16 KiB
머신러닝의 공정성

Sketchnote by Tomomi Imura
강의 전 퀴즈
소개
이 커리큘럼에서, 머신러닝이 우리의 생활에 어떻게 영향을 미칠 수 있는 지 알아보겠습니다. 지금도, 시스템과 모델은 건강 관리 진단 또는 사기 탐지와 같이 일상의 의사-결정 작업에 관여하고 있습니다. 따라서 모두에게 공정한 결과를 주기 위해서는 모델이 잘 작동하는게 중요합니다.
모델을 구축할 때 사용하는 데이터에 인종, 성별, 정치적 관점, 종교와 같이 특정 인구 통계가 부족하거나 불균형하게 나타내는 경우, 어떤 일이 발생할 지 상상해봅시다. 모델의 결과가 일부 인구 통계에 유리하도록 해석하는 경우는 어떨까요? 애플리케이션의 결과는 어떨까요?
이 강의에서, 아래 내용을 합니다:
- 머신러닝에서 공정성의 중요도에 대한 인식을 높입니다.
- 공정성-관련 피해에 대하여 알아봅니다.
- 불공정성 평가와 완화에 대하여 알아봅니다.
전제 조건
전제 조건으로, "Responsible AI Principles" 학습 과정을 수강하고 주제에 대한 영상을 시청합니다:
Learning Path를 따라서 Responsible AI에 대하여 더 자세히 알아보세요

🎥 영상을 보려면 이미지 클릭: Microsoft's Approach to Responsible AI
데이터와 알고리즘의 불공정성
"If you torture the data long enough, it will confess to anything" - Ronald Coase
이 소리는 극단적이지만, 결론을 돕기 위하여 데이터를 조작할 수 있다는 건 사실입니다. 의도치않게 발생할 수 있습니다. 사람으로서, 모두 편견을 가지고 있고, 데이터에 편향적일 때 의식하는 것은 어렵습니다.
AI와 머신러닝의 공정성을 보장하는 건 계속 복잡한 사회기술적 도전 과제로 남고 있습니다. 순수하게 사화나 기술 관점에서 다룰 수 없다고 의미합니다.
공정성-관련 피해
불공정이란 무엇일까요? "Unfairness"은 인종, 성별, 나이, 또는 장애 등급으로 정의된 인구 그룹에 대한 부정적인 영향 혹은 "harms"를 포함합니다.
공정성-관련된 주요 피해는 다음처럼 분류할 수 있습니다:
- 할당, 예를 들자면 성별이나 인종이 다른 사람들보다 선호되는 경우
- 서비스 품질. 복잡할 때 한 특정 시나리오에 맞춰 데이터를 훈련하면, 서비스 성능이 낮아집니다.
- 고정관념. 지정된 그룹을 사전에 할당한 속성에 넘깁니다.
- 명예훼손. 무언가 누군가 부당한 비판하고 라벨링합니다.
- 과도- 또는 과소- 평가. 아이디어는 특정 공언에서 그룹을 볼 수 없으며, 같이 피해를 입히는 서비스 혹은 기능을 꾸준히 홍보합니다.
이 예시를 보겠습니다.
할당
대출 심사하는 가상의 시스템을 생각해보세요. 이 시스템은 백인 남성을 다른 그룹보다 더 선택하는 경향이 있습니다. 결과적으로, 특정 지원자는 대출이 미뤄집니다.
또 다른 예시로는 후보를 뽑기 위해 대기업에서 개발한 실험적 채용 도구입니다. 모델을 사용하여 다른 단어를 선호하도록 훈련하며 하나의 성별을 특정할 수 있는 도구입니다. 이력서에 "women’s rugby team" 같은 단어가 포함되면 패널티가 주어졌습니다.
✅ 이런 실제 사례를 찾기 위하여 약간 조사해보세요
서비스 품질
연구원들은 여러가지 상용 성별 분류기에서 피부가 하얀 남성 이미지와 다르게 피부가 어두운 여성 이미지에서 오류 비율이 더 높다는 것을 발견했습니다. Reference
또 다른 이면에는 피부가 어두운 사람을 잘 인식하지 못하는 비누 디스펜서도 있습니다. Reference
고정관념
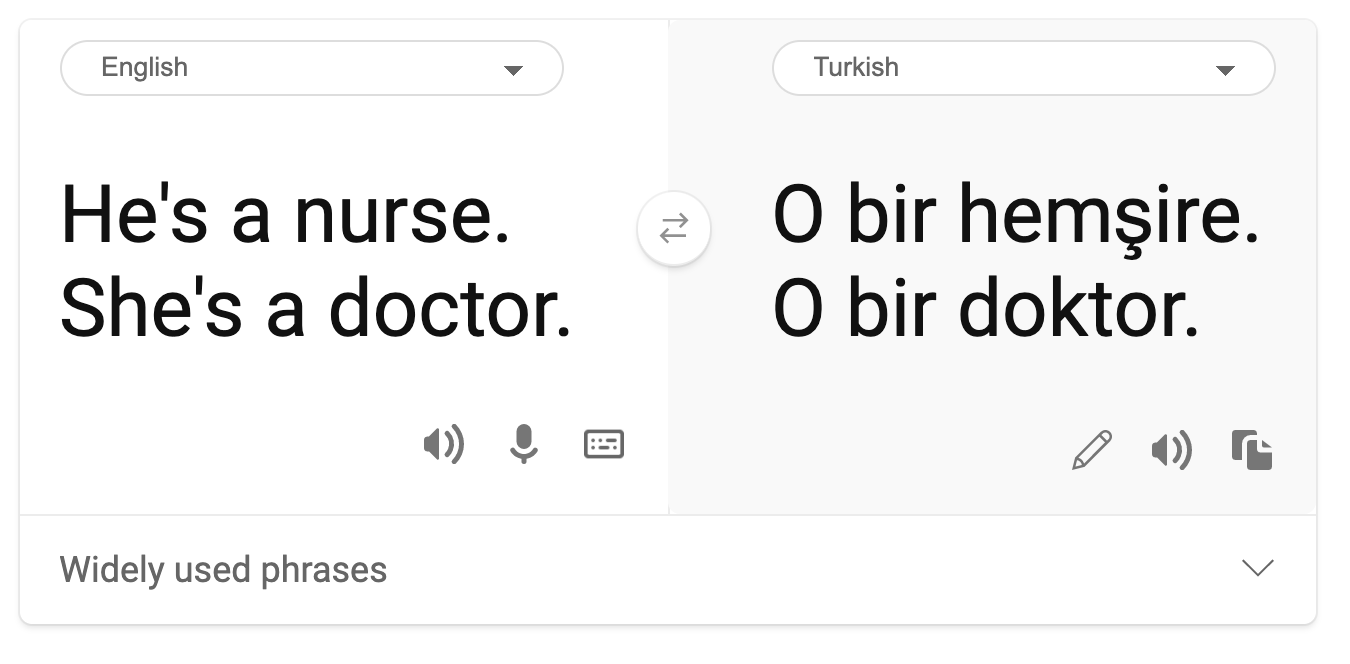
기계 번역에서 성별에 대한 고정관념이 발견되었습니다. “he is a nurse and she is a doctor”라고 터키어로 번역할 때, 문제가 발생했습니다. 터키어는 3인칭을 전달하면서 "o"가 하나인 성별을 가지리지 않지만, 터키어에서 영어로 다시 문장을 번역해보면 “she is a nurse and he is a doctor”라는 고정관념과 부정확하게 반환됩니다.

명예훼손
이미지 라벨링 기술은 어두운-피부 사람의 이미지를 고릴라로 잘 못 분류했습니다. 잘 못 라벨링된 현상은 denigrate Black people된 오랜 역사를 라벨링하며 적용했으며 시스템이 실수했을 때 해롭습니다.

🎥 영상을 보려면 이미지 클릭: AI, Ain't I a Woman - a performance showing the harm caused by racist denigration by AI
과도- 또는 과소- 평가
왜곡된 이미지 검색 결과가 이러한 피해의 올바른 예시가 됩니다. 공학, 또는 CEO와 같이, 여자보다 남자가 높거나 비슷한 비율의 직업 이미지를 검색할 때 특정 성별에 대하여 더 치우친 결과를 보여 줍니다.

This search on Bing for 'CEO' produces pretty inclusive results
5가지의 주요 피해 타입은 mutually exclusive적이지 않으며, 하나의 시스템이 여러 타입의 피해를 나타낼 수 있습니다. 또한, 각 사례들은 심각성이 다릅니다. 예를 들자면, 누군가 범죄자로 부적절하게 노출하는 것은 이미지를 잘못 보여주는 것보다 더 심한 피해입니다. 그러나, 중요한 점은, 상대적으로 심하지 않은 피해도 사람들이 소외감을 느끼거나 피하게 만들 수 있고 쌓인 영향은 꽤 부담이 될 수 있다는 점입니다.
✅ 토론: 몇 가지 예시를 다시 보고 다른 피해가 발생했는지 확인해봅시다.
| Allocation | Quality of service | Stereotyping | Denigration | Over- or under- representation | |
|---|---|---|---|---|---|
| Automated hiring system | x | x | x | x | |
| Machine translation | |||||
| Photo labeling |
불공정성 감지
주어진 시스템이 부당하게 동작하는 것은 여러 이유가 존재합니다. 사회 편견을, 예시로 들자면, 훈련에 사용한 데이터셋에 영향을 줄 수 있습니다. 예를 들자면, 채용 불공정성은 이전 데이터에 과하게 의존하여 더욱 악화되었을 가능성이 있습니다. 10년 넘게 회사에 제출된 이력서에서 패턴을 사용했으므로, 이 모델은 대부분의 이력서가 기술업의 과거 지배력을 반영했던 남자가 냈기 때문에 남자가 자격이 있다고 판단했습니다.
특정 그룹의 사람에 대한 적절하지 못한 데이터가 불공정의 이유가 될 수 있습니다. 예를 들자면, 이미지 분류기는 데이터에서 더 어두운 피부 톤를 underrepresented 했으므로 어두운-피부 사람 이미지에 대해 오류 비율이 더 높습니다.
개발하면서 잘 못된 가정을 하면 불공정성을 발생합니다. 예를 들자면, 사람들의 얼굴 이미지를 기반으로 범죄를 저지를 것 같은 사람을 예측하기 위한 얼굴 분석 시스템은 올바르지 못한 가정으로 이어질 수 있습니다. 이는 잘 못 분류된 사람들에게 큰 피해를 줄 수 있습니다.
모델 이해하고 공정성 구축하기
공정성의 많은 측면은 정량 공정성 지표에 보이지 않고, 공정성을 보장하기 위하여 시스템에서 편향성을 완전히 제거할 수 없지만, 여전히 공정성 문제를 최대한 파악하고 완화할 책임은 있습니다.
머신러닝 모델을 작업할 때, interpretability를 보장하고 불공정성을 평가하며 완화하여 모델을 이해하는 것이 중요합니다.
대출 선택 예시로 케이스를 분리하고 예측에 대한 각 영향 수준을 파악해보겠습니다.
평가 방식
-
피해 (와 이익) 식별하기. 첫 단계는 피해와 이익을 식별하는 것입니다. 행동과 결정이 잠재적 고객과 비지니스에 어떻게 영향을 미칠 지 생각해봅니다.
-
영향받는 그룹 식별하기. 어떤 종류의 피해나 이익을 발생할 수 있는지 파악했다면, 영향을 받을 수 있는 그룹을 식별합니다. 그룹은 성별, 인종, 또는 사회 집단으로 정의되나요?
-
공정성 지표 정의하기. 마지막으로, 지표를 정의하여 상황을 개선할 작업에서 특정할 무언가를 가집니다.
피해 (와 이익) 식별하기
대출과 관련한 피해와 이익은 어떤 것일까요? false negatives와 false positive 시나리오로 생각해보세요:
False negatives (거절, but Y=1) - 이 케이스와 같은 경우, 대출금을 상환할 수 있는 신청자가 거절됩니다. 자격있는 신청자에게 대출이 보류되기 때문에 불리한 이벤트입니다.
False positives (승인, but Y=0) - 이 케이스와 같은 경우, 신청자는 대출을 받지만 상환하지 못합니다. 결론적으로, 신청자의 케이스는 향후 대출에 영향을 미칠 수 있는 채권 추심으로 넘어갑니다.
영향 받는 그룹 식별
다음 단계는 영향을 받을 것 같은 그룹을 정의하는 것입니다. 예를 들자면, 신용카드를 신청하는 케이스인 경우, 모델은 여자가 가계 재산을 공유하는 배우자에 비해서 매우 낮은 신용도를 받아야 한다고 결정할 수 있습니다. 성별에 의해서, 정의된 전체 인구 통계가 영향 받습니다.
공정성 지표 정의
피해와 영향받는 그룹을 식별했습니다, 이 케이스와 같은 경우에는, 성별로 표기됩니다. 이제, 정량화된 원인으로 지표를 세분화합니다. 예시로, 아래 데이터를 사용하면, false positive 비율은 여자의 비율이 가장 크고 남자의 비율이 가장 낮으며, false negatives에서는 반대됩니다.
✅ Clustering에 대한 향후 강의에서는, 이 'confusion matrix'을 코드로 어떻게 작성하는 지 봅시다
| False positive rate | False negative rate | count | |
|---|---|---|---|
| Women | 0.37 | 0.27 | 54032 |
| Men | 0.31 | 0.35 | 28620 |
| Non-binary | 0.33 | 0.31 | 1266 |
이 테이블은 몇 가지를 알려줍니다. 먼저, 데이터에 non-binary people이 비교적 적다는 것을 알 수 있습니다. 이 데이터는 왜곡되었으므로, 이런 숫자를 해석하는 것은 조심해야 합니다.
이러한 케이스는, 3개의 그룹과 2개의 지표가 존재합니다. 시스템이 대출 신청자와 함께 소비자 그룹에 어떤 영향을 미치는지 알아볼 때는, 충분할 수 있지만, 더 많은 수의 그룹을 정의하려는 경우, 더 작은 요약 셋으로 추출할 수 있습니다. 이를 위해서, 각 false negative와 false positive의 가장 큰 차이 또는 최소 비율과 같은, 지표를 더 추가할 수 있습니다.
✅ Stop and Think: 대출 신청에 영향을 받을 수 있는 다른 그룹이 있을까요?
불공정성 완화
불공정성 완화하려면, 모델을 탐색해서 다양하게 완화된 모델을 만들고 가장 공정한 모델을 선택하기 위하여 정확성과 공정성 사이 트레이드오프해서 비교합니다.
입문 강의에서는 post-processing 및 reductions approach과 같은 알고리즘 불공정성 완화에 대한, 세부적인 사항에 대해 깊게 설명하지 않지만, 여기에서 시도할 수 있는 도구가 있습니다.
Fairlearn
Fairlearn은 시스템의 공정성을 평가하고 불공정성을 완화할 수있는 오픈소스 Python 패키지입니다.
이 도구는 모델의 예측이 다른 그룹에 미치는 영향을 평가하며 돕고, 공정성과 성능 지표를 사용하여 여러 모델을 비교할 수 있으며, binary classification과 regression의 불공정성을 완화하는 알고리즘 셋을 제공할 수 있습니다.
-
Fairlearn's GitHub를 확인하고 다양한 컴포넌트를 어떻게 쓰는 지 알아보기.
-
user guide, examples 탐색해보기.
-
sample notebooks 시도해보기.
-
Azure Machine Learning에서 머신러닝 모델의 how to enable fairness assessments 알아보기.
-
Azure Machine Learning에서 더 공정한 평가 시나리오에 대하여 sample notebooks 확인해보기.
🚀 도전
편견이 처음부터 들어오는 것을 막으려면, 이렇게 해야 합니다:
- 시스템을 작동하는 사람들 사이 다양한 배경과 관점을 가집니다
- 사회의 다양성을 반영하는 데이터 셋에 투자합니다
- 편향적일 때에 더 좋은 방법을 개발합니다
모델을 구축하고 사용하면서 불공정한 실-생활 시나리오를 생각해보세요. 어떻게 고려해야 하나요?
강의 후 퀴즈
검토 & 자기주도 학습
이 강의에서, 머신러닝의 공정성과 불공정성 개념에 대한 몇 가지 기본사항을 배웠습니다.
워크숍을 보고 토픽에 대하여 깊게 알아봅니다:
- YouTube: Fairness-related harms in AI systems: Examples, assessment, and mitigation by Hanna Wallach and Miro Dudik Fairness-related harms in AI systems: Examples, assessment, and mitigation - YouTube
또한, 읽어봅시다:
-
Microsoft의 RAI 리소스 센터: Responsible AI Resources – Microsoft AI
-
Microsoft의 FATE research 그룹: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
Fairlearn toolkit 탐색합니다
공정성을 보장하기 위한 Azure Machine Learning 도구에 대해 읽어봅시다