40 KiB
การรู้จำเสียงด้วยอุปกรณ์ IoT
สเก็ตโน้ตโดย Nitya Narasimhan คลิกที่ภาพเพื่อดูเวอร์ชันขนาดใหญ่
วิดีโอนี้ให้ภาพรวมเกี่ยวกับบริการเสียงของ Azure ซึ่งเป็นหัวข้อที่จะครอบคลุมในบทเรียนนี้:

🎥 คลิกที่ภาพด้านบนเพื่อดูวิดีโอ
แบบทดสอบก่อนเรียน
บทนำ
'อเล็กซ่า ตั้งเวลานับถอยหลัง 12 นาที'
'อเล็กซ่า สถานะของตัวจับเวลา'
'อเล็กซ่า ตั้งเวลานับถอยหลัง 8 นาที ชื่อว่า "นึ่งบร็อคโคลี่"'
อุปกรณ์อัจฉริยะกำลังแพร่หลายมากขึ้นเรื่อย ๆ ไม่ใช่แค่ลำโพงอัจฉริยะอย่าง HomePods, Echos และ Google Homes แต่ยังฝังอยู่ในโทรศัพท์มือถือ นาฬิกา และแม้กระทั่งในหลอดไฟและเทอร์โมสแตท
💁 ในบ้านของฉันมีอุปกรณ์อย่างน้อย 19 ชิ้นที่มีผู้ช่วยเสียง และนั่นเป็นเพียงอุปกรณ์ที่ฉันรู้จัก!
การควบคุมด้วยเสียงช่วยเพิ่มการเข้าถึงโดยให้ผู้ที่มีการเคลื่อนไหวจำกัดสามารถโต้ตอบกับอุปกรณ์ได้ ไม่ว่าจะเป็นความพิการถาวร เช่น การเกิดมาโดยไม่มีแขน หรือความพิการชั่วคราว เช่น แขนหัก หรือการมีมือที่เต็มไปด้วยของช้อปปิ้งหรือเด็กเล็ก การควบคุมบ้านด้วยเสียงแทนมือช่วยเปิดโลกแห่งการเข้าถึง การตะโกนว่า 'เฮ้ Siri ปิดประตูโรงรถของฉัน' ในขณะที่กำลังเปลี่ยนผ้าอ้อมเด็กและจัดการกับเด็กเล็กที่ซน อาจเป็นการปรับปรุงเล็ก ๆ แต่มีประสิทธิภาพในชีวิต
หนึ่งในวิธีการใช้งานผู้ช่วยเสียงที่ได้รับความนิยมมากที่สุดคือการตั้งเวลานับถอยหลัง โดยเฉพาะตัวจับเวลาในครัว การตั้งตัวจับเวลาหลายตัวด้วยเสียงของคุณเป็นความช่วยเหลือที่ยอดเยี่ยมในครัว - ไม่จำเป็นต้องหยุดนวดแป้ง คนซุป หรือทำความสะอาดมือที่เปื้อนไส้เกี๊ยวเพื่อใช้ตัวจับเวลาแบบกายภาพ
ในบทเรียนนี้ คุณจะได้เรียนรู้เกี่ยวกับการสร้างการรู้จำเสียงในอุปกรณ์ IoT คุณจะได้เรียนรู้เกี่ยวกับไมโครโฟนในฐานะเซ็นเซอร์ วิธีการจับเสียงจากไมโครโฟนที่เชื่อมต่อกับอุปกรณ์ IoT และวิธีการใช้ AI เพื่อแปลงสิ่งที่ได้ยินเป็นข้อความ ในโครงการที่เหลือ คุณจะสร้างตัวจับเวลาในครัวอัจฉริยะที่สามารถตั้งตัวจับเวลาหลายตัวด้วยเสียงของคุณในหลายภาษา
ในบทเรียนนี้เราจะครอบคลุม:
ไมโครโฟน
ไมโครโฟนเป็นเซ็นเซอร์แบบแอนะล็อกที่แปลงคลื่นเสียงเป็นสัญญาณไฟฟ้า การสั่นสะเทือนในอากาศทำให้ส่วนประกอบในไมโครโฟนเคลื่อนที่เล็กน้อย และสิ่งนี้ทำให้เกิดการเปลี่ยนแปลงเล็กน้อยในสัญญาณไฟฟ้า การเปลี่ยนแปลงเหล่านี้จะถูกขยายเพื่อสร้างสัญญาณไฟฟ้าออกมา
ประเภทของไมโครโฟน
ไมโครโฟนมีหลากหลายประเภท:
-
ไดนามิก - ไมโครโฟนไดนามิกมีแม่เหล็กที่ติดอยู่กับไดอะแฟรมที่เคลื่อนที่ในขดลวดลวด สร้างกระแสไฟฟ้า นี่เป็นกระบวนการตรงข้ามกับลำโพงส่วนใหญ่ที่ใช้กระแสไฟฟ้าเพื่อเคลื่อนแม่เหล็กในขดลวดลวด ทำให้ไดอะแฟรมเคลื่อนที่เพื่อสร้างเสียง ซึ่งหมายความว่าลำโพงสามารถใช้เป็นไมโครโฟนไดนามิก และไมโครโฟนไดนามิกสามารถใช้เป็นลำโพงได้ ในอุปกรณ์เช่นอินเตอร์คอมที่ผู้ใช้ฟังหรือพูด แต่ไม่ใช่ทั้งสองอย่าง อุปกรณ์หนึ่งสามารถทำหน้าที่เป็นทั้งลำโพงและไมโครโฟน
ไมโครโฟนไดนามิกไม่ต้องการพลังงานในการทำงาน สัญญาณไฟฟ้าถูกสร้างขึ้นทั้งหมดจากไมโครโฟน

-
ริบบอน - ไมโครโฟนริบบอนคล้ายกับไมโครโฟนไดนามิก แต่มีริบบอนโลหะแทนไดอะแฟรม ริบบอนนี้เคลื่อนที่ในสนามแม่เหล็กสร้างกระแสไฟฟ้า เช่นเดียวกับไมโครโฟนไดนามิก ไมโครโฟนริบบอนไม่ต้องการพลังงานในการทำงาน

-
คอนเดนเซอร์ - ไมโครโฟนคอนเดนเซอร์มีไดอะแฟรมโลหะบางและแผ่นหลังโลหะที่ติดตั้งอยู่ ไฟฟ้าจะถูกจ่ายไปยังทั้งสองส่วนนี้ และเมื่อไดอะแฟรมสั่นสะเทือน ประจุไฟฟ้าสถิตระหว่างแผ่นจะเปลี่ยนแปลง สร้างสัญญาณ ไมโครโฟนคอนเดนเซอร์ต้องการพลังงานในการทำงาน ซึ่งเรียกว่า Phantom power
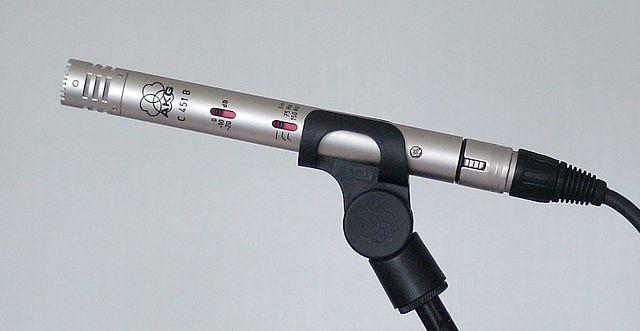
-
MEMS - ไมโครโฟนระบบไมโครอิเล็กทรอนิกส์ หรือ MEMS เป็นไมโครโฟนบนชิป มีไดอะแฟรมที่ไวต่อแรงดันซึ่งถูกแกะสลักลงบนชิปซิลิคอน และทำงานคล้ายกับไมโครโฟนคอนเดนเซอร์ ไมโครโฟนเหล่านี้สามารถมีขนาดเล็กมาก และรวมเข้ากับวงจรได้

ในภาพด้านบน ชิปที่มีป้าย LEFT คือไมโครโฟน MEMS ที่มีไดอะแฟรมขนาดเล็กน้อยกว่ามิลลิเมตร
✅ ทำการค้นคว้า: คุณมีไมโครโฟนประเภทใดรอบตัวคุณ - ไม่ว่าจะในคอมพิวเตอร์ โทรศัพท์มือถือ หูฟัง หรือในอุปกรณ์อื่น ๆ ไมโครโฟนเหล่านั้นเป็นประเภทใด?
เสียงดิจิทัล
เสียงเป็นสัญญาณแอนะล็อกที่มีข้อมูลละเอียดอ่อนมาก ในการแปลงสัญญาณนี้เป็นดิจิทัล เสียงต้องถูกสุ่มตัวอย่างหลายพันครั้งต่อวินาที
🎓 การสุ่มตัวอย่างคือการแปลงสัญญาณเสียงเป็นค่าดิจิทัลที่แสดงถึงสัญญาณในช่วงเวลานั้น
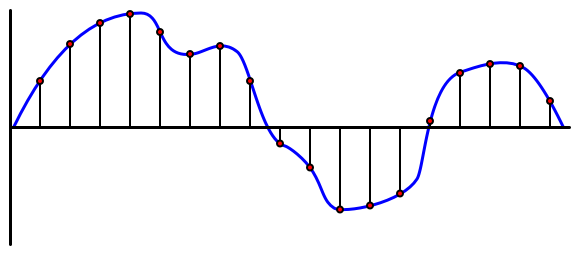
เสียงดิจิทัลถูกสุ่มตัวอย่างโดยใช้ Pulse Code Modulation หรือ PCM PCM เกี่ยวข้องกับการอ่านแรงดันไฟฟ้าของสัญญาณ และเลือกค่าดิจิทัลที่ใกล้เคียงที่สุดกับแรงดันไฟฟ้านั้นโดยใช้ขนาดที่กำหนด
💁 คุณสามารถคิดว่า PCM เป็นเวอร์ชันเซ็นเซอร์ของ Pulse Width Modulation หรือ PWM (PWM ถูกครอบคลุมใน บทเรียนที่ 3 ของโครงการเริ่มต้น) PCM เกี่ยวข้องกับการแปลงสัญญาณแอนะล็อกเป็นดิจิทัล PWM เกี่ยวข้องกับการแปลงสัญญาณดิจิทัลเป็นแอนะล็อก
ตัวอย่างเช่น บริการสตรีมเพลงส่วนใหญ่เสนอเสียง 16 บิตหรือ 24 บิต ซึ่งหมายความว่าพวกเขาแปลงแรงดันไฟฟ้าเป็นค่าที่พอดีกับจำนวนเต็ม 16 บิต หรือ 24 บิต เสียง 16 บิตพอดีกับค่าที่อยู่ในช่วง -32,768 ถึง 32,767 เสียง 24 บิตอยู่ในช่วง −8,388,608 ถึง 8,388,607 ยิ่งบิตมากเท่าไหร่ ตัวอย่างก็ยิ่งใกล้เคียงกับสิ่งที่หูของเราได้ยินจริง ๆ มากขึ้นเท่านั้น
💁 คุณอาจเคยได้ยินเสียง 8 บิต ซึ่งมักเรียกว่า LoFi นี่คือเสียงที่สุ่มตัวอย่างโดยใช้เพียง 8 บิต ดังนั้น -128 ถึง 127 เสียงคอมพิวเตอร์แรกถูกจำกัดไว้ที่ 8 บิตเนื่องจากข้อจำกัดของฮาร์ดแวร์ ดังนั้นจึงมักพบในเกมย้อนยุค
ตัวอย่างเหล่านี้ถูกนำมาหลายพันครั้งต่อวินาที โดยใช้อัตราการสุ่มตัวอย่างที่กำหนดไว้อย่างดีซึ่งวัดเป็น KHz (การอ่านหลายพันครั้งต่อวินาที) บริการสตรีมเพลงใช้ 48KHz สำหรับเสียงส่วนใหญ่ แต่เสียง 'lossless' บางประเภทใช้สูงถึง 96KHz หรือแม้แต่ 192KHz ยิ่งอัตราการสุ่มตัวอย่างสูงเท่าไหร่ เสียงก็ยิ่งใกล้เคียงกับต้นฉบับมากขึ้นเท่านั้น จนถึงจุดหนึ่ง มีการถกเถียงกันว่ามนุษย์สามารถบอกความแตกต่างได้หรือไม่เมื่อเกิน 48KHz
✅ ทำการค้นคว้า: หากคุณใช้บริการสตรีมเพลง อัตราการสุ่มตัวอย่างและขนาดที่ใช้คืออะไร? หากคุณใช้ซีดี อัตราการสุ่มตัวอย่างและขนาดของเสียงซีดีคืออะไร?
มีรูปแบบข้อมูลเสียงที่แตกต่างกันหลายรูปแบบ คุณอาจเคยได้ยินไฟล์ mp3 - ข้อมูลเสียงที่ถูกบีบอัดเพื่อให้มีขนาดเล็กลงโดยไม่สูญเสียคุณภาพ เสียงที่ไม่ถูกบีบอัดมักถูกจัดเก็บเป็นไฟล์ WAV - นี่คือไฟล์ที่มีข้อมูลส่วนหัว 44 ไบต์ ตามด้วยข้อมูลเสียงดิบ ส่วนหัวมีข้อมูลเช่นอัตราการสุ่มตัวอย่าง (เช่น 16000 สำหรับ 16KHz) และขนาดตัวอย่าง (16 สำหรับ 16 บิต) และจำนวนช่อง หลังจากส่วนหัว ไฟล์ WAV จะมีข้อมูลเสียงดิบ
🎓 ช่องหมายถึงจำนวนสตรีมเสียงที่แตกต่างกันซึ่งประกอบเป็นเสียง ตัวอย่างเช่น สำหรับเสียงสเตอริโอที่มีซ้ายและขวา จะมี 2 ช่อง สำหรับเสียงรอบทิศทาง 7.1 สำหรับระบบโฮมเธียเตอร์ จะมี 8 ช่อง
ขนาดข้อมูลเสียง
ข้อมูลเสียงมีขนาดค่อนข้างใหญ่ ตัวอย่างเช่น การจับเสียง 16 บิตที่ไม่ถูกบีบอัดที่ 16KHz (อัตราที่ดีพอสำหรับการใช้งานกับโมเดลแปลงเสียงเป็นข้อความ) ใช้ข้อมูล 32KB สำหรับเสียงหนึ่งวินาที:
- 16 บิต หมายถึง 2 ไบต์ต่อหนึ่งตัวอย่าง (1 ไบต์คือ 8 บิต)
- 16KHz คือ 16,000 ตัวอย่างต่อวินาที
- 16,000 x 2 ไบต์ = 32,000 ไบต์ต่อวินาที
นี่อาจฟังดูเป็นข้อมูลจำนวนเล็กน้อย แต่หากคุณใช้ไมโครคอนโทรลเลอร์ที่มีหน่วยความจำจำกัด นี่อาจเป็นจำนวนมาก ตัวอย่างเช่น Wio Terminal มีหน่วยความจำ 192KB และต้องเก็บโค้ดโปรแกรมและตัวแปร แม้ว่าโค้ดโปรแกรมของคุณจะเล็กมาก คุณก็ไม่สามารถจับเสียงได้เกิน 5 วินาที
ไมโครคอนโทรลเลอร์สามารถเข้าถึงพื้นที่จัดเก็บเพิ่มเติม เช่น การ์ด SD หรือหน่วยความจำแฟลช เมื่อสร้างอุปกรณ์ IoT ที่จับเสียง คุณจะต้องมั่นใจว่าไม่เพียงแต่คุณมีพื้นที่จัดเก็บเพิ่มเติม แต่โค้ดของคุณเขียนเสียงที่จับได้จากไมโครโฟนโดยตรงไปยังพื้นที่จัดเก็บ และเมื่อส่งไปยังคลาวด์ คุณสตรีมจากพื้นที่จัดเก็บไปยังคำขอเว็บ ด้วยวิธีนี้คุณสามารถหลีกเลี่ยงการใช้หน่วยความจำหมดโดยพยายามเก็บข้อมูลเสียงทั้งหมดในหน่วยความจำพร้อมกัน
การจับเสียงจากอุปกรณ์ IoT ของคุณ
อุปกรณ์ IoT ของคุณสามารถเชื่อมต่อกับไมโครโฟนเพื่อจับเสียง พร้อมสำหรับการแปลงเป็นข้อความ นอกจากนี้ยังสามารถเชื่อมต่อกับลำโพงเพื่อส่งออกเสียงได้ ในบทเรียนต่อไปนี้จะใช้เพื่อให้ข้อเสนอแนะเสียง แต่การตั้งค่าลำโพงตอนนี้จะมีประโยชน์สำหรับการทดสอบไมโครโฟน
งาน - ตั้งค่าไมโครโฟนและลำโพงของคุณ
ทำตามคำแนะนำที่เกี่ยวข้องเพื่อกำหนดค่าไมโครโฟนและลำโพงสำหรับอุปกรณ์ IoT ของคุณ:
งาน - การจับเสียง
ทำตามคำแนะนำที่เกี่ยวข้องเพื่อจับเสียงบนอุปกรณ์ IoT ของคุณ:
การแปลงเสียงเป็นข้อความ
การแปลงเสียงเป็นข้อความ หรือการรู้จำเสียง เกี่ยวข้องกับการใช้ AI เพื่อแปลงคำในสัญญาณเสียงเป็นข้อความ
โมเดลการรู้จำเสียง
ในการแปลงเสียงเป็นข้อความ ตัวอย่างจากสัญญาณเสียงจะถูกจัดกลุ่มและป้อนเข้าสู่โมเดลการเรียนรู้ของเครื่องที่สร้างขึ้นจากเครือข่ายประสาทเทียมแบบ Recurrent Neural Network (RNN) นี่เป็นประเภทของโมเดลการเรียนรู้ของเครื่องที่สามารถใช้ข้อมูลก่อนหน้าในการตัดสินใจเกี่ยวกับข้อมูลที่เข้ามา ตัวอย่างเช่น RNN สามารถตรวจจับตัวอย่างเสียงหนึ่งบล็อกว่าเป็นเสียง 'Hel' และเมื่อได้รับอีกตัวอย่างที่คิดว่าเป็นเสียง 'lo' มันสามารถรวมเข้ากับเสียงก่อนหน้า ค้นหาว่า 'Hello' เป็นคำที่ถูกต้องและเลือกคำนี้เป็นผลลัพธ์
โมเดล ML มักจะรับข้อมูลที่มีขนาดเท่ากันทุกครั้ง ตัวจำแนกภาพที่คุณสร้างในบทเรียนก่อนหน้านี้ปรับขนาดภาพให้มีขนาดคงที่และประมวลผลภาพเหล่านั้น เช่นเดียวกับโมเดลเสียง พวกมันต้องประมวลผลชิ้นส่วนเสียงที่มีขนาดคงที่ โมเดลเสียงต้องสามารถรวมผลลัพธ์ของการคาดการณ์หลายครั้งเพื่อให้ได้คำตอบ เพื่อให้สามารถแยกแยะระหว่าง 'Hi' และ 'Highway' หรือ 'flock' และ 'floccinaucinihilipilification'
โมเดลเสียงยังมีความก้าวหน้าพอที่จะเข้าใจบริบท และสามารถแก้ไขคำที่ตรวจพบได้เมื่อประมวลผลเสียงเพิ่มเติม ตัวอย่างเช่น หากคุณพูดว่า "ฉันไปที่ร้านเพื่อซื้อกล้วยสองลูกและแอปเปิ้ลด้วย" คุณจะใช้สามคำที่เสียงเหมือนกัน แต่สะกดต่างกัน - to, two และ too โมเดลเสียงสามารถเข้าใจบริบทและใช้การสะกดคำที่เหมาะสม 💁 บริการเสียงบางอย่างอนุญาตให้ปรับแต่งเพื่อให้ทำงานได้ดีขึ้นในสภาพแวดล้อมที่มีเสียงดัง เช่น โรงงาน หรือกับคำศัพท์เฉพาะทาง เช่น ชื่อสารเคมี การปรับแต่งเหล่านี้ได้รับการฝึกฝนโดยการให้ตัวอย่างเสียงและการถอดเสียง และทำงานโดยใช้การเรียนรู้แบบถ่ายโอน ซึ่งเหมือนกับวิธีที่คุณฝึกตัวจำแนกภาพโดยใช้ภาพเพียงไม่กี่ภาพในบทเรียนก่อนหน้า
ความเป็นส่วนตัว
เมื่อใช้การแปลงเสียงเป็นข้อความในอุปกรณ์ IoT สำหรับผู้บริโภค ความเป็นส่วนตัวถือเป็นสิ่งสำคัญมาก อุปกรณ์เหล่านี้ฟังเสียงอย่างต่อเนื่อง ดังนั้นในฐานะผู้บริโภค คุณคงไม่ต้องการให้ทุกสิ่งที่คุณพูดถูกส่งไปยังคลาวด์และแปลงเป็นข้อความ นอกจากจะใช้แบนด์วิดท์อินเทอร์เน็ตจำนวนมากแล้ว ยังมีผลกระทบต่อความเป็นส่วนตัวอย่างมหาศาล โดยเฉพาะเมื่อผู้ผลิตอุปกรณ์อัจฉริยะบางรายสุ่มเลือกเสียงเพื่อ ให้มนุษย์ตรวจสอบกับข้อความที่สร้างขึ้นเพื่อช่วยปรับปรุงโมเดลของพวกเขา
คุณต้องการให้อุปกรณ์อัจฉริยะของคุณส่งเสียงไปยังคลาวด์เพื่อประมวลผลเฉพาะเมื่อคุณใช้งาน ไม่ใช่เมื่อมันได้ยินเสียงในบ้านของคุณ ซึ่งอาจรวมถึงการประชุมส่วนตัวหรือการสนทนาใกล้ชิด วิธีการทำงานของอุปกรณ์อัจฉริยะส่วนใหญ่คือการใช้ คำปลุก ซึ่งเป็นวลีสำคัญ เช่น "Alexa", "Hey Siri" หรือ "OK Google" ที่ทำให้อุปกรณ์ 'ตื่น' และฟังสิ่งที่คุณพูดจนกระทั่งตรวจพบการหยุดในคำพูดของคุณ ซึ่งบ่งบอกว่าคุณพูดกับอุปกรณ์เสร็จแล้ว
🎓 การตรวจจับคำปลุกเรียกอีกอย่างว่า การค้นหาคำสำคัญ หรือ การจดจำคำสำคัญ
คำปลุกเหล่านี้ถูกตรวจจับบนอุปกรณ์ ไม่ใช่ในคลาวด์ อุปกรณ์อัจฉริยะเหล่านี้มีโมเดล AI ขนาดเล็กที่ทำงานบนอุปกรณ์เพื่อฟังคำปลุก และเมื่อตรวจพบ จะเริ่มสตรีมเสียงไปยังคลาวด์เพื่อการจดจำ โมเดลเหล่านี้มีความเฉพาะเจาะจงมาก และฟังเฉพาะคำปลุกเท่านั้น
💁 บริษัทเทคโนโลยีบางแห่งกำลังเพิ่มความเป็นส่วนตัวให้กับอุปกรณ์ของพวกเขา โดยทำการแปลงเสียงเป็นข้อความบางส่วนบนอุปกรณ์ Apple ได้ประกาศว่าเป็นส่วนหนึ่งของการอัปเดต iOS และ macOS ในปี 2021 พวกเขาจะรองรับการแปลงเสียงเป็นข้อความบนอุปกรณ์ และสามารถจัดการคำขอจำนวนมากโดยไม่ต้องใช้คลาวด์ นี่เป็นผลมาจากการมีโปรเซสเซอร์ที่ทรงพลังในอุปกรณ์ของพวกเขาที่สามารถรันโมเดล ML ได้
✅ คุณคิดว่าผลกระทบด้านความเป็นส่วนตัวและจริยธรรมของการจัดเก็บเสียงที่ส่งไปยังคลาวด์คืออะไร? เสียงนี้ควรถูกจัดเก็บหรือไม่ และถ้าควร ควรจัดเก็บอย่างไร? คุณคิดว่าการใช้การบันทึกเสียงเพื่อการบังคับใช้กฎหมายเป็นการแลกเปลี่ยนที่ดีสำหรับการสูญเสียความเป็นส่วนตัวหรือไม่?
การตรวจจับคำปลุกมักใช้เทคนิคที่เรียกว่า TinyML ซึ่งเป็นการแปลงโมเดล ML ให้สามารถทำงานบนไมโครคอนโทรลเลอร์ได้ โมเดลเหล่านี้มีขนาดเล็ก และใช้พลังงานน้อยมากในการทำงาน
เพื่อหลีกเลี่ยงความซับซ้อนของการฝึกและการใช้โมเดลคำปลุก ตัวจับเวลาที่คุณกำลังสร้างในบทเรียนนี้จะใช้ปุ่มเพื่อเปิดการจดจำเสียง
💁 หากคุณต้องการลองสร้างโมเดลตรวจจับคำปลุกเพื่อใช้งานบน Wio Terminal หรือ Raspberry Pi ลองดู บทแนะนำการตอบสนองต่อเสียงของคุณโดย Edge Impulse หากคุณต้องการใช้คอมพิวเตอร์ของคุณทำสิ่งนี้ คุณสามารถลอง เริ่มต้นใช้งาน Custom Keyword quickstart บนเอกสาร Microsoft
แปลงเสียงเป็นข้อความ
![]()
เช่นเดียวกับการจำแนกภาพในโครงการก่อนหน้า มีบริการ AI ที่สร้างไว้ล่วงหน้าที่สามารถรับเสียงเป็นไฟล์เสียงและแปลงเป็นข้อความ บริการหนึ่งคือ Speech Service ซึ่งเป็นส่วนหนึ่งของ Cognitive Services บริการ AI ที่สร้างไว้ล่วงหน้าที่คุณสามารถใช้ในแอปของคุณ
งาน - ตั้งค่าทรัพยากร AI ด้านเสียง
-
สร้าง Resource Group สำหรับโครงการนี้ชื่อ
smart-timer -
ใช้คำสั่งต่อไปนี้เพื่อสร้างทรัพยากรเสียงฟรี:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>แทนที่
<location>ด้วยตำแหน่งที่คุณใช้เมื่อสร้าง Resource Group -
คุณจะต้องใช้ API key เพื่อเข้าถึงทรัพยากรเสียงจากโค้ดของคุณ รันคำสั่งต่อไปนี้เพื่อรับคีย์:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableคัดลอกหนึ่งในคีย์ไว้
งาน - แปลงเสียงเป็นข้อความ
ทำตามคู่มือที่เกี่ยวข้องเพื่อแปลงเสียงเป็นข้อความบนอุปกรณ์ IoT ของคุณ:
🚀 ความท้าทาย
การจดจำเสียงมีมานานแล้ว และกำลังพัฒนาอย่างต่อเนื่อง ศึกษาความสามารถในปัจจุบันและเปรียบเทียบว่ามันพัฒนาไปอย่างไรเมื่อเวลาผ่านไป รวมถึงความแม่นยำของการถอดเสียงโดยเครื่องเมื่อเทียบกับมนุษย์
คุณคิดว่าอนาคตของการจดจำเสียงจะเป็นอย่างไร?
แบบทดสอบหลังการบรรยาย
ทบทวนและศึกษาด้วยตนเอง
- อ่านเกี่ยวกับประเภทไมโครโฟนต่าง ๆ และวิธีการทำงานใน บทความเกี่ยวกับความแตกต่างระหว่างไมโครโฟนแบบไดนามิกและคอนเดนเซอร์บน Musician's HQ
- อ่านเพิ่มเติมเกี่ยวกับบริการเสียงใน Cognitive Services บน เอกสารบริการเสียงบน Microsoft Docs
- อ่านเกี่ยวกับการค้นหาคำสำคัญบน เอกสารการจดจำคำสำคัญบน Microsoft Docs
งานที่ได้รับมอบหมาย
ข้อจำกัดความรับผิดชอบ:
เอกสารนี้ได้รับการแปลโดยใช้บริการแปลภาษา AI Co-op Translator แม้ว่าเราจะพยายามให้การแปลมีความถูกต้องมากที่สุด แต่โปรดทราบว่าการแปลโดยอัตโนมัติอาจมีข้อผิดพลาดหรือความไม่ถูกต้อง เอกสารต้นฉบับในภาษาที่เป็นต้นฉบับควรถือว่าเป็นแหล่งข้อมูลที่เชื่อถือได้ สำหรับข้อมูลที่สำคัญ ขอแนะนำให้ใช้บริการแปลภาษามนุษย์ที่เป็นมืออาชีพ เราไม่รับผิดชอบต่อความเข้าใจผิดหรือการตีความผิดที่เกิดจากการใช้การแปลนี้