17 KiB
分類の紹介
この4つのレッスンでは、クラシックな機械学習の基本的な焦点である_分類_について探ります。アジアとインドの素晴らしい料理に関するデータセットを使用して、さまざまな分類アルゴリズムを使用する方法を説明します。お腹が空いてきましたか?

これらのレッスンでパンアジア料理を祝おう!画像提供:Jen Looper
分類は、回帰技術と多くの共通点を持つ教師あり学習の一形態です。機械学習がデータセットを使用して値や名前を予測することに関するものであるならば、分類は一般的に2つのグループに分かれます:_二値分類_と_多クラス分類_です。

🎥 上の画像をクリックしてビデオを視聴:MITのJohn Guttagが分類を紹介
覚えておいてください:
- 線形回帰は、変数間の関係を予測し、新しいデータポイントがその線とどのように関係するかを正確に予測するのに役立ちました。例えば、_9月と12月のカボチャの価格_を予測することができました。
- ロジスティック回帰は、「二値カテゴリ」を発見するのに役立ちました:この価格帯では、このカボチャはオレンジ色か、オレンジ色でないか?
分類は、データポイントのラベルやクラスを決定するためにさまざまなアルゴリズムを使用します。この料理データを使用して、材料のグループを観察することで、その料理の起源を特定できるかどうかを見てみましょう。
事前クイズ
このレッスンはRでも利用可能です!
はじめに
分類は、機械学習研究者やデータサイエンティストの基本的な活動の1つです。二値値の基本的な分類(「このメールはスパムかどうか」)から、コンピュータビジョンを使用した複雑な画像分類やセグメンテーションまで、データをクラスに分類し、それに質問する能力は常に役立ちます。
プロセスをより科学的に述べると、分類法は入力変数と出力変数の関係をマッピングする予測モデルを作成します。

分類アルゴリズムが処理する二値問題と多クラス問題。インフォグラフィック提供:Jen Looper
データのクリーニング、視覚化、およびMLタスクの準備を開始する前に、データを分類するために機械学習を使用するさまざまな方法について学びましょう。
統計学に由来する、クラシックな機械学習を使用した分類は、smoker、weight、およびageなどの特徴を使用して、_X病を発症する可能性_を決定します。以前に行った回帰演習と同様の教師あり学習技術として、データはラベル付けされ、MLアルゴリズムはこれらのラベルを使用してデータセットのクラス(または「特徴」)を分類および予測し、それらをグループまたは結果に割り当てます。
✅ 料理に関するデータセットを想像してみてください。多クラスモデルでは何が答えられるでしょうか?二値モデルでは何が答えられるでしょうか?ある料理がフェヌグリークを使用する可能性があるかどうかを判断したい場合はどうでしょうか?星アニス、アーティチョーク、カリフラワー、ホースラディッシュが入った食料袋をプレゼントされた場合、典型的なインド料理を作れるかどうかを確認したい場合はどうでしょうか?

🎥 上の画像をクリックしてビデオを視聴。ショー「Chopped」の全体の前提は、「ミステリーバスケット」で、シェフがランダムな材料の選択から料理を作らなければならないというものです。確かにMLモデルが役立ったでしょう!
こんにちは「分類器」
この料理データセットに関して私たちが尋ねたい質問は、実際には多クラスの質問です。私たちにはいくつかの潜在的な国の料理があるためです。一連の材料が与えられた場合、そのデータはこれらの多くのクラスのどれに適合するでしょうか?
Scikit-learnは、解決したい問題の種類に応じて、データを分類するために使用できるさまざまなアルゴリズムを提供しています。次の2つのレッスンでは、これらのアルゴリズムのいくつかについて学びます。
演習 - データをクリーンアップしてバランスを取る
このプロジェクトを開始する前の最初のタスクは、データをクリーンアップしてバランスを取ることです。これにより、より良い結果が得られます。このフォルダーのルートにある空の_notebook.ipynb_ファイルから始めます。
最初にインストールするものはimblearnです。これはScikit-learnパッケージで、データのバランスをより良く取ることができます(このタスクについては後で詳しく学びます)。
-
imblearnをインストールするには、次のようにpip installを実行します:pip install imblearn -
データをインポートして視覚化するために必要なパッケージをインポートし、
imblearnからSMOTEもインポートします。import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl import numpy as np from imblearn.over_sampling import SMOTEこれで、次にデータをインポートする準備が整いました。
-
次のタスクはデータのインポートです:
df = pd.read_csv('../data/cuisines.csv')read_csv()will read the content of the csv file cusines.csv and place it in the variabledfを使用します。 -
データの形状を確認します:
df.head()最初の5行は次のようになります:
| | Unnamed: 0 | cuisine | almond | angelica | anise | anise_seed | apple | apple_brandy | apricot | armagnac | ... | whiskey | white_bread | white_wine | whole_grain_wheat_flour | wine | wood | yam | yeast | yogurt | zucchini | | --- | ---------- | ------- | ------ | -------- | ----- | ---------- | ----- | ------------ | ------- | -------- | --- | ------- | ----------- | ---------- | ----------------------- | ---- | ---- | --- | ----- | ------ | -------- | | 0 | 65 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 1 | 66 | indian | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 2 | 67 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 3 | 68 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 4 | 69 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | -
info()を呼び出してこのデータに関する情報を取得します:df.info()出力は次のようになります:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 2448 entries, 0 to 2447 Columns: 385 entries, Unnamed: 0 to zucchini dtypes: int64(384), object(1) memory usage: 7.2+ MB
演習 - 料理について学ぶ
ここからが面白くなります。料理ごとのデータの分布を見てみましょう。
-
barh()を呼び出してデータをバーとしてプロットします:df.cuisine.value_counts().plot.barh()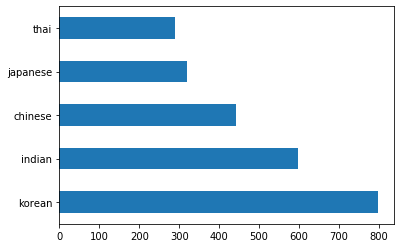
料理の数は限られていますが、データの分布は不均一です。これを修正できます!その前に、もう少し探ってみましょう。
-
料理ごとに利用可能なデータの量を調べて印刷します:
thai_df = df[(df.cuisine == "thai")] japanese_df = df[(df.cuisine == "japanese")] chinese_df = df[(df.cuisine == "chinese")] indian_df = df[(df.cuisine == "indian")] korean_df = df[(df.cuisine == "korean")] print(f'thai df: {thai_df.shape}') print(f'japanese df: {japanese_df.shape}') print(f'chinese df: {chinese_df.shape}') print(f'indian df: {indian_df.shape}') print(f'korean df: {korean_df.shape}')出力は次のようになります:
thai df: (289, 385) japanese df: (320, 385) chinese df: (442, 385) indian df: (598, 385) korean df: (799, 385)
材料の発見
次に、データをさらに深く掘り下げて、各料理の典型的な材料を学びます。料理間の混乱を引き起こす再発データをクリーニングする必要があるので、この問題について学びましょう。
-
Pythonで
create_ingredient()関数を作成して材料データフレームを作成します。この関数は、役に立たない列を削除し、カウントによって材料をソートすることから始めます:def create_ingredient_df(df): ingredient_df = df.T.drop(['cuisine','Unnamed: 0']).sum(axis=1).to_frame('value') ingredient_df = ingredient_df[(ingredient_df.T != 0).any()] ingredient_df = ingredient_df.sort_values(by='value', ascending=False, inplace=False) return ingredient_dfこれで、この関数を使用して、料理ごとのトップ10の人気材料のアイデアを得ることができます。
-
create_ingredient()and plot it callingbarh()を呼び出します:thai_ingredient_df = create_ingredient_df(thai_df) thai_ingredient_df.head(10).plot.barh()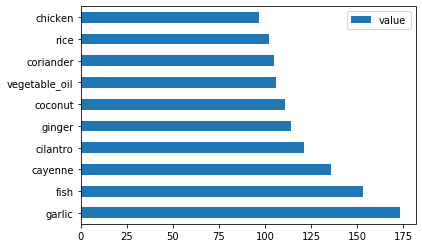
-
日本のデータについても同じことを行います:
japanese_ingredient_df = create_ingredient_df(japanese_df) japanese_ingredient_df.head(10).plot.barh()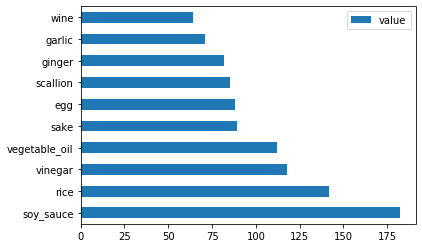
-
次に、中国の材料についても同じことを行います:
chinese_ingredient_df = create_ingredient_df(chinese_df) chinese_ingredient_df.head(10).plot.barh()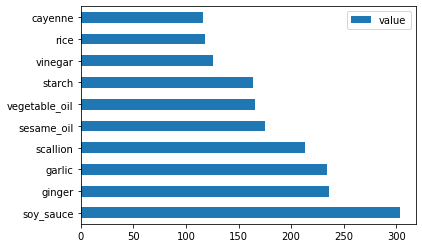
-
インドの材料をプロットします:
indian_ingredient_df = create_ingredient_df(indian_df) indian_ingredient_df.head(10).plot.barh()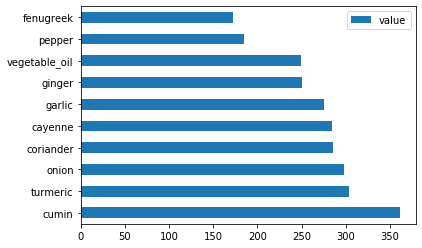
-
最後に、韓国の材料をプロットします:
korean_ingredient_df = create_ingredient_df(korean_df) korean_ingredient_df.head(10).plot.barh()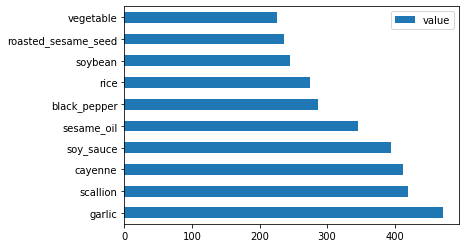
-
drop()を呼び出して、異なる料理間で混乱を引き起こす最も一般的な材料を削除します:みんなお米、にんにく、しょうがが大好きです!
feature_df= df.drop(['cuisine','Unnamed: 0','rice','garlic','ginger'], axis=1) labels_df = df.cuisine #.unique() feature_df.head()
データセットのバランスを取る
データをクリーンアップしたので、SMOTE - 「合成少数オーバーサンプリング技術」 - を使用してバランスを取ります。
-
fit_resample()を呼び出します。この戦略は、補間によって新しいサンプルを生成します。oversample = SMOTE() transformed_feature_df, transformed_label_df = oversample.fit_resample(feature_df, labels_df)データのバランスを取ることで、分類時により良い結果が得られます。二値分類を考えてみてください。データのほとんどが1つのクラスである場合、MLモデルはそのクラスをより頻繁に予測します。なぜなら、そのクラスのデータが多いためです。データのバランスを取ることで、偏ったデータを取り除き、この不均衡を解消するのに役立ちます。
-
次に、材料ごとのラベルの数を確認します:
print(f'new label count: {transformed_label_df.value_counts()}') print(f'old label count: {df.cuisine.value_counts()}')出力は次のようになります:
new label count: korean 799 chinese 799 indian 799 japanese 799 thai 799 Name: cuisine, dtype: int64 old label count: korean 799 indian 598 chinese 442 japanese 320 thai 289 Name: cuisine, dtype: int64データはきれいでバランスが取れており、とてもおいしそうです!
-
最後のステップは、ラベルと特徴を含むバランスの取れたデータを新しいデータフレームに保存し、ファイルにエクスポートできるようにすることです:
transformed_df = pd.concat([transformed_label_df,transformed_feature_df],axis=1, join='outer') -
transformed_df.head()andtransformed_df.info()を使用してデータをもう一度確認できます。今後のレッスンで使用するためにこのデータのコピーを保存します:transformed_df.head() transformed_df.info() transformed_df.to_csv("../data/cleaned_cuisines.csv")この新しいCSVはルートデータフォルダーにあります。
🚀チャレンジ
このカリキュラムにはいくつかの興味深いデータセットが含まれています。dataフォルダーを掘り下げて、二値または多クラス分類に適したデータセットが含まれているかどうかを確認してください。このデータセットにどのような質問をしますか?
事後クイズ
レビューと自己学習
SMOTEのAPIを探ってみてください。どのようなユースケースに最適ですか?どのような問題を解決しますか?
課題
免責事項: この文書は、機械ベースのAI翻訳サービスを使用して翻訳されています。正確さを期していますが、自動翻訳にはエラーや不正確さが含まれる可能性があることをご了承ください。原文の言語で書かれたオリジナル文書を権威ある情報源とみなしてください。重要な情報については、専門の人間による翻訳を推奨します。この翻訳の使用に起因する誤解や誤訳については、一切の責任を負いかねます。