13 KiB
Tecniche di Machine Learning
Il processo di creazione, utilizzo e mantenimento dei modelli di machine learning e dei dati che utilizzano è un processo molto diverso da molti altri flussi di lavoro di sviluppo. In questa lezione si demistifica il processo, e si delineano le principali tecniche che occorre conoscere. Si dovrà:
- Comprendere i processi ad alto livello alla base di machine learning.
- Esplorare concetti di base come "modelli", "previsioni" e "dati di addestramento".
Quiz Pre-Lezione
Introduzione
Ad alto livello, il mestiere di creare processi di apprendimento automatico (ML) comprende una serie di passaggi:
- Decidere circa la domanda. La maggior parte dei processi ML inizia ponendo una domanda alla quale non è possibile ottenere risposta da un semplice programma condizionale o da un motore basato su regole. Queste domande spesso ruotano attorno a previsioni basate su una raccolta di dati.
- Raccogliere e preparare i dati. Per poter rispondere alla domanda, servono dati. La qualità e, a volte, la quantità dei dati determineranno quanto bene sarà possibile rispondere alla domanda iniziale. La visualizzazione dei dati è un aspetto importante di questa fase. Questa fase include anche la suddivisione dei dati in un gruppo di addestramento (training) e test per costruire un modello.
- Scegliere un metodo di addestramento. A seconda della domanda e della natura dei dati, è necessario scegliere come si desidera addestrare un modello per riflettere al meglio i dati e fare previsioni accurate su di essi. Questa è la parte del processo di ML che richiede competenze specifiche e, spesso, una notevole quantità di sperimentazione.
- Addestrare il modello. Usando i dati di addestramento, si utilizzeranno vari algoritmi per addestrare un modello a riconoscere modelli nei dati. Il modello potrebbe sfruttare pesi interni che possono essere regolati per privilegiare alcune parti dei dati rispetto ad altre per costruire un modello migliore.
- Valutare il modello. Si utilizzano dati mai visti prima (i dati di test) da quelli raccolti per osservare le prestazioni del modello.
- Regolazione dei parametri. In base alle prestazioni del modello, si può ripetere il processo utilizzando parametri differenti, o variabili, che controllano il comportamento degli algoritmi utilizzati per addestrare il modello.
- Prevedere. Usare nuovi input per testare la precisione del modello.
Che domanda fare
I computer sono particolarmente abili nello scoprire modelli nascosti nei dati. Questa caratteristica è molto utile per i ricercatori che hanno domande su un determinato campo a cui non è possibile rispondere facilmente creando un motore di regole basato su condizioni. Dato un compito attuariale, ad esempio, un data scientist potrebbe essere in grado di costruire manualmente regole sulla mortalità dei fumatori rispetto ai non fumatori.
Quando molte altre variabili vengono introdotte nell'equazione, tuttavia, un modello ML potrebbe rivelarsi più efficiente per prevedere i tassi di mortalità futuri in base alla storia sanitaria passata. Un esempio più allegro potrebbe essere fare previsioni meteorologiche per il mese di aprile in una determinata località sulla base di dati che includono latitudine, longitudine, cambiamento climatico, vicinanza all'oceano, modelli della corrente a getto e altro ancora.
✅ Questa presentazione sui modelli meteorologici offre una prospettiva storica per l'utilizzo di ML nell'analisi meteorologica.
Attività di pre-costruzione
Prima di iniziare a costruire il proprio modello, ci sono diverse attività da completare. Per testare la domanda e formare un'ipotesi basata sulle previsioni di un modello, occorre identificare e configurare diversi elementi.
Dati
Per poter rispondere con sicurezza alla domanda, serve una buona quantità di dati del tipo giusto. Ci sono due cose da fare a questo punto:
- Raccogliere dati. Tenendo presente la lezione precedente sull'equità nell'analisi dei dati, si raccolgano i dati con cura. Ci sia consapevolezza delle fonti di questi dati, di eventuali pregiudizi intrinseci che potrebbero avere e si documenti la loro origine.
- Preparare i dati. Ci sono diversi passaggi nel processo di preparazione dei dati. Potrebbe essere necessario raccogliere i dati e normalizzarli se provengono da fonti diverse. Si può migliorare la qualità e la quantità dei dati attraverso vari metodi come la conversione di stringhe in numeri (come si fa in Clustering). Si potrebbero anche generare nuovi dati, basati sull'originale (come si fa in Classificazione). Si possono pulire e modificare i dati (come verrà fatto prima della lezione sull'app Web ). Infine, si potrebbe anche aver bisogno di renderli casuali e mescolarli, a seconda delle proprie tecniche di addestramento.
✅ Dopo aver raccolto ed elaborato i propri dati, si prenda un momento per vedere se la loro forma consentirà di rispondere alla domanda prevista. Potrebbe essere che i dati non funzionino bene nello svolgere il compito assegnato, come si scopre nelle lezioni di Clustering!
Caratteristiche e destinazione
Una funzionalità è una proprietà misurabile dei dati. In molti set di dati è espresso come intestazione di colonna come 'date' 'size' o 'color'. La variabile di funzionalità, solitamente rappresentata come X nel codice, rappresenta la variabile di input che verrà utilizzata per il training del modello.
Un obiettivo è una cosa che stai cercando di prevedere. Target solitamente rappresentato come y nel codice, rappresenta la risposta alla domanda che stai cercando di porre dei tuoi dati: a dicembre, di che colore saranno le zucche più economiche? a San Francisco, quali quartieri avranno il miglior prezzo immobiliare? A volte la destinazione viene anche definita attributo label.
Selezione della variabile caratteristica
🎓 Selezione ed estrazione della caratteristica Come si fa a sapere quale variabile scegliere quando si costruisce un modello? Probabilmente si dovrà passare attraverso un processo di selezione o estrazione delle caratteristiche per scegliere le variabili giuste per il modello più efficace. Tuttavia, non è la stessa cosa: "L'estrazione delle caratteristiche crea nuove caratteristiche dalle funzioni delle caratteristiche originali, mentre la selezione delle caratteristiche restituisce un sottoinsieme delle caratteristiche". (fonte)
Visualizzare i dati
Un aspetto importante del bagaglio del data scientist è la capacità di visualizzare i dati utilizzando diverse eccellenti librerie come Seaborn o MatPlotLib. Rappresentare visivamente i propri dati potrebbe consentire di scoprire correlazioni nascoste che si possono sfruttare. Le visualizzazioni potrebbero anche aiutare a scoprire pregiudizi o dati sbilanciati (come si scopre in Classificazione).
Dividere l'insieme di dati
Prima dell'addestramento, è necessario dividere l'insieme di dati in due o più parti di dimensioni diverse che rappresentano comunque bene i dati.
- Addestramento. Questa parte dell'insieme di dati è adatta al proprio modello per addestrarlo. Questo insieme costituisce la maggior parte dell'insieme di dati originale.
- Test. Un insieme di dati di test è un gruppo indipendente di dati, spesso raccolti dai dati originali, che si utilizzano per confermare le prestazioni del modello creato.
- Convalida. Un insieme di convalida è un gruppo indipendente più piccolo di esempi da usare per ottimizzare gli iperparametri, o architettura, del modello per migliorarlo. A seconda delle dimensioni dei propri dati e della domanda che si sta ponendo, si potrebbe non aver bisogno di creare questo terzo insieme (come si nota in Previsione delle Serie Temporali).
Costruire un modello
Utilizzando i dati di addestramento, l'obiettivo è costruire un modello o una rappresentazione statistica dei propri dati, utilizzando vari algoritmi per addestrarlo . L'addestramento di un modello lo espone ai dati e consente di formulare ipotesi sui modelli percepiti che scopre, convalida e accetta o rifiuta.
Decidere un metodo di addestramento
A seconda della domanda e della natura dei dati, si sceglierà un metodo per addestrarlo. Passando attraverso la documentazione di Scikit-learn, che si usa in questo corso, si possono esplorare molti modi per addestrare un modello. A seconda della propria esperienza, si potrebbe dover provare diversi metodi per creare il modello migliore. È probabile che si attraversi un processo in cui i data scientist valutano le prestazioni di un modello fornendogli dati non visti, verificandone l'accuratezza, i pregiudizi e altri problemi che degradano la qualità e selezionando il metodo di addestramento più appropriato per l'attività da svolgere.
Allenare un modello
Armati dei tuoi dati di allenamento, sei pronto a "adattarlo" per creare un modello. Noterai che in molte librerie ML troverai il codice "model.fit" - è in questo momento che invii la tua variabile di funzionalità come matrice di valori (in genere X) e una variabile di destinazione (di solito y).
Valutare il modello
Una volta completato il processo di addestramento (potrebbero essere necessarie molte iterazioni, o "epoche", per addestrare un modello di grandi dimensioni), si sarà in grado di valutare la qualità del modello utilizzando i dati di test per valutarne le prestazioni. Questi dati sono un sottoinsieme dei dati originali che il modello non ha analizzato in precedenza. Si può stampare una tabella di metriche sulla qualità del proprio modello.
🎓 Adattamento del modello
Nel contesto di machine learning, l'adattamento del modello si riferisce all'accuratezza della funzione sottostante del modello mentre tenta di analizzare dati con cui non ha familiarità.
🎓 Inadeguatezza o sovraadattamento sono problemi comuni che degradano la qualità del modello, poiché il modello non si adatta abbastanza bene o troppo bene. Ciò fa sì che il modello esegua previsioni troppo allineate o troppo poco allineate con i suoi dati di addestramento. Un modello overfit (sovraaddestrato) prevede troppo bene i dati di addestramento perché ha appreso troppo bene i dettagli e il rumore dei dati. Un modello underfit (inadeguato) non è accurato in quanto non può né analizzare accuratamente i suoi dati di allenamento né i dati che non ha ancora "visto".
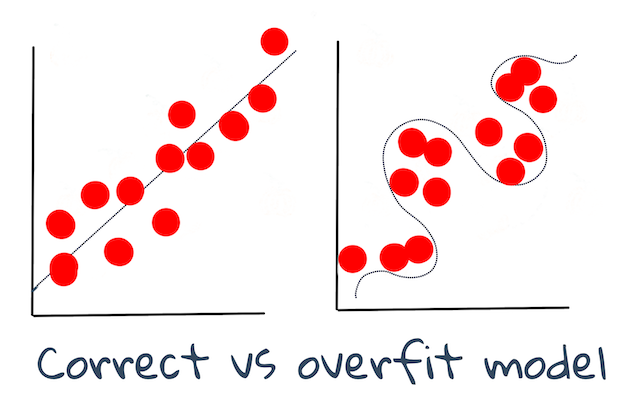
Infografica di Jen Looper
Sintonia dei parametri
Una volta completato l'addestramento iniziale, si osservi la qualità del modello e si valuti di migliorarlo modificando i suoi "iperparametri". Maggiori informazioni sul processo nella documentazione.
Previsione
Questo è il momento in cui si possono utilizzare dati completamente nuovi per testare l'accuratezza del proprio modello. In un'impostazione ML "applicata", in cui si creano risorse Web per utilizzare il modello in produzione, questo processo potrebbe comportare la raccolta dell'input dell'utente (ad esempio, la pressione di un pulsante) per impostare una variabile e inviarla al modello per l'inferenza, oppure valutazione.
In queste lezioni si scoprirà come utilizzare questi passaggi per preparare, costruire, testare, valutare e prevedere - tutti gesti di un data scientist e altro ancora, mentre si avanza nel proprio viaggio per diventare un ingegnere ML "full stack".
🚀 Sfida
Disegnare un diagramma di flusso che rifletta i passaggi di un professionista di ML. Dove ci si vede in questo momento nel processo? Dove si prevede che sorgeranno difficoltà? Cosa sembra facile?
Quiz post-lezione
Revisione e Auto Apprendimento
Cercare online le interviste con i data scientist che discutono del loro lavoro quotidiano. Eccone una.