10 KiB
Tetapkan pemasa dan berikan maklum balas secara lisan
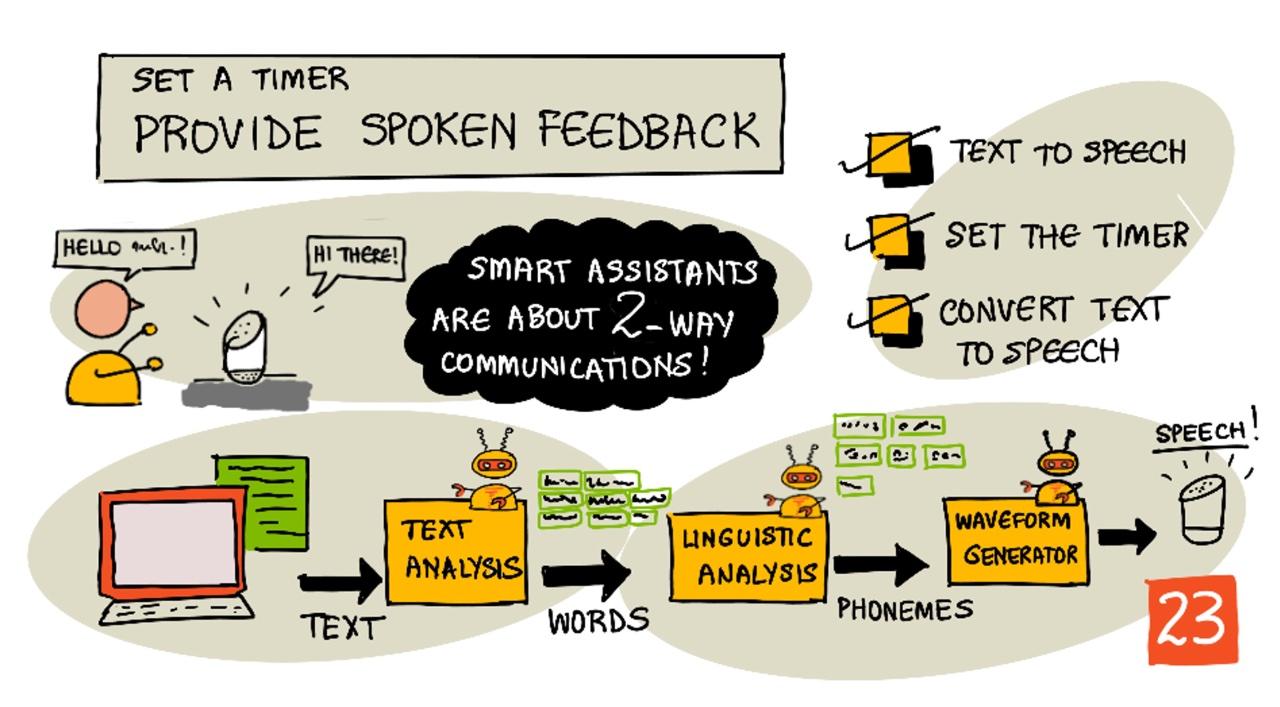
Sketchnote oleh Nitya Narasimhan. Klik imej untuk versi yang lebih besar.
Kuiz sebelum kuliah
Pengenalan
Pembantu pintar bukanlah alat komunikasi satu hala. Anda bercakap dengannya, dan ia memberikan respons:
"Alexa, tetapkan pemasa selama 3 minit"
"Baik, pemasa anda telah ditetapkan selama 3 minit"
Dalam dua pelajaran sebelum ini, anda telah belajar cara mengambil pertuturan dan menukarkannya kepada teks, kemudian mengekstrak permintaan tetapan pemasa daripada teks tersebut. Dalam pelajaran ini, anda akan belajar cara menetapkan pemasa pada peranti IoT, memberikan respons kepada pengguna dengan kata-kata lisan yang mengesahkan pemasa mereka, dan memberitahu mereka apabila pemasa selesai.
Dalam pelajaran ini, kita akan membincangkan:
Teks ke pertuturan
Teks ke pertuturan, seperti namanya, adalah proses menukar teks kepada audio yang mengandungi teks tersebut sebagai kata-kata yang diucapkan. Prinsip asasnya adalah memecahkan perkataan dalam teks kepada bunyi-bunyi konstituen mereka (dikenali sebagai fonem), dan menyusun audio untuk bunyi-bunyi tersebut, sama ada menggunakan audio yang telah dirakam terlebih dahulu atau menggunakan audio yang dihasilkan oleh model AI.

Sistem teks ke pertuturan biasanya mempunyai 3 peringkat:
- Analisis teks
- Analisis linguistik
- Penjanaan gelombang bunyi
Analisis teks
Analisis teks melibatkan mengambil teks yang diberikan dan menukarkannya kepada perkataan yang boleh digunakan untuk menghasilkan pertuturan. Sebagai contoh, jika anda menukar "Hello world", tiada analisis teks diperlukan, dua perkataan tersebut boleh terus ditukar kepada pertuturan. Jika anda mempunyai "1234" pula, ini mungkin perlu ditukar sama ada kepada perkataan "Satu ribu dua ratus tiga puluh empat" atau "Satu, dua, tiga, empat" bergantung pada konteks. Untuk "Saya ada 1234 epal", maka ia akan menjadi "Satu ribu dua ratus tiga puluh empat", tetapi untuk "Kanak-kanak itu mengira 1234" maka ia akan menjadi "Satu, dua, tiga, empat".
Perkataan yang dihasilkan berbeza bukan sahaja mengikut bahasa, tetapi juga lokasi bahasa tersebut. Sebagai contoh, dalam Bahasa Inggeris Amerika, 120 akan disebut "One hundred twenty", manakala dalam Bahasa Inggeris British ia akan disebut "One hundred and twenty", dengan penggunaan "and" selepas ratusan.
✅ Beberapa contoh lain yang memerlukan analisis teks termasuk "in" sebagai singkatan inci, dan "st" sebagai singkatan saint dan jalan. Bolehkah anda memikirkan contoh lain dalam bahasa anda tentang perkataan yang tidak jelas tanpa konteks?
Setelah perkataan ditentukan, ia dihantar untuk analisis linguistik.
Analisis linguistik
Analisis linguistik memecahkan perkataan kepada fonem. Fonem bergantung bukan sahaja pada huruf yang digunakan, tetapi juga huruf lain dalam perkataan tersebut. Sebagai contoh, dalam Bahasa Inggeris bunyi 'a' dalam 'car' dan 'care' adalah berbeza. Bahasa Inggeris mempunyai 44 fonem berbeza untuk 26 huruf dalam abjad, beberapa daripadanya dikongsi oleh huruf yang berbeza, seperti fonem yang sama digunakan pada permulaan 'circle' dan 'serpent'.
✅ Lakukan penyelidikan: Apakah fonem untuk bahasa anda?
Setelah perkataan ditukar kepada fonem, fonem ini memerlukan data tambahan untuk menyokong intonasi, menyesuaikan nada atau tempoh bergantung pada konteks. Salah satu contoh adalah dalam Bahasa Inggeris, peningkatan nada boleh digunakan untuk menukar ayat menjadi soalan, dengan nada yang meningkat pada perkataan terakhir menunjukkan soalan.
Sebagai contoh - ayat "You have an apple" adalah kenyataan yang mengatakan bahawa anda mempunyai sebiji epal. Jika nada meningkat di akhir, meningkat pada perkataan apple, ia menjadi soalan "You have an apple?", bertanya sama ada anda mempunyai sebiji epal. Analisis linguistik perlu menggunakan tanda soal di akhir untuk memutuskan untuk meningkatkan nada.
Setelah fonem dihasilkan, ia boleh dihantar untuk penjanaan gelombang bunyi untuk menghasilkan output audio.
Penjanaan gelombang bunyi
Sistem teks ke pertuturan elektronik pertama menggunakan rakaman audio tunggal untuk setiap fonem, menghasilkan suara yang sangat monoton dan seperti robot. Analisis linguistik akan menghasilkan fonem, fonem ini akan dimuatkan dari pangkalan data bunyi dan disusun untuk menghasilkan audio.
✅ Lakukan penyelidikan: Cari beberapa rakaman audio daripada sistem sintesis pertuturan awal. Bandingkan dengan sintesis pertuturan moden, seperti yang digunakan dalam pembantu pintar.
Penjanaan gelombang bunyi yang lebih moden menggunakan model ML yang dibina menggunakan pembelajaran mendalam (rangkaian neural yang sangat besar yang bertindak serupa dengan neuron dalam otak) untuk menghasilkan suara yang lebih semula jadi yang sukar dibezakan daripada manusia.
💁 Beberapa model ML ini boleh dilatih semula menggunakan pembelajaran pemindahan untuk menyerupai suara orang sebenar. Ini bermakna menggunakan suara sebagai sistem keselamatan, sesuatu yang semakin banyak digunakan oleh bank, bukan lagi idea yang baik kerana sesiapa yang mempunyai rakaman beberapa minit suara anda boleh menyamar sebagai anda.
Model ML besar ini sedang dilatih untuk menggabungkan ketiga-tiga langkah menjadi penyintesis pertuturan hujung ke hujung.
Tetapkan pemasa
Untuk menetapkan pemasa, peranti IoT anda perlu memanggil titik akhir REST yang anda buat menggunakan kod tanpa pelayan, kemudian menggunakan bilangan saat yang dihasilkan untuk menetapkan pemasa.
Tugasan - panggil fungsi tanpa pelayan untuk mendapatkan masa pemasa
Ikuti panduan yang berkaitan untuk memanggil titik akhir REST daripada peranti IoT anda dan menetapkan pemasa untuk masa yang diperlukan:
Tukar teks ke pertuturan
Perkhidmatan pertuturan yang sama yang anda gunakan untuk menukar pertuturan kepada teks boleh digunakan untuk menukar teks kembali kepada pertuturan, dan ini boleh dimainkan melalui pembesar suara pada peranti IoT anda. Teks untuk ditukar dihantar ke perkhidmatan pertuturan, bersama-sama dengan jenis audio yang diperlukan (seperti kadar sampel), dan data binari yang mengandungi audio dikembalikan.
Apabila anda menghantar permintaan ini, anda menghantarnya menggunakan Speech Synthesis Markup Language (SSML), bahasa markup berasaskan XML untuk aplikasi sintesis pertuturan. Ini mentakrifkan bukan sahaja teks untuk ditukar, tetapi juga bahasa teks, suara yang digunakan, dan bahkan boleh digunakan untuk mentakrifkan kelajuan, kelantangan, dan nada untuk beberapa atau semua perkataan dalam teks.
Sebagai contoh, SSML ini mentakrifkan permintaan untuk menukar teks "Pemasa anda selama 3 minit 5 saat telah ditetapkan" kepada pertuturan menggunakan suara Bahasa Inggeris British yang dipanggil en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 Kebanyakan sistem teks ke pertuturan mempunyai pelbagai suara untuk bahasa yang berbeza, dengan aksen yang relevan seperti suara Bahasa Inggeris British dengan aksen Inggeris dan suara Bahasa Inggeris New Zealand dengan aksen New Zealand.
Tugasan - tukar teks ke pertuturan
Ikuti panduan yang berkaitan untuk menukar teks ke pertuturan menggunakan peranti IoT anda:
🚀 Cabaran
SSML mempunyai cara untuk mengubah cara perkataan diucapkan, seperti menambah penekanan pada perkataan tertentu, menambah jeda, atau mengubah nada. Cuba beberapa cara ini, hantar SSML yang berbeza daripada peranti IoT anda dan bandingkan outputnya. Anda boleh membaca lebih lanjut tentang SSML, termasuk cara mengubah cara perkataan diucapkan dalam Spesifikasi Speech Synthesis Markup Language (SSML) Versi 1.1 daripada World Wide Web Consortium.
Kuiz selepas kuliah
Ulasan & Kajian Kendiri
- Baca lebih lanjut tentang sintesis pertuturan di halaman sintesis pertuturan di Wikipedia
- Baca lebih lanjut tentang cara penjenayah menggunakan sintesis pertuturan untuk mencuri di cerita 'suara palsu membantu penjenayah siber mencuri wang' di berita BBC
- Ketahui lebih lanjut tentang risiko kepada pelakon suara daripada versi sintesis suara mereka dalam artikel ini tentang tuntutan mahkamah TikTok yang menonjolkan bagaimana AI merugikan pelakon suara di Vice
Tugasan
Penafian:
Dokumen ini telah diterjemahkan menggunakan perkhidmatan terjemahan AI Co-op Translator. Walaupun kami berusaha untuk memastikan ketepatan, sila ambil perhatian bahawa terjemahan automatik mungkin mengandungi kesilapan atau ketidaktepatan. Dokumen asal dalam bahasa asalnya harus dianggap sebagai sumber yang berwibawa. Untuk maklumat yang kritikal, terjemahan manusia profesional adalah disyorkan. Kami tidak bertanggungjawab atas sebarang salah faham atau salah tafsir yang timbul daripada penggunaan terjemahan ini.