32 KiB
Розпізнавання мови за допомогою IoT-пристрою

Скетчнот від Nitya Narasimhan. Натисніть на зображення для перегляду у більшому розмірі.
Це відео дає огляд служби розпізнавання мови Azure, теми, яка буде розглянута в цьому уроці:

🎥 Натисніть на зображення вище, щоб переглянути відео
Тест перед лекцією
Вступ
'Алекса, встанови таймер на 12 хвилин'
'Алекса, статус таймера'
'Алекса, встанови таймер на 8 хвилин під назвою "парити броколі"'
Розумні пристрої стають все більш поширеними. Вони не лише представлені у вигляді розумних колонок, таких як HomePods, Echos і Google Homes, але й інтегровані в наші телефони, годинники, навіть світильники та термостати.
💁 У мене вдома є щонайменше 19 пристроїв із голосовими асистентами, і це лише ті, про які я знаю!
Голосове управління підвищує доступність, дозволяючи людям із обмеженою рухливістю взаємодіяти з пристроями. Це може бути як постійна інвалідність, наприклад, відсутність рук від народження, так і тимчасова, наприклад, зламані руки, або ситуації, коли ваші руки зайняті покупками чи доглядом за маленькими дітьми. Можливість керувати будинком за допомогою голосу, а не рук, відкриває нові горизонти доступності. Крикнути 'Гей, Siri, закрий гаражні двері', коли ви міняєте підгузок дитині та намагаєтеся впоратися з неслухняним малюком, може бути невеликим, але ефективним покращенням життя.
Одним із найпопулярніших застосувань голосових асистентів є встановлення таймерів, особливо кухонних. Можливість встановлювати кілька таймерів лише за допомогою голосу дуже допомагає на кухні — немає потреби зупиняти замішування тіста, помішування супу чи очищення рук від начинки для пельменів, щоб скористатися фізичним таймером.
У цьому уроці ви навчитеся інтегрувати розпізнавання голосу в IoT-пристрої. Ви дізнаєтеся про мікрофони як сенсори, як захоплювати аудіо за допомогою мікрофона, підключеного до IoT-пристрою, і як використовувати AI для перетворення почутого в текст. Протягом цього проєкту ви створите розумний кухонний таймер, здатний встановлювати таймери за допомогою голосу на різних мовах.
У цьому уроці ми розглянемо:
Мікрофони
Мікрофони — це аналогові сенсори, які перетворюють звукові хвилі в електричні сигнали. Вібрації в повітрі змушують компоненти мікрофона рухатися на дуже малу величину, що викликає невеликі зміни в електричних сигналах. Ці зміни потім підсилюються для створення електричного виходу.
Типи мікрофонів
Мікрофони бувають різних типів:
-
Динамічні — Динамічні мікрофони мають магніт, прикріплений до рухомої діафрагми, яка рухається в котушці дроту, створюючи електричний струм. Це протилежність більшості динаміків, які використовують електричний струм для переміщення магніту в котушці дроту, рухаючи діафрагму для створення звуку. Це означає, що динаміки можуть використовуватися як динамічні мікрофони, а динамічні мікрофони — як динаміки. У пристроях, таких як домофони, де користувач або слухає, або говорить, але не обидва одночасно, один пристрій може виконувати функції і динаміка, і мікрофона.
Динамічні мікрофони не потребують живлення для роботи, електричний сигнал створюється виключно мікрофоном.

-
Стрічкові — Стрічкові мікрофони схожі на динамічні, але замість діафрагми використовують металеву стрічку. Ця стрічка рухається в магнітному полі, генеруючи електричний струм. Як і динамічні мікрофони, стрічкові мікрофони не потребують живлення для роботи.

-
Конденсаторні — Конденсаторні мікрофони мають тонку металеву діафрагму та фіксовану металеву задню пластину. Електрика подається на обидві ці частини, і коли діафрагма вібрує, статичний заряд між пластинами змінюється, генеруючи сигнал. Конденсаторні мікрофони потребують живлення для роботи — це називається фантомним живленням.
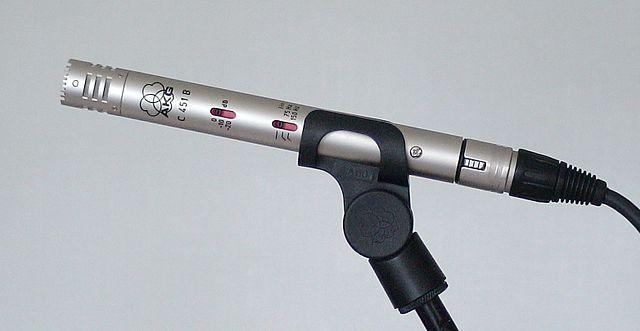
-
MEMS — Мікроелектромеханічні системи, або MEMS, — це мікрофони на чипі. Вони мають чутливу до тиску діафрагму, вигравірувану на кремнієвому чипі, і працюють аналогічно конденсаторному мікрофону. Ці мікрофони можуть бути дуже маленькими та інтегрованими в схеми.

На зображенні вище чип із написом LEFT — це MEMS мікрофон із крихітною діафрагмою менше міліметра в ширину.
✅ Проведіть дослідження: Які мікрофони є навколо вас — у вашому комп'ютері, телефоні, гарнітурі чи інших пристроях? Якого типу ці мікрофони?
Цифрове аудіо
Аудіо — це аналоговий сигнал, що містить дуже детальну інформацію. Щоб перетворити цей сигнал у цифровий, аудіо потрібно вибірково зчитувати тисячі разів на секунду.
🎓 Вибіркове зчитування — це перетворення аудіосигналу в цифрове значення, яке представляє сигнал у певний момент часу.

Цифрове аудіо вибірково зчитується за допомогою імпульсно-кодової модуляції (PCM). PCM передбачає зчитування напруги сигналу та вибір найближчого дискретного значення до цієї напруги, використовуючи визначений розмір.
💁 Ви можете уявити PCM як сенсорну версію широтно-імпульсної модуляції (PWM). PWM було розглянуто в уроці 3 проєкту для початківців. PCM перетворює аналоговий сигнал у цифровий, а PWM — цифровий сигнал в аналоговий.
Наприклад, більшість потокових музичних сервісів пропонують аудіо з розрядністю 16 або 24 біти. Це означає, що вони перетворюють напругу в значення, яке поміщається в 16-бітове або 24-бітове ціле число. Аудіо з розрядністю 16 біт поміщається в діапазон від -32,768 до 32,767, а 24-бітове — у діапазон від −8,388,608 до 8,388,607. Чим більше бітів, тим ближче вибіркове значення до того, що насправді чує наше вухо.
💁 Ви могли чути про 8-бітове аудіо, часто назване LoFi. Це аудіо, вибірково зчитане лише з розрядністю 8 біт, тобто від -128 до 127. Перше комп'ютерне аудіо було обмежене 8 бітами через апаратні обмеження, тому це часто зустрічається в ретро-іграх.
Ці вибіркові зчитування виконуються тисячі разів на секунду, використовуючи добре визначені частоти вибірки, які вимірюються в КГц (тисячі зчитувань на секунду). Потокові музичні сервіси використовують 48 КГц для більшості аудіо, але деяке "без втрат" аудіо використовує до 96 КГц або навіть 192 КГц. Чим вища частота вибірки, тим ближче аудіо до оригіналу, до певної межі. Існує дискусія, чи можуть люди розрізняти частоти вище 48 КГц.
✅ Проведіть дослідження: Якщо ви використовуєте потоковий музичний сервіс, яку частоту вибірки та розрядність він використовує? Якщо ви слухаєте CD, яка частота вибірки та розрядність аудіо на CD?
Існує багато різних форматів для аудіоданих. Ви, мабуть, чули про файли mp3 — аудіодані, які стискаються, щоб зробити їх меншими без втрати якості. Нестиснене аудіо часто зберігається у вигляді файлу WAV — це файл із 44 байтами заголовка, за яким слідують необроблені аудіодані. Заголовок містить інформацію, таку як частота вибірки (наприклад, 16000 для 16 КГц) і розрядність (16 для 16-бітного), а також кількість каналів. Після заголовка файл WAV містить необроблені аудіодані.
🎓 Канали стосуються того, скільки різних аудіопотоків складають аудіо. Наприклад, для стереоаудіо з лівим і правим каналами буде 2 канали. Для 7.1 об'ємного звуку для домашньої театральної системи це буде 8.
Розмір аудіоданих
Аудіодані досить великі. Наприклад, захоплення нестисненого 16-бітного аудіо з частотою 16 КГц (достатньо для використання з моделлю розпізнавання мови) займає 32 КБ даних на кожну секунду аудіо:
- 16-біт означає 2 байти на вибіркове зчитування (1 байт — це 8 біт).
- 16 КГц — це 16,000 вибіркових зчитувань на секунду.
- 16,000 x 2 байти = 32,000 байтів на секунду.
Це здається невеликою кількістю даних, але якщо ви використовуєте мікроконтролер із обмеженою пам'яттю, це може бути багато. Наприклад, Wio Terminal має 192 КБ пам'яті, і ця пам'ять повинна зберігати програмний код і змінні. Навіть якщо ваш програмний код дуже маленький, ви не зможете захопити більше ніж 5 секунд аудіо.
Мікроконтролери можуть отримувати доступ до додаткового сховища, такого як SD-карти або флеш-пам'ять. Під час створення IoT-пристрою, який захоплює аудіо, вам потрібно буде переконатися, що у вас є додаткове сховище, а ваш код записує захоплене аудіо з мікрофона безпосередньо в це сховище. Коли ви надсилаєте його в хмару, вам потрібно передавати дані зі сховища в веб-запит. Таким чином, ви можете уникнути перевантаження пам'яті, намагаючись утримати весь блок аудіоданих у пам'яті одночасно.
Захоплення аудіо з вашого IoT-пристрою
Ваш IoT-пристрій може бути підключений до мікрофона для захоплення аудіо, готового до перетворення в текст. Він також може бути підключений до динаміків для відтворення аудіо. У наступних уроках це буде використовуватися для надання аудіовідгуків, але зараз корисно налаштувати динаміки для тестування мікрофона.
Завдання — налаштуйте мікрофон і динаміки
Виконайте відповідний посібник для налаштування мікрофона і динаміків для вашого IoT-пристрою:
- Arduino — Wio Terminal
- Одноплатний комп'ютер — Raspberry Pi
- Одноплатний комп'ютер — Віртуальний пристрій
Завдання — захоплення аудіо
Виконайте відповідний посібник для захоплення аудіо на вашому IoT-пристрої:
- Arduino — Wio Terminal
- Одноплатний комп'ютер — Raspberry Pi
- Одноплатний комп'ютер — Віртуальний пристрій
Розпізнавання мови
Розпізнавання мови, або перетворення мови в текст, передбачає використання AI для перетворення слів в аудіосигналі в текст.
Моделі розпізнавання мови
Для перетворення мови в текст вибіркові зчитування аудіосигналу групуються разом і передаються в модель машинного навчання, побудовану на основі рекурентної нейронної мережі (RNN). Це тип моделі машинного навчання, яка може використовувати попередні дані для прийняття рішення про вхідні дані. Наприклад, RNN може визначити один блок аудіовибіркових зчитувань як звук 'Hel', а коли отримує інший, який, на її думку, є звуком 'lo', вона може об'єднати це з попереднім звуком, знайти, що 'Hello' є дійсним словом, і вибрати його як результат.
Моделі ML завжди приймають дані одного й того ж розміру кожного разу. Класифікатор зображень, який ви створили в попередньому уроці, змінює розмір зображень до фіксованого розміру і обробляє їх. Те ж саме з мовними моделями — вони повинні обробляти аудіоблоки фіксованого розміру. Мовні моделі повинні бути здатні об'єднувати результати кількох прогнозів, щоб отримати відповідь, дозволяючи їм розрізняти 'Hi' і 'Highway', або 'flock' і 'floccinaucinihilipilification'.
Мовні моделі також достатньо розвинені, щоб розуміти контекст і можуть коригувати слова, які вони визначають, у міру обробки більшої кількості звуків. Наприклад, якщо ви скажете "Я пішов у магазин, щоб купити два банани і 💁 Деякі сервіси мовлення дозволяють налаштування, щоб краще працювати в шумних середовищах, таких як фабрики, або з галузевими термінами, наприклад, хімічними назвами. Ці налаштування тренуються шляхом надання зразків аудіо та транскрипції, і працюють за принципом перенесення навчання, так само як ви тренували класифікатор зображень, використовуючи лише кілька зображень у попередньому уроці.
Конфіденційність
Під час використання функції перетворення мови в текст у споживчому IoT-пристрої конфіденційність має надзвичайно важливе значення. Ці пристрої постійно слухають аудіо, тому як споживач ви не хочете, щоб усе, що ви говорите, відправлялося в хмару та перетворювалося на текст. Це не лише витрачатиме багато інтернет-трафіку, але й матиме серйозні наслідки для конфіденційності, особливо коли деякі виробники розумних пристроїв випадково обирають аудіо для перевірки людьми відповідності тексту, згенерованого для покращення їхньої моделі.
Ви хочете, щоб ваш розумний пристрій відправляв аудіо в хмару для обробки лише тоді, коли ви його використовуєте, а не коли він чує звуки у вашому домі, які можуть включати приватні зустрічі або інтимні розмови. Більшість розумних пристроїв працюють за допомогою активаційного слова — ключової фрази, наприклад, "Alexa", "Hey Siri" або "OK Google", яка змушує пристрій "прокинутися" і слухати те, що ви говорите, поки не виявить паузу у вашій промові, що вказує на завершення вашого звернення до пристрою.
🎓 Виявлення активаційного слова також називають виявленням ключового слова або розпізнаванням ключового слова.
Ці активаційні слова розпізнаються на пристрої, а не в хмарі. Розумні пристрої мають невеликі AI-моделі, які працюють на пристрої, слухаючи активаційне слово, і коли воно виявляється, починають передавати аудіо в хмару для розпізнавання. Ці моделі дуже спеціалізовані й слухають лише активаційне слово.
💁 Деякі технологічні компанії додають більше конфіденційності до своїх пристроїв, виконуючи частину перетворення мови в текст безпосередньо на пристрої. Apple оголосила, що в рамках оновлень iOS і macOS 2021 року вони підтримуватимуть перетворення мови в текст на пристрої та зможуть обробляти багато запитів без необхідності використання хмари. Це стало можливим завдяки потужним процесорам у їхніх пристроях, які можуть запускати ML-моделі.
✅ Як ви вважаєте, які наслідки для конфіденційності та етики має зберігання аудіо, відправленого в хмару? Чи слід зберігати це аудіо, і якщо так, то як? Чи вважаєте ви використання записів для правоохоронних органів виправданим компромісом за рахунок втрати конфіденційності?
Виявлення активаційного слова зазвичай використовує техніку, відому як TinyML, яка дозволяє адаптувати ML-моделі для роботи на мікроконтролерах. Ці моделі мають невеликий розмір і споживають дуже мало енергії.
Щоб уникнути складнощів із навчанням і використанням моделі для активаційного слова, розумний таймер, який ви створюєте в цьому уроці, використовуватиме кнопку для активації розпізнавання мови.
💁 Якщо ви хочете спробувати створити модель для виявлення активаційного слова, яка працюватиме на Wio Terminal або Raspberry Pi, ознайомтеся з цим підручником від Edge Impulse про реагування на ваш голос. Якщо ви хочете використовувати свій комп’ютер для цього, спробуйте швидкий старт із налаштування власного ключового слова на Microsoft Docs.
Перетворення мови в текст
![]()
Як і у випадку з класифікацією зображень у попередньому проєкті, існують готові AI-сервіси, які можуть приймати мову у вигляді аудіофайлу та перетворювати її на текст. Одним із таких сервісів є Speech Service, частина Cognitive Services — готових AI-сервісів, які ви можете використовувати у своїх додатках.
Завдання — налаштувати ресурс AI для роботи з мовою
-
Створіть групу ресурсів для цього проєкту під назвою
smart-timer. -
Використовуйте наступну команду для створення безкоштовного ресурсу для роботи з мовою:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>Замініть
<location>на місце розташування, яке ви використовували під час створення групи ресурсів. -
Вам знадобиться API-ключ для доступу до ресурсу мови з вашого коду. Виконайте наступну команду, щоб отримати ключ:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableСкопіюйте один із ключів.
Завдання — перетворити мову в текст
Виконайте відповідний посібник для перетворення мови в текст на вашому IoT-пристрої:
- Arduino - Wio Terminal
- Одноплатний комп’ютер - Raspberry Pi
- Одноплатний комп’ютер - Віртуальний пристрій
🚀 Виклик
Розпізнавання мови існує вже давно і постійно вдосконалюється. Дослідіть сучасні можливості та порівняйте, як вони еволюціонували з часом, включаючи точність машинних транскрипцій у порівнянні з людськими.
Як ви вважаєте, що чекає на розпізнавання мови в майбутньому?
Тест після лекції
Огляд і самостійне навчання
- Прочитайте про різні типи мікрофонів і як вони працюють у статті на Musician's HQ про різницю між динамічними та конденсаторними мікрофонами.
- Дізнайтеся більше про сервіс розпізнавання мови Cognitive Services у документації Microsoft Docs.
- Прочитайте про виявлення ключових слів у документації Microsoft Docs про розпізнавання ключових слів.
Завдання
Відмова від відповідальності:
Цей документ був перекладений за допомогою сервісу автоматичного перекладу Co-op Translator. Хоча ми прагнемо до точності, будь ласка, майте на увазі, що автоматичні переклади можуть містити помилки або неточності. Оригінальний документ на його рідній мові слід вважати авторитетним джерелом. Для критичної інформації рекомендується професійний людський переклад. Ми не несемо відповідальності за будь-які непорозуміння або неправильні тлумачення, що виникають внаслідок використання цього перекладу.