25 KiB
Trainiere einen Obstqualitätsdetektor
Sketchnote von Nitya Narasimhan. Klicken Sie auf das Bild für eine größere Version.
Dieses Video gibt einen Überblick über den Azure Custom Vision-Dienst, der in dieser Lektion behandelt wird.

🎥 Klicken Sie auf das obige Bild, um das Video anzusehen.
Quiz vor der Lektion
Einführung
Der jüngste Aufschwung in Künstlicher Intelligenz (KI) und Maschinellem Lernen (ML) bietet heutigen Entwicklern eine Vielzahl von Möglichkeiten. ML-Modelle können trainiert werden, um verschiedene Dinge in Bildern zu erkennen, einschließlich unreifer Früchte. Dies kann in IoT-Geräten genutzt werden, um Produkte entweder während der Ernte oder bei der Verarbeitung in Fabriken oder Lagern zu sortieren.
In dieser Lektion lernen Sie die Bildklassifikation kennen – die Verwendung von ML-Modellen, um zwischen Bildern verschiedener Objekte zu unterscheiden. Sie lernen, wie Sie einen Bildklassifikator trainieren, um zwischen guten und schlechten Früchten zu unterscheiden, sei es unreif, überreif, beschädigt oder verdorben.
In dieser Lektion behandeln wir:
- Verwendung von KI und ML zur Lebensmittelsortierung
- Bildklassifikation durch Maschinelles Lernen
- Einen Bildklassifikator trainieren
- Ihren Bildklassifikator testen
- Ihren Bildklassifikator neu trainieren
Verwendung von KI und ML zur Lebensmittelsortierung
Die weltweite Bevölkerung zu ernähren ist eine Herausforderung, insbesondere zu einem Preis, der für alle erschwinglich ist. Einer der größten Kostenfaktoren ist die Arbeitskraft, weshalb Landwirte zunehmend auf Automatisierung und Werkzeuge wie IoT setzen, um ihre Arbeitskosten zu senken. Die manuelle Ernte ist arbeitsintensiv (und oft körperlich anstrengend) und wird zunehmend durch Maschinen ersetzt, insbesondere in wohlhabenderen Ländern. Trotz der Kosteneinsparungen durch den Einsatz von Maschinen bei der Ernte gibt es einen Nachteil – die Fähigkeit, Lebensmittel während der Ernte zu sortieren.
Nicht alle Ernten reifen gleichmäßig. Tomaten beispielsweise können noch grüne Früchte an der Pflanze haben, wenn der Großteil reif ist. Obwohl es Verschwendung ist, diese früh zu ernten, ist es für den Landwirt günstiger und einfacher, alles mit Maschinen zu ernten und die unreifen Produkte später zu entsorgen.
✅ Schauen Sie sich verschiedene Früchte oder Gemüse an, die entweder in Ihrer Nähe auf Feldern oder in Ihrem Garten wachsen oder in Geschäften erhältlich sind. Sind sie alle gleich reif, oder sehen Sie Unterschiede?
Der Aufstieg der automatisierten Ernte hat die Sortierung der Produkte von der Ernte in die Fabrik verlagert. Lebensmittel wurden auf langen Förderbändern transportiert, wobei Teams von Menschen die Produkte durchsuchten und alles entfernten, was nicht den Qualitätsstandards entsprach. Die Ernte wurde durch Maschinen günstiger, aber es gab immer noch Kosten für die manuelle Sortierung der Lebensmittel.
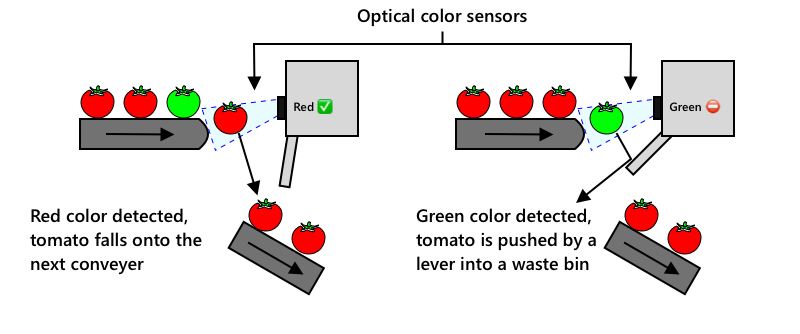
Die nächste Entwicklung war der Einsatz von Maschinen zur Sortierung, entweder in die Erntemaschinen integriert oder in den Verarbeitungsanlagen. Die erste Generation dieser Maschinen verwendete optische Sensoren, um Farben zu erkennen, und steuerte Aktuatoren, um grüne Tomaten mit Hebeln oder Luftstößen in einen Abfallbehälter zu befördern, während rote Tomaten auf einem Netzwerk von Förderbändern weitergeleitet wurden.
In diesem Video werden grüne Tomaten erkannt und mit Hebeln in einen Behälter geschleudert, während sie von einem Förderband auf ein anderes fallen.
✅ Welche Bedingungen wären in einer Fabrik oder auf einem Feld erforderlich, damit diese optischen Sensoren korrekt funktionieren?
Die neuesten Entwicklungen dieser Sortiermaschinen nutzen KI und ML, indem sie Modelle verwenden, die darauf trainiert sind, gutes von schlechtem Obst zu unterscheiden – nicht nur durch offensichtliche Farbunterschiede wie grüne Tomaten vs. rote, sondern auch durch subtilere Unterschiede im Aussehen, die auf Krankheiten oder Quetschungen hinweisen können.
Bildklassifikation durch Maschinelles Lernen
Traditionelle Programmierung bedeutet, dass Sie Daten nehmen, einen Algorithmus darauf anwenden und ein Ergebnis erhalten. Im letzten Projekt haben Sie beispielsweise GPS-Koordinaten und einen Geofence verwendet, einen von Azure Maps bereitgestellten Algorithmus angewendet und ein Ergebnis erhalten, ob der Punkt innerhalb oder außerhalb des Geofence liegt. Sie geben mehr Daten ein, und Sie erhalten mehr Ergebnisse.
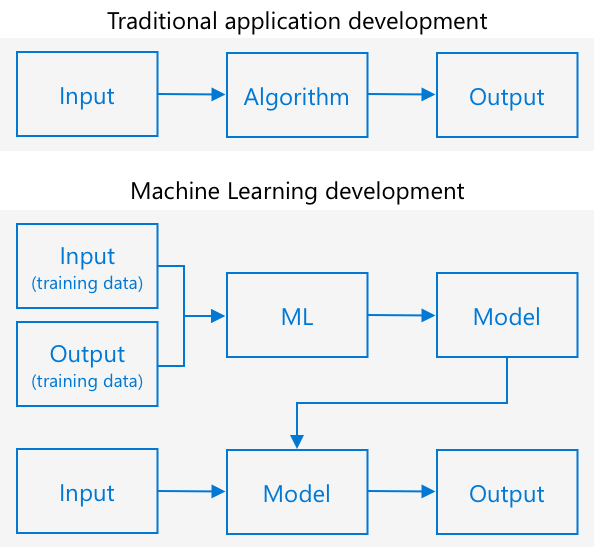
Maschinelles Lernen dreht diesen Prozess um – Sie beginnen mit Daten und bekannten Ergebnissen, und der maschinelle Lernalgorithmus lernt aus den Daten. Sie können dann diesen trainierten Algorithmus, ein sogenanntes Maschinelles Lernmodell oder Modell, verwenden, um neue Daten einzugeben und neue Ergebnisse zu erhalten.
🎓 Der Prozess, bei dem ein maschineller Lernalgorithmus aus den Daten lernt, wird als Training bezeichnet. Die Eingaben und bekannten Ergebnisse werden als Trainingsdaten bezeichnet.
Beispielsweise könnten Sie einem Modell Millionen von Bildern unreifer Bananen als Eingabetrainingsdaten geben, wobei die Trainingsergebnisse auf unreif gesetzt sind, und Millionen von Bildern reifer Bananen mit den Trainingsergebnissen reif. Der ML-Algorithmus erstellt dann ein Modell basierend auf diesen Daten. Sie geben diesem Modell ein neues Bild einer Banane, und es wird vorhersagen, ob das neue Bild eine reife oder unreife Banane zeigt.
🎓 Die Ergebnisse von ML-Modellen werden als Vorhersagen bezeichnet.

ML-Modelle geben keine binären Antworten, sondern Wahrscheinlichkeiten. Beispielsweise könnte ein Modell ein Bild einer Banane erhalten und reif mit 99,7% und unreif mit 0,3% vorhersagen. Ihr Code würde dann die beste Vorhersage auswählen und entscheiden, dass die Banane reif ist.
Das ML-Modell, das verwendet wird, um Bilder wie diese zu erkennen, wird als Bildklassifikator bezeichnet – es erhält beschriftete Bilder und klassifiziert neue Bilder basierend auf diesen Beschriftungen.
💁 Dies ist eine Vereinfachung, und es gibt viele andere Möglichkeiten, Modelle zu trainieren, die nicht immer beschriftete Ergebnisse benötigen, wie z. B. unüberwachtes Lernen. Wenn Sie mehr über ML erfahren möchten, schauen Sie sich ML für Anfänger, ein 24-Lektionen-Curriculum über Maschinelles Lernen an.
Einen Bildklassifikator trainieren
Um einen Bildklassifikator erfolgreich zu trainieren, benötigen Sie Millionen von Bildern. Es stellt sich jedoch heraus, dass Sie, sobald Sie einen Bildklassifikator haben, der auf Millionen oder Milliarden verschiedener Bilder trainiert wurde, diesen wiederverwenden und mit einer kleinen Menge an Bildern neu trainieren können, um großartige Ergebnisse zu erzielen – ein Prozess, der als Transferlernen bezeichnet wird.
🎓 Transferlernen bedeutet, dass Sie das Gelernte aus einem bestehenden ML-Modell auf ein neues Modell basierend auf neuen Daten übertragen.
Sobald ein Bildklassifikator für eine Vielzahl von Bildern trainiert wurde, ist er intern hervorragend darin, Formen, Farben und Muster zu erkennen. Transferlernen ermöglicht es dem Modell, das, was es bereits über die Erkennung von Bildteilen gelernt hat, zu nutzen, um neue Bilder zu erkennen.
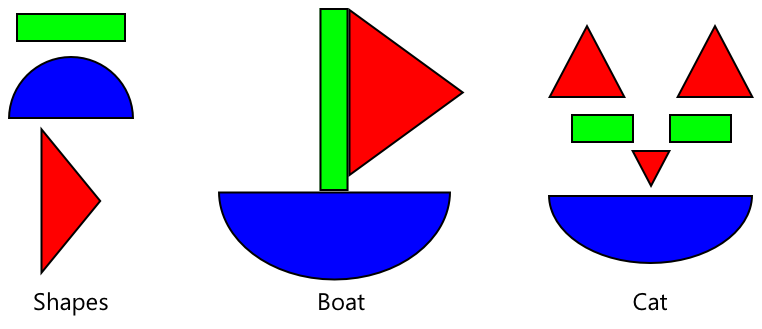
Das können Sie sich wie Kinderbücher über Formen vorstellen, bei denen Sie, sobald Sie einen Halbkreis, ein Rechteck und ein Dreieck erkennen können, ein Segelboot oder eine Katze je nach Konfiguration dieser Formen erkennen können. Der Bildklassifikator kann die Formen erkennen, und das Transferlernen lehrt ihn, welche Kombination ein Boot oder eine Katze – oder eine reife Banane – ergibt.
Es gibt eine Vielzahl von Tools, die Ihnen dabei helfen können, darunter cloudbasierte Dienste, die Ihnen helfen, Ihr Modell zu trainieren und es dann über Web-APIs zu nutzen.
💁 Das Training dieser Modelle erfordert viel Rechenleistung, normalerweise über Grafikprozessoren (GPUs). Dieselbe spezialisierte Hardware, die Spiele auf Ihrer Xbox großartig aussehen lässt, kann auch verwendet werden, um maschinelle Lernmodelle zu trainieren. Durch die Nutzung der Cloud können Sie Zeit auf leistungsstarken Computern mit GPUs mieten, um diese Modelle zu trainieren, und so die benötigte Rechenleistung nur für die Zeit nutzen, die Sie benötigen.
Custom Vision
Custom Vision ist ein cloudbasiertes Tool zum Trainieren von Bildklassifikatoren. Es ermöglicht Ihnen, einen Klassifikator mit nur einer kleinen Anzahl von Bildern zu trainieren. Sie können Bilder über ein Webportal, eine Web-API oder ein SDK hochladen und jedem Bild ein Tag zuweisen, das die Klassifikation dieses Bildes angibt. Anschließend trainieren Sie das Modell und testen es, um zu sehen, wie gut es funktioniert. Sobald Sie mit dem Modell zufrieden sind, können Sie Versionen davon veröffentlichen, die über eine Web-API oder ein SDK zugänglich sind.
![]()
💁 Sie können ein Custom Vision-Modell mit nur 5 Bildern pro Klassifikation trainieren, aber mehr ist besser. Mit mindestens 30 Bildern erzielen Sie bessere Ergebnisse.
Custom Vision ist Teil einer Reihe von KI-Tools von Microsoft, die als Cognitive Services bezeichnet werden. Diese KI-Tools können entweder ohne Training oder mit einer kleinen Menge an Training verwendet werden. Sie umfassen Spracherkennung und -übersetzung, Sprachverständnis und Bildanalyse. Diese Dienste sind mit einer kostenlosen Stufe in Azure verfügbar.
💁 Die kostenlose Stufe reicht aus, um ein Modell zu erstellen, es zu trainieren und es dann für Entwicklungsarbeiten zu verwenden. Sie können die Grenzen der kostenlosen Stufe auf der Seite zu Custom Vision-Limits und -Quoten in der Microsoft-Dokumentation nachlesen.
Aufgabe – Erstellen einer Cognitive Services-Ressource
Um Custom Vision zu verwenden, müssen Sie zunächst zwei Cognitive Services-Ressourcen in Azure mit der Azure CLI erstellen, eine für das Custom Vision-Training und eine für die Custom Vision-Vorhersage.
-
Erstellen Sie eine Ressourcengruppe für dieses Projekt mit dem Namen
fruit-quality-detector. -
Verwenden Sie den folgenden Befehl, um eine kostenlose Custom Vision-Trainingsressource zu erstellen:
az cognitiveservices account create --name fruit-quality-detector-training \ --resource-group fruit-quality-detector \ --kind CustomVision.Training \ --sku F0 \ --yes \ --location <location>Ersetzen Sie
<location>durch den Standort, den Sie beim Erstellen der Ressourcengruppe verwendet haben.Dadurch wird eine Custom Vision-Trainingsressource in Ihrer Ressourcengruppe erstellt. Sie wird
fruit-quality-detector-trainingheißen und dieF0SKU verwenden, die die kostenlose Stufe ist. Die Option--yesbedeutet, dass Sie den Bedingungen der Cognitive Services zustimmen.
💁 Verwenden Sie die
S0SKU, wenn Sie bereits ein kostenloses Konto mit einem der Cognitive Services nutzen.
-
Verwenden Sie den folgenden Befehl, um eine kostenlose Custom Vision-Vorhersageressource zu erstellen:
az cognitiveservices account create --name fruit-quality-detector-prediction \ --resource-group fruit-quality-detector \ --kind CustomVision.Prediction \ --sku F0 \ --yes \ --location <location>Ersetzen Sie
<location>durch den Standort, den Sie beim Erstellen der Ressourcengruppe verwendet haben.Dadurch wird eine Custom Vision-Vorhersageressource in Ihrer Ressourcengruppe erstellt. Sie wird
fruit-quality-detector-predictionheißen und dieF0SKU verwenden, die die kostenlose Stufe ist. Die Option--yesbedeutet, dass Sie den Bedingungen der Cognitive Services zustimmen.
Aufgabe – Erstellen eines Bildklassifikatorprojekts
-
Starten Sie das Custom Vision-Portal unter CustomVision.ai und melden Sie sich mit dem Microsoft-Konto an, das Sie für Ihr Azure-Konto verwendet haben.
-
Folgen Sie dem Abschnitt Erstellen eines neuen Projekts im Quickstart zur Erstellung eines Klassifikators in der Microsoft-Dokumentation, um ein neues Custom Vision-Projekt zu erstellen. Die Benutzeroberfläche kann sich ändern, und diese Dokumentation ist immer die aktuellste Referenz.
Nennen Sie Ihr Projekt
fruit-quality-detector.Stellen Sie beim Erstellen Ihres Projekts sicher, dass Sie die zuvor erstellte Ressource
fruit-quality-detector-trainingverwenden. Verwenden Sie den Projekttyp Klassifikation, den Klassifikationstyp Multiklassen und die Domäne Lebensmittel.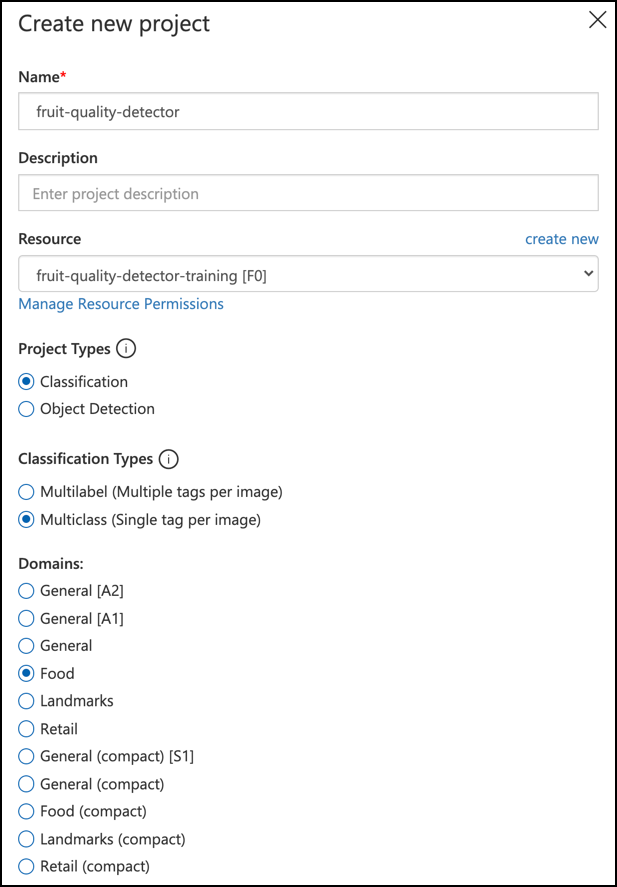
✅ Nehmen Sie sich etwas Zeit, um die Benutzeroberfläche von Custom Vision für Ihren Bildklassifikator zu erkunden.
Aufgabe – Trainieren Ihres Bildklassifikatorprojekts
Um einen Bildklassifikator zu trainieren, benötigen Sie mehrere Bilder von Obst, sowohl in guter als auch in schlechter Qualität, die Sie als gut und schlecht markieren können, wie z. B. eine reife und eine überreife Banane. 💁 Diese Klassifikatoren können Bilder von allem klassifizieren. Wenn du also keine Früchte unterschiedlicher Qualität zur Hand hast, kannst du stattdessen zwei verschiedene Obstsorten oder Katzen und Hunde verwenden! Idealerweise sollte jedes Bild nur die Frucht zeigen, entweder mit einem einheitlichen Hintergrund oder einer großen Vielfalt an Hintergründen. Achten Sie darauf, dass im Hintergrund nichts zu sehen ist, was spezifisch für reife oder unreife Früchte ist.
💁 Es ist wichtig, keine spezifischen Hintergründe oder Gegenstände zu haben, die nicht mit dem zu klassifizierenden Objekt zusammenhängen. Andernfalls könnte der Klassifikator nur auf Basis des Hintergrunds klassifizieren. Es gab einmal einen Klassifikator für Hautkrebs, der auf Muttermale trainiert wurde, sowohl normale als auch krebsartige. Die krebsartigen Muttermale hatten alle Lineale daneben, um die Größe zu messen. Es stellte sich heraus, dass der Klassifikator fast 100 % genau war, wenn es darum ging, Lineale in Bildern zu erkennen, nicht aber krebsartige Muttermale.
Bildklassifikatoren arbeiten mit sehr niedriger Auflösung. Zum Beispiel kann Custom Vision Trainings- und Vorhersagebilder bis zu 10240x10240 verarbeiten, trainiert und führt das Modell jedoch mit Bildern in 227x227 aus. Größere Bilder werden auf diese Größe verkleinert, daher sollte das zu klassifizierende Objekt einen großen Teil des Bildes einnehmen, da es sonst in der kleineren Bildgröße, die der Klassifikator verwendet, zu klein sein könnte.
-
Sammeln Sie Bilder für Ihren Klassifikator. Sie benötigen mindestens 5 Bilder für jedes Label, um den Klassifikator zu trainieren, aber je mehr, desto besser. Sie benötigen auch einige zusätzliche Bilder, um den Klassifikator zu testen. Diese Bilder sollten alle unterschiedliche Aufnahmen desselben Objekts sein. Zum Beispiel:
-
Verwenden Sie 2 reife Bananen und machen Sie einige Bilder von jeder aus verschiedenen Blickwinkeln. Machen Sie mindestens 7 Bilder (5 zum Trainieren, 2 zum Testen), idealerweise mehr.

-
Wiederholen Sie denselben Vorgang mit 2 unreifen Bananen.
Sie sollten mindestens 10 Trainingsbilder haben, mit mindestens 5 reifen und 5 unreifen, sowie 4 Testbilder, 2 reife und 2 unreife. Ihre Bilder sollten im PNG- oder JPEG-Format vorliegen und kleiner als 6 MB sein. Wenn Sie sie beispielsweise mit einem iPhone erstellen, könnten es hochauflösende HEIC-Bilder sein, die konvertiert und möglicherweise verkleinert werden müssen. Je mehr Bilder, desto besser, und Sie sollten eine ähnliche Anzahl von reifen und unreifen Bildern haben.
Wenn Sie keine reifen und unreifen Früchte haben, können Sie verschiedene Früchte oder beliebige zwei Objekte verwenden, die Sie zur Verfügung haben. Sie können auch einige Beispielbilder im images-Ordner von reifen und unreifen Bananen finden, die Sie verwenden können.
-
-
Folgen Sie dem Abschnitt Bilder hochladen und taggen im Quickstart zum Erstellen eines Klassifikators in der Microsoft-Dokumentation, um Ihre Trainingsbilder hochzuladen. Taggen Sie die reifen Früchte als
ripeund die unreifen Früchte alsunripe.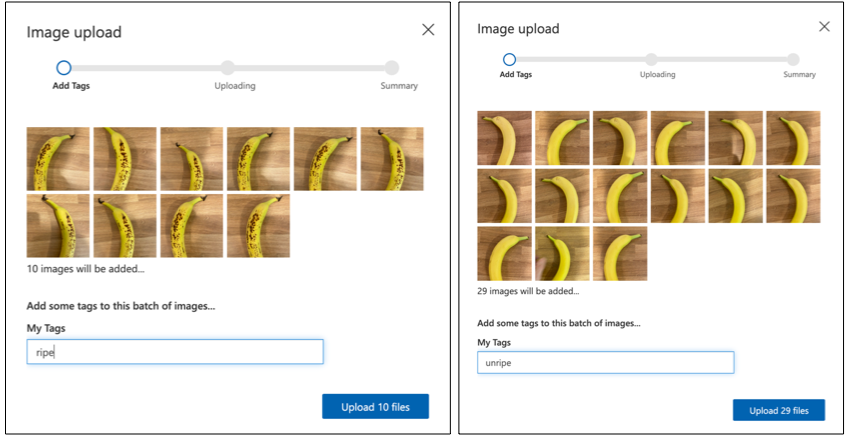
-
Folgen Sie dem Abschnitt Klassifikator trainieren im Quickstart zum Erstellen eines Klassifikators in der Microsoft-Dokumentation, um den Bildklassifikator mit Ihren hochgeladenen Bildern zu trainieren.
Sie haben die Wahl zwischen verschiedenen Trainingsarten. Wählen Sie Schnelles Training.
Der Klassifikator wird dann trainiert. Es dauert ein paar Minuten, bis das Training abgeschlossen ist.
🍌 Wenn Sie sich entscheiden, Ihre Früchte zu essen, während der Klassifikator trainiert, stellen Sie sicher, dass Sie vorher genügend Bilder zum Testen haben!
Testen Sie Ihren Bildklassifikator
Sobald Ihr Klassifikator trainiert ist, können Sie ihn testen, indem Sie ihm ein neues Bild zur Klassifikation geben.
Aufgabe - Testen Sie Ihren Bildklassifikator
-
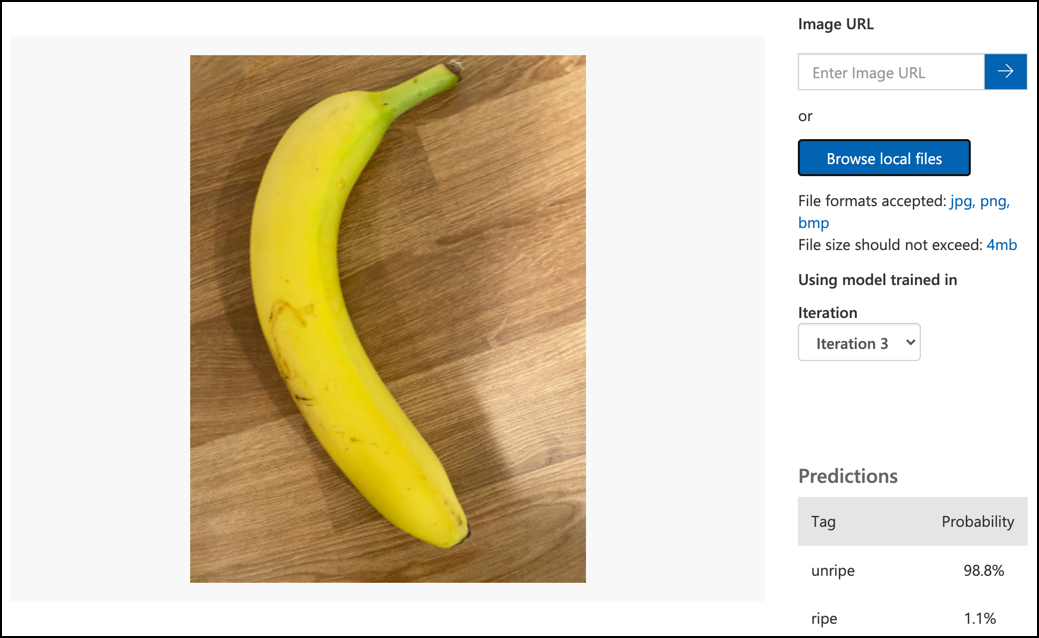
Folgen Sie der Dokumentation zum Testen Ihres Modells in der Microsoft-Dokumentation, um Ihren Bildklassifikator zu testen. Verwenden Sie die Testbilder, die Sie zuvor erstellt haben, und nicht die Bilder, die Sie für das Training verwendet haben.
-
Testen Sie alle Testbilder, die Ihnen zur Verfügung stehen, und beobachten Sie die Wahrscheinlichkeiten.
Trainieren Sie Ihren Bildklassifikator erneut
Wenn Sie Ihren Klassifikator testen, liefert er möglicherweise nicht die erwarteten Ergebnisse. Bildklassifikatoren verwenden maschinelles Lernen, um Vorhersagen darüber zu treffen, was auf einem Bild zu sehen ist, basierend auf Wahrscheinlichkeiten, dass bestimmte Merkmale eines Bildes zu einem bestimmten Label passen. Er versteht nicht, was auf dem Bild ist – er weiß nicht, was eine Banane ist oder was eine Banane von einem Boot unterscheidet. Sie können Ihren Klassifikator verbessern, indem Sie ihn mit Bildern, bei denen er Fehler macht, erneut trainieren.
Jedes Mal, wenn Sie eine Vorhersage mit der Schnelltest-Option machen, werden das Bild und die Ergebnisse gespeichert. Sie können diese Bilder verwenden, um Ihr Modell erneut zu trainieren.
Aufgabe - Trainieren Sie Ihren Bildklassifikator erneut
-
Folgen Sie der Dokumentation zur Verwendung vorhergesagter Bilder für das Training in der Microsoft-Dokumentation, um Ihr Modell erneut zu trainieren, indem Sie das richtige Tag für jedes Bild verwenden.
-
Testen Sie Ihr Modell nach dem erneuten Training mit neuen Bildern.
🚀 Herausforderung
Was glauben Sie, würde passieren, wenn Sie ein Bild einer Erdbeere mit einem Modell testen, das auf Bananen trainiert wurde, oder ein Bild einer aufblasbaren Banane, einer Person im Bananenkostüm oder sogar einer gelben Cartoonfigur wie jemandem aus den Simpsons?
Probieren Sie es aus und sehen Sie, welche Vorhersagen gemacht werden. Sie können Bilder zum Testen mit der Bing-Bildersuche finden.
Quiz nach der Vorlesung
Rückblick & Selbststudium
- Beim Training Ihres Klassifikators haben Sie Werte für Precision, Recall und AP gesehen, die das erstellte Modell bewerten. Lesen Sie nach, was diese Werte bedeuten, im Abschnitt Klassifikator bewerten im Quickstart zum Erstellen eines Klassifikators in der Microsoft-Dokumentation.
- Lesen Sie nach, wie Sie Ihren Klassifikator verbessern können, in der Anleitung zur Verbesserung Ihres Custom Vision-Modells in der Microsoft-Dokumentation.
Aufgabe
Trainieren Sie Ihren Klassifikator für mehrere Früchte und Gemüse
Haftungsausschluss:
Dieses Dokument wurde mit dem KI-Übersetzungsdienst Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, beachten Sie bitte, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die sich aus der Nutzung dieser Übersetzung ergeben.