10 KiB
Configura un temporizador y proporciona retroalimentación hablada
Boceto por Nitya Narasimhan. Haz clic en la imagen para una versión más grande.
Cuestionario previo a la lección
Cuestionario previo a la lección
Introducción
Los asistentes inteligentes no son dispositivos de comunicación unidireccional. Les hablas y ellos responden:
"Alexa, configura un temporizador de 3 minutos"
"Ok, tu temporizador está configurado para 3 minutos"
En las últimas 2 lecciones aprendiste cómo tomar un discurso y convertirlo en texto, y luego extraer una solicitud de temporizador de ese texto. En esta lección aprenderás cómo configurar el temporizador en el dispositivo IoT, respondiendo al usuario con palabras habladas que confirmen su temporizador y alertándoles cuando el temporizador haya terminado.
En esta lección cubriremos:
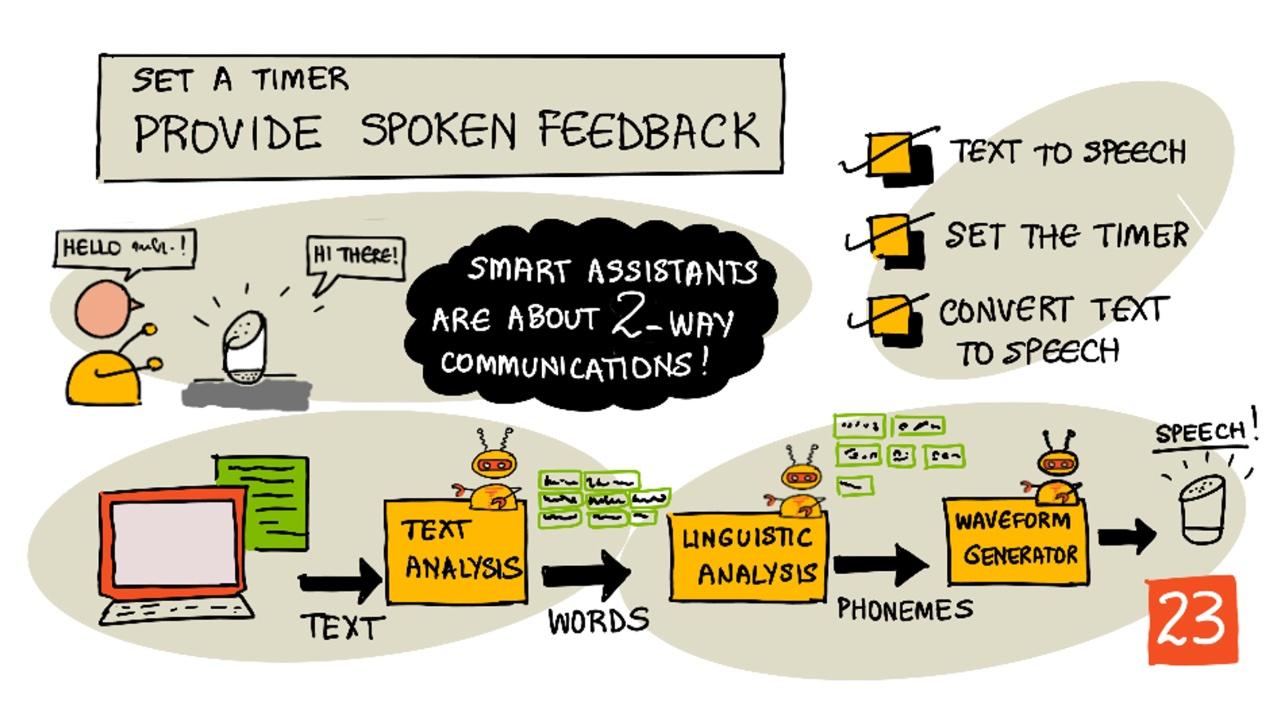
Texto a voz
Texto a voz, como su nombre lo indica, es el proceso de convertir texto en audio que contiene las palabras habladas. El principio básico es descomponer las palabras del texto en sus sonidos constituyentes (conocidos como fonemas) y unir el audio de esos sonidos, ya sea utilizando audio pregrabado o generado por modelos de inteligencia artificial.

Los sistemas de texto a voz generalmente tienen 3 etapas:
- Análisis de texto
- Análisis lingüístico
- Generación de forma de onda
Análisis de texto
El análisis de texto implica tomar el texto proporcionado y convertirlo en palabras que puedan usarse para generar voz. Por ejemplo, si conviertes "Hola mundo", no se necesita análisis de texto, las dos palabras pueden convertirse directamente en voz. Sin embargo, si tienes "1234", esto podría necesitar convertirse en las palabras "Mil doscientos treinta y cuatro" o "Uno, dos, tres, cuatro" dependiendo del contexto. Para "Tengo 1234 manzanas", sería "Mil doscientos treinta y cuatro", pero para "El niño contó 1234" sería "Uno, dos, tres, cuatro".
Las palabras creadas varían no solo por el idioma, sino también por la región de ese idioma. Por ejemplo, en inglés americano, 120 sería "One hundred twenty", mientras que en inglés británico sería "One hundred and twenty", con el uso de "and" después de los cientos.
✅ Algunos otros ejemplos que requieren análisis de texto incluyen "in" como abreviatura de pulgada, y "st" como abreviatura de santo o calle. ¿Puedes pensar en otros ejemplos en tu idioma de palabras que sean ambiguas sin contexto?
Una vez que se han definido las palabras, se envían para análisis lingüístico.
Análisis lingüístico
El análisis lingüístico descompone las palabras en fonemas. Los fonemas no solo se basan en las letras utilizadas, sino también en las otras letras de la palabra. Por ejemplo, en inglés el sonido de la 'a' en 'car' y 'care' es diferente. El idioma inglés tiene 44 fonemas diferentes para las 26 letras del alfabeto, algunos compartidos por diferentes letras, como el mismo fonema utilizado al inicio de 'circle' y 'serpent'.
✅ Investiga: ¿Cuáles son los fonemas de tu idioma?
Una vez que las palabras se han convertido en fonemas, estos necesitan datos adicionales para soportar la entonación, ajustando el tono o la duración dependiendo del contexto. Un ejemplo es que en inglés, los aumentos de tono pueden usarse para convertir una oración en una pregunta, elevando el tono de la última palabra para implicar una pregunta.
Por ejemplo, la oración "You have an apple" es una afirmación que dice que tienes una manzana. Si el tono sube al final, aumentando en la palabra "apple", se convierte en la pregunta "You have an apple?", preguntando si tienes una manzana. El análisis lingüístico necesita usar el signo de interrogación al final para decidir aumentar el tono.
Una vez que se han generado los fonemas, se pueden enviar para la generación de forma de onda para producir la salida de audio.
Generación de forma de onda
Los primeros sistemas electrónicos de texto a voz usaban grabaciones de audio individuales para cada fonema, lo que resultaba en voces muy monótonas y robóticas. El análisis lingüístico producía fonemas, estos se cargaban desde una base de datos de sonidos y se unían para crear el audio.
✅ Investiga: Encuentra algunas grabaciones de audio de los primeros sistemas de síntesis de voz. Compáralas con la síntesis de voz moderna, como la que se usa en los asistentes inteligentes.
La generación de forma de onda más moderna utiliza modelos de aprendizaje automático (ML) construidos con aprendizaje profundo (redes neuronales muy grandes que actúan de manera similar a las neuronas en el cerebro) para producir voces más naturales que pueden ser indistinguibles de las humanas.
💁 Algunos de estos modelos de ML pueden ser reentrenados utilizando aprendizaje por transferencia para sonar como personas reales. Esto significa que usar la voz como un sistema de seguridad, algo que los bancos están intentando cada vez más, ya no es una buena idea, ya que cualquiera con una grabación de unos minutos de tu voz puede hacerse pasar por ti.
Estos grandes modelos de ML están siendo entrenados para combinar los tres pasos en sintetizadores de voz de extremo a extremo.
Configurar el temporizador
Para configurar el temporizador, tu dispositivo IoT necesita llamar al endpoint REST que creaste usando código serverless, y luego usar el número resultante de segundos para configurar un temporizador.
Tarea - llamar a la función serverless para obtener el tiempo del temporizador
Sigue la guía relevante para llamar al endpoint REST desde tu dispositivo IoT y configurar un temporizador para el tiempo requerido:
Convertir texto a voz
El mismo servicio de voz que usaste para convertir voz a texto puede usarse para convertir texto de vuelta a voz, y esto puede reproducirse a través de un altavoz en tu dispositivo IoT. El texto a convertir se envía al servicio de voz, junto con el tipo de audio requerido (como la tasa de muestreo), y se devuelve un dato binario que contiene el audio.
Cuando envías esta solicitud, lo haces utilizando Lenguaje de Marcado de Síntesis de Voz (SSML), un lenguaje de marcado basado en XML para aplicaciones de síntesis de voz. Esto define no solo el texto a convertir, sino también el idioma del texto, la voz a usar, e incluso puede usarse para definir velocidad, volumen y tono para algunas o todas las palabras en el texto.
Por ejemplo, este SSML define una solicitud para convertir el texto "Tu temporizador de 3 minutos y 5 segundos ha sido configurado" a voz usando una voz en inglés británico llamada en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 La mayoría de los sistemas de texto a voz tienen múltiples voces para diferentes idiomas, con acentos relevantes como una voz en inglés británico con acento inglés y una voz en inglés de Nueva Zelanda con acento neozelandés.
Tarea - convertir texto a voz
Sigue la guía relevante para convertir texto a voz usando tu dispositivo IoT:
- Arduino - Wio Terminal
- Computadora de placa única - Raspberry Pi
- Computadora de placa única - Dispositivo virtual
🚀 Desafío
SSML tiene formas de cambiar cómo se pronuncian las palabras, como agregar énfasis a ciertas palabras, agregar pausas o cambiar el tono. Prueba algunas de estas opciones, enviando diferentes SSML desde tu dispositivo IoT y comparando los resultados. Puedes leer más sobre SSML, incluyendo cómo cambiar la forma en que se pronuncian las palabras en la especificación de la Versión 1.1 del Lenguaje de Marcado de Síntesis de Voz (SSML) del consorcio World Wide Web.
Cuestionario posterior a la lección
Cuestionario posterior a la lección
Revisión y autoestudio
- Lee más sobre síntesis de voz en la página de síntesis de voz en Wikipedia
- Lee más sobre cómo los delincuentes están utilizando la síntesis de voz para robar en la noticia de la BBC sobre voces falsas que 'ayudan a los cibercriminales a robar dinero'
- Aprende más sobre los riesgos para los actores de voz por versiones sintetizadas de sus voces en el artículo de Vice sobre cómo esta demanda de TikTok está destacando cómo la IA está perjudicando a los actores de voz
Tarea
Descargo de responsabilidad:
Este documento ha sido traducido utilizando el servicio de traducción automática Co-op Translator. Si bien nos esforzamos por garantizar la precisión, tenga en cuenta que las traducciones automatizadas pueden contener errores o imprecisiones. El documento original en su idioma nativo debe considerarse la fuente autorizada. Para información crítica, se recomienda una traducción profesional realizada por humanos. No nos hacemos responsables de malentendidos o interpretaciones erróneas que puedan surgir del uso de esta traducción.