18 KiB
Equité dans le Machine Learning

Sketchnote par Tomomi Imura
Quiz préalable
Introduction
Dans ce programme, nous allons découvrir comment le Machine Learning peut avoir un impact sur notre vie quotidienne. Encore aujourd'hui, les systèmes et les modèles sont impliqués quotidiennement dans les tâches de prise de décision, telles que les diagnostics de soins ou la détection de fraudes. Il est donc important que ces modèles fonctionnent bien afin de fournir des résultats équitables pour tout le monde.
Imaginons ce qui peut arriver lorsque les données que nous utilisons pour construire ces modèles manquent de certaines données démographiques, telles que la race, le sexe, les opinions politiques, la religion ou représentent de manière disproportionnée ces données démographiques. Qu'en est-il lorsque la sortie du modèle est interprétée pour favoriser certains éléments démographiques ? Quelle est la conséquence pour l'application l'utilisant ?
Dans cette leçon, nous :
- Sensibiliserons sur l'importance de l'équité dans le Machine Learning.
- En apprendrons plus sur les préjudices liés à l'équité.
- En apprendrons plus sur l'évaluation et l'atténuation des injustices.
Prérequis
En tant que prérequis, veuillez lire le guide des connaissances sur les "Principes de l'IA responsable" et regarder la vidéo sur le sujet suivant :
En apprendre plus sur l'IA responsable en suivant ce guide des connaissances

🎥 Cliquez sur l'image ci-dessus pour la vidéo : Microsoft's Approach to Responsible AI
Injustices dans les données et les algorithmes
"Si vous torturez les données assez longtemps, elles avoueront n'importe quoi" - Ronald Coase
Cette affirmation semble extrême, mais il est vrai que les données peuvent être manipulées pour étayer n'importe quelle conclusion. Une telle manipulation peut parfois se produire involontairement. En tant qu'êtres humains, nous avons tous des biais, et il est souvent difficile de savoir consciemment quand nous introduisons des biais dans les données.
Garantir l'équité dans l'IA et le Machine Learning reste un défi sociotechnique complexe. Cela signifie qu'il ne peut pas être abordé d'un point de vue purement social ou technique.
Dommages liés à l'équité
Qu'entendons-nous par injustice ? Le terme « injustice » englobe les impacts négatifs, ou « dommages », pour un groupe de personnes, tels que ceux définis en termes de race, de sexe, d'âge ou de statut de handicap.
Les principaux préjudices liés à l'équité peuvent être classés comme suit :
- Allocation, si un sexe ou une ethnicité par exemple est favorisé par rapport à un autre.
- Qualité de service. Si vous entraînez les données pour un scénario spécifique mais que la réalité est plus complexe, cela résulte à de très mauvaises performances du service.
- Stéréotypes. Associer à un groupe donné des attributs pré-assignés.
- Dénigration. Critiquer et étiqueter injustement quelque chose ou quelqu'un.
- Sur- ou sous- représentation. L'idée est qu'un certain groupe n'est pas vu dans une certaine profession, et tout service ou fonction qui continue de promouvoir cette représentation contribue, in-fine, à nuire à ce groupe.
Regardons quelques exemples :
Allocation
Envisageons un système hypothétique de filtrage des demandes de prêt : le système a tendance à choisir les hommes blancs comme de meilleurs candidats par rapport aux autres groupes. En conséquence, les prêts sont refusés à certains demandeurs.
Un autre exemple est un outil de recrutement expérimental développé par une grande entreprise pour sélectionner les candidats. L'outil discriminait systématiquement un sexe en utilisant des modèles qui ont été formés pour préférer les mots associés à d'autres. Cela a eu pour effet de pénaliser les candidats dont les CV contiennent des mots tels que « équipe féminine de rugby ».
✅ Faites une petite recherche pour trouver un exemple réel de ce type d'injustice.
Qualité de Service
Les chercheurs ont découvert que plusieurs classificateurs commerciaux de sexe avaient des taux d'erreur plus élevés autour des images de femmes avec des teins de peau plus foncés par opposition aux images d'hommes avec des teins de peau plus clairs. Référence
Un autre exemple tristement célèbre est un distributeur de savon pour les mains qui ne semble pas capable de détecter les personnes ayant une couleur de peau foncée. Référence
Stéréotypes
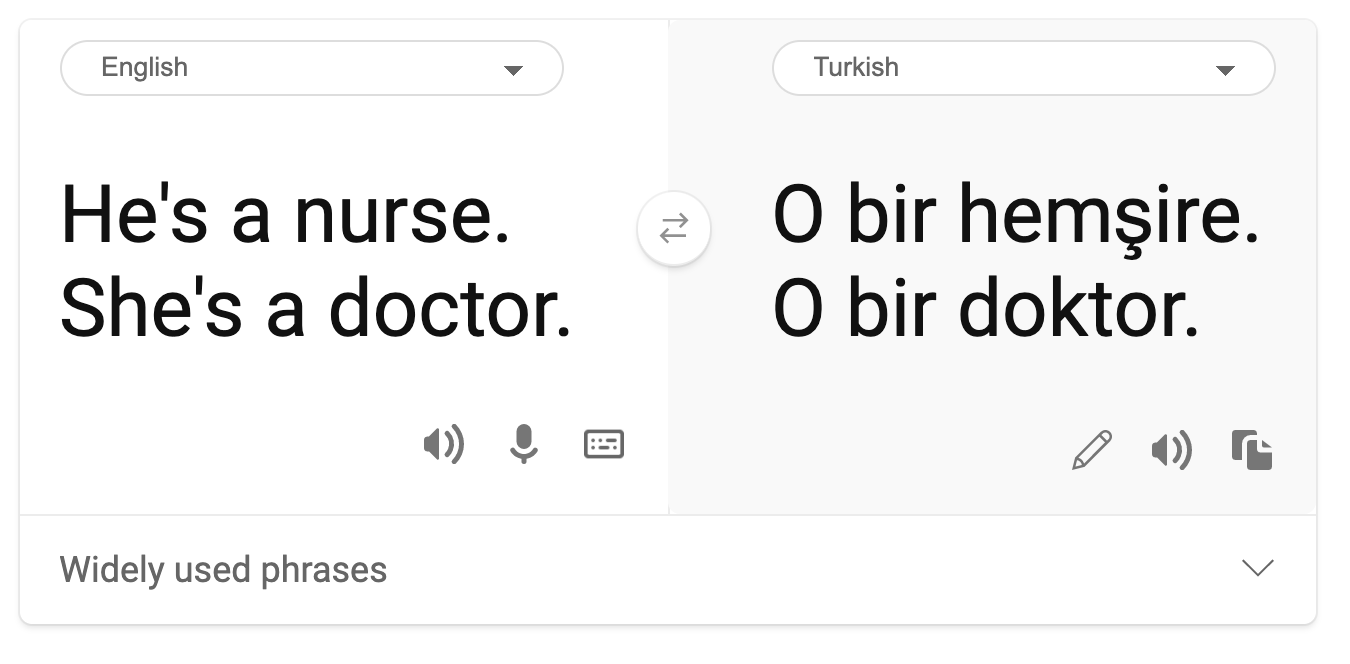
Une vision stéréotypée du sexe a été trouvée dans la traduction automatique. Lors de la traduction de « il est infirmier et elle est médecin » en turc, des problèmes ont été rencontrés. Le turc est une langue sans genre et possède un pronom « o » pour transmettre une troisième personne du singulier. Cependant, la traduction de la phrase du turc à l'anglais donne la phrase incorrecte et stéréotypée suivante : « elle est infirmière et il est médecin ».

Dénigration
Une technologie d'étiquetage d'images a notoirement mal étiqueté les images de personnes à la peau foncée comme des gorilles. L'étiquetage erroné est nocif, non seulement parce que le système fait des erreurs mais surtout car il a spécifiquement appliqué une étiquette qui a pour longtemps été délibérément détournée pour dénigrer les personnes de couleurs.

🎥 Cliquez sur l'image ci-dessus pour la vidéo : AI, Ain't I a Woman - une performance montrant le préjudice causé par le dénigrement raciste par l'IA
Sur- ou sous- représentation
Les résultats de recherche d'images biaisés peuvent être un bon exemple de ce préjudice. Lorsque nous recherchons des images de professions avec un pourcentage égal ou supérieur d'hommes que de femmes, comme l'ingénierie ou PDG, nous remarquons des résultats qui sont plus fortement biaisés en faveur d'un sexe donné.

Cette recherche sur Bing pour « PDG » produit des résultats assez inclusifs
Ces cinq principaux types de préjudices ne sont pas mutuellement exclusifs et un même système peut présenter plus d'un type de préjudice. De plus, chaque cas varie dans sa gravité. Par exemple, étiqueter injustement quelqu'un comme un criminel est un mal beaucoup plus grave que de mal étiqueter une image. Il est toutefois important de se rappeler que même des préjudices relativement peu graves peuvent causer une aliénation ou une isolation de personnes et l'impact cumulatif peut être extrêmement oppressant.
✅ Discussion: Revoyez certains des exemples et voyez s'ils montrent des préjudices différents.
| Allocation | Qualité de service | Stéréotypes | Dénigration | Sur- or sous- représentation | |
|---|---|---|---|---|---|
| Système de recrutement automatisé | x | x | x | x | |
| Traduction automatique | |||||
| Étiquetage des photos |
Détecter l'injustice
Il existe de nombreuses raisons pour lesquelles un système donné se comporte de manière injuste. Les préjugés sociaux, par exemple, pourraient se refléter dans les ensembles de données utilisés pour les former. Par exemple, l'injustice à l'embauche pourrait avoir été exacerbée par une confiance excessive dans les données historiques. Ainsi, en utilisant les curriculum vitae soumis à l'entreprise sur une période de 10 ans, le modèle a déterminé que les hommes étaient plus qualifiés car la majorité des CV provenaient d'hommes, reflet de la domination masculine passée dans l'industrie de la technologie.
Des données inadéquates sur un certain groupe de personnes peuvent être la cause d'une injustice. Par exemple, les classificateurs d'images avaient un taux d'erreur plus élevé pour les images de personnes à la peau foncée, car les teins de peau plus foncés étaient sous-représentés dans les données.
Des hypothèses erronées faites pendant le développement causent également des injustices. Par exemple, un système d'analyse faciale destiné à prédire qui va commettre un crime sur la base d'images de visages peut conduire à des hypothèses préjudiciables. Cela pourrait entraîner des dommages substantiels pour les personnes mal classées.
Comprendre vos modèles et instaurer l'équité
Bien que de nombreux aspects de l'équité ne soient pas pris en compte dans les mesures d'équité quantitatives et qu'il ne soit pas possible de supprimer complètement les biais d'un système pour garantir l'équité, nous sommes toujours responsable de détecter et d'atténuer autant que possible les problèmes d'équité.
Lorsque nous travaillons avec des modèles de Machine Learning, il est important de comprendre vos modèles en garantissant leur interprétabilité et en évaluant et en atténuant les injustices.
Utilisons l'exemple de sélection de prêt afin de déterminer le niveau d'impact de chaque facteur sur la prédiction.
Méthodes d'évaluation
-
Identifier les préjudices (et les avantages). La première étape consiste à identifier les préjudices et les avantages. Réfléchissez à la façon dont les actions et les décisions peuvent affecter à la fois les clients potentiels et l'entreprise elle-même.
-
Identifier les groupes concernés. Une fois que vous avez compris le type de préjudices ou d'avantages qui peuvent survenir, identifiez les groupes susceptibles d'être touchés. Ces groupes sont-ils définis par le sexe, l'origine ethnique ou le groupe social ?
-
Définir des mesures d'équité. Enfin, définissez une métrique afin d'avoir quelque chose à comparer dans votre travail pour améliorer la situation.
Identifier les préjudices (et les avantages)
Quels sont les inconvénients et les avantages associés au prêt ? Pensez aux faux négatifs et aux faux positifs :
Faux négatifs (rejeter, mais Y=1) - dans ce cas, un demandeur qui sera capable de rembourser un prêt est rejeté. Il s'agit d'un événement défavorable parce que les prêts sont refusées aux candidats qualifiés.
Faux positifs (accepter, mais Y=0) - dans ce cas, le demandeur obtient un prêt mais finit par faire défaut. En conséquence, le dossier du demandeur sera envoyé à une agence de recouvrement de créances, ce qui peut affecter ses futures demandes de prêt.
Identifier les groupes touchés
L'étape suivante consiste à déterminer quels groupes sont susceptibles d'être touchés. Par exemple, dans le cas d'une demande de carte de crédit, un modèle pourrait déterminer que les femmes devraient recevoir des limites de crédit beaucoup plus basses par rapport à leurs conjoints qui partagent les biens du ménage. Tout un groupe démographique, défini par le sexe, est ainsi touché.
Définir les mesures d'équité
Nous avons identifié les préjudices et un groupe affecté, dans ce cas, défini par leur sexe. Maintenant, nous pouvons utiliser les facteurs quantifiés pour désagréger leurs métriques. Par exemple, en utilisant les données ci-dessous, nous pouvons voir que les femmes ont le taux de faux positifs le plus élevé et les hommes ont le plus petit, et que l'inverse est vrai pour les faux négatifs.
✅ Dans une prochaine leçon sur le clustering, nous verrons comment construire cette 'matrice de confusion' avec du code
| Taux de faux positifs | Taux de faux négatifs | Nombre | |
|---|---|---|---|
| Femmes | 0.37 | 0.27 | 54032 |
| Hommes | 0.31 | 0.35 | 28620 |
| Non binaire | 0.33 | 0.31 | 1266 |
Ce tableau nous dit plusieurs choses. Premièrement, nous notons qu'il y a relativement peu de personnes non binaires dans les données. Les données sont faussées, nous devons donc faire attention à la façon dont nous allons interpréter ces chiffres.
Dans ce cas, nous avons 3 groupes et 2 mesures. Lorsque nous pensons à la manière dont notre système affecte le groupe de clients avec leurs demandeurs de prêt, cela peut être suffisant. Cependant si nous souhaitions définir un plus grand nombre de groupes, nous allons sûrement devoir le répartir en de plus petits ensembles de mesures. Pour ce faire, vous pouvez ajouter plus de métriques, telles que la plus grande différence ou le plus petit rapport de chaque faux négatif et faux positif.
✅ Arrêtez-vous et réfléchissez : Quels autres groupes sont susceptibles d'être affectés par la demande de prêt ?
Atténuer l'injustice
Pour atténuer l'injustice, il faut explorer le modèle pour générer divers modèles atténués et comparer les compromis qu'il fait entre précision et équité afin de sélectionner le modèle le plus équitable.
Cette leçon d'introduction ne plonge pas profondément dans les détails de l'atténuation des injustices algorithmiques, telles que l'approche du post-traitement et des réductions, mais voici un outil que vous voudrez peut-être essayer.
Fairlearn
Fairlearn est un package Python open source qui permet d'évaluer l'équité des systèmes et d'atténuer les injustices.
L'outil aide à évaluer comment les prédictions d'un modèle affectent différents groupes, en permettant de comparer plusieurs modèles en utilisant des mesures d'équité et de performance, et en fournissant un ensemble d'algorithmes pour atténuer les injustices dans la classification binaire et la régression.
-
Apprenez à utiliser les différents composants en consultant la documentation Fairlearn sur GitHub
-
Explorer le guide utilisateur, et les exemples
-
Essayez quelques notebooks d'exemples.
-
Apprenez comment activer les évaluations d'équités des modèles de machine learning sur Azure Machine Learning.
-
Jetez un coup d'oeil aux notebooks d'exemples pour plus de scénarios d'évaluation d'équités sur Azure Machine Learning.
🚀 Challenge
Pour éviter que des biais ne soient introduits en premier lieu, nous devrions :
- Avoir une diversité d'expériences et de perspectives parmi les personnes travaillant sur les systèmes
- Investir dans des ensembles de données qui reflètent la diversité de notre société
- Développer de meilleures méthodes pour détecter et corriger les biais lorsqu'ils surviennent
Pensez à des scénarios de la vie réelle où l'injustice est évidente dans la construction et l'utilisation de modèles. Que devrions-nous considérer d'autre ?
Quiz de validation des connaissances
Révision et auto-apprentissage
Dans cette leçon, nous avons appris quelques notions de base sur les concepts d'équité et d'injustice dans le machine learning.
Regardez cet atelier pour approfondir les sujets :
- YouTube : Dommages liés à l'équité dans les systèmes d'IA : exemples, évaluation et atténuation par Hanna Wallach et Miro Dudik Fairness-related harms in AI systems: Examples, assessment, and mitigation - YouTube
Lectures supplémentaires :
-
Centre de ressources Microsoft RAI : Responsible AI Resources – Microsoft AI
-
Groupe de recherche Microsoft FATE : FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
Explorer la boite à outils Fairlearn
Lire sur les outils Azure Machine Learning afin d'assurer l'équité