17 KiB
Trainiere einen Lagerbestand-Detektor
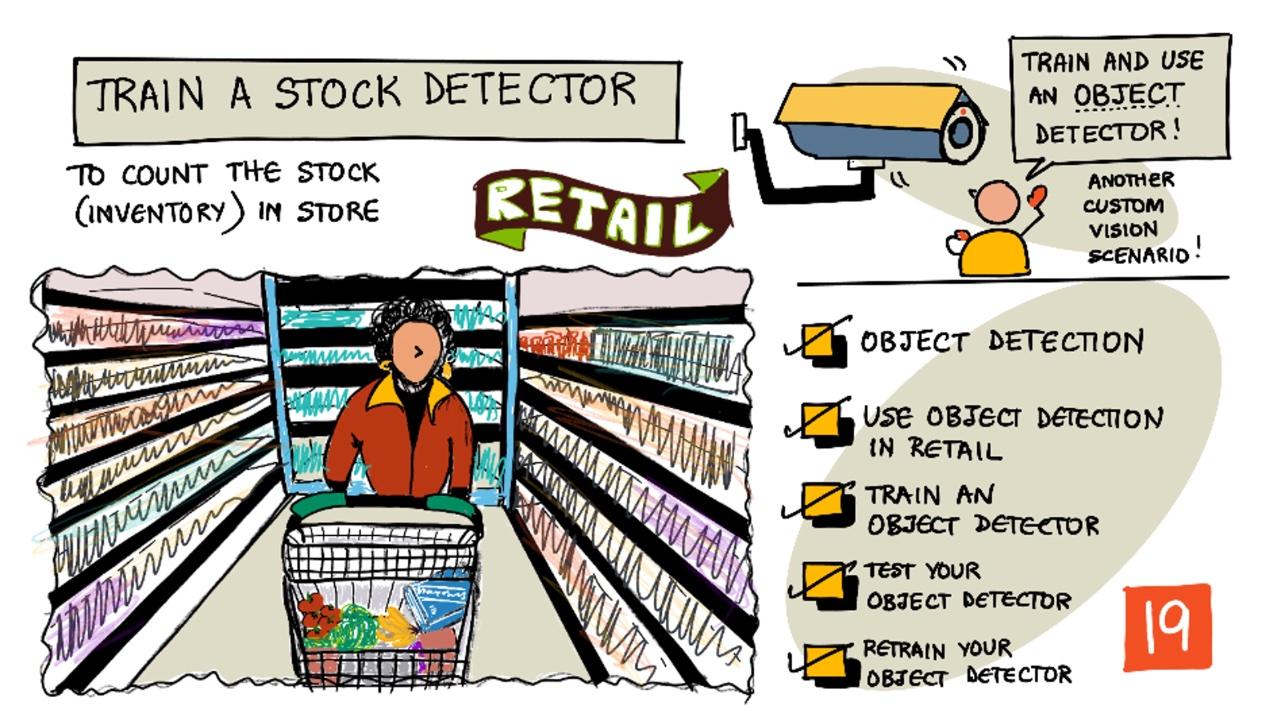
Sketchnote von Nitya Narasimhan. Klicken Sie auf das Bild für eine größere Version.
Dieses Video gibt einen Überblick über die Objekterkennung mit dem Azure Custom Vision Service, einem Dienst, der in dieser Lektion behandelt wird.

🎥 Klicken Sie auf das Bild oben, um das Video anzusehen.
Quiz vor der Vorlesung
Einführung
Im vorherigen Projekt haben Sie KI verwendet, um einen Bildklassifikator zu trainieren – ein Modell, das erkennen kann, ob ein Bild etwas enthält, wie z. B. reife oder unreife Früchte. Eine andere Art von KI-Modell, die mit Bildern verwendet werden kann, ist die Objekterkennung. Diese Modelle klassifizieren ein Bild nicht anhand von Tags, sondern werden darauf trainiert, Objekte zu erkennen und sie in Bildern zu finden. Sie erkennen nicht nur, dass das Objekt vorhanden ist, sondern auch, wo es sich im Bild befindet. Dies ermöglicht das Zählen von Objekten in Bildern.
In dieser Lektion lernen Sie die Objekterkennung kennen, einschließlich ihrer Anwendung im Einzelhandel. Außerdem erfahren Sie, wie Sie einen Objekterkenner in der Cloud trainieren können.
In dieser Lektion behandeln wir:
- Objekterkennung
- Objekterkennung im Einzelhandel einsetzen
- Einen Objekterkenner trainieren
- Den Objekterkenner testen
- Den Objekterkenner erneut trainieren
Objekterkennung
Die Objekterkennung umfasst das Erkennen von Objekten in Bildern mithilfe von KI. Im Gegensatz zum Bildklassifikator, den Sie im letzten Projekt trainiert haben, geht es bei der Objekterkennung nicht darum, das beste Tag für ein Bild als Ganzes vorherzusagen, sondern darum, ein oder mehrere Objekte in einem Bild zu finden.
Objekterkennung vs. Bildklassifikation
Die Bildklassifikation dient dazu, ein Bild als Ganzes zu klassifizieren – welche Wahrscheinlichkeiten bestehen, dass das gesamte Bild mit jedem Tag übereinstimmt. Sie erhalten Wahrscheinlichkeiten für jedes Tag, das zum Trainieren des Modells verwendet wurde.

Im obigen Beispiel werden zwei Bilder mit einem Modell klassifiziert, das darauf trainiert wurde, Dosen mit Cashewkernen oder Tomatenmark zu klassifizieren. Das erste Bild zeigt eine Dose Cashewkerne und hat zwei Ergebnisse vom Bildklassifikator:
| Tag | Wahrscheinlichkeit |
|---|---|
Cashewkerne |
98,4% |
Tomatenmark |
1,6% |
Das zweite Bild zeigt eine Dose Tomatenmark, und die Ergebnisse sind:
| Tag | Wahrscheinlichkeit |
|---|---|
Cashewkerne |
0,7% |
Tomatenmark |
99,3% |
Sie könnten diese Werte mit einem Schwellenwert verwenden, um vorherzusagen, was im Bild enthalten ist. Aber was, wenn ein Bild mehrere Dosen Tomatenmark oder sowohl Cashewkerne als auch Tomatenmark enthält? Die Ergebnisse würden wahrscheinlich nicht das liefern, was Sie möchten. Hier kommt die Objekterkennung ins Spiel.
Die Objekterkennung umfasst das Trainieren eines Modells, um Objekte zu erkennen. Anstatt ihm Bilder mit dem Objekt zu geben und ihm zu sagen, dass jedes Bild ein Tag oder ein anderes ist, markieren Sie den Abschnitt eines Bildes, der das spezifische Objekt enthält, und taggen diesen. Sie können ein einzelnes Objekt in einem Bild oder mehrere taggen. Auf diese Weise lernt das Modell, wie das Objekt selbst aussieht, nicht nur, wie Bilder aussehen, die das Objekt enthalten.
Wenn Sie es dann zur Vorhersage von Bildern verwenden, erhalten Sie anstelle einer Liste von Tags und Prozentsätzen eine Liste von erkannten Objekten mit ihrem Begrenzungsrahmen und der Wahrscheinlichkeit, dass das Objekt mit dem zugewiesenen Tag übereinstimmt.
🎓 Begrenzungsrahmen sind die Rahmen um ein Objekt.

Das obige Bild enthält sowohl eine Dose Cashewkerne als auch drei Dosen Tomatenmark. Der Objekterkenner hat die Cashewkerne erkannt und den Begrenzungsrahmen zurückgegeben, der die Cashewkerne mit der prozentualen Wahrscheinlichkeit enthält, dass der Begrenzungsrahmen das Objekt enthält, in diesem Fall 97,6%. Der Objekterkenner hat auch drei Dosen Tomatenmark erkannt und liefert drei separate Begrenzungsrahmen, einen für jede erkannte Dose, und jeder hat eine prozentuale Wahrscheinlichkeit, dass der Begrenzungsrahmen eine Dose Tomatenmark enthält.
✅ Überlegen Sie sich einige verschiedene Szenarien, für die Sie bildbasierte KI-Modelle verwenden möchten. Welche würden eine Klassifikation benötigen und welche eine Objekterkennung?
Wie funktioniert die Objekterkennung?
Die Objekterkennung verwendet komplexe ML-Modelle. Diese Modelle funktionieren, indem sie das Bild in mehrere Zellen unterteilen und dann überprüfen, ob das Zentrum des Begrenzungsrahmens das Zentrum eines Bildes ist, das mit einem der Bilder übereinstimmt, die zum Trainieren des Modells verwendet wurden. Sie können sich das wie eine Art Bildklassifikator vorstellen, der über verschiedene Teile des Bildes läuft, um Übereinstimmungen zu finden.
💁 Dies ist eine drastische Vereinfachung. Es gibt viele Techniken zur Objekterkennung, und Sie können mehr darüber auf der Wikipedia-Seite zur Objekterkennung lesen.
Es gibt eine Reihe verschiedener Modelle, die Objekterkennung durchführen können. Ein besonders bekanntes Modell ist YOLO (You only look once), das unglaublich schnell ist und 20 verschiedene Objektklassen erkennen kann, wie Personen, Hunde, Flaschen und Autos.
✅ Lesen Sie mehr über das YOLO-Modell auf pjreddie.com/darknet/yolo/
Objekterkennungsmodelle können mithilfe von Transfer-Learning neu trainiert werden, um benutzerdefinierte Objekte zu erkennen.
Objekterkennung im Einzelhandel einsetzen
Die Objekterkennung hat viele Einsatzmöglichkeiten im Einzelhandel. Einige davon sind:
- Bestandsprüfung und Zählung – Erkennen, wenn der Bestand in den Regalen niedrig ist. Wenn der Bestand zu niedrig ist, können Benachrichtigungen an Mitarbeiter oder Roboter gesendet werden, um die Regale wieder aufzufüllen.
- Maskenerkennung – In Geschäften mit Maskenpflicht während gesundheitlicher Ereignisse kann die Objekterkennung Personen mit und ohne Masken erkennen.
- Automatisierte Abrechnung – Erkennen von Artikeln, die aus Regalen genommen werden, in automatisierten Geschäften und entsprechende Abrechnung der Kunden.
- Gefahrenerkennung – Erkennen von zerbrochenen Gegenständen auf Böden oder verschütteten Flüssigkeiten und Benachrichtigung von Reinigungsteams.
✅ Recherchieren Sie: Welche weiteren Anwendungsfälle für die Objekterkennung im Einzelhandel gibt es?
Einen Objekterkenner trainieren
Sie können einen Objekterkenner mit Custom Vision trainieren, ähnlich wie Sie einen Bildklassifikator trainiert haben.
Aufgabe – einen Objekterkenner erstellen
-
Erstellen Sie eine Ressourcengruppe für dieses Projekt mit dem Namen
stock-detector. -
Erstellen Sie eine kostenlose Custom Vision Trainingsressource und eine kostenlose Custom Vision Vorhersageressource in der Ressourcengruppe
stock-detector. Nennen Sie siestock-detector-trainingundstock-detector-prediction.💁 Sie können nur eine kostenlose Trainings- und Vorhersageressource haben, stellen Sie also sicher, dass Sie Ihr Projekt aus den vorherigen Lektionen bereinigt haben.
⚠️ Sie können die Anweisungen zum Erstellen von Trainings- und Vorhersageressourcen aus Projekt 4, Lektion 1 bei Bedarf nachlesen.
-
Starten Sie das Custom Vision-Portal unter CustomVision.ai und melden Sie sich mit dem Microsoft-Konto an, das Sie für Ihr Azure-Konto verwendet haben.
-
Folgen Sie dem Abschnitt Ein neues Projekt erstellen im Quickstart für den Aufbau eines Objekterkenners in den Microsoft-Dokumenten, um ein neues Custom Vision-Projekt zu erstellen. Die Benutzeroberfläche kann sich ändern, und diese Dokumente sind immer die aktuellste Referenz.
Nennen Sie Ihr Projekt
stock-detector.Wenn Sie Ihr Projekt erstellen, stellen Sie sicher, dass Sie die zuvor erstellte Ressource
stock-detector-trainingverwenden. Verwenden Sie den Projekttyp Objekterkennung und die Domäne Produkte in Regalen.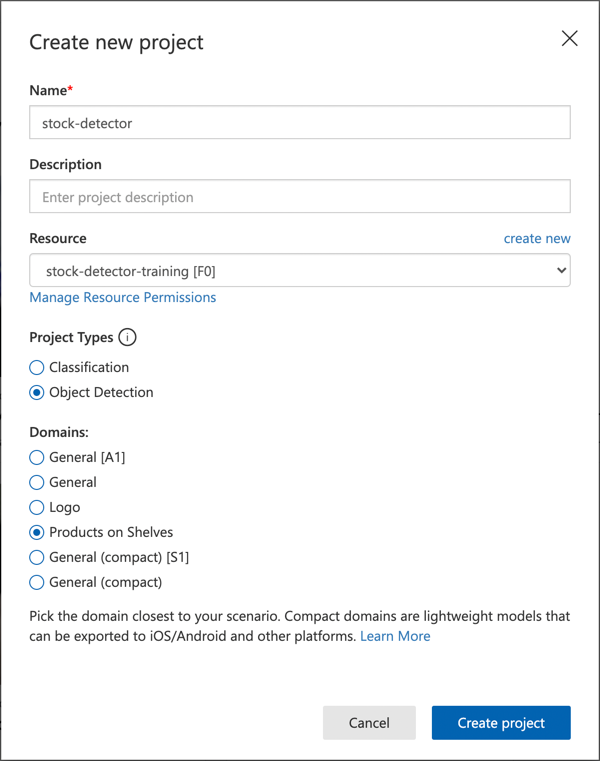
✅ Die Domäne "Produkte in Regalen" ist speziell darauf ausgerichtet, Bestände in Ladenregalen zu erkennen. Lesen Sie mehr über die verschiedenen Domänen in der Dokumentation zur Auswahl einer Domäne auf Microsoft Docs.
✅ Nehmen Sie sich Zeit, um die Benutzeroberfläche von Custom Vision für Ihren Objekterkenner zu erkunden.
Aufgabe – Ihren Objekterkenner trainieren
Um Ihr Modell zu trainieren, benötigen Sie eine Reihe von Bildern, die die Objekte enthalten, die Sie erkennen möchten.
-
Sammeln Sie Bilder, die das zu erkennende Objekt enthalten. Sie benötigen mindestens 15 Bilder, die jedes zu erkennende Objekt aus verschiedenen Blickwinkeln und unter unterschiedlichen Lichtbedingungen zeigen, aber je mehr, desto besser. Dieser Objekterkenner verwendet die Domäne Produkte in Regalen, versuchen Sie also, die Objekte so zu arrangieren, als ob sie in einem Ladenregal wären. Sie benötigen auch einige Bilder, um das Modell zu testen. Wenn Sie mehr als ein Objekt erkennen, sollten einige Testbilder alle Objekte enthalten.
💁 Bilder mit mehreren verschiedenen Objekten zählen zu den 15 Mindestbildern für alle Objekte im Bild.
Ihre Bilder sollten PNG oder JPEG sein, kleiner als 6 MB. Wenn Sie sie beispielsweise mit einem iPhone erstellen, können sie hochauflösende HEIC-Bilder sein, die konvertiert und möglicherweise verkleinert werden müssen. Je mehr Bilder, desto besser, und Sie sollten eine ähnliche Anzahl von reifen und unreifen Objekten haben.
Das Modell ist für Produkte in Regalen konzipiert, versuchen Sie also, die Fotos der Objekte in Regalen zu machen.
Sie finden einige Beispielbilder, die Sie verwenden können, im images-Ordner von Cashewkernen und Tomatenmark, die Sie verwenden können.
-
Folgen Sie dem Abschnitt Bilder hochladen und taggen im Quickstart für den Aufbau eines Objekterkenners in den Microsoft-Dokumenten, um Ihre Trainingsbilder hochzuladen. Erstellen Sie relevante Tags je nach den Arten von Objekten, die Sie erkennen möchten.
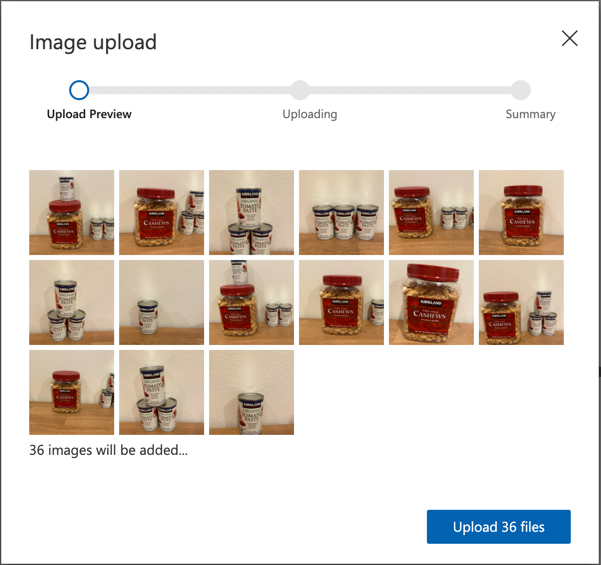
Wenn Sie Begrenzungsrahmen für Objekte zeichnen, halten Sie sie schön eng um das Objekt. Es kann eine Weile dauern, alle Bilder zu umreißen, aber das Tool erkennt, was es für Begrenzungsrahmen hält, was es schneller macht.

💁 Wenn Sie mehr als 15 Bilder für jedes Objekt haben, können Sie nach 15 trainieren und dann die Funktion Vorgeschlagene Tags verwenden. Dies wird das trainierte Modell verwenden, um die Objekte in den nicht getaggten Bildern zu erkennen. Sie können dann die erkannten Objekte bestätigen oder ablehnen und die Begrenzungsrahmen neu zeichnen. Dies kann eine Menge Zeit sparen.
-
Folgen Sie dem Abschnitt Den Erkenner trainieren im Quickstart für den Aufbau eines Objekterkenners in den Microsoft-Dokumenten, um den Objekterkenner mit Ihren getaggten Bildern zu trainieren.
Sie haben die Wahl zwischen verschiedenen Trainingsarten. Wählen Sie Schnelles Training.
Der Objekterkenner wird dann trainiert. Es dauert einige Minuten, bis das Training abgeschlossen ist.
Den Objekterkenner testen
Sobald Ihr Objekterkenner trainiert ist, können Sie ihn testen, indem Sie ihm neue Bilder geben, um Objekte darin zu erkennen.
Aufgabe – Ihren Objekterkenner testen
-
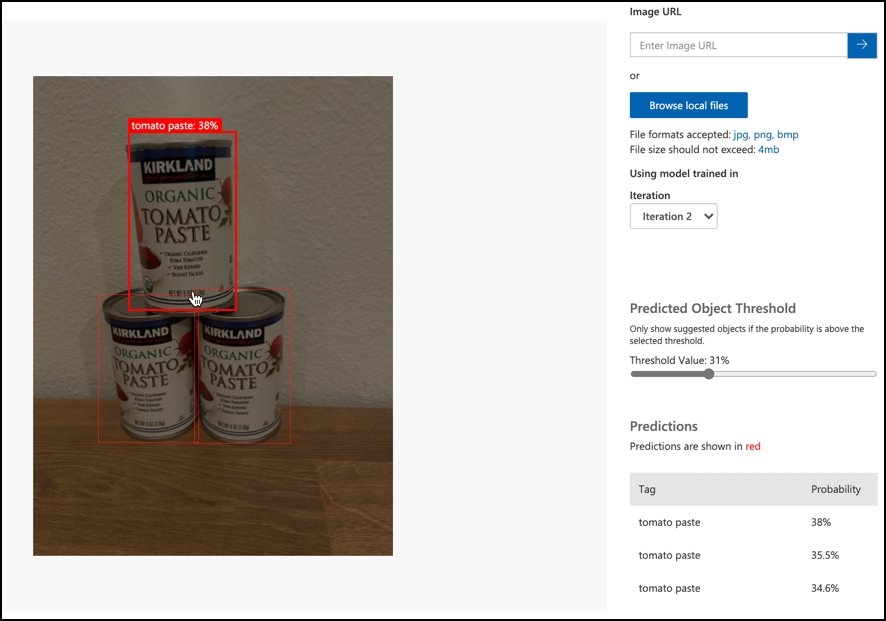
Verwenden Sie die Schaltfläche Schneller Test, um Testbilder hochzuladen und zu überprüfen, ob die Objekte erkannt werden. Verwenden Sie die Testbilder, die Sie zuvor erstellt haben, nicht die Bilder, die Sie zum Trainieren verwendet haben.
-
Testen Sie alle Testbilder, die Ihnen zur Verfügung stehen, und beobachten Sie die Wahrscheinlichkeiten.
Den Objekterkenner erneut trainieren
Wenn Sie Ihren Objekterkenner testen, liefert er möglicherweise nicht die erwarteten Ergebnisse, ähnlich wie bei Bildklassifikatoren im vorherigen Projekt. Sie können Ihren Objekterkenner verbessern, indem Sie ihn mit Bildern erneut trainieren, bei denen er Fehler macht.
Jedes Mal, wenn Sie eine Vorhersage mit der Option "Schneller Test" machen, werden das Bild und die Ergebnisse gespeichert. Sie können diese Bilder verwenden, um Ihr Modell erneut zu trainieren.
-
Verwenden Sie die Registerkarte Vorhersagen, um die Bilder zu finden, die Sie für Tests verwendet haben.
-
Bestätigen Sie alle genauen Erkennungen, löschen Sie falsche und fügen Sie fehlende Objekte hinzu.
-
Trainieren und testen Sie das Modell erneut.
🚀 Herausforderung
Was würde passieren, wenn Sie den Objekterkenner mit ähnlich aussehenden Artikeln verwenden, wie z. B. Dosen derselben Marke mit Tomatenmark und gehackten Tomaten?
Wenn Sie ähnliche Artikel haben, testen Sie es aus, indem Sie Bilder davon zu Ihrem Objekterkenner hinzufügen.
Quiz nach der Vorlesung
Überprüfung & Selbststudium
- Beim Training deines Objekterkennungsmodells hast du Werte für Precision, Recall und mAP gesehen, die die Qualität des erstellten Modells bewerten. Lies nach, was diese Werte bedeuten, indem du den Abschnitt "Evaluate the detector" im Schnellstart zur Erstellung eines Objekterkennungsmodells in der Microsoft-Dokumentation durchgehst.
- Erfahre mehr über Objekterkennung auf der Wikipedia-Seite zur Objekterkennung.
Aufgabe
Haftungsausschluss:
Dieses Dokument wurde mit dem KI-Übersetzungsdienst Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, beachten Sie bitte, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die sich aus der Nutzung dieser Übersetzung ergeben.