405 KiB
Introduction:收纳技术相关的基础知识 Redis、RocketMQ、Zookeeper、Netty、Tomcat 等总结!
[TOC]
SPI
SPI 全称为 Service Provider Interface,是一种服务发现机制。SPI 的本质是将接口实现类的全限定名,配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类,正因为该特性,我们可以很容易的通过 SPI 机制为程序提供拓展功能。
Java SPI
JDK 中 提供了一个 SPI 的功能,核心类是 java.util.ServiceLoader。其作用就是,可以通过类名获取在 META-INF/services/ 下的多个配置实现文件。为了解决上面的扩展问题,现在我们在META-INF/services/下创建一个com.github.yu120.test.SuperLoggerConfiguration文件(没有后缀)。文件中只有一行代码,那就是我们默认的com.github.yu120.test.XMLConfiguration(注意,一个文件里也可以写多个实现,回车分隔)。然后通过 ServiceLoader 获取我们的 SPI 机制配置的实现类:
// META-INF/services/com.github.test.test.SuperLoggerConfiguration:
com.github.yu120.test.XMLConfiguration
ServiceLoader<SuperLoggerConfiguration> serviceLoader = ServiceLoader.load(SuperLoggerConfiguration.class);
Iterator<SuperLoggerConfiguration> iterator = serviceLoader.iterator();
SuperLoggerConfiguration configuration;
while(iterator.hasNext()) {
// 加载并初始化实现类
configuration = iterator.next();
}
// 对最后一个configuration类调用configure方法
configuration.configure(configFile);
Dubbo SPI
Dubbo SPI 的相关逻辑被封装在了 ExtensionLoader类中,它的getExtensionLoader方法用于从缓存中获取与接口对应的ExtensionLoader,若缓存未命中,则创建一个新的实例。Dubbo SPI的核心思想其实很简单:
- 通过配置文件,解耦拓展接口和拓展实现类
- 通过IOC自动注入依赖的拓展实现类对象
- 通过URL参数,在运行时确认真正的自定义拓展类对象
Dubbo SPI 所需的配置文件需放置在 META-INF/dubbo 路径下,配置内容如下(以下demo来自dubbo官方文档)。
optimusPrime = org.apache.spi.OptimusPrime
bumblebee = org.apache.spi.Bumblebee
与 Java SPI 实现类配置不同,Dubbo SPI 是通过键值对的方式进行配置,这样我们可以按需加载指定的实现类。另外在使用时还需要在接口上标注 @SPI 注解。
Motan SPI
Motan使用SPI机制来实现模块间的访问,基于接口和name来获取实现类,降低了模块间的耦合。
Motan的SPI的实现在 motan-core/com/weibo/api/motan/core/extension 中。组织结构如下:
motan-core/com.weibo.api.motan.core.extension
|-Activation:SPI的扩展功能,例如过滤、排序
|-ActivationComparator:排序比较器
|-ExtensionLoader:核心,主要负责SPI的扫描和加载
|-Scope:模式枚举,单例、多例
|-Spi:注解,作用在接口上,表明这个接口的实现可以通过SPI的形式加载
|-SpiMeta:注解,作用在具体的SPI接口的实现类上,标注该扩展的名称
SpringBoot SPI
Spring 的 SPI 配置文件是一个固定的文件 - META-INF/spring.factories,功能上和 JDK 的类似,每个接口可以有多个扩展实现,使用起来非常简单:
// 获取所有factories文件中配置的LoggingSystemFactory
List<LoggingSystemFactory>> factories = SpringFactoriesLoader.loadFactories(LoggingSystemFactory.class, classLoader);
下面是一段 Spring Boot 中 spring.factories 的配置
# Logging Systems
org.springframework.boot.logging.LoggingSystemFactory=\
org.springframework.boot.logging.logback.LogbackLoggingSystem.Factory,\
org.springframework.boot.logging.log4j2.Log4J2LoggingSystem.Factory
# PropertySource Loaders
org.springframework.boot.env.PropertySourceLoader=\
org.springframework.boot.env.PropertiesPropertySourceLoader,\
org.springframework.boot.env.YamlPropertySourceLoader
Redis
Java类型所占字节数(或bit数)
| 类型 | 存储(byte) | bit数(bit) | 取值范围 |
|---|---|---|---|
| int | 4字节 | 4×8位 | 即 (-2)的31次方 ~ (2的31次方) - 1 |
| short | 2字节 | 2×8位 | 即 (-2)的15次方 ~ (2的15次方) - 1 |
| long | 8字节 | 8×8位 | 即 (-2)的63次方 ~ (2的63次方) - 1 |
| byte | 1字节 | 1×8位 | 即 (-2)的7次方 ~ (2的7次方) - 1,-128~127 |
| float | 4字节 | 4×8位 | float 类型的数值有一个后缀 F(例如:3.14F) |
| double | 8字节 | 8×8位 | 没有后缀 F 的浮点数值(例如:3.14)默认为 double |
| boolean | 1字节 | 1×8位 | true、false |
| char | 2字节 | 2×8位 | Java中,只要是字符,不管是数字还是英文还是汉字,都占两个字节 |
注意:
- 英文的数字、字母或符号:1个字符 = 1个字节数
- 中文的数字、字母或符号:1个字符 = 2个字节数
- 计算机的基本单位:bit 。一个bit代表一个0或1,1个字节是8个bit
- 1TB=1024GB,1GB=1024MB,1MB=1024KB,1KB=1024B(字节,byte),1B=8b(bit,位)
线程模型
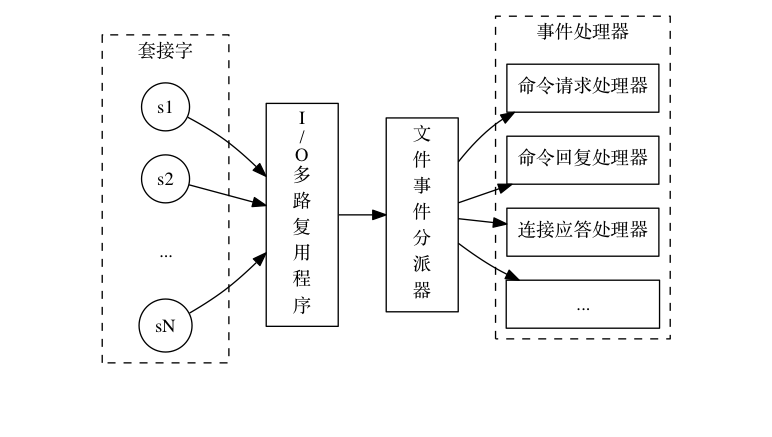
Redis内部使用文件事件处理器File Event Handler,这个文件事件处理器是单线程的所以Redis才叫做单线程的模型。它采用I/O多路复用机制同时监听多个Socket,将产生事件的Socket压入到内存队列中,事件分派器根据Socket上的事件类型来选择对应的事件处理器来进行处理。文件事件处理器包含5个部分:
- 多个Socket
- I/O多路复用程序
- Scocket队列
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
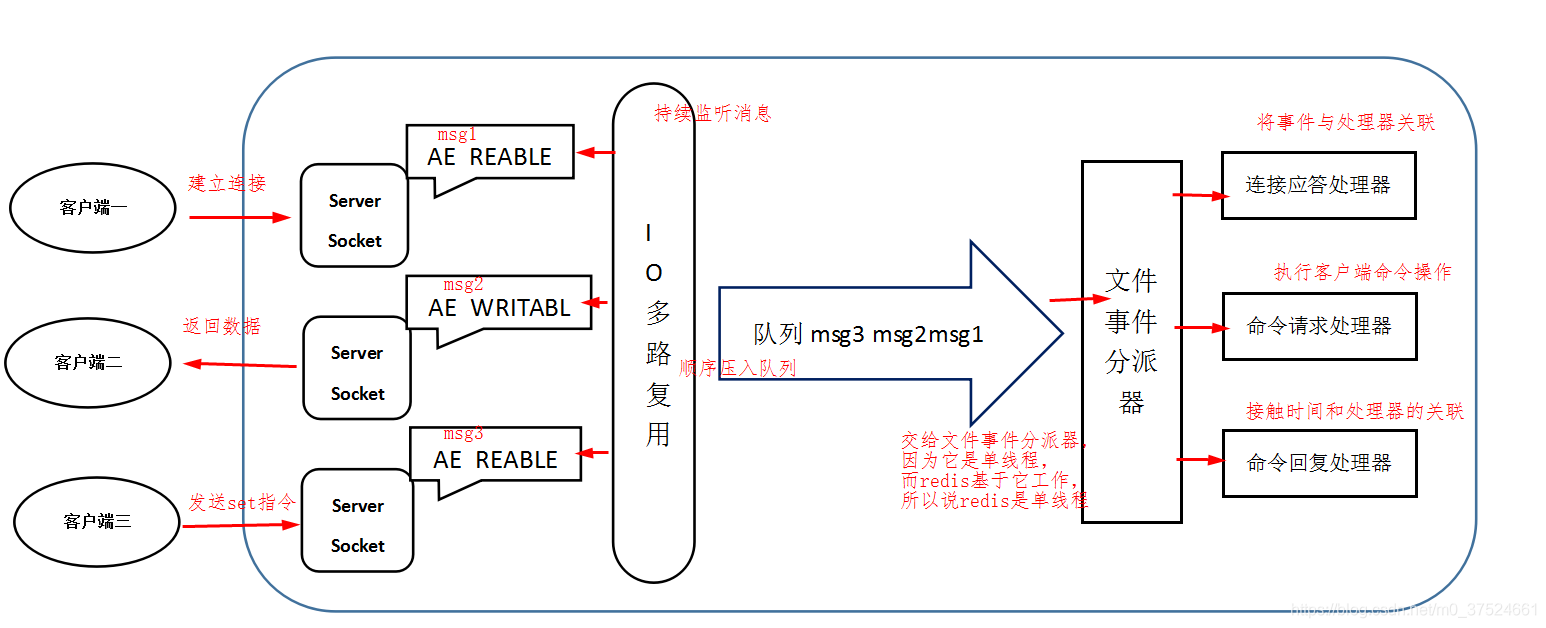
通信流程
客户端与redis的一次通信过程:
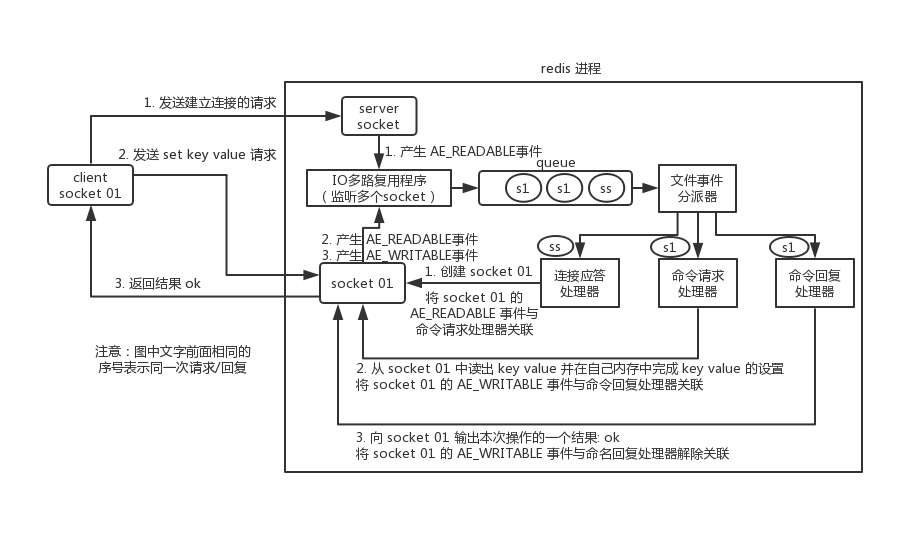
-
请求类型1:
客户端发起建立连接的请求- 服务端会产生一个
AE_READABLE事件,I/O多路复用程序接收到server socket事件后,将该socket压入队列中 - 文件事件分派器从队列中获取
socket,交给连接应答处理器,创建一个可以和客户端交流的socket01 - 将
socket01的AE_READABLE事件与命令请求处理器关联
- 服务端会产生一个
-
请求类型2:
客户端发起set key value请求socket01产生AE_READABLE事件,socket01压入队列- 将获取到的
socket01与命令请求处理器关联 - 命令请求处理器读取
socket01中的key value,并在内存中完成对应的设置 - 将
socket01的AE_WRITABLE事件与命令回复处理器关联
-
请求类型3:
服务端返回结果Redis中的socket01会产生一个AE_WRITABLE事件,压入到队列中- 将获取到的
socket01与命令回复处理器关联 - 回复处理器对
socket01输入操作结果,如ok。之后解除socket01的AE_WRITABLE事件与命令回复处理器的关联
文件事件处理器
- 基于 Reactor 模式开发了自己的网络事件处理器(文件事件处理器,file event handler)
- 文件事件处理器 使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时, 与操作相对应的文件事件就会产生, 这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件
- 文件事件处理器以单线程方式运行, 但通过使用 I/O 多路复用程序来监听多个套接字, 文件事件处理器既实现了高性能的网络通信模型, 又可以很好地与 redis 服务器中其他同样以单线程方式运行的模块进行对接, 这保持了 Redis 内部单线程设计的简单性
I/O多路复用
I/O多路复用的I/O是指网络I/O,多路指多个TCP连接(即socket或者channel),复用指复用一个或几个线程。意思说一个或一组线程处理多个TCP连接。最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程。 I/O多路复用使用两个系统调用(select/poll/epoll和recvfrom),blocking I/O只调用了recvfrom;select/poll/epoll 核心是可以同时处理多个connection,而不是更快,所以连接数不高的话,性能不一定比多线程+阻塞I/O好,多路复用模型中,每一个socket,设置为non-blocking,阻塞是被select这个函数block,而不是被socket阻塞的。
select机制 基本原理 客户端操作服务器时就会产生这三种文件描述符(简称fd):writefds(写)、readfds(读)、和exceptfds(异常)。select会阻塞住监视3类文件描述符,等有数据、可读、可写、出异常 或超时、就会返回;返回后通过遍历fdset整个数组来找到就绪的描述符fd,然后进行对应的I/O操作。 优点
- 几乎在所有的平台上支持,跨平台支持性好
缺点
- 由于是采用轮询方式全盘扫描,会随着文件描述符FD数量增多而性能下降
- 每次调用 select(),需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)
- 默认单个进程打开的FD有限制是1024个,可修改宏定义,但是效率仍然慢。
poll机制 基本原理与select一致,也是轮询+遍历;唯一的区别就是poll没有最大文件描述符限制(使用链表的方式存储fd)。
epoll机制 基本原理 没有fd个数限制,用户态拷贝到内核态只需要一次,使用时间通知机制来触发。通过epoll_ctl注册fd,一旦fd就绪就会通过callback回调机制来激活对应fd,进行相关的io操作。epoll之所以高性能是得益于它的三个函数:
epoll_create():系统启动时,在Linux内核里面申请一个B+树结构文件系统,返回epoll对象,也是一个fdepoll_ctl():每新建一个连接,都通过该函数操作epoll对象,在这个对象里面修改添加删除对应的链接fd, 绑定一个callback函数epoll_wait():轮训所有的callback集合,并完成对应的IO操作
优点
- 没fd这个限制,所支持的FD上限是操作系统的最大文件句柄数,1G内存大概支持10万个句柄
- 效率提高,使用回调通知而不是轮询的方式,不会随着FD数目的增加效率下降
- 内核和用户空间mmap同一块内存实现(mmap是一种内存映射文件方法,即将一个文件或其它对象映射到进程的地址空间)
例子:100万个连接,里面有1万个连接是活跃,我们可以对比 select、poll、epoll 的性能表现:
select:不修改宏定义默认是1024,则需要100w/1024=977个进程才可以支持 100万连接,会使得CPU性能特别的差poll: 没有最大文件描述符限制,100万个链接则需要100w个fd,遍历都响应不过来了,还有空间的拷贝消耗大量资源epoll: 请求进来时就创建fd并绑定一个callback,主需要遍历1w个活跃连接的callback即可,即高效又不用内存拷贝
执行效率高
Redis是单线程模型为什么效率还这么高?
纯内存操作:数据存放在内存中,内存的响应时间大约是100纳秒,这是Redis每秒万亿级别访问的重要基础非阻塞的I/O多路复用机制:Redis采用epoll做为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为了时间,不在I/O上浪费过多的时间C语言实现:距离操作系统更近,执行速度会更快单线程避免切换开销:单线程避免了多线程上下文切换的时间开销,预防了多线程可能产生的竞争问题
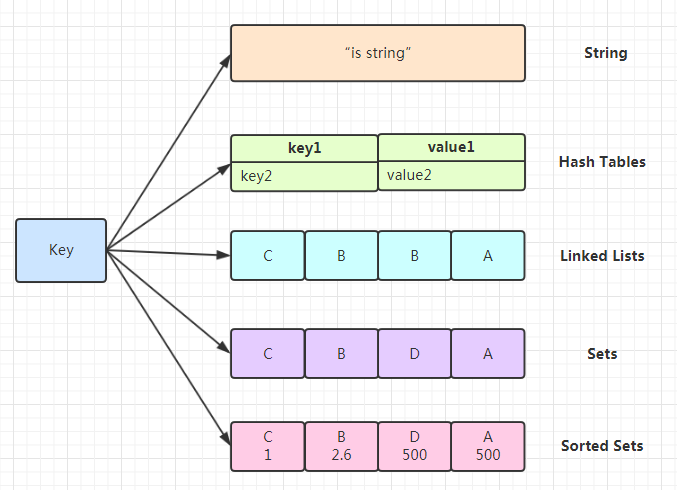
数据类型
在 Redis 中,常用的 5 种数据类型和应用场景如下:
- String: 缓存、计数器、分布式锁等
- List: 链表、队列、微博关注人时间轴列表等
- Hash: 用户信息、Hash 表等
- Set: 去重、赞、踩、共同好友等
- Zset: 访问量排行榜、点击量排行榜等
String(字符串)
String 数据结构是简单的 key-value 类型,value 不仅可以是 String,也可以是数字(当数字类型用 Long 可以表示的时候encoding 就是整型,其他都存储在 sdshdr 当做字符串)。
Hash(字典)
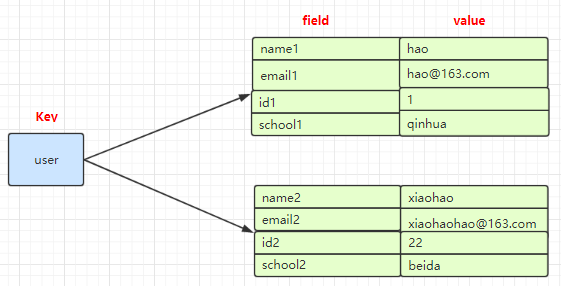
在 Memcached 中,我们经常将一些结构化的信息打包成 hashmap,在客户端序列化后存储为一个字符串的值(一般是 JSON 格式),比如用户的昵称、年龄、性别、积分等。这时候在需要修改其中某一项时,通常需要将字符串(JSON)取出来,然后进行反序列化,修改某一项的值,再序列化成字符串(JSON)存储回去。简单修改一个属性就干这么多事情,消耗必定是很大的,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分)。而 Redis 的 Hash 结构可以使你像在数据库中 Update 一个属性一样只修改某一项属性值。
- 存储、读取、修改用户属性
实战场景
- 缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力
- 计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源
- session:常见方案spring session + redis实现session共享
List(列表)
List 说白了就是链表(redis 使用双端链表实现的 List),相信学过数据结构知识的人都应该能理解其结构。使用 List 结构,我们可以轻松地实现最新消息排行等功能(比如新浪微博的 TimeLine )。List 的另一个应用就是消息队列,可以利用 List 的 *PUSH 操作,将任务存在 List 中,然后工作线程再用 POP 操作将任务取出进行执行。Redis 还提供了操作 List 中某一段元素的 API,你可以直接查询,删除 List 中某一段的元素。
- 微博 TimeLine
- 消息队列
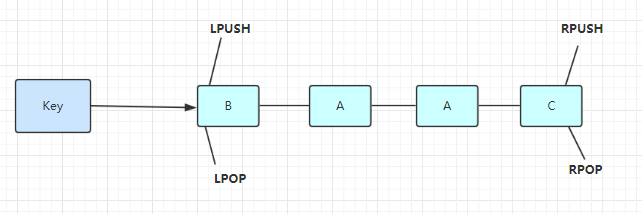
使用列表的技巧
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
实战场景:
- timeline:例如微博的时间轴,有人发布微博,用lpush加入时间轴,展示新的列表信息。
Set(集合)
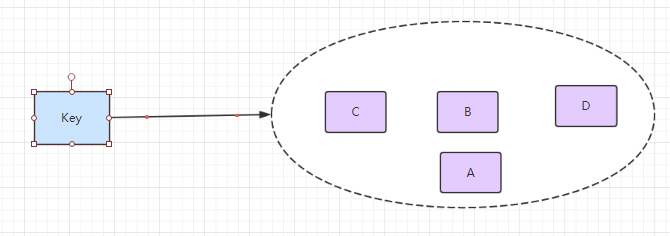
Set 就是一个集合,集合的概念就是一堆不重复值的组合。利用 Redis 提供的 Set 数据结构,可以存储一些集合性的数据。比如在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。因为 Redis 非常人性化的为集合提供了求交集、并集、差集等操作,那么就可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
- 共同好友、二度好友
- 利用唯一性,可以统计访问网站的所有独立 IP
- 好友推荐的时候,根据 tag 求交集,大于某个 threshold 就可以推荐
实战场景;
- 标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人
- 点赞,或点踩,收藏等,可以放到set中实现
Sorted Set(有序集合)
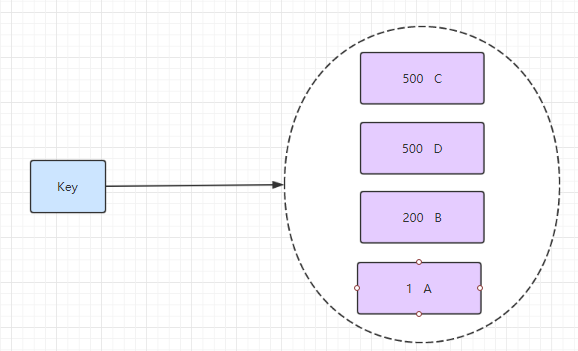
和Sets相比,Sorted Sets是将 Set 中的元素增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,比如一个存储全班同学成绩的 Sorted Sets,其集合 value 可以是同学的学号,而 score 就可以是其考试得分,这样在数据插入集合的时候,就已经进行了天然的排序。另外还可以用 Sorted Sets 来做带权重的队列,比如普通消息的 score 为1,重要消息的 score 为2,然后工作线程可以选择按 score 的倒序来获取工作任务。让重要的任务优先执行。
- 带有权重的元素,比如一个游戏的用户得分排行榜
- 比较复杂的数据结构,一般用到的场景不算太多
实战场景:
- 排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
特殊数据结构
HyperLogLog(基数统计)
HyperLogLog 主要的应用场景就是进行基数统计。实际上不会存储每个元素的值,它使用的是概率算法,通过存储元素的hash值的第一个1的位置,来计算元素数量。HyperLogLog 可用极小空间完成独立数统计。命令如下:
| 命令 | 作用 |
|---|---|
| pfadd key element ... | 将所有元素添加到key中 |
| pfcount key | 统计key的估算值(不精确) |
| pgmerge new_key key1 key2 ... | 合并key至新key |
应用案例
如何统计 Google 主页面每天被多少个不同的账户访问过?
对于 Google 这种访问量巨大的网页而言,其实统计出有十亿的访问量或十亿零十万的访问量其实是没有太多的区别的,因此,在这种业务场景下,为了节省成本,其实可以只计算出一个大概的值,而没有必要计算出精准的值。
对于上面的场景,可以使用HashMap、BitMap和HyperLogLog来解决。对于这三种解决方案,这边做下对比:
HashMap:算法简单,统计精度高,对于少量数据建议使用,但是对于大量的数据会占用很大内存空间BitMap:位图算法,具体内容可以参考我的这篇,统计精度高,虽然内存占用要比HashMap少,但是对于大量数据还是会占用较大内存HyperLogLog:存在一定误差,占用内存少,稳定占用 12k 左右内存,可以统计 2^64 个元素,对于上面举例的应用场景,建议使用
Geo(地理空间信息)
Geo主要用于存储地理位置信息,并对存储的信息进行操作(添加、获取、计算两位置之间距离、获取指定范围内位置集合、获取某地点指定范围内集合)。Redis支持将Geo信息存储到有序集合(zset)中,再通过Geohash算法进行填充。命令如下:
| 命令 | 作用 |
|---|---|
| geoadd key latitude longitude member | 添加成员位置(纬度、经度、名称)到key中 |
| geopos key member ... | 获取成员geo坐标 |
| geodist key member1 member2 [unit] | 计算成员位置间距离。若两个位置之间的其中一个不存在, 那返回空值 |
| georadius | 基于经纬度坐标范围查询 |
| georadiusbymember | 基于成员位置范围查询 |
| geohash | 计算经纬度hash |
GEORADIUS
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count]
以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。范围可以使用以下其中一个单位:
- m 表示单位为米
- km 表示单位为千米
- mi 表示单位为英里
- ft 表示单位为英尺
在给定以下可选项时, 命令会返回额外的信息:
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离单位和范围单位保持一致WITHCOORD: 将位置元素的经度和维度也一并返回WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大
命令默认返回未排序的位置元素。 通过以下两个参数, 用户可以指定被返回位置元素的排序方式:
ASC: 根据中心的位置, 按照从近到远的方式返回位置元素DESC: 根据中心的位置, 按照从远到近的方式返回位置元素
在默认情况下, GEORADIUS 命令会返回所有匹配的位置元素。 虽然用户可以使用 COUNT <count> 选项去获取前 N 个匹配元素, 但是因为命令在内部可能会需要对所有被匹配的元素进行处理, 所以在对一个非常大的区域进行搜索时, 即使只使用 COUNT 选项去获取少量元素, 命令的执行速度也可能会非常慢。 但是从另一方面来说, 使用 COUNT 选项去减少需要返回的元素数量, 对于减少带宽来说仍然是非常有用的。
Pub/Sub(发布订阅)
发布订阅类似于广播功能。redis发布订阅包括 发布者、订阅者、Channel。常用命令如下:
| 命令 | 作用 | 时间复杂度 |
|---|---|---|
| subscribe channel | 订阅一个频道 | O(n) |
| unsubscribe channel ... | 退订一个/多个频道 | O(n) |
| publish channel msg | 将信息发送到指定的频道 | O(n+m),n 是频道 channel 的订阅者数量, M 是使用模式订阅(subscribed patterns)的客户端的数量 |
| pubsub CHANNELS | 查看订阅与发布系统状态(多种子模式) | O(n) |
| psubscribe | 订阅多个频道 | O(n) |
| unsubscribe | 退订多个频道 | O(n) |
Bitmap(位图)
Bitmap就是位图,其实也就是字节数组(byte array),用一串连续的2进制数字(0或1)表示,每一位所在的位置为偏移(offset),位图就是用每一个二进制位来存放或者标记某个元素对应的值。通常是用来判断某个数据存不存在的,因为是用bit为单位来存储所以Bitmap本身会极大的节省储存空间。常用命令如下:
| 命令 | 作用 | 时间复杂度 |
|---|---|---|
| setbit key offset val | 给指定key的值的第offset赋值val | O(1) |
| getbit key offset | 获取指定key的第offset位 | O(1) |
| bitcount key start end | 返回指定key中[start,end]中为1的数量 | O(n) |
| bitop operation destkey key | 对不同的二进制存储数据进行位运算(AND、OR、NOT、XOR) | O(n) |
应用案例
有1亿用户,5千万登陆用户,那么统计每日用户的登录数。每一位标识一个用户ID,当某个用户访问我们的网站就在Bitmap中把标识此用户的位设置为1。使用set集合和Bitmap存储的对比:
| 数据类型 | 每个 userid 占用空间 | 需要存储的用户量 | 全部占用内存量 |
|---|---|---|---|
| set | 32位也就是4个字节(假设userid用的是整型,实际很多网站用的是长整型) | 50,000,000 | 32位 * 50,000,000 = 200 MB |
| Bitmap | 1 位(bit) | 100,000,000 | 1 位 * 100,000,000 = 12.5 MB |
应用场景
- 用户在线状态
- 用户签到状态
- 统计独立用户
BloomFilter(布隆过滤)
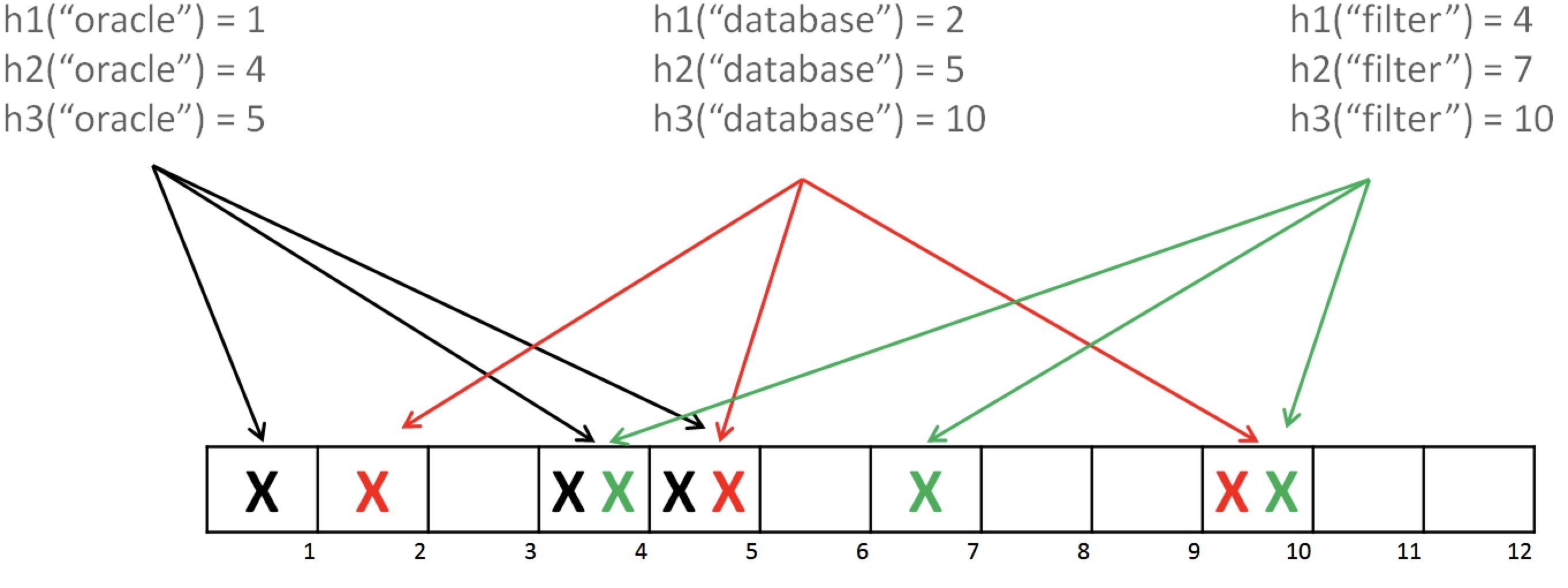
当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点(使用多个哈希函数对元素key (bloom中不存value) 进行哈希,算出一个整数索引值,然后对位数组长度进行取模运算得到一个位置,每个无偏哈希函数都会得到一个不同的位置),把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:
- 如果这些点有任何一个为0,则被检元素一定不在
- 如果都是1,并不能完全说明这个元素就一定存在其中,有可能这些位置为1是因为其他元素的存在,这就是布隆过滤器会出现误判的原因
应用场景
- 解决缓存穿透:事先把存在的key都放到redis的Bloom Filter 中,他的用途就是存在性检测,如果 BloomFilter 中不存在,那么数据一定不存在;如果 BloomFilter 中存在,实际数据也有可能会不存
- 黑名单校验:假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。把所有黑名单都放在布隆过滤器中,再收到邮件时,判断邮件地址是否在布隆过滤器中即可
- Web拦截器:用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中,从而提高缓存命中率
基于Bitmap数据结构
import com.google.common.base.Preconditions;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.Collection;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@Service
public class RedisService {
@Resource
private RedisTemplate<String, Object> redisTemplate;
/**
* 根据给定的布隆过滤器添加值
*/
public <T> void addByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public <T> boolean includeByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}
基于RedisBloom模块
RedisBloom模块提供了四种数据类型:
- Bloom Filter (布隆过滤器)
- Cuckoo Filter(布谷鸟过滤器)
- Count-Mins-Sketch
- Top-K
Bloom Filter 和 Cuckoo 用于确定(以给定的确定性)集合中是否存在某项。使用 Count-Min Sketch 来估算子线性空间中的项目数,使用 Top-K 维护K个最频繁项目的列表。
# 1.git 下载
[root@test ~]# git clone https://github.com/RedisBloom/RedisBloom.git
[root@test ~]# cd redisbloom
[root@test ~]# make
# 2.wget 下载
[root@test ~]# wget https://github.com/RedisBloom/RedisBloom/archive/v2.0.3.tar.gz
[root@test ~]# tar -zxvf RedisBloom-2.0.3.tar.gz
[root@test ~]# cd RedisBloom-2.0.3/
[root@test ~]# make
# 3.修改Redis Conf
[root@test ~]#vim /etc/redis.conf
# 在文件中添加下行
loadmodule /root/RedisBloom-2.0.3/redisbloom.so
# 4.启动Redis server
[root@test ~]# /redis-server /etc/redis.conf
# 或者启动服务时加载os文件
[root@test ~]# /redis-server /etc/redis.conf --loadmodule /root/RedisBloom/redisbloom.so
# 5.测试RedisBloom
[root@test ~]# redis-cli
127.0.0.1:6379> bf.add bloomFilter foo
127.0.0.1:6379> bf.exists bloomFilter foo
127.0.0.1:6379> cf.add cuckooFilter foo
127.0.0.1:6379> cf.exists cuckooFilter foo
底层数据结构
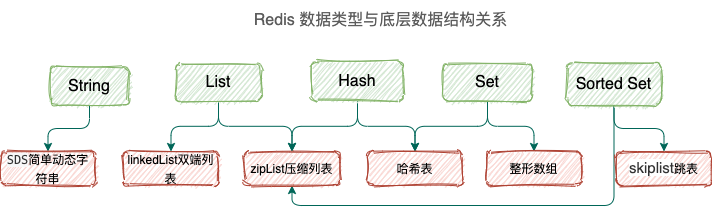
当然是为了追求速度,不同数据类型使用不同的数据结构速度才得以提升。每种数据类型都有一种或者多种数据结构来支撑,底层数据结构有 6 种。
SDS(简单动态字符)
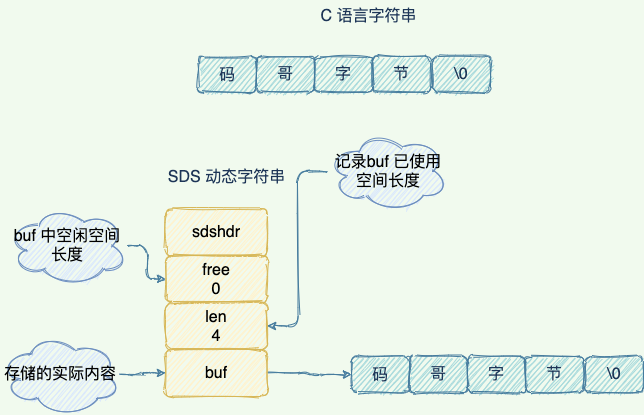
C 语言字符串结构与 SDS 字符串结构对比图如上所示:
- SDS 中 len 保存这字符串的长度,O(1) 时间复杂度查询字符串长度信息
- 空间预分配:SDS 被修改后,程序不仅会为 SDS 分配所需要的必须空间,还会分配额外的未使用空间
- 惰性空间释放:当对 SDS 进行缩短操作时,程序并不会回收多余的内存空间,而是使用 free 字段将这些字节数量记录下来不释放,后面如果需要 append 操作,则直接使用 free 中未使用的空间,减少了内存的分配
hash表(字典)
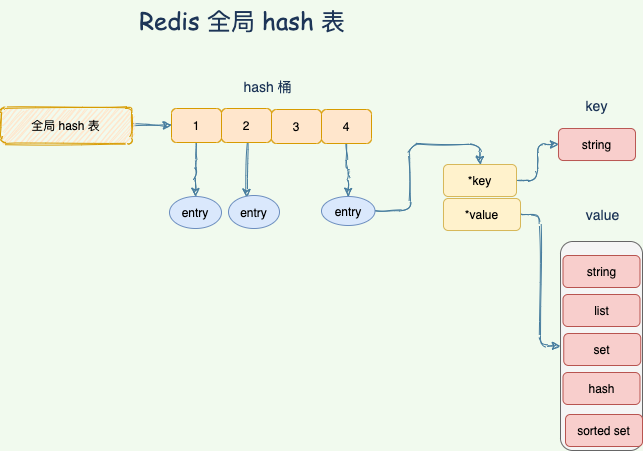
Redis 整体就是一个 哈希表来保存所有的键值对,无论数据类型是 5 种的任意一种。哈希表,本质就是一个数组,每个元素被叫做哈希桶,不管什么数据类型,每个桶里面的 entry 保存着实际具体值的指针。
整个数据库就是一个全局哈希表,而哈希表的时间复杂度是 O(1),只需要计算每个键的哈希值,便知道对应的哈希桶位置,定位桶里面的 entry 找到对应数据,这个也是 Redis 快的原因之一。
那 Hash 冲突怎么办?
当写入 Redis 的数据越来越多的时候,哈希冲突不可避免,会出现不同的 key 计算出一样的哈希值。Redis 通过链式哈希解决冲突:也就是同一个 桶里面的元素使用链表保存。但是当链表过长就会导致查找性能变差可能,所以 Redis 为了追求快,使用了两个全局哈希表。用于 rehash 操作,增加现有的哈希桶数量,减少哈希冲突。开始默认使用 hash 表 1 保存键值对数据,哈希表 2 此刻没有分配空间。
linkedList(双端列表)
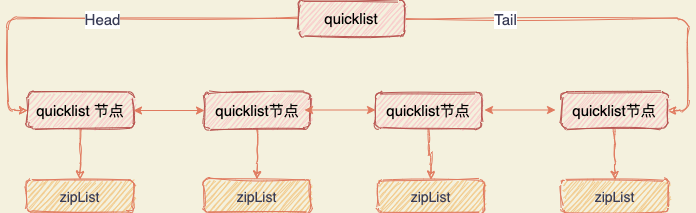
后续版本对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist。quicklist 是 ziplist 和 linkedlist 的混合体,它将 linkedlist 按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来。这也是为何 Redis 快的原因,不放过任何一个可以提升性能的细节。
zipList(压缩列表)

压缩列表是 List 、hash、 sorted Set 三种数据类型底层实现之一。当一个列表只有少量数据的时候,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么 Redis 就会使用压缩列表来做列表键的底层实现。
ziplist 是由一系列特殊编码的连续内存块组成的顺序型的数据结构,ziplist 中可以包含多个 entry 节点,每个节点可以存放整数或者字符串。ziplist 在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表占用字节数、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。
struct ziplist<T> {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N)。
skipList(跳跃表)
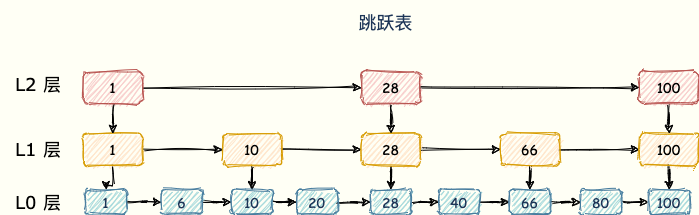
sorted set 类型的排序功能便是通过「跳跃列表」数据结构来实现。跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均 O(logN)、最坏 O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。跳表在链表的基础上,增加了多层级索引,通过索引位置的几个跳转,实现数据的快速定位。
intset(整数数组)
当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis 就会使用整数集合作为集合键的底层实现,节省内存。结构如下:
typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}intset;
contents 数组是整数集合的底层实现:整数集合的每个元素都是 contents 数组的一个数组项(item),各个项在数组中按值的大小从小到大有序地排列,并且数组中不包含任何重复项。length 属性记录了整数集合包含的元素数量,也即是 contents 数组的长度。
持久化机制
通常来说,应该同时使用两种持久化方案,以保证数据安全:
- 如果数据不敏感,且可以从其他地方重新生成,可以关闭持久化
- 如果数据比较重要,且能够承受几分钟的数据丢失,比如缓存等,只需要使用RDB即可
- 如果是用做内存数据,要使用Redis的持久化,建议是RDB和AOF都开启
- 如果只用AOF,优先使用everysec的配置选择,因为它在可靠性和性能之间取了一个平衡
当RDB与AOF两种方式都开启时,Redis会优先使用AOF恢复数据,因为AOF保存的文件比RDB文件更完整
RDB模式(内存快照)
RDB(Redis Database Backup File,Redis数据备份文件)持久化方式:是指用数据集快照的方式半持久化模式记录 Redis 数据库的所有键值对,在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点
- RDB快照是一个压缩过的非常紧凑的文件。保存着某个时间点的数据集,适合做数据的备份,灾难恢复
- 可最大化Redis的的性能。在保存RDB文件,服务器进程只需要fork一个子进程来完成RDB文件创建,父进程不需要做IO操作
- 与AOF相比,恢复大数据集的时候会更快
缺点
- RDB的数据安全性是不如AOF的,保存整个数据集的过程是比繁重的,根据配置可能要几分钟才快照一次,如果服务器宕机,那么就可能丢失几分钟的数据
- Redis数据集较大时,fork的子进程要完成快照会比较耗CPU、耗时
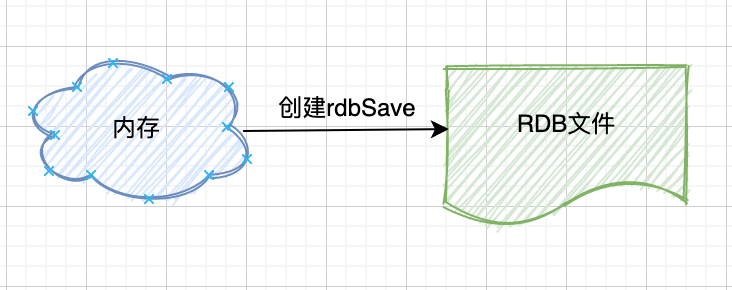
① 创建
当 Redis 持久化时,程序会将当前内存中的数据库状态保存到磁盘中。创建 RDB 文件主要有两个 Redis 命令:SAVE 和 BGSAVE。
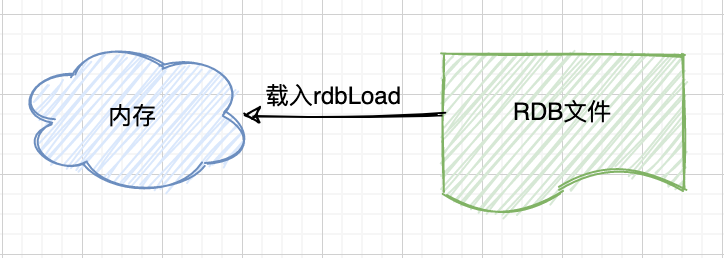
② 载入
服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
save同步保存
save 命令是同步操作,执行命令时,会 阻塞 Redis 服务器进程,拒绝客户端发送的命令请求。
具体流程如下:
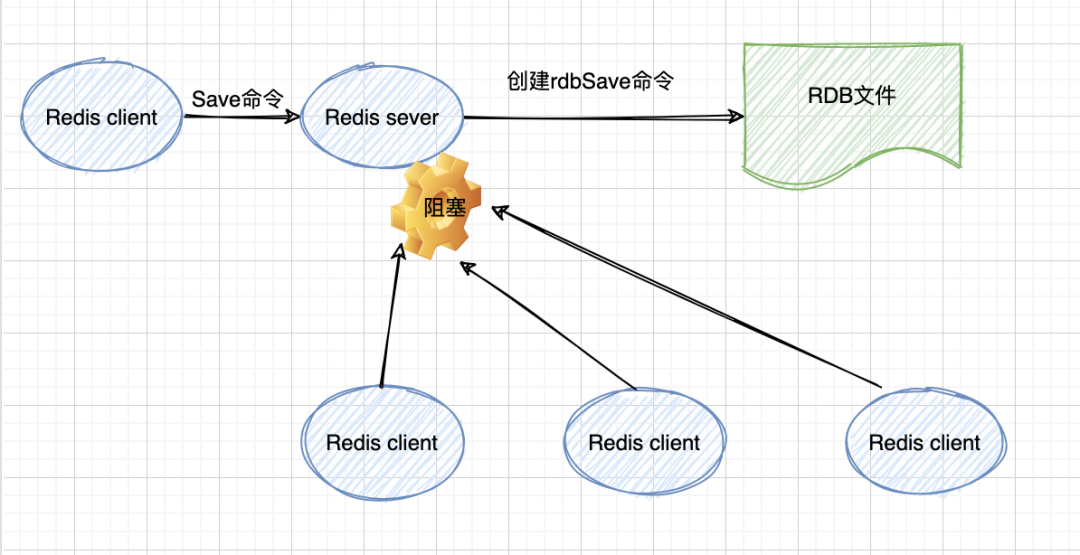
由于 save 命令是同步命令,会占用Redis的主进程。若Redis数据非常多时,save命令执行速度会非常慢,阻塞所有客户端的请求。因此很少在生产环境直接使用SAVE 命令,可以使用BGSAVE 命令代替。如果在BGSAVE命令的保存数据的子进程发生错误的时,用 SAVE命令保存最新的数据是最后的手段。
bgsave异步保存
bgsave 命令是异步操作,执行命令时,子进程执行保存工作,服务器还可以继续让主线程处理客户端发送的命令请求。
具体流程如下:
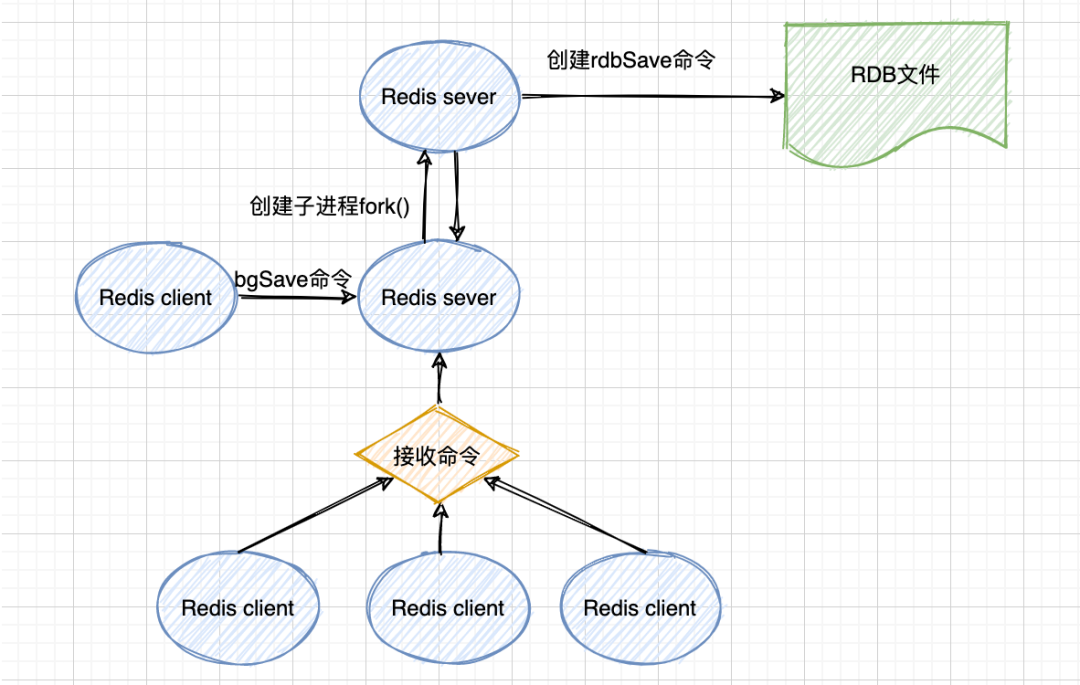
Redis使用Linux系统的fock()生成一个子进程来将DB数据保存到磁盘,主进程继续提供服务以供客户端调用。如果操作成功,可以通过客户端命令LASTSAVE来检查操作结果。
自动保存
可通过配置文件对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动进行数据集保存操作:
# RDB自动持久化规则
# 当 900 秒内有至少有 1 个键被改动时,自动进行数据集保存操作
save 900 1
# 当 300 秒内有至少有 10 个键被改动时,自动进行数据集保存操作
save 300 10
# 当 60 秒内有至少有 10000 个键被改动时,自动进行数据集保存操作
save 60 10000
# RDB持久化文件名
dbfilename dump-<port>.rdb
# 数据持久化文件存储目录
dir /var/lib/redis
# bgsave发生错误时是否停止写入,通常为yes
stop-writes-on-bgsave-error yes
# rdb文件是否使用压缩格式
rdbcompression yes
# 是否对rdb文件进行校验和检验,通常为yes
rdbchecksum yes
默认配置
RDB 文件默认的配置如下:
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
# 在给定的秒数和给定的对数据库的写操作数下,自动持久化操作。
# save <seconds> <changes>
#
save 900 1
save 300 10
save 60 10000
#bgsave发生错误时是否停止写入,一般为yes
stop-writes-on-bgsave-error yes
#持久化时是否使用LZF压缩字符串对象?
rdbcompression yes
#是否对rdb文件进行校验和检验,通常为yes
rdbchecksum yes
# RDB持久化文件名
dbfilename dump.rdb
#持久化文件存储目录
dir ./
AOF模式(日志追加)
AOF(Append Only File,追加日志文件)持久化方式:是指所有的命令行记录以 Redis 命令请求协议的格式完全持久化存储保存为 aof 文件。Redis 是先执行命令,把数据写入内存,然后才记录日志。因为该模式是只追加的方式,所以没有任何磁盘寻址的开销,所以很快,有点像 Mysql 中的binlog,AOF更适合做热备。
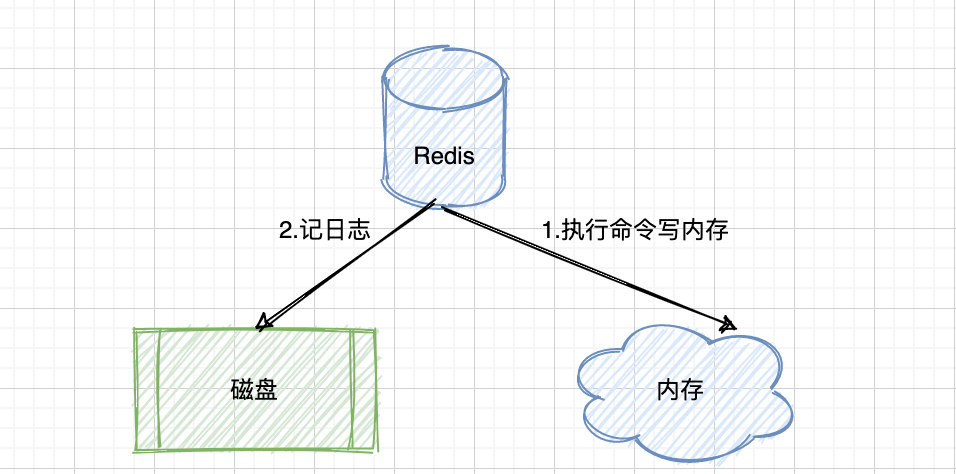
优点
- 数据更完整,安全性更高,秒级数据丢失(取决fsync策略,如果是everysec,最多丢失1秒的数据)
- AOF文件是一个只进行追加的日志文件,且写入操作是以Redis协议的格式保存的,内容是可读的,适合误删紧急恢复
缺点
- 对于相同的数据集,AOF文件的体积要大于RDB文件,数据恢复也会比较慢
- 根据所使用的fsync策略,AOF的速度可能会慢于RDB。 不过在一般情况下,每秒fsync的性能依然非常高
持久化流程

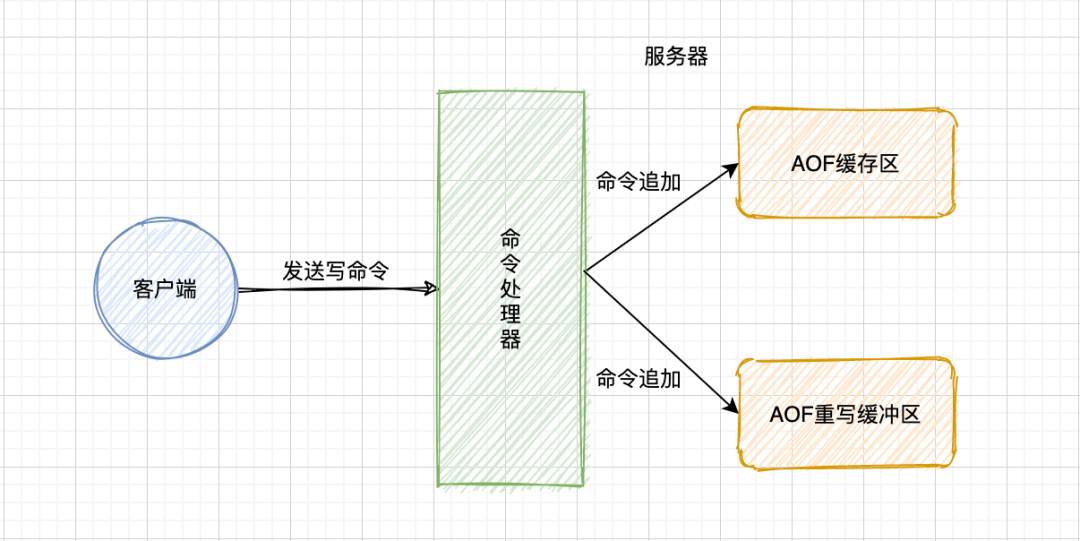
① 命令追加
若 AOF 持久化功能处于打开状态,服务器在执行完一个命令后,会以协议格式将被执行的写命令追加到服务器状态的 aof_buf 缓冲区的末尾。
② 文件同步
服务器每次结束一个事件循环之前,都会调用 flushAppendOnlyFile 函数,这个函数会考虑是否需要将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件里。flushAppendOnlyFile 函数执行以下流程:
- WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件;
- SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
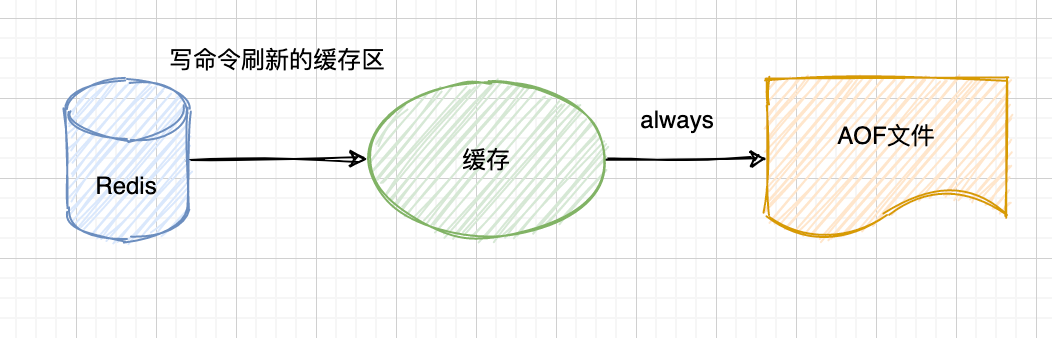
这个函数是由服务器配置的 appendfsync 的三个值:always、everysec、no 来影响的,也被称为三种策略:
-
always:每条命令都会 fsync 到硬盘中,这样 redis 的写入数据就不会丢失。
-
everysec:每秒都会刷新缓冲区到硬盘中(默认值)。
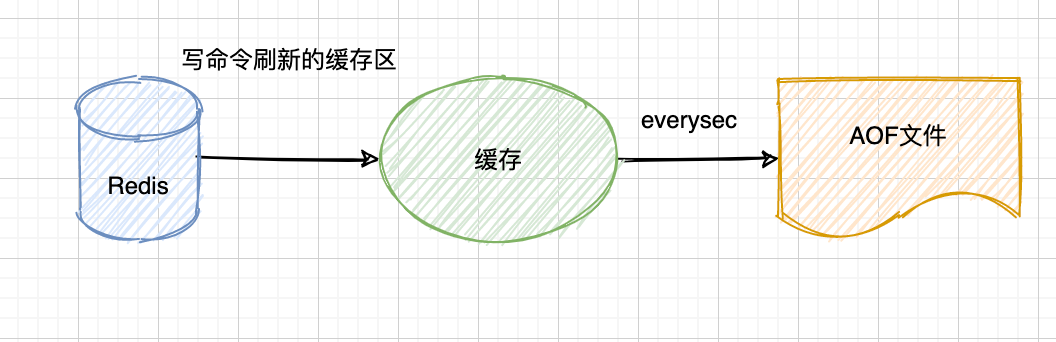
-
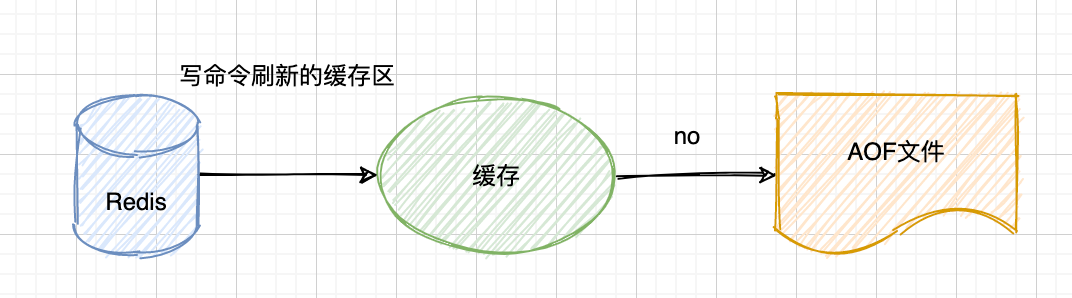
no:根据当前操作系统的规则决定什么时候刷新到硬盘中,不需要我们来考虑。
数据加载
- 创建一个不带网络连接的伪客户端
- 从 AOF 文件中分析并读取出一条写命令
- 使用伪客户端执行被读出的写命令
- 一直执行步骤 2 和 3,直到 AOF 文件中的所有写命令都被处理完毕为止
文件重写
为何需要文件重写
- 为了解决 AOF 文件体积膨胀的问题
- 通过重写创建一个新的 AOF 文件来替代现有的 AOF 文件,新的 AOF 文件不会包含任何浪费空间的冗余命令
文件重写的实现原理
- 不需要对现有的 AOF 文件进行任何操作
- 从数据库中直接读取键现在的值
- 用一条命令记录键值对,从而代替之前记录这个键值对的多条命令
后台重写
为不阻塞父进程,Redis将AOF重写程序放到子进程里执行。在子进程执行AOF重写期间,服务器进程需要执行三个流程:
- 执行客户端发来的命令
- 将执行后的写命令追加到 AOF 缓冲区
- 将执行后的写命令追加到 AOF 重写缓冲区
默认配置
AOF 文件默认的配置如下:
############################## APPEND ONLY MODE ###############################
#开启AOF持久化方式
appendonly no
#AOF持久化文件名
appendfilename "appendonly.aof"
#每秒把缓冲区的数据fsync到磁盘
appendfsync everysec
# appendfsync no
#是否在执行重写时不同步数据到AOF文件
no-appendfsync-on-rewrite no
# 触发AOF文件执行重写的增长率
auto-aof-rewrite-percentage 100
#触发AOF文件执行重写的最小size
auto-aof-rewrite-min-size 64mb
#redis在恢复时,会忽略最后一条可能存在问题的指令
aof-load-truncated yes
#是否打开混合开关
aof-use-rdb-preamble yes
过期策略
过期策略用于处理过期缓存数据。Redis采用过期策略:惰性删除 + 定期删除。memcached采用过期策略:惰性删除。
定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即对key进行清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
定期过期
每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。expires字典会保存所有设置了过期时间的key的过期时间数据,其中 key 是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。键空间是指该Redis集群中保存的所有键。
淘汰策略
Redis淘汰机制的存在是为了更好的使用内存,用一定的缓存丢失来换取内存的使用效率。当Redis内存快耗尽时,Redis会启动内存淘汰机制,将部分key清掉以腾出内存。当达到内存使用上限超过maxmemory时,可在配置文件redis.conf中指定 maxmemory-policy 的清理缓存方式。
# 配置最大内存限制
maxmemory 1000mb
# 配置淘汰策略
maxmemory-policy volatile-lru
LRU(最近最少使用)
volatile-lru:从已设置过期时间的key中,挑选**最近最少使用(最长时间没有使用)**的key进行淘汰allkeys-lru:从所有key中,挑选最近最少使用的数据淘汰
LFU(最近最不经常使用)
volatile-lfu:从已设置过期时间的key中,挑选**最近最不经常使用(使用次数最少)**的key进行淘汰allkeys-lfu:从所有key中,选择某段时间内内最近最不经常使用的数据淘汰
Random(随机淘汰)
volatile-random:从已设置过期时间的key中,任意选择数据淘汰allkeys-random:从所有key中,任意选择数据淘汰
TTL(过期时间)
volatile-ttl:从已设置过期时间的key中,挑选将要过期的数据淘汰allkeys-random:从所有key中,任意选择数据淘汰
No-Enviction(驱逐)
noenviction(驱逐):当达到最大内存时直接返回错误,不覆盖或逐出任何数据
部署架构
单节点(Single)
优点
- 架构简单,部署方便
- 高性价比:缓存使用时无需备用节点(单实例可用性可以用 supervisor 或 crontab 保证),当然为了满足业务的高可用性,也可以牺牲一个备用节点,但同时刻只有一个实例对外提供服务
- 高性能
缺点
- 不保证数据的可靠性
- 在缓存使用,进程重启后,数据丢失,即使有备用的节点解决高可用性,但是仍然不能解决缓存预热问题,因此不适用于数据可靠性要求高的业务
- 高性能受限于单核CPU的处理能力(Redis是单线程机制),CPU为主要瓶颈,所以适合操作命令简单,排序/计算较少场景
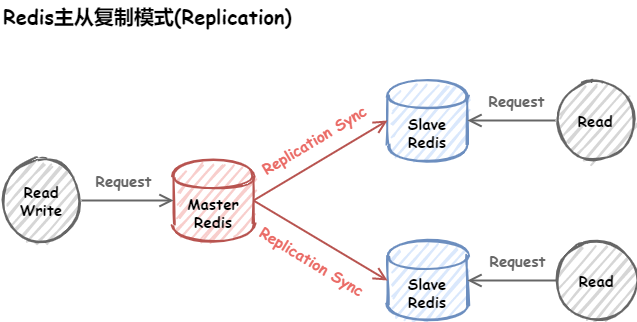
主从复制(Replication)
基本原理
主从复制模式中包含一个主数据库实例(Master)与一个或多个从数据库实例(Slave),如下图:

哨兵(Sentinel)
Sentinel主要作用如下:
- 监控:Sentinel 会不断的检查主服务器和从服务器是否正常运行
- 通知:当被监控的某个Redis服务器出现问题,Sentinel通过API脚本向管理员或者其他的应用程序发送通知
- 自动故障转移:当主节点不能正常工作时,Sentinel会开始一次自动的故障转移操作,它会将与失效主节点是主从关系的其中一个从节点升级为新的主节点,并且将其他的从节点指向新的主节点
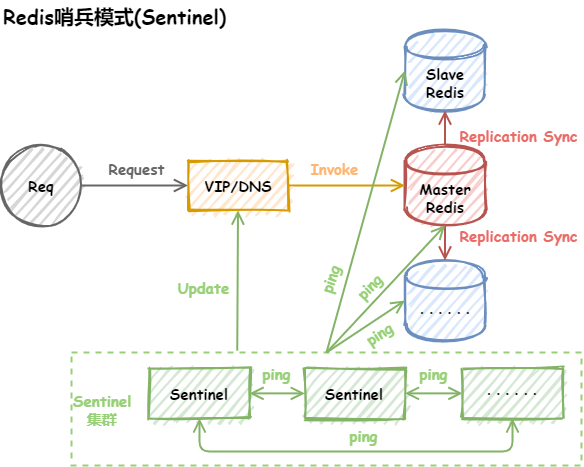

集群(Cluster)

环境搭建
Redis安装及配置
Redis的安装十分简单,打开redis的官网 http://redis.io 。
- 下载一个最新版本的安装包,如 redis-version.tar.gz
- 解压
tar zxvf redis-version.tar.gz - 执行 make (执行此命令可能会报错,例如确实gcc,一个个解决即可)
如果是 mac 电脑,安装redis将十分简单执行brew install redis即可。安装好redis之后,我们先不慌使用,先进行一些配置。打开redis.conf文件,我们主要关注以下配置:
port 6379 # 指定端口为 6379,也可自行修改
daemonize yes # 指定后台运行
单节点(Single)
安装好redis之后,我们来运行一下。启动redis的命令为 :
$ <redishome>/bin/redis-server path/to/redis.config
假设我们没有配置后台运行(即:daemonize no),那么我们会看到如下启动日志:
93825:C 20 Jan 2019 11:43:22.640 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
93825:C 20 Jan 2019 11:43:22.640 # Redis version=5.0.3, bits=64, commit=00000000, modified=0, pid=93825, just started
93825:C 20 Jan 2019 11:43:22.640 # Configuration loaded
93825:S 20 Jan 2019 11:43:22.641 * Increased maximum number of open files to 10032 (it was originally set to 256).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.3 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6380
| `-._ `._ / _.-' | PID: 93825
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
主从复制(Replication)
Redis主从配置非常简单,过程如下(演示情况下主从配置在一台电脑上):
第一步:复制两个redis配置文件(启动两个redis,只需要一份redis程序,两个不同的redis配置文件即可)
mkdir redis-master-slave
cp path/to/redis/conf/redis.conf path/to/redis-master-slave master.conf
cp path/to/redis/conf/redis.conf path/to/redis-master-slave slave.conf
第二步:修改配置
## master.conf
port 6379
## master.conf
port 6380
slaveof 127.0.0.1 6379
第三步:分别启动两个redis
redis-server path/to/redis-master-slave/master.conf
redis-server path/to/redis-master-slave/slave.conf
启动之后,打开两个命令行窗口,分别执行 telnet localhost 6379 和 telnet localhost 6380,然后分别在两个窗口中执行 info 命令,可以看到:
# Replication
role:master
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
主从配置没问题。然后在master 窗口执行 set 之后,到slave窗口执行get,可以get到,说明主从同步成功。这时,我们如果在slave窗口执行 set ,会报错:
-READONLY You can't write against a read only replica.
因为从节点是只读的。
哨兵(Sentinel)
Sentinel是用来监控主从节点的健康情况。客户端连接Redis主从的时候,先连接Sentinel,Sentinel会告诉客户端主Redis的地址是多少,然后客户端连接上Redis并进行后续的操作。当主节点挂掉的时候,客户端就得不到连接了因而报错了,客户端重新向Sentinel询问主master的地址,然后客户端得到了[新选举出来的主Redis],然后又可以愉快的操作了。
哨兵sentinel配置
为了说明sentinel的用处,我们做个试验。配置3个redis(1主2从),1个哨兵。步骤如下:
mkdir redis-sentinel
cd redis-sentinel
cp redis/path/conf/redis.conf path/to/redis-sentinel/redis01.conf
cp redis/path/conf/redis.conf path/to/redis-sentinel/redis02.conf
cp redis/path/conf/redis.conf path/to/redis-sentinel/redis03.conf
touch sentinel.conf
上我们创建了 3个redis配置文件,1个哨兵配置文件。我们将 redis01设置为master,将redis02,redis03设置为slave。
vim redis01.conf
port 63791
vim redis02.conf
port 63792
slaveof 127.0.0.1 63791
vim redis03.conf
port 63793
slaveof 127.0.0.1 63791
vim sentinel.conf
daemonize yes
port 26379
sentinel monitor mymaster 127.0.0.1 63793 1 # 下面解释含义
上面的主从配置都熟悉,只有哨兵配置 sentinel.conf,需要解释一下:
mymaster # 为主节点名字,可以随便取,后面程序里边连接的时候要用到
127.0.0.1 63793 # 为主节点的 ip,port
1 # 后面的数字 1 表示选举主节点的时候,投票数。1表示有一个sentinel同意即可升级为master
启动哨兵
上面我们配置好了redis主从,1主2从,以及1个哨兵。下面我们分别启动redis,并启动哨兵:
redis-server path/to/redis-sentinel/redis01.conf
redis-server path/to/redis-sentinel/redis02.conf
redis-server path/to/redis-sentinel/redis03.conf
redis-server path/to/redis-sentinel/sentinel.conf --sentinel
启动之后,可以分别连接到 3个redis上,执行info查看主从信息。
模拟主节点宕机情况
运行上面的程序(注意,在实验这个效果的时候,可以将sleep时间加长或者for循环增多,以防程序提前停止,不便看整体效果),然后将主redis关掉,模拟redis挂掉的情况。现在主redis为redis01,端口为63791
redis-cli -p 63791 shutdown
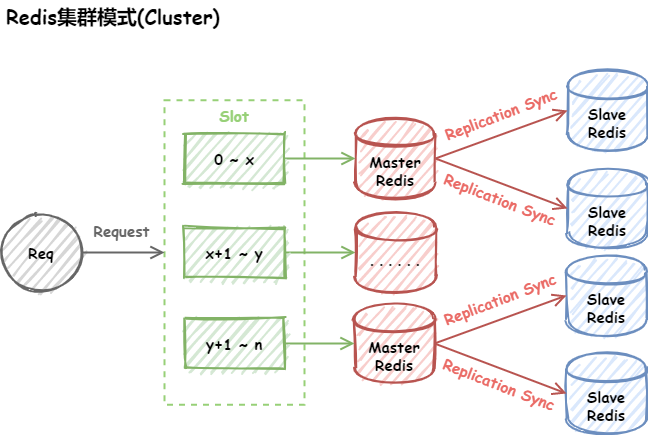
集群(Cluster)
上述所做的这些工作只是保证了数据备份以及高可用,目前为止我们的程序一直都是向1台redis写数据,其他的redis只是备份而已。实际场景中,单个redis节点可能不满足要求,因为:
- 单个redis并发有限
- 单个redis接收所有数据,最终回导致内存太大,内存太大回导致rdb文件过大,从很大的rdb文件中同步恢复数据会很慢
所以需要redis cluster 即redis集群。Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误。Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令.。Redis 集群的优势:
- 自动分割数据到不同的节点上
- 整个集群的部分节点失败或者不可达的情况下能够继续处理命令
为了配置一个redis cluster,我们需要准备至少6台redis,为啥至少6台呢?我们可以在redis的官方文档中找到如下一句话:
Note that the minimal cluster that works as expected requires to contain at least three master nodes.
因为最小的redis集群,需要至少3个主节点,既然有3个主节点,而一个主节点搭配至少一个从节点,因此至少得6台redis。然而对我来说,就是复制6个redis配置文件。本实验的redis集群搭建依然在一台电脑上模拟。
配置 redis cluster 集群
上面提到,配置redis集群需要至少6个redis节点。因此我们需要准备及配置的节点如下:
# 主:redis01 从 redis02 slaveof redis01
# 主:redis03 从 redis04 slaveof redis03
# 主:redis05 从 redis06 slaveof redis05
mkdir redis-cluster
cd redis-cluster
mkdir redis01 到 redis06 6个文件夹
cp redis.conf 到 redis01 ... redis06
# 修改端口, 分别配置3组主从关系
启动redis集群
上面的配置完成之后,分别启动6个redis实例。配置正确的情况下,都可以启动成功。然后运行如下命令创建集群:
redis-5.0.3/src/redis-cli --cluster create 127.0.0.1:6371 127.0.0.1:6372 127.0.0.1:6373 127.0.0.1:6374 127.0.0.1:6375 127.0.0.1:6376 --cluster-replicas 1
注意,这里使用的是ip:port,而不是 domain:port ,因为我在使用 localhost:6371 之类的写法执行的时候碰到错误:
ERR Invalid node address specified: localhost:6371
执行成功之后,连接一台redis,执行 cluster info 会看到类似如下信息:
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:1515
cluster_stats_messages_pong_sent:1506
cluster_stats_messages_sent:3021
cluster_stats_messages_ping_received:1501
cluster_stats_messages_pong_received:1515
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:3021
我们可以看到cluster_state:ok,cluster_slots_ok:16384,cluster_size:3。
拓展方案
分区(Partitioning)
指在面临单机的存储空间瓶颈时,即将全部数据分散在多个Redis实例中,每个实例不需要关联,可以是完全独立的。
使用方式
- 客户端处理
和传统的数据库分库分表一样,可以从key入手,先进行计算,找到对应数据存储的实例在进行操作。
- 范围角度,比如orderId:1~orderId:1000放入实例1,orderId:1001~orderId:2000放入实例2
- 哈希计算,就像我们的hashmap一样,用hash函数加上位运算或者取模,高级玩法还有一致性Hash等操作,找到对应的实例进行操作
- 使用代理中间件 我们可以开发独立的代理中间件,屏蔽掉处理数据分片的逻辑,独立运行。当然Redis也有优秀的代理中间件,譬如Twemproxy,或者codis,可以结合场景选择是否使用
缺点
- 无缘多key操作,key都不一定在一个实例上,那么多key操作或者多key事务自然是不支持
- 维护成本,由于每个实例在物理和逻辑上,都属于单独的一个节点,缺乏统一管理
- 灵活性有限,范围分片还好,比如hash+MOD这种方式,如果想动态调整Redis实例的数量,就要考虑大量数据迁移
主从(Master-Slave)
分区暂时能解决单点无法容纳的数据量问题,但是一个Key还是只在一个实例上。主从则将数据从主节点同步到从节点,然后可做读写分离,将读流量均摊在各个从节点,可靠性也能提高。主从(Master-Slave)也就是复制(Replication)方式。
使用方式
- 作为主节点的Redis实例,并不要求配置任何参数,只需要正常启动
- 作为从节点的实例,使用配置文件或命令方式
REPLICAOF 主节点Host 主节点port即可完成主从配置
缺点
- slave节点都是只读的,如果写流量大的场景,就有些力不从心
- 故障转移不友好,主节点挂掉后,写处理就无处安放,需要手工的设定新的主节点,如使用
REPLICAOF no one晋升为主节点,再梳理其他slave节点的新主配置,相对来说比较麻烦
哨兵(Sentinel)
主从的手工故障转移,肯定让人很难接受,自然就出现了高可用方案-哨兵(Sentinel)。我们可以在主从架构不变的场景,直接加入Redis Sentinel,对节点进行监控,来完成自动的故障发现与转移。并且还能够充当配置提供者,提供主节点的信息,就算发生了故障转移,也能提供正确的地址。
使用方式
Sentinel的最小配置,一行即可:
sentinel monitor <主节点别名> <主节点host> <主节点端口> <票数>
只需要配置master即可,然后用redis-sentinel <配置文件> 命令即可启用。哨兵数量建议在三个以上且为奇数。
使用场景问题
- 故障转移期间短暂的不可用,但其实官网的例子也给出了
parallel-syncs参数来指定并行的同步实例数量,以免全部实例都在同步出现整体不可用的情况,相对来说要比手工的故障转移更加方便 - 分区逻辑需要自定义处理,虽然解决了主从下的高可用问题,但是Sentinel并没有提供分区解决方案,还需开发者考虑如何建设
- 既然是还是主从,如果异常的写流量搞垮了主节点,那么自动的“故障转移”会不会变成自动“灾难传递”,即slave提升为Master之后挂掉,又进行提升又被挂掉
集群(Cluster)
Cluster在分区管理上,使用了“哈希槽”(hash slot)这么一个概念,一共有16384个槽位,每个实例负责一部分槽,通过CRC16(key)&16383这样的公式,计算出来key所对应的槽位。
使用方式
配置文件
cluster-enabled yes
cluster-config-file "redis-node.conf"
启动命令
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1
存在问题
- 虽然是对分区良好支持,但也有一些分区的老问题。如如果不在同一个“槽”的数据,是没法使用类似mset的多键操作
- 在select命令页有提到, 集群模式下只能使用一个库,虽然平时一般也是这么用的,但是要了解一下
- 运维上也要谨慎,俗话说得好,“使用越简单底层越复杂”,启动搭建是很方便,使用时面对带宽消耗,数据倾斜等等具体问题时,还需人工介入,或者研究合适的配置参数
常见问题
题目:保证Redis 中的 20w 数据都是热点数据 说明是 被频繁访问的数据,并且要保证Redis的内存能够存放20w数据,要计算出Redis内存的大小。
-
**保留热点数据:对于保留 Redis 热点数据来说,我们可以使用 Redis 的内存淘汰策略来实现,可以使用allkeys-lru淘汰策略,**该淘汰策略是从 Redis 的数据中挑选最近最少使用的数据删除,这样频繁被访问的数据就可以保留下来了
-
**保证 Redis 只存20w的数据:**1个中文占2个字节,假如1条数据有100个中文,则1条数据占200字节,20w数据 乘以 200字节 等于 4000 字节(大概等于38M);所以要保证能存20w数据,Redis 需要38M的内存
题目:MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?
限定 Redis 占用的内存,Redis 会根据自身数据淘汰策略,加载热数据到内存。所以,计算一下 20W 数据大约占用的内存,然后设置一下 Redis 内存限制即可。
题目:假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。对方接着追问:如果这个 Redis 正在给线上的业务提供服务,那使用 keys 指令会有什么问题?这个时候你要回答 Redis 关键的一个特性:Redis 的单线程的。keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞地提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
Kafka
RocketMQ
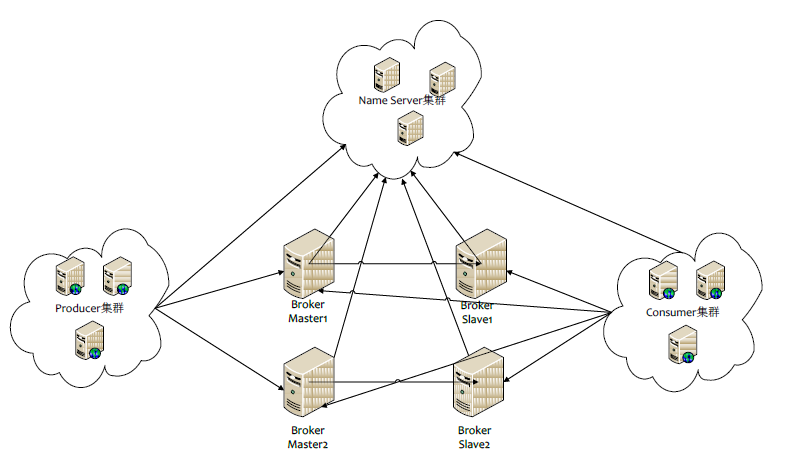
RocketMQ 是阿里巴巴开源的分布式消息中间件。支持事务消息、顺序消息、批量消息、定时消息、消息回溯等。它里面有几个区别于标准消息中件间的概念,如Group、Topic、Queue等。系统组成则由Producer、Consumer、Broker、NameServer等。
功能优势
- 削峰填谷:主要解决瞬时写压力大于应用服务能力导致消息丢失、系统奔溃等问题
- 应用解耦:解决不同重要程度、不同能力级别系统之间依赖导致一死全死
- 提升性能:当存在一对多调用时,可以发一条消息给消息系统,让消息系统通知相关系统
- 蓄流压测:线上有些链路不好压测,可以通过堆积一定量消息再放开来压测
- 异步处理:不需要同步执行的远程调用可以有效提高响应时间
架构设计
部署模型
角色
Broker
- 理解成RocketMQ本身
- Broker主要用于Producer和Consumer接收和发送消息
- Broker会定时向NameSrver提交自己的信息
- 是消息中间件的消息存储、转发服务器
- 每个Broker节点在启动时都会遍历NameServer列表,与每个NameServer建立长连接,注册自己的信息,之后定时上报
NameServer
- 理解成Zookeeper的效果,只是他没用zk,而是自己写了个NameServer来替代zk
- 底层由Netty实现,提供了路由管理、服务注册、服务发现的功能,是一个无状态节点
- NameServer是服务发现者,集群中各个角色(Producer、Broker、Consumer等)都需要定时向NameServer上报自己的状态,以便互相发现彼此,超时不上报的话,NameServer会把它从列表中剔除
- NameServer可以部署多个,当多个NameServer存在的时候,其他角色同时向他们上报信息,以保证高可用,
- NameServer集群间互不通信,没有主备的概念
- NameServer内存式存储,NameServer中的Broker、Topic等信息默认不会持久化,所以他是无状态节点
Producer
- 消息的生产者
- 随机选择其中一个NameServer节点建立长连接,获得Topic路由信息(包括Topic下的Queue,这些Queue分布在哪些Broker上等等)
- 接下来向提供Topic服务的Master建立长连接(因为RocketMQ只有Master才能写消息),且定时向Master发送心跳
Consumer
- 消息的消费者
- 通过NameServer集群获得Topic的路由信息,连接到对应的Broker上消费消息
- 由于Master和Slave都可以读取消息,因此Consumer会与Master和Slave都建立连接进行消费消息
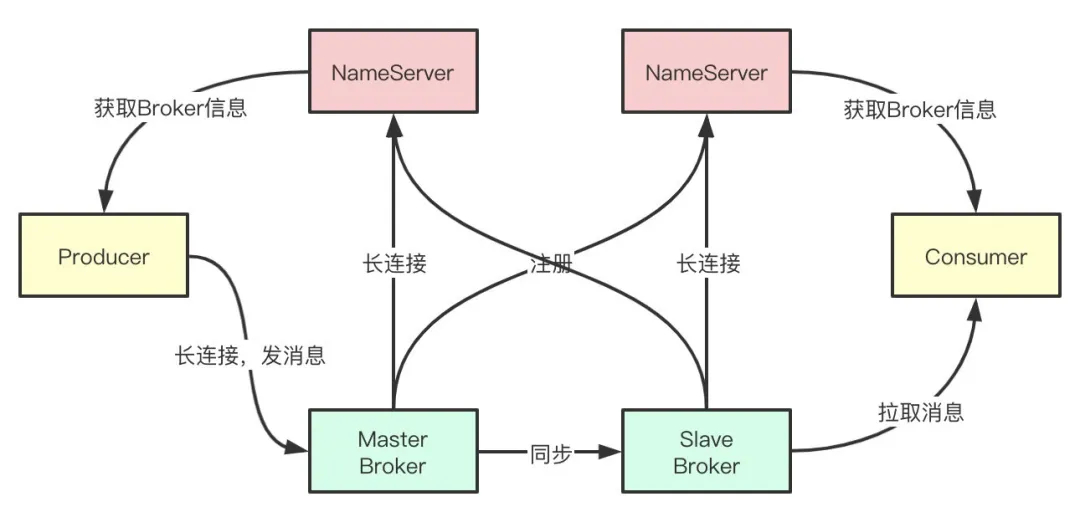
核心流程
- Broker都注册到Nameserver上
- Producer发消息的时候会从Nameserver上获取发消息的Topic信息
- Producer向提供服务的所有Master建立长连接,且定时向Master发送心跳
- Consumer通过NameServer集群获得Topic的路由信息
- Consumer会与所有的Master和所有的Slave都建立连接进行监听新消息
实现原理
RocketMQ由NameServer注册中心集群、Producer生产者集群、Consumer消费者集群和若干Broker(RocketMQ进程)组成,它的架构原理是这样的:
- Broker在启动的时候去向所有的NameServer注册,并保持长连接,每30s发送一次心跳
- Producer在发送消息的时候从NameServer获取Broker服务器地址,根据负载均衡算法选择一台服务器来发送消息
- Conusmer消费消息的时候同样从NameServer获取Broker地址,然后主动拉取消息来消费
核心概念
Message(消息)
消息载体。Message发送或者消费的时候必须指定Topic。Message有一个可选的Tag项用于过滤消息,还可以添加额外的键值对。
Topic(主题)
消息的逻辑分类,发消息之前必须要指定一个topic才能发,就是将这条消息发送到这个topic上。消费消息的时候指定这个topic进行消费。就是逻辑分类。
Queue(队列)
1个Topic会被分为N个Queue,数量是可配置的。message本身其实是存储到queue上的,消费者消费的也是queue上的消息。多说一嘴,比如1个topic4个queue,有5个Consumer都在消费这个topic,那么会有一个consumer浪费掉了,因为负载均衡策略,每个consumer消费1个queue,5>4,溢出1个,这个会不工作。
Tag(标签)
Tag 是 Topic 的进一步细分,顾名思义,标签。每个发送的时候消息都能打tag,消费的时候可以根据tag进行过滤,选择性消费。
消费模式(Message Model)
消息模型:集群(Clustering)和广播(Broadcasting)
集群模式(Clustering)
生产者往某个队列里面发送消息,一个队列可以存储多个生产者的消息,一个队列也可以有多个消费者,但是消费者之间是竞争关系,即每条消息只能被一个消费者消费。
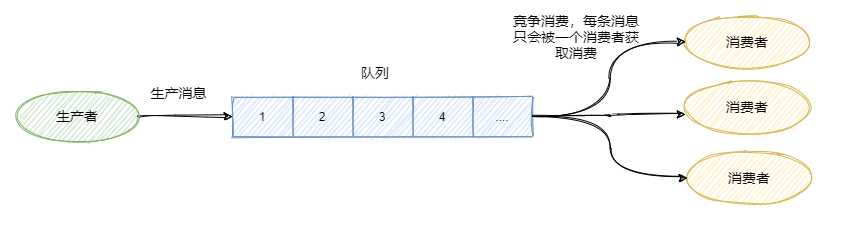
- 每条消息只需要被处理一次,Broker只会把消息发送给消费集群中的一个消费者
- 在消息重投时,不能保证路由到同一台机器上
- 消费状态由Broker维护
广播模式(Broadcasting)
为了解决一条消息能被多个消费者消费的问题,发布/订阅模型就来了。该模型是将消息发往一个Topic即主题中,所有订阅了这个 Topic 的订阅者都能消费这条消息。
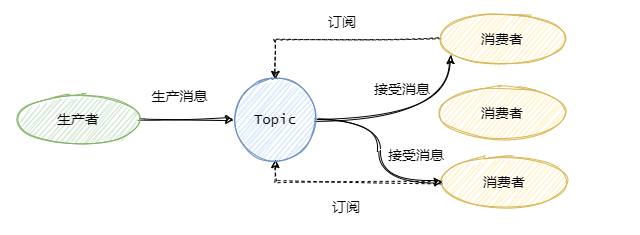
- 消费进度由Consumer维护
- 保证每个消费者都消费一次消息
- 消费失败的消息不会重投
Message Order(消息顺序)
消息顺序:顺序(Orderly)和并发(Concurrently)
顺序(Orderly)
并发(Concurrently)
Producer Group(生产组)
消息生产者组。标识发送同一类消息的Producer,通常发送逻辑一致。发送普通消息的时候,仅标识使用,并无特别用处。若事务消息,如果某条发送某条消息的producer-A宕机,使得事务消息一直处于PREPARED状态并超时,则broker会回查同一个group的其 他producer,确认这条消息应该commit还是rollback。但开源版本并不完全支持事务消息(阉割了事务回查的代码)。
Consumer Group(消费组)
消息消费者组。标识一类Consumer的集合名称,这类Consumer通常消费一类消息,且消费逻辑一致。同一个Consumer Group下的各个实例将共同消费topic的消息,起到负载均衡的作用。消费进度以Consumer Group为粒度管理,不同Consumer Group之间消费进度彼此不受影响,即消息A被Consumer Group1消费过,也会再给Consumer Group2消费。
注: RocketMQ要求同一个Consumer Group的消费者必须要拥有相同的注册信息,即必须要听一样的topic(并且tag也一样)。
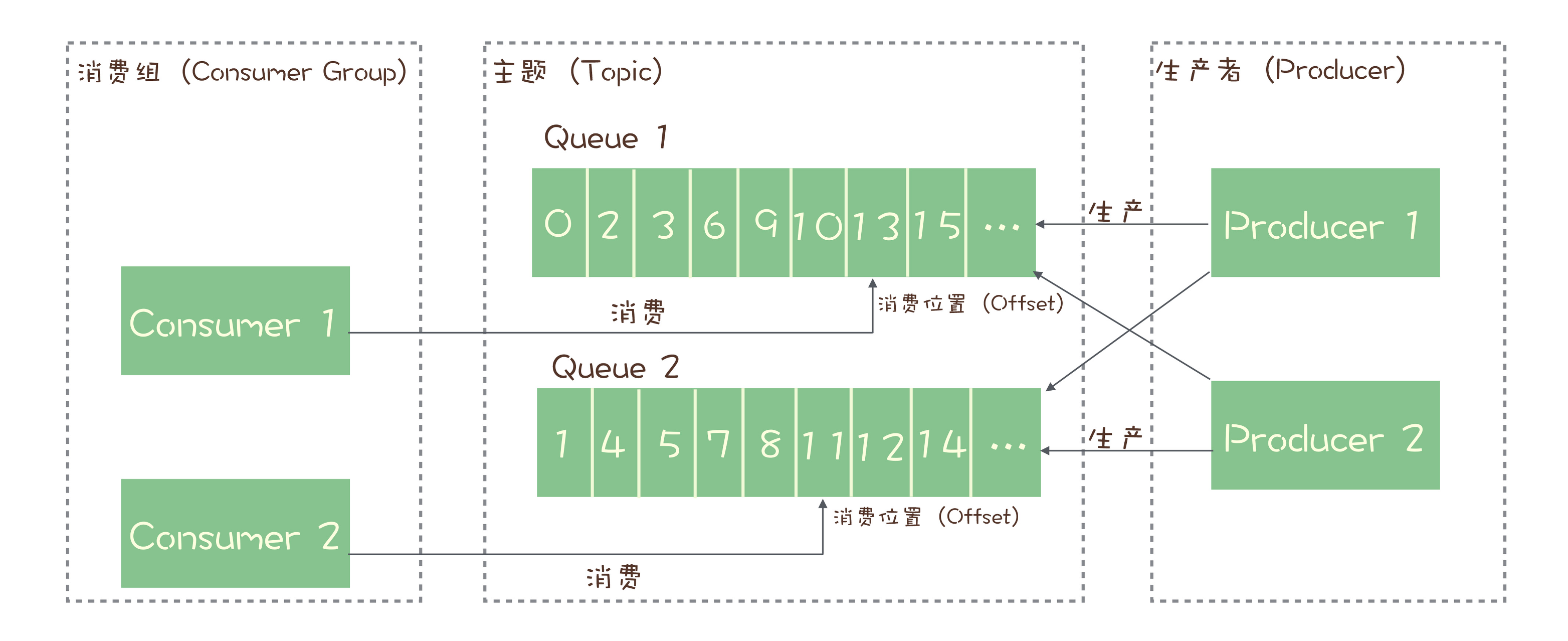
Offset
在 Topic 的消费过程中,由于消息需要被不同的组进行多次消费,所以消费完的消息并不会立即被删除,这就需要 RocketMQ 为每个消费组在每个队列上维护一个消费位置(Consumer Offset),这个位置之前的消息都被消费过,之后的消息都没有被消费过,每成功消费一条消息,消费位置就加一。这个消费位置是非常重要的概念,我们在使用消息队列的时候,丢消息的原因大多是由于消费位置处理不当导致的。
核心设计
消息清理
Broker中的消息被消费后不会立即删除,每条消息都会持久化到CommitLog中,每个Consumer连接到Broker后会维持消费进度信息,当有消息消费后只是当前Consumer的消费进度(CommitLog的offset)更新了。默认48小时后会删除不再使用的CommitLog文件:
- 检查这个文件最后访问时间
- 判断是否大于过期时间
- 指定时间删除,默认凌晨4点
/**
* {@link org.apache.rocketmq.store.DefaultMessageStore.CleanCommitLogService#isTimeToDelete()}
*/
private boolean isTimeToDelete() {
// when = "04";
String when = DefaultMessageStore.this.getMessageStoreConfig().getDeleteWhen();
// 是04点,就返回true
if (UtilAll.isItTimeToDo(when)) {
return true;
}
// 不是04点,返回false
return false;
}
/**
* {@link org.apache.rocketmq.store.DefaultMessageStore.CleanCommitLogService#deleteExpiredFiles()}
*/
private void deleteExpiredFiles() {
// isTimeToDelete()这个方法是判断是不是凌晨四点,是的话就执行删除逻辑。
if (isTimeToDelete()) {
// 默认是72,但是broker配置文件默认改成了48,所以新版本都是48。
long fileReservedTime = 48 * 60 * 60 * 1000;
deleteCount = DefaultMessageStore.this.commitLog.deleteExpiredFile(72 * 60 * 60 * 1000, xx, xx, xx);
}
}
/**
* {@link org.apache.rocketmq.store.CommitLog#deleteExpiredFile()}
*/
public int deleteExpiredFile(xxx) {
// 这个方法的主逻辑就是遍历查找最后更改时间+过期时间,小于当前系统时间的话就删了(也就是小于48小时)。
return this.mappedFileQueue.deleteExpiredFileByTime(72 * 60 * 60 * 1000, xx, xx, xx);
}
push or pull
RocketMQ没有真正意义的push,都是pull,虽然有push类,但实际底层实现采用的是长轮询机制,即拉取方式。Broker端属性 longPollingEnable 标记是否开启长轮询,默认开启。源码如下:
// {@link org.apache.rocketmq.client.impl.consumer.DefaultMQPushConsumerImpl#pullMessage()}
// 拉取消息,结果放到pullCallback里
this.pullAPIWrapper.pullKernelImpl(pullCallback);
为什么要主动拉取消息而不使用事件监听方式?
事件驱动方式是建立好长连接,由事件(发送数据)的方式来实时推送。如果broker主动推送消息的话有可能push速度快,消费速度慢的情况,那么就会造成消息在consumer端堆积过多,同时又不能被其他consumer消费的情况。而pull的方式可以根据当前自身情况来pull,不会造成过多的压力而造成瓶颈。所以采取了pull的方式。
负载均衡
RocketMQ通过Topic在多Broker中分布式存储实现。
Producer端
发送端指定message queue发送消息到相应的broker,来达到写入时的负载均衡
- 提升写入吞吐量,当多个producer同时向一个broker写入数据的时候,性能会下降
- 消息分布在多broker中,为负载消费做准备
默认策略是随机选择:
- producer维护一个index
- 每次取节点会自增
- index向所有broker个数取余
- 自带容错策略
其他实现:
-
SelectMessageQueueByHash
-
- hash的是传入的args
-
SelectMessageQueueByRandom
-
SelectMessageQueueByMachineRoom 没有实现
也可以自定义实现MessageQueueSelector接口中的select方法
MessageQueue select(final List<MessageQueue> mqs, final Message msg, final Object arg);
Consumer端
采用的是平均分配算法来进行负载均衡。
其他负载均衡算法
- 平均分配策略(默认)(AllocateMessageQueueAveragely)
- 环形分配策略(AllocateMessageQueueAveragelyByCircle)
- 手动配置分配策略(AllocateMessageQueueByConfig)
- 机房分配策略(AllocateMessageQueueByMachineRoom)
- 一致性哈希分配策略(AllocateMessageQueueConsistentHash)
- 靠近机房策略(AllocateMachineRoomNearby)
当消费负载均衡Consumer和Queue不对等的时候会发生什么?
Consumer和Queue会优先平均分配,如果Consumer少于Queue的个数,则会存在部分Consumer消费多个Queue的情况,如果Consumer等于Queue的个数,那就是一个Consumer消费一个Queue,如果Consumer个数大于Queue的个数,那么会有部分Consumer空余出来,白白的浪费了。
最佳实践
Producer
-
Topic:消息主题,通过Topic对不同的业务消息进行分类
-
Tag:消息标签,用来进一步区分某个Topic下的消息分类,消息从生产者发出即带上的属性
-
key:每个消息在业务层面的唯一标识码,要设置到 keys 字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过 topic,key来查询这条消息内容,以及消息被谁消费。由于是哈希索引,请务必保证key 尽可能唯一,这样可以避免潜在的哈希冲突
-
日志:消息发送成功或者失败,要打印消息日志,务必要打印 send result 和key 字段
-
send:send消息方法,只要不抛异常,就代表发送成功。但是发送成功会有多个状态,在sendResult里定义
- SEND_OK:消息发送成功
- FLUSH_DISK_TIMEOUT:消息发送成功,但是服务器刷盘超时,消息已经进入服务器队列,只有此时服务器宕机,消息才会丢失
- FLUSH_SLAVE_TIMEOUT:消息发送成功,但是服务器同步到Slave时超时,消息已经进入服务器队列,只有此时服务器宕机,消息才会丢失
- SLAVE_NOT_AVAILABLE:消息发送成功,但是此时slave不可用,消息已经进入服务器队列,只有此时服务器宕机,消息才会丢失
-
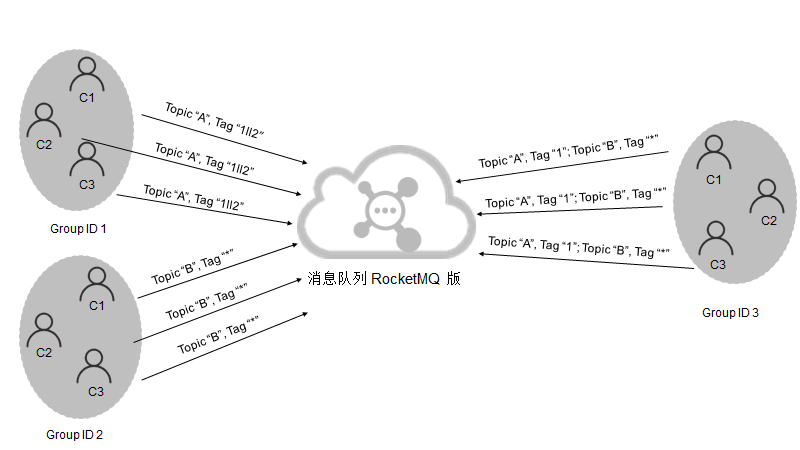
订阅关系一致
多个Group ID订阅了多个Topic,并且每个Group ID里的多个消费者实例的订阅关系保持了一致。
Consumer
-
消费幂等
为了防止消息重复消费导致业务处理异常,消息队列RocketMQ版的消费者在接收到消息后,有必要根据业务上的唯一Key对消息做幂等处理。消息重复的场景如下:
- 发送时消息重复
- 投递时消息重复
- 负载均衡时消息重复(包括但不限于网络抖动、Broker重启以及消费者应用重启)
-
日志:消费时记录日志,以便后续定位问题
-
批量消费:尽量使用批量方式消费方式,可以很大程度上提高消费吞吐量
事务消息
MQ与DB一致性原理(两方事务)
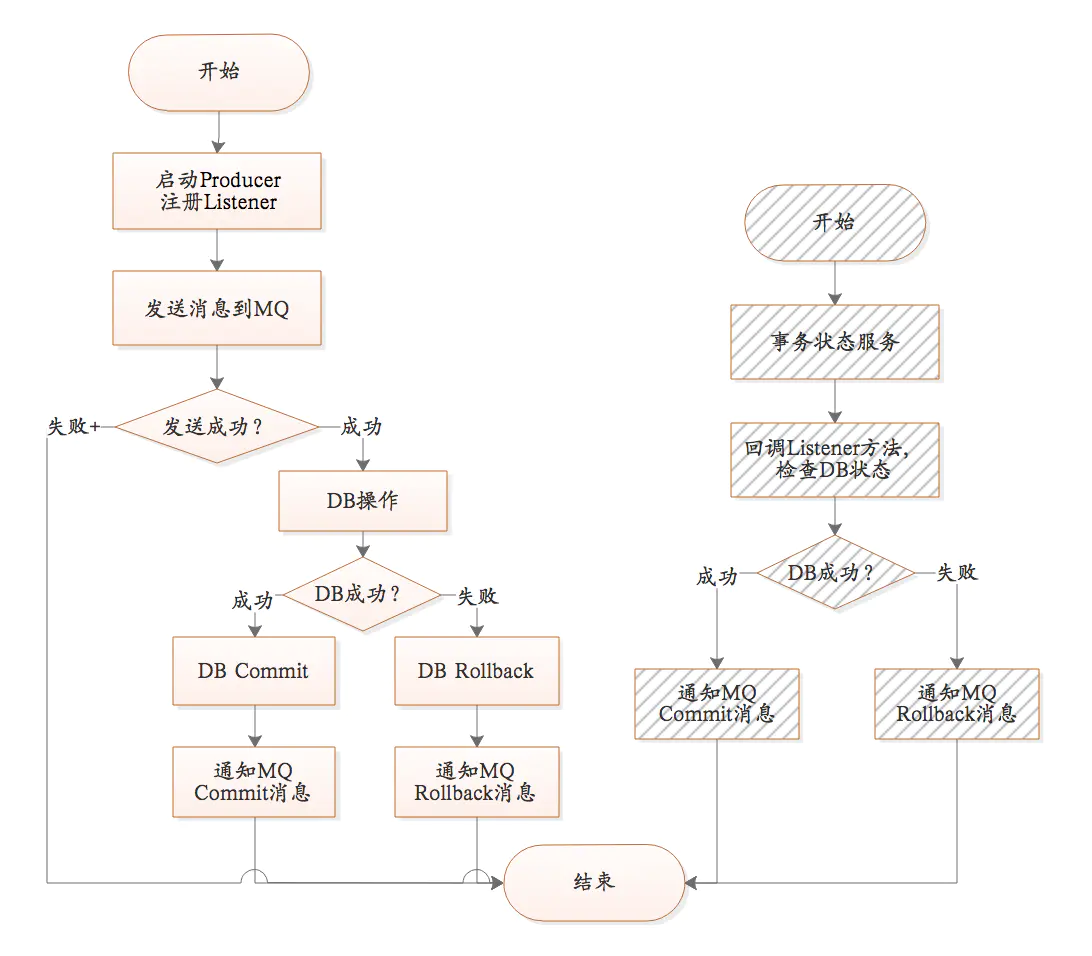
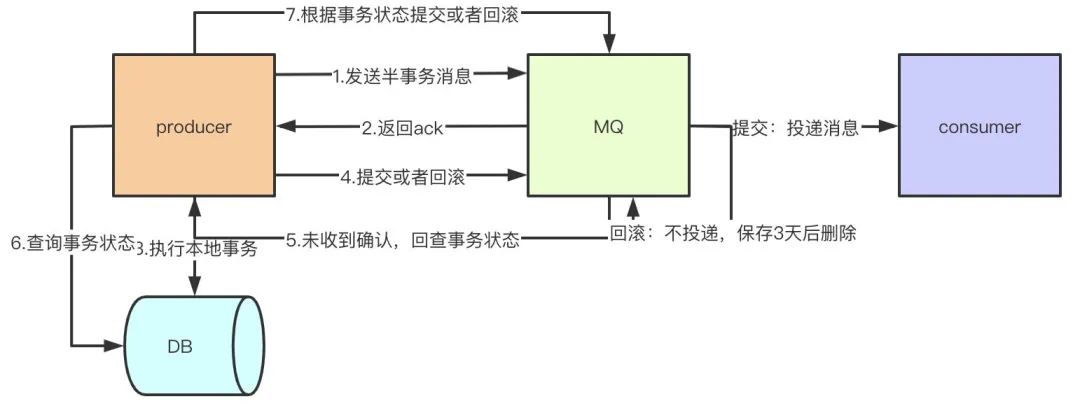
事务消息就是MQ提供的类似XA的分布式事务能力,通过事务消息可以达到分布式事务的最终一致性。半事务消息就是MQ收到了生产者的消息,但是没有收到二次确认,不能投递的消息。实现原理如下:
- 生产者先发送一条半事务消息到MQ
- MQ收到消息后返回ack确认
- 生产者开始执行本地事务
- 如果事务执行成功发送commit到MQ,失败发送rollback
- 如果MQ长时间未收到生产者的二次确认commit或者rollback,MQ对生产者发起消息回查
- 生产者查询事务执行最终状态
- 根据查询事务状态再次提交二次确认
如果MQ收到二次确认commit,就可以把消息投递给消费者,反之如果是rollback,消息会保存下来并且在3天后被删除。
保证顺序
RocketMQ的消息是存储到Topic的Queue里面的,Queue本身是FIFO(First Int First Out)先进先出队列。所以单个Queue是可以保证有序性的。
顺序消息(FIFO 消息)是 MQ 提供的一种严格按照顺序进行发布和消费的消息类型。顺序消息由两个部分组成:
- 顺序发布
- 顺序消费
顺序消息包含两种类型:
- 分区顺序:一个Partition内所有的消息按照先进先出的顺序进行发布和消费
- 全局顺序:一个Topic内所有的消息按照先进先出的顺序进行发布和消费
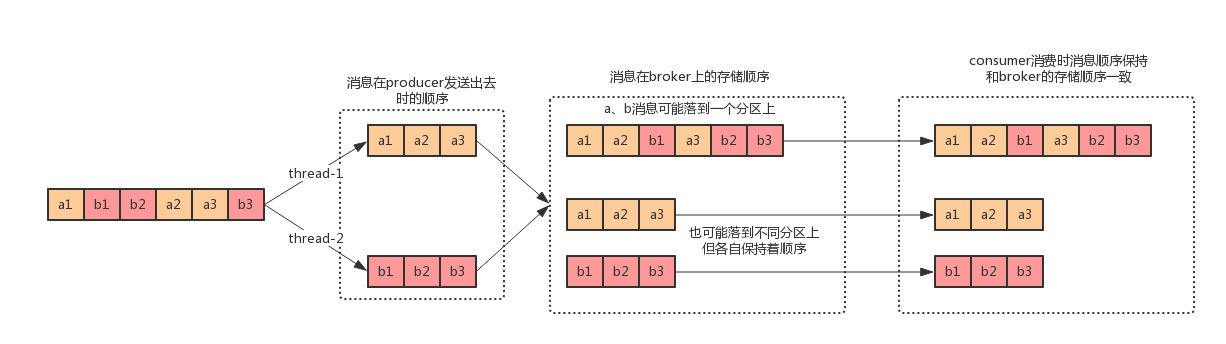
对于两个订单的消息的原始数据:a1、b1、b2、a2、a3、b3(绝对时间下发生的顺序):
- 在发送时,a订单的消息需要保持a1、a2、a3的顺序,b订单的消息也相同,但是a、b订单之间的消息没有顺序关系,这意味着a、b订单的消息可以在不同的线程中被发送出去
- 在存储时,需要分别保证a、b订单的消息的顺序,但是a、b订单之间的消息的顺序可以不保证
保持顺序发送
消息被发送时保持顺序。
保持顺序发送存储
消息被存储时保持和发送的顺序一致。
保持顺序消费
消息被消费时保持和存储的顺序一致。
MQPullConsumer
MQPullConsumer由用户控制线程,主动从服务端获取消息,每次获取到的是一个MessageQueue中的消息。PullResult中的List msgFoundList自然和存储顺序一致,用户需要再拿到这批消息后自己保证消费的顺序。
MQPushConsumer
对于PushConsumer,由用户注册MessageListener来消费消息,在客户端中需要保证调用MessageListener时消息的顺序性。
消息不丢失
一条消息从生产到被消费,将会经历三个阶段:
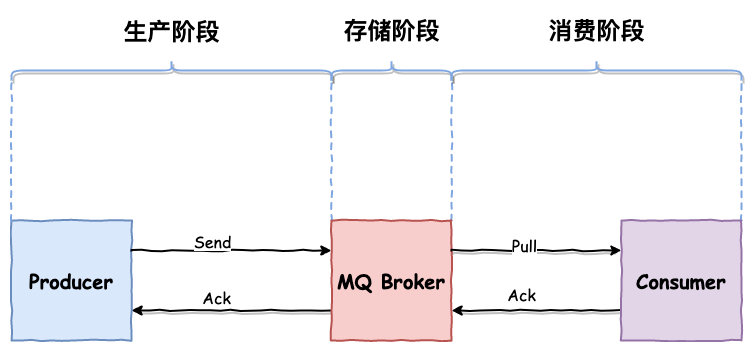
- 生产阶段:Producer 新建消息,然后通过网络将消息投递给 MQ Broker
- 存储阶段:消息将会存储在 Broker 端磁盘中
- 消息阶段:Consumer 将会从 Broker 拉取消息
以上任一阶段都可能会丢失消息,我们只要找到这三个阶段丢失消息原因,采用合理的办法避免丢失,就可以彻底解决消息丢失的问题。
生产阶段
Producer通过网络将消息发送给Broker,这个发送可能会发生丢失,比如网络延迟不可达等。
失败会自动重试,即使重试N次也不行后,那客户端也会知道消息没成功,这也可以自己补偿等,不会盲目影响到主业务逻辑。再比如即使Broker挂了,那还有其他Broker再提供服务了,高可用,不影响。
总结:同步发送+自动重试机制+多个Master节点
同步发送
有三种send方法,同步发送、异步发送、单向发送,可以采取同步发送的方式进行发送消息。
- 同步发送:发消息时会同步阻塞等待broker返回的结果,如果没成功,则不会收到SendResult,这种是最可靠的
- 异步发送:在回调方法里可以得知是否发送成功
- 单向发送(OneWay):最不靠谱的一种发送方式,我们无法保证消息真正可达
/**
* {@link org.apache.rocketmq.client.producer.DefaultMQProducer}
*/
// 同步发送
public SendResult send(Message msg) throws MQClientException, RemotingException, MQBrokerException, InterruptedException {}
// 异步发送,sendCallback作为回调
public void send(Message msg,SendCallback sendCallback) throws MQClientException, RemotingException, InterruptedException {}
// 单向发送,不关心发送结果,最不靠谱
public void sendOneway(Message msg) throws MQClientException, RemotingException, InterruptedException {}
失败重试
发送消息如果失败或者超时了,则会自动重试。默认是重试3次,可以根据api进行更改,比如改为10次:
producer.setRetryTimesWhenSendFailed(10);
底层源码逻辑如下:
/**
* {@link org.apache.rocketmq.client.producer.DefaultMQProducer#sendDefaultImpl(Message, CommunicationMode, SendCallback, long)}
*/
// 自动重试次数,this.defaultMQProducer.getRetryTimesWhenSendFailed()默认为2,如果是同步发送,默认重试3次,否则重试1次
int timesTotal = communicationMode == CommunicationMode.SYNC ? 1 + this.defaultMQProducer.getRetryTimesWhenSendFailed() : 1;
int times = 0;
for (; times < timesTotal; times++) {
// 选择发送的消息queue
MessageQueue mqSelected = this.selectOneMessageQueue(topicPublishInfo, lastBrokerName);
if (mqSelected != null) {
try {
// 真正的发送逻辑,sendKernelImpl。
sendResult = this.sendKernelImpl(msg, mq, communicationMode, sendCallback, topicPublishInfo, timeout - costTime);
switch (communicationMode) {
case ASYNC:
return null;
case ONEWAY:
return null;
case SYNC:
// 如果发送失败了,则continue,意味着还会再次进入for,继续重试发送
if (sendResult.getSendStatus() != SendStatus.SEND_OK) {
if (this.defaultMQProducer.isRetryAnotherBrokerWhenNotStoreOK()) {
continue;
}
}
// 发送成功的话,将发送结果返回给调用者
return sendResult;
default:
break;
}
} catch (RemotingException e) {
continue;
} catch (...) {
continue;
}
}
}
故障切换
假设Broker宕机了,但是生产环境一般都是多M多S的,所以还会有其他Master节点继续提供服务,这也不会影响到我们发送消息,我们消息依然可达。因为比如恰巧发送到broker的时候,broker宕机了,producer收到broker的响应发送失败了,这时候producer会自动重试,这时候宕机的broker就被踢下线了, 所以producer会换一台broker发送消息。
Broker存储阶段
若想很严格的保证Broker存储消息阶段消息不丢失,则需要如下配置,但是性能肯定远差于默认配置:
# master 节点配置
flushDiskType = SYNC_FLUSH
brokerRole=SYNC_MASTER
# slave 节点配置
brokerRole=slave
flushDiskType = SYNC_FLUSH
设置Broker同步刷盘策略
设置Broker同步刷盘策略。默认情况下,消息只要到了 Broker 端,将会优先保存到内存中,然后立刻返回确认响应给生产者。随后 Broker 定期批量的将一组消息从内存异步刷入磁盘。这种方式减少 I/O 次数,可以取得更好的性能,但是如果发生机器断电,异常宕机等情况,消息还未及时刷入磁盘,就会出现丢失消息的情况。
若想保证 Broker 端不丢消息,保证消息的可靠性,我们需要将消息保存机制修改为同步刷盘方式,即消息存储磁盘成功,才会返回响应。修改 Broker 端配置如下:
# 默认情况为 ASYNC_FLUSH
flushDiskType = SYNC_FLUSH
若 Broker 未在同步刷盘时间内(默认为 5s)完成刷盘,将会返回 SendStatus.FLUSH_DISK_TIMEOUT 状态给生产者。
等待Master和Slave刷盘完
等待Master和Slave刷盘完。即使Broker设置了同步刷盘策略,但是Broker刷完盘后磁盘坏了,这会导致盘上的消息全丢了。但是如果即使是1主1从了,但是Master刷完盘后还没来得及同步给Slave就磁盘坏了,这会导致盘上的消息全丢了。所以我们还可以配置不仅是等Master刷完盘就通知Producer,而是等Master和Slave都刷完盘后才去通知Producer说消息ok了。
# 默认为 ASYNC_MASTER
brokerRole=SYNC_MASTER
消费阶段
消费失败了其实也是消息丢失的一种变体。
只有当消费模式为 MessageModel.CLUSTERING(集群模式) 时,Broker 才会自动进行重试,对于广播消息是不会重试的。对于一直无法消费成功的消息,RocketMQ 会在达到最大重试次数之后,将该消息投递至死信队列。然后我们需要关注死信队列,并对该死信消息业务做人工的补偿操作。
手动ACK确认
消费者会先把消息拉取到本地,然后进行业务逻辑,业务逻辑完成后手动进行ack确认,这时候才会真正的代表消费完成。而不是说pull到本地后消息就算消费完了。举个例子
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
try{
for (MessageExt msg : msgs) {
String str = new String(msg.getBody());
System.out.println(str);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch(Throwable t){
log.error("消费异常:{}", msgs, t);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
});
消费异常自动重试
- 业务消费方返回 ConsumeConcurrentlyStatus.RECONSUME_LATER
- 业务消费方返回 null
- 业务消费方主动/被动抛出异常
针对以上3种情况下,Broker一般会进行重试(默认最大重试16次),RocketMQ 采用了“时间衰减策略”进行消息的重复投递,即重试次数越多,消息消费成功的可能性越小。我们可以在 RocketMQ 的 broker.conf 配置文件中配置 Consumer 侧重试次数及时间间隔(距离第1次发送的时间间隔), 配置如下:
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
消费者客户端,首先判断消费端有没有显式设置最大重试次数 MaxReconsumeTimes, 如果没有,则设置默认重试次数为 16,否则以设置的最大重试次数为准。
private int getMaxReconsumeTimes() {
// default reconsume times: 16
if (this.defaultMQPushConsumer.getMaxReconsumeTimes() == -1) {
return 16;
} else {
return this.defaultMQPushConsumer.getMaxReconsumeTimes();
}
}
消费超时无线重试
如果是消费超时情况,MQ会无限制的发送给消费端。这种情况就是Consumer端没有返回ConsumeConcurrentlyStatus. CONSUME_SUCCESS,也没有返回ConsumeConcurrentlyStatus.RECONSUME_LATER。
死信队列
死信的处理逻辑:
- 首先判断消息当前重试次数是否大于等于 16,或者消息延迟级别是否小于 0
- 只要满足上述的任意一个条件,设置新的 topic(死信 topic)为:%DLQ%+consumerGroup
- 进行前置属性的添加
- 将死信消息投递到上述步骤 2 建立的死信 topic 对应的死信队列中并落盘,使消息持久化
最后单独启动一个死信队列的消费者进行消费,然后进行人工干预处理失败的消息。
消息幂等
在所有消息系统中消费消息有三种模式:at-most-once(最多一次)、at-least-once(最少一次)和 exactly-only-once(精确仅一次),分布式消息系统都是在三者间取平衡,前两者是可行的并且被广泛使用。
at-most-once:消息投递后不论消息是否被消费成功,不会再重复投递,有可能会导致消息未被消费,RocketMQ 未使用该方式at-lease-once:消息投递后,消费完成后,向服务器返回 ACK,没有消费则一定不会返回 ACK 消息。由于网络异常、客户端重启等原因,服务器未能收到客户端返回的 ACK,服务器则会再次投递,这就会导致可能重复消费,RocketMQ 通过 ACK 来确保消息至少被消费一次exactly-only-once:在分布式系统环境下,如果要实现该模式,巨大的开销不可避免。RocketMQ 没有保证此特性,无法避免消息重复,由业务上进行幂等性处理。必须下面两个条件都满足,才能认为消息是"Exactly Only Once":- 发送消息阶段,不允许发送重复消息
- 消费消息阶段,不允许消费重复的消息
Zookeeper
**下载地址:**http://www.apache.org/dist/zookeeper/
节点角色
Leader
- 负责处理客户端发送的
读、写事务请求。这里的事务请求可以理解这个请求具有事务的 ACID 特性 - 同步
写事务请求给其他节点,且需要保证事务的顺序性 - 状态为 LEADING
Follower
- 负责处理客户端发送的读请求
- 转发写事务请求给 Leader
- 参与 Leader 的选举
- 状态为 FOLLOWING
Observer
和 Follower 一样,唯一不同的是,不参与 Leader 的选举,且状态为 OBSERING。可以用来线性扩展读的 QPS。
核心流程设计
启动阶段 Leader选举
Zookeeper 刚启动的时候,多个节点需要找出一个 Leader。怎么找呢,就是用投票。比如集群中有两个节点,A 和 B,原理图如下所示:
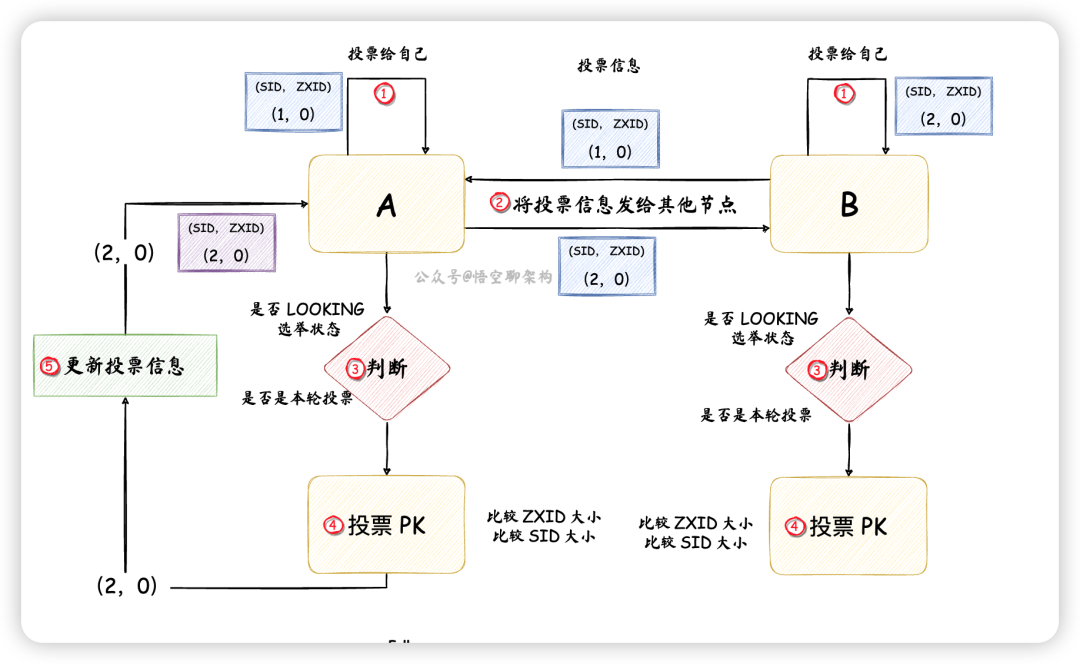
- 节点 A 先
投票给自己,投票信息包含节点 id(SID)和一个ZXID,如 (1,0)。SID 是配置好的,且唯一,ZXID 是唯一的递增编号 - 节点 B 先
投票给自己,投票信息为(2,0) - 然后节点 A 和 B 将自己的投票信息
投票给集群中所有节点 - 节点 A 收到节点 B 的投票信息后,
检查下节点 B 的状态是否是本轮投票,以及是否是正在选举(LOOKING)的状态 - 投票 PK:节点 A 会将自己的投票和别人的投票进行 PK,如果别的节点发过来的 ZXID 较大,则把自己的投票信息
更新为别的节点发过来的投票信息,如果 ZXID 相等,则比较 SID。这里节点 A 和 节点 B 的 ZXID 相同,SID 的话,节点 B 要大些,所以节点 A 更新投票信息为(2,0),然后将投票信息再次发送出去。而节点 B不需要更新投票信息,但是下一轮还需要再次将投票发出去。这个时候节点 A 的投票信息为(2,0),如下图所示:
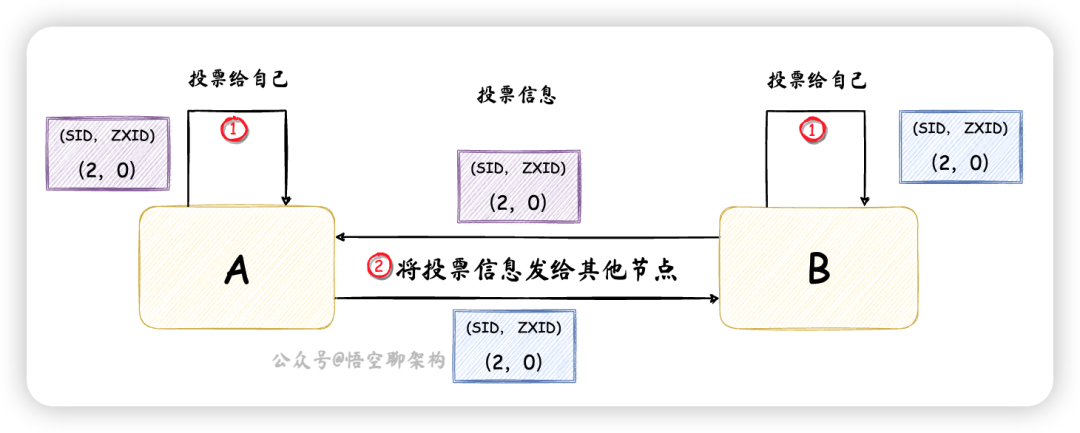
- 统计投票:每一轮投票,都会统计每台节点收到的投票信息,判断是否有
过半的节点收到了相同的投票信息。节点 A 和 节点 B 收到的投票信息都为(2,0),且数量来说,大于一半节点的数量,所以将节点 B 选出来作为 Leader - 更新节点状态:节点 A 作为
Follower,更新状态为 FOLLOWING,节点 B 作为Leader,更新状态为 LEADING
运行期间Leader宕机处理
在 Zookeeper 运行期间,Leader 会一直保持为 LEADING 状态,直到 Leader 宕机了,这个时候就要重新选 Leader,而选举过程和启动阶段的选举过程基本一致。需要注意的点:
- 剩下的 Follower 进行选举,Observer 不参与选举
- 投票信息中的 zxid 用的是本地磁盘日志文件中的。如果这个节点上的 zxid 较大,就会被当选为 Leader。如果 Follower 的 zxid 都相同,则 Follower 的节点 id 较大的会被选为 Leader
节点之间同步数据流程
不同的客户端可以分别连接到主节点或备用节点。而客户端发送读写请求时是不知道自己连的是Leader 还是 Follower,如果客户端连的是主节点,发送了写请求,那么 Leader 执行 2PC(两阶段提交协议)同步给其他 Follower 和 Observer 就可以了。但是如果客户端连的是 Follower,发送了写请求,那么 Follower 会将写请求转发给 Leader,然后 Leader 再进行 2PC 同步数据给 Follower。两阶段提交协议:
- 第一阶段:Leader 先发送 proposal 给 Follower,Follower 发送 ack 响应给 Leader。如果收到的 ack 过半,则进入下一阶段
- 第二阶段: Leader 从磁盘日志文件中加载数据到内存中,Leader 发送 commit 消息给 Follower,Follower 加载数据到内存中
我们来看下 Leader 同步数据的流程:
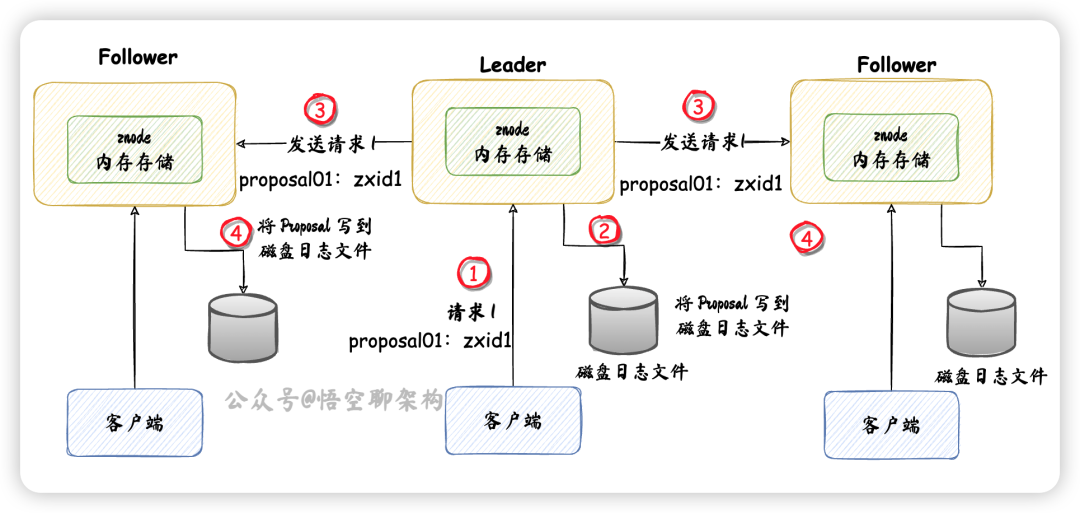
- ① 客户端发送写事务请求
- ② Leader 收到写请求后,转化为一个 "proposal01:zxid1" 事务请求,存到磁盘日志文件
- ③ 发送 proposal 给其他 Follower
- ④ Follower 收到 proposal 后,Follower 写磁盘日志文件
接着我们看下 Follower 收到 Leader 发送的 proposal 事务请求后,怎么处理的:
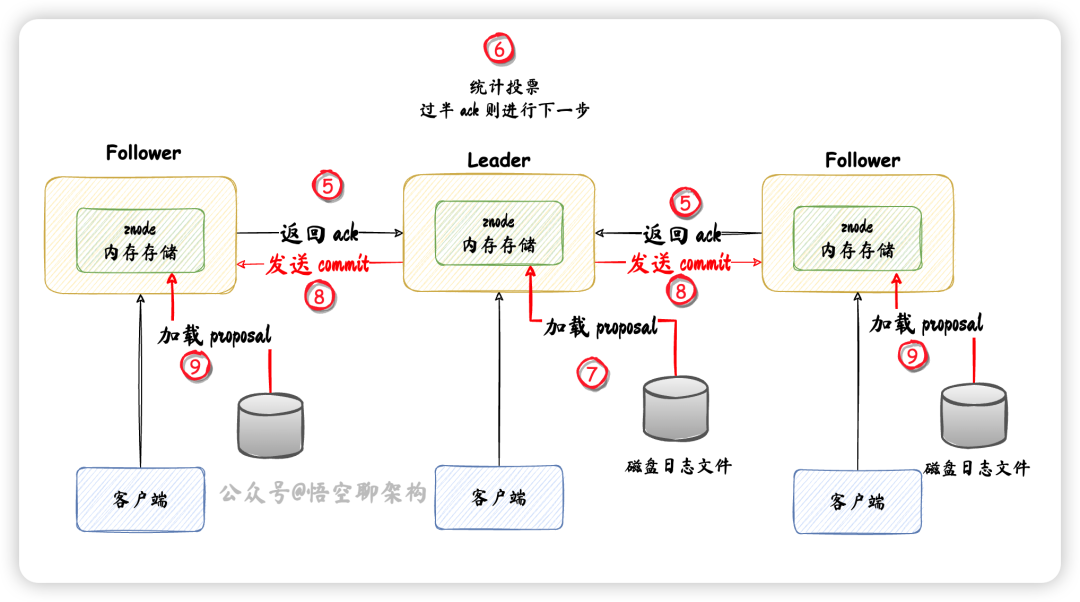
- ⑤ Follower 返回 ack 给 Leader
- ⑥ Leader 收到超过一半的 ack,进行下一阶段
- ⑦ Leader 将磁盘中的日志文件的 proposal 加载到 znode 内存数据结构中
- ⑧ Leader 发送 commit 消息给所有 Follower 和 Observer
- ⑨ Follower 收到 commit 消息后,将 磁盘中数据加载到 znode 内存数据结构中
现在Leader和Follower的数据都是在内存数据中的,且是一致的,客户端从Leader和Follower读到的数据都是一致的。
ZAB顺序一致性原理
Leader 发送 proposal 时,其实会为每个 Follower 创建一个队列,都往各自的队列中发送 proposal。如下图所示是 Zookeeper 的消息广播流程:
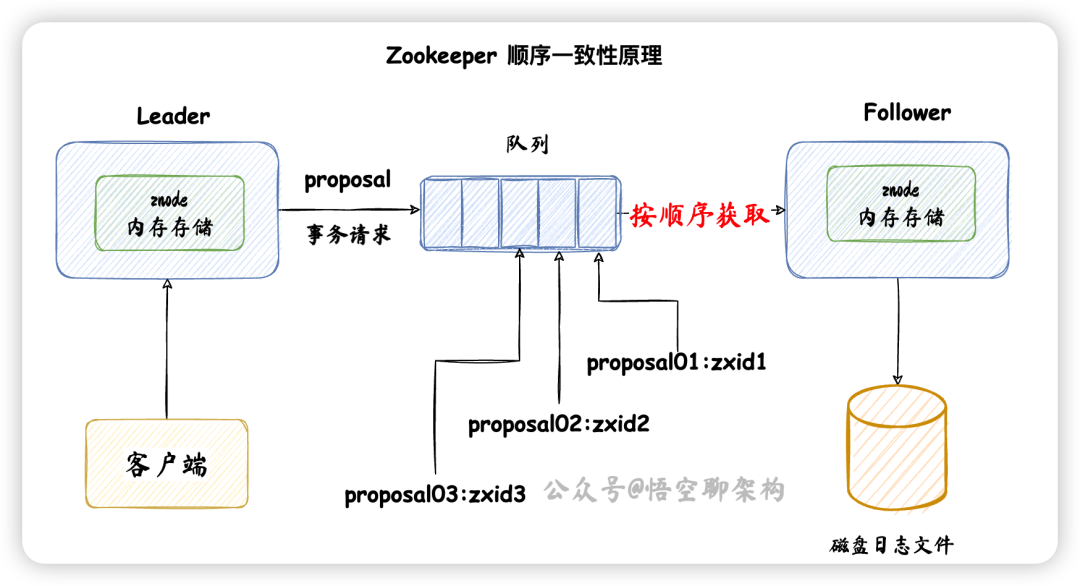
客户端发送了三条写事务请求,对应的 proposal 为
proposal01:zxid1
proposal02:zxid2
proposal03:zxid3
Leader 收到请求后,依次放到队列中,然后 Follower 依次从队列中获取请求,这样就保证了数据的顺序性。
Zookeeper是否是强一致性
官方定义:顺序一致性。
不保证强一致性,为什么呢?
因为 Leader 再发送 commit 消息给所有 Follower 和 Observer 后,它们并不是同时完成 commit 的。比如因为网络原因,不同节点收到的 commit 较晚,那么提交的时间也较晚,就会出现多个节点的数据不一致,但是经过短暂的时间后,所有节点都 commit 后,数据就保持同步了。另外 Zookeeper 支持强一致性,就是手动调用 sync 方法来保证所有节点都 commit 才算成功。
这里有个问题:如果某个节点 commit 失败,那么 Leader 会进行重试吗?如何保证数据的一致性?
Leader 宕机数据丢失问题
第一种情况:假设 Leader 已经将消息写入了本地磁盘,但是还没有发送 proposal 给 Follower,这个时候 Leader 宕机了。那就需要选新的 Leader,新 Leader 发送 proposal 的时候,包含的 zxid 自增规律会发生一次变化:
- zxid 的高 32 位自增 1 一次,高 32 位代表 Leader 的版本号。
- zxid 的低 32 位自增 1,后续还是继续保持自增长。
当老 Leader 恢复后,会转成 Follower,Leader 发送最新的 proposal 给它时,发现本地磁盘的 proposal 的 zxid 的高 32 位小于新 Leader 发送的 proposal,就丢弃自己的 proposal。
第二种情况:如果 Leader 成功发送了 commit 消息给 Follower,但是所有或者部分 Follower 还没来得及 commit 这个 proposal,也就是加载磁盘中的 proposal 到 内存中,这个时候 Leader 宕机了。
那么就需要选出磁盘日志中 zxid 最大的 Follower,如果 zxid 相同,则比较节点 id,节点 id 大的作为 Leader。
ZK特性
Zookeeper主要靠其 分布式数据一致性 为集群提供 分布式协调服务,即指在集群的节点中进行可靠的消息传递,来协调集群的工作。主要具有如下特点:
- **最终一致性:**Client无论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能
- **可靠性:**如果一个消息或事物被一台Server接受,那么它将被所有的服务器接受
- 实时性:Zookeeper不能保证强一致性,只保证顺序一致性和最终一致性,因此称为伪实时性。由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口
- **原子性:**更新只能成功或者失败,没有中间状态
- **顺序性:**包括 全序(Total order) 和 因果顺序(Causal order)
- **全序:**如果消息a在消息b之前发送,则所有Server应该看到相同的结果
- **因果顺序:**如果消息a在消息b之前发生(a导致了b),并被一起发送,则a始终在b之前被执行
ZK角色
- Server(服务端)
- **Leader(领导者):**负责对所有对ZK状态变更的请求,将状态更新请求进行排序与编号,以保证集群内部消息处理的有序性
- Learner(学习者)
- **Follower(追随者):**用于接收客户请求并向客户端返回结果,在选举过程中参与投票
- **Observer(观察者):**其作用是为了扩展集群来提供读取速度,可以接收客户端连接,将写请求转发给Leader节点,但不参与投票,只同步Leader状态
- **Client(客户端):**请求发起方
每个Server在工作过程中有三种状态:
- **LOOKING:**当前Server不知道Leader是谁,正在搜寻
- **LEADING:**当前Server即为选举出来的Leader
- **FOLLOWING:**Leader已经选举出来,当前Server与之同步
Zookeeper集群中,有Leader、Follower和Observer三种角色
-
领导者(Leader):负责进行投票的发起和决议,更新系统状态
Leader服务器是整个ZooKeeper集群工作机制中的核心,其主要工作:
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性
- 集群内部各服务的调度者
-
跟随者(Follower):用于接收客户端请求并给客户端返回结果,在选主过程中进行投票
Follower服务器是ZooKeeper集群状态的跟随者,其主要工作:
- 处理客户端非事务请求,转发事务请求给Leader服务器
- 参与事务请求Proposal的投票
- 参与Leader选举投票
-
观察者(Observer):可以接受客户端连接,将写请求转发给 leader,但是observer 不参加投票的过程,只是为了扩展系统,提高读取的速度
Observer是3.3.0 版本开始引入的一个服务器角色,它充当一个观察者角色——观察ZooKeeper集群的最新状态变化并将这些状态变更同步过来。其工作:
- 处理客户端的非事务请求,转发事务请求给 Leader 服务器
- 不参与任何形式的投票
数据模型
Zookeeper 的数据模型:
- 层次化的目录结构,命名符合常规文件系统规范,类似于Linux
- 每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
- 节点Znode可以包含数据和子节点,但是EPHEMERAL类型的节点不能有子节点
- Znode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
- 客户端应用可以在节点上设置监视器
- 节点不支持部分读写,而是一次性完整读写
Server工作状态
服务器具有四种状态,分别是 LOOKING、FOLLOWING、LEADING、OBSERVING。
- LOOKING:寻找Leader状态。当服务器处于该状态时,它会认为当前集群中没有 Leader,因此需要进入 Leader 选举状态
- FOLLOWING:跟随者状态。表明当前服务器角色是Follower
- LEADING:领导者状态。表明当前服务器角色是Leader
- OBSERVING:观察者状态。表明当前服务器角色是Observer
运行模式
Zookeeper 有三种运行模式:单机模式、伪集群模式和集群模式。
- 单机模式:这种模式一般适用于开发测试环境,一方面我们没有那么多机器资源,另外就是平时的开发调试并不需要极好的稳定性。
- 集群模式:一个 ZooKeeper 集群通常由一组机器组成,一般 3 台以上就可以组成一个可用的 ZooKeeper 集群了。组成 ZooKeeper 集群的每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都会互相保持通信。
- 伪集群模式:这是一种特殊的集群模式,即集群的所有服务器都部署在一台机器上。当你手头上有一台比较好的机器,如果作为单机模式进行部署,就会浪费资源,这种情况下,ZooKeeper 允许你在一台机器上通过启动不同的端口来启动多个 ZooKeeper 服务实例,以此来以集群的特性来对外服务。
Leader选举
服务器启动的Leader选举
zookeeper集群初始化阶段,服务器(myid=1-5)**「依次」**启动,开始zookeeper选举Leader~

-
服务器1(myid=1)启动,当前只有一台服务器,无法完成Leader选举
-
服务器2(myid=2)启动,此时两台服务器能够相互通讯,开始进入Leader选举阶段
-
每个服务器发出一个投票
服务器1 和 服务器2都将自己作为Leader服务器进行投票,投票的基本元素包括:服务器的myid和ZXID,我们以(myid,ZXID)形式表示。初始阶段,服务器1和服务器2都会投给自己,即服务器1的投票为(1,0),服务器2的投票为(2,0),然后各自将这个投票发给集群中的其他所有机器。
-
接受来自各个服务器的投票
每个服务器都会接受来自其他服务器的投票。同时,服务器会校验投票的有效性,是否本轮投票、是否来自LOOKING状态的服务器。
-
处理投票
收到其他服务器的投票,会将别人的投票跟自己的投票PK,PK规则如下:
- 优先检查ZXID。ZXID比较大的服务器优先作为leader。
- 如果ZXID相同的话,就比较myid,myid比较大的服务器作为leader。服务器1的投票是(1,0),它收到投票是(2,0),两者zxid都是0,因为收到的myid=2,大于自己的myid=1,所以它更新自己的投票为(2,0),然后重新将投票发出去。对于服务器2呢,即不再需要更新自己的投票,把上一次的投票信息发出即可。
-
统计投票
每次投票后,服务器会统计所有投票,判断是否有过半的机器接受到相同的投票信息。服务器2收到两票,少于3(n/2+1,n为总服务器5),所以继续保持LOOKING状态
-
-
服务器3(myid=3)启动,继续进入Leader选举阶段
跟前面流程一致,服务器1和2先投自己一票,因为服务器3的myid最大,所以大家把票改投给它。此时,服务器为3票(大于等于n/2+1),所以服务器3当选为Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
-
服务器4启动,发起一次选举。
此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。选票信息结果:服务器3为3票,服务器4为1票。服务器4并更改状态为FOLLOWING;
-
服务器5启动,发起一次选举。
同理,服务器也是把票投给服务器3,服务器5并更改状态为FOLLOWING;
-
投票结束,服务器3当选为Leader
服务器运行期间的Leader选举
zookeeper集群的五台服务器(myid=1-5)正在运行中,突然某个瞬间,Leader服务器3挂了,这时候便开始Leader选举~

-
变更状态
Leader 服务器挂了之后,余下的非Observer服务器都会把自己的服务器状态更改为LOOKING,然后开始进入Leader选举流程。
-
每个服务器发起投票
每个服务器都把票投给自己,因为是运行期间,所以每台服务器的ZXID可能不相同。假设服务1,2,4,5的zxid分别为333,666,999,888,则分别产生投票(1,333),(2,666),(4,999)和(5,888),然后各自将这个投票发给集群中的其他所有机器。
-
接受来自各个服务器的投票
-
处理投票
投票规则是跟Zookeeper集群启动期间一致的,优先检查ZXID,大的优先作为Leader,所以显然服务器zxid=999具有优先权。
-
统计投票
-
改变服务器状态
节点(znode)
① 节点组成
每个znode由4部分组成:
- **path:**即节点名称,用于存放简单可视化的数据
- **stat:**即状态信息,描述该znode的版本,权限等信息
- **data:**与该znode关联的数据
- **children:**该znode下的子节点
② 节点类型
-
PERSISTENT(持久化目录节点)
客户端与zookeeper断开连接后,该节点依旧存在
-
PERSISTENT_SEQUENTIAL(持久化顺序编号目录节点)
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
-
EPHEMERAL(临时目录节点)
客户端与zookeeper断开连接后,该节点被删除
-
EPHEMERAL_SEQUENTIAL(临时顺序编号目录节点)
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
关键词
-
zxid(事务ID号)
ZooKeeper状态的每一次改变,都对应着一个递增的
Transaction id,该id称为zxid。由于zxid的递增性质,如果zxid1小于zxid2,那么zxid1肯定先于zxid2发生。创建任意节点、更新任意节点的数据、删除任意节点,都会导致Zookeeper状态发生改变,从而导致zxid的值增加。 -
session(会话连接)
在Client和Server通信之前,首先需要建立连接,该连接称为session。连接建立后,如果发生连接超时、授权失败或显式关闭连接,连接便处于CLOSED状态,此时session结束。
Watcher监听机制
Zookeeper 允许客户端向服务端的某个Znode注册一个Watcher监听,当服务端的一些指定事件触发了这个Watcher,服务端会向指定客户端发送一个事件通知来实现分布式的通知功能,然后客户端根据 Watcher通知状态和事件类型做出业务上的改变。
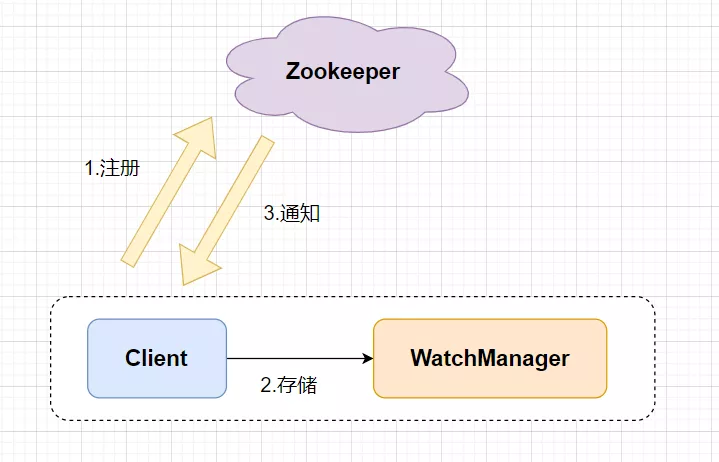
- ZooKeeper的Watcher机制主要包括客户端线程、客户端 WatcherManager、Zookeeper服务器三部分
- 客户端向ZooKeeper服务器注册Watcher的同时,会将Watcher对象存储在客户端的WatchManager中
- 当zookeeper服务器触发watcher事件后,会向客户端发送通知, 客户端线程从 WatcherManager 中取出对应的 Watcher 对象来执行回调逻辑
Watcher特性总结
- 「一次性:」 一个Watch事件是一个一次性的触发器。一次性触发,客户端只会收到一次这样的信息
- 「异步的:」 Zookeeper服务器发送watcher的通知事件到客户端是异步的,不能期望能够监控到节点每次的变化,Zookeeper只能保证最终的一致性,而无法保证强一致性
- 「轻量级:」 Watcher 通知非常简单,它只是通知发生了事件,而不会传递事件对象内容
- 「客户端串行:」 执行客户端 Watcher 回调的过程是一个串行同步的过程
- 注册 watcher用getData、exists、getChildren方法
- 触发 watcher用create、delete、setData方法
ZXID
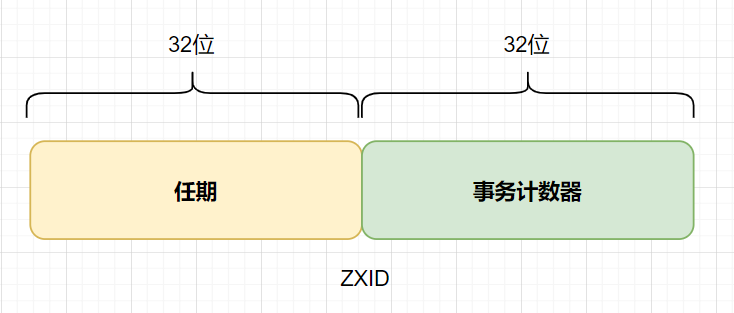
ZXID有两部分组成:
- 任期:完成本次选举后,直到下次选举前,由同一Leader负责协调写入
- 事务计数器:单调递增,每生效一次写入,计数器加一
ZXID的低32位是计数器,所以同一任期内,ZXID是连续的,每个结点又都保存着自身最新生效的ZXID,通过对比新提案的ZXID与自身最新ZXID是否相差“1”,来保证事务严格按照顺序生效的。
工作流程
① 客户端发起的操作的主要流程
Leader可以执行增删改查操作,而Follower只能进行查询操作。所有的更新操作都会被转交给Leader来处理,Leader批准的任务,再发送给Follower去执行来保证和Leader的一致性。由于网络是不稳定的,为了保证执行顺序的一致,所有的任务都会被赋予一个唯一的顺序的编号,一定是按照这个编号来执行任务,保证任务顺序的一致性。
② 客户端的请求什么时候才能算处理成功?为什么说集群过半机器宕机后无法再工作?
Leader在收到客户端提交过来的任务后,会向集群中所有的Follower发送提案等待Follower的投票,Follower们收到这个提议后,会进行投票,同意或者不同意,Leader会回收Follower的投票,一旦受到过半的投票表示同意,则Leader认为这个提案通过,再发送命令要求所有的Follower都进行这个提案中的任务。由于需要过半的机器同意才能执行任务,所以一旦集群中过半的机器挂掉,整个集群就无法工作了。
-
Leader工作流程
Leader主要有三个功能:
- 恢复数据
- 维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型
- Learner的消息类型主要有如下四种,根据不同的消息类型,进行不同的处理:
- **PING消息:**指Learner的心跳信息
- **REQUEST消息:**Follower发送的提议信息,包括写请求及同步请求
- **ACK消息:**Follower的对提议的回复,超过半数的Follower通过,则commit该提议
- **REVALIDATE消息:**用来延长SESSION有效时间
-
Follower工作流程
Follower主要有四个功能:
- 向Leader发送消息请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息)
- 接收Leader消息并进行处理
- 接收Client的请求,如果为写请求,发送给Leader进行投票
- 返回Client结果
Follower的消息循环处理如下几种来自Leader的消息:
- PING消息: 心跳消息
-
**PROPOSAL消息:**Leader发起的提案,要求Follower投票
- **COMMIT消息:**服务器端最新一次提案的信息
- **UPTODATE消息:**表明同步完成
- **REVALIDATE消息:**根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息
- **SYNC消息:**返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新
-
Observer工作流程
对于Observer的流程不再叙述,Observer流程和Follower的唯一不同的地方就是Observer不会参加Leader发起的投票。
ZAB协议
ZooKeeper并没有完全采用Paxos算法,而是使用一种称为ZooKeeper Atomic Broadcast(ZAB,Zookeeper原子消息广播协议)的协议作为其数据一致性的核心算法,简称ZAB协议。ZAB协议分为两种模式:
- **崩溃恢复模式(Recovery):**当服务初次启动或Leader节点挂了时,系统就会进入恢复模式,直到选出了有合法数量Follower的新Leader,然后新Leader负责将整个系统同步到最新状态
- **消息广播模式(Boardcast):**ZAB协议中,所有的写请求都由Leader来处理。正常工作状态下,Leader接收请求并通过广播协议来处理(如:广播提议投票、广播命令)
① 崩溃恢复模式(Recovery)
为了使Leader挂了后系统能正常工作,需要解决以下两个问题:
- 已经被处理的消息不能丢
- 被丢弃的消息不能再次出现
② 消息广播模式(Boardcast)
广播的过程实际上是一个简化的二阶段提交过程:
- Leader 接收到消息请求后,将消息赋予一个全局唯一的 64 位自增 id,叫做:zxid,通过 zxid 的大小比较即可实现因果有序这一特性
- Leader 通过先进先出队列(通过 TCP 协议来实现,以此实现了全局有序这一特性)将带有 zxid 的消息作为一个提案(proposal)分发给所有 follower
- 当 follower 接收到 proposal,先将 proposal 写到硬盘,写硬盘成功后再向 leader 回一个 ACK
- 当 leader 接收到合法数量的 ACKs 后,leader 就向所有 follower 发送 COMMIT 命令,同事会在本地执行该消息
- 当 follower 收到消息的 COMMIT 命令时,就会执行该消息
总结
个人认为 Zab 协议设计的优秀之处有两点,一是简化二阶段提交,提升了在正常工作情况下的性能;二是巧妙地利用率自增序列,简化了异常恢复的逻辑,也很好地保证了顺序处理这一特性。值得注意的是,ZAB提交事务并不像2PC一样需要全部Follower都ACK,只需要得到quorum(超过半数的节点)的ACK就可以了。
③ ZAB 的四个阶段
- **Leader election(选举阶段):**节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准Leader(只有完成ZAB的四个阶段,准Leader才会成为真正的Leader)。本阶段的目的是就是为了选出一个准Leader,然后进入下一个阶段
- **Discovery(发现阶段):**在次阶段,Followers跟准Leader进行通信,同步Followers最近接收的事务提议,这个一阶段的主要目的是发现当前大多数节点接收的最新提议
- **Synchronization(同步阶段):**同步阶段主要是利用Leader前一阶段获得的最新提议历史,同步集群中所有的副本。只有当quorum都同步完成,准Leader才会成为真正的Leader。Follower只会接收zxid比自己的lastZxid大的提议
- **Broadcast(广播阶段):**到了这个阶段,Zookeeper 集群才能正式对外提供事务服务,并且Leader可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步
④ JAVA版ZAB协议
-
Fast Leader Election:Fast Leader Election
前面提到 FLE 会选举拥有最新提议历史(lastZixd最大)的节点作为 leader,这样就省去了发现最新提议的步骤。这是基于拥有最新提议的节点也有最新提交记录的前提。成为 leader 的条件:
- 选epoch最大的
- epoch相等,选 zxid 最大的
- epoch和zxid都相等,选择server id最大的(即配置zoo.cfg中的myid)
-
Recovery Phase:这一阶段Follower发送它们的 lastZixd 给Leader,Leader 根据 lastZixd 决定如何同步数据。这里的实现跟前面 Phase 2 有所不同:Follower 收到 TRUNC 指令会中止 L.lastCommittedZxid 之后的提议,收到 DIFF 指令会接收新的提议。
-
Broadcast Phase:暂无
ZK选举过程
最开始集群启动时,会选择xzid最小的机器作为leader。
当Leader崩溃或者Leader失去大多数的Follower,这时候ZK进入恢复模式,恢复模式需要重新选举出一个新的Leader,让所有的Server都恢复到一个正确的状态。ZK的选举算法使用ZAB协议:
- 选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server
- 选举线程首先向所有Server发起一次询问(包括自己)
- 选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中
- 收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server
- 线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来
分析结论
要使Leader获得多数Server的支持,则Server总数最好是奇数2n+1,且存活的Server的数目不得少于n+1。因为需要过半存活集群才能工作,所以2n个机器提供的集群可靠性其实和2n-1个机器提供的集群可靠性是一样的。
Zookeeper安装
单机模式
第一步:安装部署
# 下载解压
wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz
tar -zxvf zookeeper-3.4.9.tar.gz
# 设置全局变量
vim ~/.bash_profile
# 最后一行加入
export ZOOKEEPER_HOME=/home/zookeeper/zookeeper-3.4.9
export PATH=$ZOOKEEPER_HOME/bin:$PATH
# 使之生效
source ~/.bash_profile
# 复制配置文件
cp /home/zookeeper/zookeeper-3.4.9/conf/zoo_sample.cfg /home/zookeeper/zookeeper-3.4.9/conf/zoo.cfg
第二步:配置信息
# 心跳间隔
tickTime=2000
# 保存数据目录
dataDir=/home/zookeeper/zookeeper-3.4.9/dataDir
# 保存日志目录
dataLogDir=/home/zookeeper/zookeeper-3.4.9/dataLogDir
# 客户端连接Zookeeper的端口
clientPort=2181
# 允许follower连接并同步到leader的初始化连接时间(心跳倍数),超过则连接失败
initLimit=5
# 表示leader和follower之间发送消息时, 请求和应答的最大时间长度
syncLimit=2
集群模式
第一步:安装部署
安装方式参考单机模式。
第二步:配置信息
在dataDir根目录下新建myid文件,并向文件myid中写入值(如:1、2、3……)
# 1表示当前集群的id号
echo "1" > myid
在单机配置情况下,新增下述参数:
# 格式:server.X=A:B:C
# X表示myid(范围1~255)
# A是该server所在的IP地址
# B配置该server和集群中的leader交换消息所使用的端口,即数据同步端口
# C配置选举leader时所使用的端口
server.1=10.24.1.62:2888:3888
server.2=10.24.1.63:2888:3888
server.3=10.24.1.64:2888:3888
运维命令
# 启动ZK服务器
./zkServer.sh start
# 使用ZK Client连接指定服务器
./zkCli.sh -server 127.0.0.1:2181
# 查看ZK服务状态
./zkServer.sh status
# 停止ZK服务
./zkServer.sh stop
# 重启ZK服务
./zkServer.sh restart
zoo.cfg配置参数
# 客户端连接server的端口,默认值2181
clientPort=2181
# 存储快照文件snapshot的目录
dataDir=/User/lry/zookeeper/data
# ZK中的最小时间单元,单位为毫秒
tickTime=5000
# 事务日志输出目录
dataLogDir=/User/lry/zookeeper/datalog
# Server端最大允许的请求堆积数,默认值为1000
globalOutstandingLimit=1000
# 每个事务日志文件的大小,默认值64M
preAllocSize=64
# 每进行snapCount次事务日志输出后,触发一次快照,默认值100000,实际代码中是随机范围触发,避免并发情况
snapCount=100000
# 单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制
maxClientCnxns=60
# 对于多网卡的机器,可以为每个IP指定不同的监听端口。默认是所有IP都监听clientPort指定的端口
clientPortAddress=10.24.22.56
# Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。默认的Session超时时间是在2*tickTime~20*tickTime这个范围
minSessionTimeoutmaxSessionTimeout
# Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许F在 initLimit 时间内完成这个工作。
initLimit
# 在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果L发出心跳包在syncLimit之后,还没有从F那里收到响应,那么就认为这个F已经不在线了。
syncLimit
# 默认情况下,Leader是会接受客户端连接,并提供正常的读写服务。但是,如果你想让Leader专注于集群中机器的协调,那么可以将这个参数设置为no,这样一来,会大大提高写操作的性能
leaderServes=yes
# server.[myid]=[hostname]:[数据同步和其它通讯端口]:[选举投票通讯]
server.x=[hostname]:nnnnn[:nnnnn]
# 对机器分组和权重设置
group.x=nnnnn[:nnnnn]weight.x=nnnnn
# Leader选举过程中,打开一次连接的超时时间,默认是5s
cnxTimeout
# 每个节点最大数据量,是默认是1M
jute.maxbuffer
Netty
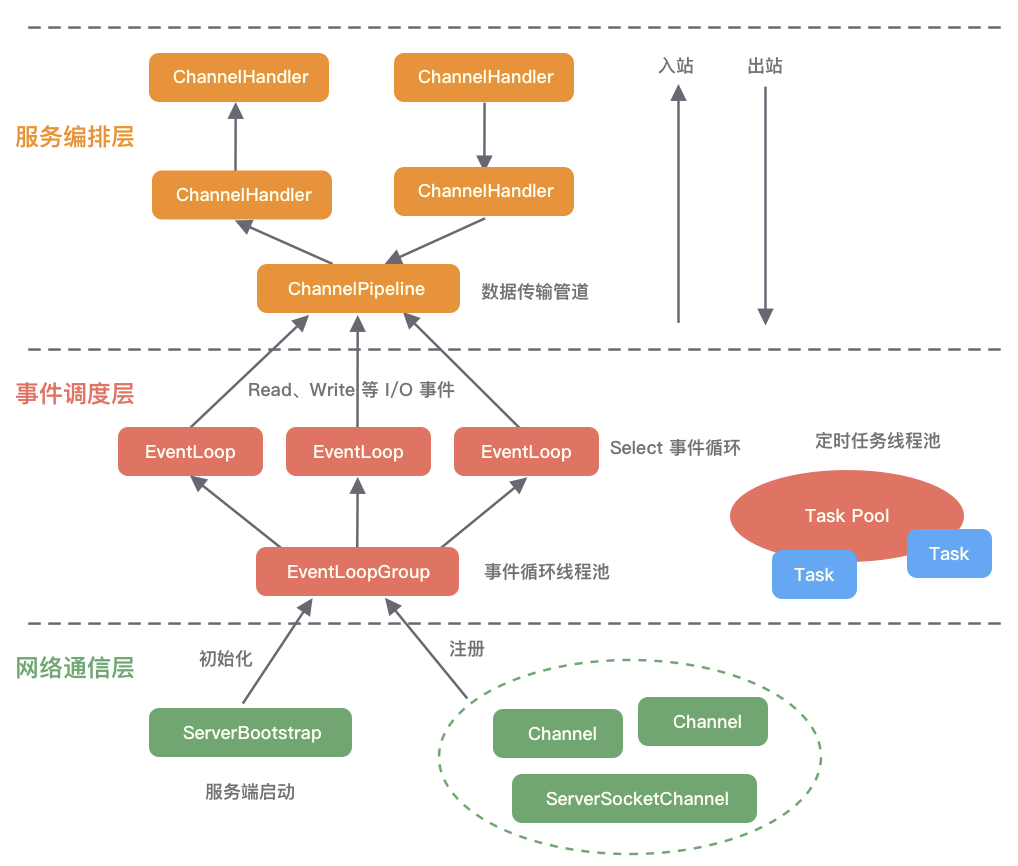
Netty逻辑架构
Netty内部逻辑的流转:
网络通信层
网络通信层的职责是执行网络I/O的操作,它支持多种网络协议和I/O模型的连接操作。当网络数据读取到内核缓冲区后,会触发各种网络事件,这些网络事件会分发给事件调度层进行处理。三个核心组件包括:
-
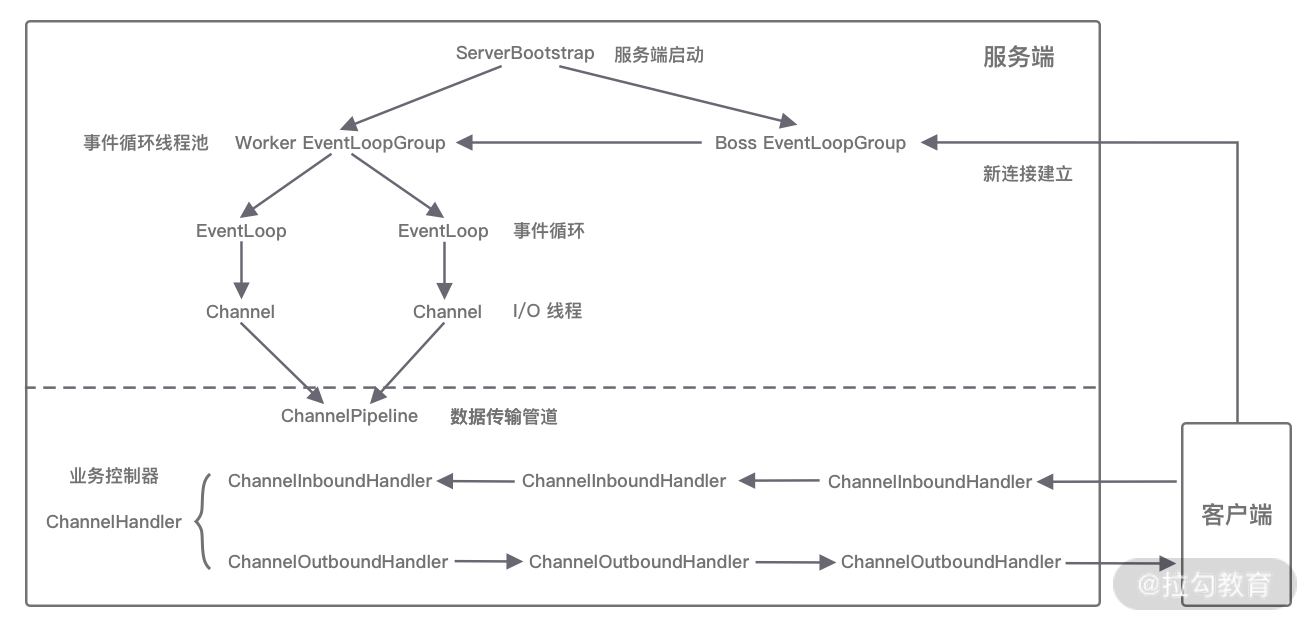
BootStrap和ServerBootStrap
主要负责整个Netty程序的启动、初始化、服务器连接等过程,它相当于一条主线,串联了Netty的其它核心组件。Bootstrap和ServerBootStrap十分相似,两者的区别在于:
- Bootstrap可用于连接远端服务器,只绑定一个EventLoopGroup
- ServerBootStrap则用于服务端启动绑定本地端口,会绑定两个EventLoopGroup,通常称为Boss和Worker(Boss 会不停地接收新的连接,然后将连接分配给一个个Worker处理连接)
-
Channel
提供了基本的API用于网络I/O操作,如register、bind、connect、read、write、flush 等。Netty的Channel是以JDK NIO Channel为基础的,相比较于JDK NIO,Netty的Channel提供了更高层次的抽象,同时屏蔽了底层Socket的复杂性,赋予了Channel更加强大的功能,在使用Netty时基本不需要再与Java Socket类直接打交道。
事件调度层
事件调度层的职责是通过Reactor线程模型对各类事件进行聚合处理,通过Selector主循环线程集成多种事件(I/O事件、信号事件、定时事件等),实际的业务处理逻辑是交由服务编排层中相关的Handler完成。两个核心组件包括:
-
EventLoopGroup、EventLoop
EventLoopGroup是Netty的核心处理引擎,本质是一个线程池,主要负责接收I/O请求,并分配线程执行处理请求。EventLoopGroup的实现类NioEventLoopGroup也是 Netty 中最被推荐使用的线程模型。是基于NIO模型开发的,可以把NioEventLoopGroup理解为一个线程池,每个线程负责处理多个Channel,而同一个Channel只会对应一个线程。
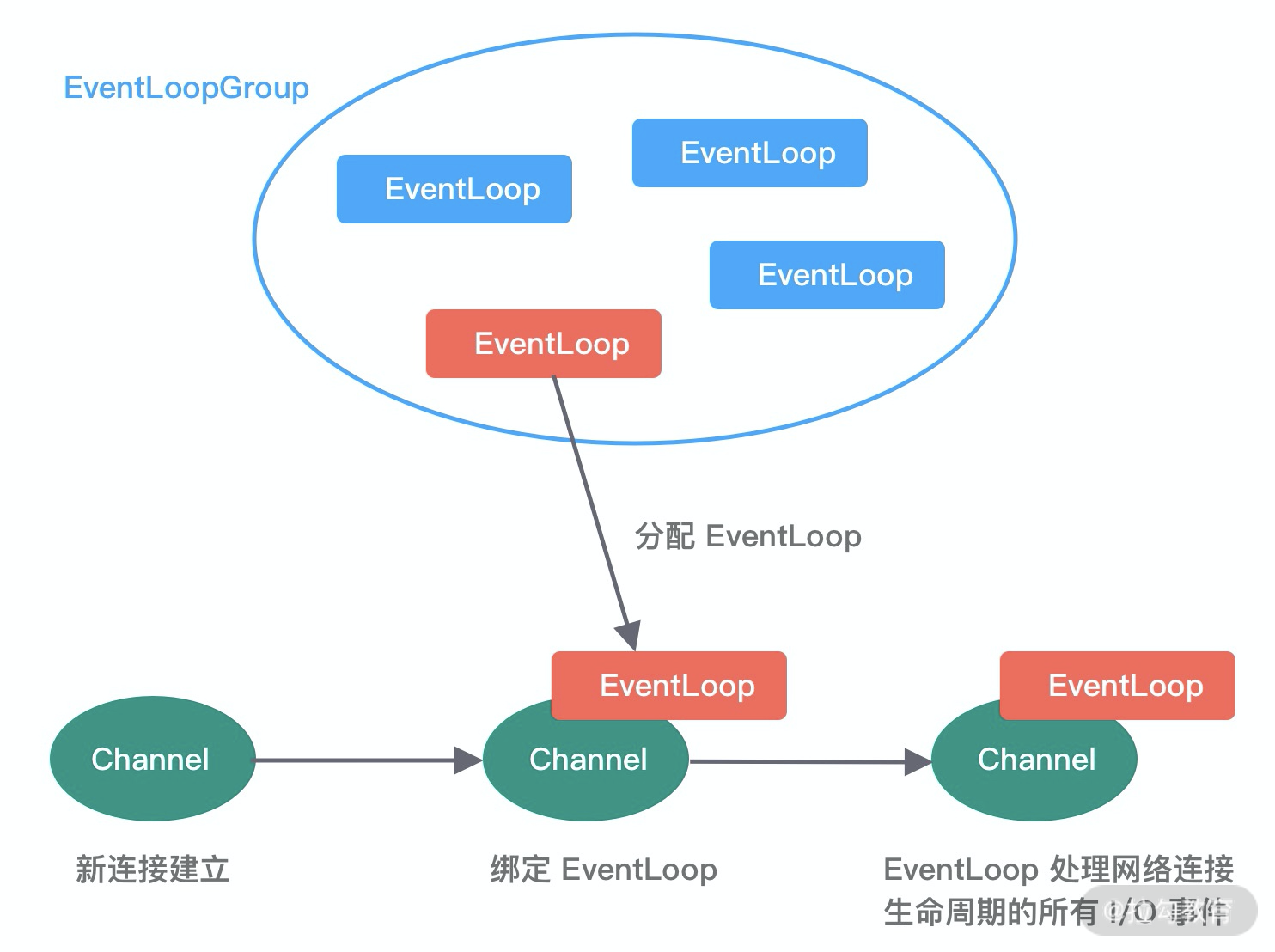
- 一个 EventLoopGroup 往往包含一个或者多个 EventLoop。EventLoop 用于处理 Channel 生命周期内的所有 I/O 事件,如 accept、connect、read、write 等 I/O 事件
- EventLoop 同一时间会与一个线程绑定,每个 EventLoop 负责处理多个 Channel
- 每新建一个 Channel,EventLoopGroup 会选择一个 EventLoop 与其绑定。该 Channel 在生命周期内都可以对 EventLoop 进行多次绑定和解绑
其实EventLoopGroup是Netty Reactor线程模型的具体实现方式,Netty通过创建不同的EventLoopGroup参数配置,就可以支持Reactor的三种线程模型:
- 单线程模型:EventLoopGroup只包含一个EventLoop,Boss和Worker使用同一个EventLoopGroup
- 多线程模型:EventLoopGroup包含多个EventLoop,Boss和Worker使用同一个EventLoopGroup
- 主从多线程模型:EventLoopGroup包含多个EventLoop,Boss是主Reactor,Worker是从Reactor,它们分别使用不同的EventLoopGroup,主Reactor负责新的网络连接Channel创建,然后把Channel注册到从Reactor
服务编排层
服务编排层的职责是负责组装各类服务,是Netty的核心处理链,用以实现网络事件的动态编排和有序传播。核心组件包括:
-
ChannelPipeline
ChannelPipeline 是 Netty 的核心编排组件,负责组装各种 ChannelHandler,实际数据的编解码以及加工处理操作都是由 ChannelHandler 完成的。ChannelPipeline 可以理解为ChannelHandler 的实例列表——内部通过双向链表将不同的 ChannelHandler 链接在一起。当 I/O 读写事件触发时,ChannelPipeline 会依次调用 ChannelHandler 列表对 Channel 的数据进行拦截和处理。
ChannelPipeline 是线程安全的,因为每一个新的 Channel 都会对应绑定一个新的 ChannelPipeline。一个 ChannelPipeline 关联一个 EventLoop,一个 EventLoop 仅会绑定一个线程。
ChannelPipeline、ChannelHandler 都是高度可定制的组件。开发者可以通过这两个核心组件掌握对 Channel 数据操作的控制权。下面我们看一下 ChannelPipeline 的结构图:

ChannelPipeline中包含入站ChannelInboundHandler和出站 ChannelOutboundHandler两种处理器,结合客户端和服务端的数据收发流程:

-
ChannelHandler & ChannelHandlerContext
数据的编解码工作以及其他转换工作实际都是通过 ChannelHandler 处理的。ChannelHandlerContext 用于保存 ChannelHandler 上下文,通过 ChannelHandlerContext 可以知道 ChannelPipeline 和 ChannelHandler 的关联关系。ChannelHandlerContext 可以实现 ChannelHandler 之间的交互,ChannelHandlerContext 包含了 ChannelHandler 生命周期的所有事件,如 connect、bind、read、flush、write、close 等。
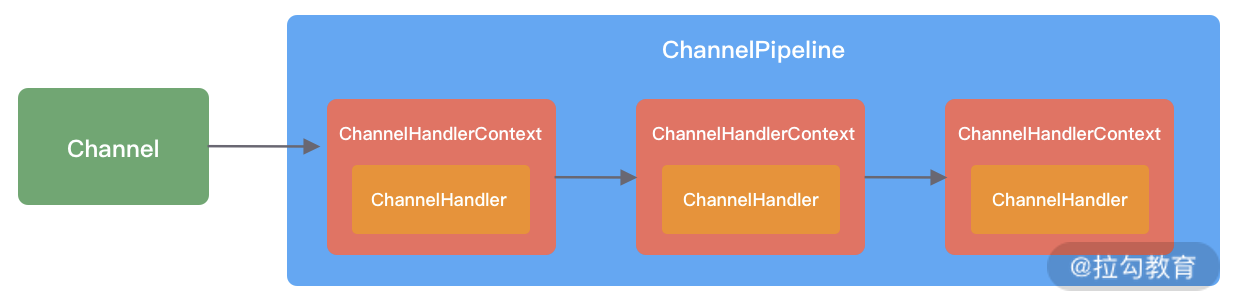
每创建一个 Channel 都会绑定一个新的 ChannelPipeline,ChannelPipeline 中每加入一个 ChannelHandler 都会绑定一个 ChannelHandlerContext。
Reactor线程模型
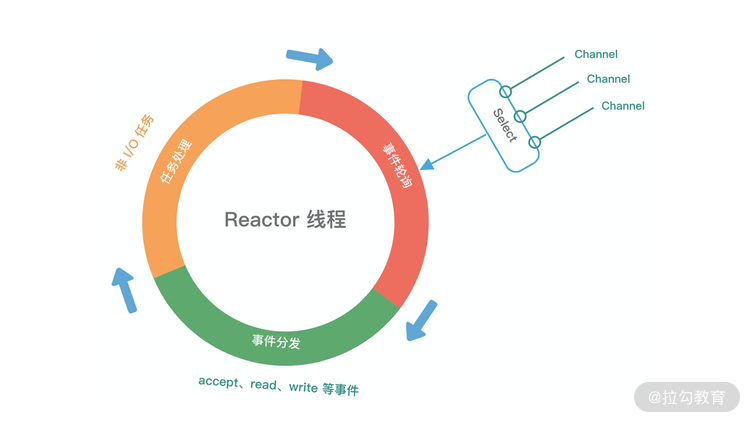
Reactor线程模型运行机制的四个步骤,分别为连接注册、事件轮询、事件分发、任务处理。
- 连接注册:Channel建立后,注册至Reactor线程中的Selector选择器
- 事件轮询:轮询Selector选择器中已注册的所有Channel的I/O事件
- 事件分发:为准备就绪的I/O事件分配相应的处理线程
- 任务处理:Reactor线程还负责任务队列中的非I/O任务,每个Worker线程从各自维护的任务队列中取出任务异步执行
单Reactor单线程
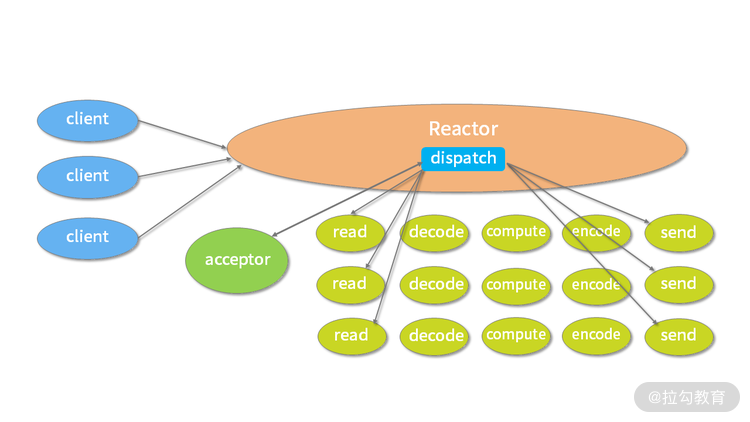
上图描述了 Reactor 的单线程模型结构,在 Reactor 单线程模型中,所有 I/O 操作(包括连接建立、数据读写、事件分发等),都是由一个线程完成的。单线程模型逻辑简单,缺陷也十分明显:
- 一个线程支持处理的连接数非常有限,CPU 很容易打满,性能方面有明显瓶颈
- 当多个事件被同时触发时,只要有一个事件没有处理完,其他后面的事件就无法执行,这就会造成消息积压及请求超时
- 线程在处理 I/O 事件时,Select 无法同时处理连接建立、事件分发等操作
- 如果 I/O 线程一直处于满负荷状态,很可能造成服务端节点不可用
单Reactor多线程
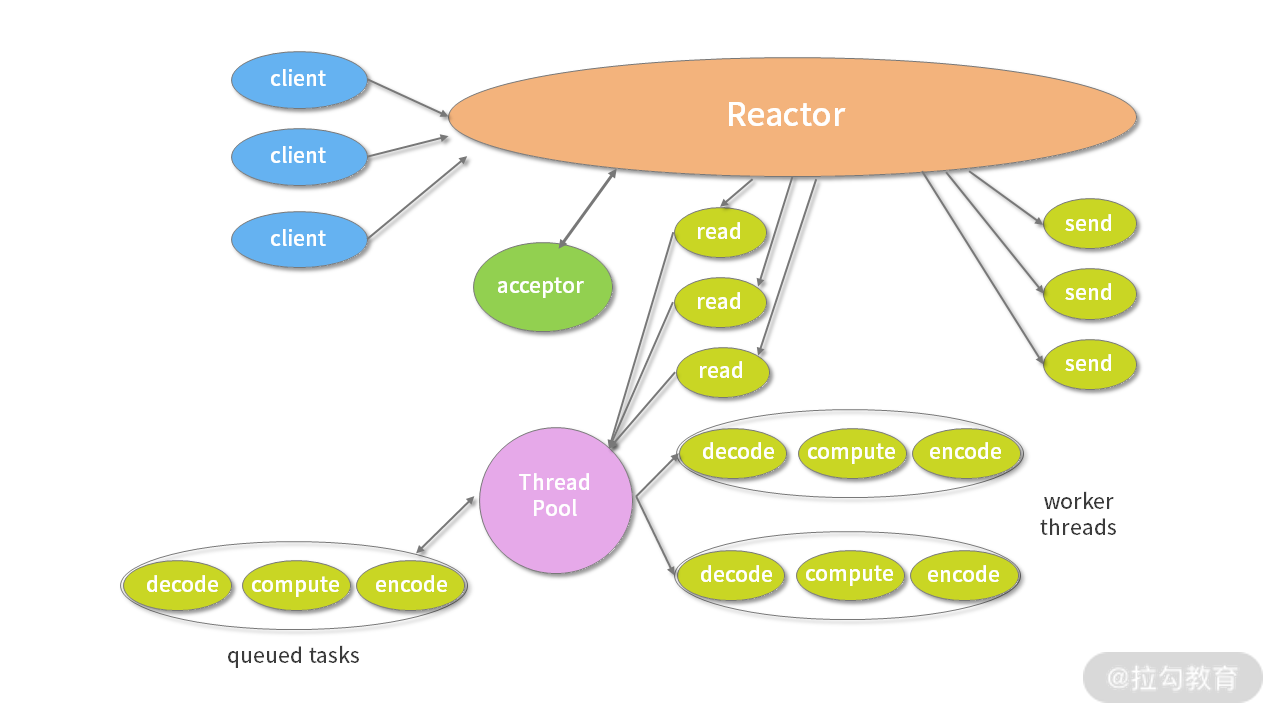
由于单线程模型有性能方面的瓶颈,多线程模型作为解决方案就应运而生了。Reactor 多线程模型将业务逻辑交给多个线程进行处理。除此之外,多线程模型其他的操作与单线程模型是类似的,例如读取数据依然保留了串行化的设计。当客户端有数据发送至服务端时,Select 会监听到可读事件,数据读取完毕后提交到业务线程池中并发处理。
主从Reactor多线程
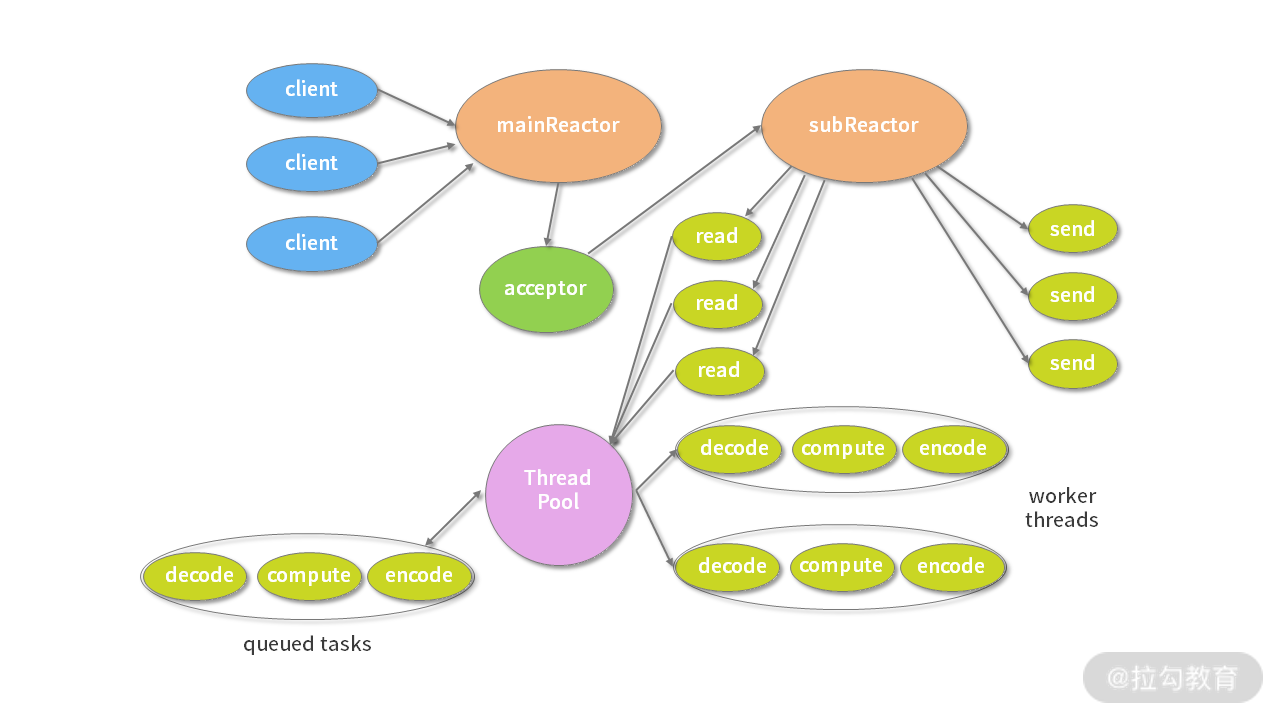
主从多线程模型由多个 Reactor 线程组成,每个 Reactor 线程都有独立的 Selector 对象。MainReactor 仅负责处理客户端连接的 Accept 事件,连接建立成功后将新创建的连接对象注册至 SubReactor。再由 SubReactor 分配线程池中的 I/O 线程与其连接绑定,它将负责连接生命周期内所有的 I/O 事件。
Netty 推荐使用主从多线程模型,这样就可以轻松达到成千上万规模的客户端连接。在海量客户端并发请求的场景下,主从多线程模式甚至可以适当增加 SubReactor 线程的数量,从而利用多核能力提升系统的吞吐量。
核心设计
Netty EventLoop原理
EventLoop 这个概念其实并不是 Netty 独有的,它是一种事件等待和处理的程序模型,可以解决多线程资源消耗高的问题。例如 Node.js 就采用了 EventLoop 的运行机制,不仅占用资源低,而且能够支撑了大规模的流量访问。
EventLoop 可以说是 Netty 的调度中心,负责监听多种事件类型:I/O 事件、信号事件、定时事件等。
EventLoop运行模式
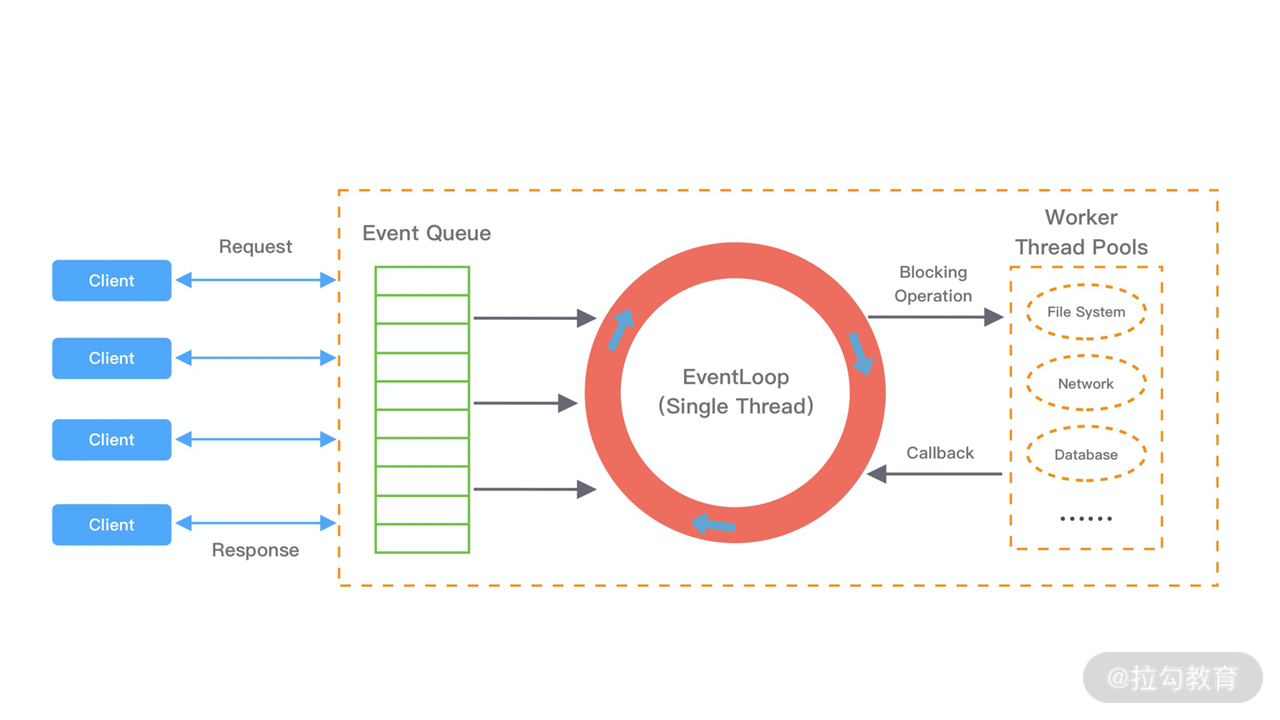
上图展示了 EventLoop 通用的运行模式。每当事件发生时,应用程序都会将产生的事件放入事件队列当中,然后 EventLoop 会轮询从队列中取出事件执行或者将事件分发给相应的事件监听者执行。事件执行的方式通常分为立即执行、延后执行、定期执行几种。
NioEventLoop原理
在 Netty 中 EventLoop 可以理解为 Reactor 线程模型的事件处理引擎,每个 EventLoop 线程都维护一个 Selector 选择器和任务队列 taskQueue。它主要负责处理 I/O 事件、普通任务和定时任务。Netty 中推荐使用 NioEventLoop 作为实现类,那么 Netty 是如何实现 NioEventLoop 的呢?首先我们来看 NioEventLoop 最核心的 run() 方法源码:
protected void run() {
for (;;) {
try {
try {
switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.BUSY_WAIT:
case SelectStrategy.SELECT:
// 轮询 I/O 事件
select(wakenUp.getAndSet(false));
if (wakenUp.get()) {
selector.wakeup();
}
default:
}
} catch (IOException e) {
rebuildSelector0();
handleLoopException(e);
continue;
}
cancelledKeys = 0;
needsToSelectAgain = false;
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
try {
// 处理 I/O 事件
processSelectedKeys();
} finally {
// 处理所有任务
runAllTasks();
}
} else {
final long ioStartTime = System.nanoTime();
try {
// 处理 I/O 事件
processSelectedKeys();
} finally {
final long ioTime = System.nanoTime() - ioStartTime;
// 处理完 I/O 事件,再处理异步任务队列
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
}
} catch (Throwable t) {
handleLoopException(t);
}
try {
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
return;
}
}
} catch (Throwable t) {
handleLoopException(t);
}
}
}
上述源码的结构比较清晰,NioEventLoop 每次循环的处理流程都包含事件轮询 select、事件处理 processSelectedKeys、任务处理 runAllTasks 几个步骤,是典型的 Reactor 线程模型的运行机制。而且 Netty 提供了一个参数 ioRatio,可以调整 I/O 事件处理和任务处理的时间比例。下面我们将着重从事件处理和任务处理两个核心部分出发,详细介绍 Netty EventLoop 的实现原理。
事件处理机制
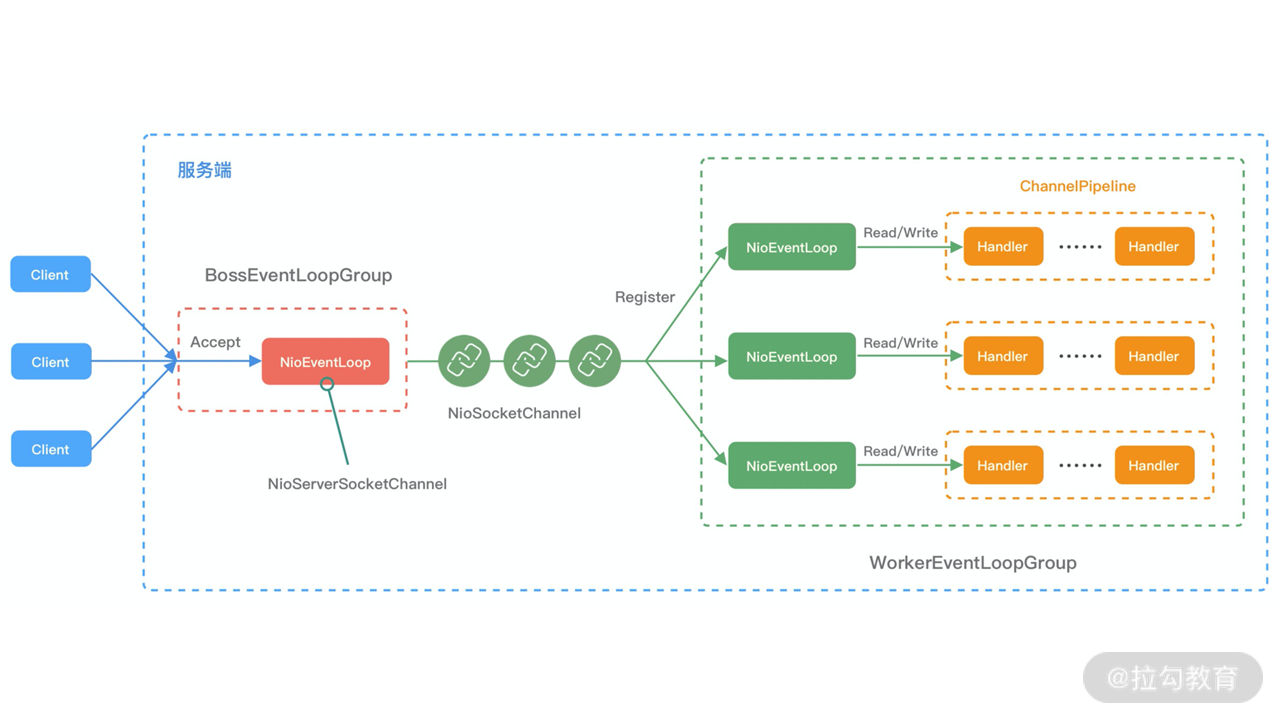
结合Netty的整体架构,看上述EventLoop的事件流转图,以便更好地理解 Netty EventLoop 的设计原理。NioEventLoop 的事件处理机制采用的是无锁串行化的设计思路:
-
BossEventLoopGroup 和 WorkerEventLoopGroup 包含一个或者多个 NioEventLoop
BossEventLoopGroup 负责监听客户端的 Accept 事件,当事件触发时,将事件注册至 WorkerEventLoopGroup 中的一个 NioEventLoop 上。每新建一个 Channel, 只选择一个 NioEventLoop 与其绑定。所以说 Channel 生命周期的所有事件处理都是线程独立的,不同的 NioEventLoop 线程之间不会发生任何交集。
-
NioEventLoop 完成数据读取后,会调用绑定的 ChannelPipeline 进行事件传播
ChannelPipeline 也是线程安全的,数据会被传递到 ChannelPipeline 的第一个 ChannelHandler 中。数据处理完成后,将加工完成的数据再传递给下一个 ChannelHandler,整个过程是串行化执行,不会发生线程上下文切换的问题。
NioEventLoop 无锁串行化的设计不仅使系统吞吐量达到最大化,而且降低了用户开发业务逻辑的难度,不需要花太多精力关心线程安全问题。虽然单线程执行避免了线程切换,但是它的缺陷就是不能执行时间过长的 I/O 操作,一旦某个 I/O 事件发生阻塞,那么后续的所有 I/O 事件都无法执行,甚至造成事件积压。在使用 Netty 进行程序开发时,我们一定要对 ChannelHandler 的实现逻辑有充分的风险意识。
NioEventLoop 线程的可靠性至关重要,一旦 NioEventLoop 发生阻塞或者陷入空轮询,就会导致整个系统不可用。在 JDK 中, Epoll 的实现是存在漏洞的,即使 Selector 轮询的事件列表为空,NIO 线程一样可以被唤醒,导致 CPU 100% 占用。这就是臭名昭著的 JDK epoll 空轮询的 Bug。Netty 作为一个高性能、高可靠的网络框架,需要保证 I/O 线程的安全性。那么它是如何解决 JDK epoll 空轮询的 Bug 呢?实际上 Netty 并没有从根源上解决该问题,而是巧妙地规避了这个问题。
抛开其它细枝末节,直接定位到事件轮询select()方法中的最后一部分代码,一起看下Netty是如何解决epoll空轮询的Bug:
long time = System.nanoTime();
if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) {
selectCnt = 1;
} else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
selector = selectRebuildSelector(selectCnt);
selectCnt = 1;
break;
}
Netty提供了一种检测机制判断线程是否可能陷入空轮询,具体的实现方式如下:
- 每次执行 select 操作之前记录当前时间 currentTimeNanos
- time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos,如果事件轮询的持续时间大于等于 timeoutMillis,那么说明是正常的,否则表明阻塞时间并未达到预期,可能触发了空轮询的 Bug
- Netty 引入了计数变量 selectCnt。在正常情况下,selectCnt 会重置,否则会对 selectCnt 自增计数。当 selectCnt 达到 SELECTOR_AUTO_REBUILD_THRESHOLD(默认512) 阈值时,会触发重建 Selector 对象
Netty 采用这种方法巧妙地规避了 JDK Bug。异常的 Selector 中所有的 SelectionKey 会重新注册到新建的 Selector 上,重建完成之后异常的 Selector 就可以废弃了。
任务处理机制
NioEventLoop 不仅负责处理 I/O 事件,还要兼顾执行任务队列中的任务。任务队列遵循 FIFO 规则,可以保证任务执行的公平性。NioEventLoop 处理的任务类型基本可以分为三类:
- 普通任务:通过 NioEventLoop 的 execute() 方法向任务队列 taskQueue 中添加任务。例如 Netty 在写数据时会封装 WriteAndFlushTask 提交给 taskQueue。taskQueue 的实现类是多生产者单消费者队列 MpscChunkedArrayQueue,在多线程并发添加任务时,可以保证线程安全
- 定时任务:通过调用 NioEventLoop 的 schedule() 方法向定时任务队列 scheduledTaskQueue 添加一个定时任务,用于周期性执行该任务。例如,心跳消息发送等。定时任务队列 scheduledTaskQueue 采用优先队列 PriorityQueue 实现
- 尾部队列:tailTasks 相比于普通任务队列优先级较低,在每次执行完 taskQueue 中任务后会去获取尾部队列中任务执行。尾部任务并不常用,主要用于做一些收尾工作,例如统计事件循环的执行时间、监控信息上报等
下面结合任务处理 runAllTasks 的源码结构,分析下 NioEventLoop 处理任务的逻辑,源码实现如下:
protected boolean runAllTasks(long timeoutNanos) {
// 1. 合并定时任务到普通任务队列
fetchFromScheduledTaskQueue();
// 2. 从普通任务队列中取出任务
Runnable task = pollTask();
if (task == null) {
afterRunningAllTasks();
return false;
}
// 3. 计算任务处理的超时时间
final long deadline = ScheduledFutureTask.nanoTime() + timeoutNanos;
long runTasks = 0;
long lastExecutionTime;
for (;;) {
// 4. 安全执行任务
safeExecute(task);
runTasks ++;
// 5. 每执行 64 个任务检查一下是否超时
if ((runTasks & 0x3F) == 0) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
if (lastExecutionTime >= deadline) {
break;
}
}
task = pollTask();
if (task == null) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
break;
}
}
// 6. 收尾工作
afterRunningAllTasks();
this.lastExecutionTime = lastExecutionTime;
return true;
}
在代码中以注释的方式标注了具体的实现步骤,可以分为 6 个步骤:
- fetchFromScheduledTaskQueue函数:将定时任务从 scheduledTaskQueue 中取出,聚合放入普通任务队列 taskQueue 中,只有定时任务的截止时间小于当前时间才可以被合并
- 从普通任务队列taskQueue中取出任务
- 计算任务执行的最大超时时间
- safeExecute函数:安全执行任务,实际直接调用的 Runnable 的 run() 方法
- 每执行 64 个任务进行超时时间的检查:如果执行时间大于最大超时时间,则立即停止执行任务,避免影响下一轮的 I/O 事件的处理
- 最后获取尾部队列中的任务执行
EventLoop最佳实践
在日常开发中用好 EventLoop 至关重要,这里结合实际工作中的经验给出一些 EventLoop 的最佳实践方案:
- 网络连接建立过程中三次握手、安全认证的过程会消耗不少时间。这里建议采用 Boss 和 Worker 两个 EventLoopGroup,有助于分担 Reactor 线程的压力
- 由于 Reactor 线程模式适合处理耗时短的任务场景,对于耗时较长的 ChannelHandler 可以考虑维护一个业务线程池,将编解码后的数据封装成 Task 进行异步处理,避免 ChannelHandler 阻塞而造成 EventLoop 不可用
- 如果业务逻辑执行时间较短,建议直接在 ChannelHandler 中执行。例如编解码操作,这样可以避免过度设计而造成架构的复杂性
- 不宜设计过多的 ChannelHandler。对于系统性能和可维护性都会存在问题,在设计业务架构的时候,需要明确业务分层和 Netty 分层之间的界限。不要一味地将业务逻辑都添加到 ChannelHandler 中
ChannelPipeline
Pipeline 的字面意思是管道、流水线。它在 Netty 中起到的作用,和一个工厂的流水线类似。原始的网络字节流经过 Pipeline,被一步步加工包装,最后得到加工后的成品。是Netty的核心处理链,用以实现网络事件的动态编排和有序传播。
ChannelPipeline内部结构
ChannelPipeline 可以看作是 ChannelHandler 的容器载体,它是由一组 ChannelHandler 实例组成的,内部通过双向链表将不同的 ChannelHandler 链接在一起,如下图所示。当有 I/O 读写事件触发时,ChannelPipeline 会依次调用 ChannelHandler 列表对 Channel 的数据进行拦截和处理。
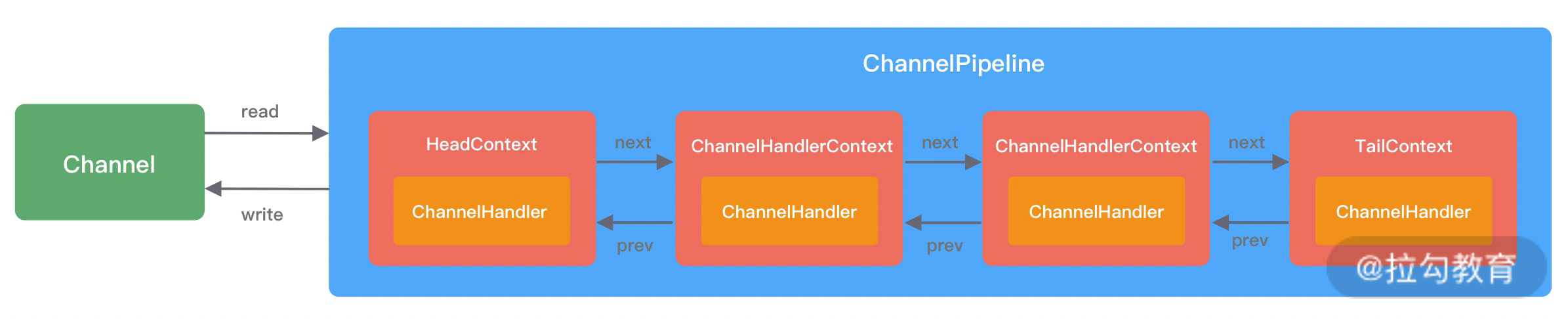
根据网络数据的流向,ChannelPipeline 分为入站 ChannelInboundHandler 和出站 ChannelOutboundHandler 两种处理器。在客户端与服务端通信的过程中,数据从客户端发向服务端的过程叫出站,反之称为入站。

ChannelHandler接口设计
整个ChannelHandler是围绕I/O事件的生命周期所设计的,如建立连接、读数据、写数据、连接销毁等。ChannelHandler 有两个重要的子接口:ChannelInboundHandler和ChannelOutboundHandler,分别拦截入站和出站的各种 I/O 事件。
① ChannelInboundHandler的事件回调方法与触发时机
| 事件回调方法 | 触发时机 |
|---|---|
| channelRegistered | Channel 被注册到 EventLoop |
| channelUnregistered | Channel 从 EventLoop 中取消注册 |
| channelActive | Channel 处于就绪状态,可以被读写 |
| channelInactive | Channel 处于非就绪状态Channel 可以从远端读取到数据 |
| channelRead | Channel 可以从远端读取到数据 |
| channelReadComplete | Channel 读取数据完成 |
| userEventTriggered | 用户事件触发时 |
| channelWritabilityChanged | Channel 的写状态发生变化 |
② ChannelOutboundHandler的事件回调方法与触发时机
ChannelOutboundHandler 的事件回调方法非常清晰,直接通过 ChannelOutboundHandler 的接口列表可以看到每种操作所对应的回调方法,如下图所示。这里每个回调方法都是在相应操作执行之前触发,在此就不多做赘述了。此外 ChannelOutboundHandler 中绝大部分接口都包含ChannelPromise 参数,以便于在操作完成时能够及时获得通知。
ChannelPipeline事件传播机制
上述ChannelPipeline可分为入站 ChannelInboundHandler 和出站 ChannelOutboundHandler 两种处理器,与此对应传输的事件类型可以分为Inbound 事件和Outbound 事件。
-
Inbound事件:传播方向为Head->Tail,即按照添加的顺序进行正向传播(A→B→C)
-
Outbound事件:传播方向为Tail->Head,即按照添加的顺序进行反向传播(C→B→A)
代码示例体验 ChannelPipeline 的事件传播机制:
serverBootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline()
.addLast(new SampleInBoundHandler("SampleInBoundHandlerA", false))
.addLast(new SampleInBoundHandler("SampleInBoundHandlerB", false))
.addLast(new SampleInBoundHandler("SampleInBoundHandlerC", true));
ch.pipeline()
.addLast(new SampleOutBoundHandler("SampleOutBoundHandlerA"))
.addLast(new SampleOutBoundHandler("SampleOutBoundHandlerB"))
.addLast(new SampleOutBoundHandler("SampleOutBoundHandlerC"));
}
}
执行结果:
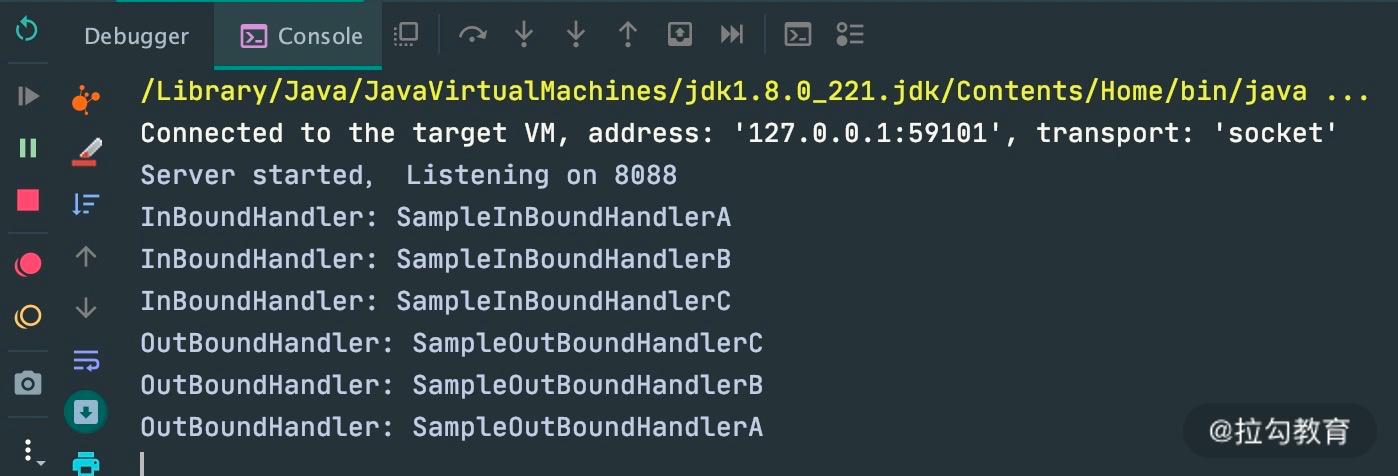
ChannelPipeline异常传播机制
ChannelPipeline 事件传播的实现采用了经典的责任链模式,调用链路环环相扣。那么如果有一个节点处理逻辑异常会出现什么现象呢?ctx.fireExceptionCaugh 会将异常按顺序从 Head 节点传播到 Tail 节点。如果用户没有对异常进行拦截处理,最后将由 Tail 节点统一处理。

建议用户自定义的异常处理器代码示例如下:
public class ExceptionHandler extends ChannelDuplexHandler {
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
if (cause instanceof RuntimeException) {
System.out.println("Handle Business Exception Success.");
}
}
}
加入统一的异常处理器后,可以看到异常已经被优雅地拦截并处理掉了。这也是 Netty 推荐的最佳异常处理实践。
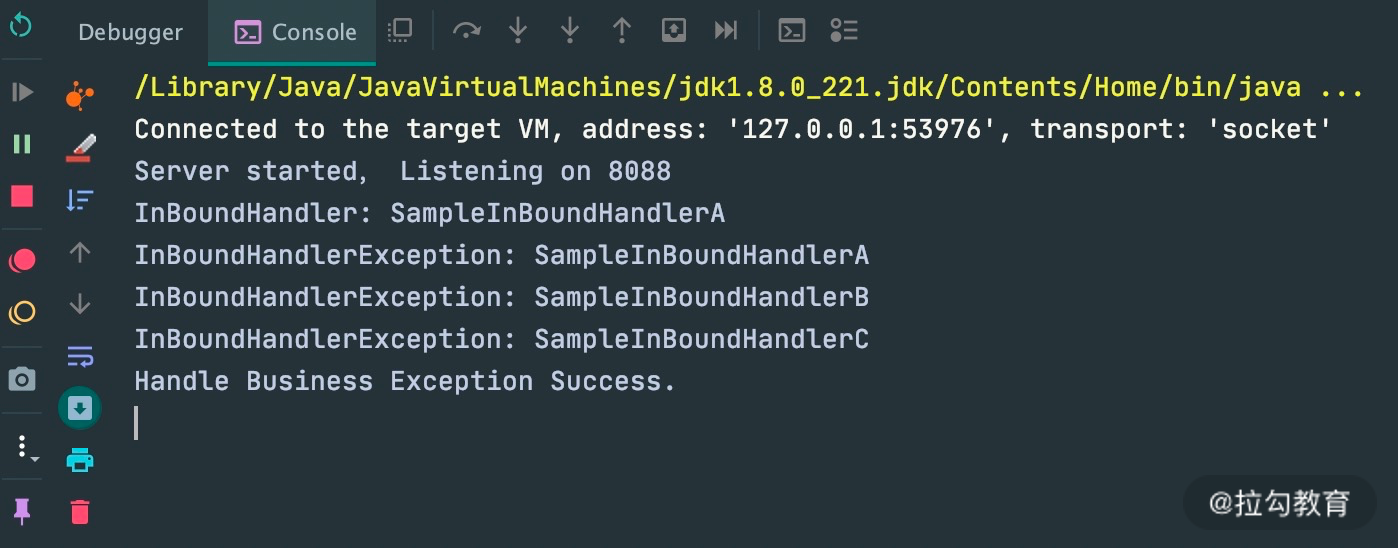
定时器TimerTask
时间轮HashedWheelTimer
时间轮其实就是一种环形的数据结构,可以想象成时钟,分成很多格子,一个格子代表一段时间。并用一个链表保存在该格子上的计划任务,同时一个指针随着时间一格一格转动,并执行相应格子中的所有到期任务。任务通过时间取模决定放入那个格子。
在网络通信中管理上万的连接,每个连接都有超时任务,如果为每个任务启动一个Timer超时器,那么会占用大量资源。为了解决这个问题,可用Netty工具类HashedWheelTimer。
Netty 的时间轮 HashedWheelTimer 给出了一个粗略的定时器实现,之所以称之为粗略的实现是因为该时间轮并没有严格的准时执行定时任务,而是在每隔一个时间间隔之后的时间节点执行,并执行当前时间节点之前到期的定时任务。
当然具体的定时任务的时间执行精度可以通过调节 HashedWheelTimer 构造方法的时间间隔的大小来进行调节,在大多数网络应用的情况下,由于 IO 延迟的存在,并不会严格要求具体的时间执行精度,所以默认的 100ms 时间间隔可以满足大多数的情况,不需要再花精力去调节该时间精度。
HashedWheelTimer的特点
- 从源码分析可以看出,其实 HashedWheelTimer 的时间精度并不高,误差能够在 100ms 左右,同时如果任务队列中的等待任务数量过多,可能会产生更大的误差
- 但是 HashedWheelTimer 能够处理非常大量的定时任务,且每次定位到要处理任务的候选集合链表只需要 O(1) 的时间,而 Timer 等则需要调整堆,是 O(logN) 的时间复杂度
- HashedWheelTimer 本质上是
模拟了时间的轮盘,将大量的任务拆分成了一个个的小任务列表,能够有效节省 CPU 和线程资源
源码解读
public HashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit,
int ticksPerWheel, boolean leakDetection, long maxPendingTimeouts) {
......
}
threadFactory:自定义线程工厂,用于创建线程对象tickDuration:间隔多久走到下一槽(相当于时钟走一格)unit:定义tickDuration的时间单位ticksPerWheel:一圈有多个槽leakDetection:是否开启内存泄漏检测maxPendingTimeouts:最多待执行的任务个数。0或负数表示无限制
优缺点
- 优点
- 可以添加、删除、取消定时任务
- 能高效的处理大批定时任务
- 缺点
- 对内存要求较高,占用较高的内存
- 时间精度要求不高
定时任务方案
目前主流的一些定时任务方案:
- Timer
- ScheduledExecutorService
- ThreadPoolTaskScheduler(基于ScheduledExecutorService)
- Netty的schedule(用到了PriorityQueue)
- Netty的HashedWheelTimer(时间轮)
- Kafka的TimingWheel(层级时间轮)
使用案例:
// 构造一个 Timer 实例
Timer timer = new HashedWheelTimer();
// 提交一个任务,让它在 5s 后执行
Timeout timeout1 = timer.newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) {
System.out.println("5s 后执行该任务");
}
}, 5, TimeUnit.SECONDS);
// 再提交一个任务,让它在 10s 后执行
Timeout timeout2 = timer.newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) {
System.out.println("10s 后执行该任务");
}
}, 10, TimeUnit.SECONDS);
// 取消掉那个 5s 后执行的任务
if (!timeout1.isExpired()) {
timeout1.cancel();
}
// 原来那个 5s 后执行的任务,已经取消了。这里我们反悔了,我们要让这个任务在 3s 后执行
// 我们说过 timeout 持有上、下层的实例,所以下面的 timer 也可以写成 timeout1.timer()
timer.newTimeout(timeout1.task(), 3, TimeUnit.SECONDS);
无锁队列mpsc queue
FastThreadLocal
ByteBuf
编解码协议
netty-codec模块主要负责编解码工作,通过编解码实现原始字节数据与业务实体对象之间的相互转化。Netty支持大多数业界主流协议的编解码器,如HTTP、HTTP2、Redis、XML等,为开发者节省了大量的精力。此外该模块提供了抽象的编解码类ByteToMessageDecoder和MessageToByteEncoder,通过继承这两个类可以轻松实现自定义的编解码逻辑。
拆包粘包
-
拆包/粘包的解决方案
-
消息长度固定:每个数据报文都需要一个固定的长度。当接收方累计读取到固定长度的报文后,就认为已经获得一个完整的消息。当发送方的数据小于固定长度时,则需要空位补齐。消息定长法使用非常简单,但是缺点也非常明显,无法很好设定固定长度的值,如果长度太大会造成字节浪费,长度太小又会影响消息传输,所以在一般情况下消息定长法不会被采用。
-
特定分隔符
既然接收方无法区分消息的边界,那么我们可以在每次发送报文的尾部加上特定分隔符,接收方就可以根据特殊分隔符进行消息拆分。
-
消息长度 + 消息内容
消息长度 + 消息内容是项目开发中最常用的一种协议,如上展示了该协议的基本格式。消息头中存放消息的总长度,例如使用 4 字节的 int 值记录消息的长度,消息体实际的二进制的字节数据。接收方在解析数据时,首先读取消息头的长度字段 Len,然后紧接着读取长度为 Len 的字节数据,该数据即判定为一个完整的数据报文。
-
核心流程
服务端启动流程
Netty 服务端的启动过程大致分为三个步骤:
- 配置线程池
- Channel 初始化
- 端口绑定
配置线程池
单线程模式 Reactor 单线程模型所有 I/O 操作都由一个线程完成,所以只需要启动一个 EventLoopGroup 即可。
EventLoopGroup group = new NioEventLoopGroup(1);
ServerBootstrap b = new ServerBootstrap();
b.group(group);
多线程模式 Reactor 单线程模型有非常严重的性能瓶颈,因此 Reactor 多线程模型出现了。在 Netty 中使用 Reactor 多线程模型与单线程模型非常相似,区别是 NioEventLoopGroup 可以不需要任何参数,它默认会启动 2 倍 CPU 核数的线程。当然,你也可以自己手动设置固定的线程数。
EventLoopGroup group = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(group);
主从多线程模式 在大多数场景下,我们采用的都是主从多线程 Reactor 模型。Boss 是主 Reactor,Worker 是从 Reactor。它们分别使用不同的 NioEventLoopGroup,主 Reactor 负责处理 Accept,然后把 Channel 注册到从 Reactor 上,从 Reactor 主要负责 Channel 生命周期内的所有 I/O 事件。
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup);
Channel 初始化
设置Channel类型
// 客户端Channel
b.channel(NioSocketChannel.class);
b.channel(OioSocketChannel.class);
// 服务端Channel
b.channel(NioServerSocketChannel.class);
b.channel(OioServerSocketChannel.class);
b.channel(EpollServerSocketChannel.class);
// UDP
b.channel(NioDatagramChannel.class);
b.channel(OioDatagramChannel.class);
注册ChannelHandler
ServerBootstrap 的 childHandler() 方法需要注册一个 ChannelHandler。ChannelInitializer是实现了 ChannelHandler接口的匿名类,通过实例化 ChannelInitializer 作为 ServerBootstrap 的参数。
b.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline()
// HTTP 编解码处理器
.addLast("codec", new HttpServerCodec())
// HTTPContent 压缩处理器
.addLast("compressor", new HttpContentCompressor())
// HTTP 消息聚合处理器
.addLast("aggregator", new HttpObjectAggregator(65536))
// 自定义业务逻辑处理器
.addLast("handler", new HttpServerHandler());
}
});
设置Channel参数
ServerBootstrap 设置 Channel 属性有option和childOption两个方法,option 主要负责设置 Boss 线程组,而 childOption 对应的是 Worker 线程组。
b.option(ChannelOption.SO_KEEPALIVE, true);
常用参数如下:
| 参数名 | 描述信息 |
|---|---|
| SO_KEEPALIVE | 设置为 true 代表启用了 TCP SO_KEEPALIVE 属性,TCP 会主动探测连接状态,即连接保活 |
| SO_BACKLOG | 已完成三次握手的请求队列最大长度,同一时刻服务端可能会处理多个连接,在高并发海量连接的场景下,该参数应适当调大 |
| TCP_NODELAY | Netty 默认是 true,表示立即发送数据。如果设置为 false 表示启用 Nagle 算法,该算法会将 TCP 网络数据包累积到一定量才会发送,虽然可以减少报文发送的数量,但是会造成一定的数据延迟。Netty 为了最小化数据传输的延迟,默认禁用了 Nagle 算法 |
| SO_SNDBUF | TCP 数据发送缓冲区大小 |
| SO_RCVBUF | TCP数据接收缓冲区大小,TCP数据接收缓冲区大小 |
| SO_LINGER | 设置延迟关闭的时间,等待缓冲区中的数据发送完成 |
| CONNECT_TIMEOUT_MILLIS | 建立连接的超时时间 |
端口绑定
bind() 方法会真正触发启动,sync() 方法则会阻塞,直至整个启动过程完成,具体使用方式如下:
ChannelFuture f = b.bind(8080).sync();
Netty流程
从功能上,流程可以分为服务启动、建立连接、读取数据、业务处理、发送数据、关闭连接以及关闭服务。整体流程如下所示(图中没有包含关闭的部分):
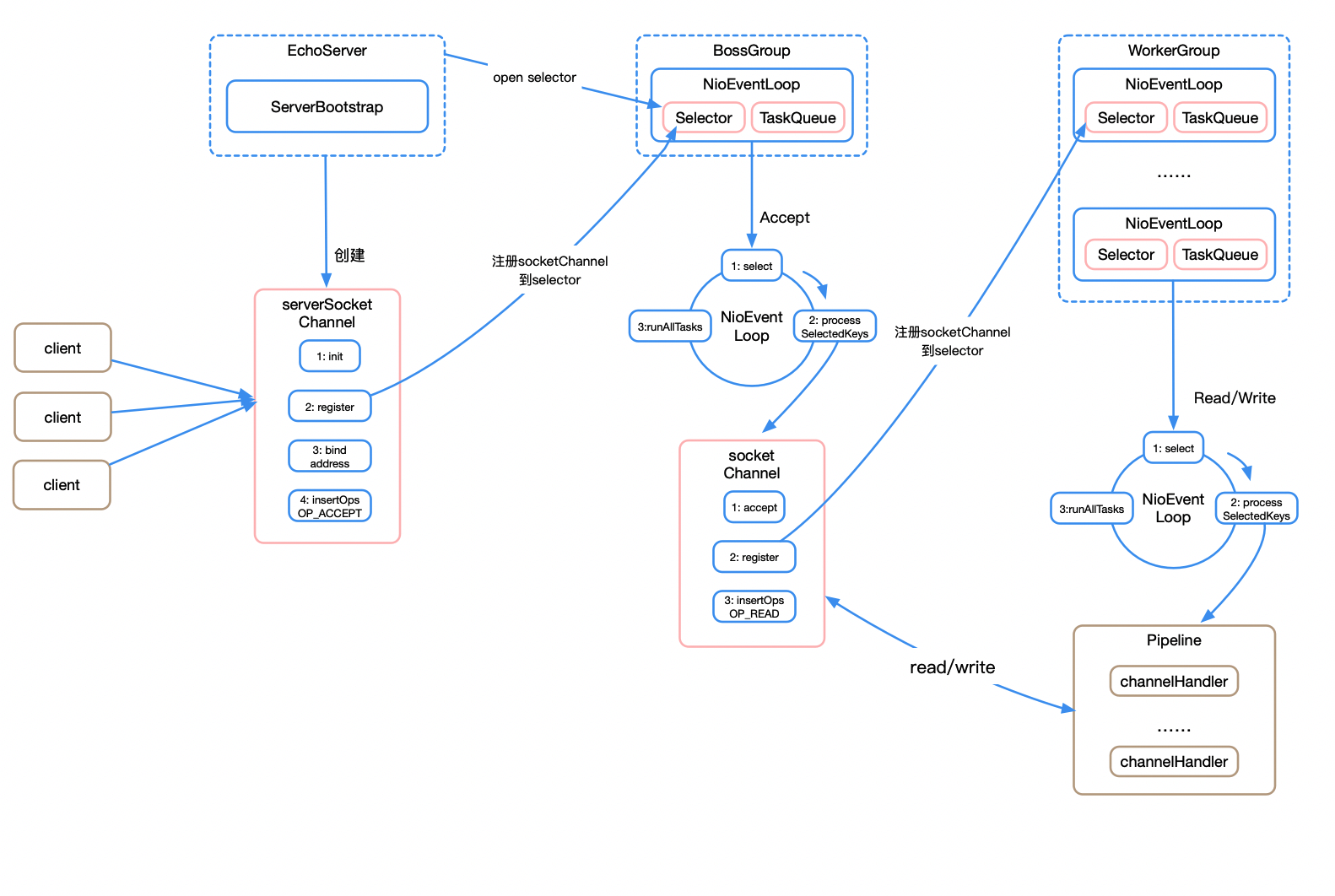
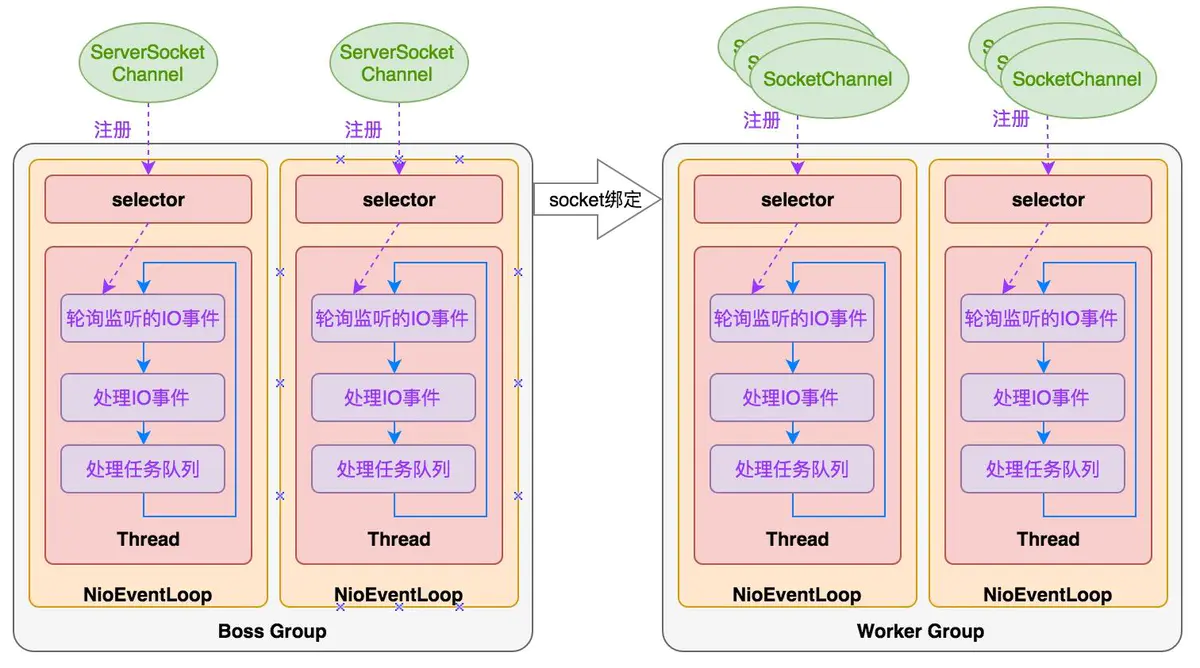
线程模型
Netty通过Reactor模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss线程池和work线程池,其中boss线程池的线程负责处理请求的accept事件,当接收到accept事件的请求时,把对应的socket封装到一个NioSocketChannel中,并交给work线程池,其中work线程池负责请求的read和write事件,由对应的Handler处理。
单线程Reactor线程模型
下图演示了单线程reactor线程模型,之所以称之为单线程,还是因为只有一个accpet Thread接受任务,之后转发到reactor线程中进行处理。两个黄色框表示的是Reactor Thread Group,里面有多个Reactor Thread。一个Reactor Thread Group中的Reactor Thread功能都是相同的,例如第一个黄色框中的Reactor Thread都是处理拆分后的任务的第一阶段,第二个黄色框中的Reactor Thread都是处理拆分后的任务的第二步骤。任务具体要怎么拆分,要结合具体场景,下图只是演示作用。一般来说,都是以比较耗时的操作(例如IO)为切分点。
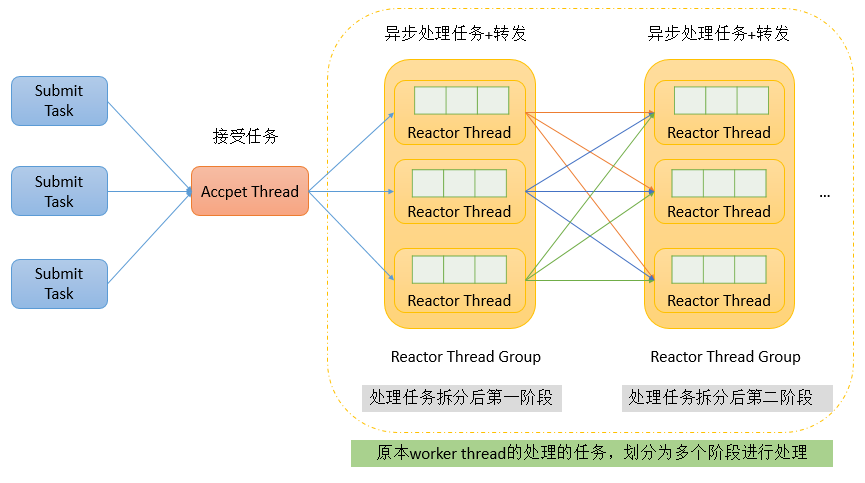
特别的,如果我们在任务处理的过程中,不划分为多个阶段进行处理的话,那么单线程reactor线程模型就退化成了并行工作和模型。事实上,可以认为并行工作者模型,就是单线程reactor线程模型的最简化版本。
多线程Reactor线程模型
所谓多线程reactor线程模型,无非就是有多个accpet线程,如下图中的虚线框中的部分。
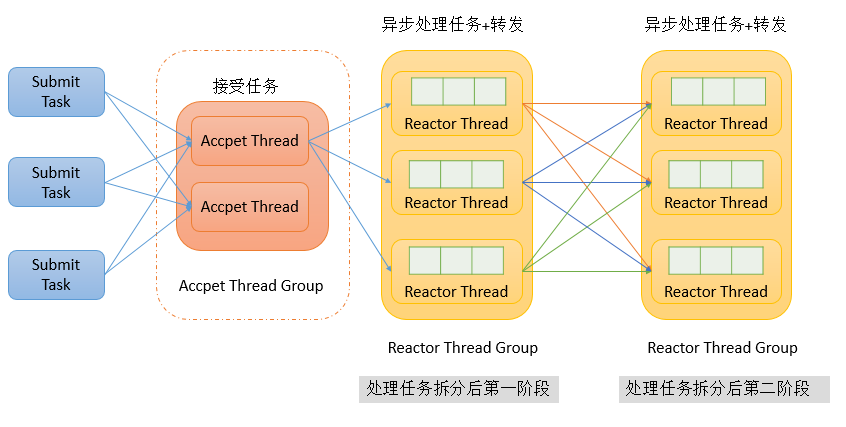
混合型Reactor线程模型
混合型reactor线程模型,实际上最能体现reactor线程模型的本质:
- 将任务处理切分成多个阶段进行,每个阶段处理完自己的部分之后,转发到下一个阶段进行处理。不同的阶段之间的执行是异步的,可以认为每个阶段都有一个独立的线程池。
- 不同的类型的任务,有着不同的处理流程,划分时需要划分成不同的阶段。如下图蓝色是一种任务、绿色是另一种任务,两种任务有着不同的执行流程
Netty-Reactor线程模型
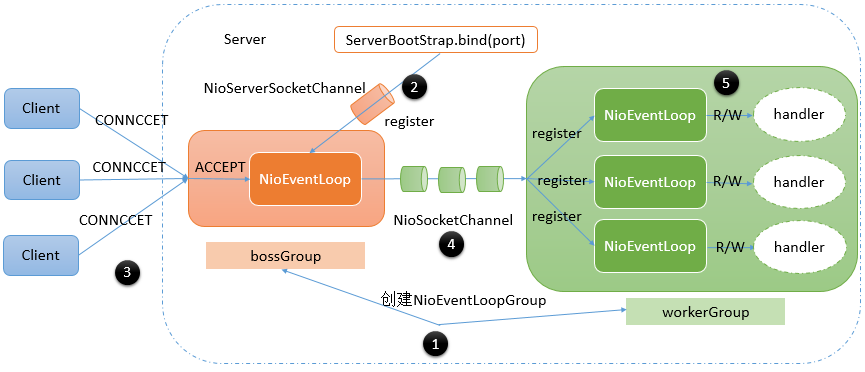
图中大致包含了5个步骤,而我们编写的服务端代码中可能并不能完全体现这样的步骤,因为Netty将其中一些步骤的细节隐藏了,笔者将会通过图形分析与源码分析相结合的方式帮助读者理解这五个步骤。这个五个步骤可以按照以下方式简要概括:
- 设置服务端ServerBootStrap启动参数
- 通过ServerBootStrap的bind方法启动服务端,bind方法会在parentGroup中注册NioServerScoketChannel,监听客户端的连接请求
- Client发起连接CONNECT请求,parentGroup中的NioEventLoop不断轮循是否有新的客户端请求,如果有,ACCEPT事件触发
- ACCEPT事件触发后,parentGroup中NioEventLoop会通过NioServerSocketChannel获取到对应的代表客户端的NioSocketChannel,并将其注册到childGroup中
- childGroup中的NioEventLoop不断检测自己管理的NioSocketChannel是否有读写事件准备好,如果有的话,调用对应的ChannelHandler进行处理
ByteBuf
工作流程
ByteBuf维护两个不同的索引:读索引(readerIndex) 和 写索引(writerIndex) 。如下图所示:

ByteBuf维护了readerIndex和writerIndex索引- 当
readerIndex > writerIndex时,则抛出IndexOutOfBoundsException ByteBuf容量 =writerIndexByteBuf可读容量 =writerIndex-readerIndexreadXXX()和writeXXX()方法将会推进其对应的索引。自动推进getXXX()和setXXX()方法将对writerIndex和readerIndex无影响
使用模式
ByteBuf本质是一个由不同的索引分别控制读访问和写访问的字节数组。ByteBuf共有三种模式:堆缓冲区模式(Heap Buffer)、直接缓冲区模式(Direct Buffer) 和 复合缓冲区模式(Composite Buffer)。
堆缓冲区模式(Heap Buffer)
堆缓冲区模式又称为支撑数组(backing array)。将数据存放在JVM的堆空间,通过将数据存储在数组中实现。
- 优点:由于数据存储在Jvm堆中可以快速创建和快速释放,并且提供了数组直接快速访问的方法
- 缺点:每次数据与I/O进行传输时,都需要将数据拷贝到直接缓冲区
public static void heapBuffer() {
// 创建Java堆缓冲区
ByteBuf heapBuf = Unpooled.buffer();
if (heapBuf.hasArray()) { // 是数组支撑
byte[] array = heapBuf.array();
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
int length = heapBuf.readableBytes();
handleArray(array, offset, length);
}
}
直接缓冲区模式(Direct Buffer)
Direct Buffer属于堆外分配的直接内存,不会占用堆的容量。适用于套接字传输过程,避免了数据从内部缓冲区拷贝到直接缓冲区的过程,性能较好。对于涉及大量I/O的数据读写,建议使用Direct Buffer。而对于用于后端的业务消息编解码模块建议使用Heap Buffer。
- 优点: 使用Socket传递数据时性能很好,避免了数据从Jvm堆内存拷贝到直接缓冲区的过程。提高了性能
- 缺点: 相对于堆缓冲区而言,Direct Buffer分配内存空间和释放更为昂贵
public static void directBuffer() {
ByteBuf directBuf = Unpooled.directBuffer();
if (!directBuf.hasArray()) {
int length = directBuf.readableBytes();
byte[] array = new byte[length];
directBuf.getBytes(directBuf.readerIndex(), array);
handleArray(array, 0, length);
}
}
复合缓冲区模式(Composite Buffer)
Composite Buffer是Netty特有的缓冲区。本质上类似于提供一个或多个ByteBuf的组合视图,可以根据需要添加和删除不同类型的ByteBuf。
- Composite Buffer是一个组合视图。它提供一种访问方式让使用者自由组合多个ByteBuf,避免了拷贝和分配新的缓冲区
- Composite Buffer不支持访问其支撑数组。因此如果要访问,需要先将内容拷贝到堆内存中,再进行访问
下图是将两个ByteBuf:头部 + Body 组合在一起,没有进行任何复制过程。仅仅创建了一个视图:

public static void byteBufComposite() {
// 复合缓冲区,只是提供一个视图
CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
ByteBuf headerBuf = Unpooled.buffer(); // can be backing or direct
ByteBuf bodyBuf = Unpooled.directBuffer(); // can be backing or direct
messageBuf.addComponents(headerBuf, bodyBuf);
messageBuf.removeComponent(0); // remove the header
for (ByteBuf buf : messageBuf) {
System.out.println(buf.toString());
}
}
字节级操作
随机访问索引
ByteBuf的索引与普通的Java字节数组一样。第一个字节的索引是0,最后一个字节索引总是capacity()-1。访问方式如下:
- readXXX()和writeXXX()方法将会推进其对应的索引readerIndex和writerIndex。自动推进
- getXXX()和setXXX()方法用于访问数据,对writerIndex和readerIndex无影响
public static void byteBufRelativeAccess() {
ByteBuf buffer = Unpooled.buffer(); // get reference form somewhere
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.getByte(i); // 不改变readerIndex值
System.out.println((char) b);
}
}
顺序访问索引
Netty的ByteBuf同时具有读索引和写索引,但JDK的ByteBuffer只有一个索引,所以JDK需要调用flip()方法在读模式和写模式之间切换。ByteBuf被读索引和写索引划分成3个区域:可丢弃字节区域、可读字节区域 和 可写字节区域 。
可丢弃字节区域
可丢弃字节区域是指:[0,readerIndex)之间的区域。可调用discardReadBytes()方法丢弃已经读过的字节。
- discardReadBytes()效果 ----- 将可读字节区域(CONTENT)[readerIndex, writerIndex)往前移动readerIndex位,同时修改读索引和写索引
- discardReadBytes()方法会移动可读字节区域内容(CONTENT)。如果频繁调用,会有多次数据复制开销,对性能有一定的影响
可读字节区域
可读字节区域是指:[readerIndex, writerIndex)之间的区域。任何名称以read和skip开头的操作方法,都会改变readerIndex索引。
可写字节区域
可写字节区域是指:[writerIndex, capacity)之间的区域。任何名称以write开头的操作方法都将改变writerIndex的值。
索引管理
- markReaderIndex()+resetReaderIndex() ----- markReaderIndex()是先备份当前的readerIndex,resetReaderIndex()则是将刚刚备份的readerIndex恢复回来。常用于dump ByteBuf的内容,又不想影响原来ByteBuf的readerIndex的值
- readerIndex(int) ----- 设置readerIndex为固定的值
- writerIndex(int) ----- 设置writerIndex为固定的值
- clear() ----- 效果是: readerIndex=0, writerIndex(0)。不会清除内存
- 调用clear()比调用discardReadBytes()轻量的多。仅仅重置readerIndex和writerIndex的值,不会拷贝任何内存,开销较小
查找操作(indexOf)
查找ByteBuf指定的值。类似于,String.indexOf("str")操作
- 最简单的方法 —— indexOf()
- 利用ByteProcessor作为参数来查找某个指定的值
public static void byteProcessor() {
ByteBuf buffer = Unpooled.buffer(); //get reference form somewhere
// 使用indexOf()方法来查找
buffer.indexOf(buffer.readerIndex(), buffer.writerIndex(), (byte)8);
// 使用ByteProcessor查找给定的值
int index = buffer.forEachByte(ByteProcessor.FIND_CR);
}
派生缓冲——视图
派生缓冲区为ByteBuf提供了一个访问的视图。视图仅仅提供一种访问操作,不做任何拷贝操作。下列方法,都会呈现给使用者一个视图,以供访问:
- duplicate()
- slice()
- slice(int, int)
- Unpooled.unmodifiableBuffer(...)
- Unpooled.wrappedBuffer(...)
- order(ByteOrder)
- readSlice(int)
理解
- 上面的6中方法,都会返回一个新的ByteBuf实例,具有自己的读索引和写索引。但是,其内部存储是与原对象是共享的。这就是视图的概念
- 请注意:如果你修改了这个新的ByteBuf实例的具体内容,那么对应的源实例也会被修改,因为其内部存储是共享的
- 如果需要拷贝现有缓冲区的真实副本,请使用copy()或copy(int, int)方法
- 使用派生缓冲区,避免了复制内存的开销,有效提高程序的性能
public static void byteBufSlice() {
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
ByteBuf sliced = buf.slice(0, 15);
System.out.println(sliced.toString(utf8));
buf.setByte(0, (byte)'J');
assert buf.getByte(0) == sliced.getByte(0); // return true
}
public static void byteBufCopy() {
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
ByteBuf copy = buf.copy(0, 15);
System.out.println(copy.toString(utf8));
buf.setByte(0, (byte)'J');
assert buf.getByte(0) != copy.getByte(0); // return true
}
读/写操作
如上文所提到的,有两种类别的读/写操作:
- get()和set()操作 ----- 从给定的索引开始,并且保持索引不变
- read()和write()操作 ----- 从给定的索引开始,并且根据已经访问过的字节数对索引进行访问
- 下图给出get()操作API,对于set()操作、read()操作和write操作可参考书籍或API
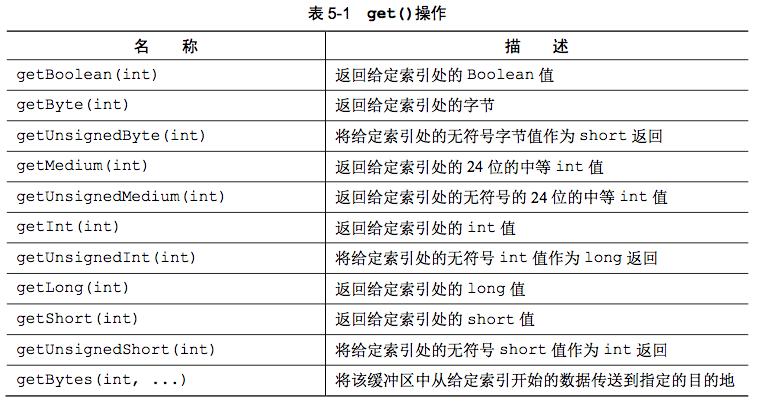
更多操作
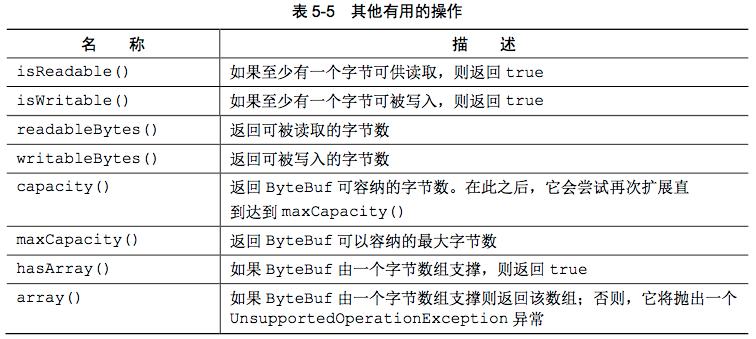
下面的两个方法操作字面意思较难理解,给出解释:
- hasArray():如果ByteBuf由一个字节数组支撑,则返回true。通俗的讲:ByteBuf是堆缓冲区模式,则代表其内部存储是由字节数组支撑的
- array():如果ByteBuf是由一个字节数组支撑泽返回数组,否则抛出UnsupportedOperationException异常。也就是,ByteBuf是堆缓冲区模式
ByteBuf分配
创建和管理ByteBuf实例的多种方式:按序分配(ByteBufAllocator)、Unpooled缓冲区 和 ByteBufUtil类。
按序分配:ByteBufAllocator接口
Netty通过接口ByteBufAllocator实现了(ByteBuf的)池化。Netty提供池化和非池化的ButeBufAllocator:
ctx.channel().alloc().buffer():本质就是ByteBufAllocator.DEFAULTByteBufAllocator.DEFAULT.buffer():返回一个基于堆或者直接内存存储的Bytebuf。默认是堆内存ByteBufAllocator.DEFAULT:有两种类型: UnpooledByteBufAllocator.DEFAULT(非池化)和PooledByteBufAllocator.DEFAULT(池化)。对于Java程序,默认使用PooledByteBufAllocator(池化)。对于安卓,默认使用UnpooledByteBufAllocator(非池化)- 可以通过BootStrap中的Config为每个Channel提供独立的ByteBufAllocator实例

解释:
- 上图中的buffer()方法,返回一个基于堆或者直接内存存储的Bytebuf ----- 缺省是堆内存。源码: AbstractByteBufAllocator() { this(false); }
- ByteBufAllocator.DEFAULT ----- 可能是池化,也可能是非池化。默认是池化(PooledByteBufAllocator.DEFAULT)
Unpooled缓冲区——非池化
Unpooled提供静态的辅助方法来创建未池化的ByteBuf。
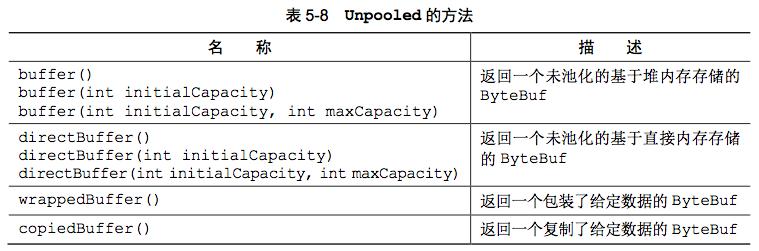
注意:
- 上图的buffer()方法,返回一个未池化的基于堆内存存储的ByteBuf
- wrappedBuffer() ----- 创建一个视图,返回一个包装了给定数据的ByteBuf。非常实用
创建ByteBuf代码:
public void createByteBuf(ChannelHandlerContext ctx) {
// 1. 通过Channel创建ByteBuf
ByteBuf buf1 = ctx.channel().alloc().buffer();
// 2. 通过ByteBufAllocator.DEFAULT创建
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer();
// 3. 通过Unpooled创建
ByteBuf buf3 = Unpooled.buffer();
}
ByteBufUtil类
ByteBufUtil类提供了用于操作ByteBuf的静态的辅助方法: hexdump()和equals
- hexdump():以十六进制的表示形式打印ByteBuf的内容。非常有价值
- equals():判断两个ByteBuf实例的相等性
引用计数
Netty4.0版本中为ButeBuf和ButeBufHolder引入了引用计数技术。请区别引用计数和可达性分析算法(jvm垃圾回收)
- 谁负责释放:一般来说,是由最后访问(引用计数)对象的那一方来负责将它释放
- buffer.release():引用计数减1
- buffer.retain():引用计数加1
- buffer.refCnt():返回当前对象引用计数值
- buffer.touch():记录当前对象的访问位置,主要用于调试
- 引用计数并非仅对于直接缓冲区(direct Buffer)。ByteBuf的三种模式: 堆缓冲区(heap Buffer)、直接缓冲区(dirrect Buffer)和复合缓冲区(Composite Buffer)都使用了引用计数,某些时候需要程序员手动维护引用数值
public static void releaseReferenceCountedObject(){
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();
// 引用计数加1
buffer.retain();
// 输出引用计数
buffer.refCnt();
// 引用计数减1
buffer.release();
}
Zero-Copy
Netty 的Zero-copy 体现在如下几个个方面:
- 通过CompositeByteBuf实现零拷贝:Netty提供了
CompositeByteBuf类,可以将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了各个ByteBuf之间的拷贝 - 通过wrap操作实现零拷贝:通过
wrap操作,可以将byte[]、ByteBuf、ByteBuffer等包装成一个Netty ByteBuf对象,进而避免了拷贝操作 - 通过slice操作实现零拷贝:ByteBuf支持
slice操作,可以将ByteBuf分解为多个共享同一个存储区域的ByteBuf,避免了内存的拷贝 - 通过FileRegion实现零拷贝:通过
FileRegion包装的FileChannel.tranferTo实现文件传输,可以直接将文件缓冲区的数据发送到目标 Channel,避免了传统通过循环write方式导致的内存拷贝问题
零拷贝操作
通过CompositeByteBuf实现零拷贝
ByteBuf header = null;
ByteBuf body = null;
// 传统合并header和body:两次额外的数据拷贝
ByteBuf allBuf = Unpooled.buffer(header.readableBytes() + body.readableBytes());
allBuf.writeBytes(header);
allBuf.writeBytes(body);
// 合并header和body:内部这两个 ByteBuf 都是单独存在的, CompositeByteBuf 只是逻辑上是一个整体
CompositeByteBuf compositeByteBuf = Unpooled.compositeBuffer();
compositeByteBuf.addComponents(true, header, body);
// 底层封装了 CompositeByteBuf 操作
ByteBuf allByteBuf = Unpooled.wrappedBuffer(header, body);
通过wrap操作实现零拷贝
byte[] bytes = null;
// 传统方式:直接将byte[]数组拷贝到ByteBuf中
ByteBuf byteBuf = Unpooled.buffer();
byteBuf.writeBytes(bytes);
// wrap方式:将bytes包装成为一个UnpooledHeapByteBuf对象, 包装过程中, 是不会有拷贝操作的
// 即最后我们生成的生成的ByteBuf对象是和bytes数组共用了同一个存储空间, 对bytes的修改也会反映到ByteBuf对象中
ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);
通过slice操作实现零拷贝
slice 操作和 wrap 操作刚好相反,Unpooled.wrappedBuffer 可以将多个 ByteBuf 合并为一个, 而 slice 操作可以将一个 **ByteBuf **切片 为多个共享一个存储区域的 ByteBuf 对象. ByteBuf 提供了两个 slice 操作方法:
public ByteBuf slice();
public ByteBuf slice(int index, int length);
不带参数的slice方法等同于buf.slice(buf.readerIndex(), buf.readableBytes()) 调用, 即返回 buf 中可读部分的切片. 而 slice(int index, int length)方法相对就比较灵活了, 我们可以设置不同的参数来获取到 buf 的不同区域的切片。
用 slice 方法产生 header 和 body 的过程是没有拷贝操作的, header 和 body 对象在内部其实是共享了 byteBuf 存储空间的不同部分而已,即:
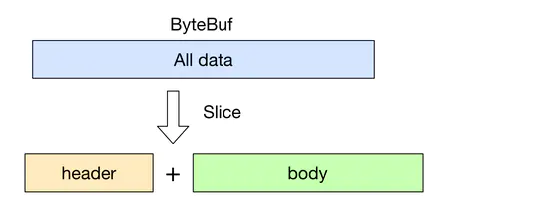
通过FileRegion实现零拷贝
Netty 中使用 FileRegion 实现文件传输的零拷贝, 不过在底层 FileRegion 是依赖于 Java NIO FileChannel.transfer 的零拷贝功能。当有了 FileRegion 后, 我们就可以直接通过它将文件的内容直接写入 Channel 中, 而不需要像传统的做法: 拷贝文件内容到临时 buffer, 然后再将 buffer 写入 Channel. 通过这样的零拷贝操作, 无疑对传输大文件很有帮助。
传统IO的流程
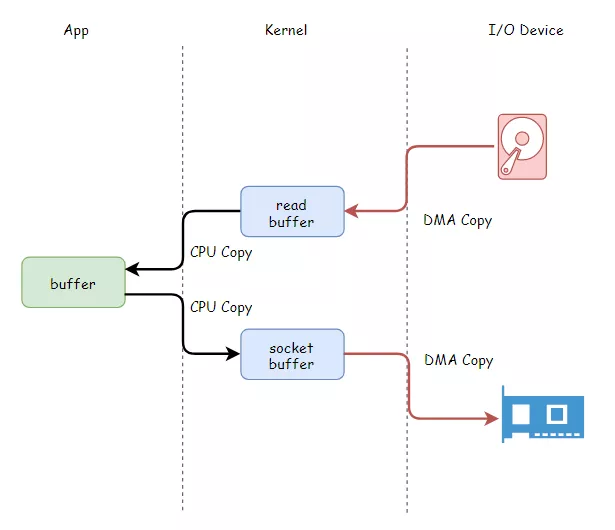
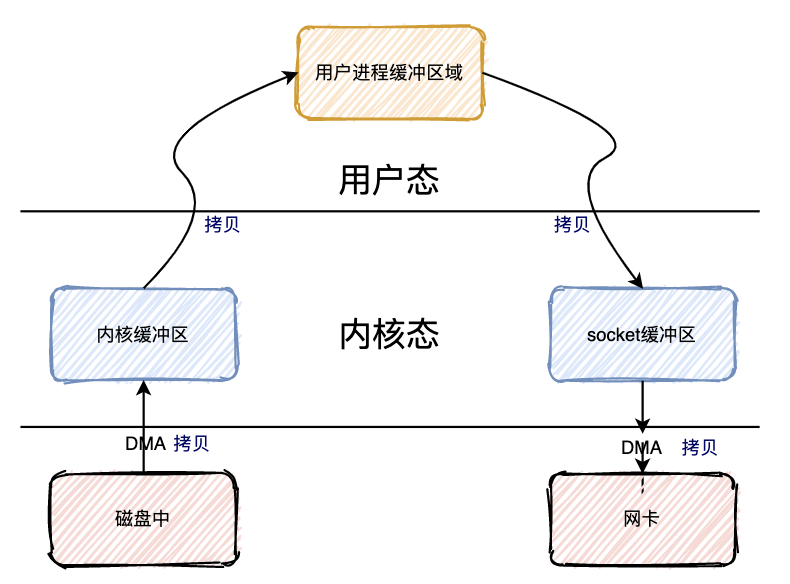
- 「第一步」:将文件通过 「DMA」 技术从磁盘中拷贝到内核缓冲区
- 「第二步」:将文件从内核缓冲区拷贝到用户进程缓冲区域中
- 「第三步」:将文件从用户进程缓冲区中拷贝到 socket 缓冲区中
- 「第四步」:将socket缓冲区中的文件通过 「DMA」 技术拷贝到网卡
零拷贝整体流程图
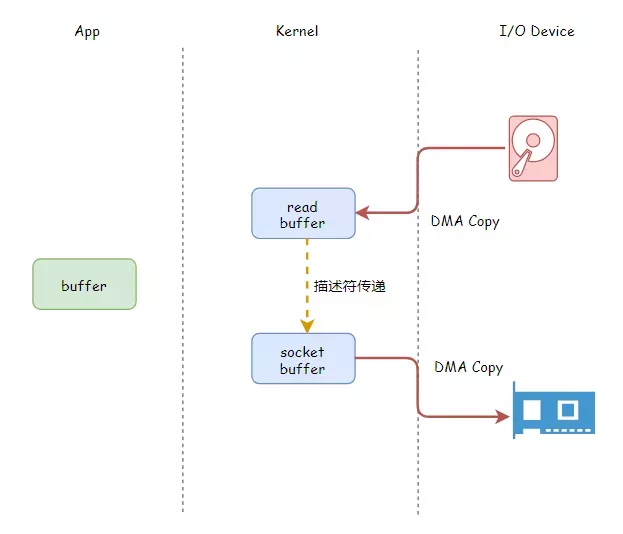
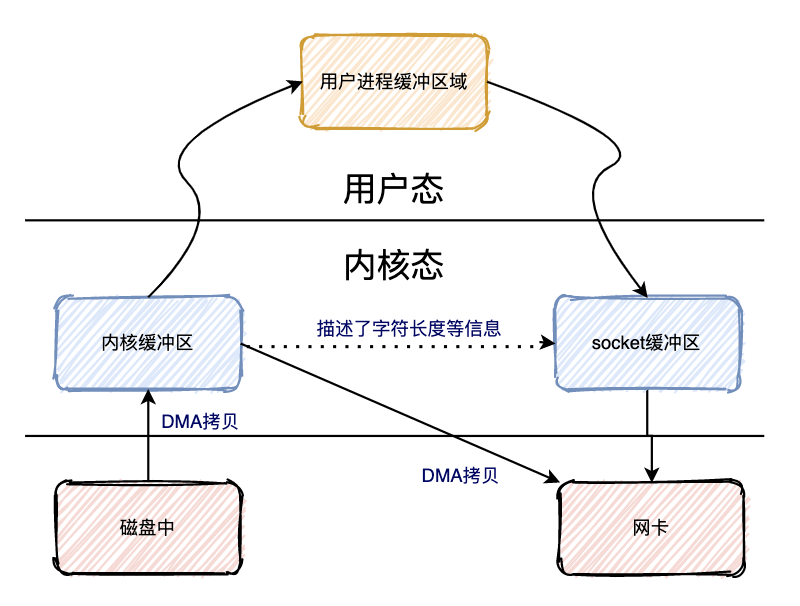
TCP粘包拆包
粘包拆包图解
假设客户端分别发送了两个数据包D1和D2给服务端,由于服务端一次读取到字节数是不确定的,故可能存在以下几种情况:
- 服务端分两次读取到两个独立的数据包,分别是D1和D2,没有粘包和拆包
- 服务端一次接收到了两个数据包,D1和D2粘在一起,发生粘包
- 服务端分两次读取到数据包,第一次读取到了完整D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,发生拆包
- 服务端分两次读取到数据包,第一次读取到部分D1包,第二次读取到剩余的D1包和全部的D2包
- 当TCP缓存再小一点的话,会把D1和D2分别拆成多个包发送
产生原因
产生粘包和拆包问题的主要原因是,操作系统在发送TCP数据的时候,底层会有一个缓冲区,例如1024个字节大小:
- 如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题
- 如果一次请求发送的数据量比较大,超过了缓冲区大小,TCP就会将其拆分为多次发送,这就是拆包,也就是将一个大的包拆分为多个小包进行发送
解决方案
固定长度
对于使用固定长度的粘包和拆包场景,可以使用:
FixedLengthFrameDecoder:每次读取固定长度的消息,如果当前读取到的消息不足指定长度,那么就会等待下一个消息到达后进行补足。其使用也比较简单,只需要在构造函数中指定每个消息的长度即可。
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// 这里将FixedLengthFrameDecoder添加到pipeline中,指定长度为20
ch.pipeline().addLast(new FixedLengthFrameDecoder(20));
// 将前一步解码得到的数据转码为字符串
ch.pipeline().addLast(new StringDecoder());
// 这里FixedLengthFrameEncoder是我们自定义的,用于将长度不足20的消息进行补全空格
ch.pipeline().addLast(new FixedLengthFrameEncoder(20));
// 最终的数据处理
ch.pipeline().addLast(new EchoServerHandler());
}
指定分隔符
对于通过分隔符进行粘包和拆包问题的处理,Netty提供了两个编解码的类:
LineBasedFrameDecoder:通过换行符,即\n或者\r\n对数据进行处理DelimiterBasedFrameDecoder:通过用户指定的分隔符对数据进行粘包和拆包处理
@Override
protected void initChannel(SocketChannel ch) throws Exception {
String delimiter = "_$";
// 将delimiter设置到DelimiterBasedFrameDecoder中,经过该解码一器进行处理之后,源数据将会
// 被按照_$进行分隔,这里1024指的是分隔的最大长度,即当读取到1024个字节的数据之后,若还是未
// 读取到分隔符,则舍弃当前数据段,因为其很有可能是由于码流紊乱造成的
ch.pipeline().addLast(new DelimiterBasedFrameDecoder(1024,
Unpooled.wrappedBuffer(delimiter.getBytes())));
// 将分隔之后的字节数据转换为字符串数据
ch.pipeline().addLast(new StringDecoder());
// 这是我们自定义的一个编码器,主要作用是在返回的响应数据最后添加分隔符
ch.pipeline().addLast(new DelimiterBasedFrameEncoder(delimiter));
// 最终处理数据并且返回响应的handler
ch.pipeline().addLast(new EchoServerHandler());
}
数据包长度字段
处理粘拆包的主要思想是在生成的数据包中添加一个长度字段,用于记录当前数据包的长度。
-
LengthFieldBasedFrameDecoder:按照参数指定的包长度偏移量数据对接收到的数据进行解码,从而得到目标消息体数据。解码过程如下图所示:
-
LengthFieldPrepender:在响应的数据前面添加指定的字节数据,这个字节数据中保存了当前消息体的整体字节数据长度。编码过程如下图所示:
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// 这里将LengthFieldBasedFrameDecoder添加到pipeline的首位,因为其需要对接收到的数据
// 进行长度字段解码,这里也会对数据进行粘包和拆包处理
ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024, 0, 2, 0, 2));
// LengthFieldPrepender是一个编码器,主要是在响应字节数据前面添加字节长度字段
ch.pipeline().addLast(new LengthFieldPrepender(2));
// 对经过粘包和拆包处理之后的数据进行json反序列化,从而得到User对象
ch.pipeline().addLast(new JsonDecoder());
// 对响应数据进行编码,主要是将User对象序列化为json
ch.pipeline().addLast(new JsonEncoder());
// 处理客户端的请求的数据,并且进行响应
ch.pipeline().addLast(new EchoServerHandler());
}
自定义粘包拆包器
可以通过实现MessageToByteEncoder和ByteToMessageDecoder来实现自定义粘包和拆包处理的目的。
MessageToByteEncoder:作用是将响应数据编码为一个ByteBuf对象ByteToMessageDecoder:将接收到的ByteBuf数据转换为某个对象数据
高性能
- IO线程模型:同步非阻塞,用最少的资源做更多的事
- 内存零拷贝:尽量减少不必要的内存拷贝,实现了更高效率的传输
- 内存池设计:申请的内存可以重用,主要指直接内存。内部实现是用一颗二叉查找树管理内存分配情况
- 串形化处理读写:避免使用锁带来的性能开销
- 高性能序列化协议:支持 protobuf 等高性能序列化协议
操作系统调优
文件描述符
- 设置系统最大文件句柄数
# 查看
cat /proc/sys/fs/file-max
# 修改
在/etc/sysctl.conf插入fs.file-max=1000000
# 配置生效
sysctl -p
- 设置单进程打开的最大句柄数
默认单进程打开的最大句柄数是 1024,通过 ulimit -a 可以查看相关参数,示例如下:
[root@test ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 256324
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
......
当并发接入的TCP连接数超过上限时,就会报“too many open files”,所有新的客户端接入将失败。通过 vi /etc/security/limits.conf 命令添加如下配置参数:
* soft nofile 1000000
* hard nofile 1000000
修改之后保存,注销当前用户,重新登录,通过 ulimit -a 查看修改的状态是否生效。
注意:尽管我们可以将单个进程打开的最大句柄数修改的非常大,但是当句柄数达到一定数量级之后,处理效率将出现明显下降,因此,需要根据服务器的硬件配置和处理能力进行合理设置。
TCP/IP相关参数
需要重点调优的TCP IP参数如下:
- net.ipv4.tcp_rmem:为每个TCP连接分配的读缓冲区内存大小。第一个值时socket接收缓冲区分配的最小字节数。
多网卡队列和软中断
-
TCP缓冲区
根据推送消息的大小,合理设置以下两个参数,对于海量长连接,通常 32K 是个不错的选择:
- SO_SNDBUF:发送缓冲区大小
- SO_RCVBUF:接收缓冲区大小
-
软中断
使用命令
cat /proc/interrupts查看网卡硬件中断的运行情况,如果全部被集中在CPU0上处理,则无法并行执行多个软中断。Linux kernel内核≥2.6.35的版本,可以开启RPS,网络通信能力提升20%以上,RPS原理是:根据数据包的源地址、目的地址和源端口等,计算出一个Hash值,然后根据Hash值来选择软中断运行的CPU,即实现每个链接和CPU绑定,通过Hash值来均衡软中断运行在多个CPU上。
Netty性能调优
设置合理的线程数
boss线程池优化
对于Netty服务端,通常只需要启动一个监听端口用于端侧设备接入,但是如果集群实例较少,甚至是单机部署,那么在短时间内大量设备接入时,需要对服务端的监听方式和线程模型做优化,即服务端监听多个端口,利用主从Reactor线程模型。由于同时监听了多个端口,每个ServerSocketChannel都对应一个独立的Acceptor线程,这样就能并行处理,加速端侧设备的接人速度,减少端侧设备的连接超时失败率,提高单节点服务端的处理性能。
work线程池优化(I/O工作线程池)
对于I/O工作线程池的优化,可以先采用系统默认值(cpu内核数*2)进行性能测试,在性能测试过程中采集I/O线程的CPU占用大小,看是否存在瓶颈,具体策略如下:
- 通过执行
ps -ef|grep java找到服务端进程pid - 执行
top -Hp pid查询该进程下所有线程的运行情况,通过“shift+p”对CPU占用大小做排序,获取线程的pid及对应的CPU占用大小 - 使用
printf'%x\n' pid将pid转换成16进制格式 - 通过
jstack -f pid命令获取线程堆栈,或者通过jvisualvm工具打印线程堆栈,找到I/O work工作线程,查看他们的CPU占用大小及线程堆栈,关键词:SelectorImpl.lockAndDoSelect
分析
- 如果连续采集几次进行对比,发现线程堆栈都停留在SelectorImpl.lockAndDoSelect处,则说明I/O线程比较空闲,无需对工作线程数做调整
- 如果发现I/O线程的热点停留在读或写操作,或停留在ChannelHandler的执行处,则可以通过适当调大NioEventLoop线程的个数来提升网络的读写性能。调整方式有两种:
- 接口API指定:在创建NioEventLoopGroup实例时指定线程数
- 系统参数指定:通过-Dio.netty.eventLoopThreads来指定NioEventLoopGroup线程池(不建议)
心跳检测优化
心跳检测的目的就是确认当前链路是否可用,对方是否活着并且能够正常接收和发送消息。从技术层面看,要解决链路的可靠性问题,必须周期性地对链路进行有效性检测。目前最流行和通用的做法就是心跳检测。
海量设备接入的服务端心跳优化策略
- 要能够及时检测失效的连接,并将其剔除。防止无效的连接句柄积压,导致OOM等问题
- 设置合理的心跳周期。防止心跳定时任务积压,造成频繁的老年代GC(新生代和老年代都有导致STW的GC,不过耗时差异较大),导致应用暂停
- 使用Nety提供的链路空闲检测机制。不要自己创建定时任务线程池,加重系统的负担,以及增加潜在的并发安全问题
心跳检测机制分为三个层面
- TCP层的心跳检测:即TCP的 Keep-Alive机制,它的作用域是整个TCP协议栈
- 协议层的心跳检测:主要存在于长连接协议中,例如MQTT
- 应用层的心跳检测:它主要由各业务产品通过约定方式定时给对方发送心跳消息实现
心跳检测机制分类
- Ping-Pong型心跳:由通信一方定时发送Ping消息,对方接收到Ping消息后立即返回Pong答应消息给对方,属于“请求-响应型”心跳
- Ping-Ping型心跳:不区分心跳请求和答应,由通信双发按照约定时间向对方发送心跳Ping消息,属于”双向心跳“
心跳检测机制策略
- 心跳超时:连续N次检测都没有收到对方的Pong应答消息或Ping请求消息,则认为链路已经发生逻辑失效
- 心跳失败:在读取和发送心跳消息的时候,如果直接发生了IO异常,说明链路已经失效
链路空闲检测机制
- 读空闲:链路持续时间T没有读取到任何消息
- 写空闲:链路持续时间T没有发送任何消息
- 读写空闲:链路持续时间T没有接收或者发送任何消息
案例分析
由于移动无线网络的特点,推送服务的心跳周期并不能设置的太长,否则长连接会被释放,造成频繁的客户端重连,但是也不能设置太短,否则在当前缺乏统一心跳框架的机制下很容易导致信令风暴(例如微信心跳信令风暴问题)。具体的心跳周期并没有统一的标准,180S 也许是个不错的选择,微信为 300S。
在 Netty 中,可以通过在 ChannelPipeline 中增加 IdleStateHandler 的方式实现心跳检测,在构造函数中指定链路空闲时间,然后实现空闲回调接口,实现心跳的发送和检测。拦截链路空闲事件并处理心跳:
public class MyHandler extends ChannelHandlerAdapter {
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
// 心跳处理
}
}
}
心跳优化结论
- 对于百万级的服务器,一般不建议很长的心跳周期和超时时长
- 心跳检测周期通常不要超过60s,心跳检测超时通常为心跳检测周期的2倍
- 建议通过IdleStateHandler实现心跳,不要自己创建定时任务线程池,加重系统负担和增加潜在并发安全问题
- 发生心跳超时或心跳失败时,都需要关闭链路,由客户端发起重连操作,保证链路能够恢复正常
- 链路空闲事件被触发后并没有关闭链路,而是触发IdleStateEvent事件,用户订阅IdleStateEvent事件,用于自定义逻辑处理。如关闭链路、客户端发起重新连接、告警和日志打印等
- 链路空闲检测类库主要包括:IdleStateHandler、ReadTimeoutHandler、WriteTimeoutHandler
接收和发送缓冲区调优
对于长链接,每个链路都需要维护自己的消息接收和发送缓冲区,JDK 原生的 NIO 类库使用的是java.nio.ByteBuffer, 它实际是一个长度固定的byte[],无法动态扩容。
场景:假设单条消息最大上限为10K,平均大小为5K,为满足10K消息处理,ByteBuffer的容量被设置为10K,这样每条链路实际上多消耗了5K内存,如果长链接链路数为100万,每个链路都独立持有ByteBuffer接收缓冲区,则额外损耗的总内存Total(M) =1000000×5K=4882M
Netty提供的ByteBuf支持容量动态调整,同时提供了两种接收缓冲区的内存分配器:
- FixedRecvByteBufAllocator:固定长度的接收缓冲区分配器,它分配的ByteBuf长度是固定大小的,并不会根据实际数据报大小动态收缩。但如果容量不足,支持动态扩展
- AdaptiveRecvByteBufAllocator:容量动态调整的接收缓冲区分配器,会根据之前Channel接收到的数据报大小进行计算,如果连续填充满接收缓冲区的可写空间,则动态扩展容量。如果连续2次接收到的数据报都小于指定值,则收缩当前的容量,以节约内存
相对于FixedRecvByteBufAllocator,使用AdaptiveRecvByteBufAllocator更为合理,可在创建客户端或者服务端的时候指定RecvByteBufAllocator。
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.RCVBUF_ALLOCATOR, AdaptiveRecvByteBufAllocator.DEFAULT)
注意:无论是接收缓冲区还是发送缓冲区,缓冲区的大小建议设置为消息的平均大小,不要设置成最大消息的上限,这会导致额外的内存浪费。
合理使用内存池
每个NioEventLoop线程处理N个链路。链路处理流程:开始处理A链路→创建接收缓冲区(创建ByteBuf)→消息解码→封装成POJO对象→提交至后台线程成Task→释放接收缓冲区→开始处理B链路。
如果使用内存池,则当A链路接收到新数据报后,从NioEventLoop的内存池中申请空闲的ByteBuf,解码完成后,调用release将ByteBuf释放到内存池中,供后续B链路继续使用。使用内存池优化后,单个NioEventLoop的ByteBuf申请和GC次数从原来的N=1000000/64= 15625次减少为最少0次(假设每次申请都有可用的内存)。
Netty默认不使用内存池,需要在创建客户端或者服务端的时候进行指定:
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
使用内存池之后,内存的申请和释放必须成对出现,即 retain() 和 release() 要成对出现,否则会导致内存泄露。值得注意的是,如果使用内存池,完成 ByteBuf 的解码工作之后必须显式的调用 ReferenceCountUtil.release(msg) 对接收缓冲区 ByteBuf 进行内存释放,否则它会被认为仍然在使用中,这样会导致内存泄露。
防止I/O线程被意外阻塞
通常情况不能在Netty的I/O线程上做执行时间不可控的操作,如访问数据库、调用第三方服务等,但有一些隐形的阻塞操作却容易被忽略,如打印日志。
生产环境中,一般需要实时打印接口日志,其它日志处于ERROR级别,当服务发生I/O异常后,会记录异常日志。如果磁盘的WIO比较高,可能会发生写日志文件操作被同步阻塞,阻塞时间无法预测,就会导致Netty的NioEventLoop线程被阻塞,Socket链路无法被及时管理,其它链路也无法进行读写操作等。
常用的log4j虽然支持异步写日志(AsyncAppender),但当日志队列满之后,它会同步阻塞业务线程,直到日志队列有空闲位置可用。
类似问题具有极强的隐蔽性,往往WIO高的时间持续非常短,或是偶现的,在测试环境中很难模拟此类故障,问题定位难度大。
I/O线程与业务线程分离
- 如果服务端不做复杂业务逻辑操作,仅是简单内存操作和消息转发,则可通过调大NioEventLoop工作线程池的方式,直接在I/O线程中执行业务ChannelHandler,这样便减少了一次线上上下文切换,性能反而更高
- 如果有复杂的业务逻辑操作,则建议I/O线程和业务线程分离。
- 对于I/O线程,由于互相之间不存在锁竞争,可以创建一个大的NioEventLoopGroup线程组,所有Channel都共享一个线程池
- 对于后端的业务线程池,则建议创建多个小的业务线程池,线程池可以与I/O线程绑定,这样既减少了锁竞争,又提升了后端的处理性能
服务端并发连接数流控
无论服务端的性能优化到多少,都需要考虑流控功能。当资源成为瓶颈,或遇到端侧设备的大量接入,需要通过流控对系统做保护。一般Netty主要考虑并发连接数的控制。
案例分析
疑似内存泄漏
环境:8C16G的Linux
描述:boss为1,worker为6,其余分配给业务使用,保持10W用户长链接,2W用户并发做消息请求
分析:dump内存堆栈发现Netty的ScheduledFutureTask增加了9076%,达到110W个实例。通过业务代码分析发现用户使用了IdleStateHandler用于在链路空闲时进行业务逻辑处理,但空闲时间比较大,为15分钟。Netty 的 IdleStateHandler 会根据用户的使用场景,启动三类定时任务,分别是:ReaderIdleTimeoutTask、WriterIdleTimeoutTask 和 AllIdleTimeoutTask,它们都会被加入到 NioEventLoop 的 Task 队列中被调度和执行。由于超时时间过长,10W 个长链接链路会创建 10W 个 ScheduledFutureTask 对象,每个对象还保存有业务的成员变量,非常消耗内存。用户的持久代设置的比较大,一些定时任务被老化到持久代中,没有被 JVM 垃圾回收掉,内存一直在增长,用户误认为存在内存泄露,即小问题被放大而引出的问题。
解决:重新设计和反复压测之后将超时时间设置为45秒,内存可以实现正常回收。
当心CLOSE_WAIT
由于网络不稳定经常会导致客户端断连,如果服务端没有能够及时关闭 socket,就会导致处于 close_wait 状态的链路过多。close_wait 状态的链路并不释放句柄和内存等资源,如果积压过多可能会导致系统句柄耗尽,发生“Too many open files”异常,新的客户端无法接入,涉及创建或者打开句柄的操作都将失败。
close_wait 是被动关闭连接是形成的,根据 TCP 状态机,服务器端收到客户端发送的 FIN,TCP 协议栈会自动发送 ACK,链接进入 close_wait 状态。但如果服务器端不执行 socket 的 close() 操作,状态就不能由 close_wait 迁移到 last_ack,则系统中会存在很多 close_wait 状态的连接。通常来说,一个 close_wait 会维持至少 2 个小时的时间(系统默认超时时间的是 7200 秒,也就是 2 小时)。如果服务端程序因某个原因导致系统造成一堆 close_wait 消耗资源,那么通常是等不到释放那一刻,系统就已崩溃。
导致 close_wait 过多的可能原因如下:
- 程序处理Bug:导致接收到对方的 fin 之后没有及时关闭 socket,这可能是 Netty 的 Bug,也可能是业务层 Bug,需要具体问题具体分析
- 关闭socket不及时:例如 I/O 线程被意外阻塞,或者 I/O 线程执行的用户自定义 Task 比例过高,导致 I/O 操作处理不及时,链路不能被及时释放
解决方案
- 不要在 Netty 的 I/O 线程(worker线程)上处理业务(心跳发送和检测除外)
- 在I/O线程上执行自定义Task要当心
- IdleStateHandler、ReadTimeoutHandler和WriteTimeoutHandler使用要当
RabbitMQ
模式介绍
在 RabbitMQ 官网上提供了 6 中工作模式:简单模式、工作队列模式、发布/订阅模式、路由模式、主题模式 和 RPC 模式。本篇只对前 5 种工作方式进行介绍。
简单模式与工作队列模式
之所以将这两种模式合并在一起介绍,是因为它们工作原理非常简单,由 3 个对象组成:生产者、队列、消费者。

生产者负责生产消息,将消息发送到队列中,消费者监听队列,队列有消息就进行消费。
当有多个消费者时,消费者平均消费队列中的消息。代码演示:
生产者:
//1.获取连接
Connection connection = ConnectionUtil.getConnection();
//2.创建通道
Channel channel = connection.createChannel();
//3.申明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//4.发送消息
channel.basicPublish("", QUEUE_NAME, null, "hello simple".getBytes());
System.out.println("发送成功");
//5.释放连接
channel.close();
connection.close();
消费者:
// 1.获取连接
Connection connection = ConnectionUtil.getConnection();
// 2.创建通道
Channel channel = connection.createChannel();
// 3.申明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 4.监听消息
channel.basicConsume(QUEUE_NAME, true, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println("接收:" + message);
}
});
发布/订阅、路由与主题模式
这 3 种模式都使用到交换机。生产者不直接与队列交互,而是将消息发送到交换机中,再由交换机将消息放入到已绑定该交换机的队列中给消费者消费。常用的交换机类型有 3 种:fanout、direct、topic。工作原理图如下:

fanout:不处理路由键。只需要简单的将队列绑定到交换机上。一个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。fanout 类型交换机转发消息是最快的。
其中,发布/订阅模式使用的是 fanout 类型的交换机。

direct:处理路由键。需要将一个队列绑定到交换机上,要求该消息与一个特定的路由键完全匹配。如果一个队列绑定到该交换机上要求路由键 “dog”,则只有被标记为 “dog” 的消息才被转发,不会转发 dog.puppy,也不会转发 dog.guard,只会转发dog。
其中,路由模式使用的是 direct 类型的交换机。
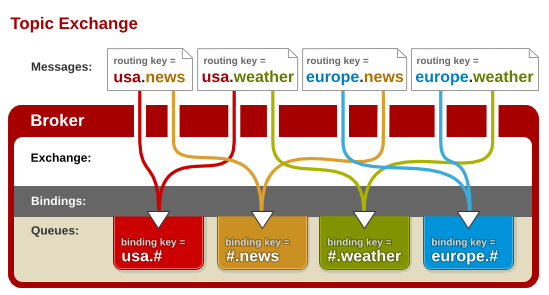
topic:将路由键和某模式进行匹配。此时队列需要绑定要一个模式上。符号 “#” 匹配一个或多个词,符号“*”匹配不多不少一个词。因此“audit.#” 能够匹配到“audit.irs.corporate”,但是“audit.*” 只会匹配到 “audit.irs”。
**其中,主题模式使用的是 topic 类型的交换机。**代码演示:
生产者:
// 1.获取连接
Connection connection = ConnectionUtil.getConnection();
// 2.创建通道
Channel channel = connection.createChannel();
// 3.申明交换机
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
// 4.发送消息
for (int i = 0; i < 100; i++) {
channel.basicPublish(EXCHANGE_NAME, "", null, ("hello ps" + i + "").getBytes());
}
System.out.println("发送成功");
// 5.释放连接
channel.close();
connection.close();
多个消费者:
// 1.获取连接
Connection connection = ConnectionUtil.getConnection();
// 2.创建通道
Channel channel = connection.createChannel();
// 3.申明交换机
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
// 4.队列绑定交换机
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "");
// 5.消费消息
channel.basicQos(1);
channel.basicConsume(QUEUE_NAME, false, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println("recv1:" + message);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
channel.basicAck(envelope.getDeliveryTag(), false);
}
});
Dubbo
Apache Dubbo 是一款高性能、轻量级的开源 Java 服务框架。Apache Dubbo 提供了六大核心能力:面向接口代理的高性能RPC调用,智能容错和负载均衡,服务自动注册和发现,高度可扩展能力,运行期流量调度,可视化的服务治理与运维。
-
面向接口代理的高性能RPC调用
提供高性能的基于代理的远程调用能力,服务以接口为粒度,为开发者屏蔽远程调用底层细节。
-
智能负载均衡
内置多种负载均衡策略,智能感知下游节点健康状况,显著减少调用延迟,提高系统吞吐量。
-
服务自动注册与发现
支持多种注册中心服务,服务实例上下线实时感知。
-
高度可扩展能力
遵循微内核+插件的设计原则,所有核心能力如Protocol、Transport、Serialization被设计为扩展点,平等对待内置实现和第三方实现。
-
运行期流量调度
内置条件、脚本等路由策略,通过配置不同的路由规则,轻松实现灰度发布,同机房优先等功能。
-
可视化的服务治理与运维
提供丰富服务治理、运维工具:随时查询服务元数据、服务健康状态及调用统计,实时下发路由策略、调整配置参数。
RPC
Remote Procedure Call Protocol 既 远程过程调用,一种能让我们像调用本地服务一样调用远程服务,可以让调用者对网络通信这些细节无感知,比如服务消费方在执行 helloWorldService.sayHello("sowhat") 时,实质上调用的是远端的服务。这种方式其实就是RPC,RPC思想在各大互联网公司中被广泛使用,如阿里巴巴的dubbo、当当的Dubbox 、Facebook 的 thrift、Google 的grpc、Twitter的finagle等。
框架设计
Dubbo 简介
Dubbo 是阿里巴巴研发开源工具,主要分为2.6.x 跟 2.7.x 版本。是一款分布式、高性能、透明化的 RPC 服务框架,提供服务自动注册、自动发现等高效服务治理方案,可以和Spring 框架无缝集成,它提供了6大核心能力:
- 面向接口代理的高性能RPC调用
- 智能容错和负载均衡
- 服务自动注册和发现
- 高度可扩展能力
- 运行期流量调度
- 可视化的服务治理与运维
调用过程:
- 服务提供者 Provider 启动然后向 Registry 注册自己所能提供的服务。
- 服务消费者 Consumer 向Registry订阅所需服务,Consumer 解析Registry提供的元信息,从服务中通过负载均衡选择 Provider调用。
- 服务提供方 Provider 元数据变更的话Registry会把变更推送给Consumer,以此保证Consumer获得最新可用信息。
注意点:
- Provider 跟 Consumer 在内存中记录调用次数跟时间,定时发送统计数据到Monitor,发送的时候是短连接。
- Monitor 跟 Registry 是可选的,可直接在配置文件中写好,Provider 跟 Consumer进行直连。
- Monitor 跟 Registry 挂了也没事, Consumer 本地缓存了 Provider 信息。
- Consumer 直接调用 Provider 不会经过 Registry。Provider、Consumer这俩到 Registry之间是长连接。
Dubbo框架分层

如上图,总的而言 Dubbo 分为三层。
- Busines层:由用户自己来提供接口和实现还有一些配置信息。
- RPC层:真正的RPC调用的核心层,封装整个RPC的调用过程、负载均衡、集群容错、代理。
- Remoting层:对网络传输协议和数据转换的封装。
如果每一层再细分下去,一共有十层:
- 接口服务层(Service):该层与业务逻辑相关,根据 provider 和 consumer 的业务设计对应的接口和实现。
- 配置层(Config):对外配置接口,以 ServiceConfig 和 ReferenceConfig 为中心初始化配置。
- 服务代理层(Proxy):服务接口透明代理,Provider跟Consumer都生成代理类,使得服务接口透明,代理层实现服务调用跟结果返回。
- 服务注册层(Registry):封装服务地址的注册和发现,以服务 URL 为中心。
- 路由层(Cluster):封装多个提供者的路由和负载均衡,并桥接注册中心,以Invoker 为中心,扩展接口为 Cluster、Directory、Router 和 LoadBlancce。
- 监控层(Monitor):RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory、Monitor 和 MonitorService。
- 远程调用层(Protocal):封装 RPC 调用,以 Invocation 和 Result 为中心,扩展接口为 Protocal、Invoker 和 Exporter。
- 信息交换层(Exchange):封装请求响应模式,同步转异步。以 Request 和Response 为中心,扩展接口为 Exchanger、ExchangeChannel、ExchangeClient 和 ExchangeServer。
- 网络传输层(Transport):抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel、Transporter、Client、Server 和 Codec。
- 数据序列化层(Serialize):可复用的一些工具,扩展接口为 Serialization、ObjectInput、ObjectOutput 和 ThreadPool。
他们之间的调用关系直接看下面官网图即可:
SPI机制
Dubbo 采用 微内核设计 + SPI 扩展技术来搭好核心框架,同时满足用户定制化需求。这里重点说下SPI。
SPI 含义
SPI 全称为 Service Provider Interface,是一种服务发现机制。它约定在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类。
Java SPI缺点
- 不能按需加载,Java SPI在加载扩展点的时候,会一次性加载所有可用的扩展点,很多是不需要的,会浪费系统资源。
- 获取某个实现类的方式不够灵活,只能通过 Iterator 形式获取,不能根据某个参数来获取对应的实现类。
- 不支持AOP与依赖注入,JAVA SPI可能会丢失加载扩展点异常信息,导致追踪问题很困难。
Dubbo SPI
JDK自带的不好用Dubbo 就自己实现了一个 SPI,该SPI 可以通过名字实例化指定的实现类,并且实现了 IOC 、AOP 与 自适应扩展 SPI 。
key = com.sowhat.value
Dubbo 对配置文件目录的约定,不同于 Java SPI ,Dubbo 分为了三类目录。
- META-INF/services/ :该目录下 SPI 配置文件是为了用来兼容 Java SPI
- META-INF/dubbo/ :该目录存放用户自定义的 SPI 配置文件
- META-INF/dubbo/internal/ :该目录存 Dubbo 内部使用的 SPI 配置文件
Dubbo SPI源码追踪
ExtensionLoader.getExtension 方法的整个思路是 查找缓存是否存在,不存在则读取SPI文件,通过反射创建类,然后设置依赖注入这些东西,有包装类就包装下,执行流程如下图所示:
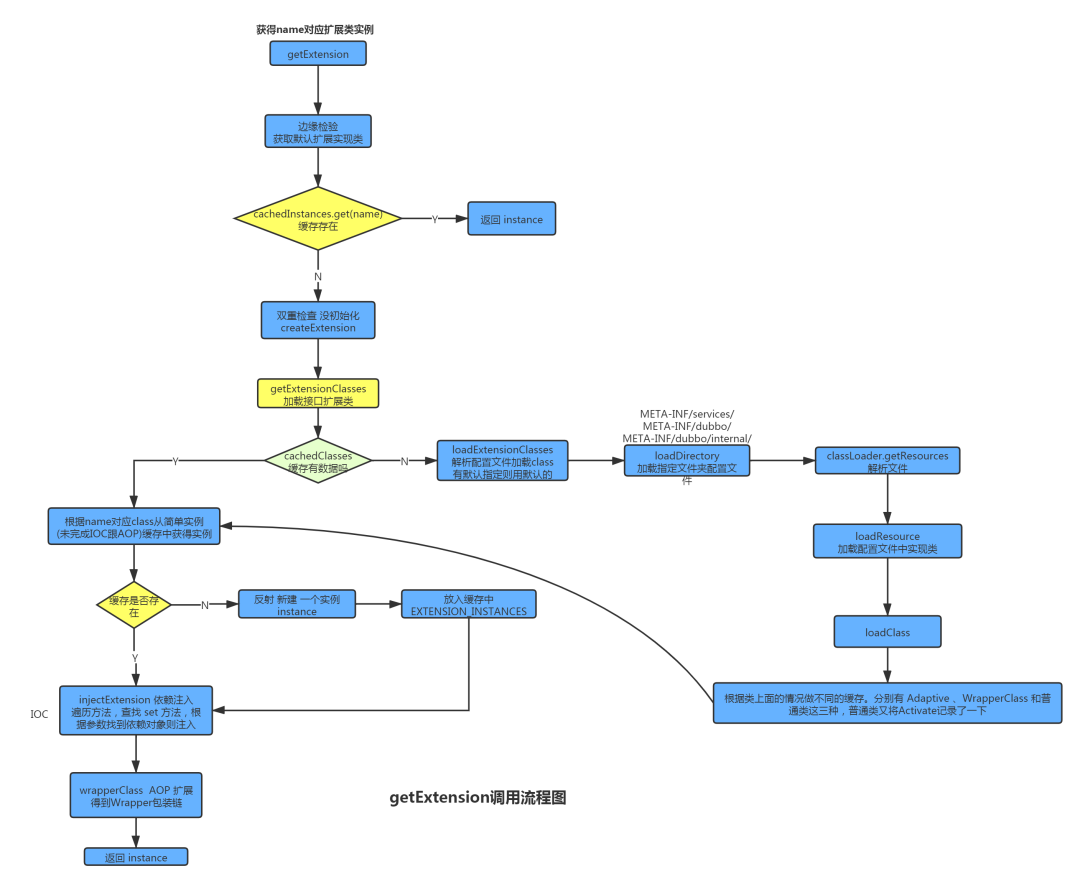
injectExtension IOC
查找 set 方法,根据参数找到依赖对象则注入。
WrapperClass AOP
包装类,Dubbo帮你自动包装,只需某个扩展类的构造函数只有一个参数,并且是扩展接口类型,就会被判定为包装类。
Activate
Active 有三个属性,group 表示修饰在哪个端,是 provider 还是 consumer,value 表示在 URL参数中出现才会被激活,order 表示实现类的顺序。
Adaptive自适应扩展
需求:根据配置来进行 SPI 扩展的加载后不想在启动的时候让扩展被加载,想根据请求时候的参数来动态选择对应的扩展。实现:Dubbo用代理机制实现了自适应扩展,为用户想扩展的接口 通过JDK 或者 Javassist 编译生成一个代理类,然后通过反射创建实例。实例会根据本来方法的请求参数得知需要的扩展类,然后通过 ExtensionLoader.getExtensionLoader(type.class).getExtension(name)来获取真正的实例来调用,看个官网样例。
public interface WheelMaker {
Wheel makeWheel(URL url);
}
// WheelMaker 接口的自适应实现类
public class AdaptiveWheelMaker implements WheelMaker {
public Wheel makeWheel(URL url) {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
// 1. 调用 url 的 getXXX 方法获取参数值
String wheelMakerName = url.getParameter("Wheel.maker");
if (wheelMakerName == null) {
throw new IllegalArgumentException("wheelMakerName == null");
}
// 2. 调用 ExtensionLoader 的 getExtensionLoader 获取加载器
// 3. 调用 ExtensionLoader 的 getExtension 根据从url获取的参数作为类名称加载实现类
WheelMaker wheelMaker = ExtensionLoader.getExtensionLoader(WheelMaker.class).getExtension(wheelMakerName);
// 4. 调用实现类的具体方法实现调用。
return wheelMaker.makeWheel(URL url);
}
}
查看Adaptive注解源码可知该注解可用在类或方法上,Adaptive 注解在类上或者方法上有不同的实现逻辑。
Adaptive注解在类上
Adaptive 注解在类上时,Dubbo 不会为该类生成代理类,Adaptive 注解在类上的情况很少,在 Dubbo 中,仅有两个类被 Adaptive 注解了,分别是 AdaptiveCompiler 和 AdaptiveExtensionFactory,表示拓展的加载逻辑由人工编码完成,这不是我们关注的重点。
Adaptive注解在方法上
Adaptive注解在方法上时,Dubbo则会为该方法生成代理逻辑,表示拓展的加载逻辑需由框架自动生成,实现机制如下:
- 加载标注有 @Adaptive 注解的接口,如果不存在,则不支持 Adaptive 机制
- 为目标接口按照一定的模板生成子类代码,并且编译生成的代码,然后通过反射生成该类的对象
- 结合生成的对象实例,通过传入的URL对象,获取指定key的配置,然后加载该key对应的类对象,最终将调用委托给该类对象进行
@SPI("apple")
public interface FruitGranter {
Fruit grant();
@Adaptive
String watering(URL url);
}
---
// 苹果种植者
public class AppleGranter implements FruitGranter {
@Override
public Fruit grant() {
return new Apple();
}
@Override
public String watering(URL url) {
System.out.println("watering apple");
return "watering finished";
}
}
---
// 香蕉种植者
public class BananaGranter implements FruitGranter {
@Override
public Fruit grant() {
return new Banana();
}
@Override
public String watering(URL url) {
System.out.println("watering banana");
return "watering success";
}
}
调用方法实现:
public class ExtensionLoaderTest {
@Test
public void testGetExtensionLoader() {
// 首先创建一个模拟用的URL对象
URL url = URL.valueOf("dubbo://192.168.0.1:1412?fruit.granter=apple");
// 通过ExtensionLoader获取一个FruitGranter对象
FruitGranter granter = ExtensionLoader.getExtensionLoader(FruitGranter.class)
.getAdaptiveExtension();
// 使用该FruitGranter调用其"自适应标注的"方法,获取调用结果
String result = granter.watering(url);
System.out.println(result);
}
}
通过如上方式生成一个内部类。
服务暴露流程
服务暴露总览
Dubbo框架是以URL为总线的模式,运行过程中所有的状态数据信息都可以通过URL来获取,比如当前系统采用什么序列化,采用什么通信,采用什么负载均衡等信息,都是通过URL的参数来呈现的,所以在框架运行过程中,运行到某个阶段需要相应的数据,都可以通过对应的Key从URL的参数列表中获取。URL 具体的参数如下:
- protocol:指的是 dubbo 中的各种协议,如:dubbo thrift http
- username/password:用户名/密码
- host/port:主机/端口
- path:接口的名称
- parameters:参数键值对
protocol://username:password@host:port/path?k=v
服务暴露从代码流程看分为三部分:
- 检查配置,最终组装成 URL。
- 暴露服务到到本地服务跟远程服务。
- 服务注册至注册中心。
服务暴露从对象构建转换看分为两步:
- 将服务封装成Invoker。
- 将Invoker通过协议转换为Exporter。
服务暴露源码追踪
- 容器启动,Spring IOC刷新完毕后调用 onApplicationEvent 开启服务暴露,ServiceBean
- export 跟 doExport 来进行拼接构建URL,为屏蔽调用的细节,统一暴露出一个可执行体,通过ProxyFactory 获取到 invoker
- 调用具体 Protocol 将把包装后的 invoker 转换成 exporter,此处用到了SPI
- 然后启动服务器server,监听端口,使用NettyServer创建监听服务器
- 通过 RegistryProtocol 将URL注册到注册中心,使得consumer可获得provider信息
服务引用流程
Dubbo中一个可执行体就是一个invoker,所以 provider 跟 consumer 都要向 invoker 靠拢。通过上面demo可知为了无感调用远程接口,底层需要有个代理类包装 invoker。
服务的引入时机有两种
-
饿汉式
通过实现 Spring 的 InitializingBean 接口中的 afterPropertiesSet 方法,容器通过调用 ReferenceBean的 afterPropertiesSet 方法时引入服务。
-
懒汉式(默认)
懒汉式是只有当服务被注入到其他类中时启动引入流程。
服务引用的三种方式
- 本地引入:服务暴露时本地暴露,避免网络调用开销
- 直接连接引入远程服务:不启动注册中心,直接写死远程Provider地址 进行直连
- 通过注册中心引入远程服务:通过注册中心抉择如何进行负载均衡调用远程服务
服务引用流程
- 检查配置构建map ,map 构建 URL ,通过URL上的协议利用自适应扩展机制调用对应的 protocol.refer 得到相应的 invoker ,此处
- 想注册中心注册自己,然后订阅注册中心相关信息,得到provider的 ip 等信息,再通过共享的netty客户端进行连接。
- 当有多个 URL 时,先遍历构建出 invoker 然后再由 StaticDirectory 封装一下,然后通过 cluster 进行合并,只暴露出一个 invoker 。
- 然后再构建代理,封装 invoker 返回服务引用,之后 Comsumer 调用的就是这个代理类。
调用方式
- oneway:不关心请求是否发送成功。
- Async异步调用:Dubbo天然异步,客户端调用请求后将返回的 ResponseFuture 存到上下文中,用户可随时调用 future.get 获取结果。异步调用通过唯一ID 标识此次请求。
- Sync同步调用:在 Dubbo 源码中就调用了 future.get,用户感觉方法被阻塞了,必须等结果后才返回。
调用整体流程
调用之前你可能需要考虑这些事
- consumer 跟 provider 约定好通讯协议,dubbo支持多种协议,比如dubbo、rmi、hessian、http、webservice等。默认走dubbo协议,连接属于单一长连接,NIO异步通信。适用传输数据量很小(单次请求在100kb以内),但是并发量很高。
- 约定序列化模式,大致分为两大类,一种是字符型(XML或json 人可看懂 但传输效率低),一种是二进制流(数据紧凑,机器友好)。默认使用 hessian2作为序列化协议。
- consumer 调用 provider 时提供对应接口、方法名、参数类型、参数值、版本号。
- provider列表对外提供服务涉及到负载均衡选择一个provider提供服务。
- consumer 跟 provider 定时向monitor 发送信息。
调用大致流程
- 客户端发起请求来调用接口,接口调用生成的代理类。代理类生成RpcInvocation 然后调用invoke方法。
- ClusterInvoker获得注册中心中服务列表,通过负载均衡给出一个可用的invoker。
- 序列化跟反序列化网络传输数据。通过NettyServer调用网络服务。
- 服务端业务线程池接受解析数据,从exportMap找到invoker进行invoke。
- 调用真正的Impl得到结果然后返回。
调用方式
- oneway:不关心请求是否发送成功,消耗最小。
- sync同步调用:在 Dubbo 源码中就调用了 future.get,用户感觉方法被阻塞了,必须等结果后才返回。
- Async 异步调用:Dubbo天然异步,客户端调用请求后将返回的 ResponseFuture 存到上下文中,用户可以随时调用future.get获取结果。异步调用通过唯一ID标识此次请求。
集群容错负载均衡
Dubbo 引入了Cluster、Directory、Router、LoadBalance、Invoker模块来保证Dubbo系统的稳健性,关系如下图:
- 服务发现时会将多个多个远程调用放入Directory,然后通过Cluster封装成一个Invoker,该invoker提供容错功能
- 消费者代用的时候从Directory中通过负载均衡获得一个可用invoker,最后发起调用
- 你可以认为Dubbo中的Cluster对上面进行了大的封装,自带各种鲁棒性功能
集群容错
集群容错是在消费者端通过Cluster子类实现的,Cluster接口有10个实现类,每个Cluster实现类都会创建一个对应的ClusterInvoker对象。核心思想是让用户选择性调用这个Cluster中间层,屏蔽后面具体实现细节。
| Cluster | Cluster Invoker | 作用 |
|---|---|---|
| FailoverCluster | FailoverClusterInvoker | 失败自动切换功能,默认 |
| FailfastCluster | FailfastClusterInvoker | 一次调用,失败异常 |
| FailsafeCluster | FailsafeClusterInvoker | 调用出错则日志记录 |
| FailbackCluster | FailbackClusterInvoker | 失败返空,定时重试2次 |
| ForkingCluster | ForkingClusterInvoker | 一个任务并发调用,一个OK则OK |
| BroadcastCluster | BroadcastClusterInvoker | 逐个调用invoker,全可用才可用 |
| AvailableCluster | AvailableClusterInvoker | 哪个能用就用那个 |
| MergeableCluster | MergeableClusterInvoker | 按组合并返回结果 |
智能容错之负载均衡
Dubbo中一般有4种负载均衡策略。
- RandomLoadBalance:加权随机,它的算法思想简单。假设有一组服务器 servers = [A, B, C],对应权重为 weights = [5, 3, 2],权重总和为10。现把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。默认实现。
- LeastActiveLoadBalance:最少活跃数负载均衡,选择现在活跃调用数最少的提供者进行调用,活跃的调用数少说明它现在很轻松,而且活跃数都是从 0 加起来的,来一个请求活跃数+1,一个请求处理完成活跃数-1,所以活跃数少也能变相的体现处理的快。
- RoundRobinLoadBalance:加权轮询负载均衡,比如现在有两台服务器 A、B,轮询的调用顺序就是 A、B、A、B,如果加了权重,A 比B 的权重是2:1,那现在的调用顺序就是 A、A、B、A、A、B。
- ConsistentHashLoadBalance:一致性 Hash 负载均衡,将服务器的 IP 等信息生成一个 hash 值,将hash 值投射到圆环上作为一个节点,然后当 key 来查找的时候顺时针查找第一个大于等于这个 key 的 hash 值的节点。一般而言还会引入虚拟节点,使得数据更加的分散,避免数据倾斜压垮某个节点。如下图 Dubbo 默认搞了 160 个虚拟节点。
智能容错之服务目录
关于 服务目录Directory 你可以理解为是相同服务Invoker的集合,核心是RegistryDirectory类。具有三个功能。
- 从注册中心获得invoker列表
- 监控着注册中心invoker的变化,invoker的上下线
- 刷新invokers列表到服务目录
智能容错之服务路由
服务路由其实就是路由规则,它规定了服务消费者可以调用哪些服务提供者。条件路由规则由两个条件组成,分别用于对服务消费者和提供者进行匹配。比如有这样一条规则:
host = 10.20.153.14 => host = 10.20.153.12
该条规则表示 IP 为 10.20.153.14 的服务消费者只可调用 IP 为 10.20.153.12 机器上的服务,不可调用其他机器上的服务。条件路由规则的格式如下:
[服务消费者匹配条件] => [服务提供者匹配条件]
如果服务消费者匹配条件为空,表示不对服务消费者进行限制。如果服务提供者匹配条件为空,表示对某些服务消费者禁用服务。
设计RPC
一个RPC框架大致需要以下功能:
- 服务的注册与发现
- 用动态代理
- 负载均衡(LoadBalance)
- 通信协议
- 序列化与反序列化
- 网络通信(Netty)
- Monitor
Nacos
基本架构
服务 (Service)
服务是指一个或一组软件功能(例如特定信息的检索或一组操作的执行),其目的是不同的客户端可以为不同的目的重用(例如通过跨进程的网络调用)。Nacos 支持主流的服务生态,如 Kubernetes Service、gRPC|Dubbo RPC Service 或者 Spring Cloud RESTful Service。
服务注册中心 (Service Registry)
服务注册中心,它是服务,其实例及元数据的数据库。服务实例在启动时注册到服务注册表,并在关闭时注销。服务和路由器的客户端查询服务注册表以查找服务的可用实例。服务注册中心可能会调用服务实例的健康检查 API 来验证它是否能够处理请求。
服务元数据 (Service Metadata)
服务元数据是指包括服务端点(endpoints)、服务标签、服务版本号、服务实例权重、路由规则、安全策略等描述服务的数据。
服务提供方 (Service Provider)
是指提供可复用和可调用服务的应用方。
服务消费方 (Service Consumer)
是指会发起对某个服务调用的应用方。
配置 (Configuration)
在系统开发过程中通常会将一些需要变更的参数、变量等从代码中分离出来独立管理,以独立的配置文件的形式存在。目的是让静态的系统工件或者交付物(如 WAR,JAR 包等)更好地和实际的物理运行环境进行适配。配置管理一般包含在系统部署的过程中,由系统管理员或者运维人员完成这个步骤。配置变更是调整系统运行时的行为的有效手段之一。
配置管理 (Configuration Management)
在数据中心中,系统中所有配置的编辑、存储、分发、变更管理、历史版本管理、变更审计等所有与配置相关的活动统称为配置管理。
名字服务 (Naming Service)
提供分布式系统中所有对象(Object)、实体(Entity)的“名字”到关联的元数据之间的映射管理服务,例如 ServiceName -> Endpoints Info, Distributed Lock Name -> Lock Owner/Status Info, DNS Domain Name -> IP List, 服务发现和 DNS 就是名字服务的2大场景。
配置服务 (Configuration Service)
在服务或者应用运行过程中,提供动态配置或者元数据以及配置管理的服务提供者。
逻辑架构
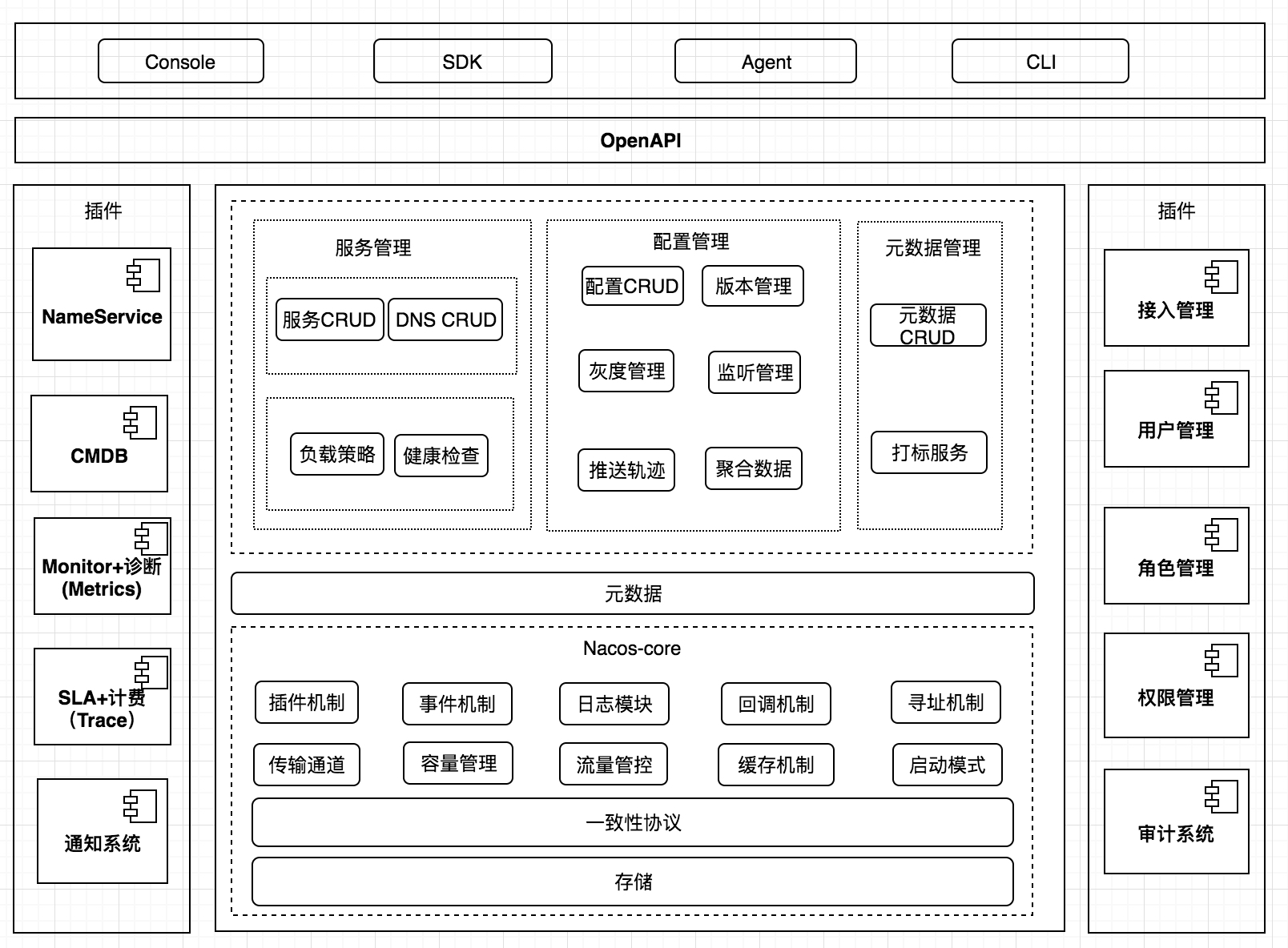
- 服务管理:实现服务CRUD,域名CRUD,服务健康状态检查,服务权重管理等功能
- 配置管理:实现配置管CRUD,版本管理,灰度管理,监听管理,推送轨迹,聚合数据等功能
- 元数据管理:提供元数据CURD 和打标能力
- 插件机制:实现三个模块可分可合能力,实现扩展点SPI机制
- 事件机制:实现异步化事件通知,sdk数据变化异步通知等逻辑
- 日志模块:管理日志分类,日志级别,日志可移植性(尤其避免冲突),日志格式,异常码+帮助文档
- 回调机制:sdk通知数据,通过统一的模式回调用户处理。接口和数据结构需要具备可扩展性
- 寻址模式:解决ip,域名,nameserver、广播等多种寻址模式,需要可扩展
- 推送通道:解决server与存储、server间、server与sdk间推送性能问题
- 容量管理:管理每个租户,分组下的容量,防止存储被写爆,影响服务可用性
- 流量管理:按照租户,分组等多个维度对请求频率,长链接个数,报文大小,请求流控进行控制
- 缓存机制:容灾目录,本地缓存,server缓存机制。容灾目录使用需要工具
- 启动模式:按照单机模式,配置模式,服务模式,dns模式,或者all模式,启动不同的程序+UI
- 一致性协议:解决不同数据,不同一致性要求情况下,不同一致性机制
- 存储模块:解决数据持久化、非持久化存储,解决数据分片问题
- Nameserver:解决namespace到clusterid的路由问题,解决用户环境与nacos物理环境映射问题
- CMDB:解决元数据存储,与三方cmdb系统对接问题,解决应用,人,资源关系
- Metrics:暴露标准metrics数据,方便与三方监控系统打通
- Trace:暴露标准trace,方便与SLA系统打通,日志白平化,推送轨迹等能力,并且可以和计量计费系统打通
- 接入管理:相当于阿里云开通服务,分配身份、容量、权限过程
- 用户管理:解决用户管理,登录,sso等问题
- 权限管理:解决身份识别,访问控制,角色管理等问题
- 审计系统:扩展接口方便与不同公司审计系统打通
- 通知系统:核心数据变更,或者操作,方便通过SMS系统打通,通知到对应人数据变更
- OpenAPI:暴露标准Rest风格HTTP接口,简单易用,方便多语言集成
- Console:易用控制台,做服务管理、配置管理等操作
- SDK:多语言sdk
- Agent:dns-f类似模式,或者与mesh等方案集成
- CLI:命令行对产品进行轻量化管理,像git一样好用
功能特性
Nacos 的关键特性包括:
-
服务发现和服务健康监测
-
动态配置服务
-
动态 DNS 服务
-
服务及其元数据管理
数据模型
Nacos 数据模型 Key 由三元组唯一确定, Namespace默认是空串,公共命名空间(public),分组默认是 DEFAULT_GROUP。
Nacos-SDK类视图
配置领域模型
围绕配置,主要有两个关联的实体,一个是配置变更历史,一个是服务标签(用于打标分类,方便索引),由 ID 关联。
安装部署
下载源码或者安装包
从 Github 上下载源码方式
git clone https://github.com/alibaba/nacos.git
cd nacos/
mvn -Prelease-nacos -Dmaven.test.skip=true clean install -U
ls -al distribution/target/
// change the $version to your actual path
cd distribution/target/nacos-server-$version/nacos/bin
下载编译后压缩包方式
您可以从 最新稳定版本 下载 nacos-server-$version.zip 包。
unzip nacos-server-$version.zip 或者 tar -xvf nacos-server-$version.tar.gz
cd nacos/bin
启动服务器
Linux/Unix/Mac
启动命令(standalone代表着单机模式运行,非集群模式):
sh startup.sh -m standalone
如果您使用的是ubuntu系统,或者运行脚本报错提示符号找不到,可尝试如下运行:
bash startup.sh -m standalone
Windows
启动命令(standalone代表着单机模式运行,非集群模式):
startup.cmd -m standalone
服务测试
服务注册
curl -X POST 'http://127.0.0.1:8848/nacos/v1/ns/instance?serviceName=nacos.naming.serviceName&ip=20.18.7.10&port=8080'
服务发现
curl -X GET 'http://127.0.0.1:8848/nacos/v1/ns/instance/list?serviceName=nacos.naming.serviceName'
发布配置
curl -X POST "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=nacos.cfg.dataId&group=test&content=HelloWorld"
获取配置
curl -X GET "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=nacos.cfg.dataId&group=test"
关闭服务器
Linux/Unix/Mac
sh shutdown.sh
Windows
shutdown.cmd
或者双击 shutdown.cmd运行文件。
开源案例
Spring Boot
启动配置管理
启动了 Nacos server 后,您就可以参考以下示例代码,为您的 Spring Boot 应用启动 Nacos 配置管理服务了。
第一步:添加依赖
<dependency>
<groupId>com.alibaba.boot</groupId>
<artifactId>nacos-config-spring-boot-starter</artifactId>
<version>${latest.version}</version>
</dependency>
注意:版本 0.2.x.RELEASE 对应的是 Spring Boot 2.x 版本,版本 0.1.x.RELEASE 对应的是 Spring Boot 1.x 版本。
第二步:在 application.properties 中配置 Nacos server 的地址:
nacos.config.server-addr=127.0.0.1:8848
第三步:使用 @NacosPropertySource 加载 dataId 为 example 的配置源,并开启自动更新:
@SpringBootApplication
@NacosPropertySource(dataId = "example", autoRefreshed = true)
public class NacosConfigApplication {
public static void main(String[] args) {
SpringApplication.run(NacosConfigApplication.class, args);
}
}
第四步:通过 Nacos 的 @NacosValue 注解设置属性值。
@Controller
@RequestMapping("config")
public class ConfigController {
@NacosValue(value = "${useLocalCache:false}", autoRefreshed = true)
private boolean useLocalCache;
@RequestMapping(value = "/get", method = GET)
@ResponseBody
public boolean get() {
return useLocalCache;
}
}
第五步:启动 NacosConfigApplication,调用 curl http://localhost:8080/config/get,返回内容是 false。
第六步:通过调用 Nacos Open API 向 Nacos server 发布配置:dataId 为example,内容为useLocalCache=true
curl -X POST "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=example&group=DEFAULT_GROUP&content=useLocalCache=true"
第七步:再次访问 http://localhost:8080/config/get,此时返回内容为true,说明程序中的useLocalCache值已经被动态更新了。
启动服务发现
本节演示如何在您的 Spring Boot 项目中启动 Nacos 的服务发现功能。
第一步:添加依赖
<dependency>
<groupId>com.alibaba.boot</groupId>
<artifactId>nacos-discovery-spring-boot-starter</artifactId>
<version>${latest.version}</version>
</dependency>
注意:版本 0.2.x.RELEASE 对应的是 Spring Boot 2.x 版本,版本 0.1.x.RELEASE 对应的是 Spring Boot 1.x 版本。
第二步:在 application.properties 中配置 Nacos server 的地址:
nacos.discovery.server-addr=127.0.0.1:8848
第三步:使用 @NacosInjected 注入 Nacos 的 NamingService 实例:
@Controller
@RequestMapping("discovery")
public class DiscoveryController {
@NacosInjected
private NamingService namingService;
@RequestMapping(value = "/get", method = GET)
@ResponseBody
public List<Instance> get(@RequestParam String serviceName) throws NacosException {
return namingService.getAllInstances(serviceName);
}
}
@SpringBootApplication
public class NacosDiscoveryApplication {
public static void main(String[] args) {
SpringApplication.run(NacosDiscoveryApplication.class, args);
}
}
第四步:启动 NacosDiscoveryApplication,调用 curl http://localhost:8080/discovery/get?serviceName=example,此时返回为空 JSON 数组[]。
第五步:通过调用 Nacos Open API 向 Nacos server 注册一个名称为 example 服务
curl -X PUT 'http://127.0.0.1:8848/nacos/v1/ns/instance?serviceName=example&ip=127.0.0.1&port=8080'
第六步:再次访问 curl http://localhost:8080/discovery/get?serviceName=example,此时返回内容为:
[
{
"instanceId": "127.0.0.1-8080-DEFAULT-example",
"ip": "127.0.0.1",
"port": 8080,
"weight": 1.0,
"healthy": true,
"cluster": {
"serviceName": null,
"name": "",
"healthChecker": {
"type": "TCP"
},
"defaultPort": 80,
"defaultCheckPort": 80,
"useIPPort4Check": true,
"metadata": {}
},
"service": null,
"metadata": {}
}
]
Spring Cloud
启动配置管理
启动了 Nacos server 后,您就可以参考以下示例代码,为您的 Spring Cloud 应用启动 Nacos 配置管理服务了。
第一步:添加依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
<version>${latest.version}</version>
</dependency>
注意:版本 2.1.x.RELEASE 对应的是 Spring Boot 2.1.x 版本。版本 2.0.x.RELEASE 对应的是 Spring Boot 2.0.x 版本,版本 1.5.x.RELEASE 对应的是 Spring Boot 1.5.x 版本。
第二步:在 bootstrap.properties 中配置 Nacos server 的地址和应用名
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.application.name=example
说明:之所以需要配置 spring.application.name ,是因为它是构成 Nacos 配置管理 dataId字段的一部分。
第三步:在 Nacos Spring Cloud 中,dataId 的完整格式如下:
${prefix}-${spring.profiles.active}.${file-extension}
prefix默认为spring.application.name的值,也可以通过配置项spring.cloud.nacos.config.prefix来配置。spring.profiles.active即为当前环境对应的 profile,详情可以参考 Spring Boot文档。 注意:当spring.profiles.active为空时,对应的连接符-也将不存在,dataId 的拼接格式变成${prefix}.${file-extension}file-exetension为配置内容的数据格式,可以通过配置项spring.cloud.nacos.config.file-extension来配置。目前只支持properties和yaml类型。
第四步:通过 Spring Cloud 原生注解 @RefreshScope 实现配置自动更新:
@RestController
@RequestMapping("/config")
@RefreshScope
public class ConfigController {
@Value("${useLocalCache:false}")
private boolean useLocalCache;
@RequestMapping("/get")
public boolean get() {
return useLocalCache;
}
}
第五步:首先通过调用 Nacos Open API 向 Nacos Server 发布配置:dataId 为example.properties,内容为useLocalCache=true
curl -X POST "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=example.properties&group=DEFAULT_GROUP&content=useLocalCache=true"
第六步:运行 NacosConfigApplication,调用 curl http://localhost:8080/config/get,返回内容是 true。
第七步:再次调用 Nacos Open API 向 Nacos server 发布配置:dataId 为example.properties,内容为useLocalCache=false
curl -X POST "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=example.properties&group=DEFAULT_GROUP&content=useLocalCache=false"
第八步:再次访问 http://localhost:8080/config/get,此时返回内容为false,说明程序中的useLocalCache值已经被动态更新了。
启动服务发现
本节通过实现一个简单的 echo service 演示如何在您的 Spring Cloud 项目中启用 Nacos 的服务发现功能,如下图示:
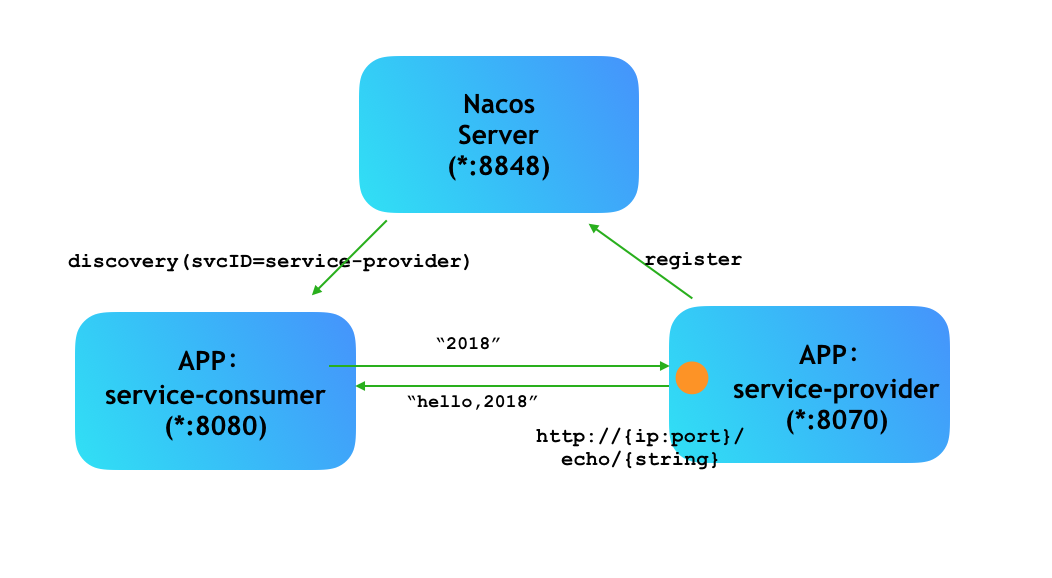
第一步:添加依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>${latest.version}</version>
</dependency>
注意:版本 2.1.x.RELEASE 对应的是 Spring Boot 2.1.x 版本。版本 2.0.x.RELEASE 对应的是 Spring Boot 2.0.x 版本,版本 1.5.x.RELEASE 对应的是 Spring Boot 1.5.x 版本。
第二步:配置服务提供者,从而服务提供者可以通过 Nacos 的服务注册发现功能将其服务注册到 Nacos server 上。
i. 在 application.properties 中配置 Nacos server 的地址:
server.port=8070
spring.application.name=service-provider
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
ii. 通过 Spring Cloud 原生注解 @EnableDiscoveryClient 开启服务注册发现功能:
@SpringBootApplication
@EnableDiscoveryClient
public class NacosProviderApplication {
public static void main(String[] args) {
SpringApplication.run(NacosProviderApplication.class, args);
}
@RestController
class EchoController {
@RequestMapping(value = "/echo/{string}", method = RequestMethod.GET)
public String echo(@PathVariable String string) {
return "Hello Nacos Discovery " + string;
}
}
}
第三步:配置服务消费者,从而服务消费者可通过 Nacos 的服务注册发现功能从 Nacos server 上获取到它要调用的服务。
i. 在 application.properties 中配置 Nacos server 的地址:
server.port=8080
spring.application.name=service-consumer
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
ii. 通过 Spring Cloud 原生注解 @EnableDiscoveryClient 开启服务注册发现功能。给 RestTemplate 实例添加 @LoadBalanced 注解,开启 @LoadBalanced 与 Ribbon 的集成:
@SpringBootApplication
@EnableDiscoveryClient
public class NacosConsumerApplication {
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(NacosConsumerApplication.class, args);
}
@RestController
public class TestController {
private final RestTemplate restTemplate;
@Autowired
public TestController(RestTemplate restTemplate) {this.restTemplate = restTemplate;}
@RequestMapping(value = "/echo/{str}", method = RequestMethod.GET)
public String echo(@PathVariable String str) {
return restTemplate.getForObject("http://service-provider/echo/" + str, String.class);
}
}
}
第四步:启动 ProviderApplication 和 ConsumerApplication ,调用 http://localhost:8080/echo/2018,返回内容为 Hello Nacos Discovery 2018。
Sentinel
Sentinel(分布式系统的流量防卫兵)。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。Sentinel 具有以下特征:
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等
主要特性
Sentinel 的主要特性:
开源生态
Sentinel 的开源生态:
Sentinel 分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器
Quick Start
手动接入Sentinel以及控制台
下面例子将展示应用如何三步接入 Sentinel。同时,Sentinel 也提供所见即所得的控制台,可实时监控资源以及管理规则。
STEP 1. 在应用中引入Sentinel Jar包
如果应用使用 pom 工程,则在 pom.xml 文件中加入以下代码即可:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.1</version>
</dependency>
注意: Sentinel仅支持JDK 1.8或者以上版本。如果未使用依赖管理工具,请到 Maven Center Repository 直接下载JAR 包。
STEP 2. 定义资源
接下来,我们把需要控制流量的代码用 Sentinel API SphU.entry("HelloWorld") 和 entry.exit() 包围起来即可。在下面的例子中,我们将 System.out.println("hello world"); 这端代码作为资源,用 API 包围起来(埋点)。参考代码如下:
public static void main(String[] args) {
initFlowRules();
while (true) {
Entry entry = null;
try {
entry = SphU.entry("HelloWorld");
/*您的业务逻辑 - 开始*/
System.out.println("hello world");
/*您的业务逻辑 - 结束*/
} catch (BlockException e1) {
/*流控逻辑处理 - 开始*/
System.out.println("block!");
/*流控逻辑处理 - 结束*/
} finally {
if (entry != null) {
entry.exit();
}
}
}
}
完成以上两步后,代码端的改造就完成了。当然,我们也提供了 注解支持模块,可以以低侵入性的方式定义资源。
STEP 3. 定义规则
接下来,通过规则来指定允许该资源通过的请求次数,如下面的代码定义了资源 HelloWorld 每秒最多只能通过 20 个请求。
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
完成上面 3 步,Sentinel 就能够正常工作了。更多的信息可以参考 使用文档。
STEP 4. 检查效果
Demo 运行之后,我们可以在日志 ~/logs/csp/${appName}-metrics.log.xxx 里看到下面的输出:
|--timestamp-|------date time----|-resource-|p |block|s |e|rt
1529998904000|2018-06-26 15:41:44|HelloWorld|20|0 |20|0|0
1529998905000|2018-06-26 15:41:45|HelloWorld|20|5579 |20|0|728
1529998906000|2018-06-26 15:41:46|HelloWorld|20|15698|20|0|0
1529998907000|2018-06-26 15:41:47|HelloWorld|20|19262|20|0|0
1529998908000|2018-06-26 15:41:48|HelloWorld|20|19502|20|0|0
1529998909000|2018-06-26 15:41:49|HelloWorld|20|18386|20|0|0
其中 p 代表通过的请求, block 代表被阻止的请求, s 代表成功执行完成的请求个数, e 代表用户自定义的异常, rt 代表平均响应时长。可以看到,这个程序每秒稳定输出 "hello world" 20 次,和规则中预先设定的阈值是一样的。
STEP 5. 启动 Sentinel 控制台
您可以参考 Sentinel 控制台文档 启动控制台,可以实时监控各个资源的运行情况,并且可以实时地修改限流规则。
Influxdb
InfluxDB 是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。InfluxDB在DB-Engines的时序数据库类别里排名第一。
重要特性
- **极简架构:**单机版的InfluxDB只需要安装一个binary,即可运行使用,完全没有任何的外部依赖
- 极强的写入能力: 底层采用自研的TSM存储引擎,TSM也是基于LSM的思想,提供极强的写能力以及高压缩率
- **高效查询:**对Tags会进行索引,提供高效的检索
- InfluxQL:提供QL-Like的查询语言,极大的方便了使用,数据库在易用性上演进的终极目标都是提供Query Language
- Continuous Queries: 通过CQ能够支持auto-rollup和pre-aggregation,对常见的查询操作可以通过CQ来预计算加速查询
存储引擎
InfluxDB 采用自研的TSM (Time-Structured Merge Tree) 作为存储引擎, 其核心思想是通过牺牲掉一些功能来对性能达到极致优化,其官方文档上有项目存储引擎经历了从LevelDB到BlotDB,再到选择自研TSM的过程,整个选择转变的思考。
时序数据库的需求:
- 数十亿个单独的数据点
- 高写入吞吐量
- 高读取吞吐量
- 大型删除(数据过期)
- 主要是插入/追加工作负载,很少更新
LSM
LSM 的局限性
在官方文档上有写, 为了解决高写入吞吐量的问题, Influxdb 一开始选择了LevelDB 作为其存储引擎。 然而,随着更多地了解人们对时间序列数据的需求,influxdb遇到了一些无法克服的挑战。
LSM (日志结构合并树)为 LevelDB的引擎原理
- levelDB 不支持热备份。 对数据库进行安全备份必须关闭后才能复制。LevelDB的RocksDB和HyperLevelDB变体可以解决此问题
- 时序数据库需要提供一种自动管理数据保存的方式。 即删除过期数据, 而在levelDB 中,删除的代价过高。(通过添加墓碑的方式, 段结构合并的时候才会真正物理性的删除)
TSM
按不同的时间范围划分为不同的分区(Shard),因为时序数据写入都是按时间线性产生的,所以分区的产生也是按时间线性增长的,写入通常是在最新的分区,而不会散列到多个分区。分区的优点是数据回收的物理删除非常简单,直接把整个分区删除即可。
- 在最开始的时候, influxdb 采用的方案每个shard都是一个独立的数据库实例,底层都是一套独立的LevelDB存储引擎。 这时带来的问题是,LevelDB底层采用level compaction策略,每个存储引擎都会打开比较多的文件,随着shard的增多,最终进程打开的文件句柄会很快触及到上限
- 由于遇到大量的客户反馈文件句柄过多的问题,InfluxDB在新版本的存储引擎选型中选择了BoltDB替换LevelDB。BoltDB底层数据结构是mmap B+树。 但由于B+ 树会产生大量的随机写。 所以写入性能较差
- 之后Influxdb 最终决定仿照LSM 的思想自研TSM ,主要改进点是基于时序数据库的特性作出一些优化,包含Cache、WAL以及Data File等各个组件,也会有flush、compaction等这类数据操作
系统架构
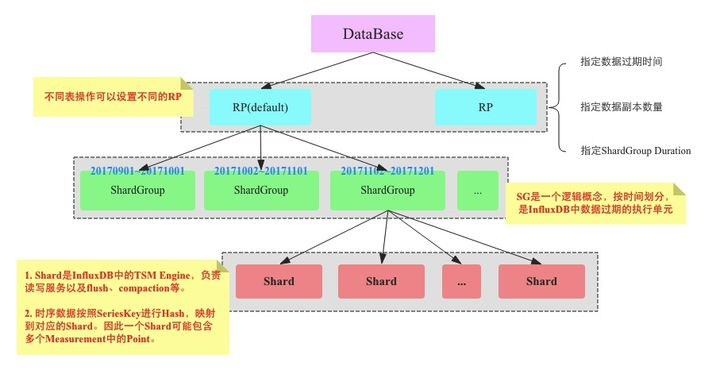
- **DataBase:**用户可以通过 create database xxx 来创建一个database
- Retention Policy(RP): 数据保留策略, 可用来规定数据的的过期时间
- Shard Group: 实现了数据分区,但是Shard Group只是一个逻辑概念,在它里面包含了大量Shard,Shard才是InfluxDB中真正存储数据以及提供读写服务的概念
Spring
Spring是一个轻量级的IoC和AOP容器框架。是为Java应用程序提供基础性服务的一套框架,目的是用于简化企业应用程序的开发,它使得开发者只需要关心业务需求。
Spring的优点?
- spring属于低侵入式设计,代码的污染极低
- spring的DI机制将对象之间的依赖关系交由框架处理,减低组件的耦合性
- Spring提供了AOP技术,支持将一些通用任务,如安全、事务、日志、权限等进行集中式管理,从而提供更好的复用
- spring对于主流的应用框架提供了集成支持
使用Spring框架的好处是什么?
- **轻量:**Spring 是轻量的,基本的版本大约2MB
- **控制反转:**Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,而不是创建或查找依赖的对象们。
- **面向切面的编程(AOP):**Spring支持面向切面的编程,并且把应用业务逻辑和系统服务分开
- **容器:**Spring 包含并管理应用中对象的生命周期和配置
- MVC框架:Spring的WEB框架是个精心设计的框架,是Web框架的一个很好的替代品
- **事务管理:**Spring 提供一个持续的事务管理接口,可以扩展到上至本地事务下至全局事务(JTA)
- **异常处理:**Spring 提供方便的API把具体技术相关的异常(比如由JDBC,Hibernate or JDO抛出的)转化为一致的unchecked 异常
相关概念
Spring
Spring是一个开源容器框架,可以接管web层,业务层,dao层,持久层的组件,并且可以配置各种bean,和维护bean与bean之间的关系。其核心就是控制反转(IOC),和面向切面(AOP),简单的说就是一个分层的轻量级开源框架。
SpringMVC
Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面。SpringMVC是一种web层mvc框架,用于替代servlet(处理|响应请求,获取表单参数,表单校验等。SpringMVC是一个MVC的开源框架,SpringMVC = struts2 + spring,springMVC就相当于是Struts2加上Spring的整合。
SpringMVC是属于SpringWeb里面的一个功能模块(SpringWebMVC)。专门用来开发SpringWeb项目的一种MVC模式的技术框架实现。
SpringBoot
Springboot是一个微服务框架,延续了spring框架的核心思想IOC和AOP,简化了应用的开发和部署。Spring Boot是为了简化Spring应用的创建、运行、调试、部署等而出现的,使用它可以做到专注于Spring应用的开发,而无需过多关注XML的配置。提供了一堆依赖打包,并已经按照使用习惯解决了依赖问题—>习惯大于约定。
Spring Boot基本上是Spring框架的扩展,它消除了设置Spring应用程序所需的XML配置,为更快,更高效的开发生态系统铺平了道路。Spring Boot中的一些特点:
- 创建独立的spring应用
- 嵌入Tomcat, JettyUndertow 而且不需要部署他们
- 提供的“starters” poms来简化Maven配置
- 尽可能自动配置spring应用
- 提供生产指标,健壮检查和外部化配置
- 绝对没有代码生成和XML配置要求
Spring原理
核心组件
Spring常用模块
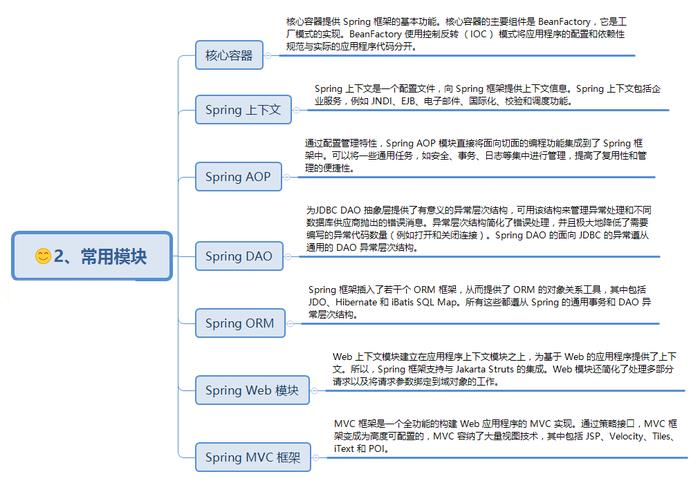
主要包括以下七个模块:
- Spring Context:提供框架式的Bean访问方式,以及企业级功能(JNDI、定时任务等)
- Spring Core:核心类库,所有功能都依赖于该类库,提供IOC和DI服务
- Spring AOP:AOP服务
- Spring Web:提供了基本的面向Web的综合特性,提供对常见框架如Struts2的支持,Spring能够管理这些框架,将Spring的资源注入给框架,也能在这些框架的前后插入拦截器
- Spring MVC:提供面向Web应用的Model-View-Controller,即MVC实现
- Spring DAO:对JDBC的抽象封装,简化了数据访问异常的处理,并能统一管理JDBC事务
- Spring ORM:对现有的ORM框架的支持
Spring主要包

Spring常用注解
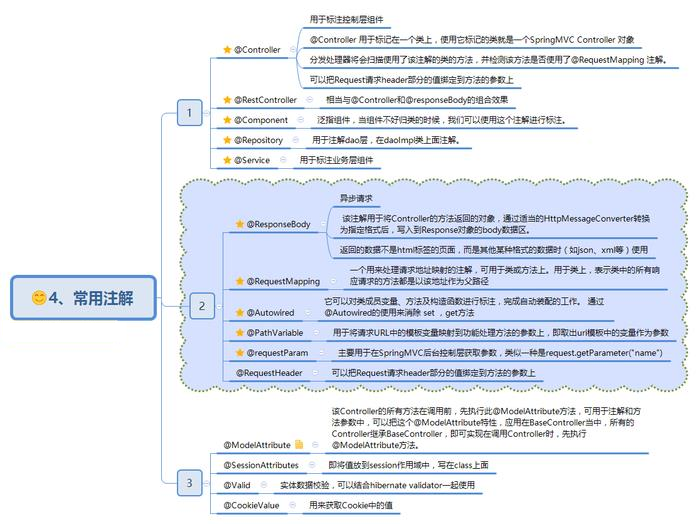
IoC
IOC就是控制反转,指创建对象的控制权转移给Spring框架进行管理,并由Spring根据配置文件去创建实例和管理各个实例之间的依赖关系,对象与对象之间松散耦合,也利于功能的复用。DI依赖注入,和控制反转是同一个概念的不同角度的描述,即 应用程序在运行时依赖IoC容器来动态注入对象需要的外部依赖。
最直观的表达就是,以前创建对象的主动权和时机都是由自己把控的,IOC让对象的创建不用去new了,可以由spring自动生产,使用java的反射机制,根据配置文件在运行时动态的去创建对象以及管理对象,并调用对象的方法的。
Spring的IOC有三种注入方式 :构造器注入、setter方法注入、根据注解注入。
AOP
AOP,一般称为面向切面,作为面向对象的一种补充,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,提高系统的可维护性。可用于权限认证、日志、事务处理。AOP实现的关键在于 代理模式,AOP代理主要分为静态代理和动态代理。静态代理的代表为AspectJ;动态代理则以Spring AOP为代表。
静态代理
AspectJ是静态代理,也称为编译时增强,AOP框架会在编译阶段生成AOP代理类,并将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
动态代理
Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理:
-
JDK动态代理:只提供接口的代理,不支持类的代理,要求被代理类实现接口。JDK动态代理的核心是InvocationHandler接口和Proxy类,在获取代理对象时,使用Proxy类来动态创建目标类的代理类(即最终真正的代理类,这个类继承自Proxy并实现了我们定义的接口),当代理对象调用真实对象的方法时, InvocationHandler 通过invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起。
InvocationHandler的invoke(Object proxy,Method method,Object[] args):
- proxy:是最终生成的代理对象
- method:是被代理目标实例的某个具体方法;
- args:是被代理目标实例某个方法的具体入参, 在方法反射调用时使用
-
CGLIB动态代理:如果被代理类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
静态代理与动态代理区别?
生成AOP代理对象的时机不同,相对来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译器进行处理,而Spring AOP则无需特定的编译器处理。
IoC让相互协作的组件保持松散的耦合,而AOP编程允许你把遍布于应用各层的功能分离出来形成可重用的功能组件。
应用场景
AOP 主要应用场景有:
- Authentication 权限
- Caching 缓存
- Context passing 内容传递
- Error handling 错误处理
- Lazy loading 懒加载
- Debugging 调试
- logging, tracing, profiling and monitoring 记录跟踪 优化 校准
- Performance optimization 性能优化
- Persistence 持久化
- Resource pooling 资源池
- Synchronization 同步
- Transactions 事务
过滤器(Filter)
主要作用是过滤字符编码、做一些业务逻辑判断,主要用于对用户请求进行预处理,同时也可进行逻辑判断。Filter在请求进入servlet容器执行service()方法之前就会经过filter过滤,不像Intreceptor一样依赖于springmvc框架,只需要依赖于servlet。Filter启动是随WEB应用的启动而启动,只需要初始化一次,以后都可以进行拦截。Filter有如下几个种类:
- 用户授权Filter:检查用户请求,根据请求过滤用户非法请求
- 日志Filter:记录某些特殊的用户请求
- 解码Filter:对非标准编码的请求解码
拦截器(Interceptor)
主要作用是拦截用户请求,进行处理。比如判断用户登录情况、权限验证,只要针对Controller请求进行处理,是通过HandlerInterceptor。
Interceptor分两种情况,一种是对会话的拦截,实现spring的HandlerInterceptor接口并注册到mvc的拦截队列中,其中**preHandle()**方法在调用Handler之前进行拦截,**postHandle()**方法在视图渲染之前调用,**afterCompletion()**方法在返回相应之前执行;另一种是对方法的拦截,需要使用@Aspect注解,在每次调用指定方法的前、后进行拦截。
Filter和Interceptor的区别
- Filter是基于函数回调(doFilter()方法)的,而Interceptor则是基于Java反射的(AOP思想)
- Filter依赖于Servlet容器,而Interceptor不依赖于Servlet容器
- Filter对几乎所有的请求起作用,而Interceptor只能对action请求起作用
- Interceptor可以访问Action的上下文,值栈里的对象,而Filter不能
- 在action的生命周期里,Interceptor可以被多次调用,而Filter只能在容器初始化时调用一次
- Filter在过滤是只能对request和response进行操作,而interceptor可以对request、response、handler、modelAndView、exception进行操作
HandlerInterceptor
HandlerInterceptor是springMVC项目中的拦截器,它拦截的目标是请求的地址,比MethodInterceptor先执行。
实现一个HandlerInterceptor拦截器可以直接实现HandlerInterceptor接口,也可以继承HandlerInterceptorAdapter类。
这两种方法殊途同归,其实HandlerInterceptorAdapter也就是声明了HandlerInterceptor接口中所有方法的默认实现,而我们在继承他之后只需要重写必要的方法。
MethodInterceptor
MethodInterceptor是AOP项目中的拦截器,它拦截的目标是方法,即使不是controller中的方法。实现MethodInterceptor 拦截器大致也分为两种,一种是实现MethodInterceptor接口,另一种利用AspectJ的注解或配置。
Spring流程
Spring容器启动流程
-
初始化Spring容器,注册内置的BeanPostProcessor的BeanDefinition到容器中
① 实例化BeanFactory【DefaultListableBeanFactory】工厂,用于生成Bean对象 ② 实例化BeanDefinitionReader注解配置读取器,用于对特定注解(如@Service、@Repository)的类进行读取转化成 BeanDefinition 对象,(BeanDefinition 是 Spring 中极其重要的一个概念,它存储了 bean 对象的所有特征信息,如是否单例,是否懒加载,factoryBeanName 等) ③ 实例化ClassPathBeanDefinitionScanner路径扫描器,用于对指定的包目录进行扫描查找 bean 对象
-
将配置类的BeanDefinition注册到容器中
-
调用refresh()方法刷新容器
① prepareRefresh()刷新前的预处理 ② obtainFreshBeanFactory():获取在容器初始化时创建的BeanFactory ③ prepareBeanFactory(beanFactory):BeanFactory的预处理工作,向容器中添加一些组件 ④ postProcessBeanFactory(beanFactory):子类重写该方法,可以实现在BeanFactory创建并预处理完成以后做进一步的设置 ⑤ invokeBeanFactoryPostProcessors(beanFactory):在BeanFactory标准初始化之后执行BeanFactoryPostProcessor的方法,即BeanFactory的后置处理器 ⑥ registerBeanPostProcessors(beanFactory):向容器中注册Bean的后置处理器BeanPostProcessor,它的主要作用是干预Spring初始化bean的流程,从而完成代理、自动注入、循环依赖等功能 ⑦ initMessageSource():初始化MessageSource组件,主要用于做国际化功能,消息绑定与消息解析 ⑧ initApplicationEventMulticaster():初始化事件派发器,在注册监听器时会用到 ⑨ onRefresh():留给子容器、子类重写这个方法,在容器刷新的时候可以自定义逻辑 ⑩ registerListeners():注册监听器。将容器中所有ApplicationListener注册到事件派发器中,并派发之前步骤产生的事件 ⑪ finishBeanFactoryInitialization(beanFactory):初始化所有剩下的单实例bean,核心方法是preInstantiateSingletons(),会调用getBean()方法创建对象 ⑫ finishRefresh():发布BeanFactory容器刷新完成事件
SpringMVC流程
- 用户发送请求至前端控制器DispatcherServlet
- DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handler
- 处理器映射器根据请求url找到具体的处理器Handler,生成处理器对象及处理器拦截器(如果有则生成),一并返回给DispatcherServlet
- DispatcherServlet 调用 HandlerAdapter处理器适配器,请求执行Handler
- HandlerAdapter 经过适配调用 具体处理器进行处理业务逻辑
- Handler执行完成返回ModelAndView
- HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet
- DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行解析
- ViewResolver解析后返回具体View
- DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)
- DispatcherServlet响应用户
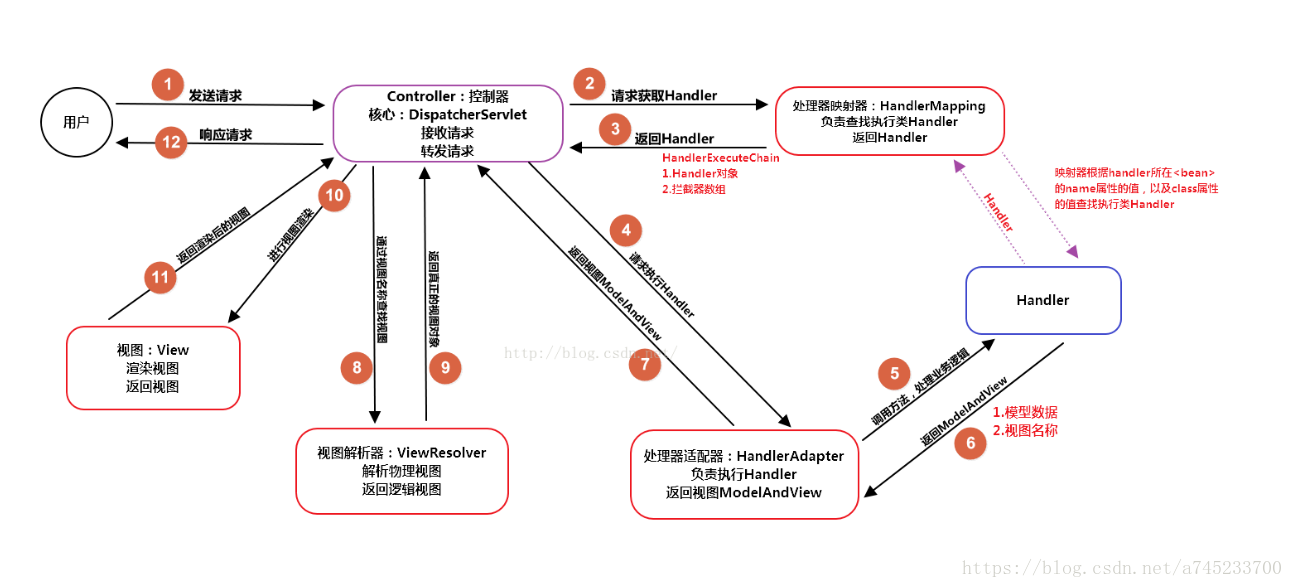
- 前端控制器 DispatcherServlet:接收请求、响应结果,相当于转发器,有了DispatcherServlet 就减少了其它组件之间的耦合度
- 处理器映射器 HandlerMapping:根据请求的URL来查找Handler
- 处理器适配器 HandlerAdapter:负责执行Handler
- 处理器 Handler:处理器,需要程序员开发
- 视图解析器 ViewResolver:进行视图的解析,根据视图逻辑名将ModelAndView解析成真正的视图(view)
- 视图View:View是一个接口, 它的实现类支持不同的视图类型,如jsp,freemarker,pdf等等
非拦截器Http请求流程
用户的普通Http请求执行顺序:
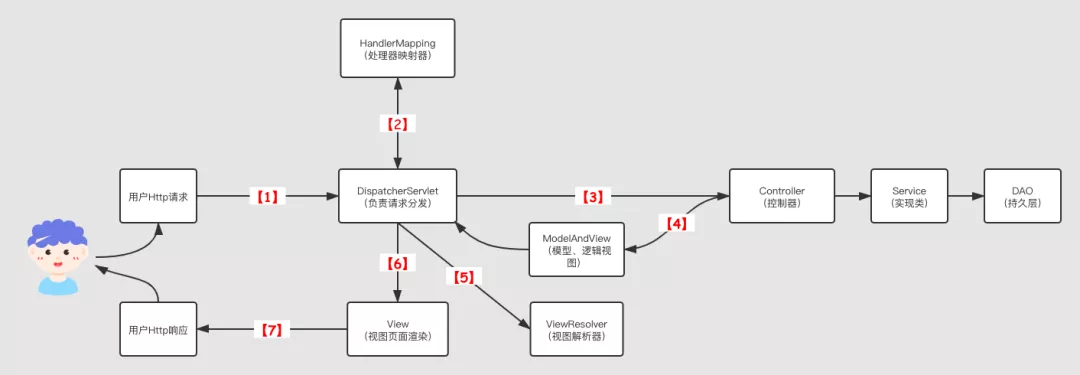
拦截器Http请求流程
过滤器、拦截器添加后的执行顺序:
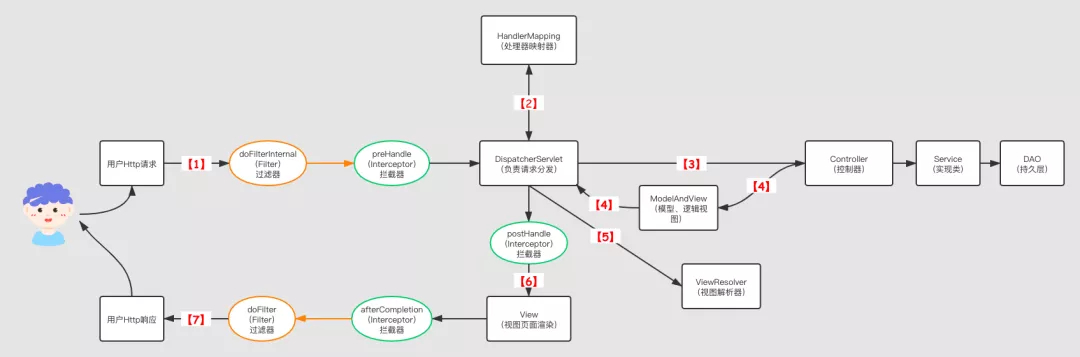
SpringBoot
启动流程扩展点
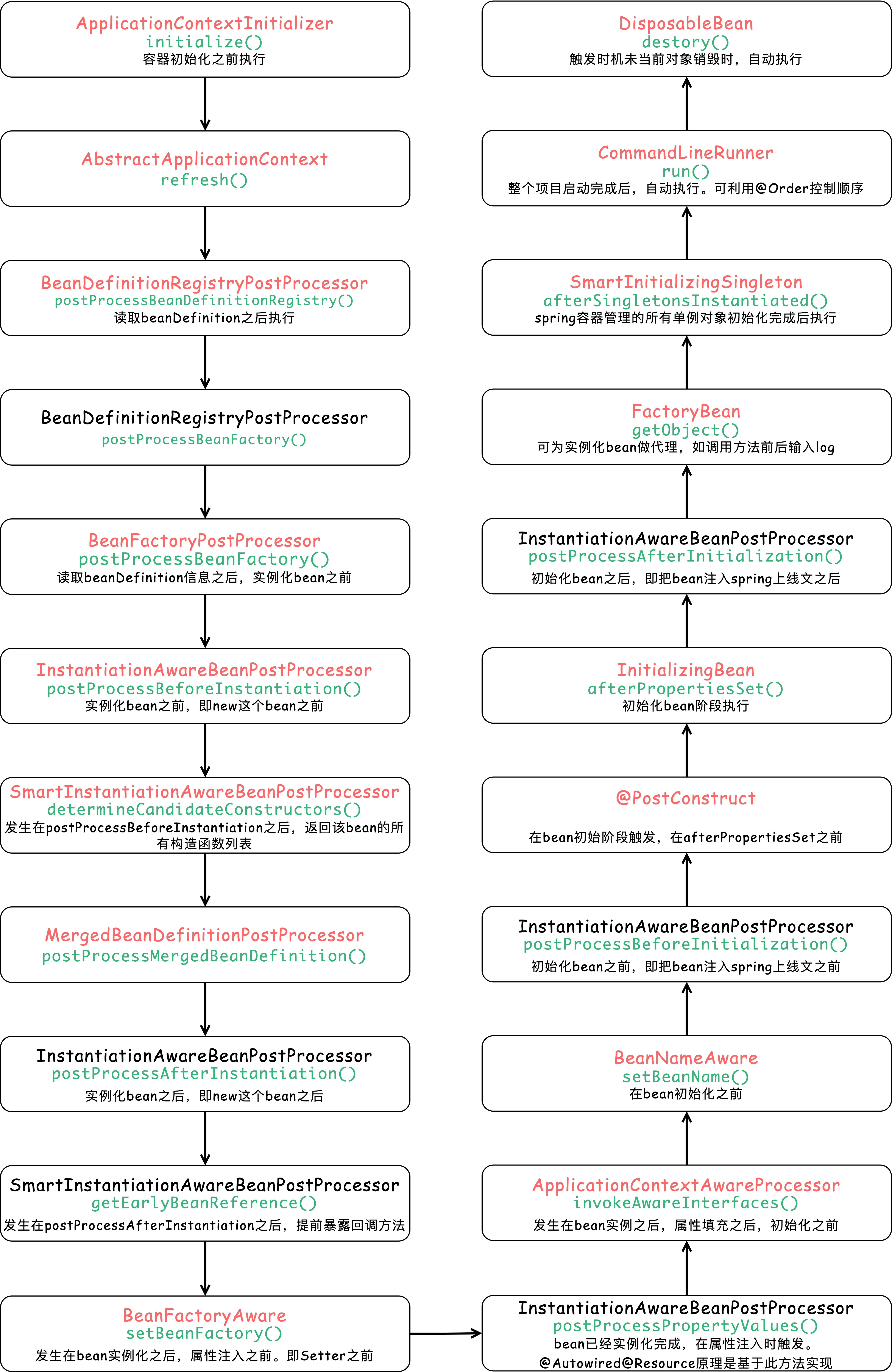
ApplicationContextInitializer
整个spring容器在刷新之前初始化ConfigurableApplicationContext的回调接口,简单来说,就是在容器刷新之前调用此类的initialize方法。用户可以在整个spring容器还没被初始化之前做一些事情。
public class TestApplicationContextInitializer implements ApplicationContextInitializer {
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
System.out.println("[ApplicationContextInitializer]");
}
}
因为这时候spring容器还没被初始化,所以想要自己的扩展的生效,有以下三种方式:
- 在启动类中用
springApplication.addInitializers(new TestApplicationContextInitializer())语句加入 - 配置文件配置
context.initializer.classes=com.example.demo.TestApplicationContextInitializer - Spring SPI扩展,在spring.factories中加入
org.springframework.context.ApplicationContextInitializer=com.example.demo.TestApplicationContextInitializer
BeanDefinitionRegistryPostProcessor
在读取项目中的beanDefinition之后执行,提供一个补充的扩展点。使用场景是你可以在这里动态注册自己的beanDefinition,可以加载classpath之外的bean。
public class TestBeanDefinitionRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("[BeanDefinitionRegistryPostProcessor] postProcessBeanDefinitionRegistry");
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("[BeanDefinitionRegistryPostProcessor] postProcessBeanFactory");
}
}
BeanFactoryPostProcessor
是beanFactory的扩展接口,调用时机在spring在读取beanDefinition信息之后,实例化bean之前。在这个时机,用户可以通过实现这个扩展接口来自行处理一些东西,比如修改已经注册的beanDefinition的元信息。
public class TestBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("[BeanFactoryPostProcessor]");
}
}
InstantiationAwareBeanPostProcessor
该接口继承了BeanPostProcess接口,区别如下:
BeanPostProcess接口只在bean的初始化阶段进行扩展(注入spring上下文前后),而InstantiationAwareBeanPostProcessor接口在此基础上增加了3个方法,把可扩展的范围增加了实例化阶段和属性注入阶段。
该类主要的扩展点有以下5个方法,主要在bean生命周期的两大阶段:实例化阶段 和初始化阶段 ,下面一起进行说明,按调用顺序为:
postProcessBeforeInstantiation:实例化bean之前,相当于new这个bean之前postProcessAfterInstantiation:实例化bean之后,相当于new这个bean之后postProcessPropertyValues:bean已经实例化完成,在属性注入时阶段触发,@Autowired,@Resource等注解原理基于此方法实现postProcessBeforeInitialization:初始化bean之前,相当于把bean注入spring上下文之前postProcessAfterInitialization:初始化bean之后,相当于把bean注入spring上下文之后
使用场景:这个扩展点非常有用 ,无论是写中间件和业务中,都能利用这个特性。比如对实现了某一类接口的bean在各个生命期间进行收集,或者对某个类型的bean进行统一的设值等等。
public class TestInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] before initialization " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] after initialization " + beanName);
return bean;
}
@Override
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] before instantiation " + beanName);
return null;
}
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] after instantiation " + beanName);
return true;
}
@Override
public PropertyValues postProcessPropertyValues(PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] postProcessPropertyValues " + beanName);
return pvs;
}
}
SmartInstantiationAwareBeanPostProcessor
该扩展接口有3个触发点方法:
predictBeanType: 该触发点发生在postProcessBeforeInstantiation之前(在图上并没有标明,因为一般不太需要扩展这个点),这个方法用于预测Bean的类型,返回第一个预测成功的Class类型,如果不能预测返回null;当你调用BeanFactory.getType(name)时当通过bean的名字无法得到bean类型信息时就调用该回调方法来决定类型信息。determineCandidateConstructors: 该触发点发生在postProcessBeforeInstantiation之后,用于确定该bean的构造函数之用,返回的是该bean的所有构造函数列表。用户可以扩展这个点,来自定义选择相应的构造器来实例化这个bean。getEarlyBeanReference: 该触发点发生在postProcessAfterInstantiation之后,当有循环依赖的场景,当bean实例化好之后,为了防止有循环依赖,会提前暴露回调方法,用于bean实例化的后置处理。这个方法就是在提前暴露的回调方法中触发。
public class TestSmartInstantiationAwareBeanPostProcessor implements SmartInstantiationAwareBeanPostProcessor {
@Override
public Class<?> predictBeanType(Class<?> beanClass, String beanName) throws BeansException {
System.out.println("[TestSmartInstantiationAwareBeanPostProcessor] predictBeanType " + beanName);
return beanClass;
}
@Override
public Constructor<?>[] determineCandidateConstructors(Class<?> beanClass, String beanName) throws BeansException {
System.out.println("[TestSmartInstantiationAwareBeanPostProcessor] determineCandidateConstructors " + beanName);
return null;
}
@Override
public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {
System.out.println("[TestSmartInstantiationAwareBeanPostProcessor] getEarlyBeanReference " + beanName);
return bean;
}
}
BeanFactoryAware
这个类只有一个触发点,发生在bean的实例化之后,注入属性之前,也就是Setter之前。这个类的扩展点方法为setBeanFactory,可以拿到BeanFactory这个属性。
使用场景为,你可以在bean实例化之后,但还未初始化之前,拿到 BeanFactory,在这个时候,可以对每个bean作特殊化的定制。也或者可以把BeanFactory拿到进行缓存,日后使用。
public class TestBeanFactoryAware implements BeanFactoryAware {
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
System.out.println("[TestBeanFactoryAware] " + beanFactory.getBean(TestBeanFactoryAware.class).getClass().getSimpleName());
}
}
ApplicationContextAwareProcessor
该类本身并没有扩展点,但是该类内部却有6个扩展点可供实现 ,这些类触发的时机在bean实例化之后,初始化之前。该类用于执行各种驱动接口,在bean实例化之后,属性填充之后,通过执行以上红框标出的扩展接口,来获取对应容器的变量。所以这里应该来说是有6个扩展点:
EnvironmentAware: 用于获取EnviromentAware的一个扩展类,这个变量非常有用, 可以获得系统内的所有参数。当然个人认为这个Aware没必要去扩展,因为spring内部都可以通过注入的方式来直接获得。EmbeddedValueResolverAware: 用于获取StringValueResolver的一个扩展类,StringValueResolver用于获取基于String类型的properties的变量,一般我们都用@Value的方式去获取,如果实现了这个Aware接口,把StringValueResolver缓存起来,通过这个类去获取String类型的变量,效果是一样的。ResourceLoaderAware: 用于获取ResourceLoader的一个扩展类,ResourceLoader可以用于获取classpath内所有的资源对象,可以扩展此类来拿到ResourceLoader对象。ApplicationEventPublisherAware: 用于获取ApplicationEventPublisher的一个扩展类,ApplicationEventPublisher可以用来发布事件,结合ApplicationListener来共同使用,下文在介绍ApplicationListener时会详细提到。这个对象也可以通过spring注入的方式来获得。MessageSourceAware: 用于获取MessageSource的一个扩展类,MessageSource主要用来做国际化。ApplicationContextAware: 用来获取ApplicationContext的一个扩展类,ApplicationContext应该是很多人非常熟悉的一个类了,就是spring上下文管理器,可以手动的获取任何在spring上下文注册的bean,我们经常扩展这个接口来缓存spring上下文,包装成静态方法。同时ApplicationContext也实现了BeanFactory,MessageSource,ApplicationEventPublisher等接口,也可以用来做相关接口的事情。
class ApplicationContextAwareProcessor implements BeanPostProcessor {
private void invokeAwareInterfaces(Object bean) {
if (bean instanceof EnvironmentAware) {
((EnvironmentAware) bean).setEnvironment(this.applicationContext.getEnvironment());
}
if (bean instanceof EmbeddedValueResolverAware) {
((EmbeddedValueResolverAware) bean).setEmbeddedValueResolver(this.embeddedValueResolver);
}
if (bean instanceof ResourceLoaderAware) {
((ResourceLoaderAware) bean).setResourceLoader(this.applicationContext);
}
if (bean instanceof ApplicationEventPublisherAware) {
((ApplicationEventPublisherAware) bean).setApplicationEventPublisher(this.applicationContext);
}
if (bean instanceof MessageSourceAware) {
((MessageSourceAware) bean).setMessageSource(this.applicationContext);
}
if (bean instanceof ApplicationContextAware) {
((ApplicationContextAware) bean).setApplicationContext(this.applicationContext);
}
}
}
BeanNameAware
这个类也是Aware扩展的一种,触发点在bean的初始化之前,也就是postProcessBeforeInitialization之前,这个类的触发点方法只有一个:setBeanName
使用场景为:用户可以扩展这个点,在初始化bean之前拿到spring容器中注册的的beanName,来自行修改这个beanName的值。
public class NormalBeanA implements BeanNameAware{
public NormalBeanA() {
System.out.println("NormalBean constructor");
}
@Override
public void setBeanName(String name) {
System.out.println("[BeanNameAware] " + name);
}
}
@PostConstruct
这个并不算一个扩展点,其实就是一个标注。其作用是在bean的初始化阶段,如果对一个方法标注了@PostConstruct,会先调用这个方法。这里重点是要关注下这个标准的触发点,这个触发点是在postProcessBeforeInitialization之后,InitializingBean.afterPropertiesSet之前。使用场景:用户可以对某一方法进行标注,来进行初始化某一个属性。
public class NormalBeanA {
public NormalBeanA() {
System.out.println("NormalBean constructor");
}
@PostConstruct
public void init(){
System.out.println("[PostConstruct] NormalBeanA");
}
}
InitializingBean
这个类,顾名思义,也是用来初始化bean的。InitializingBean接口为bean提供了初始化方法的方式,它只包括afterPropertiesSet方法,凡是继承该接口的类,在初始化bean的时候都会执行该方法。这个扩展点的触发时机在postProcessAfterInitialization之前。使用场景:用户实现此接口,来进行系统启动的时候一些业务指标的初始化工作。
public class NormalBeanA implements InitializingBean{
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("[InitializingBean] NormalBeanA");
}
}
FactoryBean
一般情况下,Spring通过反射机制利用bean的class属性指定支线类去实例化bean,在某些情况下,实例化Bean过程比较复杂,如果按照传统的方式,则需要在bean中提供大量的配置信息。配置方式的灵活性是受限的,这时采用编码的方式可能会得到一个简单的方案。Spring为此提供了一个org.springframework.bean.factory.FactoryBean的工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑。FactoryBean接口对于Spring框架来说占用重要的地位,Spring自身就提供了70多个FactoryBean的实现。它们隐藏了实例化一些复杂bean的细节,给上层应用带来了便利。从Spring3.0开始,FactoryBean开始支持泛型,即接口声明改为FactoryBean<T>的形式。
使用场景:用户可以扩展这个类,来为要实例化的bean作一个代理,比如为该对象的所有的方法作一个拦截,在调用前后输出一行log,模仿ProxyFactoryBean的功能。
public class TestFactoryBean implements FactoryBean<TestFactoryBean.TestFactoryInnerBean> {
@Override
public TestFactoryBean.TestFactoryInnerBean getObject() throws Exception {
System.out.println("[FactoryBean] getObject");
return new TestFactoryBean.TestFactoryInnerBean();
}
@Override
public Class<?> getObjectType() {
return TestFactoryBean.TestFactoryInnerBean.class;
}
@Override
public boolean isSingleton() {
return true;
}
public static class TestFactoryInnerBean{
}
}
SmartInitializingSingleton
这个接口中只有一个方法afterSingletonsInstantiated,其作用是是 在spring容器管理的所有单例对象(非懒加载对象)初始化完成之后调用的回调接口。其触发时机为postProcessAfterInitialization之后。
使用场景:用户可以扩展此接口在对所有单例对象初始化完毕后,做一些后置的业务处理。
public class TestSmartInitializingSingleton implements SmartInitializingSingleton {
@Override
public void afterSingletonsInstantiated() {
System.out.println("[TestSmartInitializingSingleton]");
}
}
CommandLineRunner
这个接口也只有一个方法:run(String... args),触发时机为整个项目启动完毕后,自动执行。如果有多个CommandLineRunner,可以利用@Order来进行排序。使用场景:用户扩展此接口,进行启动项目之后一些业务的预处理。
public class TestCommandLineRunner implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("[TestCommandLineRunner]");
}
}
DisposableBean
这个扩展点也只有一个方法:destroy(),其触发时机为当此对象销毁时,会自动执行这个方法。比如说运行applicationContext.registerShutdownHook时,就会触发这个方法。
public class NormalBeanA implements DisposableBean {
@Override
public void destroy() throws Exception {
System.out.println("[DisposableBean] NormalBeanA");
}
}
ApplicationListener
准确的说,这个应该不算spring&springboot当中的一个扩展点,ApplicationListener可以监听某个事件的event,触发时机可以穿插在业务方法执行过程中,用户可以自定义某个业务事件。但是spring内部也有一些内置事件,这种事件,可以穿插在启动调用中。我们也可以利用这个特性,来自己做一些内置事件的监听器来达到和前面一些触发点大致相同的事情。
接下来罗列下spring主要的内置事件:
- ContextRefreshedEvent
ApplicationContext 被初始化或刷新时,该事件被发布。这也可以在
ConfigurableApplicationContext接口中使用refresh()方法来发生。此处的初始化是指:所有的Bean被成功装载,后处理Bean被检测并激活,所有Singleton Bean 被预实例化,ApplicationContext容器已就绪可用。 - ContextStartedEvent
当使用
ConfigurableApplicationContext(ApplicationContext子接口)接口中的 start() 方法启动ApplicationContext时,该事件被发布。你可以调查你的数据库,或者你可以在接受到这个事件后重启任何停止的应用程序。 - ContextStoppedEvent
当使用
ConfigurableApplicationContext接口中的stop()停止ApplicationContext时,发布这个事件。你可以在接受到这个事件后做必要的清理的工作 - ContextClosedEvent
当使用
ConfigurableApplicationContext接口中的close()方法关闭ApplicationContext时,该事件被发布。一个已关闭的上下文到达生命周期末端;它不能被刷新或重启 - RequestHandledEvent 这是一个 web-specific 事件,告诉所有 bean HTTP 请求已经被服务。只能应用于使用DispatcherServlet的Web应用。在使用Spring作为前端的MVC控制器时,当Spring处理用户请求结束后,系统会自动触发该事件
MVC
HTTP请求处理流程
参数绑定
过滤器、拦截器、AOP执行顺序
IOC
Bean的加载过程
Bean实例化的过程
AOP
Others
FactoryBean
public class UserFactoryBean implements FactoryBean<User> {
@Override
public User getObject() throws Exception {
User user = new User();
System.out.println("调用 UserFactoryBean 的 getObject 方法生成 Bean:" + user);
return user;
}
@Override
public Class<?> getObjectType() {
// 这个 FactoryBean 返回的Bean的类型
return User.class;
}
}
FactoryBean在Mybatis中的实践
Mybatis的Mapper接口的动态代理也是通过FactoryBean注入到Spring中的。
public class MapperFactoryBean<T> extends SqlSessionDaoSupportimplements FactoryBean<T> {
// mapper的接口类型
private Class<T> mapperInterface;
@Override
public T getObject() throws Exception {
// 通过SqlSession获取接口的动态搭理对象
return getSqlSession().getMapper(this.mapperInterface);
}
@Override
public Class<T> getObjectType() {
return this.mapperInterface;
}
}
FactoryBean在OpenFeign中的实践
FeignClient接口的动态代理也是通过FactoryBean注入到Spring中的。
public class FeignClientFactoryBean implements
FactoryBean<Object>, InitializingBean, ApplicationContextAware {
// FeignClient接口类型
private Class<?> type;
@Override
public Object getObject() throws Exception {
return getTarget();
}
@Override
public Class<?> getObjectType() {
return type;
}
}
@Import
@Import的核心作用就是导入配置类,并且还可以根据配合(比如@EnableXXX)使用的注解的属性来决定应该往Spring中注入什么样的Bean。
实现ImportSelector接口
public class UserImportSelector implements ImportSelector {
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
System.out.println("调用 UserImportSelector 的 selectImports 方法获取一批类限定名");
return new String[]{"com.sanyou.spring.extension.User"};
}
}
@Import(UserImportSelector.class)
public class Application {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext =
new AnnotationConfigApplicationContext();
//将 Application 注册到容器中
applicationContext.register(Application.class);
applicationContext.refresh();
System.out.println("获取到的Bean为" + applicationContext.getBean(User.class));
}
}
// 运行结果如下:
// 调用 UserImportSelector 的 selectImports 方法获取一批类限定名
// 获取到的Bean为com.sanyou.spring.extension.User@282003e1
实现ImportBeanDefinitionRegistrar接口
public class UserImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry, BeanNameGenerator importBeanNameGenerator) {
//构建一个 BeanDefinition , Bean的类型为 User
AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder.rootBeanDefinition(User.class)
// 设置 User 这个Bean的属性username的值为张小凡
.addPropertyValue("username", "张小凡")
.getBeanDefinition();
System.out.println("往Spring容器中注入User");
//把 User 这个Bean的定义注册到容器中
registry.registerBeanDefinition("user", beanDefinition);
}
}
// 导入 UserImportBeanDefinitionRegistrar
@Import(UserImportBeanDefinitionRegistrar.class)
public class Application {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext();
//将 Application 注册到容器中
applicationContext.register(Application.class);
applicationContext.refresh();
User user = applicationContext.getBean(User.class);
System.out.println("获取到的Bean为" + user + ",属性username值为:" + user.getUsername());
}
}
// 运行结果如下:
// 往Spring容器中注入User
// 获取到的Bean为com.sanyou.spring.extension.User@6385cb26,属性username值为:张小凡
BeanPostProcessor
Bean的后置处理器,在Bean创建的过程中起作用。BeanPostProcessor是Bean在创建过程中一个非常重要的扩展点,因为每个Bean在创建的各个阶段,都会回调BeanPostProcessor及其子接口的方法,传入正在创建的Bean对象,这样如果想对Bean创建过程中某个阶段进行自定义扩展,那么就可以自定义BeanPostProcessor来完成。常用的两个子接口:
- InstantiationAwareBeanPostProcessor
- DestructionAwareBeanPostProcessor
public class UserBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof User) {
//如果当前的Bean的类型是 User ,就把这个对象 username 的属性赋值为 张小凡
((User) bean).setUsername("张小凡");
}
return bean;
}
}
public class Application {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext();
//将 UserBeanPostProcessor 和 User 注册到容器中
applicationContext.register(UserBeanPostProcessor.class);
applicationContext.register(User.class);
applicationContext.refresh();
User user = applicationContext.getBean(User.class);
System.out.println("获取到的Bean为" + user + ",属性username值为:" + user.getUsername());
}
}
// 运行结果如下:
// 获取到的Bean为com.sanyou.spring.extension.User@21a947fe,属性username值为:三友的java日记
Spring内置的BeanPostProcessor
| BeanPostProcessor | 作用 |
|---|---|
| AutowiredAnnotationBeanPostProcessor | 处理@Autowired、@Value注解 |
| CommonAnnotationBeanPostProcessor | 处理@Resource、@PostConstruct、@PreDestroy注解 |
| AnnotationAwareAspectJAutoProxyCreator | 处理一些注解或者是AOP切面的动态代理 |
| ApplicationContextAwareProcessor | 处理Aware接口注入的 |
| AsyncAnnotationBeanPostProcessor | 处理@Async注解 |
| ScheduledAnnotationBeanPostProcessor | 处理@Scheduled注解 |
BeanPostProcessor在Dubbo中的应用
在Dubbo中可以通过@DubboReference(@Reference)来引用生产者提供的接口,这个注解的处理也是依靠ReferenceAnnotationBeanPostProcessor,也就是 BeanPostProcessor 的扩展来实现的。
public class ReferenceAnnotationBeanPostProcessor
extends AbstractAnnotationBeanPostProcessor
implements ApplicationContextAware, BeanFactoryPostProcessor {
// 忽略
}
BeanFactoryPostProcessor
BeanFactoryPostProcessor是可以对Spring容器做处理的,方法入参就是Spring容器,通过这个接口,就对容器进行为所欲为的操作。
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
// 禁止循环依赖
((DefaultListableBeanFactory) beanFactory).setAllowCircularReferences(false);
}
}
Spring SPI机制
SPI全称为 (Service Provider Interface),是一种动态替换发现的机制,一种解耦非常优秀的思想,SPI可以很灵活的让接口和实现分离, 让API提供者只提供接口,第三方来实现,然后可使用配置文件的方式来实现替换或者扩展,在框架中比较常见,提高框架的可扩展性。
- JDK:ServiceLoader
- Dubbo:ExtensionLoader
- Spring:SpringFactoriesLoader
Spring的SPI机制规定,配置文件必须在classpath路径下的META-INF文件夹内,文件名必须为spring.factories,文件内容为键值对,一个键可以有多个值,只需要用逗号分割就行,同时键值都需要是类的全限定名。但是键和值可以没有任何关系,当然想有也可以有。
自动装配
PropertySourceLoader
在SpringBoot环境下,外部化的配置文件支持properties和yaml两种格式。但现在不想使用properties和yaml格式的文件,想使用json格式的配置文件。则可通过PropertySourceLoader来实现。
public interface PropertySourceLoader {
// 可以支持哪种文件格式的解析
String[] getFileExtensions();
// 解析配置文件,读出内容,封装成一个PropertySource<?>结合返回回去
List<PropertySource<?>> load(String name, Resource resource) throws IOException;
}
对于PropertySourceLoader的实现,SpringBoot两个实现:
-
PropertiesPropertySourceLoader:可以解析properties或者xml结尾的配置文件
public class PropertiesPropertySourceLoader implements PropertySourceLoader { private static final String XML_FILE_EXTENSION = ".xml"; public PropertiesPropertySourceLoader() { } public String[] getFileExtensions() { return new String[]{"properties", "xml"}; } public List<PropertySource<?>> load(String name, Resource resource) throws IOException { Map<String, ?> properties = this.loadProperties(resource); return properties.isEmpty() ? Collections.emptyList() : Collections.singletonList(new OriginTrackedMapPropertySource(name, Collections.unmodifiableMap(properties), true)); } private Map<String, ?> loadProperties(Resource resource) throws IOException { String filename = resource.getFilename(); return (Map)(filename != null && filename.endsWith(".xml") ? PropertiesLoaderUtils.loadProperties(resource) : (new OriginTrackedPropertiesLoader(resource)).load()); } } -
YamlPropertySourceLoader:解析以yml或者yaml结尾的配置文件
public class YamlPropertySourceLoader implements PropertySourceLoader { @Override public String[] getFileExtensions() { return new String[] { "yml", "yaml" }; } @Override public List<PropertySource<?>> load(String name, Resource resource) throws IOException { if (!ClassUtils.isPresent("org.yaml.snakeyaml.Yaml", null)) { throw new IllegalStateException( "Attempted to load " + name + " but snakeyaml was not found on the classpath"); } List<Map<String, Object>> loaded = new OriginTrackedYamlLoader(resource).load(); if (loaded.isEmpty()) { return Collections.emptyList(); } List<PropertySource<?>> propertySources = new ArrayList<>(loaded.size()); for (int i = 0; i < loaded.size(); i++) { String documentNumber = (loaded.size() != 1) ? " (document #" + i + ")" : ""; propertySources.add(new OriginTrackedMapPropertySource(name + documentNumber, Collections.unmodifiableMap(loaded.get(i)), true)); } return propertySources; } }
所以可以看出,要想实现json格式的支持,只需要自己实现可以用来解析json格式的配置文件的PropertySourceLoader就可以了。
实现可以读取json格式的配置文件
第一步:自定义一个JsonPropertySourceLoader,实现PropertySourceLoader接口
public class JsonPropertySourceLoader implements PropertySourceLoader {
@Override
public String[] getFileExtensions() {
//这个方法表明这个类支持解析以json结尾的配置文件
return new String[]{"json"};
}
@Override
public List<PropertySource<?>> load(String name, Resource resource) throws IOException {
ReadableByteChannel readableByteChannel = resource.readableChannel();
ByteBuffer byteBuffer = ByteBuffer.allocate((int) resource.contentLength());
//将文件内容读到 ByteBuffer 中
readableByteChannel.read(byteBuffer);
//将读出来的字节转换成字符串
String content = new String(byteBuffer.array());
// 将字符串转换成 JSONObject
JSONObject jsonObject = JSON.parseObject(content);
Map<String, Object> map = new HashMap<>(jsonObject.size());
//将 json 的键值对读出来,放入到 map 中
for (String key : jsonObject.keySet()) {
map.put(key, jsonObject.getString(key));
}
return Collections.singletonList(new MapPropertySource("jsonPropertySource", map));
}
}
第二步:配置PropertySourceLoader
基于SPI机制加载PropertySourceLoader实现。因此在spring.factories文件中配置如下:
org.springframework.boot.env.PropertySourceLoader=\
cn.test.JsonPropertySourceLoader
第三步:测试验证
在application.json中配置如下:
{
"test.userName": "张小凡"
}
定义配置类:
public class User {
// 注入配置文件的属性
@Value("${test.userName:}")
private String userName;
}
启动项目
@SpringBootApplication
public class Application {
public static void main(String[] args) {
ConfigurableApplicationContext applicationContext = SpringApplication.run(Application.class);
User user = applicationContext.getBean(User.class);
System.out.println("获取到的Bean为" + user + ",属性userName值为:" + user.getUserName());
}
@Bean
public User user() {
return new User();
}
}
// 运行结果如下:
// 获取到的Bean为com.sanyou.spring.extension.User@481ba2cf,属性username值为:张小凡
Nacos对于PropertySourceLoader的实现
org.springframework.boot.env.PropertySourceLoader=\
com.alibaba.cloud.nacos.parser.NacosJsonPropertySourceLoader,\
com.alibaba.cloud.nacos.parser.NacosXmlPropertySourceLoader
Nacos作为配置中心,不仅支持properties和yaml格式的文件,还支持json格式的配置文件,那么客户端拿到这些配置就需要解析,SpringBoot已经支持了properties和yaml格式的文件的解析,那么Nacos只需要实现SpringBoot不支持的就可以了。
ApplicationContextInitializer
ApplicationContextInitializer也是SpringBoot启动过程的一个扩展点。在SpringBoot启动过程,会回调这个类的实现initialize方法,传入ConfigurableApplicationContext。
org.springframework.context.ApplicationContextInitializer=\
org.springframework.boot.context.ConfigurationWarningApplicationContextInitializer,\
org.springframework.boot.context.ContextIdApplicationContextInitializer,\
org.springframework.boot.context.config.DelegatingApplicationContextInitializer,\
org.springframework.boot.rsocket.context.RSocketPortInfoApplicationContextInitializer,\
org.springframework.boot.web.context.ServerPortInfoApplicationContextInitializer
注意:这里传入的ConfigurableApplicationContext并没有调用过refresh方法,也就是里面是没有Bean对象的,一般这个接口是用来配置ConfigurableApplicationContext,而不是用来获取Bean的。
EnvironmentPostProcessor
EnvironmentPostProcessor在SpringBoot启动过程中,也会调用,也是通过SPI机制来加载扩展的。EnvironmentPostProcessor是用来处理ConfigurableEnvironment的,也就是一些配置信息,SpringBoot所有的配置都是存在这个对象的。
这个类的作用就是用来处理外部化配置文件的,也就是这个类是用来处理配置文件的,通过前面提到的PropertySourceLoader解析配置文件,放到ConfigurableEnvironment里面。
ApplicationRunner和CommandLineRunner
ApplicationRunner和CommandLineRunner都是在SpringBoot成功启动之后会调用,可以拿到启动时的参数。这两个其实不是通过SPI机制来扩展,而是直接从容器中获取的。因为调用ApplicationRunner和CommandLineRunner时,SpringBoot已经启动成功了,Spring容器都准备好了,需要什么Bean直接从容器中查找多方便。
所以要想扩展这个点,只需要实现接口,添加到Spring容器。
Spring Event 事件
什么是Spring Event 事件,就是Spring实现了这种事件模型,你只需要基于Spring提供的API进行扩展,就可以完成事件的发布订阅。
// 火灾事件
public class FireEvent extends ApplicationEvent {
public FireEvent(String source) {
super(source);
}
}
// 打119的火灾事件的监听器
public class Call119FireEventListener implements ApplicationListener<FireEvent> {
@Override
public void onApplicationEvent(FireEvent event) {
System.out.println("打119");
}
}
// 救人的火灾事件的监听器
public class SavePersonFireEventListener implements ApplicationListener<FireEvent> {
@Override
public void onApplicationEvent(FireEvent event) {
System.out.println("救人");
}
}
public class Application {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext();
//将 事件监听器 注册到容器中
applicationContext.register(Call119FireEventListener.class);
applicationContext.register(SavePersonFireEventListener.class);
applicationContext.refresh();
// 发布着火的事件,触发监听
applicationContext.publishEvent(new FireEvent("着火了"));
}
}
Spring内置的事件
Spring内置的事件很多,这里我罗列几个
| 事件类型 | 触发时机 |
|---|---|
| ContextRefreshedEvent | 在调用ConfigurableApplicationContext 接口中的refresh()方法时触发 |
| ContextStartedEvent | 在调用ConfigurableApplicationContext的start()方法时触发 |
| ContextStoppedEvent | 在调用ConfigurableApplicationContext的stop()方法时触发 |
| ContextClosedEvent | 当ApplicationContext被关闭时触发该事件,也就是调用close()方法触发 |
ApplicationEvent
事件的父类,所有具体的事件都得继承这个类,构造方法的参数是这个事件携带的参数,监听器就可以通过这个参数来进行一些业务操作。
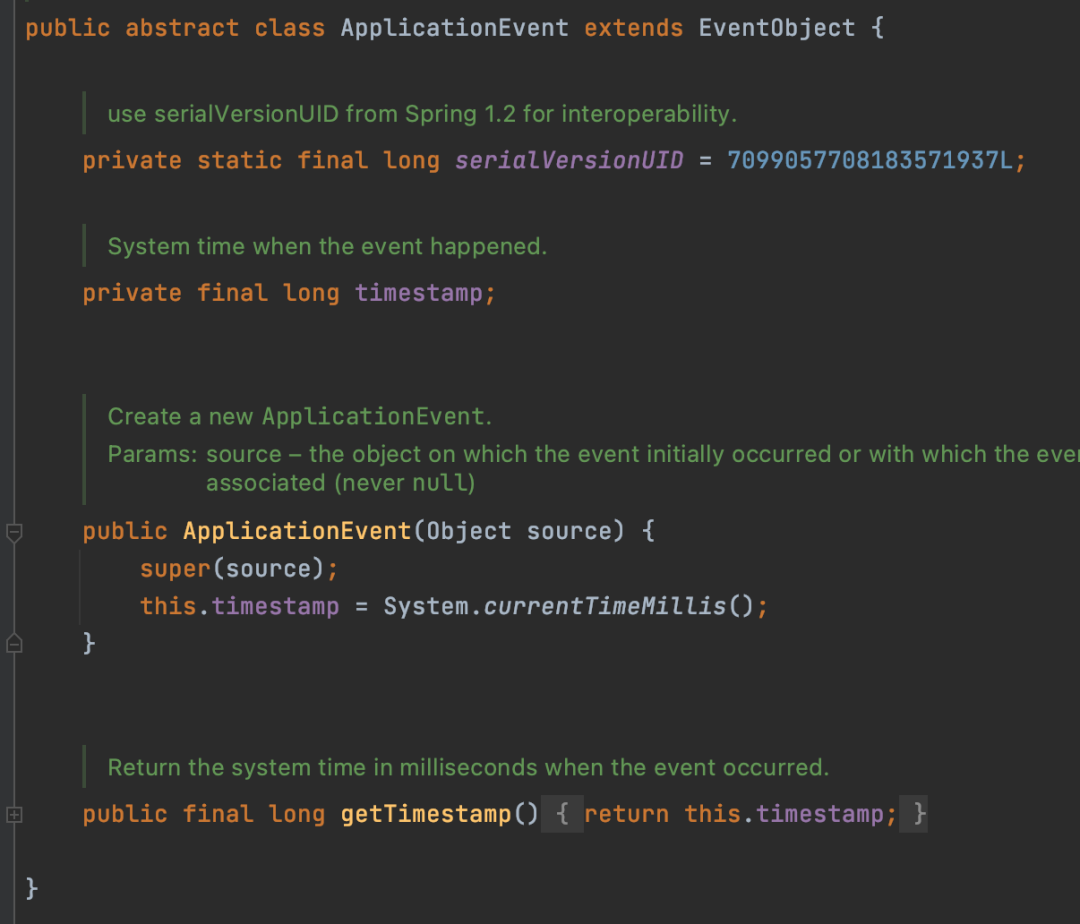
ApplicationListener
事件监听的接口,泛型是子类需要监听的事件类型,子类需要实现onApplicationEvent,参数就是事件类型,onApplicationEvent方法的实现就代表了对事件的处理,当事件发生时,Spring会回调onApplicationEvent方法的实现,传入发布的事件。

ApplicationEventPublisher
事件发布器,通过publishEvent方法就可以发布一个事件,然后就可以触发监听这个事件的监听器的回调。
ApplicationContext实现了ApplicationEventPublisher接口,所以通过ApplicationContext就可以发布事件。
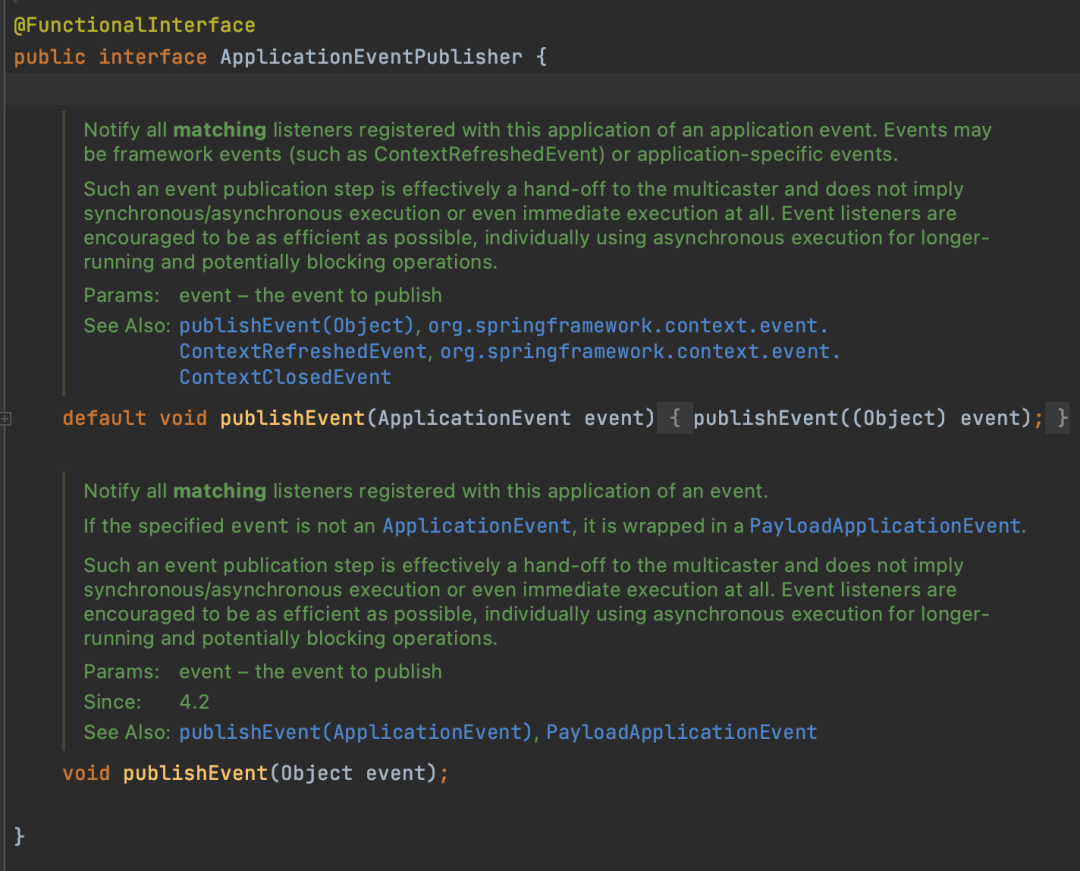
命名空间
第一步:定义一个xsd文件
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!-- xmlns 和 targetNamespace 需要定义,结尾为sanyou,前面都一样的-->
<xsd:schema xmlns="http://sanyou.com/schema/sanyou"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://sanyou.com/schema/sanyou">
<xsd:import namespace="http://www.w3.org/XML/1998/namespace"/>
<xsd:complexType name="Bean">
<xsd:attribute name="class" type="xsd:string" use="required"/>
</xsd:complexType>
<!-- sanyou 便签的子标签,类型是Bean ,就会找到上面的complexType=Bean类型,然后处理属性 -->
<xsd:element name="mybean" type="Bean"/>
</xsd:schema>
这个xsd文件来指明sanyou这个命名空间下有哪些标签和属性。这里我只指定了一个标签 mybean,mybean标签里面有个class的属性,然后这个标签的目的就是将class属性指定的Bean的类型,注入到Spring容器中,作用跟spring的标签的作用是一样的。xsd文件没有需要放的固定的位置,这里我放到 META-INF 目录下。
第二步:解析这个命名空间
解析命名空间很简单,Spring都有配套的东西--NamespaceHandler接口,只要实现这个接口就行了。但一般我们不直接实现 NamespaceHandler 接口,我们可以继承 NamespaceHandlerSupport 类,这个类实现了 NamespaceHandler 接口。
public class SanYouNameSpaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
//注册解析 mybean 标签的解析器
registerBeanDefinitionParser("mybean", new SanYouBeanDefinitionParser());
}
private static class SanYouBeanDefinitionParser extends AbstractSingleBeanDefinitionParser {
@Override
protected boolean shouldGenerateId() {
return true;
}
@Override
protected String getBeanClassName(Element element) {
return element.getAttribute("class");
}
}
}
SanYouNameSpaceHandler的作用就是将sanyou命名空间中的mybean这个标签读出来,拿到class的属性,然后将这个class属性指定的class类型注入到Spring容器中,至于注册这个环节的代码,都交给了SanYouBeanDefinitionParser的父类来做了。
第三步:创建并配置spring.handlers和spring.schemas文件
先创建spring.handlers和spring.schemas文件。spring.handlers文件内容:
http\://sanyou.com/schema/sanyou=com.sanyou.spring.extension.namespace.SanYouNameSpaceHandler
通过spring.handlers配置文件,就知道sanyou命名空间应该找SanYouNameSpaceHandler进行解析。spring.schemas文内容:
http\://sanyou.com/schema/sanyou.xsd=META-INF/sanyou.xsd
spring.schemas配置xsd文件的路径。文件都有了,只需要放到classpath下的META-INF文件夹就行了。
第四步:测试
先构建一个applicationContext.xml文件,放到resources目录下
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/beans"
xmlns:sanyou="http://sanyou.com/schema/sanyou"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://sanyou.com/schema/sanyou
http://sanyou.com/schema/sanyou.xsd
">
<!--使用 sanyou 标签,配置一个 User Bean-->
<sanyou:mybean class="com.sanyou.spring.extension.User"/>
</beans>
再写个测试类:
public class Application {
public static void main(String[] args) {
ClassPathXmlApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
applicationContext.refresh();
User user = applicationContext.getBean(User.class);
System.out.println(user);
}
}
// 运行结果
// com.sanyou.spring.extension.User@27fe3806
SpringCloud
Eurake
Netflix Eureka 是由 Netflix 开源的一款基于 REST 的服务发现组件,包括 Eureka Server 及 Eureka Client。
- Eurake客户端:负责将这个服务的信息注册到Eureka服务端中
- Eureka服务端:相当于一个注册中心,里面有注册表,注册表中保存了各个服务所在的机器和端口号,可以通过Eureka服务端找到各个服务
Eurka工作流程
Eureka的工作流程如下:
- Eureka Server 启动成功,等待服务端注册。在启动过程中如果配置了集群,集群之间定时通过 Replicate 同步注册表,每个 Eureka Server 都存在独立完整的服务注册表信息
- Eureka Client 启动时根据配置的 Eureka Server 地址去注册中心注册服务
- Eureka Client 会每30s向 Eureka Server 发送一次心跳请求,证明客户端服务正常
- 当Eureka Server 90s内没有收到Eureka Client的心跳,注册中心则认为该节点失效,会注销该实例
- 单位时间内Eureka Server统计到有大量的Eureka Client没有上送心跳,则认为可能为网络异常,进入自我保护机制,不再剔除没有上送心跳的客户端
- 当Eureka Client心跳请求恢复正常之后,Eureka Server自动退出自我保护模式
- Eureka Client定时全量或者增量从注册中心获取服务注册表,并且将获取到的信息缓存到本地
- 服务调用时,Eureka Client会先从本地缓存找调取的服务。若获取不到,先从注册中心刷新注册表,再同步到本地缓存
- Eureka Client获取到目标服务器信息,发起服务调用
- Eureka Client程序关闭时向Eureka Server发送取消请求,Eureka Server将实例从注册表中删除
Eureka Server
Eureka Server注册中心服务端主要对外提供了三个功能:
-
服务注册 服务提供者启动时,会通过 Eureka Client 向 Eureka Server 注册信息,Eureka Server 会存储该服务的信息,Eureka Server 内部有二层缓存机制来维护整个注册表。
-
提供注册表 服务消费者在调用服务时,如果 Eureka Client 没有缓存注册表的话,会从 Eureka Server 获取最新的注册表。
-
同步状态 Eureka Client 通过注册、心跳机制和 Eureka Server 同步当前客户端的状态。
自我保护机制
默认情况下,如果 Eureka Server 在一定的 90s 内没有接收到某个微服务实例的心跳,会注销该实例。但是在微服务架构下服务之间通常都是跨进程调用,网络通信往往会面临着各种问题,比如微服务状态正常,网络分区故障,导致此实例被注销。固定时间内大量实例被注销,可能会严重威胁整个微服务架构的可用性。为了解决这个问题,Eureka 开发了自我保护机制,那么什么是自我保护机制呢?Eureka Server 在运行期间会去统计心跳失败比例在 15 分钟之内是否低于 85%,如果低于 85%,Eureka Server 即会进入自我保护机制。Eureka Server 触发自我保护机制后,页面会出现提示:
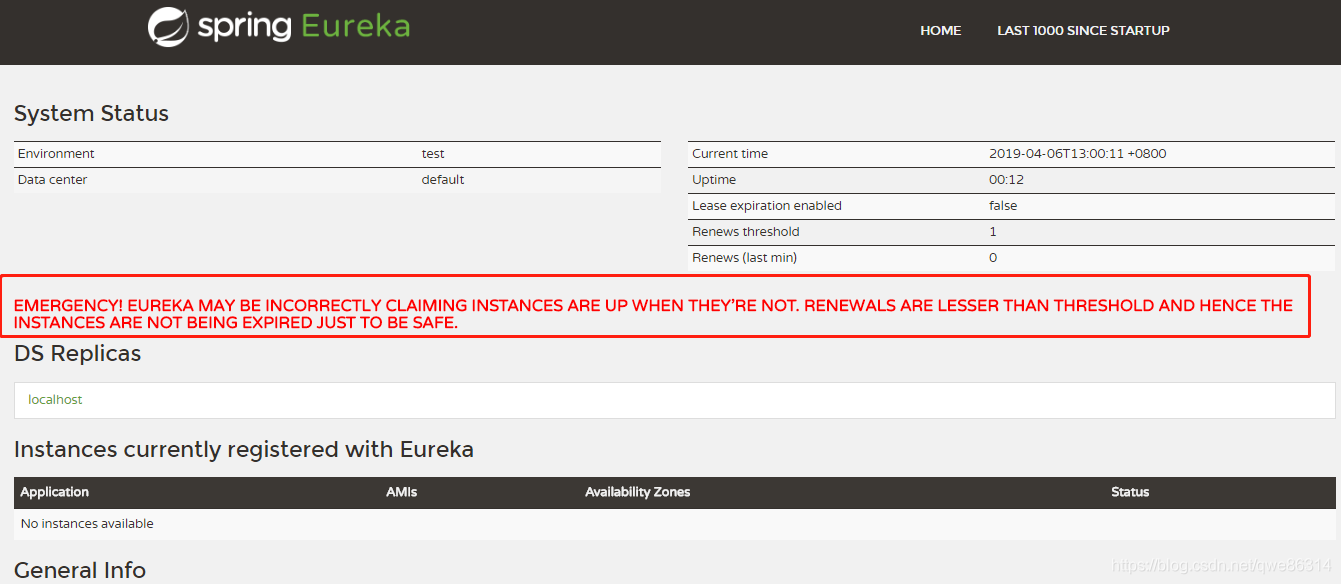
Eureka Server进入自我保护机制,会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
Eureka自我保护机制是为了防止误杀服务而提供的一个机制:
- 当个别客户端出现心跳失联时,则认为是客户端的问题,剔除掉客户端
- 当Eureka捕获到大量的心跳失败时,则认为可能是网络问题,进入自我保护机制
- 当客户端心跳恢复时,Eureka会自动退出自我保护机制
如果在保护期内刚好这个服务提供者非正常下线了,此时服务消费者就会拿到一个无效的服务实例,即会调用失败。对于这个问题需要服务消费者端要有一些容错机制,如重试,断路器等。通过在 Eureka Server 配置如下参数,开启或者关闭保护机制,生产环境建议打开:
eureka.server.enable-self-preservation=true
Eureka Client
Eureka Client注册中心客户端是一个 Java 客户端,用于简化与 Eureka Server 的交互。Eureka Client 会拉取、更新和缓存 Eureka Server 中的信息。因此当所有的 Eureka Server 节点都宕掉,服务消费者依然可以使用缓存中的信息找到服务提供者,但是当服务有更改的时候会出现信息不一致。
-
Register —— 服务注册 服务的提供者,将自身注册到注册中心,服务提供者也是一个 Eureka Client。当 Eureka Client 向 Eureka Server 注册时,它提供自身的元数据,比如 IP 地址、端口,运行状况指示符 URL,主页等。
-
Renew —— 服务续约 Eureka Client 会每隔 30 秒发送一次心跳来续约。 通过续约来告知 Eureka Server 该 Eureka Client 运行正常,没有出现问题。 默认情况下,如果 Eureka Server 在 90 秒内没有收到 Eureka Client 的续约,Server 端会将实例从其注册表中删除,此时间可配置,一般情况不建议更改。服务续约的两个重要属性:
# 服务续约任务的调用间隔时间,默认为30秒 eureka.instance.lease-renewal-interval-in-seconds=30 # 服务失效的时间,默认为90秒。 eureka.instance.lease-expiration-duration-in-seconds=90 -
Eviction —— 服务剔除 当Eureka Client和Eureka Server不再有心跳时,Eureka Server会将该服务实例从服务注册列表中删除,即服务剔除。
-
Cancel —— 服务下线 Eureka Client 在程序关闭时向 Eureka Server 发送取消请求。 发送请求后,该客户端实例信息将从 Eureka Server 的实例注册表中删除。该下线请求不会自动完成,它需要调用以下内容:
DiscoveryManager.getInstance().shutdownComponent(); -
GetRegisty —— 获取注册列表信息 Eureka Client 从服务器获取注册表信息,并将其缓存在本地。客户端会使用该信息查找其他服务,从而进行远程调用。该注册列表信息定期(每30秒钟)更新一次。每次返回注册列表信息可能与 Eureka Client 的缓存信息不同,Eureka Client 自动处理。
如果由于某种原因导致注册列表信息不能及时匹配,Eureka Client 则会重新获取整个注册表信息。 Eureka Server 缓存注册列表信息,整个注册表以及每个应用程序的信息进行了压缩,压缩内容和没有压缩的内容完全相同。Eureka Client 和 Eureka Server 可以使用 JSON/XML 格式进行通讯。在默认情况下 Eureka Client 使用压缩 JSON 格式来获取注册列表的信息。获取服务是服务消费者的基础,所以必有两个重要参数需要注意:
# 启用服务消费者从注册中心拉取服务列表的功能 eureka.client.fetch-registry=true # 设置服务消费者从注册中心拉取服务列表的间隔 eureka.client.registry-fetch-interval-seconds=30 -
Remote Call —— 远程调用 当Eureka Client从注册中心获取到服务提供者信息后,就可以通过Http请求调用对应的服务;服务提供者有多个时,Eureka Client客户端会通过Ribbon自动进行负载均衡。
Eureka缓存机制
Eureka Server数据存储
Eureka Server的数据存储层是双层的 ConcurrentHashMap:
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry= new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();
- key:为服务名,即
spring.application.name,也就是客户端实例注册的应用名 - subKey:为
instanceId,也就是服务的唯一实例ID - Lease< InstanceInfo >:Lease对象存储着这个实例的所有注册信息,包括 ip 、端口、属性等
Eureka Server缓存机制
Eureka Server为了提供响应效率,提供了两层的缓存结构,将Eureka Client所需要的注册信息,直接存储在缓存结构中。
-
第一层缓存:readOnlyCacheMap,本质上是 ConcurrentHashMap
依赖定时从 readWriteCacheMap 同步数据,默认时间为 30 秒。
readOnlyCacheMap: 是一个 CurrentHashMap 只读缓存,这个主要是为了供客户端获取注册信息时使用,其缓存更新,依赖于定时器的更新,通过和 readWriteCacheMap 的值做对比,如果数据不一致,则以 readWriteCacheMap 的数据为准。
-
第二层缓存:readWriteCacheMap,本质上是 Guava 缓存
readWriteCacheMap:readWriteCacheMap 的数据主要同步于存储层。当获取缓存时判断缓存中是否没有数据,如果不存在此数据,则通过 CacheLoader 的 load 方法去加载,加载成功之后将数据放入缓存,同时返回数据。readWriteCacheMap缓存过期时间,默认为180秒,当服务下线、过期、注册、状态变更,都会来清除此缓存中的数据。
Eureka Client 获取全量或者增量的数据时,会先从一级缓存中获取;如果一级缓存中不存在,再从二级缓存中获取;如果二级缓存也不存在,这时候先将存储层的数据同步到缓存中,再从缓存中获取。通过 Eureka Server 的二层缓存机制,可以非常有效地提升 Eureka Server 的响应时间,通过数据存储层和缓存层的数据切割,根据使用场景来提供不同的数据支持。
其它缓存设计
除过 Eureka Server 端存在缓存外,Eureka Client 也同样存在着缓存机制,Eureka Client 启动时会全量拉取服务列表,启动后每隔 30 秒从 Eureka Server 量获取服务列表信息,并保持在本地缓存中。Eureka Client 增量拉取失败,或者增量拉取之后对比 hashcode 发现不一致,就会执行全量拉取,这样避免了网络某时段分片带来的问题,同样会更新到本地缓存。同时对于服务调用,如果涉及到 ribbon 负载均衡,那么 ribbon 对于这个实例列表也有自己的缓存,这个缓存定时(默认30秒)从 Eureka Client 的缓存更新。这么多的缓存机制可能就会造成一些问题,一个服务启动后可能最长需要 90s 才能被其它服务感知到:
- 首先,Eureka Server 维护每 30s 更新的响应缓存
- Eureka Client 对已经获取到的注册信息也做了 30s 缓存
- 负载均衡组件 Ribbon 也有 30s 缓存
这三个缓存加起来,就有可能导致服务注册最长延迟 90s ,这个需要我们在特殊业务场景中注意其产生的影响。
常用配置
Eureka Server常用配置:
#服务端开启自我保护模式,前面章节有介绍
eureka.server.enable-self-preservation=true
#扫描失效服务的间隔时间(单位毫秒,默认是60*1000)即60秒
eureka.server.eviction-interval-timer-in-ms= 60000
#间隔多长时间,清除过期的 delta 数据
eureka.server.delta-retention-timer-interval-in-ms=0
#请求频率限制器
eureka.server.rate-limiter-burst-size=10
#是否开启请求频率限制器
eureka.server.rate-limiter-enabled=false
#请求频率的平均值
eureka.server.rate-limiter-full-fetch-average-rate=100
#是否对标准的client进行频率请求限制。如果是false,则只对非标准client进行限制
eureka.server.rate-limiter-throttle-standard-clients=false
#注册服务、拉去服务列表数据的请求频率的平均值
eureka.server.rate-limiter-registry-fetch-average-rate=500
#设置信任的client list
eureka.server.rate-limiter-privileged-clients=
#在设置的时间范围类,期望与client续约的百分比。
eureka.server.renewal-percent-threshold=0.85
#多长时间更新续约的阈值
eureka.server.renewal-threshold-update-interval-ms=0
#对于缓存的注册数据,多长时间过期
eureka.server.response-cache-auto-expiration-in-seconds=180
#多长时间更新一次缓存中的服务注册数据
eureka.server.response-cache-update-interval-ms=0
#缓存增量数据的时间,以便在检索的时候不丢失信息
eureka.server.retention-time-in-m-s-in-delta-queue=0
#当时间戳不一致的时候,是否进行同步
eureka.server.sync-when-timestamp-differs=true
#是否采用只读缓存策略,只读策略对于缓存的数据不会过期。
eureka.server.use-read-only-response-cache=true
################server node 与 node 之间关联的配置#####################33
#发送复制数据是否在request中,总是压缩
eureka.server.enable-replicated-request-compression=false
#指示群集节点之间的复制是否应批处理以提高网络效率。
eureka.server.batch-replication=false
#允许备份到备份池的最大复制事件数量。而这个备份池负责除状态更新的其他事件。可以根据内存大小,超时和复制流量,来设置此值得大小
eureka.server.max-elements-in-peer-replication-pool=10000
#允许备份到状态备份池的最大复制事件数量
eureka.server.max-elements-in-status-replication-pool=10000
#多个服务中心相互同步信息线程的最大空闲时间
eureka.server.max-idle-thread-age-in-minutes-for-peer-replication=15
#状态同步线程的最大空闲时间
eureka.server.max-idle-thread-in-minutes-age-for-status-replication=15
#服务注册中心各个instance相互复制数据的最大线程数量
eureka.server.max-threads-for-peer-replication=20
#服务注册中心各个instance相互复制状态数据的最大线程数量
eureka.server.max-threads-for-status-replication=1
#instance之间复制数据的通信时长
eureka.server.max-time-for-replication=30000
#正常的对等服务instance最小数量。-1表示服务中心为单节点。
eureka.server.min-available-instances-for-peer-replication=-1
#instance之间相互复制开启的最小线程数量
eureka.server.min-threads-for-peer-replication=5
#instance之间用于状态复制,开启的最小线程数量
eureka.server.min-threads-for-status-replication=1
#instance之间复制数据时可以重试的次数
eureka.server.number-of-replication-retries=5
#eureka节点间间隔多长时间更新一次数据。默认10分钟。
eureka.server.peer-eureka-nodes-update-interval-ms=600000
#eureka服务状态的相互更新的时间间隔。
eureka.server.peer-eureka-status-refresh-time-interval-ms=0
#eureka对等节点间连接超时时间
eureka.server.peer-node-connect-timeout-ms=200
#eureka对等节点连接后的空闲时间
eureka.server.peer-node-connection-idle-timeout-seconds=30
#节点间的读数据连接超时时间
eureka.server.peer-node-read-timeout-ms=200
#eureka server 节点间连接的总共最大数量
eureka.server.peer-node-total-connections=1000
#eureka server 节点间连接的单机最大数量
eureka.server.peer-node-total-connections-per-host=10
#在服务节点启动时,eureka尝试获取注册信息的次数
eureka.server.registry-sync-retries=
#在服务节点启动时,eureka多次尝试获取注册信息的间隔时间
eureka.server.registry-sync-retry-wait-ms=
#当eureka server启动的时候,不能从对等节点获取instance注册信息的情况,应等待多长时间。
eureka.server.wait-time-in-ms-when-sync-empty=0
Eureka Client 常用配置:
#该客户端是否可用
eureka.client.enabled=true
#实例是否在eureka服务器上注册自己的信息以供其他服务发现,默认为true
eureka.client.register-with-eureka=false
#此客户端是否获取eureka服务器注册表上的注册信息,默认为true
eureka.client.fetch-registry=false
#是否过滤掉,非UP的实例。默认为true
eureka.client.filter-only-up-instances=true
#与Eureka注册服务中心的通信zone和url地址
eureka.client.serviceUrl.defaultZone=http://${eureka.instance.hostname}:${server.port}/eureka/
#client连接Eureka服务端后的空闲等待时间,默认为30 秒
eureka.client.eureka-connection-idle-timeout-seconds=30
#client连接eureka服务端的连接超时时间,默认为5秒
eureka.client.eureka-server-connect-timeout-seconds=5
#client对服务端的读超时时长
eureka.client.eureka-server-read-timeout-seconds=8
#client连接all eureka服务端的总连接数,默认200
eureka.client.eureka-server-total-connections=200
#client连接eureka服务端的单机连接数量,默认50
eureka.client.eureka-server-total-connections-per-host=50
#执行程序指数回退刷新的相关属性,是重试延迟的最大倍数值,默认为10
eureka.client.cache-refresh-executor-exponential-back-off-bound=10
#执行程序缓存刷新线程池的大小,默认为5
eureka.client.cache-refresh-executor-thread-pool-size=2
#心跳执行程序回退相关的属性,是重试延迟的最大倍数值,默认为10
eureka.client.heartbeat-executor-exponential-back-off-bound=10
#心跳执行程序线程池的大小,默认为5
eureka.client.heartbeat-executor-thread-pool-size=5
# 询问Eureka服务url信息变化的频率(s),默认为300秒
eureka.client.eureka-service-url-poll-interval-seconds=300
#最初复制实例信息到eureka服务器所需的时间(s),默认为40秒
eureka.client.initial-instance-info-replication-interval-seconds=40
#间隔多长时间再次复制实例信息到eureka服务器,默认为30秒
eureka.client.instance-info-replication-interval-seconds=30
#从eureka服务器注册表中获取注册信息的时间间隔(s),默认为30秒
eureka.client.registry-fetch-interval-seconds=30
# 获取实例所在的地区。默认为us-east-1
eureka.client.region=us-east-1
#实例是否使用同一zone里的eureka服务器,默认为true,理想状态下,eureka客户端与服务端是在同一zone下
eureka.client.prefer-same-zone-eureka=true
# 获取实例所在的地区下可用性的区域列表,用逗号隔开。(AWS)
eureka.client.availability-zones.china=defaultZone,defaultZone1,defaultZone2
#eureka服务注册表信息里的以逗号隔开的地区名单,如果不这样返回这些地区名单,则客户端启动将会出错。默认为null
eureka.client.fetch-remote-regions-registry=
#服务器是否能够重定向客户端请求到备份服务器。 如果设置为false,服务器将直接处理请求,如果设置为true,它可能发送HTTP重定向到客户端。默认为false
eureka.client.allow-redirects=false
#客户端数据接收
eureka.client.client-data-accept=
#增量信息是否可以提供给客户端看,默认为false
eureka.client.disable-delta=false
#eureka服务器序列化/反序列化的信息中获取“_”符号的的替换字符串。默认为“__“
eureka.client.escape-char-replacement=__
#eureka服务器序列化/反序列化的信息中获取“$”符号的替换字符串。默认为“_-”
eureka.client.dollar-replacement="_-"
#当服务端支持压缩的情况下,是否支持从服务端获取的信息进行压缩。默认为true
eureka.client.g-zip-content=true
#是否记录eureka服务器和客户端之间在注册表的信息方面的差异,默认为false
eureka.client.log-delta-diff=false
# 如果设置为true,客户端的状态更新将会点播更新到远程服务器上,默认为true
eureka.client.on-demand-update-status-change=true
#此客户端只对一个单一的VIP注册表的信息感兴趣。默认为null
eureka.client.registry-refresh-single-vip-address=
#client是否在初始化阶段强行注册到服务中心,默认为false
eureka.client.should-enforce-registration-at-init=false
#client在shutdown的时候是否显示的注销服务从服务中心,默认为true
eureka.client.should-unregister-on-shutdown=true
Eureka Instance 常用配置:
#服务注册中心实例的主机名
eureka.instance.hostname=localhost
#注册在Eureka服务中的应用组名
eureka.instance.app-group-name=
#注册在的Eureka服务中的应用名称
eureka.instance.appname=
#该实例注册到服务中心的唯一ID
eureka.instance.instance-id=
#该实例的IP地址
eureka.instance.ip-address=
#该实例,相较于hostname是否优先使用IP
eureka.instance.prefer-ip-address=false
Eureka集群原理
-
Eureka Server集群相互之间通过 Replicate(复制) 来同步数据
相互之间不区分主节点和从节点,所有的节点都是平等的。在这种架构中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其它节点。
-
如果某台Eureka Server宕机,Eureka Client的请求会自动切换到新的Eureka Server节点
当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会进行节点间复制,将请求复制到其它 Eureka Server 所知的所有节点中。
-
Eureka Server的同步遵循一个原则:只要有一条边将节点连接,就可以进行信息传播与同步
如果存在多个节点,只需要将节点之间两两连接起来形成通路,那么其它注册中心都可以共享信息。每个 Eureka Server 同时也是 Eureka Client,多个 Eureka Server 之间通过 P2P 的方式完成服务注册表的同步。
-
Eureka Server集群之间的状态是采用异步方式同步的
所以不保证节点间的状态一定是一致的,不过基本能保证最终状态是一致的。
Eureka 分区 Eureka 提供了 Region 和 Zone 两个概念来进行分区,这两个概念均来自于亚马逊的 AWS:
- region:可以理解为地理上的不同区域,比如亚洲地区,中国区或者深圳等等。没有具体大小的限制。根据项目具体的情况,可以自行合理划分 region
- zone:可以简单理解为 region 内的具体机房,比如说 region 划分为深圳,然后深圳有两个机房,就可以在此 region 之下划分出 zone1、zone2 两个 zone
上图中的 us-east-1c、us-east-1d、us-east-1e 就代表了不同的 Zone。Zone 内的 Eureka Client 优先和 Zone 内的 Eureka Server 进行心跳同步,同样调用端优先在 Zone 内的 Eureka Server 获取服务列表,当 Zone 内的 Eureka Server 挂掉之后,才会从别的 Zone 中获取信息。
Eurka 保证 AP
Eureka Server 各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而 Eureka Client 在向某个 Eureka 注册时,如果发现连接失败,则会自动切换至其它节点。只要有一台 Eureka Server 还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
Eureka一致性协议
Eureka 和 Zookeeper 的最大区别: Eureka 是 AP 模型,Zookeeper 是 CP 模型。在出现脑裂等场景时,Eureka 可用性是每一位,也就是说出现脑裂时,每个分区仍可以独立提供服务,是去中心化的。那Eureka是如何实现最终一致性的呢?
消息广播
-
Eureka Server 管理了全部的服务器列表(PeerEurekaNodes)
-
当 Eureka Server 收到客户端的注册、下线、心跳请求时,通过 PeerEurekaNode 向其余的服务器进行消息广播,如果广播失败则重试,直到任务过期后取消任务,此时这两台服务器之间数据会出现短暂的不一致。
注意: 虽然消息广播失败,但只要收到客户端的心跳,仍会向所有的服务器(包括失联的服务器)广播心跳任务。
-
如果网络恢复正常,收到了其它服务器广播的心跳任务,此时可能有三种情况:
- 一是脑裂很快恢复,一切正常;
- 二是该实例已经自动过期,则重新进行注册;
- 三是数据冲突,出现不一致的情况,则需要发起同步请求,其实也就是重新注册一次,同时踢除老的实例。
总之,通过集群之间的消息广播可以实现数据的最终一致性。
服务注册
- Spring Cloud Eureka 在应用启动时,会在 EurekaAutoServiceRegistration 这个类初始化的时候,主动去 Eureka Server 端注册。
- Eureka 在启动完成之后会启动一个 40 秒执行一次的定时任务,该任务会去监测自身的 IP 信息以及自身的配置信息是否发生改变,如果发生改变,则会重新发起注册。
- 续约返回 404 状态码时,会去重新注册
主动下线
Eureka 会在 spring 容器销毁的时候执行 shutDown 方法 ,该方法首先会将自身的状态改为 DOWN,接着发送cancle 命令至 Eureka Server 请求下掉自己的服务。
心跳续约与自动下线
健康检测,一般都是 TTL(Time To Live) 机制。eg: 客户端每 5s 发送心跳,服务端 15s 没收到心跳包,更新实例状态为不健康, 30s 未收到心跳包,从服务列表中删除。Eureka Server 默认每 30s 发送心跳包,90s 未收心跳则删除。这个清理过期实例的线程,每 60s 执行一次。
崩溃恢复
重启
Spring Cloud Eureka 启动时,在初始化 EurekaServerBootstrap#initEurekaServerContext 时会调用 PeerAwareInstanceRegistryImpl#syncUp 从其它 Eureka 中同步数据。
脑裂
- 发生脑裂后:和 Eureka Server 同区的服务可以正常访问,而不同区的服务则自动过期。
- 脑裂恢复后:接收其它 Eureka Sever 发送过来的心跳请求,此时有三种情况:一是脑裂很快恢复,一切正常;二是该实例已经自动过期,则重新进行注册;三是数据冲突,出现不一致的情况,则需要发起同步请求。
Zuul
Zuul 是由 Netflix 孵化的一个致力于“网关 “解决方案的开源组件。
网关的作用
- 统一入口:未全部为服务提供一个唯一的入口,网关起到外部和内部隔离的作用,保障了后台服务的安全性
- 鉴权校验:识别每个请求的权限,拒绝不符合要求的请求
- 动态路由:动态的将请求路由到不同的后端集群中
- 减少客户端与服务端的耦合:服务可以独立发展,通过网关层来做映射
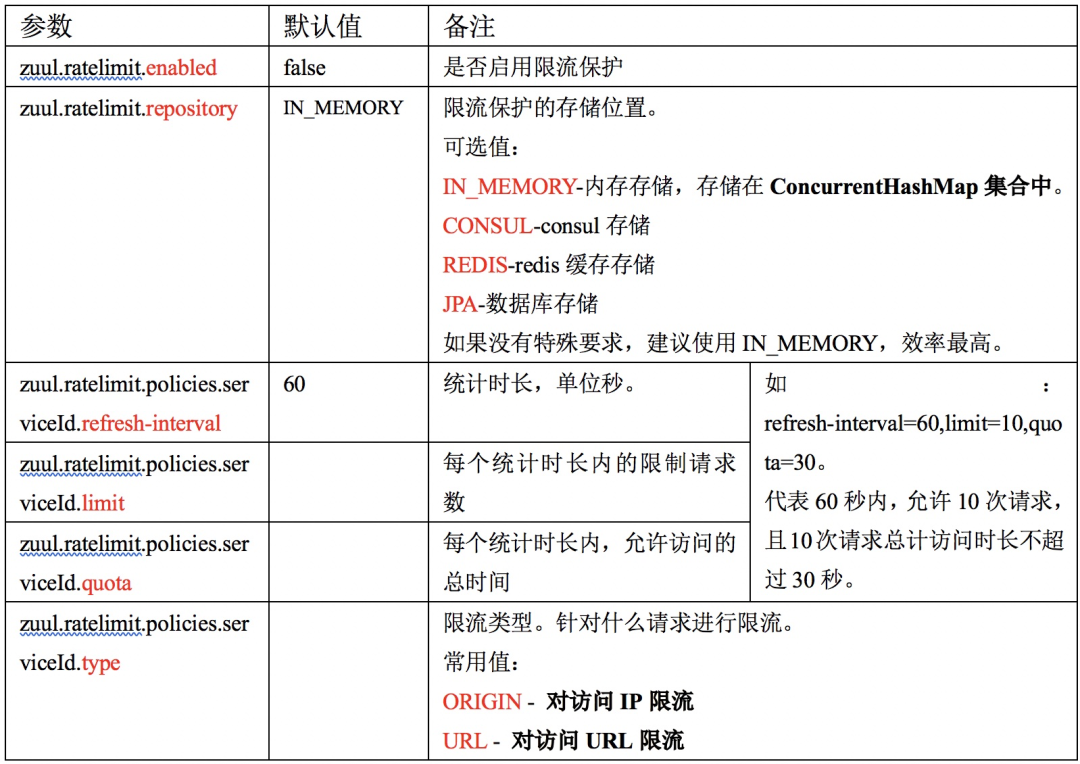
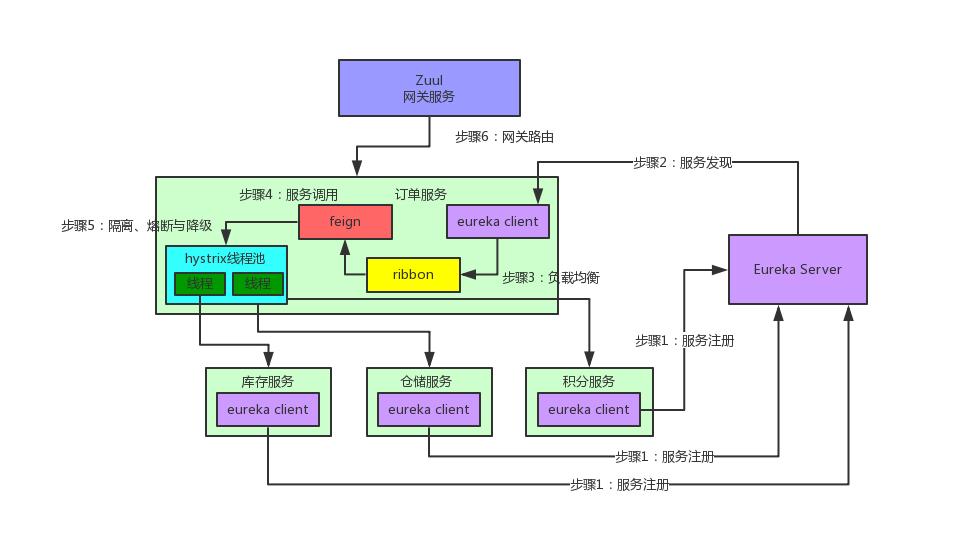
Feign
Feign 使用时分成两步:一是生成 Feign 的动态代理;二是 Feign 执行。
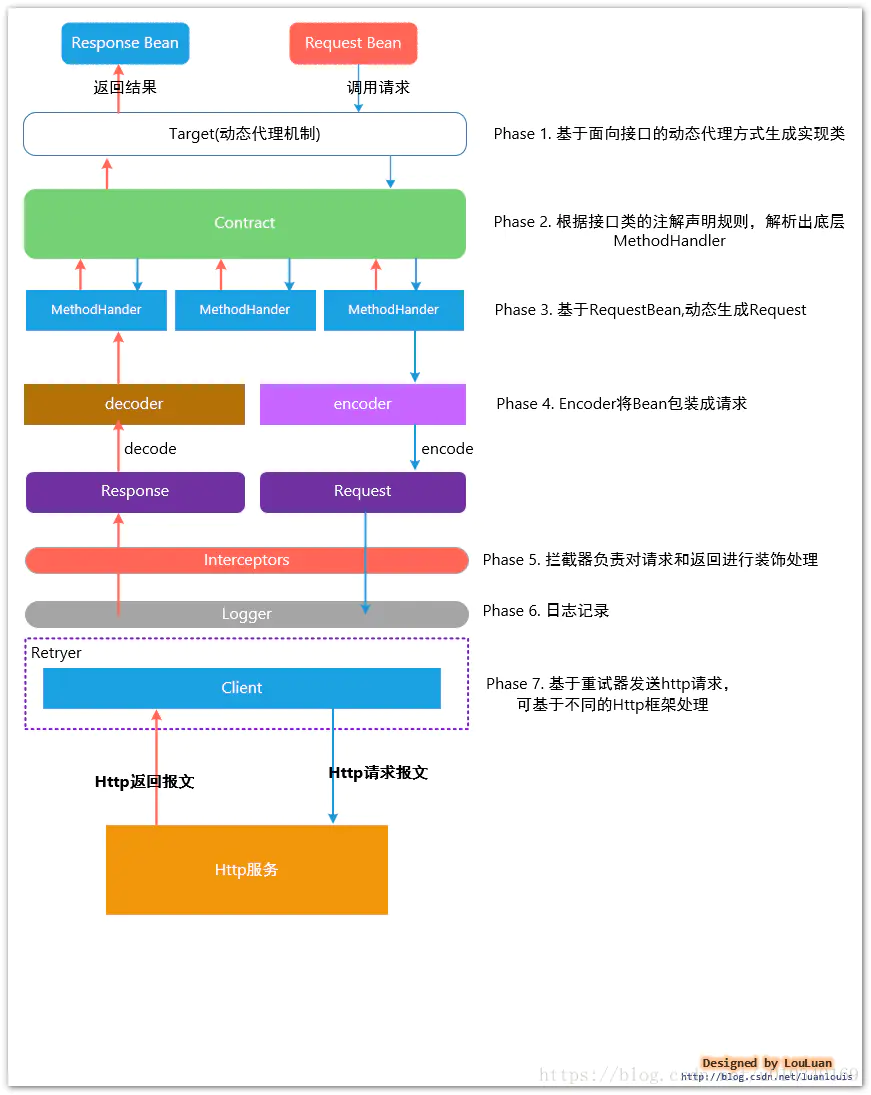
总结:
- 前两步是生成动态对象:将 Method 方法的注解解析成 MethodMetadata,并最终生成 Feign 动态代理对象
- 后几步是调用过程:根据解析的MethodMetadata对象,将Method方法的参数转换成Request,最后调用Client发送请求
Feign动态代理
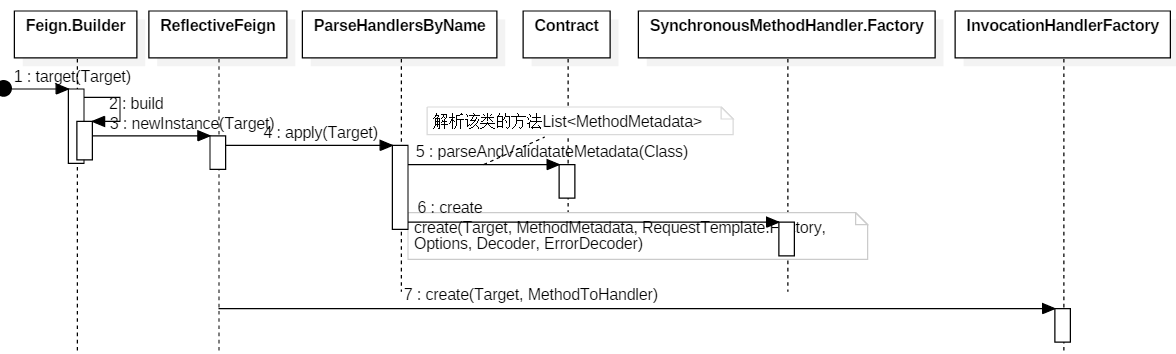
Feign 的默认实现是 ReflectiveFeign,通过 Feign.Builder 构建。总结
- Contract 统一将方法解析 MethodMetadata(*),这样就可以通过实现不同的 Contract 适配各种 REST 声明式规范。
- buildTemplate 实际上将 Method 方法的参数转换成 Request。
- 将 metadata 和 buildTemplate 封装成 MethodHandler。
基于Feign实现负载均衡
基于 Feign 的负载均衡(整合 Ribbon)。想要进行负载均衡,那就要对 Client 进行包装,实现负载均衡。 相关代码见RibbonClient和LBClient。
// RibbonClient 主要逻辑
private final Client delegate;
private final LBClientFactory lbClientFactory;
public Response execute(Request request, Request.Options options) throws IOException {
try {
URI asUri = URI.create(request.url());
String clientName = asUri.getHost();
URI uriWithoutHost = cleanUrl(request.url(), clientName);
// 封装 RibbonRequest,包含 Client、Request、uri
LBClient.RibbonRequest ribbonRequest =
new LBClient.RibbonRequest(delegate, request, uriWithoutHost);
// executeWithLoadBalancer 实现负载均衡
return lbClient(clientName).executeWithLoadBalancer(
ribbonRequest,
new FeignOptionsClientConfig(options)).toResponse();
} catch (ClientException e) {
propagateFirstIOException(e);
throw new RuntimeException(e);
}
}
总结: 实际上是把 Client 对象包装了一下,通过 executeWithLoadBalancer 进行负载均衡,这是 Ribbon 提供了 API。更多关于 Ribbon 的负载均衡就不在这进一步说明了。
public final class LBClient extends AbstractLoadBalancerAwareClient
<LBClient.RibbonRequest, LBClient.RibbonResponse> {
// executeWithLoadBalancer 方法通过负载均衡算法后,最终调用 execute
@Override
public RibbonResponse execute(RibbonRequest request, IClientConfig configOverride)
throws IOException, ClientException {
Request.Options options;
if (configOverride != null) {
options = new Request.Options(
configOverride.get(CommonClientConfigKey.ConnectTimeout, connectTimeout),
configOverride.get(CommonClientConfigKey.ReadTimeout, readTimeout),
configOverride.get(CommonClientConfigKey.FollowRedirects, followRedirects));
} else {
options = new Request.Options(connectTimeout, readTimeout);
}
// http 请求
Response response = request.client().execute(request.toRequest(), options);
if (retryableStatusCodes.contains(response.status())) {
response.close();
throw new ClientException(ClientException.ErrorType.SERVER_THROTTLED);
}
return new RibbonResponse(request.getUri(), response);
}
}
基于Feign实现熔断
基于 Feign 的熔断与限流(整合 Hystrix)。想要进行限流,那就要在方法执行前进行拦截,也就是重写InvocationHandlerFactory,在方法执行前进行熔断与限流。相关代码见 HystrixFeign,其实也就是实现了 HystrixInvocationHandler。
// HystrixInvocationHandler 主要逻辑
public Object invoke(final Object proxy, final Method method, final Object[] args)
throws Throwable {
HystrixCommand<Object> hystrixCommand =
new HystrixCommand<Object>(setterMethodMap.get(method)) {
@Override
protected Object run() throws Exception {
return HystrixInvocationHandler.this.dispatch.get(method).invoke(args);
}
@Override
protected Object getFallback() {
};
}
...
return hystrixCommand.execute();
}
Feign参数编码整体流程
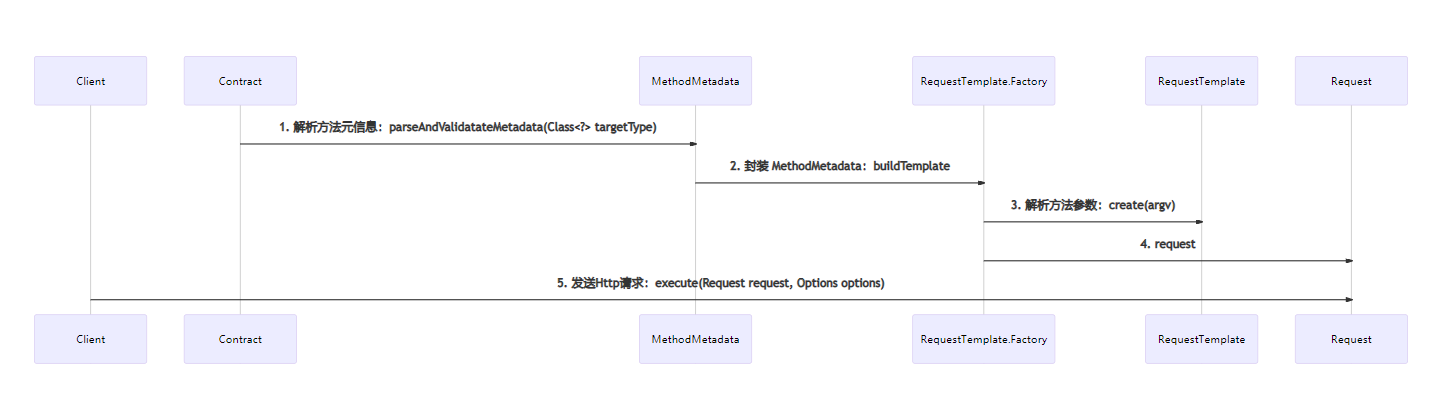 总结:
总结:
- 前两步是
Feign代理生成阶段,解析方法参数及注解元信息。后三步是调用阶段,将方法参数编码成Http请求的数据格式 - Contract 接口将 UserService 中每个接口中的方法及其注解解析为 MethodMetadata,然后使用 RequestTemplate# request 编码为一个 Request
- RequestTemplate#request 编码为一个 Request 后就可以调用 Client#execute 发送 Http 请求
- Client 的具体实现有 HttpURLConnection、Apache HttpComponnets、OkHttp3 、Netty 等。本文关注前三步:即 Feign 方法元信息解析及参数编码过程。
Feign整体装配流程
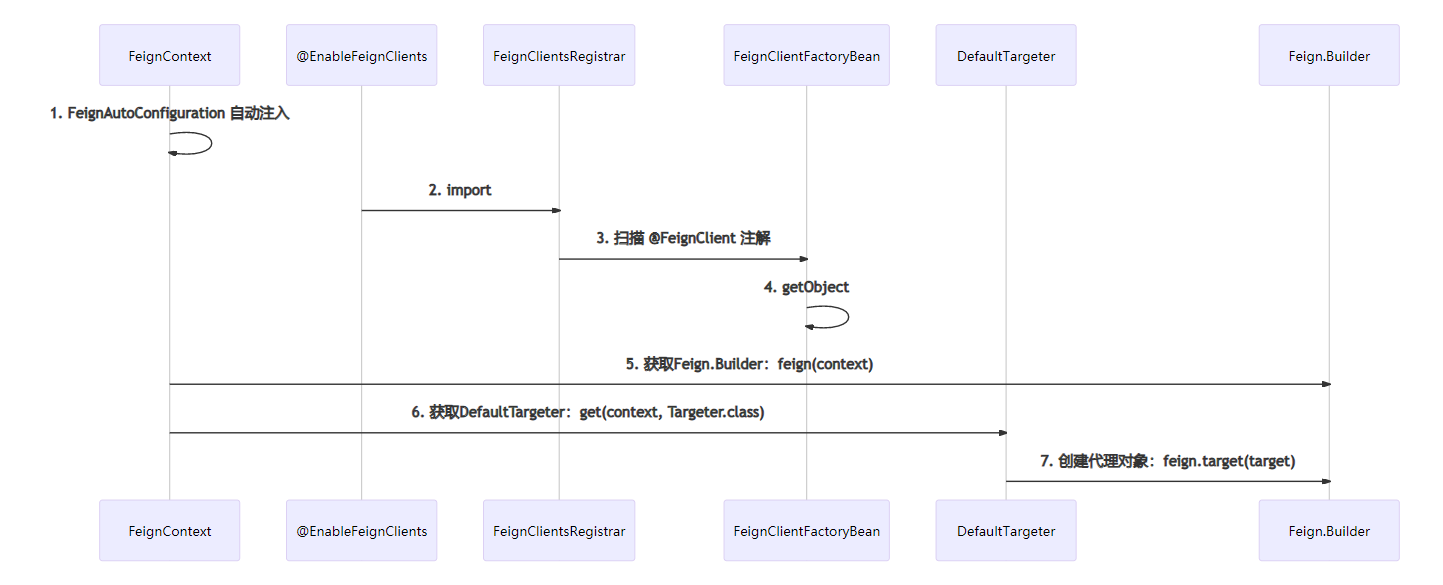
总结: OpenFeign 装配有两个入口:
-
@EnableAutoConfiguration 自动装配(spring.factories)
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ org.springframework.cloud.openfeign.ribbon.FeignRibbonClientAutoConfiguration,\ org.springframework.cloud.openfeign.FeignAutoConfiguration- FeignAutoConfiguration自动装配 FeignContext 和 Targeter,以及 Client 配置。
FeignContext是每个 FeignClient 的装配上下文,默认的配置是 FeignClientsConfigurationTargeter有两种实现:一是 DefaultTargeter,直接调用 Feign.Builder; 二是 HystrixTargeter,调用 HystrixFeign.Builder,开启熔断。Client:自动装配 ApacheHttpClient,OkHttpClient,装配条件不满足,默认是 Client.Default。但这些 Client 都没有实现负载均衡。
- FeignRibbonClientAutoConfiguration实现负载均衡,负载均衡是在 Client 这一层实现的。
HttpClientFeignLoadBalancedConfigurationApacheHttpClient 实现负载均衡OkHttpFeignLoadBalancedConfigurationOkHttpClient实现负载均衡DefaultFeignLoadBalancedConfigurationClient.Default实现负载均衡
- FeignAutoConfiguration自动装配 FeignContext 和 Targeter,以及 Client 配置。
-
@EnableFeignClients 自动扫描
@EnableFeignClients 注入 FeignClientsRegistrar,FeignClientsRegistrar 开启自动扫描,将包下 @FeignClient 标注的接口包装成 FeignClientFactoryBean 对象,最终通过 Feign.Builder 生成该接口的代理对象。而 Feign.Builder 的默认配置是 FeignClientsConfiguration,是在 FeignAutoConfiguration 自动注入的。
注意: 熔断与限流是 FeignAutoConfiguration 通过注入 HystrixTargeter 完成的,而负载均衡是FeignRibbonClientAutoConfiguration 注入的。
其它
Feign是是一个声明式的Web Service客户端。
Feign就是使用了动态代理:
- 首先,如果你对某个接口定义了@FeignClient注解,Feign就会针对这个接口创建一个动态代理
- 接着你要是调用那个接口,本质就是会调用 Feign创建的动态代理,这是核心中的核心
- Feign的动态代理会根据你在接口上的@RequestMapping等注解,来动态构造出你要请求的服务的地址
- 最后针对这个地址,发起请求、解析响应
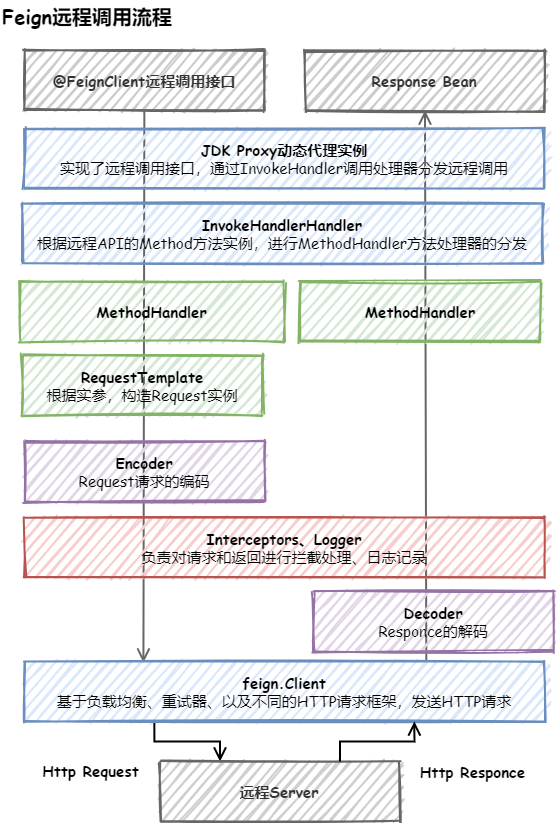
Ribbon
Ribbon Netflix 公司开源的一个负载均衡的组件。
Ribbon在服务消费者端配置和使用,它的作用就是负载均衡,然后默认使用的负载均衡算法是轮询算法,Ribbon会从Eureka服务端中获取到对应的服务注册表,然后就知道相应服务的位置,然后Ribbon根据设计的负载均衡算法去选择一台机器,Feigin就会针对这些机器构造并发送请求,如下图所示:

Hystrix
Hystrix是Netstflix 公司开源的一个项目,它提供了熔断器功能,能够阻止分布式系统中出现联动故障。
Hystrix是隔离、熔断以及降级的一个框架,说白了就是Hystrix会搞很多小线程池然后让这些小线程池去请求服务,返回结果,Hystrix相当于是个中间过滤区,如果我们的积分服务挂了,那我们请求积分服务直接就返回了,不需要等待超时时间结束抛出异常,这就是所谓的熔断,但是也不能啥都不干就返回啊,不然我们之后手动加积分咋整啊,那我们每次调用积分服务就在数据库里记录一条消息,这就是所谓的降级,Hystrix隔离、熔断和降级的全流程如下:
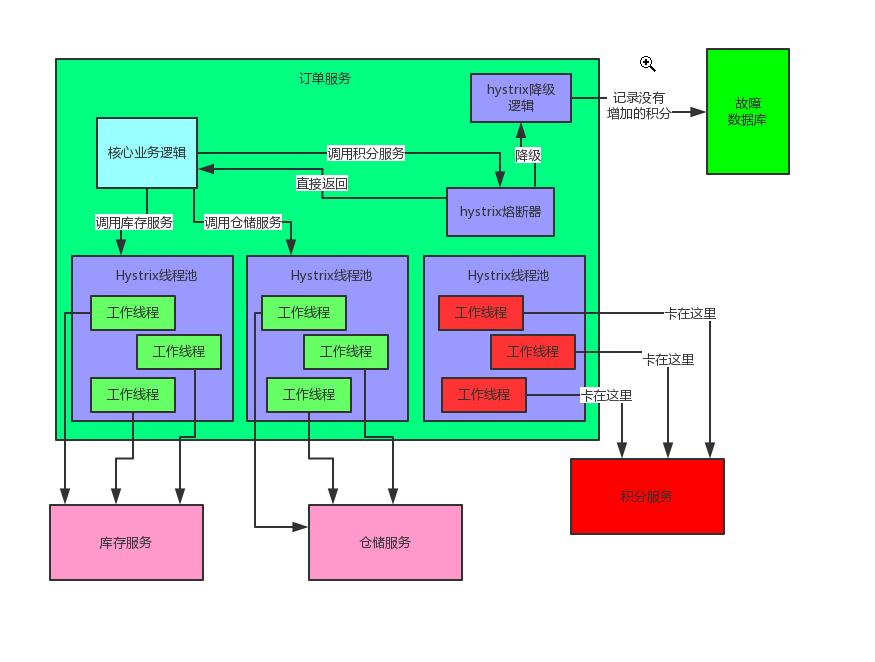
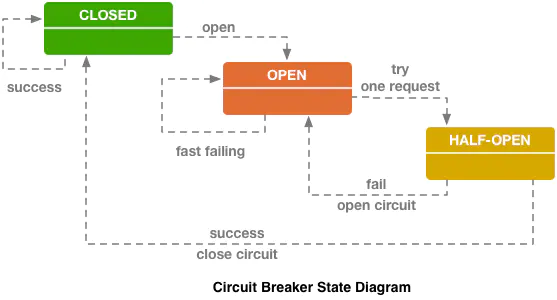
Gateway
Spring Cloud Gateway 是 Spring 官方基于 Spring 5.0、 Spring Boot 2.0 和 Project Reactor 等技术开发的网关, Spring Cloud Gateway 旨在为微服务架构提供简单、 有效且统一的 API 路由管理方式。
Config
Spring Cloud 中提供了分布式配置中 Spring Cloud Config ,为外部配置提供了客户端和服务器端的支持。
Bus
使用 Spring Cloud Bus, 可以非常容易地搭建起消息总线。
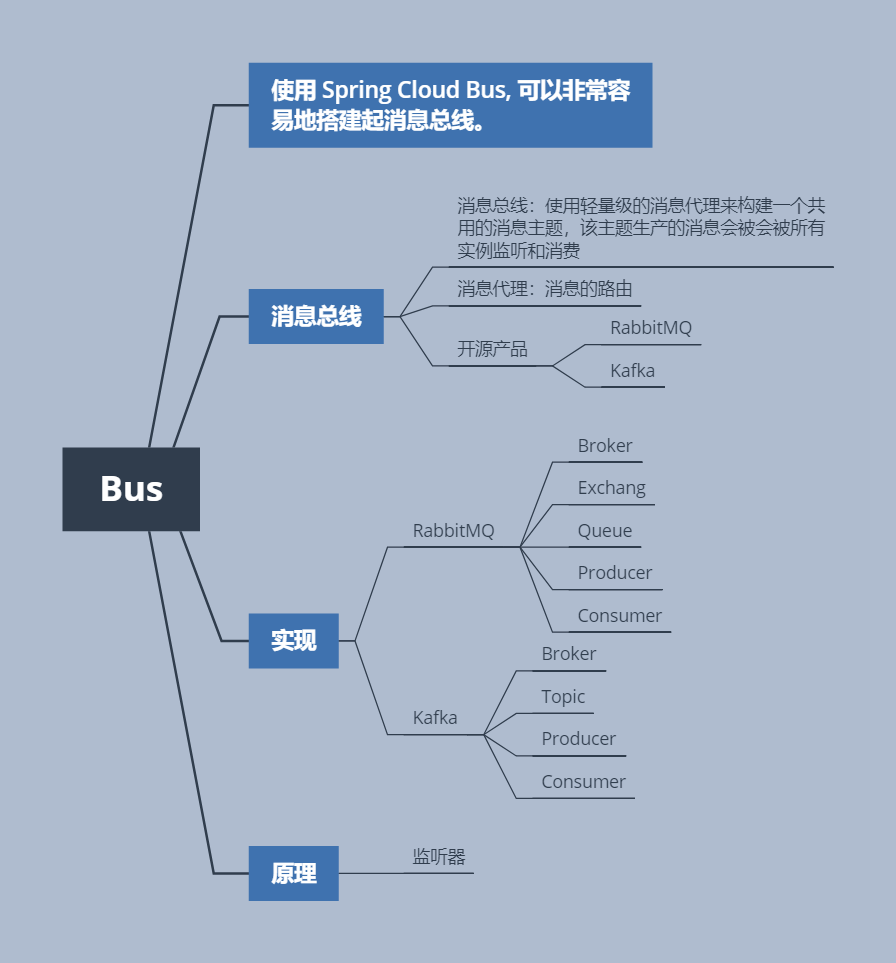
OAuth2
Sprin Cloud 构建的微服务系统中可以使用 Spring Cloud OAuth2 来保护微服务系统。
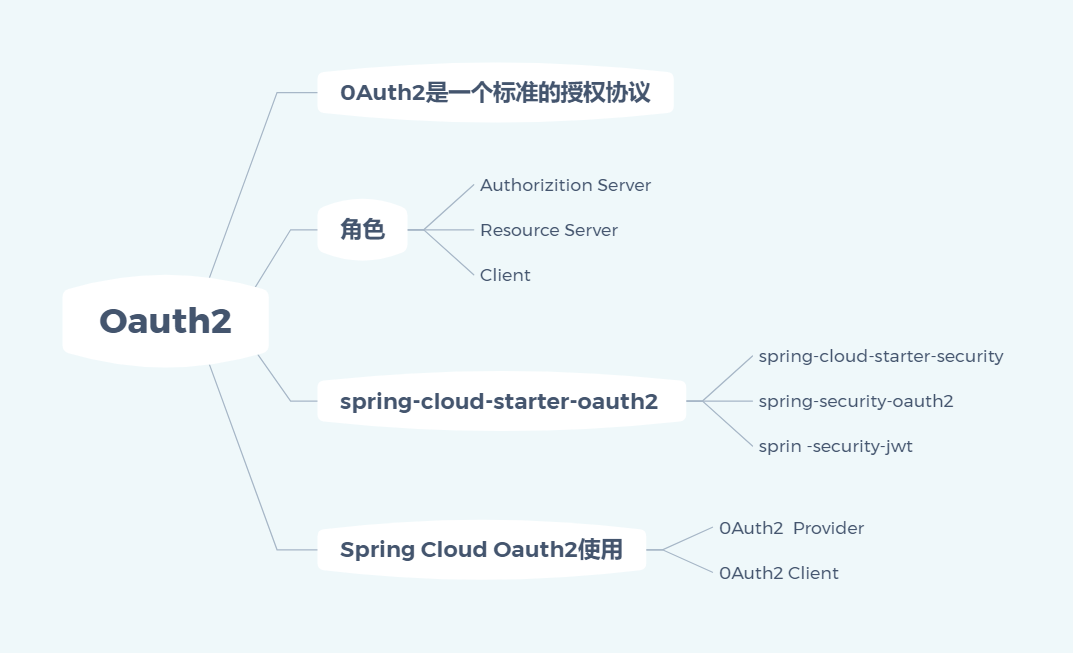
Sleuth
Spring Cloud Sleuth是Spring Cloud 个组件,它的主要功能是在分布式系统中提供服务链路追踪的解决方案。
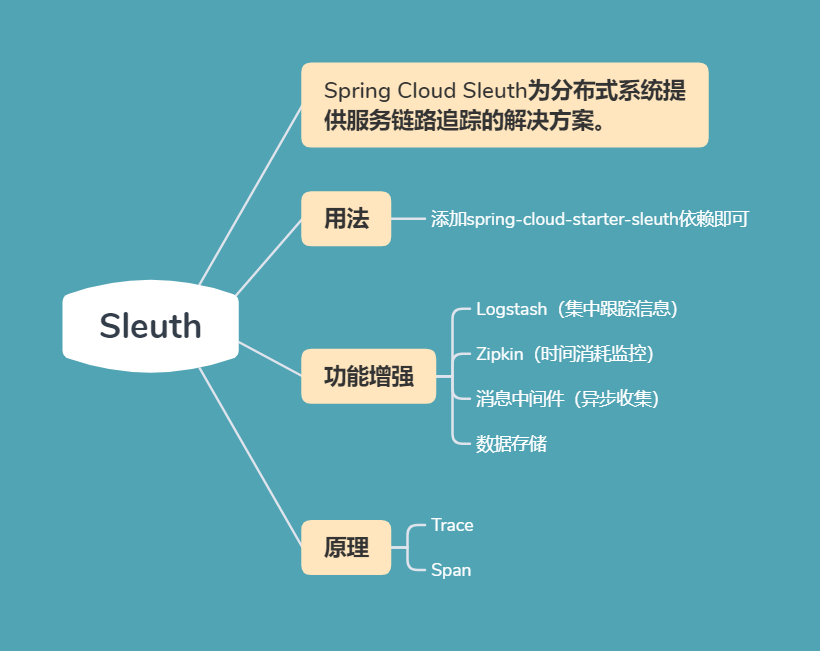
MyBatis
Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,加载驱动、创建连接、创建statement等繁杂的过程,开发者开发时只需要关注如何编写SQL语句,可以严格控制sql执行性能,灵活度高。
作为一个半ORM框架,MyBatis 可以使用 XML 或注解来配置和映射原生信息,将 POJO映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
通过xml 文件或注解的方式将要执行的各种 statement 配置起来,并通过java对象和 statement中sql的动态参数进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射为java对象并返回。(从执行sql到返回result的过程)。
由于MyBatis专注于SQL本身,灵活度高,所以比较适合对性能的要求很高,或者需求变化较多的项目,如互联网项目。
Mybaits优缺点
-
优点
- 基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用
- 与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接
- 很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)
- 能够与Spring很好的集成
- 提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护
-
缺点
-
SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求
-
SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库
#{}和${}的区别是什么?
${}是字符串替换#{}是预处理
使用#{}可以有效的防止SQL注入,提高系统安全性。
MyBatis架构
核心成员说明
| 核心成员 | 功能说明 |
|---|---|
| Configuration | 保存MyBatis大部分配置信息 |
| SqlSession | MyBatis主要的顶层API,与数据库交互,实现数据库增删改查功能 |
| Executor | MyBatis 调度器,负责SQL语句的生成和查询缓存的维护 |
| StatementHandler | 封装JDBC,负责对JDBC statement 的操作,如设置参数等 |
| ParameterHandler | 用户传递的参数转换成JDBC Statement 所对应的数据类型 |
| ResultSetHandler | 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合 |
| TypeHandler | 负责java数据类型和jdbc数据类型(也可以说是数据表列类型)之间的映射和转换 |
| MappedStatement | MappedStatement维护一条<select|update|delete|insert>节点的封装 |
| SqlSource | 负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回 |
| BoundSql | 表示动态生成的SQL语句以及相应的参数信息 |
MyBatis流程
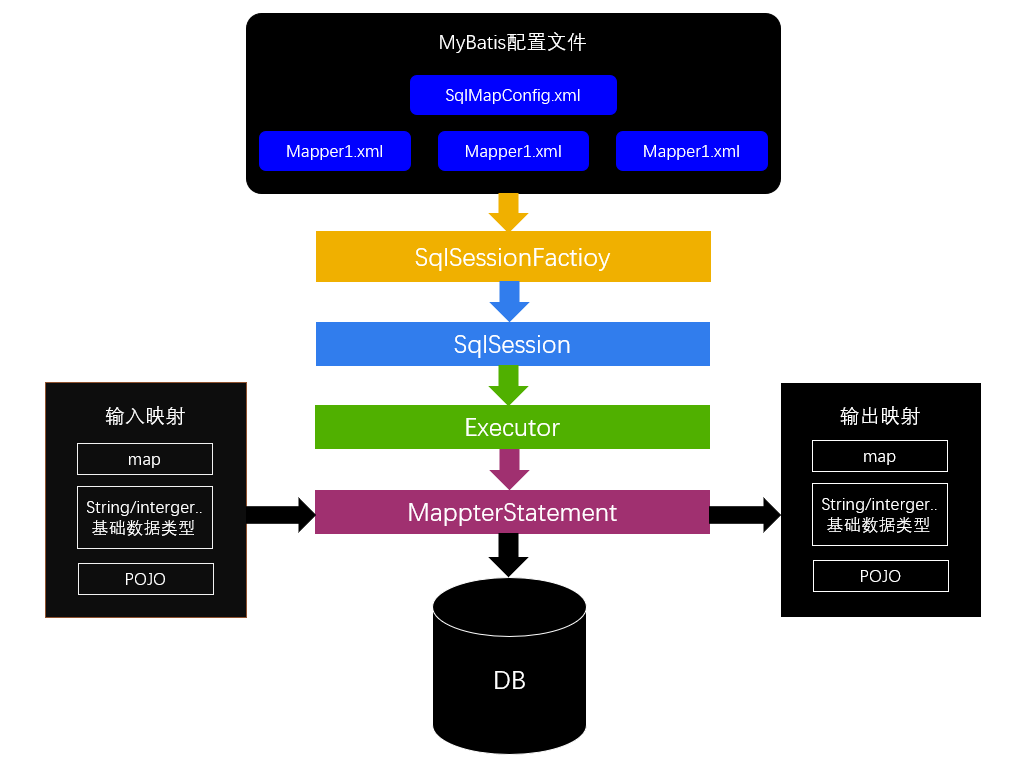
Dao接口工作原理
Mapper 接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Mapper接口生成代理对象proxy,代理对象会拦截接口方法,根据类的全限定名+方法名,唯一定位到一个MapperStatement并调用执行器执行所代表的sql,然后将sql执行结果返回。
Mapper接口里的方法,是不能重载的,因为是使用 全限名+方法名 的保存和寻找策略。
MyBatis缓存
MyBatis 中有一级缓存和二级缓存,默认情况下一级缓存是开启的,而且是不能关闭的。一级缓存是指 SqlSession 级别的缓存,当在同一个 SqlSession 中进行相同的 SQL 语句查询时,第二次以后的查询不会从数据库查询,而是直接从缓存中获取,一级缓存最多缓存 1024 条 SQL。二级缓存是指可以跨 SqlSession 的缓存。是 mapper 级别的缓存,对于mapper级别的缓存不同的sqlsession 是可以共享的。一级缓存核心类是PerpetualCache,本质是一个hashMap。二级缓存默认不开启。
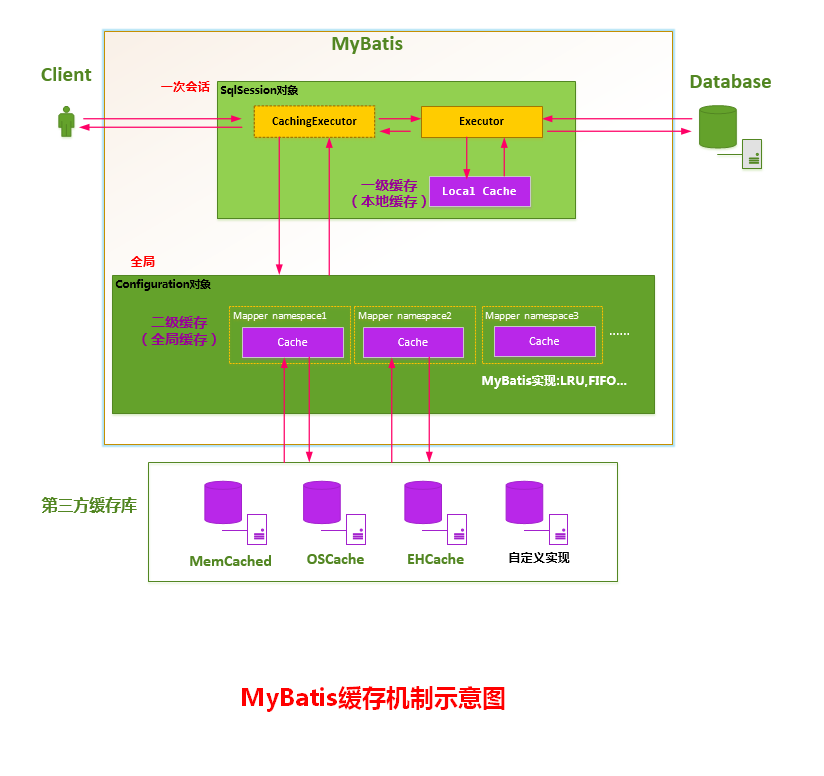
一级缓存
Mybatis的一级缓存原理(sqlsession级别)。第一次发出一个查询 sql,sql 查询结果写入 sqlsession 的一级缓存中,缓存使用的数据结构是一个 map。
- key:MapperID+offset+limit+Sql+所有的入参
- value:用户信息
同一个 sqlsession 再次发出相同的 sql,就从缓存中取出数据。如果两次中间出现 commit 操作(修改、添加、删除),本 sqlsession 中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。
二级缓存
二级缓存的范围是 mapper 级别(mapper 同一个命名空间),mapper 以命名空间为单位创建缓存数据结构,结构是 map。mybatis 的二级缓存是通过 CacheExecutor 实现的。CacheExecutor其实是 Executor 的代理对象。所有的查询操作,在 CacheExecutor 中都会先匹配缓存中是否存在,不存在则查询数据库。
- key:MapperID+offset+limit+Sql+所有的入参
具体使用需要配置:
- Mybatis 全局配置中启用二级缓存配置
- 在对应的 Mapper.xml 中配置 cache 节点
- 在对应的 select 查询节点中添加 useCache=true
MyBatis主要组件
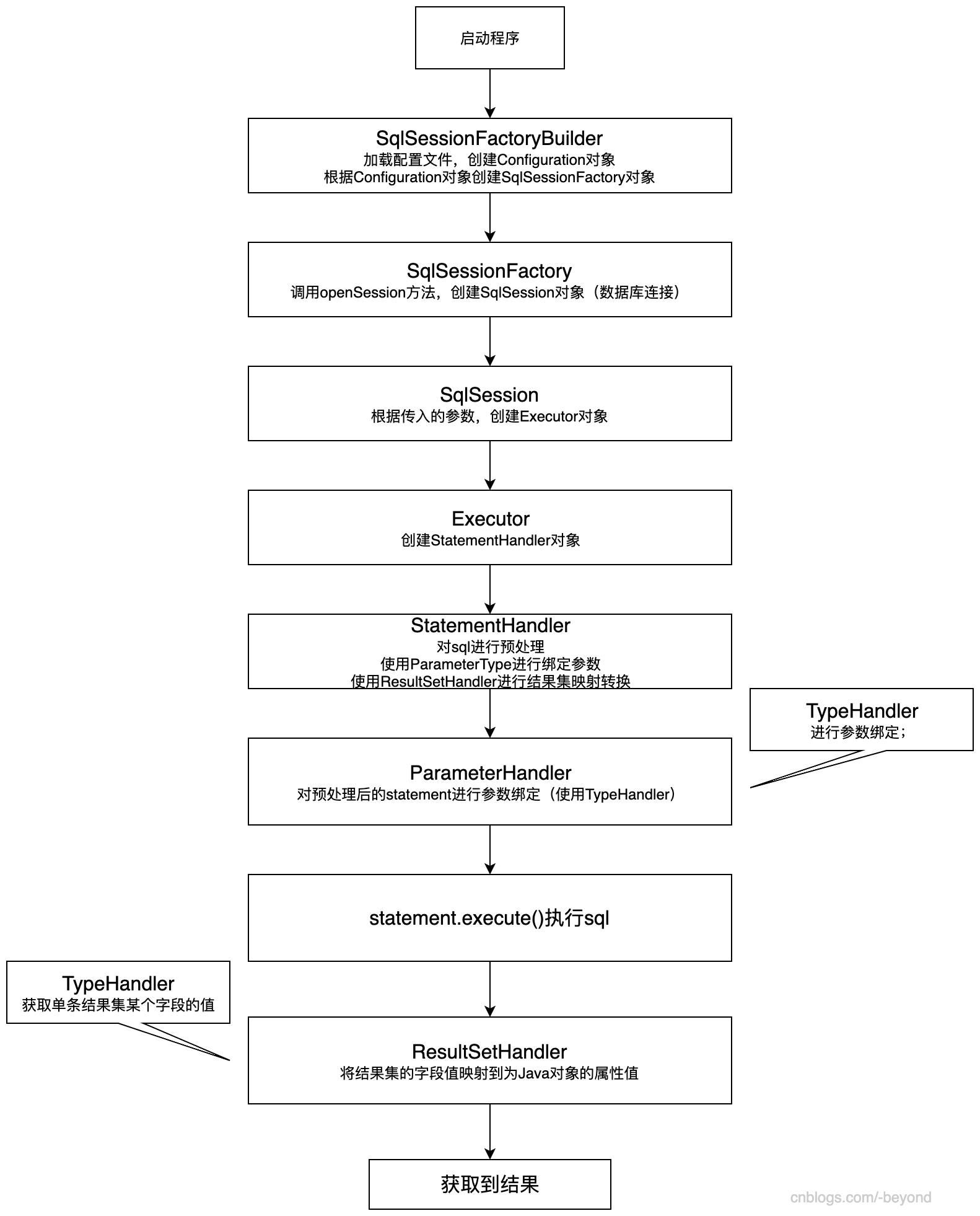
SqlSessionFactoryBuilder
从名称长可以看出来使用的建造者设计模式(Builder),用于构建SqlSessionFactory对象:
- 解析mybatis的xml配置文件,然后创建Configuration对象(对应标签)
- 根据创建的Configuration对象,创建SqlSessionFactory(默认使用DefaultSqlSessionFactory)
SqlSessionFactory
从名称上可以看出使用的工厂模式(Factory),用于创建并初始化SqlSession对象(数据库会话)
- 调用openSession方法,创建SqlSession对象,可以将SqlSession理解为数据库连接(会话)
- openSession方法有多个重载,可以创建SqlSession关闭自动提交、指定ExecutorType、指定数据库事务隔离级别
SqlSession
如果了解web开发,就应该知道cookie和session吧,SqlSession的session和web开发中的session概念类似。session,译为“会话、会议”,数据的有效时间范围是在会话期间(会议期间),会话(会议)结束后,数据就清除了。也可以将SqlSession理解为一个数据库连接(但也不完全正确,因为创建SqlSession之后,如果不执行sql,那么这个连接是无意义的,所以数据库连接在执行sql的时候才建立的)。
SqlSession只是定义了执行sql的一些方法,而具体的实现由子类来完成,比如SqlSession有一个接口实现类DefaultSqlSession。MyBatis中通过Executor来执行sql的,在创建SqlSession的时候(openSession),同时会创建一个Executor对象。
Executor
Executor(人称“执行器”)是一个接口,定义了对JDBC的封装。MyBatis中提供了多种执行器,如下:
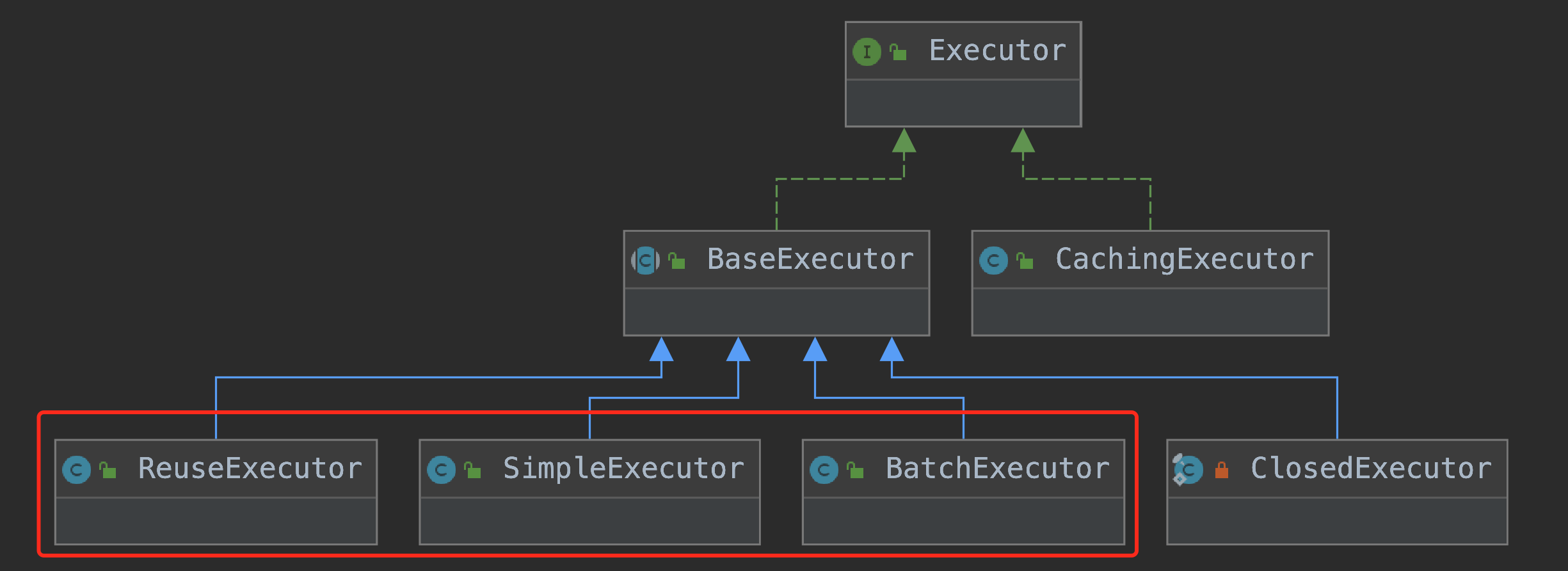 CacheExecutor其实是一个Executor代理类,包含一个delegate,需要创建时手动传入(要入simple、reuse、batch三者之一)。ClosedExecutor,所有接口都会抛出异常,表示一个已经关闭的Executor。创建SqlSession时,默认使用的是SimpleExecutor。
CacheExecutor其实是一个Executor代理类,包含一个delegate,需要创建时手动传入(要入simple、reuse、batch三者之一)。ClosedExecutor,所有接口都会抛出异常,表示一个已经关闭的Executor。创建SqlSession时,默认使用的是SimpleExecutor。
Executor是对JDBC的封装。当我们使用JDBC来执行sql时,一般会先预处理sql,也就是conn.prepareStatement(sql),获取返回的PreparedStatement对象(实现了Statement接口),再调用statement的executeXxx()来执行sql。也就是说,Executor在执行sql的时候也是需要创建Statement对象的。
StatementHandler
在JDBC中,是调用Statement.executeXxx()来执行sql。在MyBatis,也是调用Statement.executeXxx()来执行sql,此时就不得不提StatementHandler,可以将其理解为一个工人,他的工作包括
- 对sql进行预处理
- 调用statement.executeXxx()执行sql
- 将数据库返回的结果集进行对象转换(ORM)
ParameterHandler
ParameterHandler的功能就是sql预处理后,进行设置参数。ParamterHandler有一个DefaultParameterHandler。
ResultSetHandler
当执行statement.execute()后,就可以通过statement.getResultSet()来获取结果集,获取到结果集之后,MyBatis会使用ResultSetHandler来将结果集的数据转换为Java对象(ORM映射)。ResultSetHandler有一个实现类,DefaultResultHandler,其重写handlerResultSets方法。
TypeHandler
TypeHandler主要用在两个地方:
-
参数绑定,发生在ParameterHandler.setParamenters()中
MyBatis中,可以使用来定义结果的映射关系,包括每一个字段的类型。TypeHandler可以对某个字段按照xml中配置的类型进行设置值,比如设置sql的uid参数时,类型为INTEGER(jdbcType)
-
获取结果集中的字段值,发生在ResultSetHandler处理结果集的过程中
Nginx
Nginx安装
# CentOS
yum install nginx;
# Ubuntu
sudo apt-get install nginx;
# Mac
brew install nginx;
安装完成后,通过 rpm \-ql nginx 命令查看 Nginx 的安装信息:
# Nginx配置文件
/etc/nginx/nginx.conf # nginx 主配置文件
/etc/nginx/nginx.conf.default
# 可执行程序文件
/usr/bin/nginx-upgrade
/usr/sbin/nginx
# nginx库文件
/usr/lib/systemd/system/nginx.service # 用于配置系统守护进程
/usr/lib64/nginx/modules # Nginx模块目录
# 帮助文档
/usr/share/doc/nginx-1.16.1
/usr/share/doc/nginx-1.16.1/CHANGES
/usr/share/doc/nginx-1.16.1/README
/usr/share/doc/nginx-1.16.1/README.dynamic
/usr/share/doc/nginx-1.16.1/UPGRADE-NOTES-1.6-to-1.10
# 静态资源目录
/usr/share/nginx/html/404.html
/usr/share/nginx/html/50x.html
/usr/share/nginx/html/index.html
# 存放Nginx日志文件
/var/log/nginx
主要关注的文件夹有两个:
-
/etc/nginx/conf.d/是子配置项存放处,/etc/nginx/nginx.conf主配置文件会默认把该文件夹中所有子配置项都引入 -
/usr/share/nginx/html/静态文件都放在这个文件夹,也可以根据你自己的习惯放在其他地方
运维命令
一般可以在 /etc/nginx/nginx.conf 中配置。
systemctl命令
# 开机配置
# 开机自动启动
systemctl enable nginx
# 关闭开机自动启动
systemctl disable nginx
# 启动Nginx
systemctl start nginx # 启动Nginx成功后,可以直接访问主机IP,此时会展示Nginx默认页面
# 停止Nginx
systemctl stop nginx
# 重启Nginx
systemctl restart nginx
# 重新加载Nginx
systemctl reload nginx
# 查看 Nginx 运行状态
systemctl status nginx
# 查看Nginx进程
ps -ef | grep nginx
# 杀死Nginx进程
kill -9 pid # 根据上面查看到的Nginx进程号,杀死Nginx进程,-9 表示强制结束进程
Nginx应用命令
# 启动
nginx -s start
# 向主进程发送信号,重新加载配置文件,热重启
nginx -s reload
# 重启 Nginx
nginx -s reopen
# 快速关闭
nginx -s stop
# 等待工作进程处理完成后关闭
nginx -s quit
# 查看当前 Nginx 最终的配置
nginx -T
# 检查配置是否有问题
nginx -t
配置规则
Nginx层级结构如下:
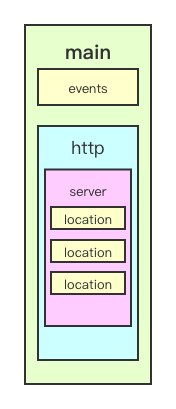
URI匹配
location = / {
# 完全匹配 =
# 大小写敏感 ~
# 忽略大小写 ~*
}
location ^~ /images/ {
# 前半部分匹配 ^~
# 可以使用正则,如:
# location ~* \.(gif|jpg|png)$ { }
}
location / {
# 如果以上都未匹配,会进入这里
}
upstream
语法:upstream name {
...
}
上下文:http
示例:
upstream back_end_server{
server 192.168.100.33:8081
}
upstream 用于定义上游服务器(指的就是后台提供的应用服务器)的相关信息。
upstream test_server{
# weight=3 权重值,默认为1
# max_conns=1000 上游服务器的最大并发连接数
# fail_timeout=10s 服务器不可用的判定时间
# max_fails=2 服务器不可用的检查次数
# backup 备份服务器,仅当其他服务器都不可用时才会启用
# down 标记服务器长期不可用,离线维护;
server 127.0.0.1:8081 weight=3 max_conns=1000 fail_timeout=10s max_fails=2;
# 限制每个worker子进程与上游服务器空闲长连接的最大数量
keepalive 16;
# 单个长连接可以处理的最多 HTTP 请求个数
keepalive_requests 100;
# 空闲长连接的最长保持时间
keepalive_timeout 60s;
}
proxy_pass
语法:proxy_pass URL;
上下文:location、if、limit_except
示例:
proxy_pass http://127.0.0.1:8081
proxy_pass http://127.0.0.1:8081/proxy
URL 参数原则:
-
URL必须以http或https开头 -
URL中可以携带变量 -
URL中是否带URI,会直接影响发往上游请求的URL
URL 后缀带 / 和不带 / 的区别:
- 不带
/意味着Nginx不会修改用户URL,而是直接透传给上游的应用服务器 - 带
/意味着Nginx会修改用户URL,修改方法是将location后的URL从用户URL中删除
# 用户请求 URL :/bbs/abc/test.html
location /bbs/{
# 请求到达上游应用服务器的 URL :/bbs/abc/test.html
proxy_pass http://127.0.0.1:8080;
# 请求到达上游应用服务器的 URL :/abc/test.html
proxy_pass http://127.0.0.1:8080/;
}
应用场景
反向代理
# 1 /etc/nginx/conf.d/proxy.conf
# 1.1 模拟被代理服务
server{
listen 8080;
server_name localhost;
location /proxy/ {
root /usr/share/nginx/html/proxy;
index index.html;
}
}
# 1.2 /usr/share/nginx/html/proxy/index.html
<h1> 121.42.11.34 proxy html </h1>
# 2 /etc/nginx/conf.d/proxy.conf
# 2.1 back server
upstream back_end {
server 121.42.11.34:8080 weight=2 max_conns=1000 fail_timeout=10s max_fails=3;
keepalive 32;
keepalive_requests 80;
keepalive_timeout 20s;
}
# 2.2 代理配置
server {
listen 80;
# vim /etc/hosts进入配置文件,添加如下内容:121.5.180.193 proxy.lion.club
server_name proxy.lion.club;
location /proxy {
proxy_pass http://back_end/proxy;
}
}
负载均衡
# 1 /etc/nginx/conf.d/balance.conf
# 1.1 模拟被代理服务1
server{
listen 8020;
location / {
return 200 'return 8020 \n';
}
}
# 1.2 模拟被代理服务2
server{
listen 8030;
location / {
return 200 'return 8030 \n';
}
}
# 1.3 模拟被代理服务3
server{
listen 8040;
location / {
return 200 'return 8040 \n';
}
}
# 2 /etc/nginx/conf.d/balance.conf
# 2.1 demo server list
upstream demo_server {
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
# 2.2 代理配置
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}
hash算法
upstream demo_server {
hash $request_uri;
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}
hash $request_uri 表示使用 request_uri 变量作为 hash 的 key 值,只要访问的 URI 保持不变,就会一直分发给同一台服务器。
ip_hash
upstream demo_server {
ip_hash;
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}
根据客户端的请求 ip 进行判断,只要 ip 地址不变就永远分配到同一台主机。它可以有效解决后台服务器 session 保持的问题。
最少连接数算法
upstream demo_server {
zone test 10M; # zone可以设置共享内存空间的名字和大小
least_conn;
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}
各个 worker 子进程通过读取共享内存的数据,来获取后端服务器的信息。来挑选一台当前已建立连接数最少的服务器进行分配请求。
配置缓存
① proxy_cache
存储一些之前被访问过、而且可能将要被再次访问的资源,使用户可以直接从代理服务器获得,从而减少上游服务器的压力,加快整个访问速度。
语法:proxy_cache zone | off ; # zone 是共享内存的名称
默认值:proxy_cache off;
上下文:http、server、location
② proxy_cache_path
设置缓存文件的存放路径。
语法:proxy_cache_path path [level=levels] ...可选参数省略,下面会详细列举
默认值:proxy_cache_path off
上下文:http
参数含义:
path缓存文件的存放路径level path的目录层级keys_zone设置共享内存inactive在指定时间内没有被访问,缓存会被清理,默认10分钟
③ proxy_cache_key
设置缓存文件的 key 。
语法:proxy_cache_key
默认值:proxy_cache_key $scheme$proxy_host$request_uri;
上下文:http、server、location
④ proxy_cache_valid
配置什么状态码可以被缓存,以及缓存时长。
语法:proxy_cache_valid [code...] time;
上下文:http、server、location
配置示例:proxy_cache_valid 200 304 2m;; # 说明对于状态为200和304的缓存文件的缓存时间是2分钟
⑤ proxy_no_cache
定义相应保存到缓存的条件,如果字符串参数的至少一个值不为空且不等于“ 0”,则将不保存该响应到缓存。
语法:proxy_no_cache string;
上下文:http、server、location
示例:proxy_no_cache $http_pragma $http_authorization;
⑥ proxy_cache_bypass
定义条件,在该条件下将不会从缓存中获取响应。
语法:proxy_cache_bypass string;
上下文:http、server、location
示例:proxy_cache_bypass $http_pragma $http_authorization;
⑦ upstream_cache_status 变量
它存储了缓存是否命中的信息,会设置在响应头信息中,在调试中非常有用。
MISS: 未命中缓存
HIT:命中缓存
EXPIRED: 缓存过期
STALE: 命中了陈旧缓存
REVALIDDATED: Nginx验证陈旧缓存依然有效
UPDATING: 内容陈旧,但正在更新
BYPASS: X响应从原始服务器获取
proxy_cache_path /etc/nginx/cache_temp levels=2:2 keys_zone=cache_zone:30m max_size=2g inactive=60m use_temp_path=off;
upstream cache_server{
server 121.42.11.34:1010;
server 121.42.11.34:1020;
}
server {
listen 80;
server_name cache.lion.club;
# 场景一:实时性要求不高,则配置缓存
location /demo {
proxy_cache cache_zone; # 设置缓存内存,上面配置中已经定义好的
proxy_cache_valid 200 5m; # 缓存状态为200的请求,缓存时长为5分钟
proxy_cache_key $request_uri; # 缓存文件的key为请求的URI
add_header Nginx-Cache-Status $upstream_cache_status # 把缓存状态设置为头部信息,响应给客户端
proxy_pass http://cache_server; # 代理转发
}
# 场景二:实时性要求非常高,则配置不缓存
# URI 中后缀为 .txt 或 .text 的设置变量值为 "no cache"
if ($request_uri ~ \.(txt|text)$) {
set $cache_name "no cache"
}
location /test {
proxy_no_cache $cache_name; # 判断该变量是否有值,如果有值则不进行缓存,如果没有值则进行缓存
proxy_cache cache_zone; # 设置缓存内存
proxy_cache_valid 200 5m; # 缓存状态为200的请求,缓存时长为5分钟
proxy_cache_key $request_uri; # 缓存文件的key为请求的URI
add_header Nginx-Cache-Status $upstream_cache_status # 把缓存状态设置为头部信息,响应给客户端
proxy_pass http://cache_server; # 代理转发
}
}
HTTPS
下载证书的压缩文件,里面有个 Nginx 文件夹,把 xxx.crt 和 xxx.key 文件拷贝到服务器目录,再进行如下配置:
server {
listen 443 ssl http2 default_server; # SSL 访问端口号为 443
server_name lion.club; # 填写绑定证书的域名(我这里是随便写的)
ssl_certificate /etc/nginx/https/lion.club_bundle.crt; # 证书地址
ssl_certificate_key /etc/nginx/https/lion.club.key; # 私钥地址
ssl_session_timeout 10m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2; # 支持ssl协议版本,默认为后三个,主流版本是[TLSv1.2]
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
}
开启gzip压缩
在 /etc/nginx/conf.d/ 文件夹中新建配置文件 gzip.conf :
# 默认off,是否开启gzip
gzip on;
# 要采用 gzip 压缩的 MIME 文件类型,其中 text/html 被系统强制启用
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript;
# ---- 以上两个参数开启就可以支持Gzip压缩了 ----
# 默认 off,该模块启用后,Nginx 首先检查是否存在请求静态文件的 gz 结尾的文件,如果有则直接返回该 .gz 文件内容
gzip_static on;
# 默认 off,nginx做为反向代理时启用,用于设置启用或禁用从代理服务器上收到相应内容 gzip 压缩
gzip_proxied any;
# 用于在响应消息头中添加Vary:Accept-Encoding,使代理服务器根据请求头中的Accept-Encoding识别是否启用gzip压缩
gzip_vary on;
# gzip 压缩比,压缩级别是 1-9,1 压缩级别最低,9 最高,级别越高压缩率越大,压缩时间越长,建议 4-6
gzip_comp_level 6;
# 获取多少内存用于缓存压缩结果,16 8k 表示以 8k*16 为单位获得
gzip_buffers 16 8k;
# 允许压缩的页面最小字节数,页面字节数从header头中的 Content-Length 中进行获取。默认值是 0,不管页面多大都压缩。建议设置成大于 1k 的字节数,小于 1k 可能会越压越大
gzip_min_length 1k;
# 默认 1.1,启用 gzip 所需的 HTTP 最低版本
gzip_http_version 1.1;
常用配置
侦听端口
server {
# Standard HTTP Protocol
listen 80;
# Standard HTTPS Protocol
listen 443 ssl;
# For http2
listen 443 ssl http2;
# Listen on 80 using IPv6
listen [::]:80;
# Listen only on using IPv6
listen [::]:80 ipv6only=on;
}
访问日志
server {
# Relative or full path to log file
access_log /path/to/file.log;
# Turn 'on' or 'off'
access_log on;
}
域名
server {
# Listen to yourdomain.com
server_name yourdomain.com;
# Listen to multiple domains server_name yourdomain.com www.yourdomain.com;
# Listen to all domains
server_name *.yourdomain.com;
# Listen to all top-level domains
server_name yourdomain.*;
# Listen to unspecified Hostnames (Listens to IP address itself)
server_name "";
}
静态资源
server {
listen 80;
server_name yourdomain.com;
location / {
root /path/to/website;
}
}
重定向
server {
listen 80;
server_name www.yourdomain.com;
return 301 http://yourdomain.com$request_uri;
}
server {
listen 80;
server_name www.yourdomain.com;
location /redirect-url {
return 301 http://otherdomain.com;
}
}
反向代理
server {
listen 80;
server_name yourdomain.com;
location / {
proxy_pass http://0.0.0.0:3000;
# where 0.0.0.0:3000 is your application server (Ex: node.js) bound on 0.0.0.0 listening on port 3000
}
}
负载均衡
upstream node_js {
server 0.0.0.0:3000;
server 0.0.0.0:4000;
server 123.131.121.122;
}
server {
listen 80;
server_name yourdomain.com;
location / {
proxy_pass http://node_js;
}
}
SSL协议
server {
listen 443 ssl;
server_name yourdomain.com;
ssl on;
ssl_certificate /path/to/cert.pem;
ssl_certificate_key /path/to/privatekey.pem;
ssl_stapling on;
ssl_stapling_verify on;
ssl_trusted_certificate /path/to/fullchain.pem;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_session_timeout 1h;
ssl_session_cache shared:SSL:50m;
add_header Strict-Transport-Security max-age=15768000;
}
# Permanent Redirect for HTTP to HTTPS
server {
listen 80;
server_name yourdomain.com;
return 301 https://$host$request_uri;
}
日志分析
# 统计IP访问量
awk '{print $1}' access.log | sort -n | uniq | wc -l
# 查看某一时间段的IP访问量(4-5点)
grep "07/Apr/2017:0[4-5]" access.log | awk '{print $1}' | sort | uniq -c| sort -nr | wc -l
# 查看访问最频繁的前100个IP
awk '{print $1}' access.log | sort -n |uniq -c | sort -rn | head -n 100
# 查看访问100次以上的IP
awk '{print $1}' access.log | sort -n |uniq -c |awk '{if($1 >100) print $0}'|sort -rn
# 查询某个IP的详细访问情况,按访问频率排序
grep '104.217.108.66' access.log |awk '{print $7}'|sort |uniq -c |sort -rn |head -n 100
# 页面访问统计
# 查看访问最频的页面(TOP100)
awk '{print $7}' access.log | sort |uniq -c | sort -rn | head -n 100
# 查看访问最频的页面([排除php页面】(TOP100)
grep -v ".php" access.log | awk '{print $7}' | sort |uniq -c | sort -rn | head -n 100
# 查看页面访问次数超过100次的页面
cat access.log | cut -d ' ' -f 7 | sort |uniq -c | awk '{if ($1 > 100) print $0}' | less
# 查看最近1000条记录,访问量最高的页面
tail -1000 access.log |awk '{print $7}'|sort|uniq -c|sort -nr|less
# 请求量统计
# 统计每秒的请求数,top100的时间点(精确到秒)
awk '{print $4}' access.log |cut -c 14-21|sort|uniq -c|sort -nr|head -n 100
# 统计每分钟的请求数,top100的时间点(精确到分钟)
awk '{print $4}' access.log |cut -c 14-18|sort|uniq -c|sort -nr|head -n 100
# 统计每小时的请求数,top100的时间点(精确到小时)
awk '{print $4}' access.log |cut -c 14-15|sort|uniq -c|sort -nr|head -n 100
# 性能分析
# 列出传输时间超过 3 秒的页面,显示前20条
cat access.log|awk '($NF > 3){print $7}'|sort -n|uniq -c|sort -nr|head -20
# 列出php页面请求时间超过3秒的页面,并统计其出现的次数,显示前100条
cat access.log|awk '($NF > 1 && $7~/\.php/){print $7}'|sort -n|uniq -c|sort -nr|head -100
# 蜘蛛抓取统计
# 统计蜘蛛抓取次数
grep 'Baiduspider' access.log |wc -l
# 统计蜘蛛抓取404的次数
grep 'Baiduspider' access.log |grep '404' | wc -l
# TCP连接统计
# 查看当前TCP连接数
netstat -tan | grep "ESTABLISHED" | grep ":80" | wc -l
# 用tcpdump嗅探80端口的访问看看谁最高
tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F"." '{print $1"."$2"."$3"."$4}' | sort | uniq -c | sort -nr
awk '{print $1}' $logpath |sort -n|uniq|wc -l
# 系统正在统计某一个时间段IP访问量为
sed -n '/22\/Jun\/2017:1[5]/,/22\/Jun\/2017:1[6]/p' $logpath|awk '{print $1}'|sort -n|uniq|wc -l
# 访问100次以上的IP
awk '{print $1}' $logpath|sort -n|uniq -c|awk '{if($1>100) print $0}'|sort -rn
# 访问最频繁的请求(TOP50)
awk '{print $7}' $logpath |sort |uniq -c|sort -rn |head -n 50
# 统计每秒的请求数(TOP50)
awk '{print $4}' $logpath|cut -c 14-21|sort |uniq -c|sort -nr|head -n 50
# 统计每分钟的请求数(TOP50)
awk '{print $4}' $logpath|cut -c 14-18|sort|uniq -c|sort -nr|head -n 50
# 统计每小时请求数(TOP50)
awk '{print $4}' $logpath|cut -c 14-15|sort|uniq -c|sort -nr|head -n 50
# 传输时间超过1秒的请求(TOP20)
cat $logpath|awk '($NF > 1){print $7}'|sort -n|uniq -c|sort -nr|head -20
LVS
LVS是Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统。
工作模式
LVS有三种常见的负载均衡的模式:NAT模式(网络地址转换模式)、IP TUN(隧道模式)、DR(知己路由模式)。阿里云还提供了两种模式:full NAT模式、ENAT模式。
术语
- DS:Director Server,指的是前端负载均衡器
- RS:Real Server,后端真实的工作服务器
- VIP:Virtual Ip Address,向外部直接面向用户请求,作为用户请求的目标的IP地址
- DIP:Director Server IP,主要用于和内部主机通讯的IP地址
- RIP:Real Server IP,后端服务器的IP地址
- CIP:Client IP,客户端主机IP地址
(假设 cip 是200.200.200.2, vip是200.200.200.1)
NAT模式(网络地址转换)
NAT模式(NetWork Address Translation-网络地址转换)。客户发出请求,发送请求给链接调度器的VIP,调度器将请求报文中的目标Ip地址改为RIP。这样服务器RealServer将请求的内容发给调度器,调度器再将报文中的源IP地址改为VIP。
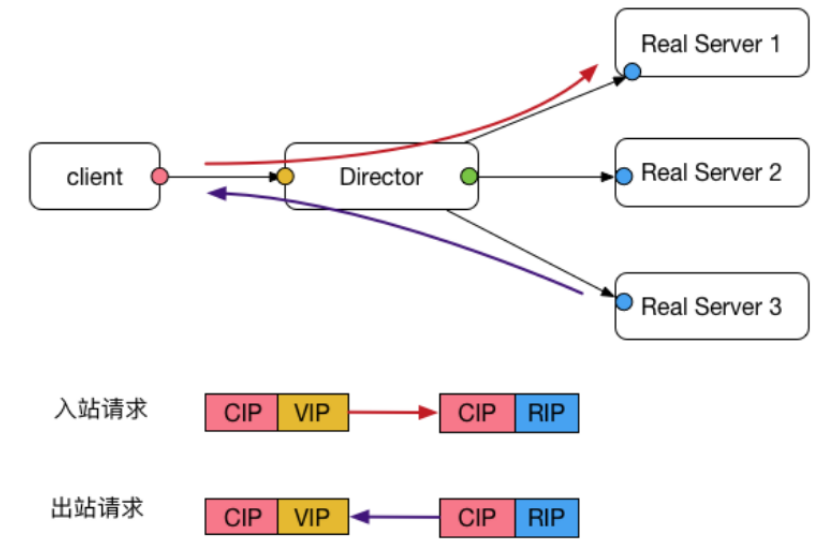
原理
- client发出请求(sip 200.200.200.2,dip 200.200.200.1)
- 请求包到达lvs,lvs修改请求包为(sip 200.200.200.2, dip rip)
- 请求包到达rs, rs回复(sip rip,dip 200.200.200.2)
- 这个回复包不能直接给client,因为rip不是VIP会被reset掉
- 但是因为lvs是网关,所以这个回复包先走到网关,网关有机会修改sip
- 网关修改sip为VIP,修改后的回复包(sip 200.200.200.1,dip 200.200.200.2)发给client
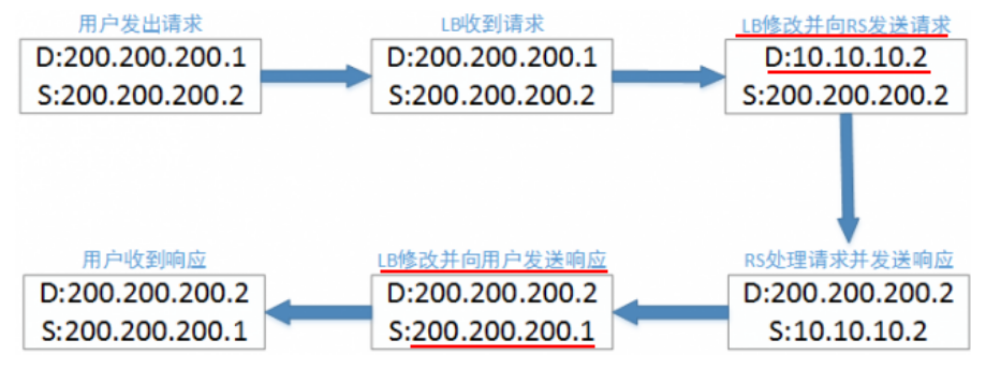
优点
- 配置简单
- 支持端口映射(看名字就知道)
- RIP一般是私有地址,主要用户LVS和RS之间通信
缺点
- LVS和所有RS必须在同一个vlan
- 进出流量都要走LVS转发
- LVS容易成为瓶颈
- 一般而言需要将VIP配置成RS的网关
分析
-
为什么NAT要求lvs和RS在同一个vlan?
因为回复包必须经过lvs再次修改sip为vip,client才认,如果回复包的sip不是client包请求的dip(也就是vip),那么这个连接会被reset掉。如果LVS不是网关,因为回复包的dip是cip,那么可能从其它路由就走了,LVS没有机会修改回复包的sip
NAT结构
- LVS修改进出包的(sip, dip)的时只改了其中一个(所以才有接下来的full NAT)
- NAT最大的缺点是要求LVS和RS必须在同一个vlan,这样限制了LVS集群和RS集群的部署灵活性
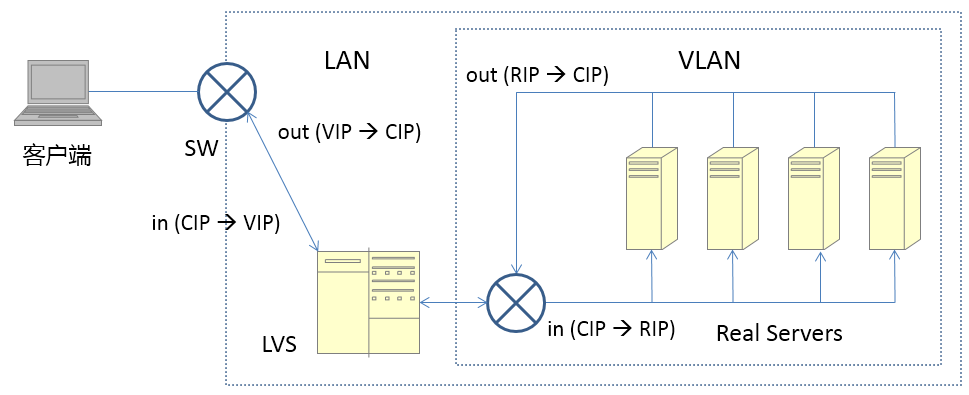
IP TUN模型(IP隧道)
IP TUN模型(IP Tunneling-IP隧道)。和DR模式差不多,但是比DR多了一个隧道技术以支持realserver不在同一个物理环境中。就是realserver一个在北京,一个工作在上海。在原有的IP报文外再次封装多一层IP首部,内部IP首部(源地址为CIP,目标IIP为VIP),外层IP首部(源地址为DIP,目标IP为RIP
原理
- 请求包到达LVS后,LVS将请求包封装成一个新的IP报文
- 新的IP包的目的IP是某一RS的IP,然后转发给RS
- RS收到报文后IPIP内核模块解封装,取出用户的请求报文
- 发现目的IP是VIP,而自己的tunl0网卡上配置了这个IP,从而愉快地处理请求并将结果直接发送给客户
优点
- 集群节点可以跨vlan
- 跟DR一样,响应报文直接发给client
缺点
- RS上必须安装运行IPIP模块
- 多增加了一个IP头
- LVS和RS上的tunl0虚拟网卡上配置同一个VIP(类似DR)
分析
-
为什么IP TUN不要求同一个vlan?
因为IP TUN中不是修改MAC来路由,所以不要求同一个vlan,只要求lvs和rs之间ip能通就行。DR模式要求的是lvs和RS之间广播能通
-
IP TUN性能
回包不走LVS,但是多做了一次封包解包,不如DR好
IP TUN结构
- 图中红线是再次封装过的包,ipip是操作系统的一个内核模块
- DR可能在小公司用的比较多,IP TUN用的少一些
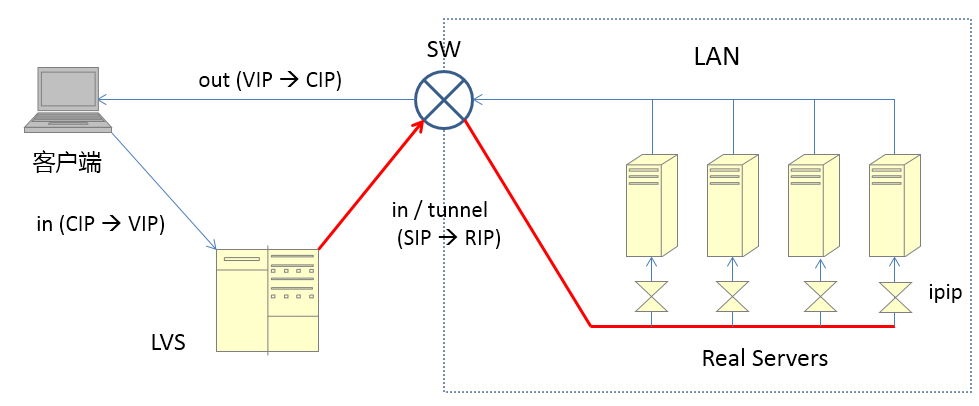
DR模式(直接路由)
DR模式(Director Routing-直接路由)。整个DR模式都是停留在第二层的数据链路层。直接修改MAC。实现报文的转发。
原理
- 请求流量(sip 200.200.200.2, dip 200.200.200.1) 先到达LVS
- 然后LVS,根据负载策略挑选众多 RS中的一个,然后将这个网络包的MAC地址修改成这个选中的RS的MAC
- 然后丢给交换机,交换机将这个包丢给选中的RS
- 选中的RS看到MAC地址是自己的、dip也是自己的,愉快地手下并处理、回复
- 回复包(sip 200.200.200.1, dip 200.200.200.2)
- 经过交换机直接回复给client了(不再走LVS)
优点
- DR模式是性能最好的一种模式,入站请求走LVS,回复报文绕过LVS直接发给Client
缺点
- 要求LVS和rs在同一个vlan
- RS需要配置vip同时特殊处理arp
- 不支持端口映射
分析
-
为什么要求LVS和RS在同一个vlan(或说同一个二层网络里)?
因为DR模式依赖多个RS和LVS共用同一个VIP,然后依据MAC地址来在LVS和多个RS之间路由,所以LVS和RS必须在一个vlan或者说同一个二层网络里
-
DR 模式为什么性能最好?
因为回复包不走LVS了,大部分情况下都是请求包小,回复包大,LVS很容易成为流量瓶颈,同时LVS只需要修改进来的包的MAC地址。
-
DR 模式为什么回包不需要走LVS了?
因为RS和LVS共享同一个vip,回复的时候RS能正确地填好sip为vip,不再需要LVS来多修改一次(后面讲的NAT、Full NAT都需要)。
DR结构
- 绿色是请求包进来,红色是修改过MAC的请求包
full NAT模式
full NAT模式(full NetWork Address Translation-全部网络地址转换)。
原理(类似NAT)
- client发出请求(sip 200.200.200.2 dip 200.200.200.1)
- 请求包到达lvs,lvs修改请求包为**(sip 200.200.200.1, dip rip)** 注意这里sip/dip都被修改了
- 请求包到达rs, rs回复(sip rip,dip 200.200.200.1)
- 这个回复包的目的IP是VIP(不像NAT中是 cip),所以LVS和RS不在一个vlan通过IP路由也能到达lvs
- lvs修改sip为vip, dip为cip,修改后的回复包(sip 200.200.200.1,dip 200.200.200.2)发给client
优点
- 解决了NAT对LVS和RS要求在同一个vlan的问题,适用更复杂的部署形式
缺点
- RS看不到cip(NAT模式下可以看到)
- 进出流量还是都走的lvs,容易成为瓶颈(跟NAT一样都有这个问题)
分析
- 为什么full NAT解决了NAT中要求的LVS和RS必须在同一个vlan的问题?
因为LVS修改进来的包的时候把(sip, dip)都修改了(这也是full的主要含义吧),RS的回复包目的地址是vip(NAT中是cip),所以只要vip和rs之间三层可通就行,这样LVS和RS可以在不同的vlan了,也就是LVS不再要求是网关,从而LVS和RS可以在更复杂的网络环境下部署。
- 为什么full NAT后RS看不见cip了?
因为cip被修改掉了,RS只能看到LVS的vip,在阿里内部会将cip放入TCP包的Option中传递给RS,RS上一般部署自己写的toa模块来从Options中读取的cip,这样RS能看到cip了, 当然这不是一个开源的通用方案。
full NAT结构
- full NAT解决了NAT的同vlan的要求,基本上可以用于公有云
- 但还没解决进出流量都走LVS的问题(LVS要修改进出的包)
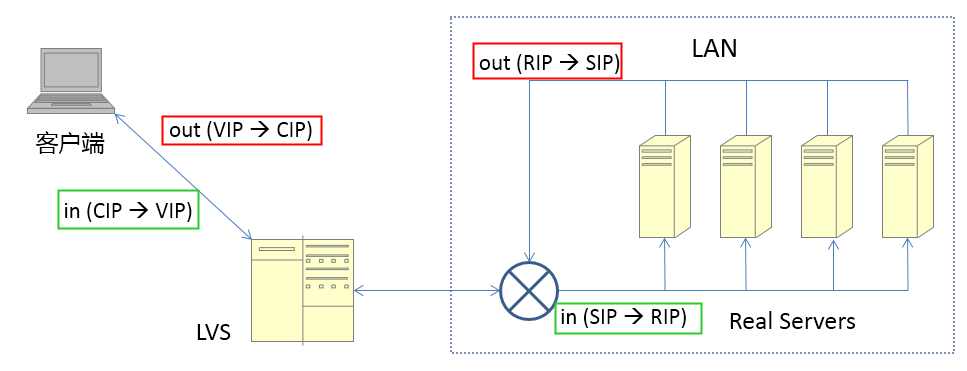
ENAT模式
ENAT模式(enhence NAT)。ENAT模式在内部也会被称为 三角模式或者DNAT/SNAT模式。
原理
- client发出请求(cip,vip)
- 请求包到达lvs,lvs修改请求包为(vip,rip),并将cip放入TCP Option中
- 请求包根据ip路由到达rs, ctk模块读取TCP Option中的cip
- 回复包(RIP, vip)被ctk模块截获,并将回复包改写为(vip, cip)
- 因为回复包的目的地址是cip所以不需要经过lvs,可以直接发给client
优点
- 不要求LVS和RS在同一个vlan
- 出去的流量不需要走LVS,性能好
缺点
- 集团实现的自定义方案,需要在所有RS上安装ctk组件(类似full NAT中的toa)
分析
- 为什么ENAT的回复包不需要走回LVS了?
因为full NAT模式下要走回去是需要LVS再次改写回复包的IP,而ENAT模式下,该事情在RS上被ctk模块提前做掉。
- 为什么ENAT的LVS和RS可以在不同的vlan?
跟full NAT一样。
ENAT结构
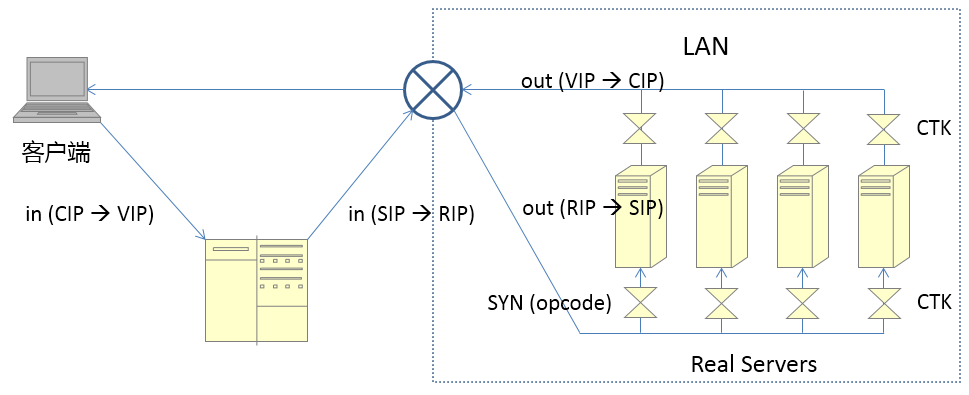
调度算法
静态调度算法
只根据算法进行调度 而不考虑后端服务器的实际连接情况和负载情况。
-
RR:轮叫调度(Round Robin) 调度器通过”轮叫”调度算法将外部请求按顺序轮流分配到集群中的真实服务器上,它均等地对待每一台服务器,而不管服务器上实际的连接数和系统负载。
-
WRR:加权轮叫(Weight RR) 调度器通过“加权轮叫”调度算法根据真实服务器的不同处理能力来调度访问请求。这样可以保证处理能力强的服务器处理更多的访问流量。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
-
DH:目标地址散列调度(Destination Hash ) 根据请求的目标IP地址,作为散列键(HashKey)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
-
SH:源地址 hash(Source Hash) 源地址散列”调度算法根据请求的源IP地址,作为散列键(HashKey)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
动态调度算法
-
LC:最少链接(Least Connections) 调度器通过”最少连接”调度算法动态地将网络请求调度到已建立的链接数最少的服务器上。如果集群系统的真实服务器具有相近的系统性能,采用”最小连接”调度算法可以较好地均衡负载。
-
WLC:加权最少连接(默认)(Weighted Least Connections) 在集群系统中的服务器性能差异较大的情况下,调度器采用“加权最少链接”调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
-
SED:最短延迟调度(Shortest Expected Delay ) 在WLC基础上改进,Overhead = (ACTIVE+1)*256/加权,不再考虑非活动状态,把当前处于活动状态的数目+1来实现,数目最小的,接受下次请求,+1的目的是为了考虑加权的时候,非活动连接过多缺陷:当权限过大的时候,会倒置空闲服务器一直处于无连接状态。
-
NQ永不排队/最少队列调度(Never Queue Scheduling NQ) 无需队列。如果有台 realserver的连接数=0就直接分配过去,不需要再进行sed运算,保证不会有一个主机很空间。在SED基础上无论+几,第二次一定给下一个,保证不会有一个主机不会很空闲着,不考虑非活动连接,才用NQ,SED要考虑活动状态连接,对于DNS的UDP不需要考虑非活动连接,而httpd的处于保持状态的服务就需要考虑非活动连接给服务器的压力。
-
LBLC:基于局部性的最少链接(locality-Based Least Connections) 基于局部性的最少链接”调度算法是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用“最少链接”的原则选出一个可用的服务器,将请求发送到该服务器。
-
LBLCR:带复制的基于局部性最少连接(Locality-Based Least Connections with Replication) 带复制的基于局部性最少链接”调度算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务器组,按”最小连接”原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按“最小连接”原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
常见问题分析
脑裂
由于两台高可用服务器对之间,在指定时间内,无法相互检测到对方的心跳,而各自启动故障切换转移功能,取得资源服务及所有权,而此时的两台高可用服务器对都还或者,并且正在运行,这样就会导致同一个IP或服务在两段同时启动而发生冲突的严重问题,最严重的是两台主机占用同一个VIP,当用户写入数据的时候可能同时写在两台服务器上。 1)产生裂脑原因
- 心跳链路故障,导致无法通信
- 开启防火墙阻挡心跳消息传输
- 心跳网卡地址配置等不正确
- 其他:心跳方式不同,心跳广播冲突,软件bug等1234
备注:
- 心跳线坏了(故障或老化)
- 网卡相关驱动坏了,IP配置即冲突问题(直连)
- 心跳线间连接的设备故障(网卡及交换机)
- 仲裁机器出问题
2)防止裂脑的方法
- 采用串行或以太网电缆连接,同时用两条心跳线路
- 做好裂脑的监控报警,在问题发生时人为第一时间介入仲裁
- 启用磁盘锁,即正在服务的一方只在发现心跳线全部断开时,才开启磁盘锁
- fence设备(智能电源管理设备)
- 增加仲裁盘
- 加冗余线路
负载不均
原因分析
- lvs自身的会话保持参数设置。优化:使用cookie代替session
- lvs调度算法设置,例如rr、wrr
- 后端RS节点的会话保持参数,例如apache的keepalive参数
- 访问量较少的情况下,不均衡的现象更加明显
- 用户发送的请求时间长短和请求资源多少以及大小
排错
先检查客户端到服务端——>然后检查负载均衡到RS端——>最后检查客户端到LVS端。
- 调度器上lvs调度规则及IP正确性
- RS节点上VIP和ARP抑制的检查
生成思路
- 对绑定的VIP做实时监控,出问题报警或自动处理后报警
- 把绑定的VIP做成配置文件,例如: vim /etc/sysconfig/network-scripts/lo:0
ARP抑制的配置思路
- 如果是单个VIP,那么可以用stop传参设置0
- 如果RS端有多个VIP绑定,此时,即使是停止VIP绑定也不一定不要置0.
- RS节点上自身提供服务的检查
- 辅助排除工具有tcpdump、ping等
- 负载均衡和反向代理三角形排查理论
Keepalived
Keepalived是一个免费开源的,用C编写的类似于layer3, 4 & 7交换机制软件,具备我们平时说的第3层、第4层和第7层交换机的功能。主要提供loadbalancing(负载均衡)和 high-availability(高可用)功能,负载均衡实现需要依赖Linux的虚拟服务内核模块(ipvs),而高可用是通过VRRP协议实现多台机器之间的故障转移服务。
功能体系
Keepalived的所有功能是配置keepalived.conf文件来实现的。上图是Keepalived的功能体系结构,大致分两层:
-
内核空间(kernel space)
主要包括IPVS(IP虚拟服务器,用于实现网络服务的负载均衡)和NETLINK(提供高级路由及其他相关的网络功能)两个部份。
-
用户空间(user space)
- WatchDog:负载监控checkers和VRRP进程的状况
- VRRP Stack:负载负载均衡器之间的失败切换FailOver,如果只用一个负载均稀器,则VRRP不是必须的
- Checkers:负责真实服务器的健康检查healthchecking,是keepalived最主要的功能。换言之,可以没有VRRP Stack,但健康检查healthchecking是一定要有的
- IPVS wrapper:用户发送设定的规则到内核ipvs代码
- Netlink Reflector:用来设定vrrp的vip地址等
重要功能
- 管理LVS负载均衡软件
- 实现LVS集群节点的健康检查中
- 作为系统网络服务的高可用性(failover)
高可用故障切换转移原理
Keepalived高可用服务对之间的故障切换转移,是通过 VRRP (Virtual Router Redundancy Protocol ,虚拟路由器冗余协议)来实现的。
在 Keepalived服务正常工作时,主 Master节点会不断地向备节点发送(多播的方式)心跳消息,用以告诉备Backup节点自己还活看,当主 Master节点发生故障时,就无法发送心跳消息,备节点也就因此无法继续检测到来自主 Master节点的心跳了,于是调用自身的接管程序,接管主Master节点的 IP资源及服务。而当主 Master节点恢复时,备Backup节点又会释放主节点故障时自身接管的IP资源及服务,恢复到原来的备用角色。
VRRP
全称Virtual Router Redundancy Protocol ,中文名为虚拟路由冗余协议 ,VRRP的出现就是为了解决静态踣甶的单点故障问题,VRRP是通过一种竞选机制来将路由的任务交给某台VRRP路由器的。
脑裂问题
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
对付HA系统“裂脑”的对策,目前达成共识的的大概有以下几条:
- 添加冗余的心跳线,例如:双线条线(心跳线也HA),尽量减少“裂脑”发生几率
- 启用磁盘锁。正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了
- 设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅“心跳”、还兼对外“服务”的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源
产生原因
一般来说,裂脑的发生,有以下几种原因:
- 高可用服务器对之间心跳线链路发生故障,导致无法正常通信
- 因心跳线坏了(包括断了,老化)
- 因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)
- 因心跳线间连接的设备故障(网卡及交换机)
- 因仲裁的机器出问题(采用仲裁的方案)
- 高可用服务器上开启了 iptables防火墙阻挡了心跳消息传输
- 高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
- 其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等
提示: Keepalived配置里同一 VRRP实例如果 virtual_router_id两端参数配置不一致也会导致裂脑问题发生。
解决方案
在实际生产环境中,我们可以从以下几个方面来防止裂脑问题的发生:
- 同时使用串行电缆和以太网电缆连接,同时用两条心跳线路,这样一条线路坏了,另一个还是好的,依然能传送心跳消息
- 当检测到裂脑时强行关闭一个心跳节点(这个功能需特殊设备支持,如Stonith、feyce)。相当于备节点接收不到心跳消患,通过单独的线路发送关机命令关闭主节点的电源
- 做好对裂脑的监控报警(如邮件及手机短信等或值班).在问题发生时人为第一时间介入仲裁,降低损失。例如,百度的监控报警短倍就有上行和下行的区别。报警消息发送到管理员手机上,管理员可以通过手机回复对应数字或简单的字符串操作返回给服务器.让服务器根据指令自动处理相应故障,这样解决故障的时间更短.
在实施高可用方案时,要根据业务实际需求确定是否能容忍这样的损失。对于一般的网站常规业务,这个损失是可容忍的。
安装部署
第一步:keepalived软件安装
yum install keepalived -y
/etc/keepalived
/etc/keepalived/keepalived.conf #keepalived服务主配置文件
/etc/rc.d/init.d/keepalived #服务启动脚本
/etc/sysconfig/keepalived
/usr/bin/genhash
/usr/libexec/keepalived
/usr/sbin/keepalived
第二步:配置文件说明
全局配置
global_defs { # 全局配置
notification_email { # 定义报警邮件地址
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc # 定义发送邮件的地址
smtp_server 192.168.200.1 # 邮箱服务器
smtp_connect_timeout 30 # 定义超时时间
router_id LVS_DEVEL # 定义路由标识信息,相同局域网唯一
}
虚拟ip配置brrp
vrrp_instance VI_1 { # 定义实例
state MASTER # 状态参数 master/backup 只是说明
interface eth0 # 虚IP地址放置的网卡位置
virtual_router_id 51 # 同一家族要一直,同一个集群id一致
priority 100 # 优先级决定是主还是备 越大越优先
advert_int 1 # 主备通讯时间间隔
authentication {
auth_type PASS
auth_pass 1111 # 认证
}
virtual_ipaddress {
192.168.200.16 # 设备之间使用的虚拟ip地址
192.168.200.17
192.168.200.18
}
}
第三步:最终配置文件
主负载均衡服务器配置
[root@lb01 conf]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb01
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
备负载均衡服务器配置
[root@lb02 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb02
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
第四步:启动keepalived
[root@lb02 ~]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
第五步:在进行访问测试之前要保证后端的节点都能够单独的访问
测试连通性. 后端节点
[root@lb01 conf]# curl -H host:www.etiantian.org 10.0.0.8
web01 www
[root@lb01 conf]# curl -H host:www.etiantian.org 10.0.0.7
web02 www
[root@lb01 conf]# curl -H host:www.etiantian.org 10.0.0.9
web03 www
[root@lb01 conf]# curl -H host:bbs.etiantian.org 10.0.0.9
web03 bbs
[root@lb01 conf]# curl -H host:bbs.etiantian.org 10.0.0.8
web01 bbs
[root@lb01 conf]# curl -H host:bbs.etiantian.org 10.0.0.7
web02 bbs
第六步:查看虚拟ip状态
[root@lb01 conf]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:90:7f:0d brd ff:ff:ff:ff:ff:ff
inet 10.0.0.5/24 brd 10.0.0.255 scope global eth0
inet 10.0.0.3/24 scope global secondary eth0:1
inet6 fe80::20c:29ff:fe90:7f0d/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:90:7f:17 brd ff:ff:ff:ff:ff:ff
inet 172.16.1.5/24 brd 172.16.1.255 scope global eth1
inet6 fe80::20c:29ff:fe90:7f17/64 scope link
valid_lft forever preferred_lft forever
第七步:【总结】配置文件修改
Keepalived主备配置文件区别:
- router_id 信息不一致
- state 状态描述信息不一致
- priority 主备竞选优先级数值不一致
HAProxy
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代 理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上。
四层负载均衡
所谓的四层就是ISO参考模型中的第四层。四层负载均衡也称为四层交换机,它主要是通过分析IP层及TCP/UDP层的流量实现的基于IP加端口的负载均衡。常见的基于四层的负载均衡器有LVS、F5等。
以常见的TCP应用为例,负载均衡器在接收到第一个来自客户端的SYN请求时,会通过设定的负载均衡算法选择一个最佳的后端服务器,同时将报文中目标IP地址修改为后端服务器IP,然后直接转发给该后端服务器,这样一个负载均衡请求就完成了。从这个过程来看,一个TCP连接是客户端和服务器直接建立的,而负载均衡器只不过完成了一个类似路由器的转发动作。在某些负载均衡策略中,为保证后端服务器返回的报文可以正确传递给负载均衡器,在转发报文的同时可能还会对报文原来的源地址进行修改。
七层负载均衡
七层负载均衡器也称为七层交换机,位于OSI的最高层,即应用层,此时负载均衡器支持多种应用协议,常见的有HTTP、FTP、SMTP等。七层负载均衡器可以根据报文内容,再配合负载均衡算法来选择后端服务器,因此也称为“内容交换器”。比如,对于Web服务器的负载均衡,七层负载均衡器不但可以根据“IP+端口”的方式进行负载分流,还可以根据网站的URL、访问域名、浏览器类别、语言等决定负载均衡的策略。例如,有两台Web服务器分别对应中英文两个网站,两个域名分别是A、B,要实现访问A域名时进入中文网站,访问B域名时进入英文网站,这在四层负载均衡器中几乎是无法实现的,而七层负载均衡可以根据客户端访问域名的不同选择对应的网页进行负载均衡处理。常见的七层负载均衡器有HAproxy、Nginx等。
这里仍以常见的TCP应用为例,由于负载均衡器要获取到报文的内容,因此只能先代替后端服务器和客户端建立连接,接着,才能收到客户端发送过来的报文内容,然后再根据该报文中特定字段加上负载均衡器中设置的负载均衡算法来决定最终选择的内部服务器。纵观整个过程,七层负载均衡器在这种情况下类似于一个代理服务器。整个过程如下图所示。
四层和七层负载均衡
对比四层负载均衡和七层负载均衡运行的整个过程,可以看出,在七层负载均衡模式下,负载均衡器与客户端及后端的服务器会分别建立一次TCP连接,而在四层负载均衡模式下,仅建立一次TCP连接。由此可知,七层负载均衡对负载均衡设备的要求更高,而七层负载均衡的处理能力也必然低于四层模式的负载均衡。
负载均衡策略
- roundrobin:表示简单的轮询
- static-rr:表示根据权重
- leastconn:表示最少连接者先处理
- source:表示根据请求的源IP,类似Nginx的IP_hash机制
- uri:表示根据请求的URI
- url_param:表示根据HTTP请求头来锁定每一次HTTP请求
- rdp-cookie(name):表示根据据cookie(name)来锁定并哈希每一次TCP请求
常用的负载均衡算法
- 轮询算法:roundrobin
- 根据请求源IP算法:source
- 最少连接者先处理算法:lestconn
HAProxy与LVS的区别
HAProxy负载均衡与LVS负载均衡的区别:
- 两者都是软件负载均衡产品,但是LVS是基于Linux操作系统实现的一种软负载均衡,而HAProxy是基于第三应用实现的软负载均衡
- LVS是基于四层的IP负载均衡技术,而HAProxy是基于四层和七层技术、可提供TCP和HTTP应用的负载均衡综合解决方案
- LVS工作在ISO模型的第四层,因此其状态监测功能单一,而HAProxy在状态监测方面功能强大,可支持端口、URL、脚本等多种状态检测方式
- HAProxy虽然功能强大,但是整体处理性能低于四层模式的LVS负载均衡,而LVS拥有接近硬件设备的网络吞吐和连接负载能力
综上所述,HAProxy和LVS各有优缺点,没有好坏之分,要选择哪个作为负载均衡器,要以实际的应用环境来决定。
安装配置
第一步:安装依赖
[root@test ~] # yum -y install make gcc gcc-c++ openssl-devel
第二步:安装haproxy
[root@test ~] # wget http://haproxy.1wt.eu/download/1.3/src/haproxy-1.3.20.tar.gz
[root@test ~] # tar zcvf haproxy-1.3.20.tar.gz
[root@test ~] # cd haproxy-1.3.20
[root@test ~] # make TARGET=linux26 PREFIX=/usr/local/haproxy # 将haproxy安装到/usr/local/haproxy
[root@test ~] # make install PREFIX=/usr/local/haproxy