|
|
2 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 2 years ago | |
| README.id.md | 2 years ago | |
| README.it.md | 2 years ago | |
| README.ja.md | 2 years ago | |
| README.ko.md | 2 years ago | |
| README.pt-br.md | 2 years ago | |
| README.pt.md | 2 years ago | |
| README.tr.md | 2 years ago | |
| README.zh-cn.md | 2 years ago | |
| README.zh-tw.md | 2 years ago | |
| assignment.es.md | 3 years ago | |
| assignment.it.md | 3 years ago | |
| assignment.ja.md | 3 years ago | |
| assignment.ko.md | 3 years ago | |
| assignment.pt-br.md | 3 years ago | |
| assignment.pt.md | 3 years ago | |
| assignment.tr.md | 3 years ago | |
| assignment.zh-cn.md | 3 years ago | |
| assignment.zh-tw.md | 2 years ago | |
README.zh-tw.md
開始使用 Python 和 Scikit 學習回歸模型
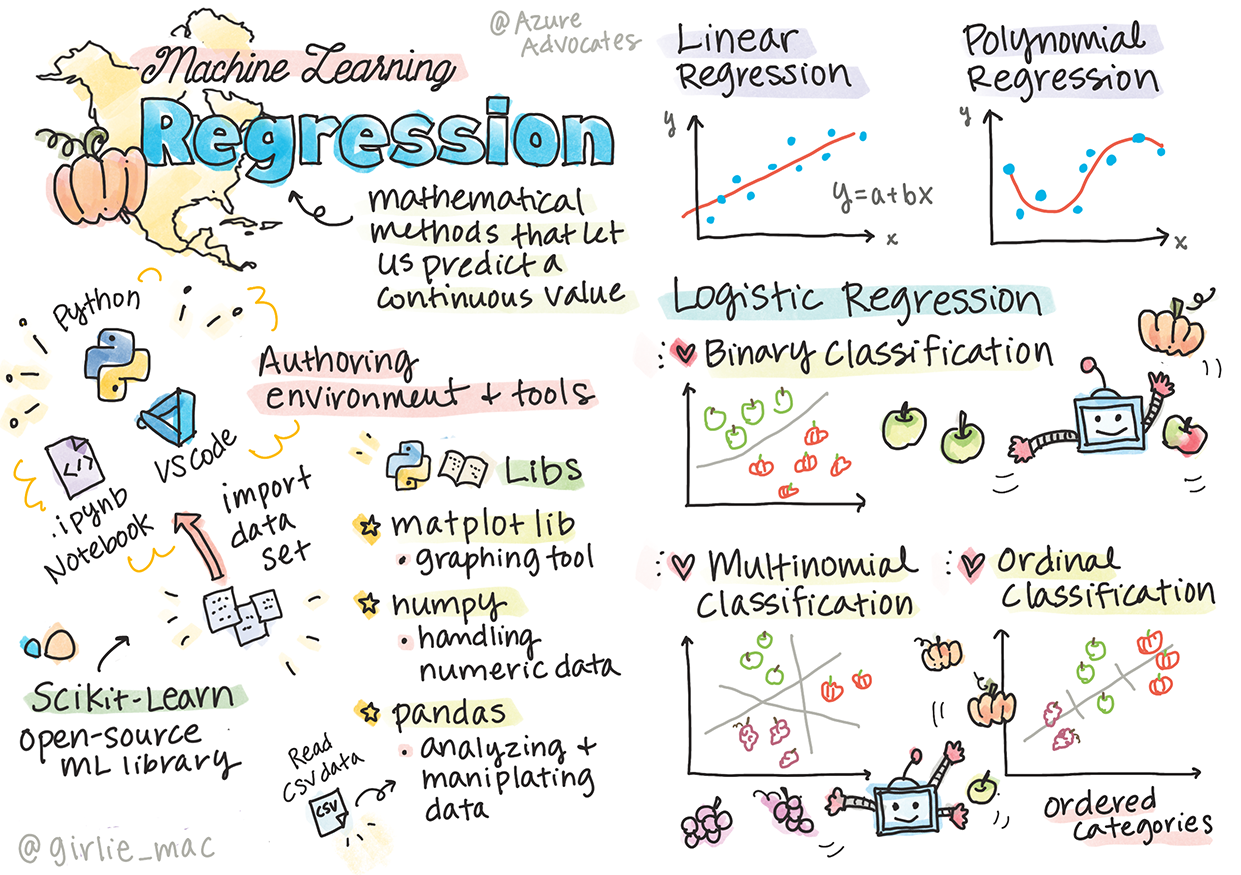
作者 Tomomi Imura
課前測
介紹
在這四節課中,你將了解如何構建回歸模型。我們將很快討論這些是什麽。但在你做任何事情之前,請確保你有合適的工具來開始這個過程!
在本課中,你將學習如何:
- 為本地機器學習任務配置你的計算機。
- 使用 Jupyter notebooks。
- 使用 Scikit-learn,包括安裝。
- 通過動手練習探索線性回歸。
安裝和配置

🎥 單擊上圖觀看視頻:在 VS Code 中使用 Python。
-
安裝 Python。確保你的計算機上安裝了 Python。你將在許多數據科學和機器學習任務中使用 Python。大多數計算機系統已經安裝了 Python。也有一些有用的 Python 編碼包 可用於簡化某些用戶的設置。
然而,Python 的某些用法需要一個版本的軟件,而其他用法則需要另一個不同的版本。 因此,在 虛擬環境 中工作很有用。
-
安裝 Visual Studio Code。確保你的計算機上安裝了 Visual Studio Code。按照這些說明 安裝 Visual Studio Code 進行基本安裝。在本課程中,你將在 Visual Studio Code 中使用 Python,因此你可能想復習如何 配置 Visual Studio Code 用於 Python 開發。
通過學習這一系列的 學習模塊 熟悉 Python
-
按照 這些說明 安裝 Scikit learn。由於你需要確保使用 Python3,因此建議你使用虛擬環境。註意,如果你是在 M1 Mac 上安裝這個庫,在上面鏈接的頁面上有特別的說明。
-
安裝 Jupyter Notebook。你需要 安裝 Jupyter 包。
你的 ML 工作環境
你將使用 notebooks 開發 Python 代碼並創建機器學習模型。這種類型的文件是數據科學家的常用工具,可以通過後綴或擴展名 .ipynb 來識別它們。
Notebooks 是一個交互式環境,允許開發人員編寫代碼並添加註釋並圍繞代碼編寫文檔,這對於實驗或面向研究的項目非常有幫助。
練習 - 使用 notebook
-
在 Visual Studio Code 中打開 notebook.ipynb。
Jupyter 服務器將以 python3+啟動。你會發現 notebook 可以「運行」的區域、代碼塊。你可以通過選擇看起來像播放按鈕的圖標來運行代碼塊。
-
選擇
md圖標並添加一點 markdown,輸入文字 # Welcome to your notebook。接下來,添加一些 Python 代碼。
-
在代碼塊中輸入 print("hello notebook")。
-
選擇箭頭運行代碼。
你應該看到打印的語句:
hello notebook
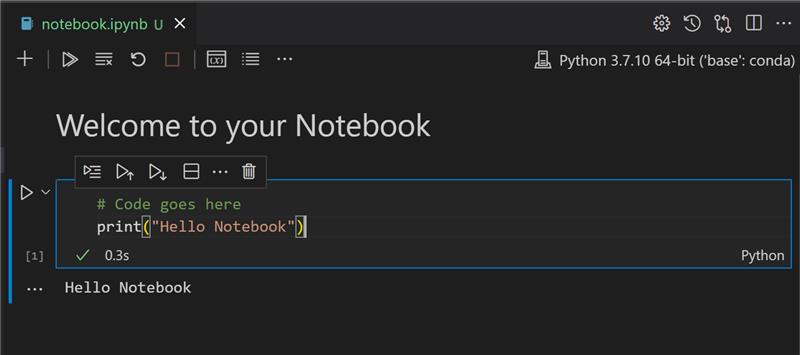
你可以為你的代碼添加註釋,以便 notebook 可以自描述。
✅ 想一想 web 開發人員的工作環境與數據科學家的工作環境有多大的不同。
啟動並運行 Scikit-learn
現在 Python 已在你的本地環境中設置好,並且你對 Jupyter notebook 感到滿意,讓我們同樣熟悉 Scikit-learn(在「science」中發音為「sci」)。 Scikit-learn 提供了 大量的 API 來幫助你執行 ML 任務。
根據他們的 網站,「Scikit-learn 是一個開源機器學習庫,支持有監督和無監督學習。它還提供了各種模型擬合工具、數據預處理、模型選擇和評估以及許多其他實用程序。」
在本課程中,你將使用 Scikit-learn 和其他工具來構建機器學習模型,以執行我們所謂的「傳統機器學習」任務。我們特意避免了神經網絡和深度學習,因為它們在我們即將推出的「面向初學者的人工智能」課程中得到了更好的介紹。
Scikit-learn 使構建模型和評估它們的使用變得簡單。它主要側重於使用數字數據,並包含幾個現成的數據集用作學習工具。它還包括供學生嘗試的預建模型。讓我們探索加載預先打包的數據和使用內置的 estimator first ML 模型和 Scikit-learn 以及一些基本數據的過程。
練習 - 你的第一個 Scikit-learn notebook
本教程的靈感來自 Scikit-learn 網站上的 線性回歸示例。
在與本課程相關的 notebook.ipynb 文件中,通過點擊「垃圾桶」圖標清除所有單元格。
在本節中,你將使用一個關於糖尿病的小數據集,該數據集內置於 Scikit-learn 中以用於學習目的。想象一下,你想為糖尿病患者測試一種治療方法。機器學習模型可能會幫助你根據變量組合確定哪些患者對治療反應更好。即使是非常基本的回歸模型,在可視化時,也可能會顯示有助於組織理論臨床試驗的變量信息。
✅ 回歸方法有很多種,你選擇哪一種取決於你正在尋找的答案。如果你想預測給定年齡的人的可能身高,你可以使用線性回歸,因為你正在尋找數值。如果你有興趣了解某種菜肴是否應被視為素食主義者,那麽你正在尋找類別分配,以便使用邏輯回歸。稍後你將了解有關邏輯回歸的更多信息。想一想你可以對數據提出的一些問題,以及這些方法中的哪一個更合適。
讓我們開始這項任務。
導入庫
對於此任務,我們將導入一些庫:
- matplotlib。這是一個有用的 繪圖工具,我們將使用它來創建線圖。
- numpy。 numpy 是一個有用的庫,用於在 Python 中處理數字數據。
- sklearn。這是 Scikit-learn 庫。
導入一些庫來幫助你完成任務。
-
通過輸入以下代碼添加導入:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selection在上面的代碼中,你正在導入
matplottlib、numpy,你正在從sklearn導入datasets、linear_model和model_selection。model_selection用於將數據拆分為訓練集和測試集。
糖尿病數據集
內置的 糖尿病數據集 包含 442 個圍繞糖尿病的數據樣本,具有 10 個特征變量,其中包括:
- age:歲數
- bmi:體重指數
- bp:平均血壓
- s1 tc:T 細胞(一種白細胞)
✅ 該數據集包括「性別」的概念,作為對糖尿病研究很重要的特征變量。許多醫學數據集包括這種類型的二元分類。想一想諸如此類的分類如何將人群的某些部分排除在治療之外。
現在,加載 X 和 y 數據。
🎓 請記住,這是監督學習,我們需要一個命名為「y」的目標。
在新的代碼單元中,通過調用 load_diabetes() 加載糖尿病數據集。輸入 return_X_y=True 表示 X 將是一個數據矩陣,而y將是回歸目標。
-
添加一些打印命令來顯示數據矩陣的形狀及其第一個元素:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])作為響應返回的是一個元組。你正在做的是將元組的前兩個值分別分配給
X和y。了解更多 關於元組。你可以看到這個數據有 442 個項目,組成了 10 個元素的數組:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ 稍微思考一下數據和回歸目標之間的關系。線性回歸預測特征 X 和目標變量 y 之間的關系。你能在文檔中找到糖尿病數據集的 目標 嗎?鑒於該目標,該數據集展示了什麽?
-
接下來,通過使用 numpy 的
newaxis函數將數據集的一部分排列到一個新數組中。我們將使用線性回歸根據它確定的模式在此數據中的值之間生成一條線。X = X[:, np.newaxis, 2]✅ 隨時打印數據以檢查其形狀。
-
現在你已準備好繪製數據,你可以看到計算機是否可以幫助確定此數據集中數字之間的邏輯分割。為此你需要將數據 (X) 和目標 (y) 拆分為測試集和訓練集。Scikit-learn 有一個簡單的方法來做到這一點;你可以在給定點拆分測試數據。
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
現在你已準備好訓練你的模型!加載線性回歸模型並使用
model.fit()使用 X 和 y 訓練集對其進行訓練:model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()是一個你會在許多機器學習庫(例如 TensorFlow)中看到的函數 -
然後,使用函數
predict(),使用測試數據創建預測。這將用於繪製數據組之間的線y_pred = model.predict(X_test) -
現在是時候在圖中顯示數據了。Matplotlib 是完成此任務的非常有用的工具。創建所有 X 和 y 測試數據的散點圖,並使用預測在模型的數據分組之間最合適的位置畫一條線。
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.show()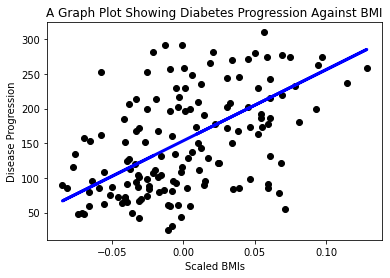
✅ 想一想這裏發生了什麽。一條直線穿過許多小數據點,但它到底在做什麽?你能看到你應該如何使用這條線來預測一個新的、未見過的數據點對應的 y 軸值嗎?嘗試用語言描述該模型的實際用途。
恭喜,你構建了第一個線性回歸模型,使用它創建了預測,並將其顯示在繪圖中!
🚀挑戰
從這個數據集中繪製一個不同的變量。提示:編輯這一行:X = X[:, np.newaxis, 2]。鑒於此數據集的目標,你能夠發現糖尿病作為一種疾病的進展情況嗎?
課後測
復習與自學
在本教程中,你使用了簡單線性回歸,而不是單變量或多元線性回歸。閱讀一些關於這些方法之間差異的信息,或查看 此視頻
閱讀有關回歸概念的更多信息,並思考這種技術可以回答哪些類型的問題。用這個 教程 加深你的理解。