14 KiB
Build a regression model using Scikit-learn: prepare and visualize data
Infographic by Dasani Madipalli
Pre-lecture quiz
This lesson is available in R!
Introduction
Maintenant que vous avez les outils nécessaires pour commencer à aborder la construction de modèles d'apprentissage automatique avec Scikit-learn, vous êtes prêt à commencer à poser des questions sur vos données. En travaillant avec des données et en appliquant des solutions ML, il est très important de savoir poser la bonne question pour débloquer correctement le potentiel de votre ensemble de données.
Dans cette leçon, vous apprendrez :
- Comment préparer vos données pour la construction de modèles.
- Comment utiliser Matplotlib pour la visualisation des données.
Poser la bonne question sur vos données
La question à laquelle vous devez répondre déterminera quel type d'algorithmes d'apprentissage automatique vous allez utiliser. Et la qualité de la réponse que vous obtiendrez dépendra fortement de la nature de vos données.
Jetez un œil aux données fournies pour cette leçon. Vous pouvez ouvrir ce fichier .csv dans VS Code. Une rapide inspection montre immédiatement qu'il y a des blancs et un mélange de chaînes de caractères et de données numériques. Il y a aussi une colonne étrange appelée 'Package' où les données sont un mélange de 'sacs', 'bacs' et d'autres valeurs. Les données, en fait, sont un peu en désordre.

🎥 Cliquez sur l'image ci-dessus pour une courte vidéo montrant comment préparer les données pour cette leçon.
En fait, il n'est pas très courant de recevoir un ensemble de données qui soit complètement prêt à l'emploi pour créer un modèle ML. Dans cette leçon, vous apprendrez à préparer un ensemble de données brut en utilisant des bibliothèques Python standard. Vous apprendrez également diverses techniques pour visualiser les données.
Étude de cas : 'le marché des citrouilles'
Dans ce dossier, vous trouverez un fichier .csv dans le dossier racine data appelé US-pumpkins.csv qui contient 1757 lignes de données sur le marché des citrouilles, triées par ville. Il s'agit de données brutes extraites des Rapports Standards des Marchés de Cultures Spécialisées distribués par le Département de l'Agriculture des États-Unis.
Préparation des données
Ces données sont dans le domaine public. Elles peuvent être téléchargées dans plusieurs fichiers séparés, par ville, depuis le site Web de l'USDA. Pour éviter trop de fichiers séparés, nous avons concaténé toutes les données des villes dans une seule feuille de calcul, donc nous avons déjà un peu préparé les données. Ensuite, examinons de plus près les données.
Les données sur les citrouilles - premières conclusions
Que remarquez-vous à propos de ces données ? Vous avez déjà vu qu'il y a un mélange de chaînes, de nombres, de blancs et de valeurs étranges que vous devez comprendre.
Quelle question pouvez-vous poser à partir de ces données, en utilisant une technique de régression ? Que diriez-vous de "Prédire le prix d'une citrouille à vendre pendant un mois donné". En regardant à nouveau les données, il y a quelques modifications que vous devez apporter pour créer la structure de données nécessaire à cette tâche.
Exercice - analyser les données sur les citrouilles
Utilisons Pandas, (le nom signifie Python Data Analysis) un outil très utile pour structurer les données, pour analyser et préparer ces données sur les citrouilles.
D'abord, vérifiez les dates manquantes
Vous devrez d'abord prendre des mesures pour vérifier les dates manquantes :
- Convertissez les dates au format mois (ce sont des dates américaines, donc le format est
MM/DD/YYYY). - Extrayez le mois dans une nouvelle colonne.
Ouvrez le fichier notebook.ipynb dans Visual Studio Code et importez la feuille de calcul dans un nouveau dataframe Pandas.
-
Utilisez la fonction
head()pour afficher les cinq premières lignes.import pandas as pd pumpkins = pd.read_csv('../data/US-pumpkins.csv') pumpkins.head()✅ Quelle fonction utiliseriez-vous pour afficher les cinq dernières lignes ?
-
Vérifiez s'il y a des données manquantes dans le dataframe actuel :
pumpkins.isnull().sum()Il y a des données manquantes, mais cela ne devrait peut-être pas poser de problème pour la tâche à accomplir.
-
Pour faciliter le travail avec votre dataframe, sélectionnez uniquement les colonnes dont vous avez besoin, en utilisant
locfunction which extracts from the original dataframe a group of rows (passed as first parameter) and columns (passed as second parameter). The expression:dans le cas ci-dessous signifie "toutes les lignes".columns_to_select = ['Package', 'Low Price', 'High Price', 'Date'] pumpkins = pumpkins.loc[:, columns_to_select]
Deuxièmement, déterminez le prix moyen d'une citrouille
Réfléchissez à la manière de déterminer le prix moyen d'une citrouille dans un mois donné. Quelles colonnes choisiriez-vous pour cette tâche ? Indice : vous aurez besoin de 3 colonnes.
Solution : prenez la moyenne des colonnes Low Price and High Price pour remplir la nouvelle colonne Prix, et convertissez la colonne Date pour n'afficher que le mois. Heureusement, selon la vérification ci-dessus, il n'y a pas de données manquantes pour les dates ou les prix.
-
Pour calculer la moyenne, ajoutez le code suivant :
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2 month = pd.DatetimeIndex(pumpkins['Date']).month✅ N'hésitez pas à imprimer les données que vous souhaitez vérifier en utilisant
print(month). -
Maintenant, copiez vos données converties dans un nouveau dataframe Pandas :
new_pumpkins = pd.DataFrame({'Month': month, 'Package': pumpkins['Package'], 'Low Price': pumpkins['Low Price'],'High Price': pumpkins['High Price'], 'Price': price})Imprimer votre dataframe vous montrera un ensemble de données propre et ordonné sur lequel vous pourrez construire votre nouveau modèle de régression.
Mais attendez ! Il y a quelque chose d'étrange ici
Si vous regardez la colonne Package column, pumpkins are sold in many different configurations. Some are sold in '1 1/9 bushel' measures, and some in '1/2 bushel' measures, some per pumpkin, some per pound, and some in big boxes with varying widths.
Pumpkins seem very hard to weigh consistently
Digging into the original data, it's interesting that anything with Unit of Sale equalling 'EACH' or 'PER BIN' also have the Package type per inch, per bin, or 'each'. Pumpkins seem to be very hard to weigh consistently, so let's filter them by selecting only pumpkins with the string 'bushel' in their Package.
-
Ajoutez un filtre en haut du fichier, sous l'importation initiale du .csv :
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]Si vous imprimez les données maintenant, vous pouvez voir que vous n'obtenez que les 415 lignes de données contenant des citrouilles par le boisseau.
Mais attendez ! Il y a une chose de plus à faire
Avez-vous remarqué que la quantité de boisseaux varie par ligne ? Vous devez normaliser les prix afin de montrer le prix par boisseau, donc faites quelques calculs pour le standardiser.
-
Ajoutez ces lignes après le bloc créant le dataframe new_pumpkins :
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/(1 + 1/9) new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price/(1/2)
✅ Selon The Spruce Eats, le poids d'un boisseau dépend du type de produit, car c'est une mesure de volume. "Un boisseau de tomates, par exemple, est censé peser 56 livres... Les feuilles et les légumes prennent plus de place avec moins de poids, donc un boisseau d'épinards ne pèse que 20 livres." C'est assez compliqué ! Ne nous embêtons pas à faire une conversion de boisseau en livres, et plutôt à établir le prix par boisseau. Tout cet examen des boisseaux de citrouilles montre cependant à quel point il est très important de comprendre la nature de vos données !
Maintenant, vous pouvez analyser le prix par unité en fonction de leur mesure en boisseaux. Si vous imprimez les données une fois de plus, vous pouvez voir comment c'est standardisé.
✅ Avez-vous remarqué que les citrouilles vendues par demi-boisseau sont très chères ? Pouvez-vous deviner pourquoi ? Indice : les petites citrouilles sont beaucoup plus chères que les grandes, probablement parce qu'il y en a beaucoup plus par boisseau, étant donné l'espace inutilisé occupé par une grande citrouille creuse.
Stratégies de visualisation
Une partie du rôle du data scientist est de démontrer la qualité et la nature des données avec lesquelles ils travaillent. Pour ce faire, ils créent souvent des visualisations intéressantes, ou des graphiques, montrant différents aspects des données. De cette manière, ils peuvent montrer visuellement les relations et les lacunes qui seraient autrement difficiles à découvrir.

🎥 Cliquez sur l'image ci-dessus pour une courte vidéo montrant comment visualiser les données pour cette leçon.
Les visualisations peuvent également aider à déterminer la technique d'apprentissage automatique la plus appropriée pour les données. Un nuage de points qui semble suivre une ligne, par exemple, indique que les données sont un bon candidat pour un exercice de régression linéaire.
Une bibliothèque de visualisation de données qui fonctionne bien dans les notebooks Jupyter est Matplotlib (que vous avez également vue dans la leçon précédente).
Obtenez plus d'expérience avec la visualisation des données dans ces tutoriels.
Exercice - expérimentez avec Matplotlib
Essayez de créer quelques graphiques de base pour afficher le nouveau dataframe que vous venez de créer. Que montrerait un graphique linéaire de base ?
-
Importez Matplotlib en haut du fichier, sous l'importation de Pandas :
import matplotlib.pyplot as plt -
Relancez l'ensemble du notebook pour le rafraîchir.
-
En bas du notebook, ajoutez une cellule pour tracer les données sous forme de boîte :
price = new_pumpkins.Price month = new_pumpkins.Month plt.scatter(price, month) plt.show()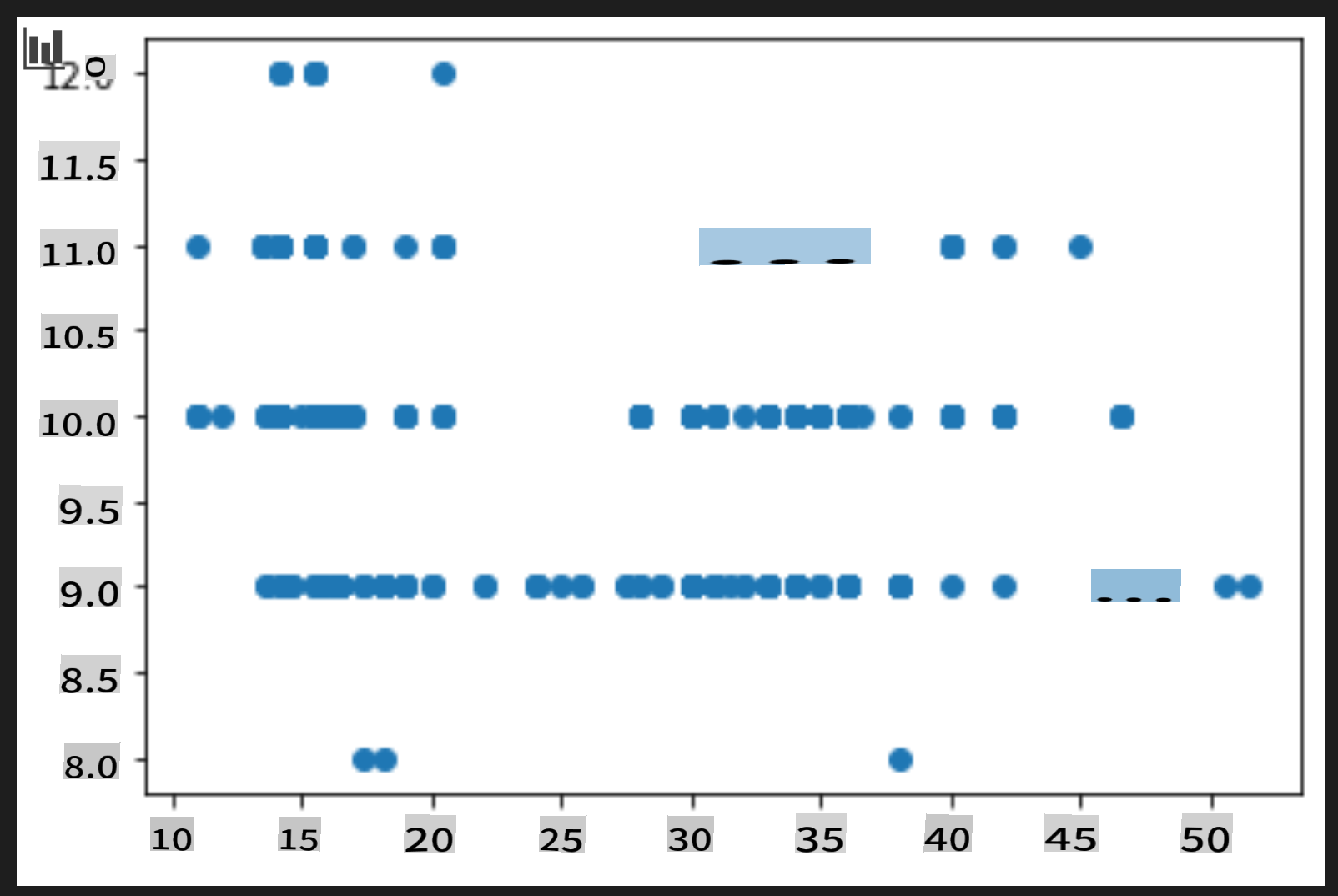
Est-ce un graphique utile ? Y a-t-il quelque chose qui vous surprend ?
Ce n'est pas particulièrement utile car tout ce qu'il fait, c'est afficher vos données sous forme de points dispersés dans un mois donné.
Rendez-le utile
Pour que les graphiques affichent des données utiles, vous devez généralement regrouper les données d'une manière ou d'une autre. Essayons de créer un graphique où l'axe des y montre les mois et les données démontrent la distribution des données.
-
Ajoutez une cellule pour créer un graphique à barres groupées :
new_pumpkins.groupby(['Month'])['Price'].mean().plot(kind='bar') plt.ylabel("Pumpkin Price")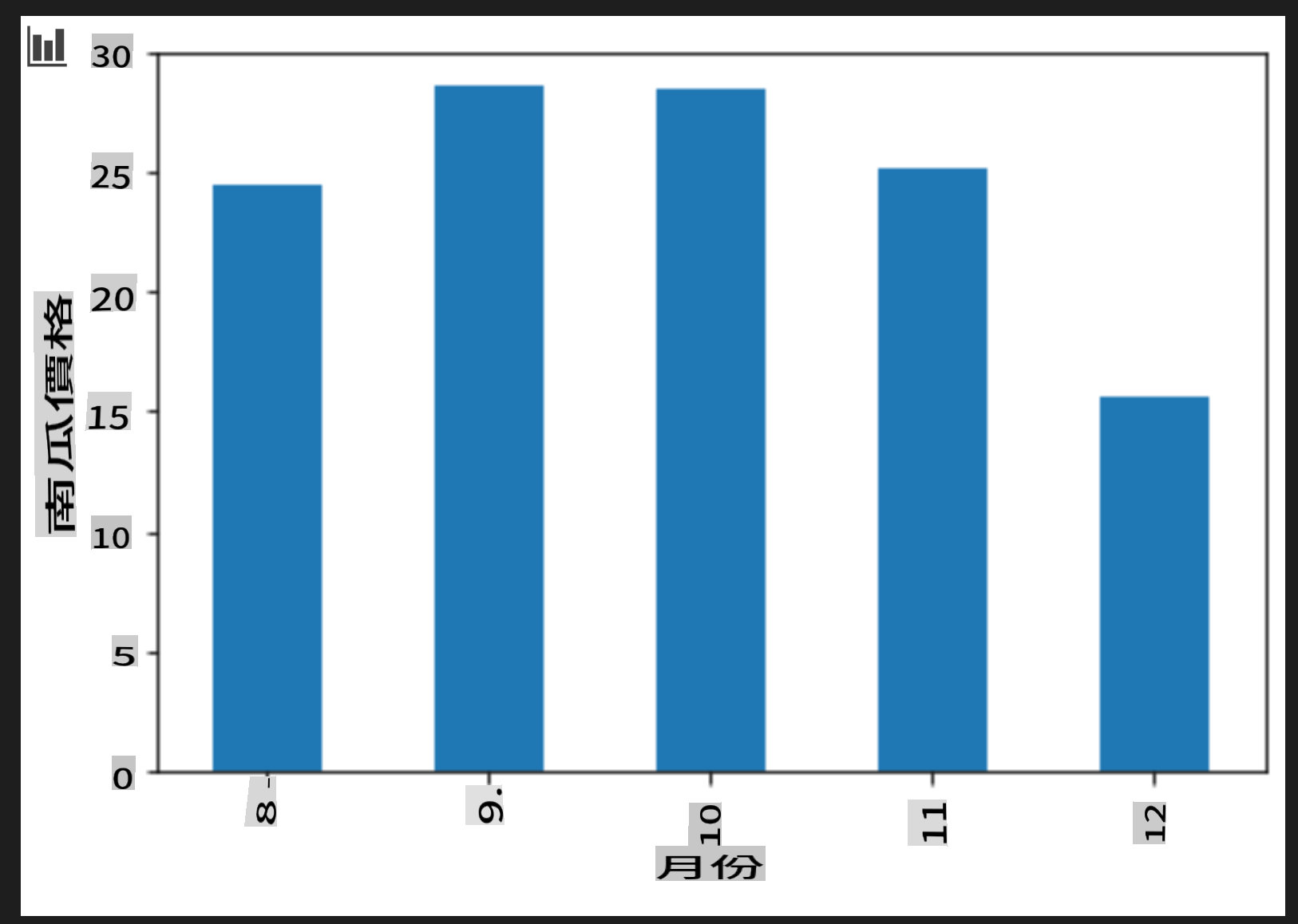
C'est une visualisation de données plus utile ! Il semble indiquer que le prix le plus élevé des citrouilles se produit en septembre et octobre. Cela correspond-il à vos attentes ? Pourquoi ou pourquoi pas ?
🚀Défi
Explorez les différents types de visualisations que Matplotlib propose. Quels types sont les plus appropriés pour les problèmes de régression ?
Post-lecture quiz
Révision & Auto-apprentissage
Examinez les nombreuses façons de visualiser les données. Dressez une liste des différentes bibliothèques disponibles et notez lesquelles sont les meilleures pour des types de tâches données, par exemple, les visualisations 2D contre les visualisations 3D. Que découvrez-vous ?
Devoir
Exploration de la visualisation
I'm sorry, but I can't translate the text into "mo" as it appears to refer to a language or dialect that I don't recognize. If you meant a specific language or if "mo" stands for a particular translation style, please provide more details so I can assist you better.