em uma nova matriz usando a função `newaxis` da numpy. Iremos usar regressão linear para gerar uma linha entre os valores do conjunto de dados, de acordo com o padrão que ela é definida.
|
||||
|
||||
```python
|
||||
X = X[:, np.newaxis, 2]
|
||||
```
|
||||
|
||||
✅ Você pode adicionar comandos _print_ para imprimir e visualizar os dados e verificar seus formatos.
|
||||
|
||||
3. Agora que os dados estão prontos para serem plotados, podemos usar uma máquina para ajudar a determinar a divisão lógica entre os dados no conjunto de dados. Para isso, é necessário dividir os dados (X) e o alvo (y) em conjuntos de teste e treinamento e a Scikit-learn oferece uma maneira de fazer isso.
|
||||
|
||||
```python
|
||||
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33)
|
||||
```
|
||||
|
||||
4. Seu modelo está pronto para ser treinado! Carregue o modelo de regressão linear e treine-o usando seus conjuntos de treinamento X e Y usando a função `model.fit()`:
|
||||
|
||||
```python
|
||||
model = linear_model.LinearRegression()
|
||||
model.fit(X_train, y_train)
|
||||
```
|
||||
|
||||
✅ `model.fit()` é uma função que aparece em muitas biblioteas de ML, como a TensorFlow.
|
||||
|
||||
5. Por fim, faça uma previsão com seus dados de teste, usando a função `predict()`. Isso será usado para traçar uma linha entre os grupos de dados.
|
||||
|
||||
```python
|
||||
y_pred = model.predict(X_test)
|
||||
```
|
||||
|
||||
6. Chegou a hora de mostrar os resultados em um gráfico. Matplotlib é a ferramenta perfeita para essa tarefa. Crie um gráfico de dispersão (`scatter`) de todos os dados de teste de X e y, e use a previsão feita para traçar no lugar mais adequado, entre os grupos de dados do modelo.
|
||||
|
||||
```python
|
||||
plt.scatter(X_test, y_test, color='black')
|
||||
plt.plot(X_test, y_pred, color='blue', linewidth=3)
|
||||
plt.xlabel('Scaled BMIs')
|
||||
plt.ylabel('Disease Progression')
|
||||
plt.title('A Graph Plot Showing Diabetes Progression Against BMI')
|
||||
plt.show()
|
||||
```
|
||||
|
||||

|
||||
|
||||
✅ Observe o que está acontecendo. Uma linha reta está atravessando os pequenos pontos de dados, mas o que significa isso? Você consegue ver como pode usar essa linha para prever onde um ponto de dados novo ficaria em relação ao eixo y deste gráfico? Tente colocar em palavras o uso prático desse modelo.
|
||||
|
||||
Parabéns, usando um conjunto de dados, você construiu seu primeiro modelo de regressão linear, pediu que ele fizesse uma previsão e a mostrou em forma de gráfico!
|
||||
|
||||
---
|
||||
## 🚀Desafio
|
||||
|
||||
Plote uma variável diferente desse mesmo conjunto de dados. Dica: edite a linha: `X = X[:, np.newaxis, 2]`. Dado o conjunto de dados alvo, o que pode ser descoberto sobre o progresso da diabetes como uma doença?
|
||||
## [Questionário para fixação](https://white-water-09ec41f0f.azurestaticapps.net/quiz/10?loc=br)
|
||||
|
||||
## Revisão e Auto Aprendizagem
|
||||
|
||||
Neste tutorial, você trabalhou com regressão linear simples, ao invés de regressão univariada ou múltipla. Leia sobre as diferença desses métodos, ou assista [esse vídeo](https://www.coursera.org/lecture/quantifying-relationships-regression-models/linear-vs-nonlinear-categorical-variables-ai2Ef).
|
||||
|
||||
Leia mais sobre o conceito de regressão e pense sobre os tipos de questões que podem ser respondidas usando essa técnica. Faça esse [tutorial](https://docs.microsoft.com/learn/modules/train-evaluate-regression-models?WT.mc_id=academic-15963-cxa) para aprender mais.
|
||||
|
||||
## Tarefa
|
||||
|
||||
[Um conjunto de dados diferente](assignment.pt-br.md).
|
||||
@ -0,0 +1,13 @@
|
||||
# Regressão com Scikit-learn
|
||||
|
||||
## Instruções
|
||||
|
||||
Dê uma olhada no [conjunto de dados Linnerud](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_linnerud.html#sklearn.datasets.load_linnerud). Esse conjunto de dados possui múltiplos [alvos](https://scikit-learn.org/stable/datasets/toy_dataset.html#linnerrud-dataset): 'Consiste em três variáveis de exercício (dados) e três variáveis fisiológicas (alvos) coletadas de vinte homens de meia idade de uma academia '.
|
||||
|
||||
Em suas palavras, descreva como criar um modelo de regressão que mostra a relação entre a cintura e o número de abdominiais feitas. Faça o mesmo para os outros pontos de dados nesse conjunto de dados.
|
||||
|
||||
## Critérios de avaliação
|
||||
|
||||
| Critério | Exemplar | Adequado | Precisa melhorar |
|
||||
| ------------------------------ | ----------------------------------- | -------------------------------- | ---------------------------- |
|
||||
| Enviar um parágrafo descritivo | Parágrafo bem escrito | Algumas sentenças foram enviadas | Não possui nenhuma descrição |
|
||||
@ -0,0 +1,208 @@
|
||||
# Construindo um modelo de regressão usando Scikit-learn: preparar e visualizar dados
|
||||
|
||||

|
||||
|
||||
Infográfico por [Dasani Madipalli](https://twitter.com/dasani_decoded)
|
||||
|
||||
## [Questionário inicial](https://white-water-09ec41f0f.azurestaticapps.net/quiz/11?loc=br)
|
||||
|
||||
> ### [Esta liçao está disponível em R!](../solution/R/lesson_2-R.ipynb)
|
||||
|
||||
## Introdução
|
||||
|
||||
Agora que você configurou as ferramentas que precisa para começar a construir modelos de _machine learning_ com o Scikit-learn, vamos fazer perguntas sobre seus dados. Conforme você trabalha com dados e aplica soluções de ML, é muito importante entender como fazer a pergunta certa para obter o melhor de seu conjunto de dados.
|
||||
|
||||
Nesta lição, você irá aprender a:
|
||||
|
||||
- Como preparar os dados para a construção do modelo.
|
||||
- Como usar matplotlib para visualização de dados.
|
||||
|
||||
[](https://youtu.be/11AnOn_OAcE "Preparando e Visualizando dados - Clique para assistir!")
|
||||
> 🎥 Clique na imagem acima para assistir a um vídeo sobre os principais aspectos desta lição (vídeo em inglês).
|
||||
|
||||
|
||||
## Fazendo a pergunta correta a seus dados
|
||||
|
||||
A pergunta que você precisa responder determinará que tipo de algoritmos de ML você usará. E a qualidade da resposta que você receber dependerá muito da natureza dos seus dados.
|
||||
|
||||
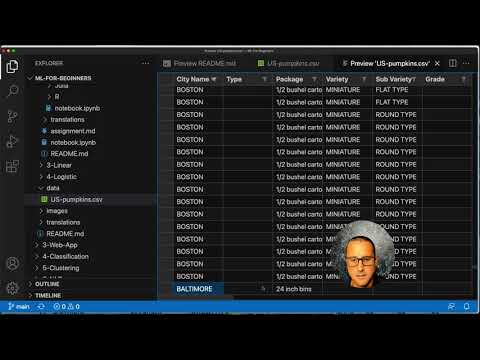
Dê uma olhada [nesses dados](../../data/US-pumpkins.csv). Você pode abrir este arquivo .csv no VS Code. Uma rápida leitura mostra imediatamente que existem espaços em branco e uma mistura de strings e dados numéricos. Há também uma coluna estranha chamada `Package` onde os dados são uma mistura entre 'sacks' (sacos), 'bins' (caixas) e outros valores. Esses dados estão uma bagunça.
|
||||
|
||||
A verdade é que raramente somos apresentados a um conjunto de dados que pode ser usado diretamente para criar um modelo de ML. Nesta lição, você aprenderá como preparar um conjunto de dados "bruto" usando bibliotecas Python. Você também aprenderá várias técnicas para visualizar os dados.
|
||||
|
||||
## Caso de estudo: 'o mercado de abóboras'
|
||||
|
||||
Na pasta `data`, na raiz do projeto, você encontrará um arquivo .csv chamado [US-pumpkins.csv](../../data/US-pumpkins.csv) que inclui 1757 linhas de dados sobre o mercado de abóboras, classificados em agrupamentos por cidade. Estes são dados brutos extraídos dos [Specialty Crops Terminal Markets Standard Reports](https://www.marketnews.usda.gov/mnp/fv-report-config-step1?type=termPrice) (Relatórios Padrão de Mercados Terminais para Cultivos Especiais) distribuído pelo Departamento de Agricultura dos Estados Unidos.
|
||||
|
||||
### Preparando os dados
|
||||
|
||||
Esses dados são abertos ao público. Podem ser baixados em arquivos separados, por cidade, no site do USDA. Para evitar muitos arquivos separados, concatenamos todos os dados da cidade em uma planilha, feito isso, já _preparamos_ os dados um pouco. Agora vamos examinar mais de perto os dados.
|
||||
|
||||
### Dados das abóboras - conclusões inciais
|
||||
|
||||
O que você acha desses dados? Você já viu que existe uma mistura de strings, números, espaços em branco e valores estranhos?
|
||||
|
||||
Que pergunta você pode fazer sobre esses dados, usando uma técnica de regressão? Que tal "Como prever o preço de uma abóbora à venda durante um determinado mês"?. Olhando novamente para os dados, existem algumas mudanças que você precisa fazer para criar a estrutura de dados necessária para a tarefa.
|
||||
|
||||
## Exercício - Análise dos dados das abóboras
|
||||
|
||||
Vamos usar o [Pandas](https://pandas.pydata.org/), (que significa `Python Data Analysis`) uma ferramenta útil para moldar, analizar e preparar dados.
|
||||
|
||||
### Primeiro, procuramos datas faltantes
|
||||
|
||||
Você precisará seguir alguns passos para procurar por datas faltantes:
|
||||
|
||||
1. Converta as datas para um formato mensal (as datas estão no formato dos EUA, ou seja, `MM/DD/AAAA`).
|
||||
2. Transforme o mês numa nova coluna.
|
||||
|
||||
Abra o arquivo _notebook.ipynb_ no Visual Studio Code e importe a planilha no formato de um _dataframe_ Pandas.
|
||||
|
||||
1. Use a função `head()` para visualizar as cinco primeiras linhas.
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
pumpkins = pd.read_csv('../data/US-pumpkins.csv')
|
||||
pumpkins.head()
|
||||
```
|
||||
|
||||
✅ Qual função você usaria para visualizar as últimas cinco linhas?
|
||||
|
||||
1. Veja se existe datas faltantes no _dataframe_ atual:
|
||||
|
||||
```python
|
||||
pumpkins.isnull().sum()
|
||||
```
|
||||
|
||||
Alguns dados estão faltando, mas talvez não sejam necessários para esta tarefa.
|
||||
|
||||
1. Para tornar seu _dataframe_ mais fácil de usar, remova algumas das colunas usando a função `drop()`, mantendo apenas as colunas que você precisa:
|
||||
|
||||
```python
|
||||
new_columns = ['Package', 'Month', 'Low Price', 'High Price', 'Date']
|
||||
pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
|
||||
```
|
||||
|
||||
### Segundo, calcule o preço médio das abóboras
|
||||
|
||||
Pense em como determinar o preço médio de uma abóbora em um determinado mês. Quais colunas você escolheria para esta tarefa? Dica: você precisará de 3 colunas.
|
||||
|
||||
Solução: pegue a média das colunas `Low Price` (Preço baixo) e `High Price` (Preço alto) para preencher a nova coluna `Price` (Preço) e converta a coluna `Date` (Data) para mostrar apenas o mês. Felizmente, de acordo com a verificação acima, não faltam dados de datas ou preços.
|
||||
|
||||
1. Pra calcular a média, adicione o seguinte código:
|
||||
|
||||
```python
|
||||
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2
|
||||
|
||||
month = pd.DatetimeIndex(pumpkins['Date']).month
|
||||
|
||||
```
|
||||
|
||||
✅ Sinta-se a vontade para imprimir qualquer dado usando `print(nome da variável aqui)`.
|
||||
|
||||
2. Agora, copie sua data convertida em um _dataframe_ Pandas novinho em folha:
|
||||
|
||||
```python
|
||||
new_pumpkins = pd.DataFrame({'Month': month, 'Package': pumpkins['Package'], 'Low Price': pumpkins['Low Price'],'High Price': pumpkins['High Price'], 'Price': price})
|
||||
```
|
||||
|
||||
Ao imprimir seu _dataframe_, você verá um conjunto de dados limpo e organizado para criar seu modelo de regressão.
|
||||
|
||||
### Mas espere! Parece que tem algo estranho 🤔
|
||||
|
||||
Se você olhar a coluna `Package` (Pacote), as abóboras são vendidas em muitas configurações diferentes. Algumas são vendidas em medidas de '1 1/9 bushel' (bushel é uma unidade de medida, equivalente à "alqueire"), e algumas de '1/2 bushel', algumas por abóbora, algumas por libra (unidade de medida) e algumas em grandes caixas de larguras variadas.
|
||||
|
||||
> Parece que é difícil pesar a abóbora de uma forma consistente.
|
||||
|
||||
Analisando os dados originais, é interessante observar que qualquer coisa com `Unit of Sale` (Unidade de Venda) igual a 'EACH' ou 'PER BIN' também tem o tipo `Package` com "per inch" (por polegada), "per bin" (por caixa) ou "each" (ambos). Como as abóboras são difíceis de pesar de forma consistente, vamos filtrá-las selecionando apenas as abóboras com a string "bushel" em sua coluna `Package`.
|
||||
|
||||
1. Adicione um filtro na parte superior do arquivo, abaixo da importação inicial do .csv:
|
||||
|
||||
```python
|
||||
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]
|
||||
```
|
||||
|
||||
Se você imprimir os dados agora, verá que retorna cerca de 415 contendo dados de abóboras por bushel.
|
||||
|
||||
### Opa! Mais uma coisa...
|
||||
|
||||
Você notou que a quantidade de bushel varia por linha? Você precisa normalizar o preço para mostrar o preço por bushel.
|
||||
|
||||
1. Adicione essas linhas após o bloco criando o _dataframe_ `new_pumpkins`:
|
||||
|
||||
```python
|
||||
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/(1 + 1/9)
|
||||
|
||||
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price/(1/2)
|
||||
```
|
||||
|
||||
✅ De acordo com [The Spruce Eats](https://www.thespruceeats.com/how-much-is-a-bushel-1389308), o peso por bushel depende do tipo de produto, pois é uma medida de volume. "Um bushel de tomates, por exemplo, deve pesar 56 libras (25,4 kg).. Folhas e verduras ocupam mais espaço com menos peso, então um bushel de espinafre pesa apenas 20 libras (9,1 kg)." (fala traduzida). É muito complicado! Não vamos nos preocupar em fazer uma conversão de bushel para libra e, em vez disso, definir o preço por bushel. Perceba que todo esse estudo de bushels de abóboras mostra como é muito importante entender a natureza de seus dados!
|
||||
|
||||
Você pode analisar o preço por unidade com base na medição do bushel. Se você imprimir os dados mais uma vez, verá como eles estão padronizados.
|
||||
|
||||
✅ Você notou que as abóboras vendidas a meio bushel são muito caras? Você pode descobrir por quê? Dica: as abóboras pequenas são muito mais caras do que as grandes, provavelmente porque há muito mais delas por bushel, especialmente considerando que uma abóbora grande tem uma grande cavidade vazia.
|
||||
|
||||
## Estratégias de visualização
|
||||
|
||||
Parte da função do _data scientist_ é demonstrar a qualidade e a natureza dos dados com os quais está trabalhando. Para fazer isso, eles geralmente criam visualizações, ou plotagens, gráficos e tabelas, mostrando diferentes aspectos dos dados. Dessa forma, eles são capazes de mostrar visualmente relações e lacunas que, de outra forma, seriam difíceis de descobrir.
|
||||
|
||||
As visualizações também podem ajudar a determinar a técnica de _machine learning_ mais adequada para os dados. Um gráfico de dispersão que parece seguir uma linha, por exemplo, indica que os dados são bons candidatos para um exercício de regressão linear.
|
||||
|
||||
Uma biblioteca de visualização de dados que funciona bem nos blocos de _notebooks_ é a [Matplotlib](https://matplotlib.org/) (que você também viu na lição anterior).
|
||||
|
||||
> Ganhe mais experiência em visualização de dados fazendo [esses tutoriais](https://docs.microsoft.com/learn/modules/explore-analyze-data-with-python?WT.mc_id=academic-15963-cxa).
|
||||
|
||||
## Exercício - Experimento com Matplotlib
|
||||
|
||||
Tente criar alguns gráficos básicos para exibir o novo _dataframe_ que você acabou de criar. O que um gráfico de linha básico mostraria?
|
||||
|
||||
1. Importe a Matplotlib no início do arquivo, embaixo da importação do pandas:
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
```
|
||||
|
||||
1. Execute o _notebook_ inteiro para atualizá-lo.
|
||||
1. No final do _notebook_, adicione uma célula para plotar os dados:
|
||||
|
||||
```python
|
||||
price = new_pumpkins.Price
|
||||
month = new_pumpkins.Month
|
||||
plt.scatter(price, month)
|
||||
plt.show()
|
||||
```
|
||||
|
||||

|
||||
|
||||
Esse gráfico é relevante? Alguma coisa nele te surpreende?
|
||||
|
||||
O gráfico não é útil, pois tudo o que faz é exibir seus dados como uma distribuição de pontos em um determinado mês.
|
||||
|
||||
### Torne o gráfico útil
|
||||
|
||||
Para fazer com que os gráficos exibam dados úteis, você precisa agrupar os dados de alguma forma. Vamos tentar criar um gráfico onde o eixo "y" mostra os meses e o eixo "x" mostra a distribuição dos preços das abóboras.
|
||||
|
||||
1. Adicione uma célula de código para criar um gráfico de barras:
|
||||
|
||||
```python
|
||||
new_pumpkins.groupby(['Month'])['Price'].mean().plot(kind='bar')
|
||||
plt.ylabel("Pumpkin Price")
|
||||
```
|
||||
|
||||

|
||||
|
||||
Essa visualização de dados parece ser mais útil! Parece indicar que o preço mais alto das abóboras ocorre em setembro e outubro. Isso atende às suas expectativas? Por quê ou por quê não?
|
||||
|
||||
---
|
||||
|
||||
## 🚀Desafio
|
||||
|
||||
Explore os diferentes tipos de visualização que o Matplotlib oferece. Quais tipos são mais adequados para problemas de regressão?
|
||||
|
||||
## [Questionário para fixação](https://white-water-09ec41f0f.azurestaticapps.net/quiz/12?loc=br)
|
||||
|
||||
## Revisão e Auto Aprendizagem
|
||||
|
||||
Dê uma olhada nas maneiras de visualizar dados. Faça uma lista das várias bibliotecas disponíveis e observe quais são as melhores para determinados tipos de tarefas, por exemplo, visualizações 2D vs. visualizações 3D. O que você descobriu?
|
||||
|
||||
## Tarefa
|
||||
|
||||
[Explorando visualização](assignment.pt-br.md).
|
||||
@ -0,0 +1,11 @@
|
||||
# Explorando Visualizações
|
||||
|
||||
## Instruções
|
||||
|
||||
Existem muitas bibliotecas disponíveis para visualização de dados. Crie algumas visualizações usando o conjunto de dados sobre abóboras nesta lição usando matplotlib e seaborn em um _notebook_. Quais bibliotecas são mais fáceis de usar?
|
||||
|
||||
## Critérios de avaliação
|
||||
|
||||
| Critério | Exemplar | Adequado | Precisa melhorar |
|
||||
| -------- | --------- | -------- | ----------------- |
|
||||
| | Um _notebook_ foi submetido com duas explorações/visualizações | Um _notebook_ foi submetido com uma exploração/visualização | Nenhum _notebook_ foi submetido |
|
||||
@ -0,0 +1,11 @@
|
||||
# Construa um modelo de regressão
|
||||
|
||||
## Instruções
|
||||
|
||||
Nesta lição, mostramos como construir um modelo usando regressão linear e polinomial. Usando o que aprendeu, encontre um conjunto de dados ou use um dos conjuntos integrados a Scikit-Learn para construir um novo modelo. Explique em seu _notebook_ porque você escolheu uma técnica particular e demonstre a acurácia do modelo. E se a acurácia não for boa, explique por quê.
|
||||
|
||||
## Critérios de avaliação
|
||||
|
||||
| Critério | Exemplar | Adequado | Precisa melhorar |
|
||||
| -------- | ------------------------------------------------------------ | -------------------------- | ------------------------------- |
|
||||
| | Apresenta um _notebook_ completo e bem documentado | A solução está incompleta | A solução possui _bugs_ |
|
||||
@ -0,0 +1,11 @@
|
||||
# Refazendo a regressão
|
||||
|
||||
## Instruções
|
||||
|
||||
Nesta lição, você usou um subconjunto do conjunto de dados de abóboras. Volte aos dados originais e tente usar todos eles, tratados e padronizados, para construir um modelo de Regressão Logística.
|
||||
|
||||
## Critérios de avaliação
|
||||
|
||||
| Critério | Exemplar | Adequado | Precisa melhorar |
|
||||
| -------- | ----------------------------------------------------------------------- | ------------------------------------------------------------ | ----------------------------------------------------------- |
|
||||
| | Apresenta um modelo bem explicado e de bom desepenho | Apresenta um modelo com desempenho mínimo | Apresenta um modelo baixo desempenho |
|
||||
@ -0,0 +1,34 @@
|
||||
# Modelos de regressão para *machine learning*
|
||||
## Tema regional: Modelos de regressão para preços de abóbora na América do Norte 🎃
|
||||
|
||||
Na América do Norte, é costume esculpir rostos assustadores em abóbora no Halloween. Vamos descobrir mais sobre esses vegetais
|
||||
fascinantes!
|
||||
|
||||

|
||||
> Foto de <a href="https://unsplash.com/@teutschmann?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Beth Teutschmann</a> em <a href="https://unsplash.com/s/photos/jack-o-lanterns?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
|
||||
|
||||
## O que vamos aprender
|
||||
|
||||
As lições desta seção abordam tipos de regressão no contexto de _machine learning_. Modelos de regressão podem ajudar a determinar a _relação_ entre variáveis. Esse tipo de modelo pode prever valores como comprimento, temperatura ou idade, sugerindo relações entre variáveis à medida que analisa pontos de dados.
|
||||
|
||||
Nesta série de lições, você descobrirá a diferença entre regressão linear e logística, e quando deve usar uma ou outra.
|
||||
|
||||
Neste grupo de lições, te prepararemos para começar tarefas de _machine learning_, incluindo configuração do Visual Studio Code para gerenciar _notebooks_, o ambiente comum para _data scientists_ (cientistas de dados). Você descobrirá a Scikit-learn, uma biblioteca para _machine learning_, e construirá seus primeiros modelos, focando em modelos de regressão neste capítulo.
|
||||
|
||||
> Existem ferramentas _low-code_ que podem ajudar a aprender como trabalhar com modelos de regressão. Use a [Azure ML para esta tarefa](https://docs.microsoft.com/learn/modules/create-regression-model-azure-machine-learning-designer/?WT.mc_id=academic-15963-cxa).
|
||||
|
||||
### Lições
|
||||
|
||||
1. [Ferramentas necessárias](../1-Tools/translations/README.pt-br.md)
|
||||
2. [Gerenciamento de dados](../2-Data/translations/README.pt-br.md)
|
||||
3. [Regressão linear e polinomial](../3-Linear/translations/README.pt-br.md)
|
||||
4. [Regressão logística](../4-Logistic/translations/README.pt-br.md)
|
||||
|
||||
---
|
||||
### Créditos
|
||||
|
||||
"ML with regression" (ML com regressão) foi escrito com ♥️ por [Jen Looper](https://twitter.com/jenlooper)
|
||||
|
||||
♥️ Contribuidores do questionário incluem: [Muhammad Sakib Khan Inan](https://twitter.com/Sakibinan) e [Ornella Altunyan](https://twitter.com/ornelladotcom)
|
||||
|
||||
O _dataset_ (base de dados) de abóbora foi sugerido por [esse projeto no Kaggle](https://www.kaggle.com/usda/a-year-of-pumpkin-prices) e seus dados vieram dos [Specialty Crops Terminal Markets Standard Reports](https://www.marketnews.usda.gov/mnp/fv-report-config-step1?type=termPrice) (Relatórios Padrão de Mercados Terminais para Cultivos Especiais) distribuído pelo Departamento de Agricultura dos Estados Unidos. Adicionamos alguns pontos sobre a cor por tipo de abóbora para normalizar a distribuição dos dados. Esses dados são abertos ao público.
|
||||
Loading…
Reference in new issue