20 KiB
Kenali Ucapan dengan Peranti IoT
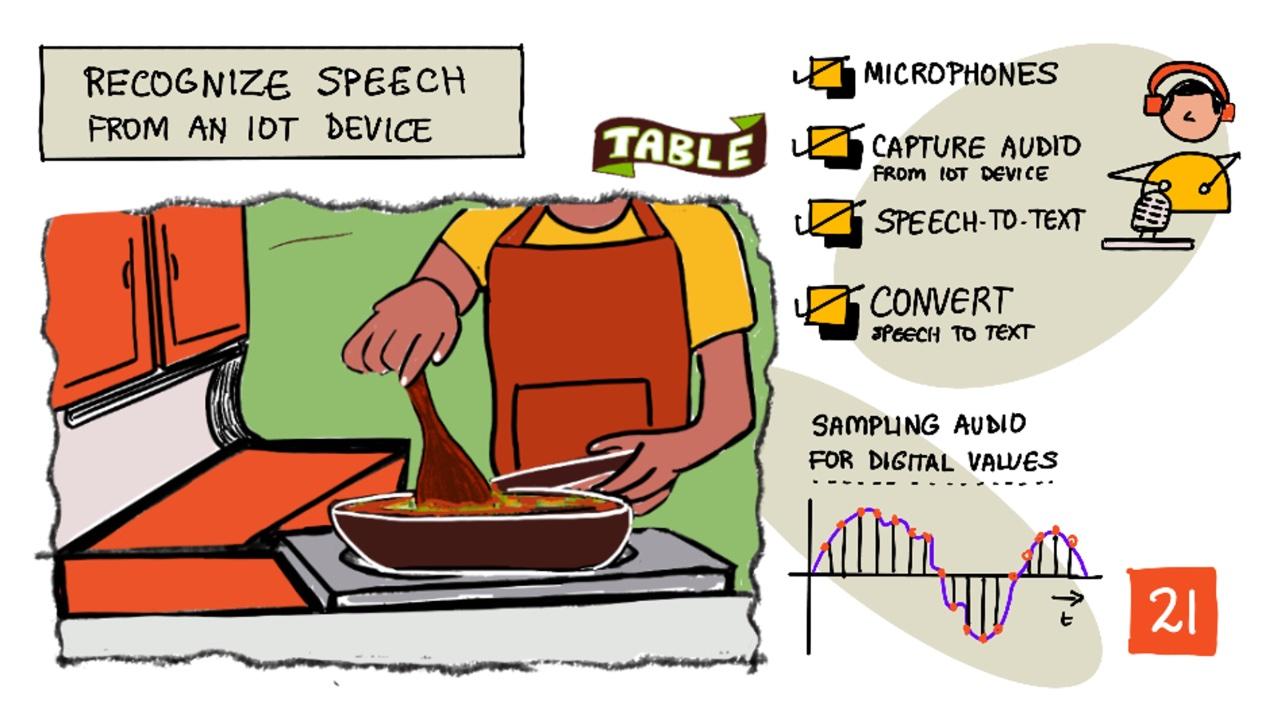
Sketchnote oleh Nitya Narasimhan. Klik imej untuk versi yang lebih besar.
Video ini memberikan gambaran tentang perkhidmatan ucapan Azure, topik yang akan dibincangkan dalam pelajaran ini:

🎥 Klik imej di atas untuk menonton video
Kuiz sebelum kuliah
Pengenalan
'Alexa, tetapkan pemasa 12 minit'
'Alexa, status pemasa'
'Alexa, tetapkan pemasa 8 minit bernama kukus brokoli'
Peranti pintar semakin meluas penggunaannya. Bukan sahaja sebagai pembesar suara pintar seperti HomePods, Echos dan Google Homes, tetapi juga tertanam dalam telefon, jam tangan, bahkan lampu dan termostat.
💁 Saya mempunyai sekurang-kurangnya 19 peranti di rumah saya yang mempunyai pembantu suara, dan itu hanya yang saya tahu!
Kawalan suara meningkatkan aksesibiliti dengan membolehkan individu yang mempunyai pergerakan terhad berinteraksi dengan peranti. Sama ada kecacatan kekal seperti dilahirkan tanpa tangan, kecacatan sementara seperti tangan patah, atau tangan penuh dengan barang belian atau anak kecil, kemampuan untuk mengawal rumah kita dengan suara dan bukannya tangan membuka dunia akses yang baru. Menjerit 'Hey Siri, tutup pintu garaj saya' sambil menguruskan bayi dan anak kecil yang nakal boleh menjadi peningkatan kecil tetapi berkesan dalam kehidupan.
Salah satu kegunaan yang paling popular untuk pembantu suara adalah menetapkan pemasa, terutamanya pemasa dapur. Kemampuan untuk menetapkan beberapa pemasa hanya dengan suara adalah sangat membantu di dapur - tidak perlu berhenti menguli doh, mengacau sup, atau membersihkan tangan daripada isi dumpling untuk menggunakan pemasa fizikal.
Dalam pelajaran ini, anda akan belajar tentang membina pengenalan suara ke dalam peranti IoT. Anda akan belajar tentang mikrofon sebagai sensor, cara menangkap audio dari mikrofon yang disambungkan ke peranti IoT, dan cara menggunakan AI untuk menukar apa yang didengar menjadi teks. Sepanjang projek ini, anda akan membina pemasa dapur pintar yang mampu menetapkan pemasa menggunakan suara dengan pelbagai bahasa.
Dalam pelajaran ini kita akan membincangkan:
Mikrofon
Mikrofon adalah sensor analog yang menukar gelombang bunyi menjadi isyarat elektrik. Getaran di udara menyebabkan komponen dalam mikrofon bergerak sedikit, dan ini menyebabkan perubahan kecil dalam isyarat elektrik. Perubahan ini kemudian diperkuat untuk menghasilkan output elektrik.
Jenis mikrofon
Mikrofon datang dalam pelbagai jenis:
-
Dinamik - Mikrofon dinamik mempunyai magnet yang dilekatkan pada diafragma bergerak yang bergerak dalam gegelung wayar, menghasilkan arus elektrik. Ini adalah kebalikan daripada kebanyakan pembesar suara, yang menggunakan arus elektrik untuk menggerakkan magnet dalam gegelung wayar, menggerakkan diafragma untuk menghasilkan bunyi. Ini bermakna pembesar suara boleh digunakan sebagai mikrofon dinamik, dan mikrofon dinamik boleh digunakan sebagai pembesar suara. Dalam peranti seperti interkom di mana pengguna sama ada mendengar atau bercakap, tetapi tidak kedua-duanya, satu peranti boleh bertindak sebagai pembesar suara dan mikrofon.
Mikrofon dinamik tidak memerlukan kuasa untuk berfungsi, isyarat elektrik dihasilkan sepenuhnya oleh mikrofon.

-
Reben - Mikrofon reben serupa dengan mikrofon dinamik, kecuali ia mempunyai reben logam dan bukannya diafragma. Reben ini bergerak dalam medan magnet menghasilkan arus elektrik. Seperti mikrofon dinamik, mikrofon reben tidak memerlukan kuasa untuk berfungsi.

-
Kondensor - Mikrofon kondensor mempunyai diafragma logam nipis dan plat belakang logam tetap. Elektrik digunakan pada kedua-duanya dan apabila diafragma bergetar, cas statik antara plat berubah menghasilkan isyarat. Mikrofon kondensor memerlukan kuasa untuk berfungsi - dipanggil Phantom power.
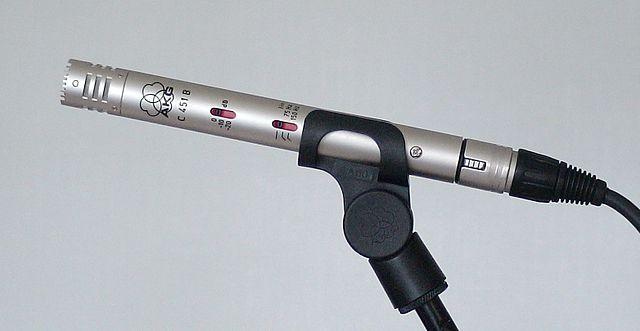
-
MEMS - Mikrofon sistem mikroelektromekanikal, atau MEMS, adalah mikrofon pada cip. Ia mempunyai diafragma sensitif tekanan yang diukir pada cip silikon, dan berfungsi serupa dengan mikrofon kondensor. Mikrofon ini boleh menjadi sangat kecil, dan diintegrasikan ke dalam litar.

Dalam imej di atas, cip yang dilabelkan LEFT adalah mikrofon MEMS, dengan diafragma kecil kurang daripada satu milimeter lebar.
✅ Lakukan penyelidikan: Apakah mikrofon yang anda ada di sekitar anda - sama ada dalam komputer, telefon, headset atau dalam peranti lain. Apakah jenis mikrofon yang mereka gunakan?
Audio digital
Audio adalah isyarat analog yang membawa maklumat yang sangat terperinci. Untuk menukar isyarat ini kepada digital, audio perlu disampel beribu-ribu kali sesaat.
🎓 Pensampelan adalah menukar isyarat audio kepada nilai digital yang mewakili isyarat pada masa itu.
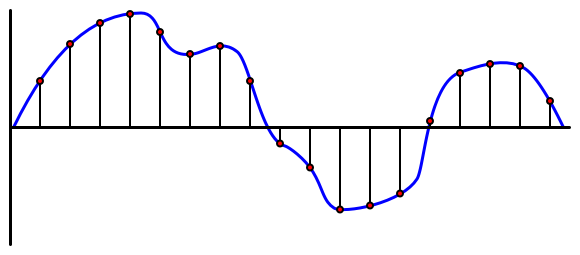
Audio digital disampel menggunakan Modulasi Kod Nadi, atau PCM. PCM melibatkan membaca voltan isyarat, dan memilih nilai diskret yang paling hampir dengan voltan itu menggunakan saiz yang ditentukan.
💁 Anda boleh menganggap PCM sebagai versi sensor modulasi lebar nadi, atau PWM (PWM telah dibincangkan dalam pelajaran 3 projek permulaan). PCM melibatkan penukaran isyarat analog kepada digital, PWM melibatkan penukaran isyarat digital kepada analog.
Sebagai contoh, kebanyakan perkhidmatan muzik penstriman menawarkan audio 16-bit atau 24-bit. Ini bermakna mereka menukar voltan kepada nilai yang sesuai dengan integer 16-bit, atau integer 24-bit. Audio 16-bit sesuai dengan nilai dalam julat -32,768 hingga 32,767, 24-bit adalah dalam julat −8,388,608 hingga 8,388,607. Lebih banyak bit, lebih dekat sampel dengan apa yang sebenarnya didengar oleh telinga kita.
💁 Anda mungkin pernah mendengar tentang audio 8-bit, sering dirujuk sebagai LoFi. Ini adalah audio yang disampel menggunakan hanya 8-bit, jadi -128 hingga 127. Audio komputer pertama terhad kepada 8-bit kerana batasan perkakasan, jadi ini sering dilihat dalam permainan retro.
Sampel ini diambil beribu-ribu kali sesaat, menggunakan kadar sampel yang ditentukan dengan baik yang diukur dalam KHz (ribuan bacaan sesaat). Perkhidmatan muzik penstriman menggunakan 48KHz untuk kebanyakan audio, tetapi beberapa audio 'lossless' menggunakan sehingga 96KHz atau bahkan 192KHz. Semakin tinggi kadar sampel, semakin dekat dengan asal audio, sehingga satu titik. Terdapat perdebatan sama ada manusia boleh membezakan di atas 48KHz.
✅ Lakukan penyelidikan: Jika anda menggunakan perkhidmatan muzik penstriman, apakah kadar sampel dan saiz yang digunakan? Jika anda menggunakan CD, apakah kadar sampel dan saiz audio CD?
Terdapat beberapa format berbeza untuk data audio. Anda mungkin pernah mendengar tentang fail mp3 - data audio yang dimampatkan untuk menjadikannya lebih kecil tanpa kehilangan kualiti. Audio yang tidak dimampatkan sering disimpan sebagai fail WAV - ini adalah fail dengan 44 bait maklumat header, diikuti oleh data audio mentah. Header mengandungi maklumat seperti kadar sampel (contohnya 16000 untuk 16KHz) dan saiz sampel (16 untuk 16-bit), dan bilangan saluran. Selepas header, fail WAV mengandungi data audio mentah.
🎓 Saluran merujuk kepada berapa banyak aliran audio berbeza yang membentuk audio. Sebagai contoh, untuk audio stereo dengan kiri dan kanan, akan ada 2 saluran. Untuk bunyi sekeliling 7.1 untuk sistem teater rumah, ini akan menjadi 8.
Saiz data audio
Data audio agak besar. Sebagai contoh, menangkap audio 16-bit yang tidak dimampatkan pada 16KHz (kadar yang cukup baik untuk digunakan dengan model ucapan ke teks), mengambil 32KB data untuk setiap saat audio:
- 16-bit bermaksud 2 bait setiap sampel (1 bait adalah 8 bit).
- 16KHz adalah 16,000 sampel sesaat.
- 16,000 x 2 bait = 32,000 bait sesaat.
Ini mungkin kelihatan seperti jumlah data yang kecil, tetapi jika anda menggunakan mikrokontroler dengan memori terhad, ini boleh menjadi banyak. Sebagai contoh, Wio Terminal mempunyai 192KB memori, dan itu perlu menyimpan kod program dan pembolehubah. Walaupun kod program anda kecil, anda tidak boleh menangkap lebih daripada 5 saat audio.
Mikrokontroler boleh mengakses storan tambahan, seperti kad SD atau memori flash. Apabila membina peranti IoT yang menangkap audio, anda perlu memastikan bukan sahaja anda mempunyai storan tambahan, tetapi kod anda menulis audio yang ditangkap dari mikrofon anda terus ke storan itu, dan apabila menghantarnya ke awan, anda menstrim dari storan ke permintaan web. Dengan cara itu anda boleh mengelakkan kehabisan memori dengan cuba memegang keseluruhan blok data audio dalam memori sekaligus.
Menangkap audio dari peranti IoT anda
Peranti IoT anda boleh disambungkan ke mikrofon untuk menangkap audio, sedia untuk ditukar kepada teks. Ia juga boleh disambungkan ke pembesar suara untuk output audio. Dalam pelajaran seterusnya, ini akan digunakan untuk memberikan maklum balas audio, tetapi adalah berguna untuk menyediakan pembesar suara sekarang untuk menguji mikrofon.
Tugasan - konfigurasikan mikrofon dan pembesar suara anda
Ikuti panduan yang relevan untuk mengkonfigurasi mikrofon dan pembesar suara untuk peranti IoT anda:
Tugasan - menangkap audio
Ikuti panduan yang relevan untuk menangkap audio pada peranti IoT anda:
Ucapan ke teks
Ucapan ke teks, atau pengenalan ucapan, melibatkan penggunaan AI untuk menukar perkataan dalam isyarat audio kepada teks.
Model pengenalan ucapan
Untuk menukar ucapan kepada teks, sampel dari isyarat audio dikumpulkan bersama dan dimasukkan ke dalam model pembelajaran mesin berdasarkan Rangkaian Neural Berulang (RNN). Ini adalah jenis model pembelajaran mesin yang boleh menggunakan data sebelumnya untuk membuat keputusan tentang data yang masuk. Sebagai contoh, RNN boleh mengesan satu blok sampel audio sebagai bunyi 'Hel', dan apabila ia menerima satu lagi yang ia fikir adalah bunyi 'lo', ia boleh menggabungkan ini dengan bunyi sebelumnya, mendapati bahawa 'Hello' adalah perkataan yang sah dan memilih itu sebagai hasilnya.
Model ML sentiasa menerima data dengan saiz yang sama setiap kali. Pengklasifikasi imej yang anda bina dalam pelajaran sebelumnya mengubah saiz imej kepada saiz tetap dan memprosesnya. Begitu juga dengan model ucapan, mereka perlu memproses blok audio bersaiz tetap. Model ucapan perlu dapat menggabungkan output daripada pelbagai ramalan untuk mendapatkan jawapan, untuk membolehkan ia membezakan antara 'Hi' dan 'Highway', atau 'flock' dan 'floccinaucinihilipilification'.
Model ucapan juga cukup maju untuk memahami konteks, dan boleh membetulkan perkataan yang mereka kesan apabila lebih banyak bunyi diproses. Sebagai contoh, jika anda berkata "Saya pergi ke kedai untuk mendapatkan dua pisang dan satu epal juga", anda akan menggunakan tiga perkataan yang berbunyi sama, tetapi dieja berbeza - to, two dan too. Model ucapan mampu memahami konteks dan menggunakan ejaan perkataan yang sesuai. 💁 Sesetengah perkhidmatan ucapan membenarkan penyesuaian untuk menjadikannya berfungsi lebih baik dalam persekitaran yang bising seperti kilang, atau dengan perkataan khusus industri seperti nama bahan kimia. Penyesuaian ini dilatih dengan menyediakan audio sampel dan transkripsi, dan berfungsi menggunakan pembelajaran pemindahan, sama seperti cara anda melatih pengklasifikasi imej menggunakan hanya beberapa imej dalam pelajaran sebelumnya.
Privasi
Apabila menggunakan teknologi pertuturan ke teks dalam peranti IoT pengguna, privasi adalah sangat penting. Peranti ini mendengar audio secara berterusan, jadi sebagai pengguna, anda tidak mahu semua yang anda katakan dihantar ke awan dan ditukar kepada teks. Bukan sahaja ini akan menggunakan banyak jalur lebar Internet, ia juga mempunyai implikasi privasi yang besar, terutamanya apabila sesetengah pengeluar peranti pintar memilih audio secara rawak untuk manusia mengesahkan teks yang dijana bagi membantu meningkatkan model mereka.
Anda hanya mahu peranti pintar anda menghantar audio ke awan untuk diproses apabila anda menggunakannya, bukan apabila ia mendengar audio di rumah anda, audio yang mungkin termasuk mesyuarat peribadi atau interaksi intim. Cara kebanyakan peranti pintar berfungsi adalah dengan wake word, frasa utama seperti "Alexa", "Hey Siri", atau "OK Google" yang menyebabkan peranti 'bangun' dan mendengar apa yang anda katakan sehingga ia mengesan jeda dalam pertuturan anda, menunjukkan anda telah selesai bercakap dengan peranti tersebut.
🎓 Pengesanan wake word juga dikenali sebagai Keyword spotting atau Keyword recognition.
Wake word ini dikesan pada peranti, bukan di awan. Peranti pintar ini mempunyai model AI kecil yang berjalan pada peranti yang mendengar wake word, dan apabila ia dikesan, mula menstrim audio ke awan untuk pengiktirafan. Model ini sangat khusus, dan hanya mendengar wake word.
💁 Sesetengah syarikat teknologi menambah lebih banyak privasi kepada peranti mereka dan melakukan sebahagian daripada penukaran pertuturan ke teks pada peranti. Apple telah mengumumkan bahawa sebagai sebahagian daripada kemas kini iOS dan macOS 2021 mereka, mereka akan menyokong penukaran pertuturan ke teks pada peranti, dan dapat mengendalikan banyak permintaan tanpa perlu menggunakan awan. Ini adalah hasil daripada pemproses yang berkuasa dalam peranti mereka yang boleh menjalankan model ML.
✅ Apakah pendapat anda tentang implikasi privasi dan etika menyimpan audio yang dihantar ke awan? Adakah audio ini patut disimpan, dan jika ya, bagaimana? Adakah anda fikir penggunaan rakaman untuk penguatkuasaan undang-undang adalah pertukaran yang baik untuk kehilangan privasi?
Pengesanan wake word biasanya menggunakan teknik yang dikenali sebagai TinyML, iaitu menukar model ML supaya dapat berjalan pada mikrokontroler. Model ini bersaiz kecil, dan menggunakan kuasa yang sangat sedikit untuk beroperasi.
Untuk mengelakkan kerumitan melatih dan menggunakan model wake word, pemasa pintar yang anda bina dalam pelajaran ini akan menggunakan butang untuk menghidupkan pengiktirafan pertuturan.
💁 Jika anda ingin mencuba mencipta model pengesanan wake word untuk dijalankan pada Wio Terminal atau Raspberry Pi, lihat tutorial bertindak balas kepada suara anda oleh Edge Impulse. Jika anda ingin menggunakan komputer anda untuk melakukan ini, anda boleh mencuba panduan pantas memulakan Custom Keyword pada dokumen Microsoft.
Tukar pertuturan ke teks
![]()
Sama seperti klasifikasi imej dalam projek terdahulu, terdapat perkhidmatan AI sedia ada yang boleh mengambil pertuturan sebagai fail audio dan menukarnya kepada teks. Salah satu perkhidmatan tersebut ialah Speech Service, sebahagian daripada Cognitive Services, perkhidmatan AI sedia ada yang boleh anda gunakan dalam aplikasi anda.
Tugasan - konfigurasikan sumber AI pertuturan
-
Cipta Resource Group untuk projek ini yang dinamakan
smart-timer -
Gunakan arahan berikut untuk mencipta sumber pertuturan percuma:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>Gantikan
<location>dengan lokasi yang anda gunakan semasa mencipta Resource Group. -
Anda memerlukan kunci API untuk mengakses sumber pertuturan daripada kod anda. Jalankan arahan berikut untuk mendapatkan kunci:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableSalin salah satu kunci tersebut.
Tugasan - tukar pertuturan ke teks
Ikuti panduan yang berkaitan untuk menukar pertuturan ke teks pada peranti IoT anda:
🚀 Cabaran
Pengiktirafan pertuturan telah wujud sejak sekian lama, dan terus bertambah baik. Lakukan kajian tentang keupayaan semasa dan bandingkan bagaimana ia telah berkembang dari masa ke masa, termasuk sejauh mana ketepatan transkripsi mesin berbanding manusia.
Apakah pendapat anda tentang masa depan pengiktirafan pertuturan?
Kuiz selepas kuliah
Ulasan & Kajian Kendiri
- Baca tentang jenis mikrofon yang berbeza dan cara ia berfungsi dalam artikel tentang perbezaan antara mikrofon dinamik dan kondensor di Musician's HQ.
- Baca lebih lanjut tentang perkhidmatan pertuturan Cognitive Services dalam dokumentasi perkhidmatan pertuturan di Microsoft Docs.
- Baca tentang pengesanan kata kunci dalam dokumentasi pengiktirafan kata kunci di Microsoft Docs.
Tugasan
Penafian:
Dokumen ini telah diterjemahkan menggunakan perkhidmatan terjemahan AI Co-op Translator. Walaupun kami berusaha untuk memastikan ketepatan, sila ambil perhatian bahawa terjemahan automatik mungkin mengandungi kesilapan atau ketidaktepatan. Dokumen asal dalam bahasa asalnya harus dianggap sebagai sumber yang berwibawa. Untuk maklumat yang kritikal, terjemahan manusia profesional adalah disyorkan. Kami tidak bertanggungjawab atas sebarang salah faham atau salah tafsir yang timbul daripada penggunaan terjemahan ini.