48 KiB
วิทยาศาสตร์ข้อมูลบนคลาวด์: วิธี "Low code/No code"
 |
|---|
| วิทยาศาสตร์ข้อมูลบนคลาวด์: Low Code - ภาพสเก็ตช์โดย @nitya |
สารบัญ:
- วิทยาศาสตร์ข้อมูลบนคลาวด์: วิธี "Low code/No code"
แบบทดสอบก่อนเรียน
1. บทนำ
1.1 Azure Machine Learning คืออะไร?
แพลตฟอร์มคลาวด์ Azure มีผลิตภัณฑ์และบริการคลาวด์มากกว่า 200 รายการที่ออกแบบมาเพื่อช่วยให้คุณสร้างโซลูชันใหม่ๆ ได้อย่างมีประสิทธิภาพ นักวิทยาศาสตร์ข้อมูลใช้ความพยายามอย่างมากในการสำรวจและเตรียมข้อมูล รวมถึงการทดลองใช้อัลกอริธึมการฝึกโมเดลต่างๆ เพื่อสร้างโมเดลที่แม่นยำ งานเหล่านี้ใช้เวลามากและมักใช้ทรัพยากรการประมวลผลที่มีราคาแพงอย่างไม่มีประสิทธิภาพ
Azure ML เป็นแพลตฟอร์มบนคลาวด์สำหรับการสร้างและดำเนินการโซลูชัน Machine Learning บน Azure โดยมีฟีเจอร์และความสามารถหลากหลายที่ช่วยให้นักวิทยาศาสตร์ข้อมูลเตรียมข้อมูล ฝึกโมเดล เผยแพร่บริการพยากรณ์ และติดตามการใช้งาน สิ่งสำคัญที่สุดคือช่วยเพิ่มประสิทธิภาพโดยการทำงานที่ใช้เวลามากให้เป็นอัตโนมัติ และช่วยให้ใช้ทรัพยากรการประมวลผลบนคลาวด์ที่สามารถปรับขนาดได้อย่างมีประสิทธิภาพเพื่อจัดการข้อมูลปริมาณมาก โดยเสียค่าใช้จ่ายเฉพาะเมื่อใช้งานจริง
Azure ML มีเครื่องมือทั้งหมดที่นักพัฒนาและนักวิทยาศาสตร์ข้อมูลต้องการสำหรับการทำงาน Machine Learning ซึ่งรวมถึง:
- Azure Machine Learning Studio: พอร์ทัลเว็บใน Azure Machine Learning สำหรับตัวเลือกแบบ low-code และ no-code สำหรับการฝึกโมเดล การปรับใช้ การทำงานอัตโนมัติ การติดตาม และการจัดการทรัพยากร Studio นี้ผสานรวมกับ Azure Machine Learning SDK เพื่อประสบการณ์ที่ราบรื่น
- Jupyter Notebooks: ใช้สำหรับการสร้างต้นแบบและทดสอบโมเดล ML อย่างรวดเร็ว
- Azure Machine Learning Designer: เครื่องมือที่ช่วยให้ลากและวางโมดูลเพื่อสร้างการทดลองและปรับใช้ pipeline ในสภาพแวดล้อมแบบ low-code
- Automated machine learning UI (AutoML): ทำงานซ้ำๆ ในการพัฒนาโมเดล Machine Learning โดยอัตโนมัติ ช่วยสร้างโมเดล ML ที่มีประสิทธิภาพและคุณภาพสูง
- Data Labelling: เครื่องมือ ML ที่ช่วยในการติดป้ายกำกับข้อมูลโดยอัตโนมัติ
- ส่วนขยาย Machine Learning สำหรับ Visual Studio Code: มอบสภาพแวดล้อมการพัฒนาแบบครบวงจรสำหรับการสร้างและจัดการโครงการ ML
- Machine learning CLI: คำสั่งสำหรับจัดการทรัพยากร Azure ML ผ่านบรรทัดคำสั่ง
- การผสานรวมกับเฟรมเวิร์กโอเพ่นซอร์ส เช่น PyTorch, TensorFlow, Scikit-learn และอื่นๆ สำหรับการฝึก การปรับใช้ และการจัดการกระบวนการ Machine Learning แบบครบวงจร
- MLflow: ไลบรารีโอเพ่นซอร์สสำหรับจัดการวงจรชีวิตของการทดลอง Machine Learning MLFlow Tracking เป็นส่วนประกอบของ MLflow ที่บันทึกและติดตามเมตริกการฝึกและสิ่งประดิษฐ์ของโมเดล ไม่ว่าจะอยู่ในสภาพแวดล้อมใดก็ตาม
1.2 โครงการพยากรณ์ภาวะหัวใจล้มเหลว:
ไม่มีข้อสงสัยเลยว่าการสร้างและพัฒนาโครงการเป็นวิธีที่ดีที่สุดในการทดสอบทักษะและความรู้ของคุณ ในบทเรียนนี้ เราจะสำรวจสองวิธีที่แตกต่างกันในการสร้างโครงการวิทยาศาสตร์ข้อมูลเพื่อพยากรณ์การเกิดภาวะหัวใจล้มเหลวใน Azure ML Studio ผ่านวิธี Low code/No code และผ่าน Azure ML SDK ตามแผนภาพต่อไปนี้:
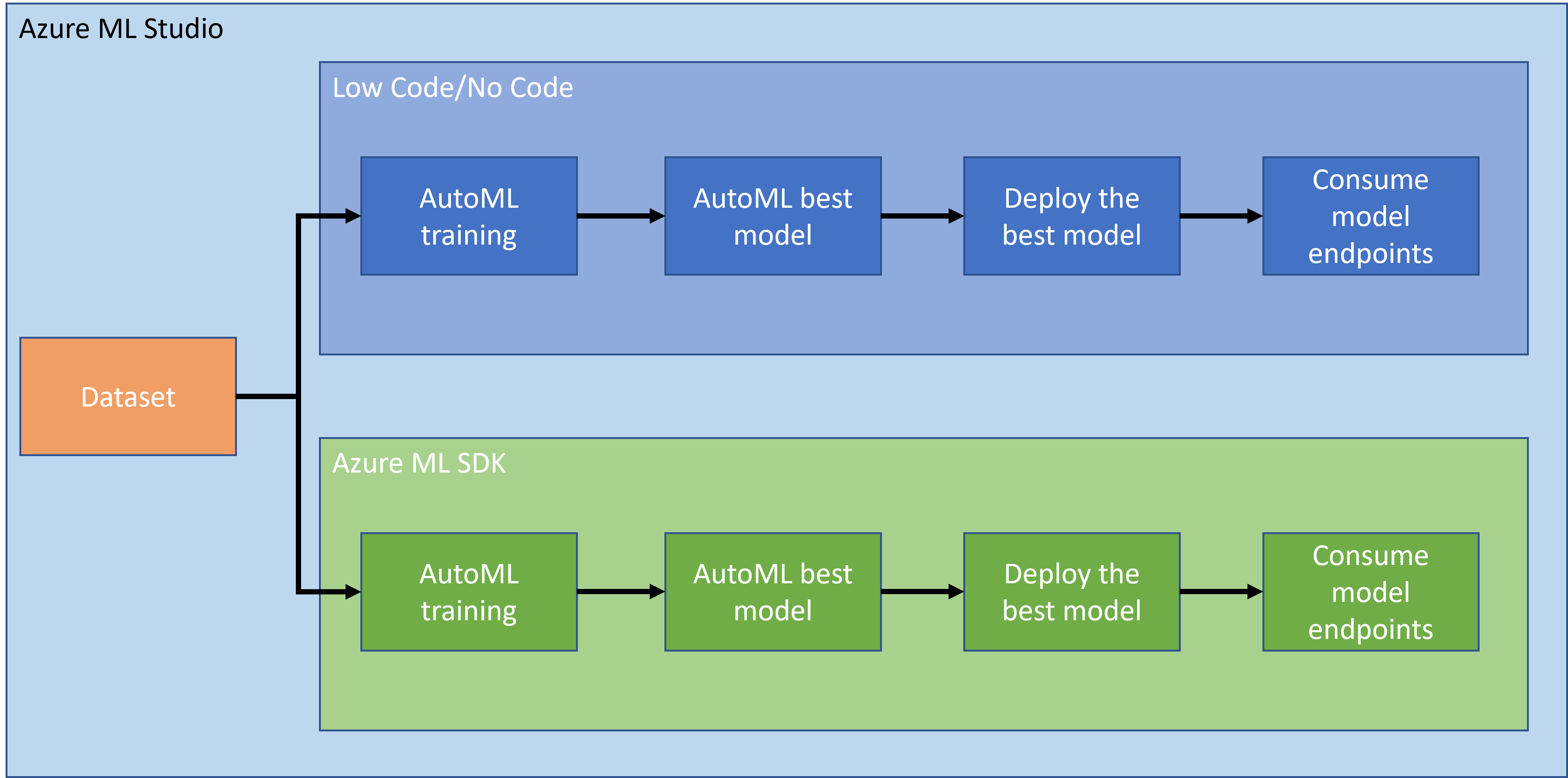
แต่ละวิธีมีข้อดีและข้อเสียของตัวเอง วิธี Low code/No code นั้นเริ่มต้นได้ง่ายกว่าเพราะเกี่ยวข้องกับการใช้งาน GUI (Graphical User Interface) โดยไม่ต้องมีความรู้เกี่ยวกับโค้ดมาก่อน วิธีนี้ช่วยให้ทดสอบความเป็นไปได้ของโครงการและสร้าง POC (Proof Of Concept) ได้อย่างรวดเร็ว อย่างไรก็ตาม เมื่อโครงการเติบโตขึ้นและต้องการความพร้อมสำหรับการใช้งานจริง การสร้างทรัพยากรผ่าน GUI อาจไม่เหมาะสม เราจำเป็นต้องทำให้ทุกอย่างเป็นอัตโนมัติผ่านการเขียนโปรแกรม ตั้งแต่การสร้างทรัพยากรไปจนถึงการปรับใช้โมเดล ซึ่งการรู้วิธีใช้ Azure ML SDK จึงมีความสำคัญ
| Low code/No code | Azure ML SDK | |
|---|---|---|
| ความเชี่ยวชาญในโค้ด | ไม่จำเป็น | จำเป็น |
| เวลาที่ใช้ในการพัฒนา | รวดเร็วและง่าย | ขึ้นอยู่กับความเชี่ยวชาญในโค้ด |
| พร้อมสำหรับการใช้งานจริง | ไม่ | ใช่ |
1.3 ชุดข้อมูลภาวะหัวใจล้มเหลว:
โรคหัวใจและหลอดเลือด (CVDs) เป็นสาเหตุการเสียชีวิตอันดับ 1 ทั่วโลก คิดเป็น 31% ของการเสียชีวิตทั้งหมดทั่วโลก ปัจจัยเสี่ยงด้านสิ่งแวดล้อมและพฤติกรรม เช่น การใช้ยาสูบ อาหารที่ไม่ดีต่อสุขภาพและโรคอ้วน การขาดการออกกำลังกาย และการใช้แอลกอฮอล์ในทางที่ผิด สามารถใช้เป็นคุณลักษณะสำหรับโมเดลการประมาณการได้ การสามารถประมาณความน่าจะเป็นของการพัฒนา CVD จะเป็นประโยชน์อย่างมากในการป้องกันการเกิดภาวะหัวใจล้มเหลวในผู้ที่มีความเสี่ยงสูง
Kaggle ได้เผยแพร่ ชุดข้อมูลภาวะหัวใจล้มเหลว ให้ใช้งานได้ฟรี ซึ่งเราจะใช้สำหรับโครงการนี้ คุณสามารถดาวน์โหลดชุดข้อมูลได้ทันที ชุดข้อมูลนี้เป็นข้อมูลแบบตารางที่มี 13 คอลัมน์ (12 คุณลักษณะและ 1 ตัวแปรเป้าหมาย) และ 299 แถว
| ชื่อตัวแปร | ประเภท | คำอธิบาย | ตัวอย่าง | |
|---|---|---|---|---|
| 1 | age | เชิงตัวเลข | อายุของผู้ป่วย | 25 |
| 2 | anaemia | บูลีน | การลดลงของเซลล์เม็ดเลือดแดงหรือฮีโมโกลบิน | 0 หรือ 1 |
| 3 | creatinine_phosphokinase | เชิงตัวเลข | ระดับเอนไซม์ CPK ในเลือด | 542 |
| 4 | diabetes | บูลีน | ผู้ป่วยเป็นเบาหวานหรือไม่ | 0 หรือ 1 |
| 5 | ejection_fraction | เชิงตัวเลข | เปอร์เซ็นต์ของเลือดที่ออกจากหัวใจในแต่ละการบีบตัว | 45 |
| 6 | high_blood_pressure | บูลีน | ผู้ป่วยมีความดันโลหิตสูงหรือไม่ | 0 หรือ 1 |
| 7 | platelets | เชิงตัวเลข | จำนวนเกล็ดเลือดในเลือด | 149000 |
| 8 | serum_creatinine | เชิงตัวเลข | ระดับเซรั่มครีเอตินินในเลือด | 0.5 |
| 9 | serum_sodium | เชิงตัวเลข | ระดับเซรั่มโซเดียมในเลือด | jun |
| 10 | sex | บูลีน | เพศหญิงหรือเพศชาย | 0 หรือ 1 |
| 11 | smoking | บูลีน | ผู้ป่วยสูบบุหรี่หรือไม่ | 0 หรือ 1 |
| 12 | time | เชิงตัวเลข | ระยะเวลาติดตามผล (วัน) | 4 |
| ---- | --------------------------- | ----------------- | --------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Target] | บูลีน | ผู้ป่วยเสียชีวิตในช่วงระยะเวลาติดตามผลหรือไม่ | 0 หรือ 1 |
เมื่อคุณมีชุดข้อมูลแล้ว เราสามารถเริ่มโครงการใน Azure ได้
2. การฝึกโมเดลแบบ Low code/No code ใน Azure ML Studio
2.1 การสร้าง Azure ML workspace
ในการฝึกโมเดลใน Azure ML คุณต้องสร้าง Azure ML workspace ก่อน Workspace เป็นทรัพยากรระดับสูงสุดสำหรับ Azure Machine Learning ซึ่งให้สถานที่ส่วนกลางสำหรับการทำงานกับสิ่งประดิษฐ์ทั้งหมดที่คุณสร้างเมื่อใช้ Azure Machine Learning Workspace จะเก็บประวัติของการฝึกทั้งหมด รวมถึงบันทึก เมตริก ผลลัพธ์ และสแนปช็อตของสคริปต์ของคุณ คุณสามารถใช้ข้อมูลนี้เพื่อตัดสินใจว่าการฝึกครั้งใดให้โมเดลที่ดีที่สุด เรียนรู้เพิ่มเติม
แนะนำให้ใช้เบราว์เซอร์ที่ทันสมัยที่สุดที่เข้ากันได้กับระบบปฏิบัติการของคุณ เบราว์เซอร์ที่รองรับได้แก่:
- Microsoft Edge (Microsoft Edge ใหม่ เวอร์ชันล่าสุด ไม่ใช่ Microsoft Edge legacy)
- Safari (เวอร์ชันล่าสุด เฉพาะ Mac)
- Chrome (เวอร์ชันล่าสุด)
- Firefox (เวอร์ชันล่าสุด)
ในการใช้ Azure Machine Learning ให้สร้าง workspace ในการสมัครสมาชิก Azure ของคุณ จากนั้นคุณสามารถใช้ workspace นี้เพื่อจัดการข้อมูล ทรัพยากรการประมวลผล โค้ด โมเดล และสิ่งประดิษฐ์อื่นๆ ที่เกี่ยวข้องกับงาน Machine Learning ของคุณ
หมายเหตุ: การสมัครสมาชิก Azure ของคุณจะถูกเรียกเก็บเงินจำนวนเล็กน้อยสำหรับการจัดเก็บข้อมูลตราบใดที่ Azure Machine Learning workspace ยังคงอยู่ในบัญชีของคุณ ดังนั้นแนะนำให้ลบ workspace เมื่อคุณไม่ได้ใช้งานอีกต่อไป
-
ลงชื่อเข้าใช้ Azure portal โดยใช้ข้อมูลประจำตัว Microsoft ที่เชื่อมโยงกับการสมัครสมาชิก Azure ของคุณ
-
เลือก +Create a resource
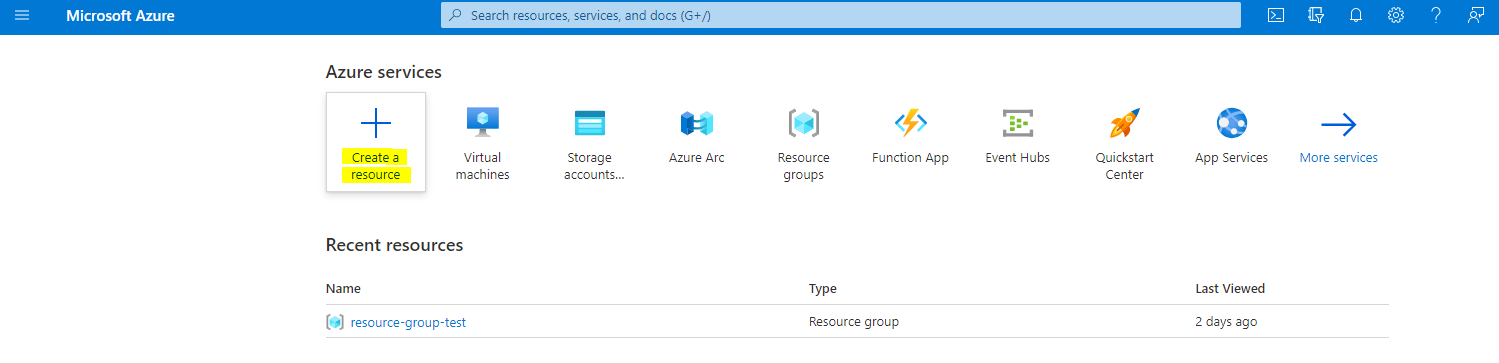
ค้นหา Machine Learning และเลือกไทล์ Machine Learning
คลิกปุ่มสร้าง
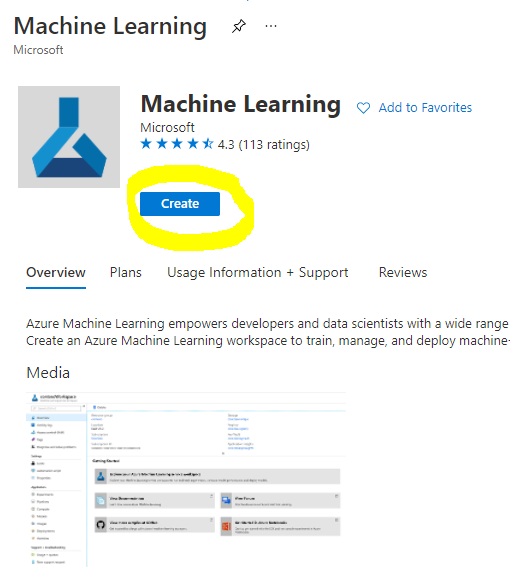
กรอกการตั้งค่าดังนี้:
- Subscription: การสมัครสมาชิก Azure ของคุณ
- Resource group: สร้างหรือเลือกกลุ่มทรัพยากร
- Workspace name: ใส่ชื่อที่ไม่ซ้ำสำหรับ workspace ของคุณ
- Region: เลือกภูมิภาคที่ใกล้คุณที่สุด
- Storage account: สังเกตบัญชีจัดเก็บข้อมูลใหม่ที่สร้างขึ้นโดยค่าเริ่มต้นสำหรับ workspace ของคุณ
- Key vault: สังเกต Key Vault ใหม่ที่สร้างขึ้นโดยค่าเริ่มต้นสำหรับ workspace ของคุณ
- Application insights: สังเกตทรัพยากร Application Insights ใหม่ที่สร้างขึ้นโดยค่าเริ่มต้นสำหรับ workspace ของคุณ
- Container registry: ไม่มี (จะถูกสร้างโดยอัตโนมัติเมื่อคุณปรับใช้โมเดลในคอนเทนเนอร์ครั้งแรก)
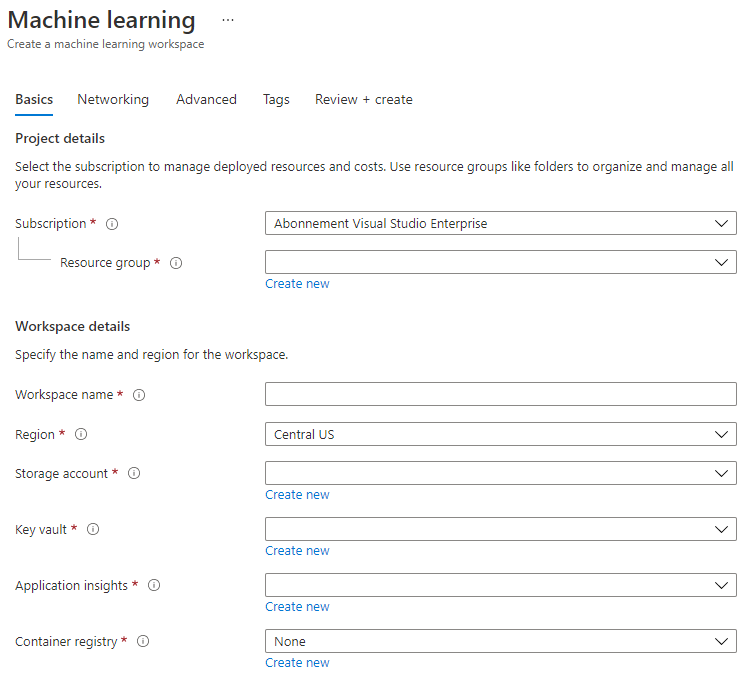
- คลิกปุ่มสร้าง + ตรวจสอบ และจากนั้นคลิกปุ่มสร้าง
-
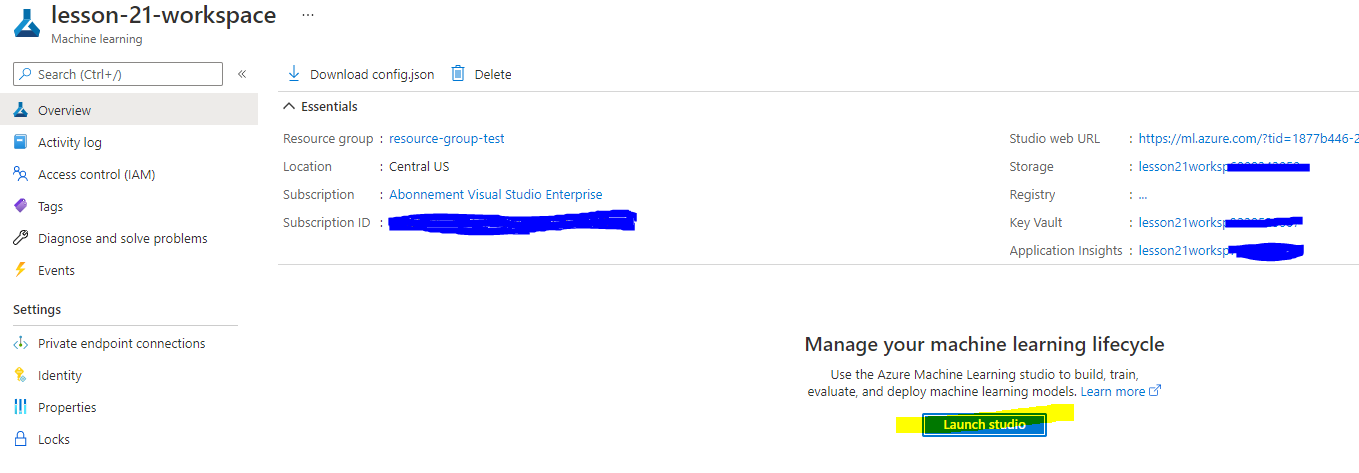
รอให้ workspace ของคุณถูกสร้าง (อาจใช้เวลาสักครู่) จากนั้นไปที่ workspace ในพอร์ทัล คุณสามารถค้นหาได้ผ่านบริการ Azure Machine Learning
-
ในหน้า Overview ของ workspace ของคุณ เปิด Azure Machine Learning studio (หรือเปิดแท็บเบราว์เซอร์ใหม่และไปที่ https://ml.azure.com) และลงชื่อเข้าใช้ Azure Machine Learning studio โดยใช้บัญชี Microsoft ของคุณ หากได้รับแจ้ง ให้เลือกไดเรกทอรีและการสมัครสมาชิก Azure ของคุณ และ workspace Azure Machine Learning ของคุณ
- ใน Azure Machine Learning studio ให้สลับไอคอน ☰ ที่มุมบนซ้ายเพื่อดูหน้าต่างๆ ในอินเทอร์เฟซ คุณสามารถใช้หน้านี้เพื่อจัดการทรัพยากรใน workspace ของคุณ
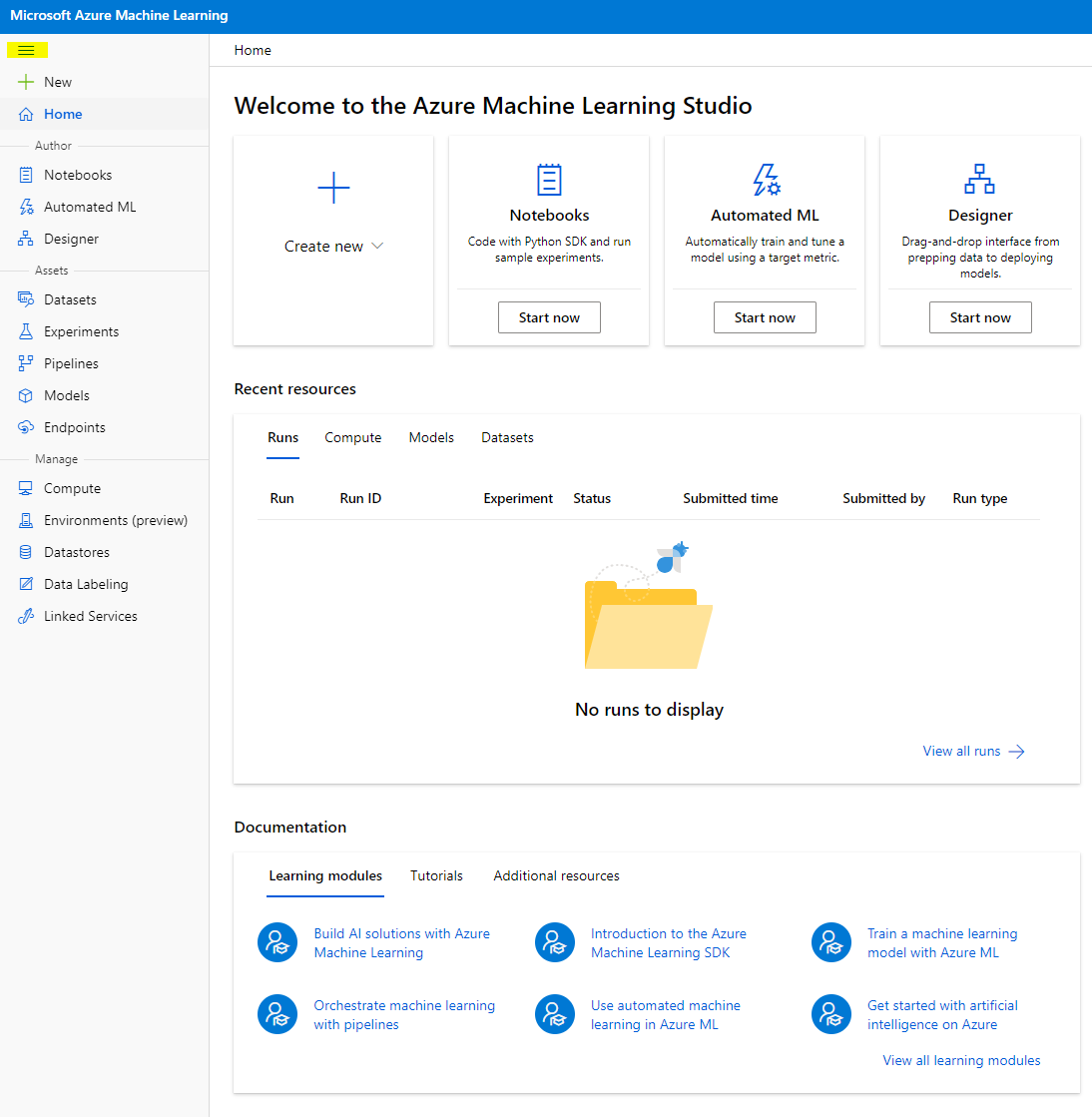
คุณสามารถจัดการ workspace ของคุณโดยใช้ Azure portal แต่สำหรับนักวิทยาศาสตร์ข้อมูลและวิศวกร Machine Learning Operations Azure Machine Learning Studio มอบอินเทอร์เฟซที่เน้นการใช้งานสำหรับการจัดการทรัพยากร workspace
2.2 ทรัพยากรการประมวลผล
ทรัพยากรการประมวลผลคือทรัพยากรบนคลาวด์ที่คุณสามารถใช้รันกระบวนการฝึกโมเดลและสำรวจข้อมูล มีทรัพยากรการประมวลผล 4 ประเภทที่คุณสามารถสร้างได้:
- Compute Instances: สถานีงานพัฒนาที่นักวิทยาศาสตร์ข้อมูลสามารถใช้ทำงานกับข้อมูลและโมเดลได้ ซึ่งเกี่ยวข้องกับการสร้าง Virtual Machine (VM) และเปิดตัวโน้ตบุ๊กอินสแตนซ์ จากนั้นคุณสามารถฝึกโมเดลโดยเรียกคลัสเตอร์การประมวลผลจากโน้ตบุ๊ก
- Compute Clusters: คลัสเตอร์ VM ที่ปรับขนาดได้สำหรับการประมวลผลโค้ดการทดลองตามความต้องการ คุณจะต้องใช้เมื่อฝึกโมเดล คลัสเตอร์การประมวลผลยังสามารถใช้ทรัพยากร GPU หรือ CPU เฉพาะทางได้
- Inference Clusters: เป้าหมายการปรับใช้สำหรับบริการพยากรณ์ที่ใช้โมเดลที่คุณฝึก
- Attached Compute: ลิงก์ไปยังทรัพยากรคอมพิวเตอร์ Azure ที่มีอยู่ เช่น Virtual Machines หรือคลัสเตอร์ Azure Databricks
2.2.1 การเลือกตัวเลือกที่เหมาะสมสำหรับทรัพยากรคอมพิวเตอร์ของคุณ
มีปัจจัยสำคัญบางประการที่ควรพิจารณาเมื่อสร้างทรัพยากรคอมพิวเตอร์ และตัวเลือกเหล่านี้อาจเป็นการตัดสินใจที่สำคัญ
คุณต้องการ CPU หรือ GPU?
CPU (Central Processing Unit) คือวงจรอิเล็กทรอนิกส์ที่ทำหน้าที่ประมวลผลคำสั่งในโปรแกรมคอมพิวเตอร์ ส่วน GPU (Graphics Processing Unit) เป็นวงจรอิเล็กทรอนิกส์เฉพาะทางที่สามารถประมวลผลโค้ดที่เกี่ยวข้องกับกราฟิกได้ในอัตราที่สูงมาก
ความแตกต่างหลักระหว่างสถาปัตยกรรม CPU และ GPU คือ CPU ถูกออกแบบมาเพื่อจัดการงานที่หลากหลายได้อย่างรวดเร็ว (วัดจากความเร็วของนาฬิกา CPU) แต่มีข้อจำกัดในความสามารถในการทำงานพร้อมกัน GPU ถูกออกแบบมาสำหรับการประมวลผลแบบขนานและเหมาะสมกว่าสำหรับงานการเรียนรู้เชิงลึก
| CPU | GPU |
|---|---|
| ราคาถูกกว่า | ราคาแพงกว่า |
| ระดับการทำงานพร้อมกันต่ำ | ระดับการทำงานพร้อมกันสูง |
| ช้ากว่าในการฝึกโมเดลการเรียนรู้เชิงลึก | เหมาะสมสำหรับการเรียนรู้เชิงลึก |
ขนาดของคลัสเตอร์
คลัสเตอร์ที่ใหญ่กว่าจะมีค่าใช้จ่ายสูงกว่า แต่จะให้การตอบสนองที่ดีกว่า ดังนั้น หากคุณมีเวลาแต่มีงบประมาณจำกัด คุณควรเริ่มต้นด้วยคลัสเตอร์ขนาดเล็ก ในทางกลับกัน หากคุณมีงบประมาณแต่มีเวลาจำกัด คุณควรเริ่มต้นด้วยคลัสเตอร์ขนาดใหญ่
ขนาดของ VM
ขึ้นอยู่กับข้อจำกัดด้านเวลาและงบประมาณ คุณสามารถปรับขนาด RAM, ดิสก์, จำนวนคอร์ และความเร็วของนาฬิกา การเพิ่มพารามิเตอร์เหล่านี้ทั้งหมดจะมีค่าใช้จ่ายสูงขึ้น แต่จะให้ประสิทธิภาพที่ดีกว่า
อินสแตนซ์แบบเฉพาะหรือแบบลำดับความสำคัญต่ำ?
อินสแตนซ์แบบลำดับความสำคัญต่ำหมายความว่าสามารถถูกขัดจังหวะได้: โดยพื้นฐานแล้ว Microsoft Azure สามารถนำทรัพยากรเหล่านั้นไปใช้กับงานอื่น ทำให้งานถูกขัดจังหวะ อินสแตนซ์แบบเฉพาะ หรือแบบไม่สามารถขัดจังหวะได้ หมายความว่างานจะไม่ถูกยกเลิกโดยไม่ได้รับอนุญาตจากคุณ นี่เป็นอีกหนึ่งการพิจารณาระหว่างเวลาและเงิน เนื่องจากอินสแตนซ์ที่สามารถขัดจังหวะได้มีราคาถูกกว่าอินสแตนซ์แบบเฉพาะ
2.2.2 การสร้างคลัสเตอร์คอมพิวเตอร์
ใน Azure ML workspace ที่เราสร้างไว้ก่อนหน้านี้ ไปที่ Compute และคุณจะเห็นทรัพยากรคอมพิวเตอร์ต่างๆ ที่เราเพิ่งพูดถึง (เช่น Compute instances, Compute clusters, Inference clusters และ Attached compute) สำหรับโปรเจกต์นี้ เราจะต้องใช้ Compute cluster สำหรับการฝึกโมเดล ใน Studio คลิกที่เมนู "Compute" จากนั้นแท็บ "Compute cluster" และคลิกปุ่ม "+ New" เพื่อสร้าง Compute cluster
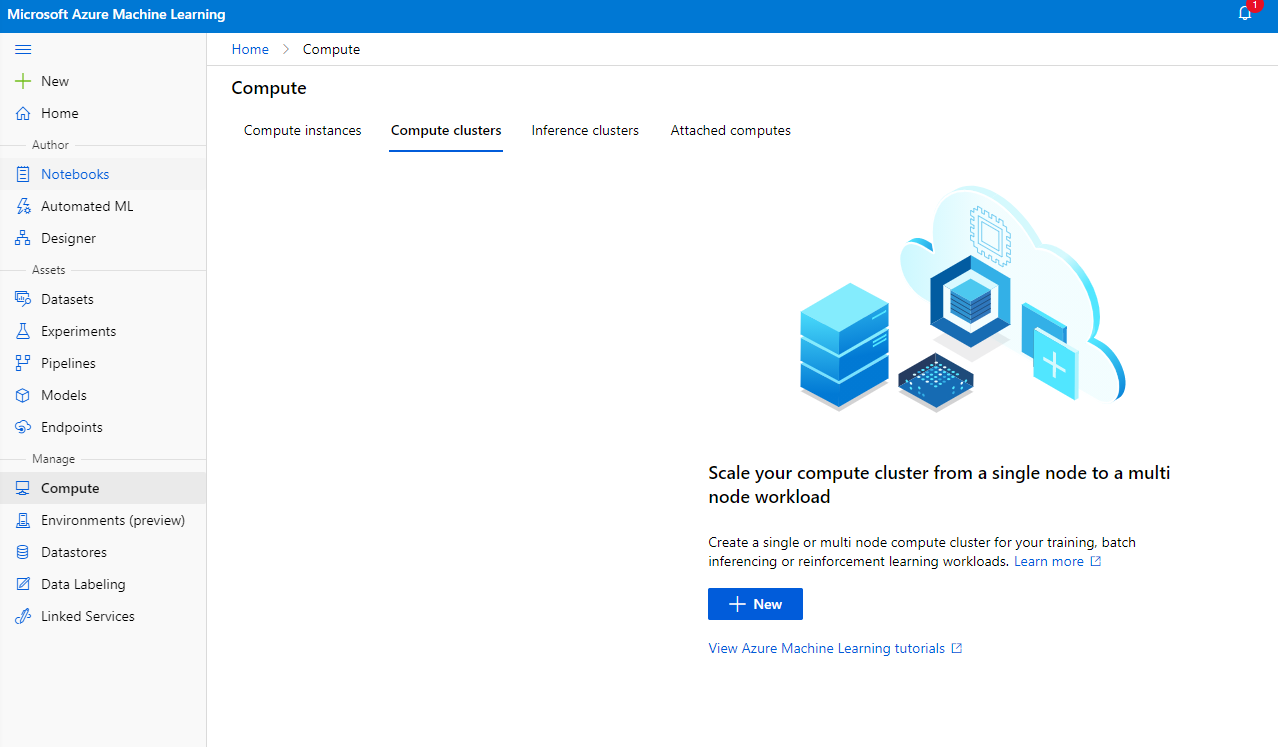
- เลือกตัวเลือกของคุณ: Dedicated vs Low priority, CPU หรือ GPU, ขนาด VM และจำนวนคอร์ (คุณสามารถใช้การตั้งค่าเริ่มต้นสำหรับโปรเจกต์นี้)
- คลิกปุ่ม Next
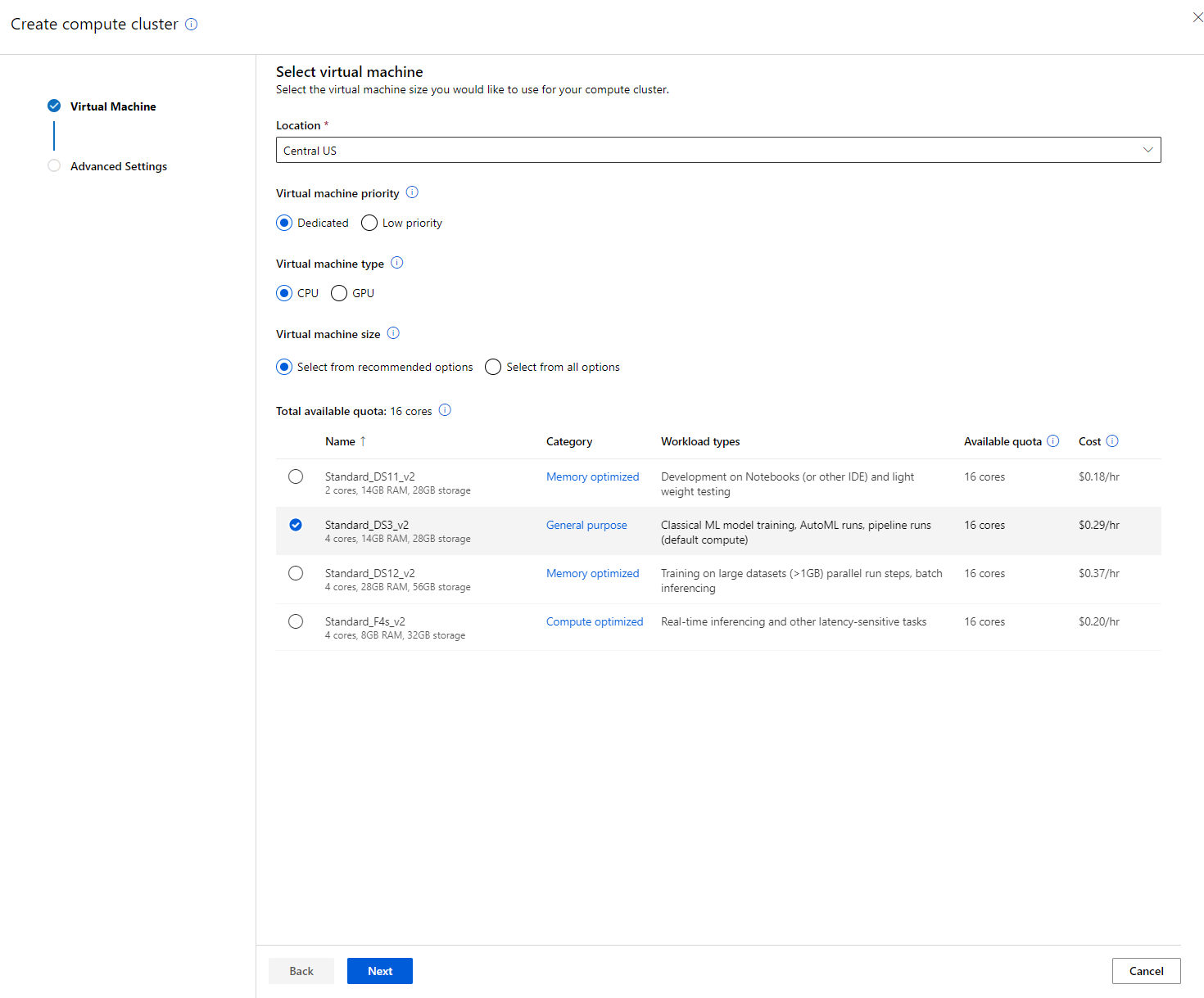
- ตั้งชื่อคลัสเตอร์
- เลือกตัวเลือกของคุณ: จำนวนโหนดขั้นต่ำ/สูงสุด, วินาทีที่ไม่ได้ใช้งานก่อนลดขนาดลง, การเข้าถึง SSH โปรดทราบว่าหากจำนวนโหนดขั้นต่ำคือ 0 คุณจะประหยัดเงินเมื่อคลัสเตอร์ไม่ได้ใช้งาน โปรดทราบว่าจำนวนโหนดสูงสุดที่มากขึ้นจะทำให้การฝึกโมเดลเร็วขึ้น จำนวนโหนดสูงสุดที่แนะนำคือ 3
- คลิกปุ่ม "Create" ขั้นตอนนี้อาจใช้เวลาสักครู่
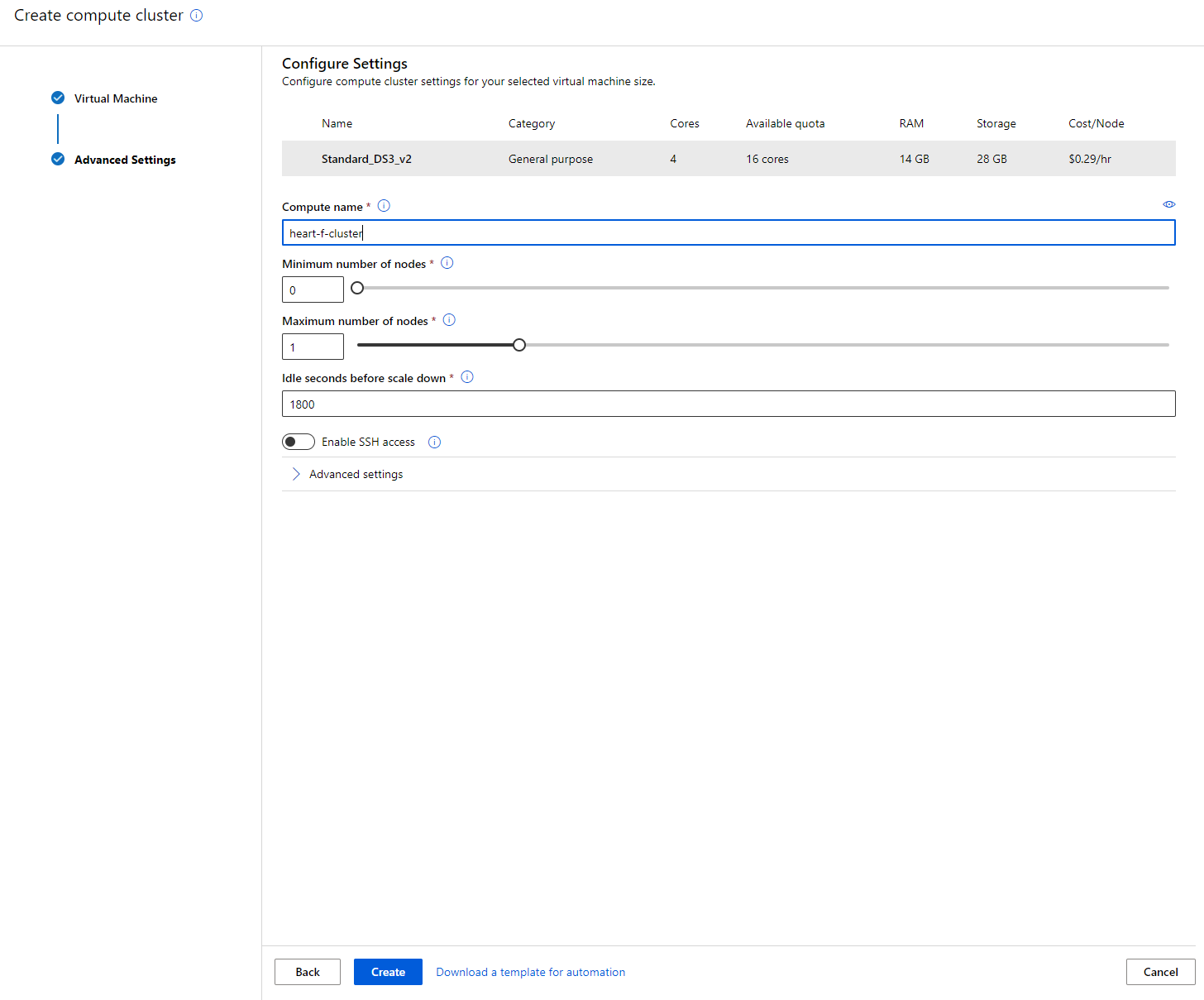
เยี่ยมมาก! ตอนนี้เรามี Compute cluster แล้ว เราจำเป็นต้องโหลดข้อมูลไปยัง Azure ML Studio
2.3 การโหลดชุดข้อมูล
-
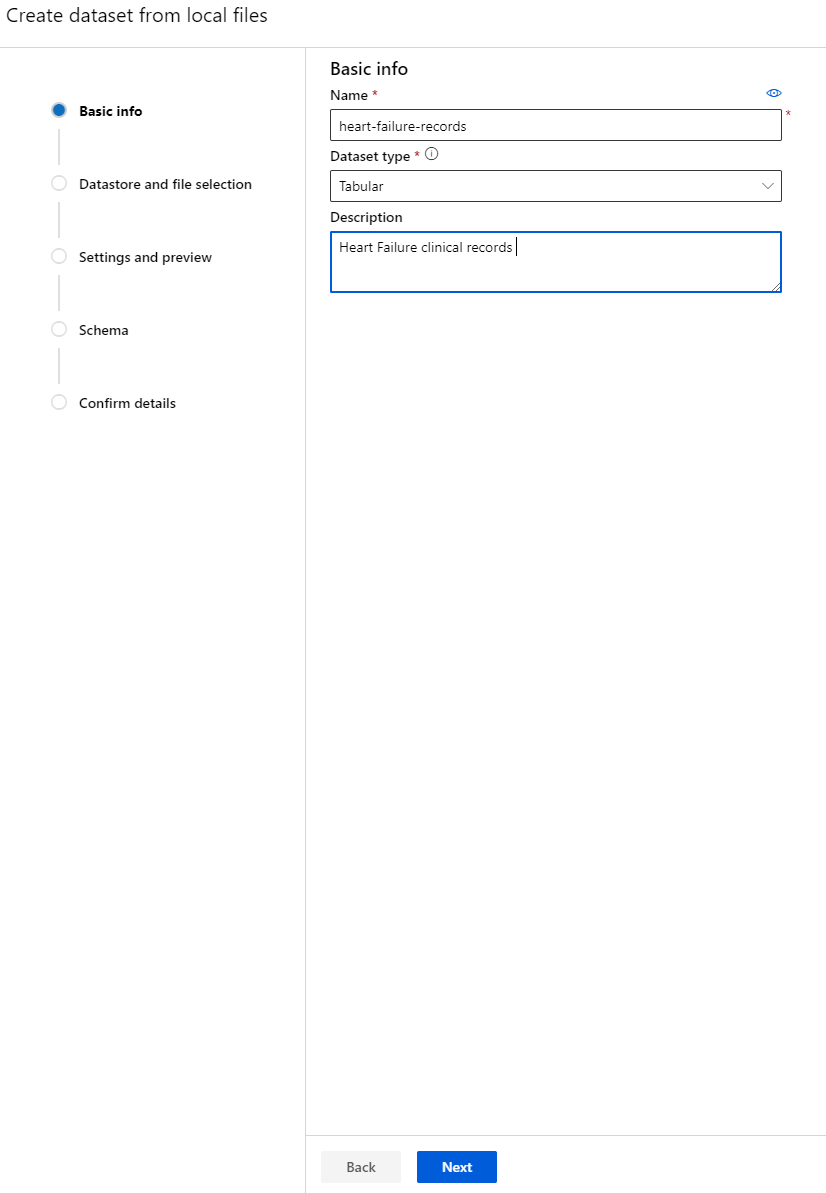
ใน Azure ML workspace ที่เราสร้างไว้ก่อนหน้านี้ คลิกที่ "Datasets" ในเมนูด้านซ้ายและคลิกปุ่ม "+ Create dataset" เพื่อสร้างชุดข้อมูล เลือกตัวเลือก "From local files" และเลือกชุดข้อมูล Kaggle ที่เราดาวน์โหลดไว้ก่อนหน้านี้
-
ตั้งชื่อชุดข้อมูลของคุณ ประเภท และคำอธิบาย คลิก Next อัปโหลดข้อมูลจากไฟล์ คลิก Next
-
ใน Schema เปลี่ยนประเภทข้อมูลเป็น Boolean สำหรับฟีเจอร์ต่อไปนี้: anaemia, diabetes, high blood pressure, sex, smoking, และ DEATH_EVENT คลิก Next และคลิก Create
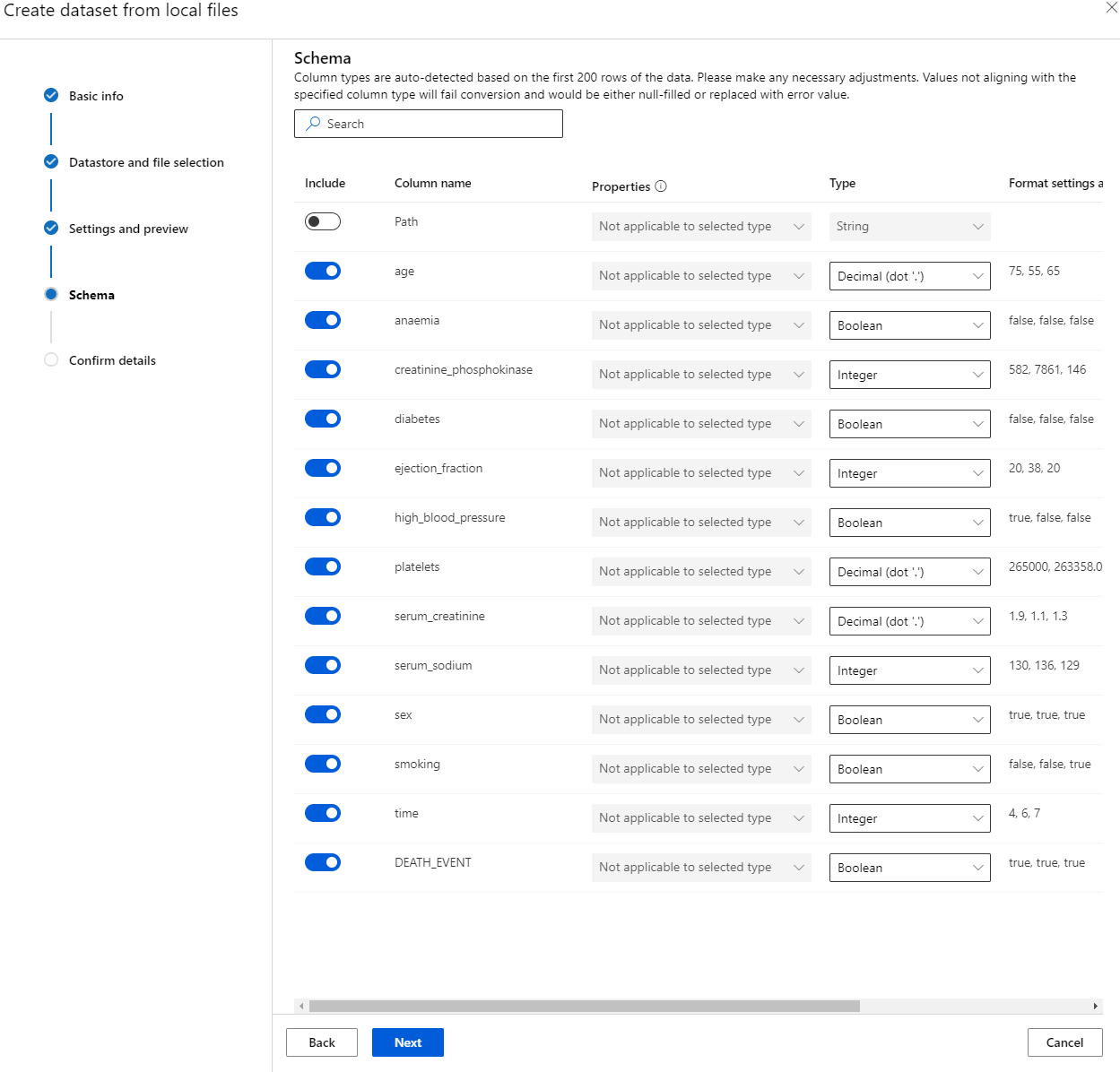
เยี่ยมมาก! ตอนนี้ชุดข้อมูลพร้อมแล้วและ Compute cluster ถูกสร้างขึ้น เราสามารถเริ่มการฝึกโมเดลได้!
2.4 การฝึกโมเดลแบบ Low code/No code ด้วย AutoML
การพัฒนาโมเดลการเรียนรู้ของเครื่องแบบดั้งเดิมใช้ทรัพยากรมาก ต้องการความรู้เฉพาะทางและเวลาในการสร้างและเปรียบเทียบโมเดลหลายๆ ตัว AutoML (Automated Machine Learning) เป็นกระบวนการอัตโนมัติที่ช่วยลดงานที่ใช้เวลานานและซ้ำซากในการพัฒนาโมเดลการเรียนรู้ของเครื่อง มันช่วยให้นักวิทยาศาสตร์ข้อมูล นักวิเคราะห์ และนักพัฒนาสามารถสร้างโมเดล ML ได้อย่างมีประสิทธิภาพและรวดเร็ว โดยยังคงรักษาคุณภาพของโมเดล เรียนรู้เพิ่มเติม
-
ใน Azure ML workspace ที่เราสร้างไว้ก่อนหน้านี้ คลิกที่ "Automated ML" ในเมนูด้านซ้ายและเลือกชุดข้อมูลที่คุณเพิ่งอัปโหลด คลิก Next
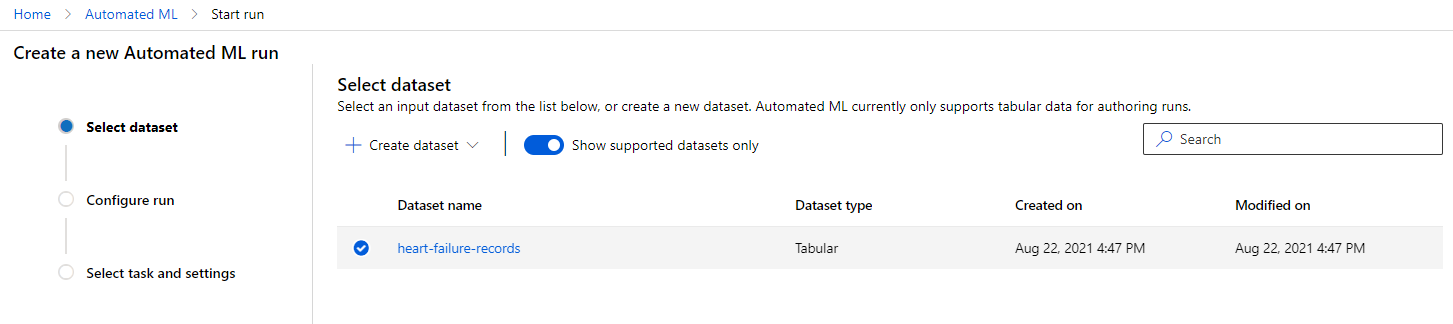
-
ตั้งชื่อการทดลองใหม่ คอลัมน์เป้าหมาย (DEATH_EVENT) และ Compute cluster ที่เราสร้างไว้ คลิก Next
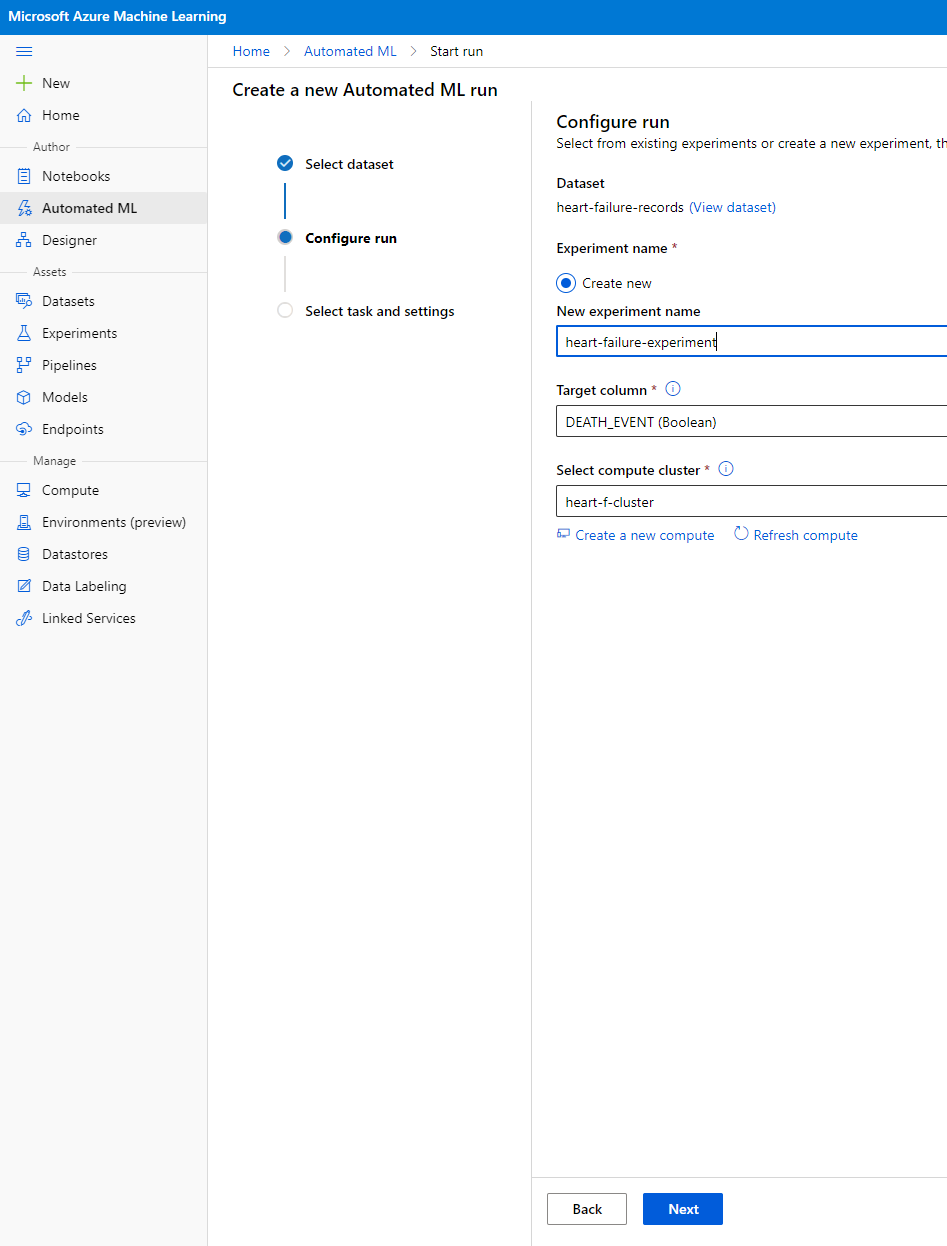
-
เลือก "Classification" และคลิก Finish ขั้นตอนนี้อาจใช้เวลาระหว่าง 30 นาทีถึง 1 ชั่วโมง ขึ้นอยู่กับขนาด Compute cluster ของคุณ
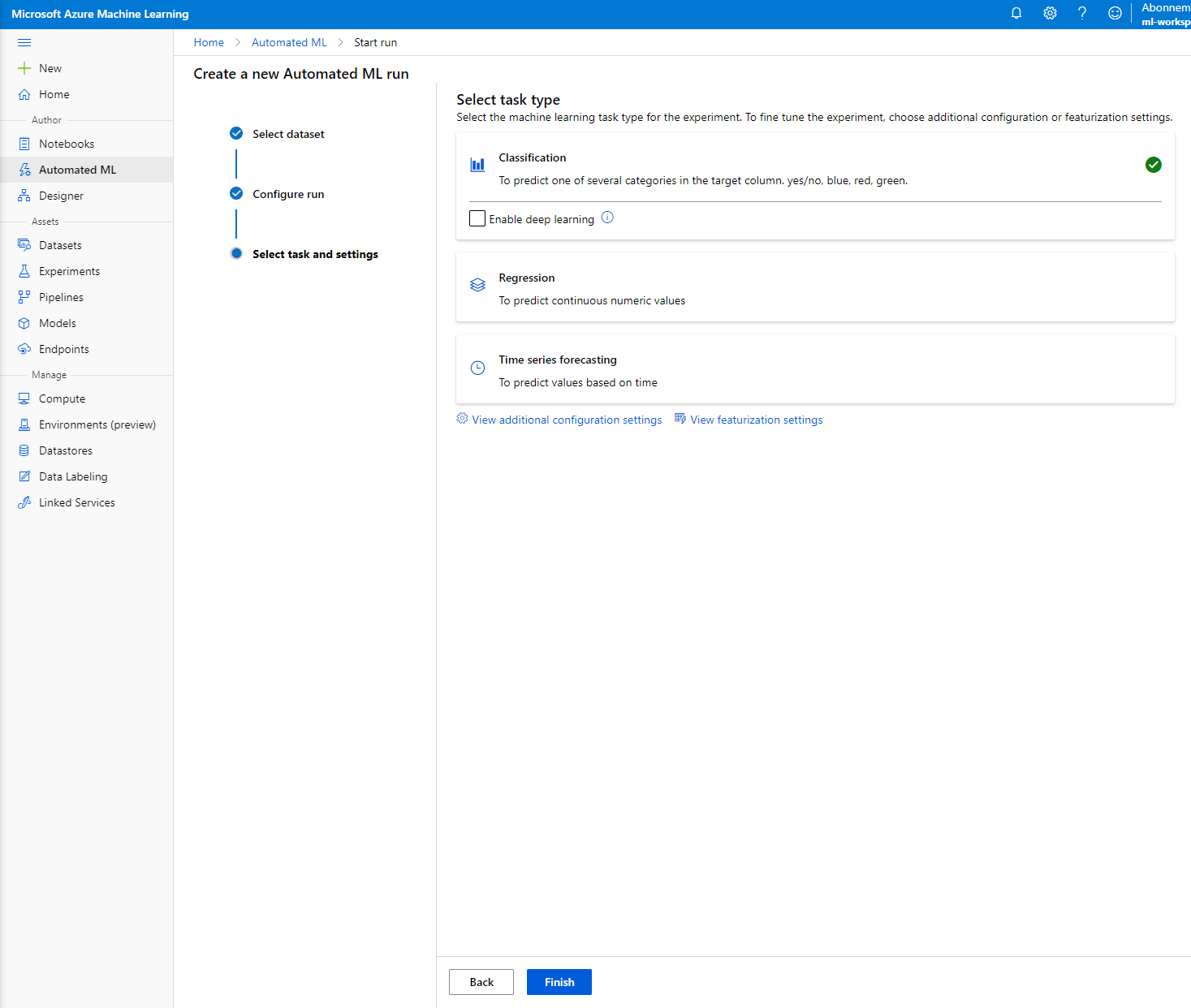
-
เมื่อการรันเสร็จสิ้น คลิกที่แท็บ "Automated ML" คลิกที่การรันของคุณ และคลิกที่อัลกอริทึมในการ์ด "Best model summary"
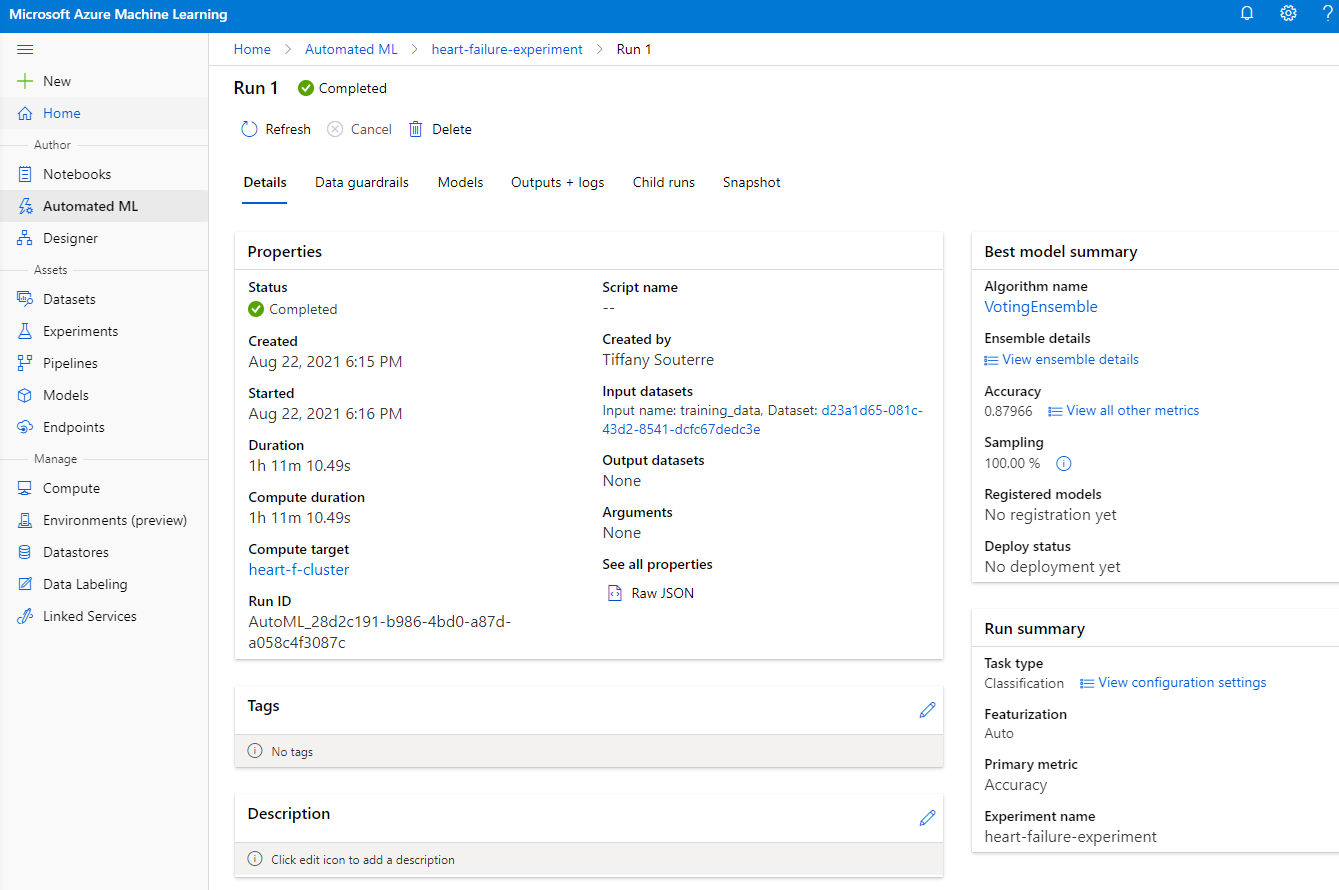
ที่นี่คุณสามารถดูคำอธิบายโดยละเอียดของโมเดลที่ดีที่สุดที่ AutoML สร้างขึ้น คุณยังสามารถสำรวจโมเดลอื่นๆ ที่สร้างขึ้นในแท็บ Models ใช้เวลาสักครู่เพื่อสำรวจโมเดลในปุ่ม Explanations (preview) เมื่อคุณเลือกโมเดลที่ต้องการใช้ (ในที่นี้เราจะเลือกโมเดลที่ดีที่สุดที่ AutoML เลือกไว้) เราจะดูวิธีการนำไปใช้งาน
3. การนำโมเดลไปใช้งานและการบริโภค Endpoint แบบ Low code/No code
3.1 การนำโมเดลไปใช้งาน
อินเทอร์เฟซ AutoML ช่วยให้คุณนำโมเดลที่ดีที่สุดไปใช้งานเป็นบริการเว็บได้ในไม่กี่ขั้นตอน การนำไปใช้งานคือการรวมโมเดลเพื่อให้สามารถทำการพยากรณ์ตามข้อมูลใหม่และระบุพื้นที่ที่มีโอกาส สำหรับโปรเจกต์นี้ การนำไปใช้งานเป็นบริการเว็บหมายความว่าแอปพลิเคชันทางการแพทย์จะสามารถใช้โมเดลเพื่อทำการพยากรณ์สดเกี่ยวกับความเสี่ยงของผู้ป่วยที่จะเกิดโรคหัวใจ
ในคำอธิบายโมเดลที่ดีที่สุด คลิกที่ปุ่ม "Deploy"
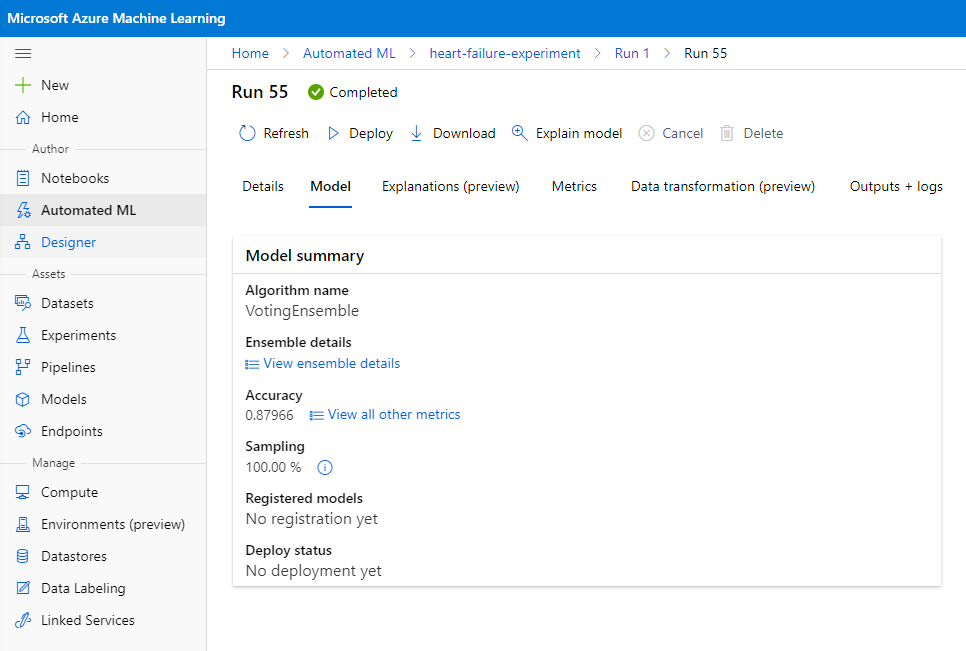
- ตั้งชื่อ คำอธิบาย ประเภท Compute (Azure Container Instance) เปิดใช้งานการตรวจสอบสิทธิ์ และคลิก Deploy ขั้นตอนนี้อาจใช้เวลาประมาณ 20 นาที การนำไปใช้งานประกอบด้วยหลายขั้นตอน รวมถึงการลงทะเบียนโมเดล การสร้างทรัพยากร และการกำหนดค่าทรัพยากรสำหรับบริการเว็บ ข้อความสถานะจะปรากฏใต้ Deploy status เลือก Refresh เป็นระยะเพื่อตรวจสอบสถานะการนำไปใช้งาน เมื่อสถานะเป็น "Healthy" หมายความว่าการนำไปใช้งานเสร็จสมบูรณ์และกำลังทำงาน
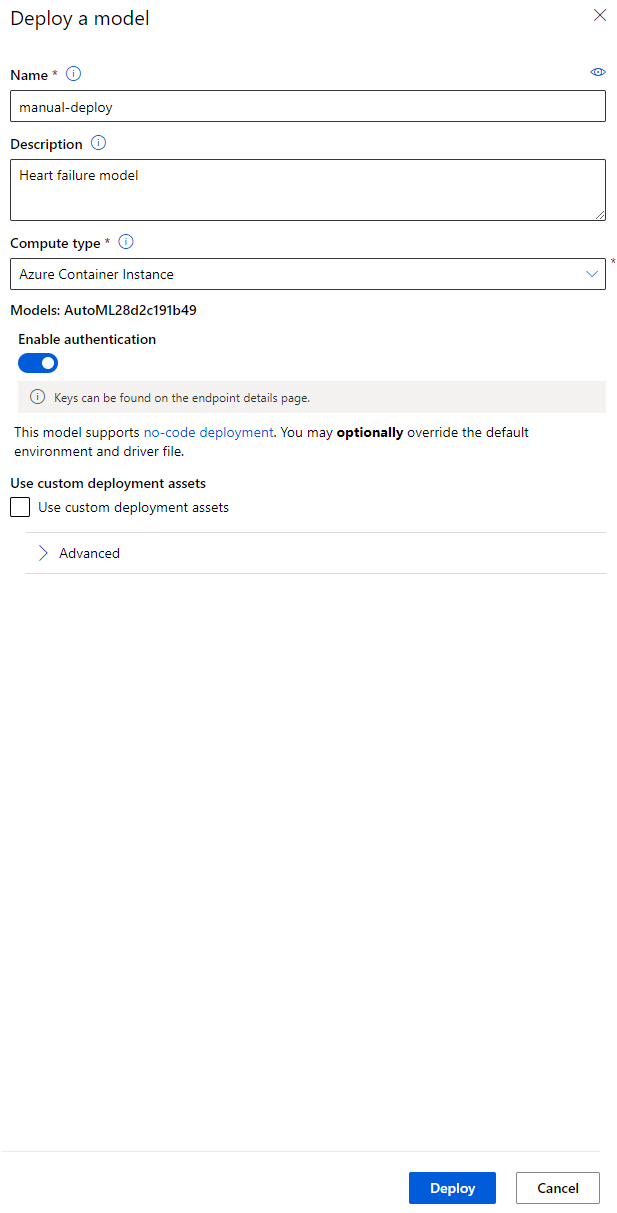
- เมื่อการนำไปใช้งานเสร็จสิ้น คลิกที่แท็บ Endpoint และคลิกที่ Endpoint ที่คุณเพิ่งนำไปใช้งาน คุณสามารถค้นหาข้อมูลทั้งหมดเกี่ยวกับ Endpoint ได้ที่นี่
ยอดเยี่ยม! ตอนนี้เรามีโมเดลที่นำไปใช้งานแล้ว เราสามารถเริ่มการบริโภค Endpoint ได้
3.2 การบริโภค Endpoint
คลิกที่แท็บ "Consume" ที่นี่คุณสามารถค้นหา REST endpoint และสคริปต์ Python ในตัวเลือกการบริโภค ใช้เวลาสักครู่เพื่ออ่านโค้ด Python
สคริปต์นี้สามารถรันได้โดยตรงจากเครื่องของคุณและจะบริโภค Endpoint ของคุณ
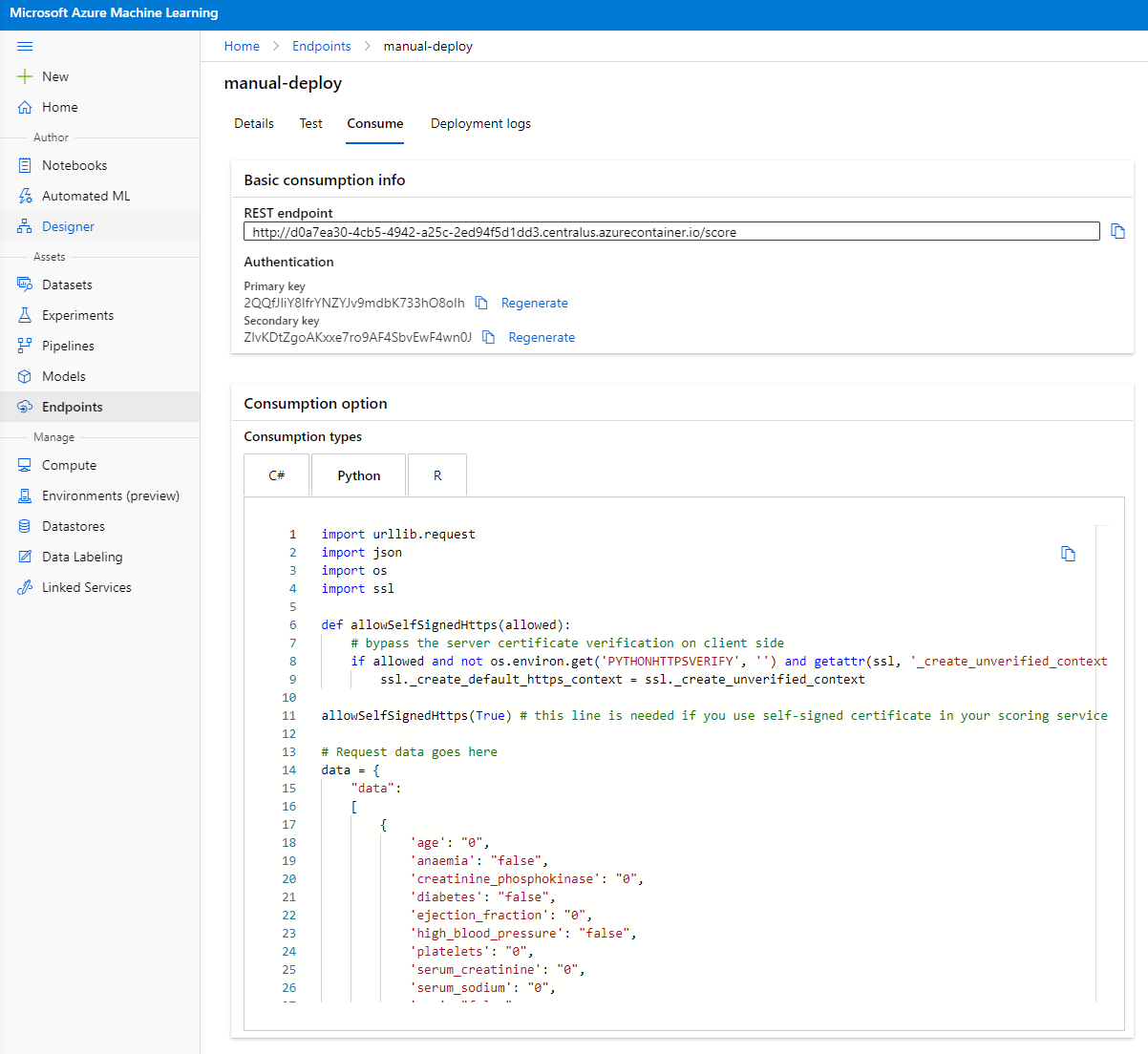
ใช้เวลาสักครู่เพื่อดูสองบรรทัดของโค้ดนี้:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
ตัวแปร url คือ REST endpoint ที่พบในแท็บ Consume และตัวแปร api_key คือคีย์หลักที่พบในแท็บ Consume (เฉพาะในกรณีที่คุณเปิดใช้งานการตรวจสอบสิทธิ์) นี่คือวิธีที่สคริปต์สามารถบริโภค Endpoint ได้
- เมื่อรันสคริปต์ คุณควรเห็นผลลัพธ์ดังนี้:
b'"{\\"result\\": [true]}"'
หมายความว่าการพยากรณ์ความล้มเหลวของหัวใจสำหรับข้อมูลที่ให้ไว้เป็นจริง ซึ่งสมเหตุสมผลเพราะหากคุณดูข้อมูลที่สร้างขึ้นโดยอัตโนมัติในสคริปต์ ทุกอย่างจะเป็น 0 และ false โดยค่าเริ่มต้น คุณสามารถเปลี่ยนข้อมูลด้วยตัวอย่างข้อมูลต่อไปนี้:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
สคริปต์ควรแสดงผลลัพธ์:
python b'"{\\"result\\": [true, false]}"'
ขอแสดงความยินดี! คุณเพิ่งบริโภคโมเดลที่นำไปใช้งานและฝึกฝนบน Azure ML!
หมายเหตุ: เมื่อคุณทำโปรเจกต์เสร็จแล้ว อย่าลืมลบทรัพยากรทั้งหมด
🚀 ความท้าทาย
ดูรายละเอียดคำอธิบายโมเดลและรายละเอียดที่ AutoML สร้างขึ้นสำหรับโมเดลอันดับต้นๆ พยายามทำความเข้าใจว่าทำไมโมเดลที่ดีที่สุดถึงดีกว่าโมเดลอื่นๆ อัลกอริทึมใดที่ถูกเปรียบเทียบ? ความแตกต่างระหว่างพวกมันคืออะไร? ทำไมโมเดลที่ดีที่สุดถึงมีประสิทธิภาพดีกว่าในกรณีนี้?
แบบทดสอบหลังการบรรยาย
การทบทวนและการศึกษาด้วยตนเอง
ในบทเรียนนี้ คุณได้เรียนรู้วิธีการฝึกฝน นำไปใช้งาน และบริโภคโมเดลเพื่อพยากรณ์ความเสี่ยงของหัวใจล้มเหลวในรูปแบบ Low code/No code บนคลาวด์ หากคุณยังไม่ได้ทำ ลองเจาะลึกคำอธิบายโมเดลที่ AutoML สร้างขึ้นสำหรับโมเดลอันดับต้นๆ และพยายามทำความเข้าใจว่าทำไมโมเดลที่ดีที่สุดถึงดีกว่าโมเดลอื่นๆ
คุณสามารถศึกษาต่อเกี่ยวกับ AutoML แบบ Low code/No code ได้โดยอ่าน เอกสารนี้
งานที่ได้รับมอบหมาย
โปรเจกต์ Data Science แบบ Low code/No code บน Azure ML
ข้อจำกัดความรับผิดชอบ:
เอกสารนี้ได้รับการแปลโดยใช้บริการแปลภาษา AI Co-op Translator แม้ว่าเราจะพยายามให้การแปลมีความถูกต้อง แต่โปรดทราบว่าการแปลอัตโนมัติอาจมีข้อผิดพลาดหรือความไม่แม่นยำ เอกสารต้นฉบับในภาษาดั้งเดิมควรถือเป็นแหล่งข้อมูลที่เชื่อถือได้ สำหรับข้อมูลที่สำคัญ แนะนำให้ใช้บริการแปลภาษาจากผู้เชี่ยวชาญ เราไม่รับผิดชอบต่อความเข้าใจผิดหรือการตีความที่ผิดพลาดซึ่งเกิดจากการใช้การแปลนี้