24 KiB
Introduzione al clustering
Il clustering è un tipo di apprendimento non supervisionato che presuppone che un insieme di dati non sia etichettato o che i suoi input non siano abbinati a output predefiniti. Utilizza vari algoritmi per ordinare i dati non etichettati e fornire raggruppamenti in base ai modelli che individua nei dati.

🎥 Fare clic sull'immagine sopra per un video. Mentre si studia machine learning con il clustering, si potranno gradire brani della Nigerian Dance Hall: questa è una canzone molto apprezzata del 2014 di PSquare.
Quiz Pre-Lezione
Introduzione
Il clustering è molto utile per l'esplorazione dei dati. Si vedrà se può aiutare a scoprire tendenze e modelli nel modo in cui il pubblico nigeriano consuma la musica.
✅ Ci si prenda un minuto per pensare agli usi del clustering. Nella vita reale, il clustering si verifica ogni volta che si ha una pila di biancheria e si devono sistemare i vestiti dei propri familiari 🧦👕👖🩲. Nella scienza dei dati, il clustering si verifica quando si tenta di analizzare le preferenze di un utente o di determinare le caratteristiche di qualsiasi insieme di dati senza etichetta. Il clustering, in un certo senso, aiuta a dare un senso al caos, come un cassetto dei calzini.

🎥 Fare clic sull'immagine sopra per un video: John Guttag del MIT introduce il clustering
In un ambiente professionale, il clustering può essere utilizzato per determinare cose come la segmentazione del mercato, determinare quali fasce d'età acquistano quali articoli, ad esempio. Un altro uso sarebbe il rilevamento di anomalie, forse per rilevare le frodi da un insieme di dati delle transazioni con carta di credito. Oppure si potrebbe usare il clustering per determinare i tumori in una serie di scansioni mediche.
✅ Si pensi un minuto a come si potrebbe aver incontrato il clustering 'nel mondo reale', in un ambiente bancario, e-commerce o aziendale.
🎓 È interessante notare che l'analisi dei cluster ha avuto origine nei campi dell'antropologia e della psicologia negli anni '30. Si riusce a immaginare come potrebbe essere stato utilizzato?
In alternativa, lo si può utilizzare per raggruppare i risultati di ricerca, ad esempio tramite link per acquisti, immagini o recensioni. Il clustering è utile quando si dispone di un insieme di dati di grandi dimensioni che si desidera ridurre e sul quale si desidera eseguire un'analisi più granulare, quindi la tecnica può essere utilizzata per conoscere i dati prima che vengano costruiti altri modelli.
✅ Una volta che i dati sono organizzati in cluster, viene assegnato un ID cluster e questa tecnica può essere utile quando si preserva la privacy di un insieme di dati; si può invece fare riferimento a un punto dati tramite il suo ID cluster, piuttosto che dati identificabili più rivelatori. Si riesce a pensare ad altri motivi per cui fare riferimento a un ID cluster piuttosto che ad altri elementi del cluster per identificarlo?
In questo modulo di apprendimento si approfondirà la propria comprensione delle tecniche di clustering
Iniziare con il clustering
Scikit-learn offre una vasta gamma di metodi per eseguire il clustering. Il tipo scelto dipenderà dal caso d'uso. Secondo la documentazione, ogni metodo ha diversi vantaggi. Ecco una tabella semplificata dei metodi supportati da Scikit-learn e dei loro casi d'uso appropriati:
| Nome del metodo | Caso d'uso |
|---|---|
| K-MEANS | uso generale, induttivo |
| Affinity propagation (Propagazione dell'affinità) | molti, cluster irregolari, induttivo |
| Mean-shift (Spostamento medio) | molti, cluster irregolari, induttivo |
| Spectral clustering (Raggruppamento spettrale) | pochi, anche grappoli, trasduttivi |
| Ward hierarchical clustering (Cluster gerarchico) | molti, cluster vincolati, trasduttivi |
| Agglomerative clustering (Raggruppamento agglomerativo) | molte, vincolate, distanze non euclidee, trasduttive |
| DBSCAN | geometria non piatta, cluster irregolari, trasduttivo |
| OPTICS | geometria non piatta, cluster irregolari con densità variabile, trasduttivo |
| Gaussian mixtures (miscele gaussiane) | geometria piana, induttiva |
| BIRCH | insiemi di dati di grandi dimensioni con valori anomali, induttivo |
🎓 Il modo in cui si creno i cluster ha molto a che fare con il modo in cui si raccolgono punti dati in gruppi. Si esamina un po' di vocabolario:
🎓 'trasduttivo' vs. 'induttivo'
L'inferenza trasduttiva è derivata da casi di addestramento osservati che mappano casi di test specifici. L'inferenza induttiva è derivata da casi di addestramento che mappano regole generali che vengono poi applicate ai casi di test.
Un esempio: si immagini di avere un insieme di dati che è solo parzialmente etichettato. Alcune cose sono "dischi", alcune "cd" e altre sono vuote. Il compito è fornire etichette per gli spazi vuoti. Se si scegliesse un approccio induttivo, si addestrerebbe un modello alla ricerca di "dischi" e "cd" e si applicherebbero quelle etichette ai dati non etichettati. Questo approccio avrà problemi a classificare cose che sono in realtà "cassette". Un approccio trasduttivo, d'altra parte, gestisce questi dati sconosciuti in modo più efficace poiché funziona raggruppando elementi simili e quindi applica un'etichetta a un gruppo. In questo caso, i cluster potrebbero riflettere "cose musicali rotonde" e "cose musicali quadrate".
🎓 Geometria 'non piatta' (non-flat) vs. 'piatta' (flat)
Derivato dalla terminologia matematica, la geometria non piatta rispetto a quella piatta si riferisce alla misura delle distanze tra i punti mediante metodi geometrici "piatti" (euclidei) o "non piatti" (non euclidei).
"Piatto" in questo contesto si riferisce alla geometria euclidea (parti della quale vengono insegnate come geometria "piana") e non piatto si riferisce alla geometria non euclidea. Cosa ha a che fare la geometria con machine learning? Bene, come due campi che sono radicati nella matematica, ci deve essere un modo comune per misurare le distanze tra i punti nei cluster, e questo può essere fatto in modo "piatto" o "non piatto", a seconda della natura dei dati . Le distanze euclidee sono misurate come la lunghezza di un segmento di linea tra due punti. Le distanze non euclidee sono misurate lungo una curva. Se i dati, visualizzati, sembrano non esistere su un piano, si potrebbe dover utilizzare un algoritmo specializzato per gestirli.
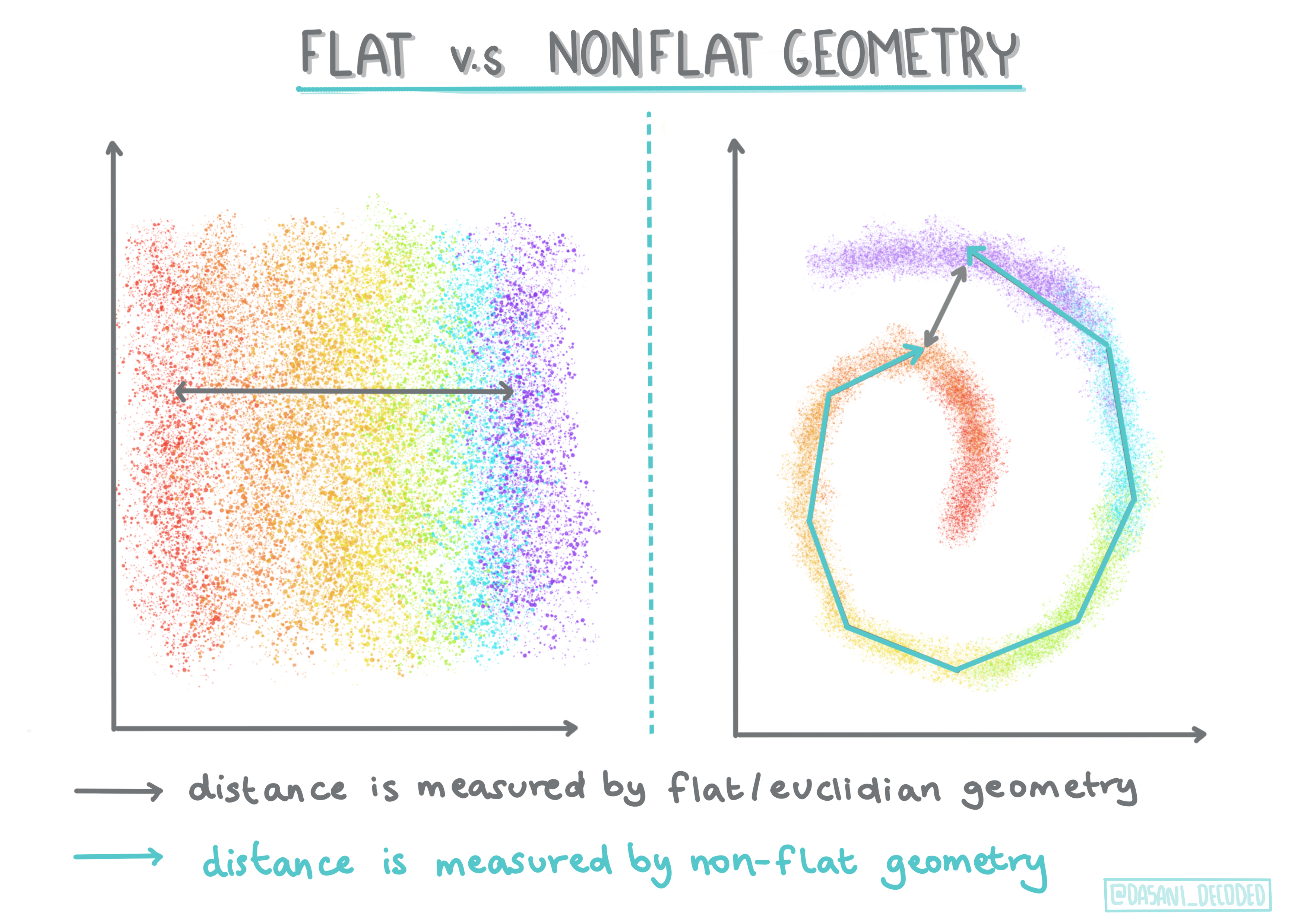
Infografica di Dasani Madipalli
I cluster sono definiti dalla loro matrice di distanza, ad esempio le distanze tra i punti. Questa distanza può essere misurata in alcuni modi. I cluster euclidei sono definiti dalla media dei valori dei punti e contengono un 'centroide' o baricentro. Le distanze sono quindi misurate dalla distanza da quel baricentro. Le distanze non euclidee si riferiscono a "clustroidi", il punto più vicino ad altri punti. I clustroidi a loro volta possono essere definiti in vari modi.
Constrained Clustering introduce l'apprendimento 'semi-supervisionato' in questo metodo non supervisionato. Le relazioni tra i punti sono contrassegnate come "non è possibile collegare" o "è necessario collegare", quindi alcune regole sono imposte sull'insieme di dati.
Un esempio: se un algoritmo viene applicato su un batch di dati non etichettati o semi-etichettati, i cluster che produce potrebbero essere di scarsa qualità. Nell'esempio sopra, i cluster potrebbero raggruppare "cose musicali rotonde" e "cose musicali quadrate" e "cose triangolari" e "biscotti". Se vengono dati dei vincoli, o delle regole da seguire ("l'oggetto deve essere di plastica", "l'oggetto deve essere in grado di produrre musica"), questo può aiutare a "vincolare" l'algoritmo a fare scelte migliori.
'Densità'
I dati "rumorosi" sono considerati "densi". Le distanze tra i punti in ciascuno dei suoi cluster possono rivelarsi, all'esame, più o meno dense, o "affollate" e quindi questi dati devono essere analizzati con il metodo di clustering appropriato. Questo articolo dimostra la differenza tra l'utilizzo del clustering K-Means rispetto agli algoritmi HDBSCAN per esplorare un insieme di dati rumoroso con densità di cluster non uniforme.
Algoritmi di clustering
Esistono oltre 100 algoritmi di clustering e il loro utilizzo dipende dalla natura dei dati a portata di mano. Si discutono alcuni dei principali:
-
Raggruppamento gerarchico. Se un oggetto viene classificato in base alla sua vicinanza a un oggetto vicino, piuttosto che a uno più lontano, i cluster vengono formati in base alla distanza dei loro membri da e verso altri oggetti. Il clustering agglomerativo di Scikit-learn è gerarchico.
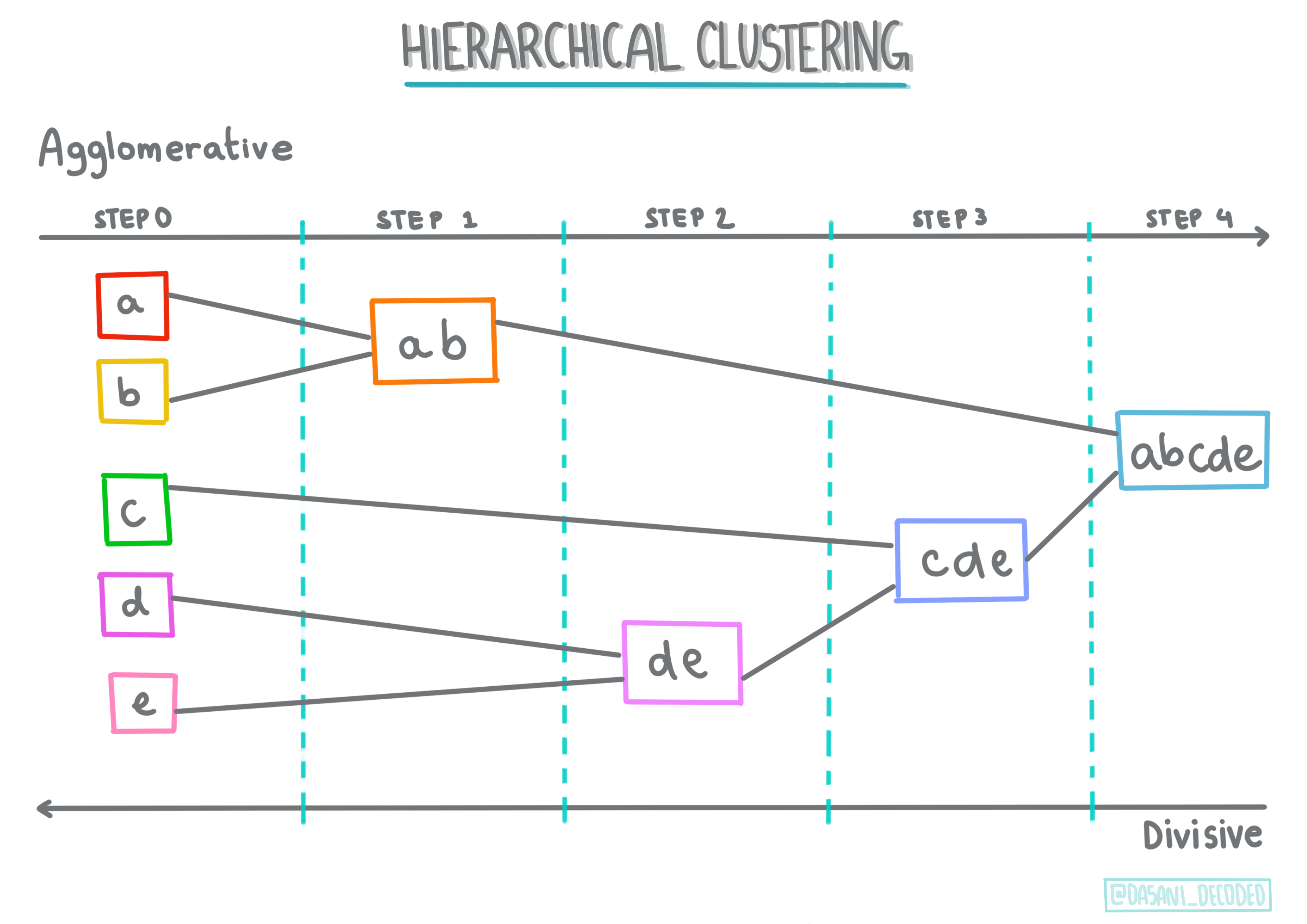
Infografica di Dasani Madipalli
-
Raggruppamento centroide. Questo popolare algoritmo richiede la scelta di 'k', o il numero di cluster da formare, dopodiché l'algoritmo determina il punto centrale di un cluster e raccoglie i dati attorno a quel punto. Il clustering K-means è una versione popolare del clustering centroide. Il centro è determinato dalla media più vicina, da qui il nome. La distanza al quadrato dal cluster è ridotta al minimo.
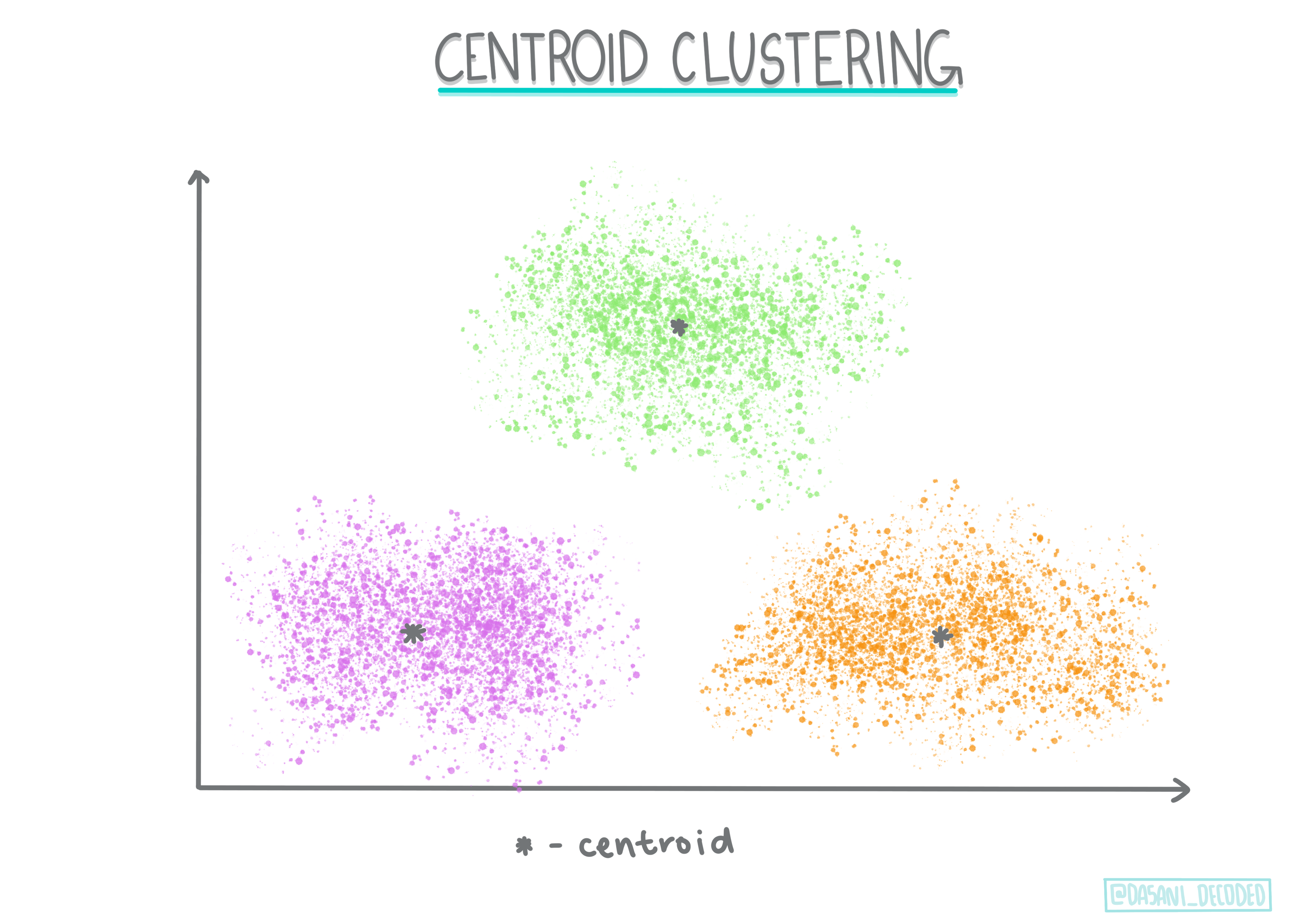
Infografica di Dasani Madipalli
-
Clustering basato sulla distribuzione. Basato sulla modellazione statistica, il clustering basato sulla distribuzione è incentrato sulla determinazione della probabilità che un punto dati appartenga a un cluster e sull'assegnazione di conseguenza. I metodi di miscelazione gaussiana appartengono a questo tipo.
-
Clustering basato sulla densità. I punti dati vengono assegnati ai cluster in base alla loro densità o al loro raggruppamento l'uno intorno all'altro. I punti dati lontani dal gruppo sono considerati valori anomali o rumore. DBSCAN, Mean-shift e OPTICS appartengono a questo tipo di clustering.
-
Clustering basato su griglia. Per gli insiemi di dati multidimensionali, viene creata una griglia e i dati vengono divisi tra le celle della griglia, creando così dei cluster.
Esercizio: raggruppare i dati
Il clustering come tecnica è notevolmente aiutato da una corretta visualizzazione, quindi si inizia visualizzando i dati musicali. Questo esercizio aiuterà a decidere quale dei metodi di clustering si dovranno utilizzare in modo più efficace per la natura di questi dati.
-
Aprire il file notebook.ipynb in questa cartella.
-
Importare il pacchetto
Seabornper una buona visualizzazione dei dati.!pip install seaborn -
Aggiungere i dati dei brani da nigerian-songs.csv. Caricare un dataframe con alcuni dati sulle canzoni. Prepararsi a esplorare questi dati importando le librerie e scaricando i dati:
import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv("../data/nigerian-songs.csv") df.head()Controllare le prime righe di dati:
name album artist artist_top_genre release_date length popularity danceability acousticness energy instrumentalness liveness loudness speechiness tempo time_signature 0 Sparky Mandy & The Jungle Cruel Santino alternative r&b 2019 144000 48 0.666 0.851 0.42 0.534 0.11 -6.699 0.0829 133.015 5 1 shuga rush EVERYTHING YOU HEARD IS TRUE Odunsi (The Engine) afropop 2020 89488 30 0.71 0.0822 0.683 0.000169 0.101 -5.64 0.36 129.993 3 2 LITT! LITT! AYLØ indie r&b 2018 207758 40 0.836 0.272 0.564 0.000537 0.11 -7.127 0.0424 130.005 4 3 Confident / Feeling Cool Enjoy Your Life Lady Donli nigerian pop 2019 175135 14 0.894 0.798 0.611 0.000187 0.0964 -4.961 0.113 111.087 4 4 wanted you rare. Odunsi (The Engine) afropop 2018 152049 25 0.702 0.116 0.833 0.91 0.348 -6.044 0.0447 105.115 4 -
Ottenere alcune informazioni sul dataframe, chiamando
info():df.info()Il risultato appare così:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 530 entries, 0 to 529 Data columns (total 16 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 name 530 non-null object 1 album 530 non-null object 2 artist 530 non-null object 3 artist_top_genre 530 non-null object 4 release_date 530 non-null int64 5 length 530 non-null int64 6 popularity 530 non-null int64 7 danceability 530 non-null float64 8 acousticness 530 non-null float64 9 energy 530 non-null float64 10 instrumentalness 530 non-null float64 11 liveness 530 non-null float64 12 loudness 530 non-null float64 13 speechiness 530 non-null float64 14 tempo 530 non-null float64 15 time_signature 530 non-null int64 dtypes: float64(8), int64(4), object(4) memory usage: 66.4+ KB -
Ricontrollare i valori null, chiamando
isnull()e verificando che la somma sia 0:df.isnull().sum()Si presenta bene!
name 0 album 0 artist 0 artist_top_genre 0 release_date 0 length 0 popularity 0 danceability 0 acousticness 0 energy 0 instrumentalness 0 liveness 0 loudness 0 speechiness 0 tempo 0 time_signature 0 dtype: int64 -
Descrivere i dati:
df.describe()release_date lenght popularity danceability acousticness Energia strumentale vitalità livello di percezione sonora parlato tempo #ora_firma estero) 530 530 530 530 530 530 530 530 530 530 530 530 mezzo 2015.390566 222298.1698 17.507547 0.741619 0.265412 0.760623 0,016305 0,147308 -4.953011 0,130748 116.487864 3.986792 std 3.131688 39696.82226 18.992212 0,117522 0.208342 0.148533 0.090321 0,123588 2.464186 0,092939 23.518601 0.333701 min 1998 89488 0 0,255 0,000665 0,111 0 0,0283 -19,362 0,0278 61.695 3 25% 2014 199305 0 0,681 0,089525 0,669 0 0,07565 -6.29875 0,0591 102.96125 4 50% 2016 218509 13 0,761 0.2205 0.7845 0.000004 0,1035 -4.5585 0,09795 112.7145 4 75% 2017 242098.5 31 0,8295 0.403 0.87575 0.000234 0,164 -3.331 0,177 125.03925 4 max 2020 511738 73 0.966 0,954 0,995 0,91 0,811 0,582 0.514 206.007 5
🤔 Se si sta lavorando con il clustering, un metodo non supervisionato che non richiede dati etichettati, perché si stanno mostrando questi dati con etichette? Nella fase di esplorazione dei dati, sono utili, ma non sono necessari per il funzionamento degli algoritmi di clustering. Si potrebbero anche rimuovere le intestazioni delle colonne e fare riferimento ai dati per numero di colonna.
Dare un'occhiata ai valori generali dei dati. Si nota che la popolarità può essere "0", che mostra i brani che non hanno una classifica. Quelli verranno rimossi a breve.
-
Usare un grafico a barre per scoprire i generi più popolari:
import seaborn as sns top = df['artist_top_genre'].value_counts() plt.figure(figsize=(10,7)) sns.barplot(x=top[:5].index,y=top[:5].values) plt.xticks(rotation=45) plt.title('Top genres',color = 'blue')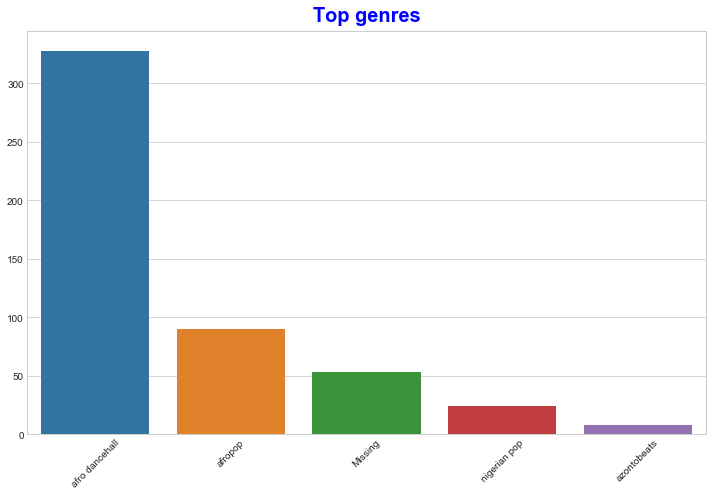
✅ Se si desidera vedere più valori superiori, modificare il valore di top [:5] con un valore più grande o rimuoverlo per vederli tutti.
Nota, quando un valore di top è descritto come "Missing", ciò significa che Spotify non lo ha classificato, quindi va rimosso.
-
Eliminare i dati mancanti escludendoli via filtro
df = df[df['artist_top_genre'] != 'Missing'] top = df['artist_top_genre'].value_counts() plt.figure(figsize=(10,7)) sns.barplot(x=top.index,y=top.values) plt.xticks(rotation=45) plt.title('Top genres',color = 'blue')Ora ricontrollare i generi:
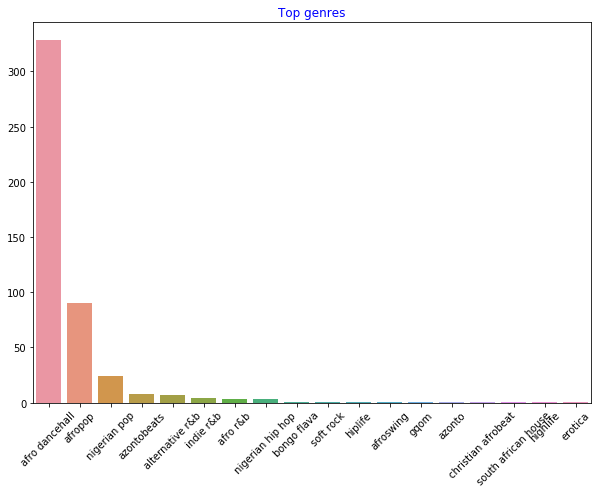
-
Di gran lunga, i primi tre generi dominano questo insieme di dati. Si pone l'attenzione su
afrodancehall,afropopenigerian pop, filtrando inoltre l'insieme di dati per rimuovere qualsiasi cosa con un valore di popolarità 0 (il che significa che non è stato classificato con una popolarità nell'insieme di dati e può essere considerato rumore per gli scopi attuali):df = df[(df['artist_top_genre'] == 'afro dancehall') | (df['artist_top_genre'] == 'afropop') | (df['artist_top_genre'] == 'nigerian pop')] df = df[(df['popularity'] > 0)] top = df['artist_top_genre'].value_counts() plt.figure(figsize=(10,7)) sns.barplot(x=top.index,y=top.values) plt.xticks(rotation=45) plt.title('Top genres',color = 'blue') -
Fare un test rapido per vedere se i dati sono correlati in modo particolarmente forte:
corrmat = df.corr() f, ax = plt.subplots(figsize=(12, 9)) sns.heatmap(corrmat, vmax=.8, square=True)
L'unica forte correlazione è tra
energyeloudness(volume), il che non è troppo sorprendente, dato che la musica ad alto volume di solito è piuttosto energica. Altrimenti, le correlazioni sono relativamente deboli. Sarà interessante vedere cosa può fare un algoritmo di clustering di questi dati.🎓 Notare che la correlazione non implica la causalità! Ci sono prove di correlazione ma nessuna prova di causalità. Un sito web divertente ha alcune immagini che enfatizzano questo punto.
C'è qualche convergenza in questo insieme di dati intorno alla popolarità e alla ballabilità percepite di una canzone? Una FacetGrid mostra che ci sono cerchi concentrici che si allineano, indipendentemente dal genere. Potrebbe essere che i gusti nigeriani convergano ad un certo livello di ballabilità per questo genere?
✅ Provare diversi punti dati (energy, loudness, speachiness) e più o diversi generi musicali. Cosa si può scoprire? Dare un'occhiata alla tabella con df.describe() per vedere la diffusione generale dei punti dati.
Esercizio - distribuzione dei dati
Questi tre generi sono significativamente differenti nella percezione della loro ballabilità, in base alla loro popolarità?
-
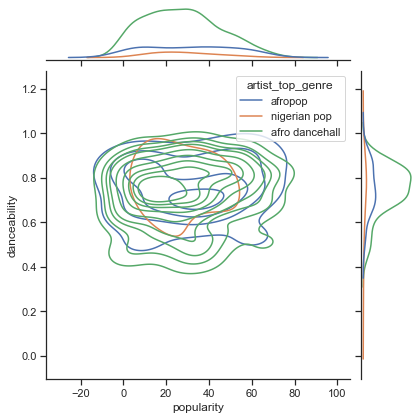
Esaminare la distribuzione dei dati sui tre principali generi per la popolarità e la ballabilità lungo un dato asse x e y.
sns.set_theme(style="ticks") g = sns.jointplot( data=df, x="popularity", y="danceability", hue="artist_top_genre", kind="kde", )Si possono scoprire cerchi concentrici attorno a un punto di convergenza generale, che mostra la distribuzione dei punti.
🎓 Si noti che questo esempio utilizza un grafico KDE (Kernel Density Estimate) che rappresenta i dati utilizzando una curva di densità di probabilità continua. Questo consente di interpretare i dati quando si lavora con più distribuzioni.
In generale, i tre generi si allineano liberamente in termini di popolarità e ballabilità. Determinare i cluster in questi dati vagamente allineati sarà una sfida:
-
Crea un grafico a dispersione:
sns.FacetGrid(df, hue="artist_top_genre", size=5) \ .map(plt.scatter, "popularity", "danceability") \ .add_legend()Un grafico a dispersione degli stessi assi mostra un modello di convergenza simile
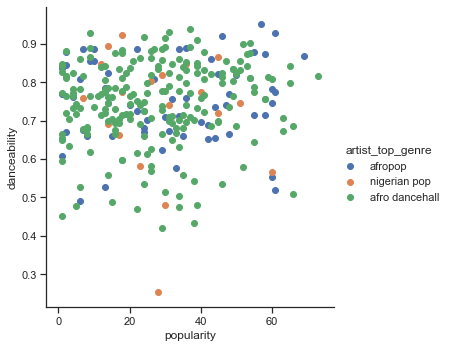
In generale, per il clustering è possibile utilizzare i grafici a dispersione per mostrare i cluster di dati, quindi è molto utile padroneggiare questo tipo di visualizzazione. Nella prossima lezione, si prenderanno questi dati filtrati e si utilizzerà il clustering k-means per scoprire gruppi in questi dati che si sovrappongono in modi interessanti.
🚀 Sfida
In preparazione per la lezione successiva, creare un grafico sui vari algoritmi di clustering che si potrebbero scoprire e utilizzare in un ambiente di produzione. Che tipo di problemi sta cercando di affrontare il clustering?
Quiz post-lezione
Revisione e Auto Apprendimento
Prima di applicare gli algoritmi di clustering, come si è appreso, è una buona idea comprendere la natura del proprio insieme di dati. Leggere di più su questo argomento qui
Questo utile articolo illustra i diversi modi in cui si comportano i vari algoritmi di clustering, date diverse forme di dati.