10 KiB
Setează un cronometru și oferă feedback vocal
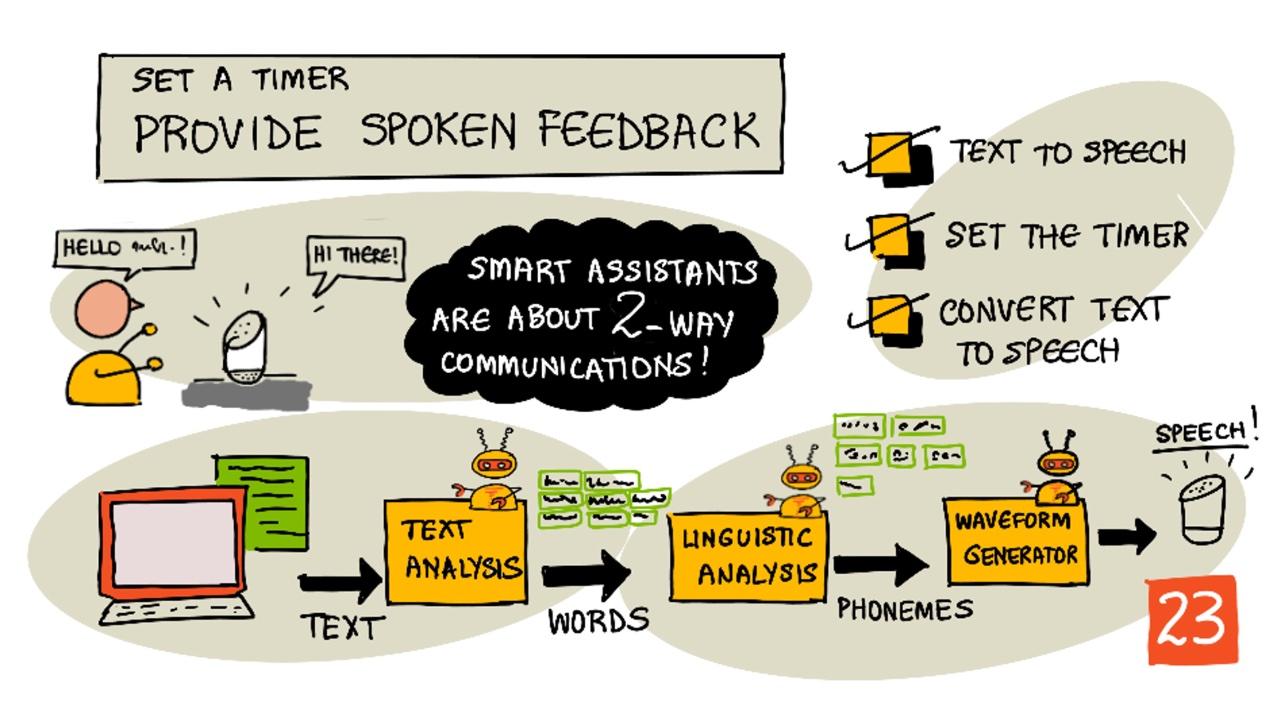
Prezentare grafică realizată de Nitya Narasimhan. Click pe imagine pentru o versiune mai mare.
Chestionar înainte de lecție
Introducere
Asistenții inteligenți nu sunt dispozitive de comunicare unidirecțională. Vorbești cu ei, iar ei răspund:
"Alexa, setează un cronometru de 3 minute"
"Ok, cronometrul tău este setat pentru 3 minute"
În ultimele 2 lecții ai învățat cum să transformi vorbirea în text și apoi să extragi o cerere de setare a unui cronometru din acel text. În această lecție vei învăța cum să setezi cronometrul pe un dispozitiv IoT, să răspunzi utilizatorului cu cuvinte vorbite care confirmă cronometrul și să îl alertezi când cronometrul s-a terminat.
În această lecție vom acoperi:
Text în vorbire
Text în vorbire, așa cum sugerează numele, este procesul de a converti textul în audio care conține cuvintele rostite. Principiul de bază este de a descompune cuvintele din text în sunetele lor componente (cunoscute sub numele de foneme) și de a îmbina audio pentru acele sunete, fie folosind înregistrări audio preexistente, fie audio generat de modele AI.

Sistemele de text în vorbire au de obicei 3 etape:
- Analiza textului
- Analiza lingvistică
- Generarea formei de undă
Analiza textului
Analiza textului implică preluarea textului furnizat și convertirea acestuia în cuvinte care pot fi utilizate pentru a genera vorbire. De exemplu, dacă convertești "Salut lume", nu este necesară analiza textului, cele două cuvinte pot fi convertite direct în vorbire. Dacă ai "1234", însă, acest lucru ar putea necesita conversia fie în cuvintele "O mie două sute treizeci și patru", fie "Unu, doi, trei, patru", în funcție de context. Pentru "Am 1234 mere", ar fi "O mie două sute treizeci și patru", dar pentru "Copilul a numărat 1234" ar fi "Unu, doi, trei, patru".
Cuvintele create variază nu doar în funcție de limbă, ci și de regiunea acelei limbi. De exemplu, în engleza americană, 120 ar fi "One hundred twenty", iar în engleza britanică ar fi "One hundred and twenty", cu utilizarea lui "and" după sute.
✅ Alte exemple care necesită analiza textului includ "in" ca abreviere pentru inch și "st" ca abreviere pentru saint sau street. Poți găsi alte exemple în limba ta de cuvinte care sunt ambigue fără context?
Odată ce cuvintele au fost definite, acestea sunt trimise pentru analiza lingvistică.
Analiza lingvistică
Analiza lingvistică descompune cuvintele în foneme. Fonemele se bazează nu doar pe literele utilizate, ci și pe celelalte litere din cuvânt. De exemplu, în engleză, sunetul 'a' din 'car' și 'care' este diferit. Limba engleză are 44 de foneme diferite pentru cele 26 de litere din alfabet, unele fiind împărțite de litere diferite, cum ar fi același fonem utilizat la începutul cuvintelor 'circle' și 'serpent'.
✅ Fă niște cercetări: Care sunt fonemele pentru limba ta?
Odată ce cuvintele au fost convertite în foneme, aceste foneme necesită date suplimentare pentru a susține intonația, ajustând tonul sau durata în funcție de context. Un exemplu este în engleză, unde creșterea tonului poate transforma o propoziție într-o întrebare, ridicând tonul pentru ultimul cuvânt.
De exemplu - propoziția "You have an apple" este o afirmație care spune că ai un măr. Dacă tonul crește la sfârșit, crescând pentru cuvântul "apple", devine întrebarea "You have an apple?", întrebând dacă ai un măr. Analiza lingvistică trebuie să folosească semnul de întrebare de la sfârșit pentru a decide să crească tonul.
Odată ce fonemele au fost generate, acestea pot fi trimise pentru generarea formei de undă pentru a produce ieșirea audio.
Generarea formei de undă
Primele sisteme electronice de text în vorbire foloseau înregistrări audio unice pentru fiecare fonem, ceea ce ducea la voci foarte monotone, robotice. Analiza lingvistică producea foneme, acestea erau încărcate dintr-o bază de date de sunete și îmbinate pentru a crea audio.
✅ Fă niște cercetări: Găsește înregistrări audio din sistemele timpurii de sinteză vocală. Compară-le cu sinteza vocală modernă, cum ar fi cea utilizată de asistenții inteligenți.
Generarea modernă a formei de undă folosește modele ML construite prin deep learning (rețele neuronale foarte mari care funcționează într-un mod similar neuronilor din creier) pentru a produce voci mai naturale, care pot fi indistincte de cele umane.
💁 Unele dintre aceste modele ML pot fi re-antrenate folosind transfer learning pentru a suna ca persoane reale. Acest lucru înseamnă că utilizarea vocii ca sistem de securitate, ceva ce băncile încearcă din ce în ce mai mult să facă, nu mai este o idee bună, deoarece oricine are o înregistrare de câteva minute a vocii tale te poate imita.
Aceste modele ML mari sunt antrenate pentru a combina toate cele trei etape într-un sintetizator vocal complet.
Setarea cronometrului
Pentru a seta cronometrul, dispozitivul tău IoT trebuie să apeleze endpoint-ul REST pe care l-ai creat folosind cod serverless, apoi să folosească numărul de secunde rezultat pentru a seta un cronometru.
Sarcină - apelează funcția serverless pentru a obține timpul cronometrului
Urmează ghidul relevant pentru a apela endpoint-ul REST de pe dispozitivul tău IoT și pentru a seta un cronometru pentru timpul necesar:
Convertirea textului în vorbire
Același serviciu de vorbire pe care l-ai folosit pentru a converti vorbirea în text poate fi folosit pentru a converti textul înapoi în vorbire, iar acest lucru poate fi redat printr-un difuzor de pe dispozitivul tău IoT. Textul de convertit este trimis către serviciul de vorbire, împreună cu tipul de audio necesar (cum ar fi rata de eșantionare), iar datele binare care conțin audio sunt returnate.
Când trimiți această cerere, o faci folosind Speech Synthesis Markup Language (SSML), un limbaj de marcare bazat pe XML pentru aplicații de sinteză vocală. Acesta definește nu doar textul care trebuie convertit, ci și limba textului, vocea de utilizat și poate fi folosit chiar pentru a defini viteza, volumul și tonul pentru unele sau toate cuvintele din text.
De exemplu, acest SSML definește o cerere de a converti textul "Your 3 minute 5 second time has been set" în vorbire folosind o voce britanică engleză numită en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 Majoritatea sistemelor de text în vorbire au mai multe voci pentru limbi diferite, cu accente relevante, cum ar fi o voce engleză britanică cu accent englezesc și o voce engleză din Noua Zeelandă cu accent neozeelandez.
Sarcină - convertește textul în vorbire
Parcurge ghidul relevant pentru a converti textul în vorbire folosind dispozitivul tău IoT:
- Arduino - Wio Terminal
- Computer cu o singură placă - Raspberry Pi
- Computer cu o singură placă - Dispozitiv virtual
🚀 Provocare
SSML are modalități de a schimba modul în care sunt rostite cuvintele, cum ar fi adăugarea de accent pe anumite cuvinte, adăugarea de pauze sau schimbarea tonului. Încearcă unele dintre acestea, trimițând SSML diferit de pe dispozitivul tău IoT și comparând rezultatele. Poți citi mai multe despre SSML, inclusiv cum să schimbi modul în care sunt rostite cuvintele, în Speech Synthesis Markup Language (SSML) Version 1.1 specification from the World Wide Web consortium.
Chestionar după lecție
Recapitulare și studiu individual
- Citește mai multe despre sinteza vocală pe pagina despre sinteza vocală de pe Wikipedia
- Citește mai multe despre modurile în care infractorii folosesc sinteza vocală pentru a fura în articolul despre voci false care ajută infractorii cibernetici să fure bani de pe BBC News
- Află mai multe despre riscurile pentru actorii vocali din cauza versiunilor sintetizate ale vocilor lor în articolul despre procesul TikTok care evidențiază cum AI afectează actorii vocali pe Vice
Temă
Declinarea responsabilității:
Acest document a fost tradus folosind serviciul de traducere AI Co-op Translator. Deși ne străduim să asigurăm acuratețea, vă rugăm să rețineți că traducerile automate pot conține erori sau inexactități. Documentul original în limba sa natală ar trebui considerat sursa autoritară. Pentru informații critice, se recomandă traducerea profesională realizată de un specialist uman. Nu ne asumăm răspunderea pentru eventualele neînțelegeri sau interpretări greșite care pot apărea din utilizarea acestei traduceri.