21 KiB
Pagkilala sa boses gamit ang IoT device
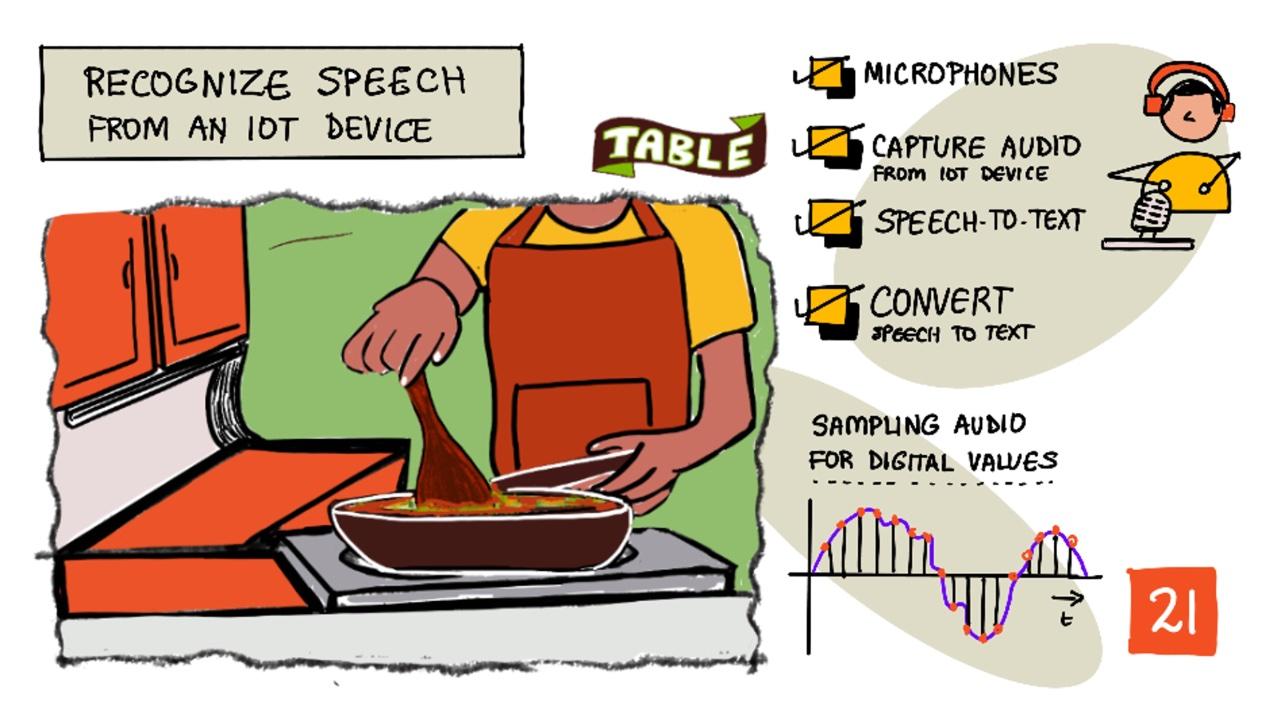
Sketchnote ni Nitya Narasimhan. I-click ang imahe para sa mas malaking bersyon.
Ang video na ito ay nagbibigay ng overview ng Azure speech service, isang paksa na tatalakayin sa araling ito:

🎥 I-click ang imahe sa itaas para panoorin ang video
Pre-lecture quiz
Panimula
'Alexa, mag-set ng 12 minutong timer'
'Alexa, ano ang status ng timer'
'Alexa, mag-set ng 8 minutong timer na tinatawag na steam broccoli'
Ang mga smart device ay nagiging mas laganap. Hindi lamang bilang mga smart speaker tulad ng HomePods, Echos, at Google Homes, kundi pati na rin sa ating mga telepono, relo, at maging sa mga ilaw at thermostat.
💁 Mayroon akong hindi bababa sa 19 na device sa bahay na may voice assistants, at iyon ay ang mga alam ko lang!
Ang voice control ay nagpapataas ng accessibility sa pamamagitan ng pagbibigay-daan sa mga taong may limitadong galaw na makipag-ugnayan sa mga device. Mula sa permanenteng kapansanan tulad ng pagiging ipinanganak na walang braso, hanggang sa pansamantalang kapansanan tulad ng nabaling braso, o kapag puno ang mga kamay ng pamimili o pag-aalaga ng bata, ang kakayahang kontrolin ang ating mga bahay gamit ang boses sa halip na mga kamay ay nagbubukas ng mundo ng access. Ang pagsigaw ng 'Hey Siri, isara ang pintuan ng garahe' habang nag-aalaga ng sanggol at makulit na bata ay maaaring maging maliit ngunit epektibong pagpapabuti sa buhay.
Isa sa mga pinakasikat na gamit ng voice assistants ay ang pag-set ng timer, lalo na ang mga kitchen timer. Ang kakayahang mag-set ng maraming timer gamit lamang ang boses ay malaking tulong sa kusina - hindi na kailangang huminto sa pagmamasa ng dough, paghalo ng sopas, o paglilinis ng dumpling filling sa mga kamay para gumamit ng pisikal na timer.
Sa araling ito, matututo ka tungkol sa pagbuo ng voice recognition sa IoT devices. Matututo ka tungkol sa mga mikropono bilang sensors, kung paano kumuha ng audio mula sa mikropono na nakakabit sa IoT device, at kung paano gamitin ang AI para i-convert ang naririnig sa text. Sa buong proyekto, magtatayo ka ng smart kitchen timer na kayang mag-set ng timer gamit ang boses sa iba't ibang wika.
Sa araling ito, tatalakayin natin:
- Mga Mikropono
- Pagkuha ng audio mula sa iyong IoT device
- Speech to text
- Pag-convert ng speech sa text
Mga Mikropono
Ang mga mikropono ay analog sensors na nagko-convert ng sound waves sa electrical signals. Ang vibrations sa hangin ay nagdudulot ng paggalaw ng mga bahagi sa mikropono, na nagdudulot ng maliliit na pagbabago sa electrical signals. Ang mga pagbabagong ito ay pinapalakas upang makabuo ng electrical output.
Mga Uri ng Mikropono
Ang mga mikropono ay may iba't ibang uri:
-
Dynamic - Ang dynamic microphones ay may magnet na nakakabit sa isang gumagalaw na diaphragm na gumagalaw sa isang coil ng wire na lumilikha ng electrical current. Ito ay kabaligtaran ng karamihan sa mga loudspeakers, na gumagamit ng electrical current upang gumalaw ang magnet sa coil ng wire, gumagalaw ang diaphragm upang lumikha ng tunog. Nangangahulugan ito na ang mga speakers ay maaaring gamitin bilang dynamic microphones, at ang dynamic microphones ay maaaring gamitin bilang speakers. Sa mga device tulad ng intercoms kung saan ang user ay nakikinig o nagsasalita, ngunit hindi pareho, isang device ang maaaring kumilos bilang parehong speaker at mikropono.
Ang dynamic microphones ay hindi nangangailangan ng power upang gumana, ang electrical signal ay nililikha nang buo mula sa mikropono.

-
Ribbon - Ang ribbon microphones ay katulad ng dynamic microphones, maliban na mayroon silang metal ribbon sa halip na diaphragm. Ang ribbon na ito ay gumagalaw sa magnetic field na lumilikha ng electrical current. Tulad ng dynamic microphones, ang ribbon microphones ay hindi nangangailangan ng power upang gumana.

-
Condenser - Ang condenser microphones ay may manipis na metal diaphragm at fixed metal backplate. Ang kuryente ay inilalapat sa pareho ng mga ito at habang ang diaphragm ay nag-vibrate, ang static charge sa pagitan ng mga plates ay nagbabago na lumilikha ng signal. Ang condenser microphones ay nangangailangan ng power upang gumana - tinatawag na Phantom power.
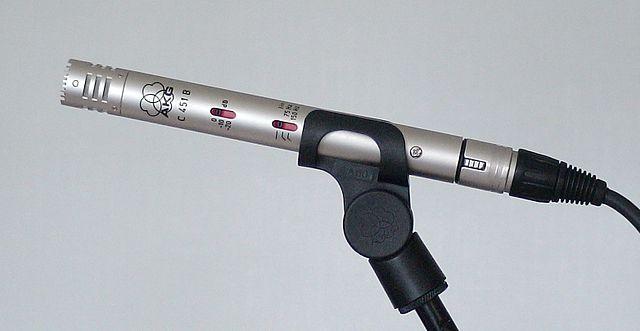
-
MEMS - Ang Microelectromechanical systems microphones, o MEMS, ay mga mikropono sa isang chip. Mayroon silang pressure sensitive diaphragm na naka-etch sa isang silicon chip, at gumagana katulad ng condenser microphone. Ang mga mikroponong ito ay maaaring maging napakaliit, at isinama sa circuitry.

Sa imahe sa itaas, ang chip na may label na LEFT ay isang MEMS microphone, na may napakaliit na diaphragm na mas mababa sa isang millimeter ang lapad.
✅ Mag-research: Anong mga mikropono ang mayroon sa paligid mo - sa iyong computer, telepono, headset, o sa iba pang mga device? Anong uri ng mga mikropono ang mga ito?
Digital na Audio
Ang audio ay isang analog signal na nagdadala ng napaka-pinong impormasyon. Upang i-convert ang signal na ito sa digital, ang audio ay kailangang i-sample ng libu-libong beses bawat segundo.
🎓 Ang sampling ay ang pag-convert ng audio signal sa digital na halaga na kumakatawan sa signal sa puntong iyon ng oras.
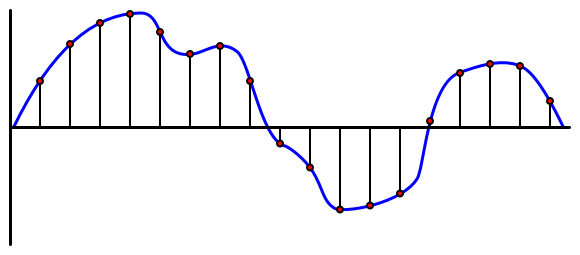
Ang digital na audio ay sinasample gamit ang Pulse Code Modulation, o PCM. Ang PCM ay kinabibilangan ng pagbabasa ng boltahe ng signal, at pagpili ng pinakamalapit na discrete value sa boltahe gamit ang isang tinukoy na laki.
💁 Maaari mong isipin ang PCM bilang sensor version ng pulse width modulation, o PWM (Ang PWM ay tinalakay sa lesson 3 ng getting started project). Ang PCM ay kinabibilangan ng pag-convert ng analog signal sa digital, ang PWM ay kinabibilangan ng pag-convert ng digital signal sa analog.
Halimbawa, karamihan sa mga streaming music services ay nag-aalok ng 16-bit o 24-bit audio. Nangangahulugan ito na kino-convert nila ang boltahe sa isang halaga na kasya sa isang 16-bit integer, o 24-bit integer. Ang 16-bit audio ay kasya sa halaga sa isang numero na nasa saklaw mula -32,768 hanggang 32,767, ang 24-bit ay nasa saklaw −8,388,608 hanggang 8,388,607. Ang mas maraming bits, mas malapit ang sample sa kung ano ang aktwal na naririnig ng ating mga tainga.
💁 Maaaring narinig mo ang 8-bit audio, na madalas tinatawag na LoFi. Ito ay audio na sinample gamit lamang ang 8-bits, kaya -128 hanggang 127. Ang unang computer audio ay limitado sa 8 bits dahil sa hardware limitations, kaya madalas itong nakikita sa retro gaming.
Ang mga sample na ito ay kinukuha ng libu-libong beses bawat segundo, gamit ang well-defined sample rates na sinusukat sa KHz (libu-libong readings bawat segundo). Ang mga streaming music services ay gumagamit ng 48KHz para sa karamihan ng audio, ngunit ang ilang 'lossless' audio ay gumagamit ng hanggang 96KHz o kahit 192KHz. Ang mas mataas na sample rate, mas malapit sa orihinal ang audio, hanggang sa isang punto. May debate kung ang mga tao ay makakaramdam ng pagkakaiba sa itaas ng 48KHz.
✅ Mag-research: Kung gumagamit ka ng streaming music service, anong sample rate at size ang ginagamit nito? Kung gumagamit ka ng CDs, ano ang sample rate at size ng CD audio?
Mayroong iba't ibang format para sa audio data. Marahil narinig mo na ang mp3 files - audio data na compressed upang gawing mas maliit nang hindi nawawala ang kalidad. Ang uncompressed audio ay madalas na nakaimbak bilang WAV file - ito ay isang file na may 44 bytes ng header information, na sinusundan ng raw audio data. Ang header ay naglalaman ng impormasyon tulad ng sample rate (halimbawa 16000 para sa 16KHz) at sample size (16 para sa 16-bit), at ang bilang ng channels. Pagkatapos ng header, ang WAV file ay naglalaman ng raw audio data.
🎓 Ang channels ay tumutukoy sa kung ilang iba't ibang audio streams ang bumubuo sa audio. Halimbawa, para sa stereo audio na may kaliwa at kanan, magkakaroon ng 2 channels. Para sa 7.1 surround sound para sa home theater system, ito ay magiging 8.
Laki ng Audio Data
Ang audio data ay medyo malaki. Halimbawa, ang pagkuha ng uncompressed 16-bit audio sa 16KHz (isang sapat na rate para sa paggamit sa speech to text model), ay kumukuha ng 32KB ng data para sa bawat segundo ng audio:
- Ang 16-bit ay nangangahulugan ng 2 bytes bawat sample (1 byte ay 8 bits).
- Ang 16KHz ay 16,000 samples bawat segundo.
- 16,000 x 2 bytes = 32,000 bytes bawat segundo.
Mukhang maliit ang dami ng data na ito, ngunit kung gumagamit ka ng microcontroller na may limitadong memory, ito ay maaaring maging marami. Halimbawa, ang Wio Terminal ay may 192KB ng memory, at kailangang mag-imbak ng program code at variables. Kahit na ang iyong program code ay napakaliit, hindi ka maaaring kumuha ng higit sa 5 segundo ng audio.
Ang mga microcontroller ay maaaring mag-access ng karagdagang storage, tulad ng SD cards o flash memory. Kapag gumagawa ng IoT device na kumukuha ng audio, kailangan mong tiyakin na hindi lamang mayroon kang karagdagang storage, ngunit ang iyong code ay nagsusulat ng audio na nakuha mula sa mikropono nang direkta sa storage, at kapag ipinapadala ito sa cloud, ikaw ay nag-stream mula sa storage papunta sa web request. Sa ganitong paraan, maiiwasan mong maubusan ng memory sa pamamagitan ng pagtatangkang hawakan ang buong block ng audio data sa memory nang sabay-sabay.
Pagkuha ng audio mula sa iyong IoT device
Ang iyong IoT device ay maaaring ikonekta sa mikropono upang kumuha ng audio, handa na para sa conversion sa text. Maaari rin itong ikonekta sa speakers upang mag-output ng audio. Sa mga susunod na aralin, ito ay gagamitin upang magbigay ng audio feedback, ngunit kapaki-pakinabang na i-set up ang speakers ngayon upang subukan ang mikropono.
Gawain - i-configure ang iyong mikropono at speakers
Sundin ang kaukulang gabay upang i-configure ang mikropono at speakers para sa iyong IoT device:
Gawain - kumuha ng audio
Sundin ang kaukulang gabay upang kumuha ng audio sa iyong IoT device:
Speech to text
Ang Speech to text, o speech recognition, ay kinabibilangan ng paggamit ng AI upang i-convert ang mga salita sa audio signal sa text.
Mga Modelo ng Speech Recognition
Upang i-convert ang speech sa text, ang mga sample mula sa audio signal ay pinagsama-sama at ipinapasok sa isang machine learning model na nakabase sa Recurrent Neural Network (RNN). Ito ay isang uri ng machine learning model na maaaring gumamit ng nakaraang data upang gumawa ng desisyon tungkol sa papasok na data. Halimbawa, ang RNN ay maaaring makakita ng isang block ng audio samples bilang tunog na 'Hel', at kapag nakatanggap ito ng isa pa na iniisip nitong tunog na 'lo', maaari nitong pagsamahin ito sa nakaraang tunog, hanapin na ang 'Hello' ay isang valid na salita at piliin iyon bilang resulta.
Ang mga ML models ay palaging tumatanggap ng data na may parehong laki sa bawat oras. Ang image classifier na ginawa mo sa isang naunang aralin ay nagre-resize ng mga imahe sa isang fixed size at pinoproseso ang mga ito. Ganito rin sa speech models, kailangan nilang magproseso ng fixed sized audio chunks. Ang speech models ay kailangang magawang pagsamahin ang mga output ng maraming predictions upang makuha ang sagot, upang payagan itong makilala sa pagitan ng 'Hi' at 'Highway', o 'flock' at 'floccinaucinihilipilification'.
Ang mga speech models ay sapat na advanced upang maunawaan ang konteksto, at maaaring itama ang mga salitang kanilang nadetect habang mas maraming tunog ang napoproseso. Halimbawa, kung sasabihin mo "Pumunta ako sa tindahan para kumuha ng dalawang saging at isang mansanas din", gagamit ka ng tatlong salita na pareho ang tunog ngunit magkaiba ang spelling - to, two, at too. Ang mga speech models ay kayang maunawaan ang konteksto at gamitin ang tamang spelling ng salita. 💁 Ang ilang mga serbisyo sa pagsasalita ay nagbibigay-daan sa pag-customize upang mas gumana ang mga ito sa maingay na kapaligiran tulad ng mga pabrika, o sa mga salitang partikular sa industriya tulad ng mga pangalan ng kemikal. Ang mga customizations na ito ay sinasanay sa pamamagitan ng pagbibigay ng sample na audio at transcription, at gumagana gamit ang transfer learning, katulad ng kung paano ka nagsanay ng isang image classifier gamit lamang ang ilang mga larawan sa isang naunang aralin.
Privacy
Kapag gumagamit ng speech to text sa isang consumer IoT device, napakahalaga ng privacy. Ang mga device na ito ay patuloy na nakikinig sa audio, kaya bilang isang consumer, ayaw mong lahat ng sinasabi mo ay mapunta sa cloud at ma-convert sa text. Bukod sa magastos ito sa Internet bandwidth, may malalaking implikasyon ito sa privacy, lalo na kapag ang ilang gumagawa ng smart device ay random na pumipili ng audio para sa mga tao na mag-validate laban sa text na nabuo upang mapabuti ang kanilang modelo.
Gusto mo lang na ang iyong smart device ay magpadala ng audio sa cloud para sa pagproseso kapag ginagamit mo ito, hindi kapag nakakarinig ito ng audio sa iyong bahay, audio na maaaring maglaman ng mga pribadong pagpupulong o maseselang interaksyon. Ang paraan ng karamihan sa mga smart device ay gumagana ay sa pamamagitan ng isang wake word, isang key phrase tulad ng "Alexa", "Hey Siri", o "OK Google" na nagiging sanhi ng pag-'gising' ng device at makinig sa sinasabi mo hanggang sa matukoy nito ang isang pahinga sa iyong pagsasalita, na nagpapahiwatig na natapos ka nang magsalita sa device.
🎓 Ang wake word detection ay tinatawag din na Keyword spotting o Keyword recognition.
Ang mga wake word na ito ay natutukoy sa device, hindi sa cloud. Ang mga smart device na ito ay may maliliit na AI models na tumatakbo sa device na nakikinig para sa wake word, at kapag ito ay natukoy, nagsisimula itong mag-stream ng audio sa cloud para sa pagkilala. Ang mga modelong ito ay napaka-espesyalista, at nakikinig lamang para sa wake word.
💁 Ang ilang mga tech company ay nagdadagdag ng mas maraming privacy sa kanilang mga device at ginagawa ang bahagi ng speech to text conversion sa device. Inanunsyo ng Apple na bilang bahagi ng kanilang 2021 iOS at macOS updates, susuportahan nila ang speech to text conversion sa device, at magagawang hawakan ang maraming mga kahilingan nang hindi kinakailangang gumamit ng cloud. Ito ay dahil sa pagkakaroon ng makapangyarihang processors sa kanilang mga device na maaaring magpatakbo ng ML models.
✅ Ano sa tingin mo ang mga implikasyon sa privacy at etika ng pag-iimbak ng audio na ipinadala sa cloud? Dapat bang iimbak ang audio na ito, at kung oo, paano? Sa tingin mo ba ang paggamit ng recordings para sa law enforcement ay isang magandang kapalit para sa pagkawala ng privacy?
Ang wake word detection ay karaniwang gumagamit ng isang teknik na tinatawag na TinyML, na nagko-convert ng ML models upang magamit sa microcontrollers. Ang mga modelong ito ay maliit ang sukat, at napakaliit ng konsumo sa enerhiya upang patakbuhin.
Upang maiwasan ang komplikasyon ng pag-train at paggamit ng wake word model, ang smart timer na iyong itatayo sa araling ito ay gagamit ng button upang i-on ang speech recognition.
💁 Kung nais mong subukan ang paggawa ng wake word detection model na tumatakbo sa Wio Terminal o Raspberry Pi, tingnan ang responding to your voice tutorial ng Edge Impulse. Kung nais mong gamitin ang iyong computer para dito, maaari mong subukan ang get started with Custom Keyword quickstart sa Microsoft docs.
Convert speech to text
![]()
Katulad ng image classification sa isang naunang proyekto, may mga pre-built AI services na maaaring kumuha ng speech bilang audio file at i-convert ito sa text. Isa sa mga serbisyong ito ay ang Speech Service, bahagi ng Cognitive Services, mga pre-built AI services na maaari mong gamitin sa iyong apps.
Task - mag-configure ng speech AI resource
-
Gumawa ng Resource Group para sa proyektong ito na tinatawag na
smart-timer -
Gamitin ang sumusunod na command upang gumawa ng libreng speech resource:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>Palitan ang
<location>ng lokasyon na ginamit mo nang gumawa ng Resource Group. -
Kakailanganin mo ng API key upang ma-access ang speech resource mula sa iyong code. Patakbuhin ang sumusunod na command upang makuha ang key:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableKopyahin ang isa sa mga keys.
Task - i-convert ang speech sa text
Sundan ang kaukulang gabay upang i-convert ang speech sa text sa iyong IoT device:
🚀 Hamon
Ang speech recognition ay matagal nang umiiral, at patuloy na umuunlad. Mag-research tungkol sa kasalukuyang kakayahan nito at ikumpara kung paano ito nag-evolve sa paglipas ng panahon, kabilang ang kung gaano katumpak ang machine transcriptions kumpara sa tao.
Ano sa tingin mo ang hinaharap ng speech recognition?
Post-lecture quiz
Review & Self Study
- Basahin ang tungkol sa iba't ibang uri ng mikropono at kung paano ito gumagana sa what's the difference between dynamic and condenser microphones article sa Musician's HQ.
- Magbasa pa tungkol sa Cognitive Services speech service sa speech service documentation sa Microsoft Docs
- Basahin ang tungkol sa keyword spotting sa keyword recognition documentation sa Microsoft Docs
Assignment
Paunawa:
Ang dokumentong ito ay isinalin gamit ang AI translation service na Co-op Translator. Bagama't sinisikap naming maging tumpak, tandaan na ang mga awtomatikong pagsasalin ay maaaring maglaman ng mga pagkakamali o hindi pagkakatugma. Ang orihinal na dokumento sa kanyang katutubong wika ang dapat ituring na opisyal na pinagmulan. Para sa mahalagang impormasyon, inirerekomenda ang propesyonal na pagsasalin ng tao. Hindi kami mananagot sa anumang hindi pagkakaunawaan o maling interpretasyon na dulot ng paggamit ng pagsasaling ito.