|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Tren en fruktkvalitetsdetektor
Sketchnote av Nitya Narasimhan. Klikk på bildet for en større versjon.
Denne videoen gir en oversikt over Azure Custom Vision-tjenesten, en tjeneste som vil bli dekket i denne leksjonen.

🎥 Klikk på bildet ovenfor for å se videoen
Quiz før leksjonen
Introduksjon
Den nylige fremveksten av Kunstig Intelligens (AI) og Maskinlæring (ML) gir dagens utviklere et bredt spekter av muligheter. ML-modeller kan trenes til å gjenkjenne ulike ting i bilder, inkludert umoden frukt, og dette kan brukes i IoT-enheter for å hjelpe til med å sortere produkter enten under innhøsting eller under prosessering i fabrikker eller lagre.
I denne leksjonen vil du lære om bildegjenkjenning – å bruke ML-modeller til å skille mellom bilder av ulike ting. Du vil lære hvordan du trener en bildegjenkjenner til å skille mellom frukt som er god og frukt som er dårlig, enten umoden, overmoden, skadet eller råtten.
I denne leksjonen dekker vi:
- Bruke AI og ML til å sortere mat
- Bildegjenkjenning via maskinlæring
- Trene en bildegjenkjenner
- Teste bildegjenkjenneren din
- Trene bildegjenkjenneren din på nytt
Bruke AI og ML til å sortere mat
Å mate verdens befolkning er utfordrende, spesielt til en pris som gjør mat tilgjengelig for alle. En av de største kostnadene er arbeidskraft, så bønder vender seg i økende grad til automatisering og verktøy som IoT for å redusere arbeidskostnadene. Håndplukking er arbeidskrevende (og ofte fysisk krevende arbeid) og blir erstattet av maskiner, spesielt i rikere land. Til tross for kostnadsbesparelsene ved å bruke maskiner til innhøsting, er det en ulempe – evnen til å sortere mat mens den høstes.
Ikke alle avlinger modnes jevnt. Tomater, for eksempel, kan fortsatt ha noen grønne frukter på planten når majoriteten er klar for innhøsting. Selv om det er sløsing å høste disse tidlig, er det billigere og enklere for bonden å høste alt med maskiner og kvitte seg med den umodne frukten senere.
✅ Ta en titt på ulike frukter eller grønnsaker, enten de vokser i nærheten av deg på gårder eller i hagen din, eller i butikker. Er de alle like modne, eller ser du variasjon?
Den økte bruken av automatisert innhøsting flyttet sorteringen av produkter fra innhøstingen til fabrikken. Mat ble transportert på lange transportbånd med team av mennesker som plukket ut produkter som ikke oppfylte kvalitetsstandardene. Innhøstingen ble billigere takket være maskiner, men det var fortsatt en kostnad forbundet med manuell sortering av mat.
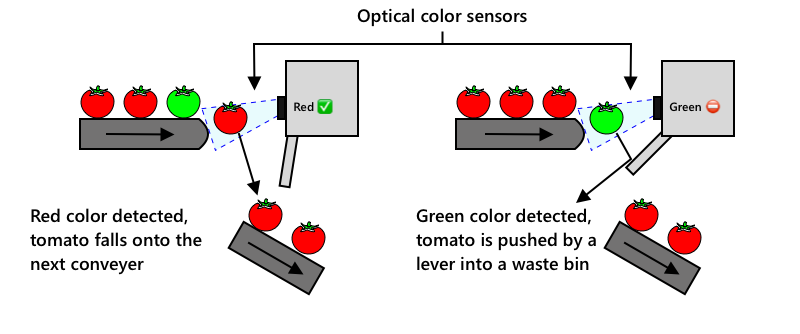
Den neste utviklingen var å bruke maskiner til å sortere, enten innebygd i innhøstingsmaskinen eller i prosesseringsanleggene. Den første generasjonen av disse maskinene brukte optiske sensorer til å oppdage farger, og styrte aktuatorer for å skyve grønne tomater inn i en avfallsbøtte ved hjelp av spaker eller lufttrykk, mens røde tomater fortsatte på et nettverk av transportbånd.
I denne videoen, når tomater faller fra ett transportbånd til et annet, blir grønne tomater oppdaget og dyttet inn i en bøtte ved hjelp av spaker.
✅ Hvilke forhold ville du trenge i en fabrikk eller på et jorde for at disse optiske sensorene skal fungere riktig?
De nyeste utviklingene av disse sorteringsmaskinene drar nytte av AI og ML, ved å bruke modeller som er trent til å skille god frukt fra dårlig, ikke bare ved åpenbare fargeforskjeller som grønne tomater vs røde, men også ved mer subtile forskjeller i utseende som kan indikere sykdom eller skader.
Bildegjenkjenning via maskinlæring
Tradisjonell programmering innebærer at du tar data, bruker en algoritme på dataene, og får et resultat. For eksempel, i det forrige prosjektet tok du GPS-koordinater og en geofence, brukte en algoritme levert av Azure Maps, og fikk tilbake et resultat om punktet var innenfor eller utenfor geofencen. Du gir mer data, du får mer output.
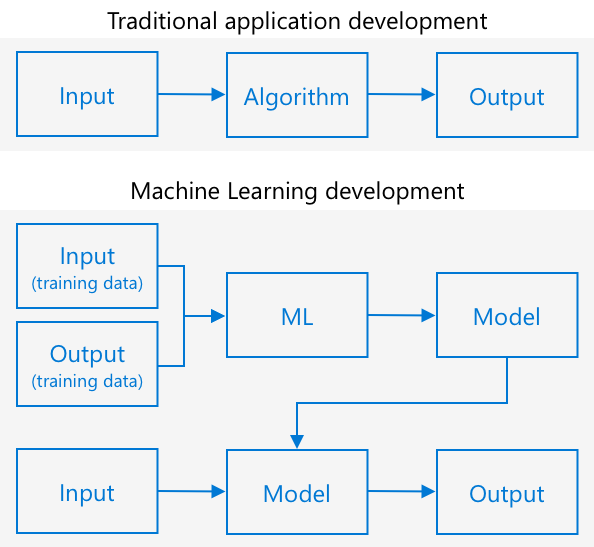
Maskinlæring snur dette rundt – du starter med data og kjente resultater, og maskinlæringsalgoritmen lærer fra dataene. Du kan deretter ta den trente algoritmen, kalt en maskinlæringsmodell eller modell, og gi den nye data for å få nye resultater.
🎓 Prosessen der en maskinlæringsalgoritme lærer fra dataene kalles trening. Inputene og de kjente resultatene kalles treningsdata.
For eksempel kan du gi en modell millioner av bilder av umodne bananer som input-treningsdata, med treningsresultatet satt til umoden, og millioner av bilder av modne bananer som treningsdata med resultatet satt til moden. ML-algoritmen vil deretter lage en modell basert på disse dataene. Du kan deretter gi denne modellen et nytt bilde av en banan, og den vil forutsi om bildet viser en moden eller umoden banan.
🎓 Resultatene fra ML-modeller kalles prediksjoner.

ML-modeller gir ikke et binært svar, men heller sannsynligheter. For eksempel kan en modell bli gitt et bilde av en banan og forutsi moden med 99,7 % og umoden med 0,3 %. Koden din vil deretter velge den beste prediksjonen og avgjøre at bananen er moden.
ML-modellen som brukes til å oppdage bilder som dette kalles en bildegjenkjenner – den får merkelappede bilder og klassifiserer nye bilder basert på disse merkelappene.
💁 Dette er en forenkling, og det finnes mange andre måter å trene modeller på som ikke alltid krever merkelappede resultater, som for eksempel usupervisert læring. Hvis du vil lære mer om ML, sjekk ut ML for nybegynnere, et 24-leksjonskurs om maskinlæring.
Trene en bildegjenkjenner
For å trene en bildegjenkjenner med suksess trenger du millioner av bilder. Det viser seg at når du først har en bildegjenkjenner trent på millioner eller milliarder av ulike bilder, kan du gjenbruke den og trene den på nytt med et lite sett bilder og oppnå gode resultater, ved hjelp av en prosess kalt transfer learning.
🎓 Transfer learning er når du overfører læringen fra en eksisterende ML-modell til en ny modell basert på nye data.
Når en bildegjenkjenner har blitt trent på et bredt spekter av bilder, er dens interne mekanismer gode til å gjenkjenne former, farger og mønstre. Transfer learning lar modellen bruke det den allerede har lært om å gjenkjenne bildeelementer, og bruke det til å gjenkjenne nye bilder.
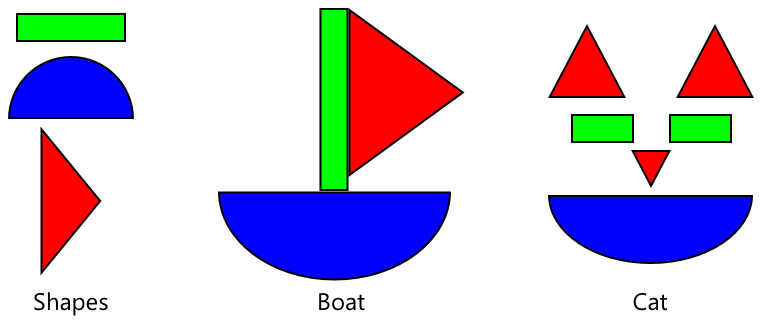
Du kan tenke på dette som barnebøker om former, der du, når du kan gjenkjenne en halvsirkel, et rektangel og en trekant, kan gjenkjenne en seilbåt eller en katt avhengig av konfigurasjonen av disse formene. Bildegjenkjenneren kan gjenkjenne formene, og transfer learning lærer den hvilken kombinasjon som utgjør en båt eller en katt – eller en moden banan.
Det finnes et bredt spekter av verktøy som kan hjelpe deg med dette, inkludert skybaserte tjenester som kan hjelpe deg med å trene modellen din og deretter bruke den via web-API-er.
💁 Å trene disse modellene krever mye datakraft, vanligvis via grafikkprosessorer (GPU-er). Den samme spesialiserte maskinvaren som gjør spillene på Xbox-en din fantastiske, kan også brukes til å trene maskinlæringsmodeller. Ved å bruke skyen kan du leie tid på kraftige datamaskiner med GPU-er for å trene disse modellene, og få tilgang til den datakraften du trenger, kun for den tiden du trenger den.
Custom Vision
Custom Vision er et skybasert verktøy for å trene bildegjenkjenner. Det lar deg trene en gjenkjenner ved hjelp av bare et lite antall bilder. Du kan laste opp bilder gjennom en nettportal, et web-API eller et SDK, og gi hvert bilde en merkelapp som klassifiserer bildet. Deretter trener du modellen og tester den for å se hvor godt den fungerer. Når du er fornøyd med modellen, kan du publisere versjoner av den som kan nås via et web-API eller et SDK.
![]()
💁 Du kan trene en Custom Vision-modell med så lite som 5 bilder per klassifisering, men flere bilder gir bedre resultater. Du kan oppnå bedre resultater med minst 30 bilder.
Custom Vision er en del av en rekke AI-verktøy fra Microsoft kalt Cognitive Services. Dette er AI-verktøy som kan brukes enten uten trening eller med en liten mengde trening. De inkluderer talegjenkjenning og oversettelse, språkforståelse og bildeanalyse. Disse er tilgjengelige med en gratis nivå som tjenester i Azure.
💁 Gratisnivået er mer enn nok til å lage en modell, trene den og deretter bruke den til utviklingsarbeid. Du kan lese om begrensningene for gratisnivået på Custom Vision Limits and quotas-siden på Microsoft Docs.
Oppgave – opprett en Cognitive Services-ressurs
For å bruke Custom Vision må du først opprette to Cognitive Services-ressurser i Azure ved hjelp av Azure CLI, én for Custom Vision-trening og én for Custom Vision-prediksjon.
-
Opprett en ressursgruppe for dette prosjektet kalt
fruit-quality-detector. -
Bruk følgende kommando for å opprette en gratis Custom Vision-treningsressurs:
az cognitiveservices account create --name fruit-quality-detector-training \ --resource-group fruit-quality-detector \ --kind CustomVision.Training \ --sku F0 \ --yes \ --location <location>Erstatt
<location>med plasseringen du brukte da du opprettet ressursgruppen.Dette vil opprette en Custom Vision-treningsressurs i ressursgruppen din. Den vil bli kalt
fruit-quality-detector-trainingog brukeF0SKU, som er gratisnivået. Alternativet--yesbetyr at du godtar vilkårene og betingelsene for Cognitive Services.
💁 Bruk
S0SKU hvis du allerede har en gratis konto som bruker noen av Cognitive Services.
-
Bruk følgende kommando for å opprette en gratis Custom Vision-prediksjonsressurs:
az cognitiveservices account create --name fruit-quality-detector-prediction \ --resource-group fruit-quality-detector \ --kind CustomVision.Prediction \ --sku F0 \ --yes \ --location <location>Erstatt
<location>med plasseringen du brukte da du opprettet ressursgruppen.Dette vil opprette en Custom Vision-prediksjonsressurs i ressursgruppen din. Den vil bli kalt
fruit-quality-detector-predictionog brukeF0SKU, som er gratisnivået. Alternativet--yesbetyr at du godtar vilkårene og betingelsene for Cognitive Services.
Oppgave – opprett et bildegjenkjennerprosjekt
-
Åpne Custom Vision-portalen på CustomVision.ai, og logg inn med Microsoft-kontoen du brukte for Azure-kontoen din.
-
Følg seksjonen for å opprette et nytt prosjekt i hurtigstarten for å bygge en gjenkjenner på Microsoft Docs for å opprette et nytt Custom Vision-prosjekt. Brukergrensesnittet kan endres, og disse dokumentene er alltid den mest oppdaterte referansen.
Kall prosjektet ditt
fruit-quality-detector.Når du oppretter prosjektet ditt, må du sørge for å bruke
fruit-quality-detector-training-ressursen du opprettet tidligere. Bruk en Klassifisering-prosjekttype, en Multiklasse-klassifiseringstype og Mat-domenet.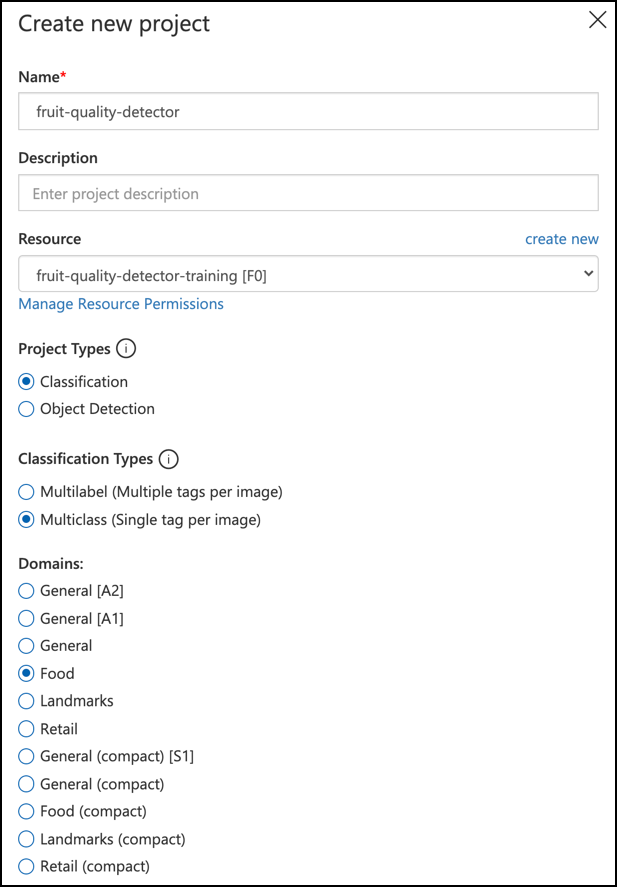
✅ Ta deg tid til å utforske Custom Vision-brukergrensesnittet for bildegjenkjenneren din.
Oppgave – tren bildegjenkjennerprosjektet ditt
For å trene en bildegjenkjenner trenger du flere bilder av frukt, både av god og dårlig kvalitet, som du kan merke som god og dårlig, for eksempel en moden og en overmoden banan. 💁 Disse klassifiseringsmodellene kan klassifisere bilder av hva som helst, så hvis du ikke har frukt tilgjengelig med ulik kvalitet, kan du bruke to forskjellige typer frukt, eller katter og hunder! Ideelt sett bør hvert bilde kun vise frukten, med enten en konsistent bakgrunn eller et bredt utvalg av bakgrunner. Sørg for at det ikke er noe i bakgrunnen som er spesifikt for moden vs umoden frukt.
💁 Det er viktig å unngå spesifikke bakgrunner eller spesifikke elementer som ikke er relatert til det som klassifiseres for hver tag. Ellers kan det hende at klassifiseringsmodellen bare klassifiserer basert på bakgrunnen. Det var en klassifiseringsmodell for hudkreft som ble trent på føflekker, både normale og kreftfremkallende. De kreftfremkallende hadde alle linjaler ved siden av for å måle størrelsen. Det viste seg at modellen var nesten 100 % nøyaktig til å identifisere linjaler i bilder, ikke kreftfremkallende føflekker.
Bildeklassifiseringsmodeller kjører på svært lav oppløsning. For eksempel kan Custom Vision bruke trenings- og prediksjonsbilder opptil 10240x10240, men trener og kjører modellen på bilder i 227x227. Større bilder blir krympet til denne størrelsen, så sørg for at det du klassifiserer tar opp en stor del av bildet. Ellers kan det bli for lite i det mindre bildet som brukes av modellen.
-
Samle bilder til klassifiseringsmodellen din. Du trenger minst 5 bilder for hver etikett for å trene modellen, men jo flere, jo bedre. Du vil også trenge noen ekstra bilder for å teste modellen. Disse bildene bør alle være forskjellige bilder av samme ting. For eksempel:
-
Bruk 2 modne bananer, ta noen bilder av hver fra forskjellige vinkler, minst 7 bilder (5 for trening, 2 for testing), men helst flere.

-
Gjenta samme prosess med 2 umodne bananer.
Du bør ha minst 10 treningsbilder, med minst 5 modne og 5 umodne, og 4 testbilder, 2 modne og 2 umodne. Bildene dine bør være i png- eller jpeg-format og mindre enn 6 MB. Hvis du for eksempel tar dem med en iPhone, kan de være høyoppløselige HEIC-bilder, så de må konverteres og muligens krympes. Jo flere bilder, jo bedre, og du bør ha et lignende antall modne og umodne.
Hvis du ikke har både moden og umoden frukt, kan du bruke forskjellige frukter eller andre to objekter du har tilgjengelig. Du kan også finne noen eksempelbilder i images-mappen av modne og umodne bananer som du kan bruke.
-
-
Følg seksjonen for opplasting og tagging av bilder i hurtigstarten for å bygge en klassifiseringsmodell på Microsoft Docs for å laste opp treningsbildene dine. Merk de modne fruktene som
ripe, og de umodne somunripe.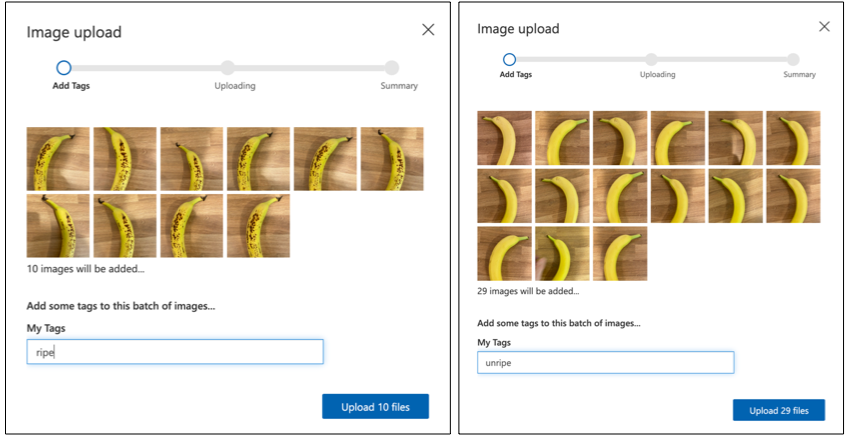
-
Følg seksjonen for å trene klassifiseringsmodellen i hurtigstarten på Microsoft Docs for å trene bildeklassifiseringsmodellen på de opplastede bildene dine.
Du vil få et valg av treningstype. Velg Quick Training.
Modellen vil deretter trenes. Det vil ta noen minutter før treningen er fullført.
🍌 Hvis du bestemmer deg for å spise frukten din mens modellen trenes, sørg for at du har nok bilder til testing først!
Test bildeklassifiseringsmodellen din
Når modellen din er trent, kan du teste den ved å gi den et nytt bilde å klassifisere.
Oppgave - test bildeklassifiseringsmodellen din
-
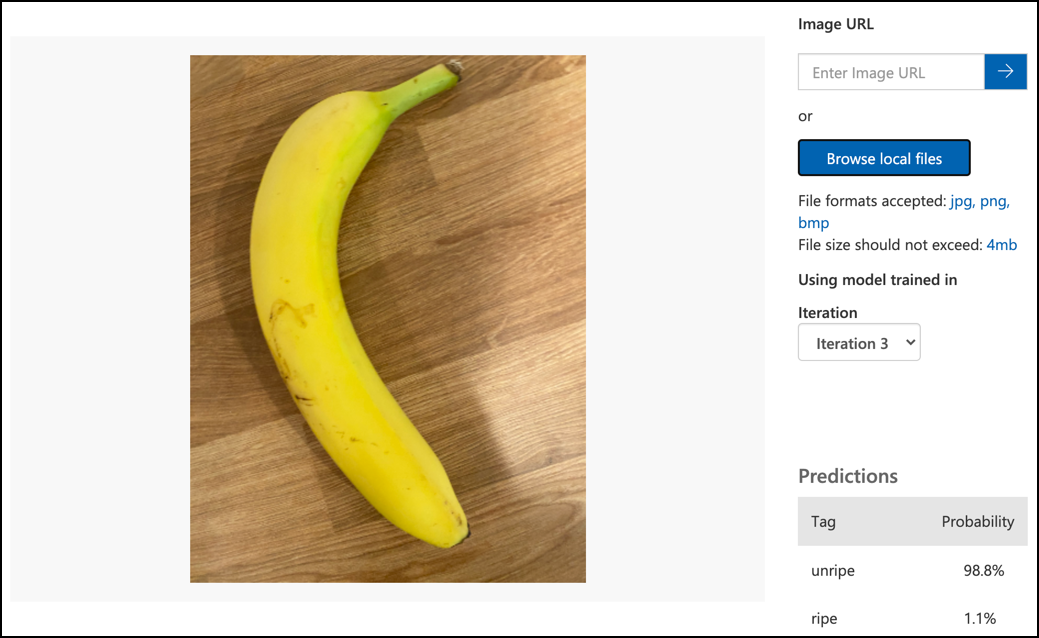
Følg dokumentasjonen for å teste modellen din på Microsoft Docs for å teste bildeklassifiseringsmodellen din. Bruk testbildene du opprettet tidligere, ikke noen av bildene du brukte til trening.
-
Prøv alle testbildene du har tilgang til og observer sannsynlighetene.
Tren bildeklassifiseringsmodellen din på nytt
Når du tester modellen din, kan det hende at den ikke gir de resultatene du forventer. Bildeklassifiseringsmodeller bruker maskinlæring for å gjøre prediksjoner om hva som er i et bilde, basert på sannsynligheter for at bestemte trekk ved et bilde betyr at det samsvarer med en bestemt etikett. Den forstår ikke hva som er i bildet – den vet ikke hva en banan er eller forstår hva som gjør en banan til en banan i stedet for en båt. Du kan forbedre modellen din ved å trene den på nytt med bilder den klassifiserer feil.
Hver gang du gjør en prediksjon ved hjelp av hurtigtestalternativet, lagres bildet og resultatene. Du kan bruke disse bildene til å trene modellen din på nytt.
Oppgave - tren bildeklassifiseringsmodellen din på nytt
-
Følg dokumentasjonen for å bruke det predikerte bildet til trening på Microsoft Docs for å trene modellen din på nytt, ved å bruke riktig tag for hvert bilde.
-
Når modellen din er trent på nytt, test den på nye bilder.
🚀 Utfordring
Hva tror du vil skje hvis du bruker et bilde av et jordbær med en modell trent på bananer, eller et bilde av en oppblåsbar banan, eller en person i et banankostyme, eller til og med en gul tegneseriefigur som noen fra Simpsons?
Prøv det og se hva prediksjonene er. Du kan finne bilder å prøve med ved å bruke Bing Image search.
Quiz etter forelesning
Gjennomgang og selvstudium
- Når du trente modellen din, ville du ha sett verdier for Precision, Recall og AP som vurderer modellen som ble opprettet. Les om hva disse verdiene er ved å bruke seksjonen for å evaluere klassifiseringsmodellen i hurtigstarten på Microsoft Docs
- Les om hvordan du kan forbedre modellen din fra hvordan forbedre Custom Vision-modellen din på Microsoft Docs
Oppgave
Tren modellen din for flere frukter og grønnsaker
Ansvarsfraskrivelse:
Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten Co-op Translator. Selv om vi streber etter nøyaktighet, vær oppmerksom på at automatiserte oversettelser kan inneholde feil eller unøyaktigheter. Det originale dokumentet på sitt opprinnelige språk bør anses som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.