31 KiB
Препознавање говора са IoT уређајем
Скица од Nitya Narasimhan. Кликните на слику за већу верзију.
Овај видео пружа преглед Azure услуге за говор, теме која ће бити обрађена у овој лекцији:

🎥 Кликните на слику изнад да бисте погледали видео
Квиз пре предавања
Увод
'Алекса, подеси тајмер на 12 минута'
'Алекса, статус тајмера'
'Алекса, подеси тајмер на 8 минута и назови га "кување броколија на пари"'
Паметни уређаји постају све присутнији. Не само као паметни звучници попут HomePods, Echos и Google Homes, већ и уграђени у наше телефоне, сатове, па чак и у расвету и термостате.
💁 У мом дому имам најмање 19 уређаја са гласовним асистентима, и то су само они за које знам!
Гласовна контрола повећава приступачност омогућавајући људима са ограниченим покретима да интерагују са уређајима. Било да је у питању трајни инвалидитет, као што је рођење без руку, привремени инвалидитет, попут сломљене руке, или ситуације када су вам руке пуне куповине или мале деце, могућност контроле куће гласом уместо рукама отвара свет могућности. Узвикнути 'Хеј Сири, затвори гаражна врата' док се борите са пресвлачењем бебе и немирним дететом може бити мала, али значајна олакшица у животу.
Једна од популарнијих употреба гласовних асистената је подешавање тајмера, посебно кухињских. Могућност подешавања више тајмера само гласом је велика помоћ у кухињи - нема потребе да прекидате мешење теста, мешање супе или чишћење руку од пуњења за кнедле да бисте користили физички тајмер.
У овој лекцији ћете научити како да изградите препознавање гласа у IoT уређајима. Научићете о микрофонима као сензорима, како да снимите звук са микрофона повезаног на IoT уређај и како да користите вештачку интелигенцију за претварање онога што се чује у текст. Током остатка овог пројекта изградићете паметни кухињски тајмер који може подешавати тајмере користећи ваш глас на више језика.
У овој лекцији ћемо обрадити:
Микрофони
Микрофони су аналогни сензори који претварају звучне таласе у електричне сигнале. Вибрације у ваздуху узрокују да се компоненте у микрофону померају за врло мале износе, што доводи до малих промена у електричним сигналима. Ове промене се затим појачавају како би се генерисао електрични излаз.
Типови микрофона
Микрофони долазе у различитим типовима:
-
Динамички - Динамички микрофони имају магнет причвршћен за покретну дијафрагму која се помера у калему жице стварајући електричну струју. Ово је супротно од већине звучника, који користе електричну струју за померање магнета у калему жице, покрећући дијафрагму да би створили звук. То значи да звучници могу бити коришћени као динамички микрофони, а динамички микрофони као звучници. Уређаји попут интеркома, где корисник или слуша или говори, али не оба истовремено, могу користити један уређај као и звучник и микрофон.
Динамички микрофони не захтевају напајање за рад, електрични сигнал се у потпуности ствара из микрофона.

-
Тракасти - Тракасти микрофони су слични динамичким микрофонима, осим што имају металну траку уместо дијафрагме. Ова трака се помера у магнетном пољу стварајући електричну струју. Као и динамички микрофони, тракасти микрофони не захтевају напајање за рад.

-
Кондензаторски - Кондензаторски микрофони имају танку металну дијафрагму и фиксну металну задњу плочу. Електрична енергија се примењује на обе и како дијафрагма вибрира, статички набој између плоча се мења, генеришући сигнал. Кондензаторски микрофони захтевају напајање за рад - названо Phantom power.
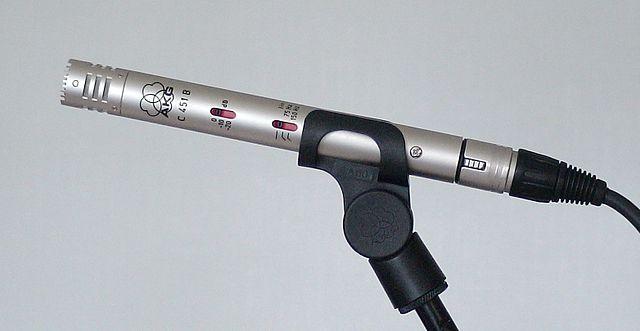
-
MEMS - Микроелектромеханички системи микрофони, или MEMS, су микрофони на чипу. Имају дијафрагму осетљиву на притисак угравирану на силиконски чип и раде слично као кондензаторски микрофони. Ови микрофони могу бити веома мали и интегрисани у електронске кола.

На слици изнад, чип означен LEFT је MEMS микрофон, са малом дијафрагмом мањом од једног милиметра.
✅ Урадите истраживање: Које микрофоне имате око себе - било у вашем рачунару, телефону, слушалицама или другим уређајима? Које врсте микрофона су то?
Дигитални звук
Звук је аналогни сигнал који носи веома детаљне информације. Да би се овај сигнал претворио у дигитални, звук мора бити узоркован хиљадама пута у секунди.
🎓 Узорковање је процес претварања звучног сигнала у дигиталну вредност која представља сигнал у том тренутку.
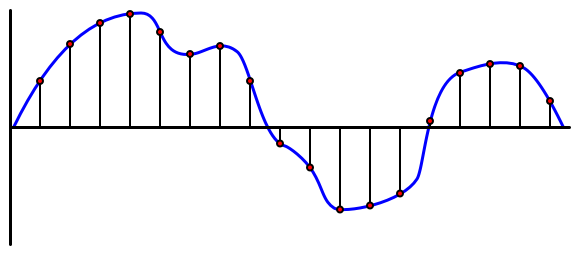
Дигитални звук се узоркује коришћењем модулације импулсног кода (PCM). PCM укључује читање напона сигнала и одабир најближе дискретне вредности том напону користећи дефинисану величину.
💁 PCM можете замислити као сензорску верзију модулације ширине импулса (PWM). (PWM је обрађен у лекцији 3 пројекта за почетнике). PCM претвара аналогни сигнал у дигитални, док PWM претвара дигитални сигнал у аналогни.
На пример, већина музичких стриминг сервиса нуди звук од 16-битног или 24-битног квалитета. То значи да претварају напон у вредност која се уклапа у 16-битни или 24-битни цео број. 16-битни звук уклапа вредност у опсег од -32,768 до 32,767, док је 24-битни у опсегу −8,388,608 до 8,388,607. Што је више битова, узорак је ближи ономе што наше уши заправо чују.
💁 Можда сте чули за 8-битни звук, често називан LoFi. Ово је звук узоркован коришћењем само 8 битова, у опсегу -128 до 127. Први рачунарски звук био је ограничен на 8 битова због хардверских ограничења, па се често виђа у ретро играма.
Ови узорци се узимају хиљадама пута у секунди, користећи добро дефинисане стопе узорковања мерене у KHz (хиљадама очитавања у секунди). Стриминг музички сервиси користе 48KHz за већину звука, али неки 'lossless' звук користи до 96KHz или чак 192KHz. Што је већа стопа узорковања, звук је ближи оригиналу, до одређене тачке. Постоји дебата да ли људи могу приметити разлику изнад 48KHz.
✅ Урадите истраживање: Ако користите музички стриминг сервис, коју стопу узорковања и величину користи? Ако користите CD-ове, која је стопа узорковања и величина CD звука?
Постоји велики број различитих формата за аудио податке. Вероватно сте чули за mp3 датотеке - аудио податке који су компримовани како би били мањи без губитка квалитета. Некомпримовани звук се често чува као WAV датотека - ово је датотека са 44 бајта заглавља, након чега следе сирови аудио подаци. Заглавље садржи информације као што су стопа узорковања (на пример 16000 за 16KHz) и величина узорка (16 за 16-битни), као и број канала. Након заглавља, WAV датотека садржи сирове аудио податке.
🎓 Канали се односе на то колико различитих аудио токова чини звук. На пример, за стерео звук са левим и десним каналом, постоје 2 канала. За 7.1 сурраунд звук за кућни биоскоп, то би било 8 канала.
Величина аудио података
Аудио подаци су релативно велики. На пример, снимање некомпримованог 16-битног звука на 16KHz (довољно добра стопа за модел претварања говора у текст), захтева 32KB података за сваку секунду звука:
- 16-битни значи 2 бајта по узорку (1 бајт је 8 битова).
- 16KHz је 16,000 узорака у секунди.
- 16,000 x 2 бајта = 32,000 бајтова у секунди.
Ово можда звучи као мала количина података, али ако користите микроконтролер са ограниченом меморијом, ово може бити много. На пример, Wio Terminal има 192KB меморије, која мора да складишти програмски код и променљиве. Чак и ако је ваш програмски код мали, не бисте могли снимити више од 5 секунди звука.
Микроконтролери могу приступити додатном складишту, као што су SD картице или флеш меморија. Када градите IoT уређај који снима звук, мораћете да осигурате не само да имате додатно складиште, већ и да ваш код пише снимљени звук директно на то складиште. Када га шаљете у облак, потребно је да стримујете са складишта у веб захтев. На тај начин можете избећи недостатак меморије покушавајући да држите цео блок аудио података у меморији одједном.
Снимање звука са вашег IoT уређаја
Ваш IoT уређај може бити повезан са микрофоном за снимање звука, спремног за претварање у текст. Такође може бити повезан са звучницима за репродукцију звука. У каснијим лекцијама ово ће се користити за давање аудио повратних информација, али је корисно подесити звучнике сада како бисте тестирали микрофон.
Задатак - конфигуришите микрофон и звучнике
Прођите кроз одговарајући водич за конфигурацију микрофона и звучника за ваш IoT уређај:
- Arduino - Wio Terminal
- Рачунар на једној плочи - Raspberry Pi
- Рачунар на једној плочи - Виртуелни уређај
Задатак - снимање звука
Прођите кроз одговарајући водич за снимање звука на вашем IoT уређају:
- Arduino - Wio Terminal
- Рачунар на једној плочи - Raspberry Pi
- Рачунар на једној плочи - Виртуелни уређај
Говор у текст
Говор у текст, или препознавање говора, укључује коришћење вештачке интелигенције за претварање речи из аудио сигнала у текст.
Модели за препознавање говора
Да би се говор претворио у текст, узорци из аудио сигнала се групишу и уносе у модел машинског учења заснован на рекурентној неуронској мрежи (RNN). Ово је тип модела машинског учења који може користити претходне податке за доношење одлука о долазним подацима. На пример, RNN може препознати један блок аудио узорака као звук 'Hel', а када добије други блок који препозна као звук 'lo', може комбиновати ово са претходним звуком, пронаћи да је 'Hello' важећа реч и изабрати је као резултат.
Модели машинског учења увек прихватају податке исте величине сваки пут. Класификатор слика који сте направили у претходној лекцији мења величину слика на фиксну величину и обрађује их. Исто важи и за моделе говора, они морају обрађивати аудио блокове фиксне величине. Модели говора морају бити у стању да комбинују излазе више предвиђања како би добили одговор, што им омогућава да разликују између 'Hi' и 'Highway', или 'flock' и 'floccinaucinihilipilification'.
Модели говора су такође довољно напредни да разумеју контекст и могу исправити речи које препознају како се обрађује више звукова. На пример, ако кажете "Ишао сам у продавницу да купим две банане и јабуку такође", користили бисте три речи које звуче исто, али се различито пишу - to, two и too. Модели говора могу разумети контекст и користити одговарајући правопис речи. 💁 Неки говорни сервиси омогућавају прилагођавање како би боље функционисали у бучним окружењима, као што су фабрике, или са речима специфичним за одређене индустрије, као што су хемијски називи. Ова прилагођавања се обучавају пружањем узорног аудио снимка и транскрипта, и функционишу користећи трансфер учење, исто као што сте раније обучавали класификатор слика користећи само неколико слика у претходној лекцији.
Приватност
Када користите препознавање говора на потрошачком IoT уређају, приватност је изузетно важна. Ови уређаји континуирано слушају звук, тако да као корисник не желите да све што кажете буде послато у облак и претворено у текст. Ово не само да троши пуно интернет пропусног опсега, већ има и огромне импликације на приватност, посебно када неки произвођачи паметних уређаја насумично бирају аудио снимке за људску валидацију у односу на генерисани текст како би побољшали свој модел.
Желите да ваш паметни уређај шаље звук у облак за обраду само када га користите, а не када чује звук у вашем дому, звук који може укључивати приватне састанке или интимне интеракције. Начин на који већина паметних уређаја функционише је помоћу активирајуће речи, кључне фразе као што су "Алекса", "Хеј Сири" или "ОК Гугл", која узрокује да се уређај "пробуди" и слуша оно што говорите све док не детектује паузу у вашем говору, што указује да сте завршили са обраћањем уређају.
🎓 Детекција активирајуће речи се такође назива препознавање кључне речи или откривање кључне речи.
Ове активирајуће речи се детектују на самом уређају, а не у облаку. Ови паметни уређаји имају мале AI моделе који раде на самом уређају и слушају активирајућу реч, а када је детектују, почињу да стримују звук у облак ради препознавања. Ови модели су веома специјализовани и слушају само активирајућу реч.
💁 Неке технолошке компаније додају више приватности својим уређајима и обављају део конверзије говора у текст на самом уређају. Apple је најавио да ће као део својих ажурирања за iOS и macOS у 2021. години подржати конверзију говора у текст на уређају и бити у могућности да обрађује многе захтеве без потребе за коришћењем облака. Ово је могуће захваљујући снажним процесорима у њиховим уређајима који могу покретати ML моделе.
✅ Шта мислите, које су импликације на приватност и етику када се аудио снимци шаљу у облак? Да ли би ови снимци требало да се чувају, и ако да, како? Да ли мислите да је коришћење снимака за спровођење закона добра замена за губитак приватности?
Детекција активирајуће речи обично користи технику познату као TinyML, која подразумева конвертовање ML модела тако да могу радити на микроконтролерима. Ови модели су мале величине и троше веома мало енергије за рад.
Да бисте избегли сложеност тренирања и коришћења модела за активирајућу реч, паметни тајмер који правите у овој лекцији ће користити дугме за укључивање препознавања говора.
💁 Ако желите да покушате да направите модел за детекцију активирајуће речи који ради на Wio Terminal-у или Raspberry Pi-ју, погледајте овај Edge Impulse водич за одговор на ваш глас. Ако желите да користите свој рачунар за ово, можете испробати брзи почетак са прилагођеним кључним речима на Microsoft документацији.
Претварање говора у текст
![]()
Као и код класификације слика у ранијем пројекту, постоје унапред изграђене AI услуге које могу узети говор као аудио датотеку и претворити га у текст. Једна од таквих услуга је Услуга за говор, део Cognitive Services, унапред изграђених AI услуга које можете користити у својим апликацијама.
Задатак - конфигуришите AI ресурс за говор
-
Направите Resource Group за овај пројекат под називом
smart-timer. -
Користите следећу команду да направите бесплатан ресурс за говор:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>Замените
<location>локацијом коју сте користили приликом креирања Resource Group-а. -
Биће вам потребан API кључ за приступ ресурсу за говор из вашег кода. Покрените следећу команду да добијете кључ:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableСачувајте један од кључева.
Задатак - претворите говор у текст
Пратите одговарајући водич за претварање говора у текст на вашем IoT уређају:
- Arduino - Wio Terminal
- Рачунар са једном плочом - Raspberry Pi
- Рачунар са једном плочом - Виртуелни уређај
🚀 Изазов
Препознавање говора постоји већ дуго и стално се унапређује. Истражите тренутне могућности и упоредите како су се оне развијале током времена, укључујући колико су тачне машинске транскрипције у поређењу са људским.
Шта мислите, шта будућност доноси за препознавање говора?
Квиз након предавања
Преглед и самостално учење
- Прочитајте о различитим типовима микрофона и како функционишу у чланку која је разлика између динамичких и кондензаторских микрофона на Musician's HQ.
- Прочитајте више о услузи за говор у оквиру Cognitive Services на документацији о услузи за говор на Microsoft Docs.
- Прочитајте о препознавању кључних речи на документацији о препознавању кључних речи на Microsoft Docs.
Задатак
Одрицање од одговорности:
Овај документ је преведен коришћењем услуге за превођење помоћу вештачке интелигенције Co-op Translator. Иако се трудимо да обезбедимо тачност, молимо вас да имате у виду да аутоматски преводи могу садржати грешке или нетачности. Оригинални документ на његовом изворном језику треба сматрати ауторитативним извором. За критичне информације препоручује се професионални превод од стране људи. Не преузимамо одговорност за било каква погрешна тумачења или неспоразуме који могу настати услед коришћења овог превода.