|
|
2 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 2 years ago | |
| README.fr.md | 2 years ago | |
| README.id.md | 2 years ago | |
| README.it.md | 2 years ago | |
| README.ja.md | 2 years ago | |
| README.ko.md | 2 years ago | |
| README.pt-br.md | 2 years ago | |
| README.zh-cn.md | 2 years ago | |
| README.zh-tw.md | 2 years ago | |
| assignment.es.md | 3 years ago | |
| assignment.fr.md | 3 years ago | |
| assignment.id.md | 3 years ago | |
| assignment.it.md | 3 years ago | |
| assignment.ja.md | 3 years ago | |
| assignment.ko.md | 3 years ago | |
| assignment.pt-br.md | 3 years ago | |
| assignment.zh-cn.md | 3 years ago | |
| assignment.zh-tw.md | 2 years ago | |
README.zh-tw.md
機器學習中的公平性

作者 Tomomi Imura
課前測驗
介紹
在本課程中,你將開始了解機器學習如何影響我們的日常生活。截至目前,系統和模型已經參與到日常決策任務中,例如醫療診斷或發現欺詐。因此,這些模型運行良好,並為每個人提供公平的結果非常重要。
想象一下,當你用於構建這些模型的數據缺少某些人口統計信息時會發生什麽情況,例如種族、性別、政治觀點、宗教,或者不成比例地代表了這些人口統計信息。當模型的輸出被解釋為有利於某些人口統計學的時候呢?申請結果如何?
在本課中,你將:
- 提高你對機器學習中公平的重要性的認識。
- 了解公平相關的危害。
- 了解不公平評估和緩解措施。
先決條件
作為先決條件,請選擇「負責任的人工智能原則」學習路徑並觀看以下主題視頻:
按照此學習路徑了解有關負責任 AI 的更多信息

🎥 點擊上圖觀看視頻:微軟對負責任人工智能的做法
數據和算法的不公平性
「如果你折磨數據足夠長的時間,它會坦白一切」 - Ronald Coase 這種說法聽起來很極端,但數據確實可以被操縱以支持任何結論。這種操縱有時可能是無意中發生的。作為人類,我們都有偏見,當你在數據中引入偏見時,往往很難有意識地知道。
保證人工智能和機器學習的公平性仍然是一項復雜的社會技術挑戰。這意味著它不能從純粹的社會或技術角度來解決。
與公平相關的危害
你說的不公平是什麽意思?「不公平」包括對一群人的負面影響或「傷害」,例如根據種族、性別、年齡或殘疾狀況定義的那些人。
與公平相關的主要危害可分為:
- 分配,如果一個性別或種族比另一個更受青睞。
- 服務質量。 如果你針對一種特定場景訓練數據,但實際情況要復雜得多,則會導致服務性能不佳。
- 刻板印象。 將給定的組與預先分配的屬性相關聯。
- 詆毀。 不公平地批評和標記某事或某人。
- 代表性過高或過低。這種想法是,某個群體在某個行業中不被看到,而這個行業一直在提升,這是造成傷害的原因。
讓我們來看看這些例子。
分配
考慮一個用於篩選貸款申請的假設系統。該系統傾向於選擇白人男性作為比其他群體更好的候選人。因此,某些申請人的貸款被拒。
另一個例子是一家大型公司開發的一種實驗性招聘工具,用於篩選應聘者。通過使用這些模型,該工具系統地歧視了一種性別,並被訓練為更喜歡與另一種性別相關的詞。這導致了對簡歷中含有「女子橄欖球隊」等字樣的候選人的不公正地對待。
✅ 做一點研究,找出一個真實的例子
服務質量
研究人員發現,與膚色較淺的男性相比,一些商業性的性別分類工具在膚色較深的女性圖像上的錯誤率更高。參考
另一個臭名昭著的例子是洗手液分配器,它似乎無法感知皮膚黝黑的人。參考
刻板印象
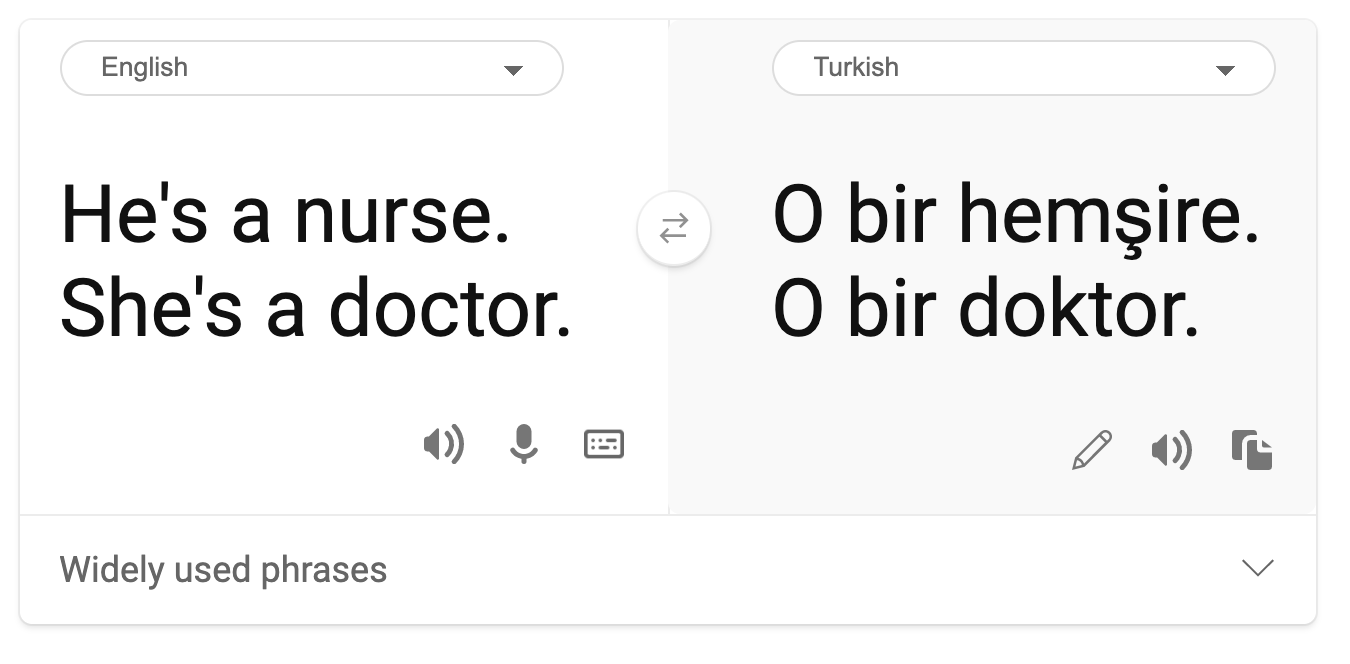
機器翻譯中存在著刻板的性別觀。在將「他是護士,她是醫生」翻譯成土耳其語時,遇到了一些問題。土耳其語是一種無性別的語言,它有一個代詞「o」來表示單數第三人稱,但把這個句子從土耳其語翻譯成英語,會產生「她是護士,他是醫生」這樣的刻板印象和錯誤。

詆毀
一種圖像標記技術,臭名昭著地將深色皮膚的人的圖像錯誤地標記為大猩猩。錯誤的標簽是有害的,不僅僅是因為這個系統犯了一個錯誤,而且它還特別使用了一個長期以來被故意用來詆毀黑人的標簽。

🎥 點擊上圖觀看視頻:AI,我不是女人嗎 - 一場展示 AI 種族主義詆毀造成的傷害的表演
代表性過高或過低
有傾向性的圖像搜索結果就是一個很好的例子。在搜索男性比例等於或高於女性的職業的圖片時,比如工程或首席執行官,要註意那些更傾向於特定性別的結果。

在 Bing 上搜索「CEO」會得到非常全面的結果 這五種主要類型的危害不是相互排斥的,一個單一的系統可以表現出一種以上的危害。此外,每個案例的嚴重程度各不相同。例如,不公平地給某人貼上罪犯的標簽比給形象貼上錯誤的標簽要嚴重得多。然而,重要的是要記住,即使是相對不嚴重的傷害也會讓人感到疏遠或被孤立,累積的影響可能會非常壓抑。
✅ 討論:重溫一些例子,看看它們是否顯示出不同的危害。
| 分配 | 服務質量 | 刻板印象 | 詆毀 | 代表性過高或過低 | |
|---|---|---|---|---|---|
| 自動招聘系統 | x | x | x | x | |
| 機器翻譯 | |||||
| 照片加標簽 |
檢測不公平
給定系統行為不公平的原因有很多。例如,社會偏見可能會反映在用於訓練它們的數據集中。例如,過度依賴歷史數據可能會加劇招聘不公平。通過使用過去 10 年提交給公司的簡歷中的模式,該模型確定男性更合格,因為大多數簡歷來自男性,這反映了過去男性在整個科技行業的主導地位。
關於特定人群的數據不足可能是不公平的原因。例如,圖像分類器對於深膚色人的圖像具有較高的錯誤率,因為數據中沒有充分代表較深的膚色。
開發過程中做出的錯誤假設也會導致不公平。例如,旨在根據人臉圖像預測誰將犯罪的面部分析系統可能會導致破壞性假設。這可能會對錯誤分類的人造成重大傷害。
了解你的模型並建立公平性
盡管公平性的許多方面都沒有包含在量化公平性指標中,並且不可能從系統中完全消除偏見以保證公平性,但你仍然有責任盡可能多地檢測和緩解公平性問題。
當你使用機器學習模型時,通過確保模型的可解釋性以及評估和減輕不公平性來理解模型非常重要。
讓我們使用貸款選擇示例來作為分析案例,以確定每個因素對預測的影響程度。
評價方法
-
識別危害(和好處)。第一步是找出危害和好處。思考行動和決策如何影響潛在客戶和企業本身。
-
確定受影響的群體。一旦你了解了什麽樣的傷害或好處可能會發生,找出可能受到影響的群體。這些群體是按性別、種族或社會群體界定的嗎?
-
定義公平性度量。最後,定義一個度量標準,這樣你就可以在工作中衡量一些東西來改善這種情況。
識別危害(和好處)
與貸款相關的危害和好處是什麽?想想假陰性和假陽性的情況:
假陰性(拒絕,但 Y=1)-在這種情況下,將拒絕有能力償還貸款的申請人。這是一個不利的事件,因為貸款的資源是從合格的申請人扣留。
假陽性(接受,但 Y=0)-在這種情況下,申請人確實獲得了貸款,但最終違約。因此,申請人的案件將被送往一個債務催收機構,這可能會影響他們未來的貸款申請。
確定受影響的群體
下一步是確定哪些群體可能受到影響。例如,在信用卡申請的情況下,模型可能會確定女性應獲得比共享家庭資產的配偶低得多的信用額度。因此,由性別定義的整個人口統計數據都會受到影響。
定義公平性度量
你已經確定了傷害和受影響的群體,在本例中,是按性別劃分的。現在,使用量化因子來分解它們的度量。例如,使用下面的數據,你可以看到女性的假陽性率最大,男性的假陽性率最小,而對於假陰性則相反。
✅ 在以後關於聚類的課程中,你將看到如何在代碼中構建這個「混淆矩陣」
| 假陽性率 | 假陰性率 | 數量 | |
|---|---|---|---|
| 女性 | 0.37 | 0.27 | 54032 |
| 男性 | 0.31 | 0.35 | 28620 |
| 未列出性別 | 0.33 | 0.31 | 1266 |
這個表格告訴我們幾件事。首先,我們註意到數據中的未列出性別的人相對較少。數據是有偏差的,所以你需要小心解釋這些數字。
在本例中,我們有 3 個組和 2 個度量。當我們考慮我們的系統如何影響貸款申請人的客戶群時,這可能就足夠了,但是當你想要定義更多的組時,你可能需要將其提取到更小的摘要集。為此,你可以添加更多的度量,例如每個假陰性和假陽性的最大差異或最小比率。
✅ 停下來想一想:還有哪些群體可能會受到貸款申請的影響?
減輕不公平
為了緩解不公平,探索模型生成各種緩解模型,並比較其在準確性和公平性之間的權衡,以選擇最公平的模型。
這個介紹性的課程並沒有深入探討算法不公平緩解的細節,比如後處理和減少方法,但是這裏有一個你可能想嘗試的工具。
Fairlearn
Fairlearn 是一個開源 Python 包,可讓你評估系統的公平性並減輕不公平性。
該工具可幫助你評估模型的預測如何影響不同的組,使你能夠通過使用公平性和性能指標來比較多個模型,並提供一組算法來減輕二元分類和回歸中的不公平性。
-
通過查看 Fairlearn 的 GitHub 了解如何使用不同的組件
-
嘗試一些 示例 Notebook.
-
了解Azure機器學習中機器學習模型如何啟用公平性評估。
-
看看這些示例 Notebook了解 Azure 機器學習中的更多公平性評估場景。
🚀 挑戰
為了防止首先引入偏見,我們應該:
-
在系統工作人員中有不同的背景和觀點
-
獲取反映我們社會多樣性的數據集
-
開發更好的方法來檢測和糾正偏差
想想現實生活中的場景,在模型構建和使用中明顯存在不公平。我們還應該考慮什麽?
課後測驗
復習與自學
在本課中,你學習了機器學習中公平和不公平概念的一些基礎知識。
觀看本次研討會,深入探討以下主題:
- YouTube:人工智能系統中與公平相關的危害:示例、評估和緩解 Hanna Wallach 和 Miro Dudik人工智能系統中與公平相關的危害:示例、評估和緩解-YouTube
另外,請閱讀:
-
微軟RAI資源中心:負責人工智能資源-微軟人工智能
-
微軟 FATE 研究小組:FATE:AI 中的公平、問責、透明和道德-微軟研究院
探索 Fairlearn 工具箱
了解 Azure 機器學習的工具以確保公平性