16 KiB
Träna en lagerdetektor
Sketchnote av Nitya Narasimhan. Klicka på bilden för en större version.
Den här videon ger en översikt av objektdetektering med Azure Custom Vision-tjänsten, en tjänst som kommer att behandlas i denna lektion.

🎥 Klicka på bilden ovan för att titta på videon
Förtest
Introduktion
I det föregående projektet använde du AI för att träna en bildklassificerare – en modell som kan avgöra om en bild innehåller något, som mogen eller omogen frukt. En annan typ av AI-modell som kan användas med bilder är objektdetektering. Dessa modeller klassificerar inte en bild med hjälp av taggar, utan tränas för att känna igen objekt och kan hitta dem i bilder. De upptäcker inte bara att objektet finns i bilden, utan också var i bilden det finns. Detta gör det möjligt att räkna objekt i bilder.
I denna lektion kommer du att lära dig om objektdetektering, inklusive hur det kan användas inom detaljhandeln. Du kommer också att lära dig hur man tränar en objektdetektor i molnet.
I denna lektion kommer vi att täcka:
- Objektdetektering
- Använd objektdetektering inom detaljhandeln
- Träna en objektdetektor
- Testa din objektdetektor
- Träna om din objektdetektor
Objektdetektering
Objektdetektering handlar om att upptäcka objekt i bilder med hjälp av AI. Till skillnad från bildklassificeraren du tränade i det senaste projektet handlar objektdetektering inte om att förutsäga den bästa taggen för en hel bild, utan om att hitta ett eller flera objekt i en bild.
Objektdetektering vs bildklassificering
Bildklassificering handlar om att klassificera en hel bild – vilka är sannolikheterna att hela bilden matchar varje tagg. Du får tillbaka sannolikheter för varje tagg som användes för att träna modellen.

I exemplet ovan klassificeras två bilder med hjälp av en modell som tränats för att klassificera burkar med cashewnötter eller tomatpuré. Den första bilden är en burk med cashewnötter och har två resultat från bildklassificeraren:
| Tagg | Sannolikhet |
|---|---|
cashewnötter |
98,4% |
tomatpuré |
1,6% |
Den andra bilden är en burk med tomatpuré, och resultaten är:
| Tagg | Sannolikhet |
|---|---|
cashewnötter |
0,7% |
tomatpuré |
99,3% |
Du kan använda dessa värden med en tröskelprocent för att förutsäga vad som finns i bilden. Men vad händer om en bild innehåller flera burkar med tomatpuré, eller både cashewnötter och tomatpuré? Resultaten skulle förmodligen inte ge dig det du vill ha. Det är här objektdetektering kommer in.
Objektdetektering handlar om att träna en modell att känna igen objekt. Istället för att ge den bilder som innehåller objektet och säga att varje bild är en tagg eller en annan, markerar du den del av bilden som innehåller det specifika objektet och taggar det. Du kan tagga ett enda objekt i en bild eller flera. På så sätt lär sig modellen hur själva objektet ser ut, inte bara hur bilder som innehåller objektet ser ut.
När du sedan använder den för att förutsäga bilder får du inte tillbaka en lista med taggar och procent, utan en lista med upptäckta objekt, med deras avgränsningsrutor och sannolikheten att objektet matchar den tilldelade taggen.
🎓 Avgränsningsrutor är rutorna runt ett objekt.

Bilden ovan innehåller både en burk med cashewnötter och tre burkar med tomatpuré. Objektdetektorn upptäckte cashewnötterna och returnerade avgränsningsrutan som innehåller cashewnötterna med sannolikheten att rutan innehåller objektet, i detta fall 97,6%. Objektdetektorn har också upptäckt tre burkar med tomatpuré och ger tre separata avgränsningsrutor, en för varje upptäckt burk, och var och en har en sannolikhet att rutan innehåller en burk med tomatpuré.
✅ Fundera på några olika scenarier där du kanske vill använda bildbaserade AI-modeller. Vilka skulle behöva klassificering, och vilka skulle behöva objektdetektering?
Hur objektdetektering fungerar
Objektdetektering använder komplexa ML-modeller. Dessa modeller fungerar genom att dela upp bilden i flera celler och sedan kontrollera om mitten av avgränsningsrutan är centrum för en bild som matchar en av bilderna som användes för att träna modellen. Du kan tänka på detta som att köra en bildklassificerare över olika delar av bilden för att leta efter matchningar.
💁 Detta är en drastisk förenkling. Det finns många tekniker för objektdetektering, och du kan läsa mer om dem på Objektdetekteringssidan på Wikipedia.
Det finns ett antal olika modeller som kan utföra objektdetektering. En särskilt känd modell är YOLO (You Only Look Once), som är otroligt snabb och kan upptäcka 20 olika klasser av objekt, såsom människor, hundar, flaskor och bilar.
✅ Läs mer om YOLO-modellen på pjreddie.com/darknet/yolo/
Objektdetekteringsmodeller kan tränas om med hjälp av transfer learning för att upptäcka anpassade objekt.
Använd objektdetektering inom detaljhandeln
Objektdetektering har flera användningsområden inom detaljhandeln. Några inkluderar:
- Lagerkontroll och räkning – känna igen när lagret är lågt på hyllorna. Om lagret är för lågt kan meddelanden skickas till personal eller robotar för att fylla på hyllorna.
- Maskdetektering – i butiker med maskpolicyer under folkhälsokriser kan objektdetektering känna igen personer med och utan masker.
- Automatisk fakturering – upptäcka föremål som plockas från hyllor i automatiserade butiker och fakturera kunder korrekt.
- Farlighetsdetektering – känna igen trasiga föremål på golv eller spillda vätskor och larma städpersonal.
✅ Gör lite research: Vilka fler användningsområden för objektdetektering finns inom detaljhandeln?
Träna en objektdetektor
Du kan träna en objektdetektor med Custom Vision, på ett liknande sätt som du tränade en bildklassificerare.
Uppgift – skapa en objektdetektor
-
Skapa en resursgrupp för detta projekt som heter
stock-detector. -
Skapa en gratis Custom Vision-träningsresurs och en gratis Custom Vision-prediktionsresurs i resursgruppen
stock-detector. Namnge demstock-detector-trainingochstock-detector-prediction.💁 Du kan bara ha en gratis tränings- och prediktionsresurs, så se till att du har rensat upp ditt projekt från tidigare lektioner.
⚠️ Du kan hänvisa till instruktionerna för att skapa tränings- och prediktionsresurser från projekt 4, lektion 1 om det behövs.
-
Starta Custom Vision-portalen på CustomVision.ai och logga in med det Microsoft-konto du använde för ditt Azure-konto.
-
Följ Skapa ett nytt projekt-sektionen i snabbstartsguiden för att bygga en objektdetektor på Microsoft Docs för att skapa ett nytt Custom Vision-projekt. Gränssnittet kan ändras och dessa dokument är alltid den mest aktuella referensen.
Namnge ditt projekt
stock-detector.När du skapar ditt projekt, se till att använda resursen
stock-detector-trainingsom du skapade tidigare. Använd projekttypen Object Detection och domänen Products on Shelves.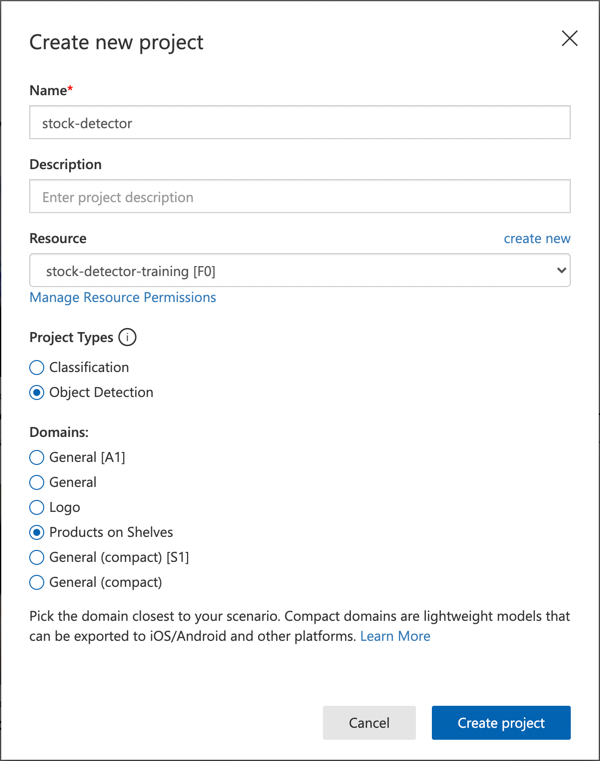
✅ Domänen Products on Shelves är specifikt inriktad på att upptäcka lager på butikshyllor. Läs mer om de olika domänerna i Välj en domän-dokumentationen på Microsoft Docs
✅ Ta dig tid att utforska Custom Vision-gränssnittet för din objektdetektor.
Uppgift – träna din objektdetektor
För att träna din modell behöver du en uppsättning bilder som innehåller de objekt du vill upptäcka.
-
Samla bilder som innehåller objektet du vill upptäcka. Du behöver minst 15 bilder som innehåller varje objekt du vill upptäcka från olika vinklar och i olika ljusförhållanden, men ju fler desto bättre. Denna objektdetektor använder domänen Products on Shelves, så försök att arrangera objekten som om de var på en butikshylla. Du kommer också att behöva några bilder för att testa modellen. Om du upptäcker mer än ett objekt vill du ha några testbilder som innehåller alla objekten.
💁 Bilder med flera olika objekt räknas mot minimikravet på 15 bilder för alla objekt i bilden.
Dina bilder bör vara i png- eller jpeg-format och mindre än 6 MB. Om du skapar dem med en iPhone, till exempel, kan de vara högupplösta HEIC-bilder, så de kan behöva konverteras och eventuellt förminskas. Ju fler bilder desto bättre, och du bör ha ett liknande antal mogna och omogna.
Modellen är designad för produkter på hyllor, så försök att ta bilder av objekten på hyllor.
Du kan hitta några exempelbilder som du kan använda i images-mappen med cashewnötter och tomatpuré som du kan använda.
-
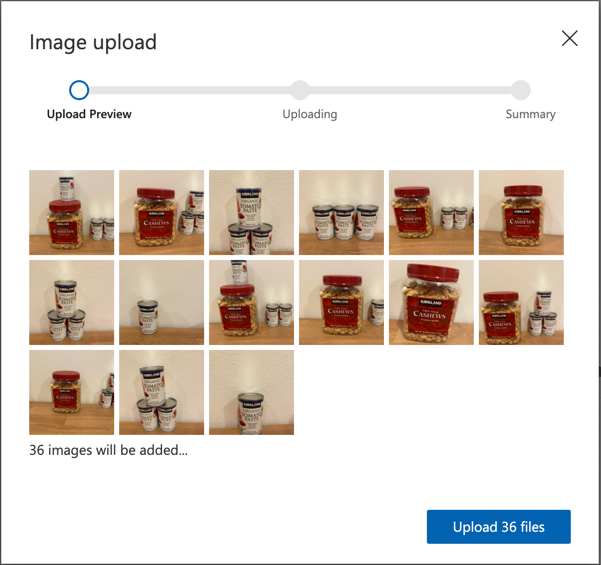
Följ Ladda upp och tagga bilder-sektionen i snabbstartsguiden för att bygga en objektdetektor på Microsoft Docs för att ladda upp dina träningsbilder. Skapa relevanta taggar beroende på vilka typer av objekt du vill upptäcka.
När du ritar avgränsningsrutor för objekt, håll dem tätt runt objektet. Det kan ta ett tag att markera alla bilder, men verktyget kommer att upptäcka vad det tror är avgränsningsrutorna, vilket gör det snabbare.
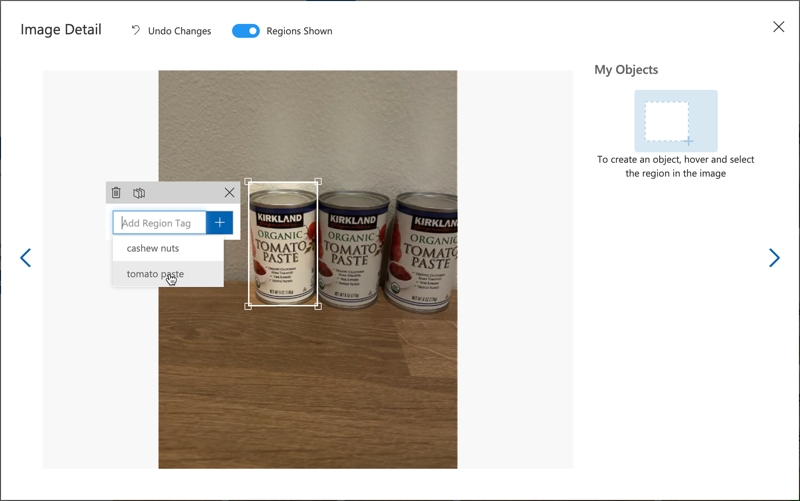
💁 Om du har fler än 15 bilder för varje objekt kan du träna efter 15 och sedan använda funktionen Föreslagna taggar. Detta kommer att använda den tränade modellen för att upptäcka objekten i de otaggade bilderna. Du kan sedan bekräfta de upptäckta objekten eller avvisa och rita om avgränsningsrutorna. Detta kan spara mycket tid.
-
Följ Träna detektorn-sektionen i snabbstartsguiden för att bygga en objektdetektor på Microsoft Docs för att träna objektdetektorn på dina taggade bilder.
Du kommer att få välja träningstyp. Välj Snabbträning.
Objektdetektorn kommer sedan att tränas. Det tar några minuter för träningen att slutföras.
Testa din objektdetektor
När din objektdetektor är tränad kan du testa den genom att ge den nya bilder för att upptäcka objekt i.
Uppgift – testa din objektdetektor
-
Använd knappen Snabbtest för att ladda upp testbilder och verifiera att objekten upptäcks. Använd testbilderna du skapade tidigare, inte några av bilderna du använde för träning.
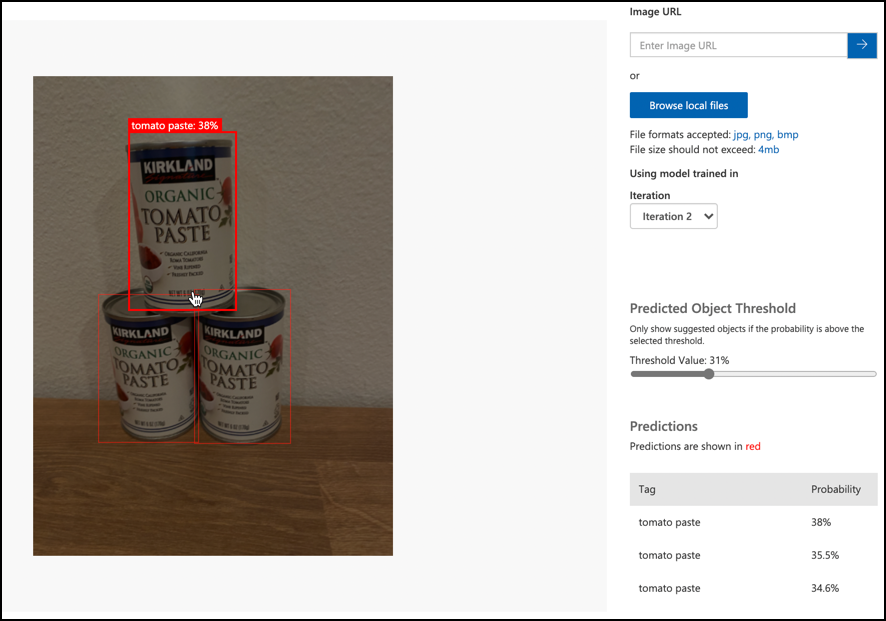
-
Testa alla testbilder du har tillgång till och observera sannolikheterna.
Träna om din objektdetektor
När du testar din objektdetektor kanske den inte ger de resultat du förväntar dig, precis som med bildklassificerare i det föregående projektet. Du kan förbättra din objektdetektor genom att träna om den med bilder den gör fel på.
Varje gång du gör en förutsägelse med snabbtestalternativet sparas bilden och resultaten. Du kan använda dessa bilder för att träna om din modell.
-
Använd fliken Förutsägelser för att hitta bilderna du använde för testning.
-
Bekräfta alla korrekta upptäckter, ta bort felaktiga och lägg till eventuella saknade objekt.
-
Träna om och testa modellen igen.
🚀 Utmaning
Vad skulle hända om du använde objektdetektorn med liknande föremål, som burkar med samma varumärke av tomatpuré och hackade tomater?
Om du har några liknande föremål, testa genom att lägga till bilder av dem i din objektdetektor.
Eftertest
Granskning & Självstudier
- När du tränade din objektdetektor skulle du ha sett värden för Precision, Recall och mAP som bedömer den modell som skapades. Läs mer om vad dessa värden innebär med hjälp av avsnittet Utvärdera detektorn i Snabbstart för att bygga en objektdetektor på Microsoft Docs
- Läs mer om objektdetektering på sidan om objektdetektering på Wikipedia
Uppgift
Ansvarsfriskrivning:
Detta dokument har översatts med hjälp av AI-översättningstjänsten Co-op Translator. Även om vi strävar efter noggrannhet, bör du vara medveten om att automatiserade översättningar kan innehålla fel eller brister. Det ursprungliga dokumentet på dess originalspråk bör betraktas som den auktoritativa källan. För kritisk information rekommenderas professionell mänsklig översättning. Vi ansvarar inte för eventuella missförstånd eller feltolkningar som uppstår vid användning av denna översättning.