24 KiB
פוסטסקריפט: איתור שגיאות במודלים של למידת מכונה באמצעות רכיבי לוח מחוונים של AI אחראי
שאלון לפני השיעור
מבוא
למידת מכונה משפיעה על חיי היומיום שלנו. הבינה המלאכותית מוצאת את דרכה למערכות החשובות ביותר שמשפיעות עלינו כיחידים ועל החברה שלנו, כמו בריאות, פיננסים, חינוך ותעסוקה. לדוגמה, מערכות ומודלים מעורבים במשימות קבלת החלטות יומיומיות, כמו אבחנות רפואיות או זיהוי הונאות. כתוצאה מכך, ההתקדמות בבינה מלאכותית יחד עם האימוץ המואץ שלה נתקלים בציפיות חברתיות מתפתחות ובתקנות הולכות וגוברות בתגובה. אנו רואים באופן קבוע תחומים שבהם מערכות AI ממשיכות לאכזב; הן חושפות אתגרים חדשים; וממשלות מתחילות להסדיר פתרונות AI. לכן, חשוב לנתח את המודלים הללו כדי להבטיח תוצאות הוגנות, אמינות, כוללות, שקופות ואחראיות לכולם.
בתוכנית הלימודים הזו, נבחן כלים מעשיים שניתן להשתמש בהם כדי להעריך אם למודל יש בעיות של AI אחראי. טכניקות מסורתיות לאיתור שגיאות במודלים של למידת מכונה נוטות להתבסס על חישובים כמותיים כמו דיוק מצטבר או ממוצע הפסד שגיאה. דמיינו מה יכול לקרות כאשר הנתונים שבהם אתם משתמשים לבניית המודלים הללו חסרים דמוגרפיות מסוימות, כמו גזע, מגדר, השקפה פוליטית, דת, או מייצגים באופן לא פרופורציונלי דמוגרפיות כאלה. ומה לגבי מצב שבו הפלט של המודל מפורש כמעדיף דמוגרפיה מסוימת? זה יכול להוביל לייצוג יתר או חסר של קבוצות תכונות רגישות, מה שגורם לבעיות של הוגנות, הכללה או אמינות במודל. גורם נוסף הוא שמודלים של למידת מכונה נחשבים לקופסאות שחורות, מה שמקשה להבין ולהסביר מה מניע את התחזיות של המודל. כל אלה הם אתגרים שמדעני נתונים ומפתחי AI מתמודדים איתם כאשר אין להם כלים מתאימים לאיתור שגיאות ולהערכת ההוגנות או האמינות של מודל.
בשיעור זה תלמדו על איתור שגיאות במודלים באמצעות:
- ניתוח שגיאות: זיהוי אזורים בהתפלגות הנתונים שבהם למודל יש שיעורי שגיאה גבוהים.
- סקירת מודל: ביצוע ניתוח השוואתי בין קבוצות נתונים שונות כדי לגלות פערים במדדי הביצועים של המודל.
- ניתוח נתונים: חקירה של אזורים שבהם עשויה להיות ייצוג יתר או חסר של הנתונים, מה שעלול להטות את המודל להעדיף דמוגרפיה אחת על פני אחרת.
- חשיבות תכונות: הבנה אילו תכונות מניעות את התחזיות של המודל ברמה גלובלית או מקומית.
דרישות מקדימות
כדרישה מקדימה, אנא עיינו בכלי AI אחראי למפתחים

ניתוח שגיאות
מדדי ביצועים מסורתיים של מודלים המשמשים למדידת דיוק הם לרוב חישובים המבוססים על תחזיות נכונות מול שגויות. לדוגמה, קביעה שמודל מדויק ב-89% מהזמן עם הפסד שגיאה של 0.001 יכולה להיחשב כביצועים טובים. שגיאות אינן מחולקות באופן אחיד בנתוני הבסיס שלכם. ייתכן שתקבלו ציון דיוק של 89% למודל אך תגלו שיש אזורים שונים בנתונים שבהם המודל נכשל ב-42% מהזמן. ההשלכות של דפוסי כשל אלה עם קבוצות נתונים מסוימות יכולות להוביל לבעיות של הוגנות או אמינות. חשוב להבין את האזורים שבהם המודל מתפקד היטב או לא. אזורי הנתונים שבהם יש מספר גבוה של אי דיוקים במודל עשויים להתברר כדמוגרפיה נתונים חשובה.

רכיב ניתוח השגיאות בלוח המחוונים של RAI ממחיש כיצד כשלי המודל מחולקים בין קבוצות שונות באמצעות ויזואליזציה של עץ. זה שימושי בזיהוי תכונות או אזורים שבהם יש שיעור שגיאות גבוה בנתונים שלכם. על ידי צפייה במקור רוב אי הדיוקים של המודל, תוכלו להתחיל לחקור את שורש הבעיה. ניתן גם ליצור קבוצות נתונים כדי לבצע ניתוח עליהן. קבוצות נתונים אלו מסייעות בתהליך איתור השגיאות כדי לקבוע מדוע ביצועי המודל טובים בקבוצה אחת אך שגויים באחרת.

הסימנים הוויזואליים במפת העץ מסייעים באיתור אזורי הבעיה במהירות. לדוגמה, ככל שצבע אדום כהה יותר מופיע בצומת עץ, כך שיעור השגיאות גבוה יותר.
מפת חום היא פונקציונליות ויזואליזציה נוספת שמשתמשים יכולים להשתמש בה כדי לחקור את שיעור השגיאות באמצעות תכונה אחת או שתיים ולמצוא גורם תורם לשגיאות המודל על פני כל קבוצת הנתונים או הקבוצות.

השתמשו בניתוח שגיאות כאשר אתם צריכים:
- להבין לעומק כיצד כשלי המודל מחולקים על פני קבוצת נתונים ועל פני מספר ממדי קלט ותכונות.
- לפרק את מדדי הביצועים המצטברים כדי לגלות באופן אוטומטי קבוצות שגויות וליידע את הצעדים הממוקדים שלכם למיתון הבעיה.
סקירת מודל
הערכת ביצועי מודל למידת מכונה דורשת הבנה הוליסטית של התנהגותו. ניתן להשיג זאת על ידי סקירת יותר ממדד אחד, כמו שיעור שגיאות, דיוק, ריקול, דיוק תחזיות או MAE (שגיאה מוחלטת ממוצעת), כדי למצוא פערים בין מדדי ביצועים. מדד ביצועים אחד עשוי להיראות מצוין, אך אי דיוקים יכולים להתגלות במדד אחר. בנוסף, השוואת המדדים לפערים על פני כל קבוצת הנתונים או הקבוצות עוזרת להאיר את האזורים שבהם המודל מתפקד היטב או לא. זה חשוב במיוחד כדי לראות את ביצועי המודל בין תכונות רגישות לעומת לא רגישות (למשל, גזע, מגדר או גיל של מטופל) כדי לחשוף אי הוגנות פוטנציאלית במודל. לדוגמה, גילוי שהמודל שגוי יותר בקבוצה שיש לה תכונות רגישות יכול לחשוף אי הוגנות פוטנציאלית במודל.
רכיב סקירת המודל בלוח המחוונים של RAI מסייע לא רק בניתוח מדדי הביצועים של ייצוג הנתונים בקבוצה, אלא גם נותן למשתמשים את היכולת להשוות את התנהגות המודל בין קבוצות שונות.

הפונקציונליות של ניתוח מבוסס תכונות של הרכיב מאפשרת למשתמשים לצמצם תת-קבוצות נתונים בתוך תכונה מסוימת כדי לזהות אנומליות ברמה גרעינית. לדוגמה, ללוח המחוונים יש אינטליגנציה מובנית ליצירת קבוצות באופן אוטומטי עבור תכונה שנבחרה על ידי המשתמש (למשל, "time_in_hospital < 3" או "time_in_hospital >= 7"). זה מאפשר למשתמש לבודד תכונה מסוימת מקבוצת נתונים גדולה יותר כדי לראות אם היא משפיעה על תוצאות שגויות של המודל.

רכיב סקירת המודל תומך בשני סוגים של מדדי פערים:
פער בביצועי המודל: קבוצת מדדים זו מחשבת את הפער (ההבדל) בערכים של מדד הביצועים הנבחר בין תת-קבוצות נתונים. הנה כמה דוגמאות:
- פער בשיעור דיוק
- פער בשיעור שגיאות
- פער בדיוק תחזיות
- פער בריקול
- פער בשגיאה מוחלטת ממוצעת (MAE)
פער בשיעור הבחירה: מדד זה מכיל את ההבדל בשיעור הבחירה (תחזית חיובית) בין תת-קבוצות. דוגמה לכך היא הפער בשיעורי אישור הלוואות. שיעור הבחירה מתייחס לחלק מנקודות הנתונים בכל מחלקה שמסווגות כ-1 (במיון בינארי) או להתפלגות ערכי התחזיות (ברגרסיה).
ניתוח נתונים
"אם תענה את הנתונים מספיק זמן, הם יודו בכל דבר" - רונלד קואז
האמירה הזו נשמעת קיצונית, אבל נכון שנתונים יכולים להיות מנוצלים כדי לתמוך בכל מסקנה. מניפולציה כזו יכולה לפעמים לקרות באופן לא מכוון. כבני אדם, לכולנו יש הטיות, ולעיתים קרובות קשה לדעת באופן מודע מתי אנו מכניסים הטיה לנתונים. הבטחת הוגנות ב-AI ולמידת מכונה נותרת אתגר מורכב.
נתונים הם נקודת עיוור גדולה עבור מדדי ביצועים מסורתיים של מודלים. ייתכן שיש לכם ציוני דיוק גבוהים, אך זה לא תמיד משקף את הטיה הנתונים הבסיסית שיכולה להיות בקבוצת הנתונים שלכם. לדוגמה, אם קבוצת נתונים של עובדים כוללת 27% נשים בתפקידים בכירים בחברה ו-73% גברים באותו רמה, מודל AI לפרסום משרות שמאומן על נתונים אלו עשוי לכוון בעיקר לקהל גברים עבור משרות בכירות. חוסר איזון זה בנתונים הטה את תחזיות המודל להעדיף מגדר אחד. זה חושף בעיית הוגנות שבה יש הטיה מגדרית במודל AI.
רכיב ניתוח הנתונים בלוח המחוונים של RAI מסייע בזיהוי אזורים שבהם יש ייצוג יתר או חסר בקבוצת הנתונים. הוא עוזר למשתמשים לאבחן את שורש הבעיות של שגיאות ובעיות הוגנות שנגרמות מחוסר איזון בנתונים או מחוסר ייצוג של קבוצת נתונים מסוימת. זה נותן למשתמשים את היכולת להציג ויזואלית קבוצות נתונים על סמך תחזיות ותוצאות בפועל, קבוצות שגיאות ותכונות ספציפיות. לפעמים גילוי קבוצת נתונים לא מיוצגת יכול גם לחשוף שהמודל לא לומד היטב, ולכן יש אי דיוקים גבוהים. מודל שיש לו הטיה נתונים הוא לא רק בעיית הוגנות אלא גם מראה שהמודל אינו כולל או אמין.

השתמשו בניתוח נתונים כאשר אתם צריכים:
- לחקור את סטטיסטיקות קבוצת הנתונים שלכם על ידי בחירת מסננים שונים כדי לחלק את הנתונים שלכם לממדים שונים (המכונים גם קבוצות).
- להבין את התפלגות קבוצת הנתונים שלכם על פני קבוצות שונות וקבוצות תכונות.
- לקבוע האם הממצאים שלכם הקשורים להוגנות, ניתוח שגיאות וסיבתיות (שנגזרו מרכיבים אחרים בלוח המחוונים) הם תוצאה של התפלגות קבוצת הנתונים שלכם.
- להחליט באילו אזורים לאסוף יותר נתונים כדי למתן שגיאות שנובעות מבעיות ייצוג, רעש תוויות, רעש תכונות, הטיה תוויות וגורמים דומים.
פרשנות מודל
מודלים של למידת מכונה נוטים להיות קופסאות שחורות. הבנת אילו תכונות נתונים מרכזיות מניעות את התחזיות של מודל יכולה להיות מאתגרת. חשוב לספק שקיפות לגבי הסיבה שמודל עושה תחזית מסוימת. לדוגמה, אם מערכת AI חוזה שמטופל סוכרתי נמצא בסיכון לחזור לבית חולים תוך פחות מ-30 ימים, עליה לספק נתונים תומכים שהובילו לתחזית שלה. נתונים תומכים אלו מביאים שקיפות שעוזרת לרופאים או בתי חולים לקבל החלטות מושכלות. בנוסף, היכולת להסביר מדוע מודל עשה תחזית עבור מטופל מסוים מאפשרת אחריות עם תקנות בריאות. כאשר אתם משתמשים במודלים של למידת מכונה בדרכים שמשפיעות על חיי אנשים, חשוב להבין ולהסביר מה משפיע על התנהגות המודל. פרשנות והסבר מודל עוזרים לענות על שאלות בתרחישים כמו:
- איתור שגיאות במודל: מדוע המודל שלי עשה את הטעות הזו? איך אני יכול לשפר את המודל שלי?
- שיתוף פעולה בין אדם ל-AI: איך אני יכול להבין ולסמוך על ההחלטות של המודל?
- עמידה בתקנות: האם המודל שלי עומד בדרישות החוקיות?
רכיב חשיבות התכונות בלוח המחוונים של RAI עוזר לכם לאתר שגיאות ולקבל הבנה מקיפה של איך מודל עושה תחזיות. זהו גם כלי שימושי עבור אנשי מקצוע בלמידת מכונה ומקבלי החלטות להסביר ולהציג ראיות לתכונות שמשפיעות על התנהגות המודל לצורך עמידה בתקנות. לאחר מכן, משתמשים יכולים לחקור הסברים גלובליים ומקומיים כדי לאמת אילו תכונות מניעות את התחזיות של המודל. הסברים גלובליים מציגים את התכונות המרכזיות שהשפיעו על התחזיות הכוללות של המודל. הסברים מקומיים מציגים אילו תכונות הובילו לתחזית של המודל עבור מקרה יחיד. היכולת להעריך הסברים מקומיים מועילה גם באיתור שגיאות או בביקורת מקרה ספציפי כדי להבין ולהסביר מדוע מודל עשה תחזית מדויקת או שגויה.
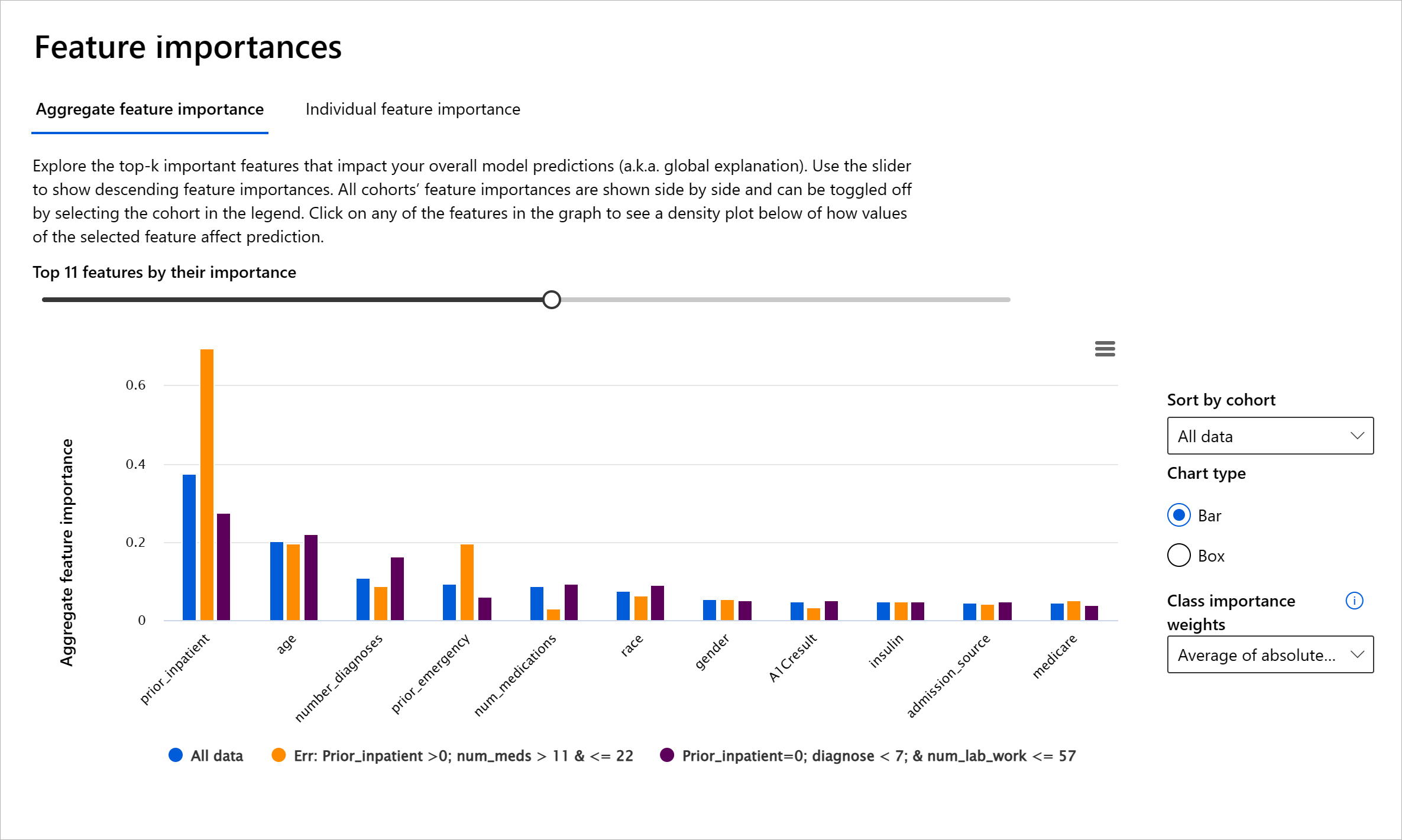
- הסברים גלובליים: לדוגמה, אילו תכונות משפיעות על ההתנהגות הכוללת של מודל חזרה לבית חולים של חולי סוכרת?
- הסברים מקומיים: לדוגמה, מדוע מטופל סוכרתי מעל גיל 60 עם אשפוזים קודמים חזה שיחזור או לא יחזור לבית חולים תוך 30 ימים?
בתהליך איתור שגיאות של בחינת ביצועי המודל על פני קבוצות שונות, חשיבות התכונות מראה מהי רמת ההשפעה של תכונה על פני הקבוצות. זה עוזר לחשוף אנומליות כאשר משווים את רמת ההשפעה של התכונה על תחזיות שגויות של המודל. רכיב חשיבות התכונות יכול להראות אילו ערכים בתכונה השפיעו באופן חיובי או שלילי על תוצאות המודל. לדוגמה, אם מודל עשה תחזית שגויה, הרכיב נותן לכם את היכולת להעמיק ולזהות אילו תכונות או ערכי תכונות הובילו לתחזית. רמת פירוט זו עוזרת לא רק באיתור שגיאות אלא מספקת שקיפות ואחריות במצבי ביקורת. לבסוף, הרכיב יכול לעזור לכם לזהות בעיות הוגנות. לדוגמה, אם תכונה רגישה כמו אתניות או מגדר משפיעה מאוד על תחזיות המודל, זה יכול להיות סימן להטיה גזעית או מגדרית במודל.
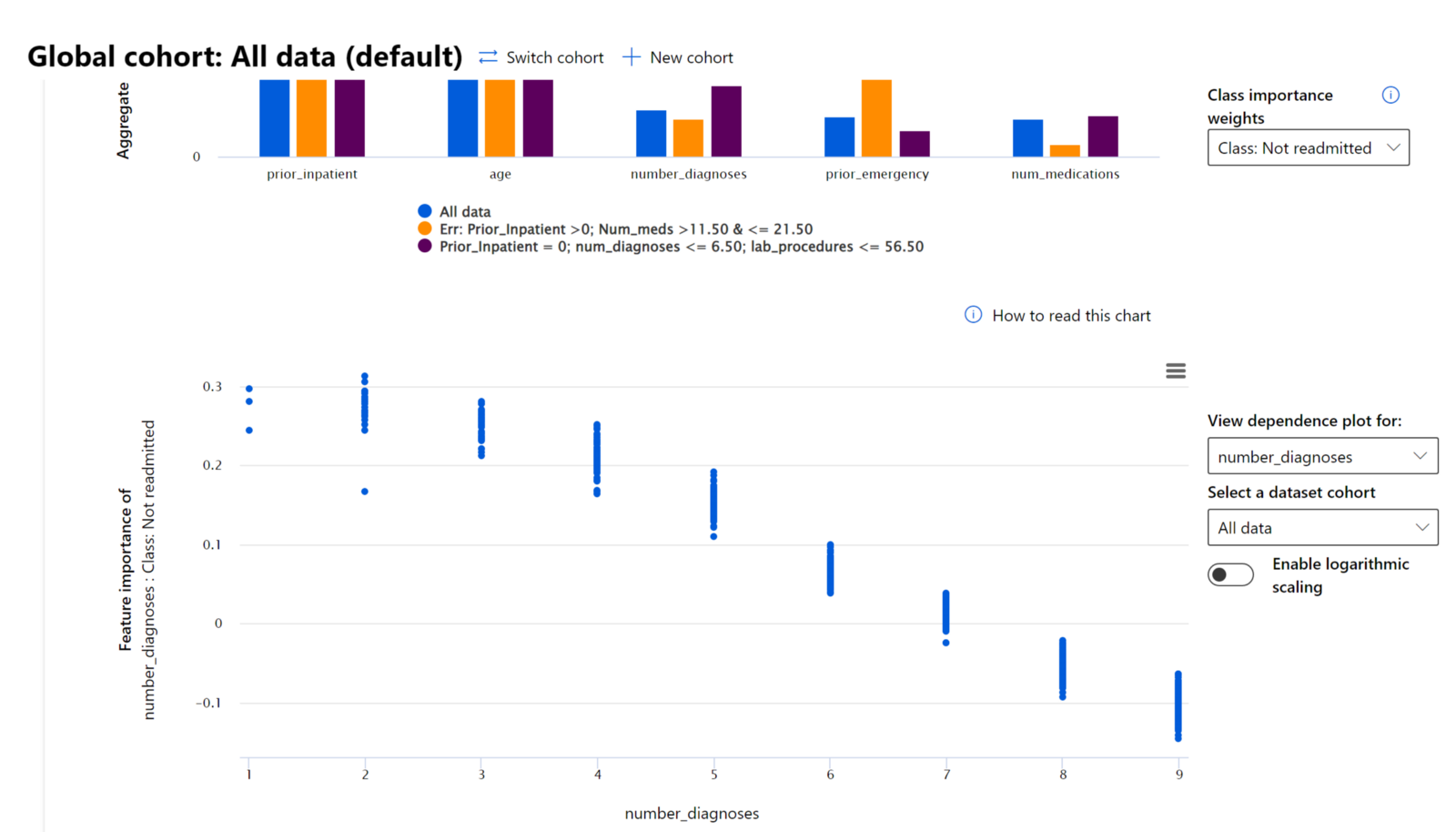
השתמשו בפרשנות כאשר אתם צריכים:
- לקבוע עד כמה ניתן לסמוך על תחזיות מערכת ה-AI שלכם על ידי הבנת אילו תכונות הן החשובות ביותר עבור התחזיות.
- לגשת לאיתור שגיאות במודל שלכם על ידי הבנתו תחילה וזיהוי האם המודל משתמש בתכונות בריאות או רק בקורלציות שגויות.
- לחשוף מקורות פוטנציאליים של אי הוגנות על ידי הבנת האם המודל מבסס תחזיות על תכונות רגישות או על תכונות שמקושרות מאוד אליהן.
- לבנות אמון משתמש בהחלטות המודל שלכם על ידי יצירת הסברים מקומיים להמחשת התוצאות שלהם.
- להשלים ביקורת רגולטורית של מערכת AI כדי לאמת מודלים ולפקח על ההשפעה של החלטות המודל על בני אדם.
סיכום
כל רכיבי לוח המחוונים של RAI הם כלים מעשיים שעוזרים לכם לבנות מודלים של למידת מכונה שפוגעים פחות ומעוררים יותר אמון בחברה.
- ייצוג יתר או חסר. הרעיון הוא שקבוצה מסוימת אינה נראית במקצוע מסוים, וכל שירות או פונקציה שממשיכים לקדם זאת תורמים לנזק.
לוח מחוונים של Azure RAI
לוח המחוונים של Azure RAI מבוסס על כלים בקוד פתוח שפותחו על ידי מוסדות אקדמיים וארגונים מובילים, כולל Microsoft. כלים אלו חיוניים למדעני נתונים ומפתחי AI כדי להבין טוב יותר את התנהגות המודל, לגלות ולתקן בעיות לא רצויות במודלים של AI.
-
למדו כיצד להשתמש ברכיבים השונים על ידי עיון בתיעוד לוח המחוונים של RAI.
-
עיינו בכמה מחברות לדוגמה של לוח המחוונים של RAI לצורך איתור בעיות בתרחישים של AI אחראי ב-Azure Machine Learning.
🚀 אתגר
כדי למנוע מראש הטיה סטטיסטית או הטיה בנתונים, עלינו:
- להבטיח מגוון רקעים ונקודות מבט בקרב האנשים שעובדים על המערכות
- להשקיע במאגרי נתונים שמשקפים את המגוון בחברה שלנו
- לפתח שיטות טובות יותר לזיהוי ותיקון הטיה כאשר היא מתרחשת
חשבו על תרחישים אמיתיים שבהם אי-צדק ניכר בבניית מודלים ובשימוש בהם. מה עוד כדאי לקחת בחשבון?
שאלון לאחר ההרצאה
סקירה ולימוד עצמי
בשיעור זה, למדתם כמה מהכלים המעשיים לשילוב AI אחראי בלמידת מכונה.
צפו בסדנה זו כדי להעמיק בנושאים:
- לוח מחוונים של AI אחראי: פתרון כולל ליישום RAI בפועל מאת Besmira Nushi ו-Mehrnoosh Sameki

🎥 לחצו על התמונה למעלה לצפייה בסרטון: לוח מחוונים של AI אחראי: פתרון כולל ליישום RAI בפועל מאת Besmira Nushi ו-Mehrnoosh Sameki
עיינו בחומרים הבאים כדי ללמוד עוד על AI אחראי וכיצד לבנות מודלים אמינים יותר:
-
כלים של Microsoft ללוח מחוונים של RAI לצורך איתור בעיות במודלים של ML: משאבי כלים ל-AI אחראי
-
חקרו את ערכת הכלים ל-AI אחראי: Github
-
מרכז המשאבים של Microsoft ל-AI אחראי: משאבי AI אחראי – Microsoft AI
-
קבוצת המחקר FATE של Microsoft: FATE: צדק, אחריות, שקיפות ואתיקה ב-AI - Microsoft Research
משימה
כתב ויתור:
מסמך זה תורגם באמצעות שירות תרגום מבוסס בינה מלאכותית Co-op Translator. בעוד שאנו שואפים לדיוק, יש להיות מודעים לכך שתרגומים אוטומטיים עשויים להכיל שגיאות או אי דיוקים. המסמך המקורי בשפתו המקורית צריך להיחשב כמקור סמכותי. עבור מידע קריטי, מומלץ להשתמש בתרגום מקצועי על ידי אדם. איננו נושאים באחריות לאי הבנות או לפרשנויות שגויות הנובעות משימוש בתרגום זה.