9.5 KiB
Sett en timer og gi muntlig tilbakemelding
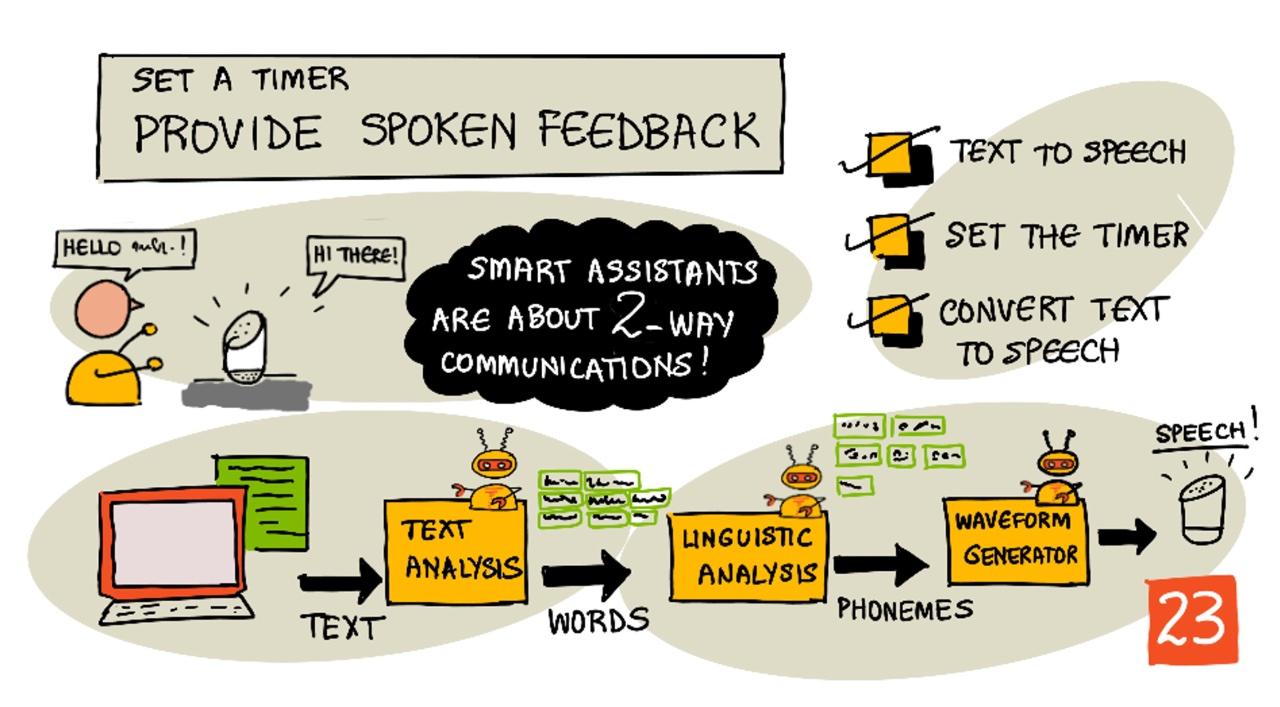
Sketchnote av Nitya Narasimhan. Klikk på bildet for en større versjon.
Quiz før forelesning
Introduksjon
Smarthjelpere er ikke enveis kommunikasjonsenheter. Du snakker til dem, og de svarer:
"Alexa, sett en 3-minutters timer"
"Ok, timeren din er satt til 3 minutter"
I de to siste leksjonene lærte du hvordan du tar tale og lager tekst, og deretter trekker ut en forespørsel om å sette en timer fra den teksten. I denne leksjonen vil du lære hvordan du setter timeren på IoT-enheten, svarer brukeren med muntlige ord som bekrefter timeren, og varsler dem når timeren er ferdig.
I denne leksjonen skal vi dekke:
Tekst til tale
Tekst til tale, som navnet antyder, er prosessen med å konvertere tekst til lyd som inneholder teksten som talte ord. Det grunnleggende prinsippet er å bryte ned ordene i teksten til deres bestanddeler (kjent som fonemer), og sette sammen lyd for disse lydene, enten ved å bruke forhåndsinnspilt lyd eller lyd generert av AI-modeller.

Tekst-til-tale-systemer har vanligvis 3 stadier:
- Tekstanalyse
- Lingvistisk analyse
- Generering av lydbølger
Tekstanalyse
Tekstanalyse innebærer å ta den gitte teksten og konvertere den til ord som kan brukes til å generere tale. For eksempel, hvis du konverterer "Hei verden", er det ingen tekstanalyse nødvendig, de to ordene kan konverteres til tale. Hvis du har "1234" derimot, må dette kanskje konverteres enten til ordene "Tusen to hundre og trettifire" eller "En, to, tre, fire" avhengig av konteksten. For "Jeg har 1234 epler", ville det være "Tusen to hundre og trettifire", men for "Barnet telte 1234" ville det være "En, to, tre, fire".
Ordene som opprettes varierer ikke bare for språket, men også for dialekten av det språket. For eksempel, på amerikansk engelsk, ville 120 være "One hundred twenty", mens på britisk engelsk ville det være "One hundred and twenty", med bruk av "and" etter hundretallet.
✅ Noen andre eksempler som krever tekstanalyse inkluderer "in" som en forkortelse for tomme, og "st" som en forkortelse for helgen og gate. Kan du tenke på andre eksempler på ditt språk der ord er tvetydige uten kontekst?
Når ordene er definert, sendes de til lingvistisk analyse.
Lingvistisk analyse
Lingvistisk analyse bryter ordene ned i fonemer. Fonemer er basert ikke bare på bokstavene som brukes, men også på de andre bokstavene i ordet. For eksempel, på engelsk er 'a'-lyden i 'car' og 'care' forskjellig. Det engelske språket har 44 forskjellige fonemer for de 26 bokstavene i alfabetet, noen delt av forskjellige bokstaver, som det samme fonemet som brukes i starten av 'circle' og 'serpent'.
✅ Gjør litt research: Hva er fonemene for ditt språk?
Når ordene er konvertert til fonemer, trenger disse fonemene tilleggsdata for å støtte intonasjon, justere tone eller varighet avhengig av konteksten. Et eksempel er på engelsk der tonehøyde kan økes for å gjøre en setning til et spørsmål, med en hevet tonehøyde for det siste ordet som antyder et spørsmål.
For eksempel - setningen "You have an apple" er en uttalelse som sier at du har et eple. Hvis tonehøyden går opp på slutten, økende for ordet "apple", blir det spørsmålet "You have an apple?", som spør om du har et eple. Den lingvistiske analysen må bruke spørsmålstegnet på slutten for å bestemme seg for å øke tonehøyden.
Når fonemene er generert, kan de sendes til generering av lydbølger for å produsere lydutgangen.
Generering av lydbølger
De første elektroniske tekst-til-tale-systemene brukte enkeltlydopptak for hvert fonem, noe som førte til veldig monotone, robotaktige stemmer. Den lingvistiske analysen ville produsere fonemer, disse ville bli lastet fra en database med lyder og satt sammen for å lage lyden.
✅ Gjør litt research: Finn noen lydopptak fra tidlige talesyntesesystemer. Sammenlign det med moderne talesyntese, som den som brukes i smarthjelpere.
Mer moderne generering av lydbølger bruker ML-modeller bygget med dyp læring (veldig store nevrale nettverk som fungerer på en lignende måte som nevroner i hjernen) for å produsere mer naturlige stemmer som kan være umulige å skille fra menneskelige.
💁 Noen av disse ML-modellene kan trenes på nytt ved hjelp av overføringslæring for å høres ut som ekte mennesker. Dette betyr at bruk av stemme som et sikkerhetssystem, noe banker i økende grad prøver, ikke lenger er en god idé, da hvem som helst med et opptak på noen få minutter av stemmen din kan utgi seg for å være deg.
Disse store ML-modellene blir trent til å kombinere alle tre trinnene til ende-til-ende talesyntese.
Sett timeren
For å sette timeren må IoT-enheten din kalle REST-endepunktet du opprettet ved hjelp av serverløs kode, og deretter bruke det resulterende antallet sekunder til å sette en timer.
Oppgave - kall den serverløse funksjonen for å få timerens tid
Følg den relevante guiden for å kalle REST-endepunktet fra IoT-enheten din og sett en timer for ønsket tid:
Konverter tekst til tale
Den samme taleservicen du brukte for å konvertere tale til tekst kan brukes til å konvertere tekst tilbake til tale, og dette kan spilles av gjennom en høyttaler på IoT-enheten din. Teksten som skal konverteres sendes til taleservicen, sammen med typen lyd som kreves (som samplingsfrekvensen), og binære data som inneholder lyden returneres.
Når du sender denne forespørselen, sender du den ved hjelp av Speech Synthesis Markup Language (SSML), et XML-basert markeringsspråk for talesynteseapplikasjoner. Dette definerer ikke bare teksten som skal konverteres, men også språket for teksten, stemmen som skal brukes, og kan til og med brukes til å definere hastighet, volum og tonehøyde for noen eller alle ordene i teksten.
For eksempel definerer denne SSML en forespørsel om å konvertere teksten "Din 3-minutters og 5-sekunders timer er satt" til tale ved hjelp av en britisk engelsk stemme kalt en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 De fleste tekst-til-tale-systemer har flere stemmer for forskjellige språk, med relevante aksenter som en britisk engelsk stemme med engelsk aksent og en New Zealand engelsk stemme med New Zealand aksent.
Oppgave - konverter tekst til tale
Arbeid gjennom den relevante guiden for å konvertere tekst til tale ved hjelp av IoT-enheten din:
🚀 Utfordring
SSML har måter å endre hvordan ord blir uttalt, som å legge til vekt på visse ord, legge til pauser eller endre tonehøyde. Prøv noen av disse, send forskjellige SSML fra IoT-enheten din og sammenlign resultatet. Du kan lese mer om SSML, inkludert hvordan du endrer måten ord blir uttalt på, i Speech Synthesis Markup Language (SSML) Version 1.1 spesifikasjonen fra World Wide Web Consortium.
Quiz etter forelesning
Gjennomgang og selvstudium
- Les mer om talesyntese på talesyntesesiden på Wikipedia
- Les mer om måter kriminelle bruker talesyntese til å stjele på falske stemmer 'hjelper nettkriminelle med å stjele penger' artikkelen på BBC nyheter
- Lær mer om risikoen for stemmeskuespillere fra syntetiserte versjoner av stemmene deres i denne TikTok-søksmålet fremhever hvordan AI skader stemmeskuespillere artikkelen på Vice
Oppgave
Ansvarsfraskrivelse:
Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten Co-op Translator. Selv om vi streber etter nøyaktighet, vær oppmerksom på at automatiske oversettelser kan inneholde feil eller unøyaktigheter. Det originale dokumentet på sitt opprinnelige språk bør anses som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.