33 KiB
Разпознаване на реч с IoT устройство
Скица от Nitya Narasimhan. Кликнете върху изображението за по-голяма версия.
Това видео предоставя преглед на услугата за разпознаване на реч в Azure, тема, която ще бъде разгледана в този урок:

🎥 Кликнете върху изображението по-горе, за да гледате видеото
Тест преди лекцията
Въведение
'Алекса, настрой таймер за 12 минути'
'Алекса, какво е състоянието на таймера?'
'Алекса, настрой таймер за 8 минути, наречен "задушаване на броколи"'
Умните устройства стават все по-разпространени. Не само като умни високоговорители като HomePods, Echos и Google Homes, но и вградени в нашите телефони, часовници, дори осветителни тела и термостати.
💁 В дома си имам поне 19 устройства с гласови асистенти, и това са само тези, за които знам!
Гласовото управление увеличава достъпността, като позволява на хора с ограничена подвижност да взаимодействат с устройства. Независимо дали става въпрос за постоянна инвалидност, като липса на ръце, временна травма като счупена ръка, или просто когато ръцете ви са заети с пазаруване или малки деца, възможността да контролираме дома си с глас вместо с ръце отваря нови възможности. Да извикате "Хей, Сири, затвори гаражната врата", докато се справяте с бебе и палаво дете, може да бъде малко, но значително улеснение в живота.
Една от най-популярните употреби на гласовите асистенти е настройването на таймери, особено кухненски таймери. Възможността да настроите няколко таймера само с гласа си е голяма помощ в кухнята – няма нужда да спирате месенето на тесто, разбъркването на супа или да чистите ръцете си, за да използвате физически таймер.
В този урок ще научите как да вградите разпознаване на глас в IoT устройства. Ще научите за микрофоните като сензори, как да записвате аудио от микрофон, свързан към IoT устройство, и как да използвате изкуствен интелект, за да преобразувате чутото в текст. В рамките на този проект ще изградите умен кухненски таймер, който може да настройва таймери с вашия глас на няколко езика.
В този урок ще разгледаме:
Микрофони
Микрофоните са аналогови сензори, които преобразуват звуковите вълни в електрически сигнали. Вибрациите във въздуха карат компонентите в микрофона да се движат с минимални количества, което води до малки промени в електрическите сигнали. Тези промени след това се усилват, за да се генерира електрически изход.
Видове микрофони
Микрофоните се предлагат в различни видове:
-
Динамични - Динамичните микрофони имат магнит, прикрепен към движеща се диафрагма, която се движи в намотка от проводник, създавайки електрически ток. Това е обратното на повечето високоговорители, които използват електрически ток, за да движат магнит в намотка, движейки диафрагма, за да създадат звук. Това означава, че високоговорителите могат да се използват като динамични микрофони, а динамичните микрофони могат да се използват като високоговорители. В устройства като домофони, където потребителят или слуша, или говори, но не и двете едновременно, едно устройство може да действа както като високоговорител, така и като микрофон.
Динамичните микрофони не се нуждаят от захранване, за да работят – електрическият сигнал се създава изцяло от микрофона.

-
Лентови - Лентовите микрофони са подобни на динамичните, но вместо диафрагма имат метална лента. Тази лента се движи в магнитно поле, генерирайки електрически ток. Както и динамичните микрофони, лентовите не се нуждаят от захранване.

-
Кондензаторни - Кондензаторните микрофони имат тънка метална диафрагма и фиксирана метална задна плоча. Електричество се прилага към двете, и когато диафрагмата вибрира, статичният заряд между плочите се променя, генерирайки сигнал. Кондензаторните микрофони се нуждаят от захранване, наречено Phantom power.
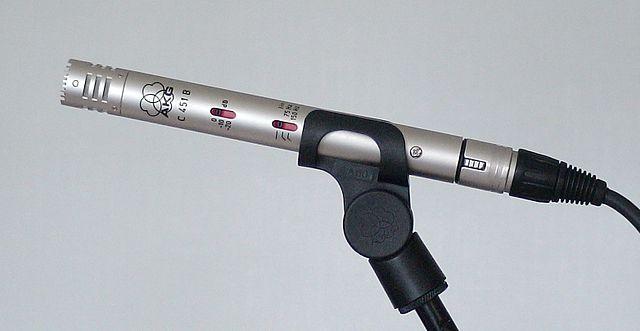
-
MEMS - Микроелектромеханичните системи микрофони, или MEMS, са микрофони на чип. Те имат чувствителна на налягане диафрагма, гравирана върху силициев чип, и работят подобно на кондензаторен микрофон. Тези микрофони могат да бъдат изключително малки и интегрирани в електронни схеми.

На изображението по-горе, чипът с надпис LEFT е MEMS микрофон с миниатюрна диафрагма, по-малка от милиметър.
✅ Направете проучване: Какви микрофони имате около вас – в компютъра, телефона, слушалките или други устройства? Какъв тип микрофони са те?
Дигитално аудио
Аудиото е аналогов сигнал, който носи много фини детайли. За да се преобразува този сигнал в дигитален, аудиото трябва да бъде семплирано хиляди пъти в секунда.
🎓 Семплирането е процесът на преобразуване на аудио сигнала в дигитална стойност, която представлява сигнала в даден момент.
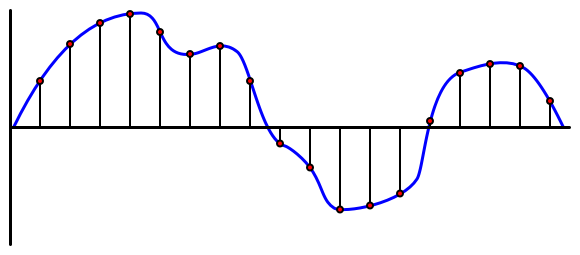
Дигиталното аудио се семплира чрез импулсно-кодова модулация (Pulse Code Modulation, PCM). PCM включва измерване на напрежението на сигнала и избор на най-близката дискретна стойност към това напрежение, използвайки определен размер.
💁 Можете да мислите за PCM като сензорната версия на импулсно-широчинната модулация (PWM). PCM преобразува аналогов сигнал в дигитален, докато PWM преобразува дигитален сигнал в аналогов.
Например, повечето стрийминг услуги за музика предлагат 16-битово или 24-битово аудио. Това означава, че те преобразуват напрежението в стойност, която се побира в 16-битово или 24-битово цяло число. 16-битовото аудио използва стойности в диапазона от -32,768 до 32,767, а 24-битовото – от −8,388,608 до 8,388,607. Колкото повече битове, толкова по-близо е семпълът до това, което чуват ушите ни.
💁 Може би сте чували за 8-битово аудио, често наричано LoFi. Това е аудио, семплирано само с 8 бита, в диапазона от -128 до 127. Първото компютърно аудио е било ограничено до 8 бита поради хардуерни ограничения, затова често се свързва с ретро игрите.
Тези семпли се вземат хиляди пъти в секунда, използвайки добре дефинирани честоти на семплиране, измервани в KHz (хиляди измервания в секунда). Стрийминг услугите за музика използват 48KHz за повечето аудио, но някои "без загуби" аудио формати използват до 96KHz или дори 192KHz. Колкото по-висока е честотата на семплиране, толкова по-близо е аудиото до оригинала, до определена степен. Има дебат дали хората могат да различат разликата над 48KHz.
✅ Направете проучване: Ако използвате стрийминг услуга за музика, каква честота и размер на семплирането използва тя? Ако използвате CD-та, каква е честотата и размерът на семплирането на CD аудиото?
Съществуват различни формати за аудио данни. Вероятно сте чували за mp3 файлове – аудио данни, които са компресирани, за да бъдат по-малки, без загуба на качество. Некомпресираното аудио често се съхранява като WAV файл – това е файл с 44 байта заглавна информация, последвана от сурови аудио данни. Заглавието съдържа информация като честота на семплиране (например 16000 за 16KHz), размер на семплирането (16 за 16-битово) и броя на каналите. След заглавието WAV файлът съдържа суровите аудио данни.
🎓 Каналите се отнасят до броя на различните аудио потоци, които съставят аудиото. Например, за стерео аудио с ляв и десен канал ще има 2 канала. За 7.1 съраунд звук за домашна кино система това ще бъдат 8 канала.
Размер на аудио данните
Аудио данните са сравнително големи. Например, записването на некомпресирано 16-битово аудио при 16KHz (достатъчно добра честота за модели за преобразуване на реч в текст) изисква 32KB данни за всяка секунда аудио:
- 16-битово означава 2 байта на семпъл (1 байт е 8 бита).
- 16KHz е 16,000 семпъла в секунда.
- 16,000 x 2 байта = 32,000 байта в секунда.
Това може да изглежда като малко количество данни, но ако използвате микроконтролер с ограничена памет, това може да бъде значително. Например, Wio Terminal има 192KB памет, която трябва да съхранява програмния код и променливите. Дори ако програмният код е минимален, не можете да запишете повече от 5 секунди аудио.
Микроконтролерите могат да използват допълнителна памет, като SD карти или флаш памет. Когато изграждате IoT устройство, което записва аудио, трябва да се уверите, че разполагате с допълнителна памет и че кодът ви записва аудиото директно в тази памет. Когато изпращате данните към облака, трябва да стриймвате от паметта към уеб заявката, за да избегнете изчерпване на паметта, като се опитвате да задържите целия блок аудио данни наведнъж.
Запис на аудио от вашето IoT устройство
Вашето IoT устройство може да бъде свързано към микрофон за запис на аудио, готово за преобразуване в текст. То може също да бъде свързано към високоговорители за възпроизвеждане на аудио. В по-късните уроци това ще се използва за предоставяне на аудио обратна връзка, но е полезно да настроите високоговорителите сега, за да тествате микрофона.
Задача - конфигурирайте микрофона и високоговорителите
Следвайте съответното ръководство, за да конфигурирате микрофона и високоговорителите за вашето IoT устройство:
- Arduino - Wio Terminal
- Едноплатков компютър - Raspberry Pi
- Едноплатков компютър - Виртуално устройство
Задача - запис на аудио
Следвайте съответното ръководство, за да запишете аудио на вашето IoT устройство:
- Arduino - Wio Terminal
- Едноплатков компютър - Raspberry Pi
- Едноплатков компютър - Виртуално устройство
Реч към текст
Преобразуването на реч в текст, или разпознаването на реч, включва използването на изкуствен интелект за преобразуване на думи от аудио сигнал в текст.
Модели за разпознаване на реч
За да се преобразува реч в текст, семпли от аудио сигнала се групират и подават към модел за машинно обучение, базиран на рекурентна невронна мрежа (RNN). Това е тип модел за машинно обучение, който може да използва предишни данни, за да вземе решение за входящите данни. Например, RNN може да разпознае един блок аудио семпли като звук "Hel", а когато получи друг блок, който смята за звук "lo", може да комбинира това с предишния звук, да установи, че "Hello" е валидна дума, и да избере този резултат.
Моделите за машинно обучение винаги приемат данни с фиксиран размер. Класификаторът на изображения, който създадохте в по-ранен урок, преоразмерява изображенията до фиксиран размер, преди да ги обработи. Същото важи и за моделите за реч – те трябва да обработват аудио блокове с фиксиран размер. Моделите за реч трябва да могат да комбинират резултатите от множество предсказания, за да получат отговор, което им позволява да различават между "Hi" и "Highway" или "flock" и "floccinaucinihilipilification".
Моделите за реч също са достатъчно напреднали, за да разбират контекста и могат да коригират думите, които разпознават, докато обработват повече звуци. Например, ако кажете "Отидох до магазина, за да купя два банана и една ябълка също", ще използвате три думи, които звучат еднакво, но се пишат различно – to, two и too. Моделите за реч могат да разберат контекста и да използват правилния правопис на думата. 💁 Някои услуги за разпознаване на реч позволяват персонализация, за да работят по-добре в шумни среди като фабрики или с думи, специфични за дадена индустрия, като например химически наименования. Тези персонализации се обучават чрез предоставяне на примерни аудиозаписи и транскрипции и работят с помощта на трансферно обучение, по същия начин, по който обучихте класификатор на изображения, използвайки само няколко изображения в предишен урок.
Поверителност
Когато използвате преобразуване на реч в текст в потребителско IoT устройство, поверителността е изключително важна. Тези устройства слушат аудио непрекъснато, така че като потребител не искате всичко, което казвате, да бъде изпратено в облака и преобразувано в текст. Това не само ще използва много интернет трафик, но също така има сериозни последици за поверителността, особено когато някои производители на умни устройства случайно избират аудио за човешка проверка спрямо генерирания текст, за да подобрят модела си.
Искате вашето умно устройство да изпраща аудио към облака за обработка само когато го използвате, а не когато чува аудио във вашия дом, което може да включва лични срещи или интимни взаимодействия. Начинът, по който работят повечето умни устройства, е чрез активираща дума, ключова фраза като "Alexa", "Hey Siri" или "OK Google", която кара устройството да се "събуди" и да слуша какво казвате, докато не открие пауза в речта ви, което показва, че сте приключили да говорите с устройството.
🎓 Откриването на активираща дума се нарича още разпознаване на ключова дума или засичане на ключова дума.
Тези активиращи думи се откриват на самото устройство, а не в облака. Умните устройства имат малки AI модели, които работят на устройството и слушат за активиращата дума, а когато тя бъде открита, започват да стриймват аудиото към облака за разпознаване. Тези модели са много специализирани и слушат само за активиращата дума.
💁 Някои технологични компании добавят повече поверителност към своите устройства и извършват част от преобразуването на реч в текст на самото устройство. Apple обявиха, че като част от своите актуализации за iOS и macOS през 2021 г. ще поддържат преобразуването на реч в текст на устройството и ще могат да обработват много заявки без да използват облака. Това е възможно благодарение на мощните процесори в техните устройства, които могат да изпълняват ML модели.
✅ Какви според вас са последиците за поверителността и етиката от съхраняването на аудиото, изпратено в облака? Трябва ли това аудио да се съхранява и ако да, как? Смятате ли, че използването на записи за правоприлагане е добра размяна за загубата на поверителност?
Откриването на активираща дума обикновено използва техника, известна като TinyML, която преобразува ML модели, за да могат да работят на микроконтролери. Тези модели са малки по размер и консумират много малко енергия за работа.
За да избегнете сложността на обучението и използването на модел за активираща дума, умният таймер, който изграждате в този урок, ще използва бутон за включване на разпознаването на реч.
💁 Ако искате да опитате да създадете модел за откриване на активираща дума, който да работи на Wio Terminal или Raspberry Pi, разгледайте този урок за реагиране на вашия глас от Edge Impulse. Ако искате да използвате компютъра си за това, можете да опитате бързото начало за персонализирана ключова дума в документацията на Microsoft.
Преобразуване на реч в текст
![]()
Точно както при класификацията на изображения в по-ранен проект, съществуват предварително изградени AI услуги, които могат да приемат реч като аудио файл и да я преобразуват в текст. Една такава услуга е Speech Service, част от Cognitive Services, предварително изградени AI услуги, които можете да използвате в своите приложения.
Задача - конфигуриране на AI ресурс за реч
-
Създайте Resource Group за този проект с име
smart-timer. -
Използвайте следната команда, за да създадете безплатен ресурс за реч:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>Заменете
<location>с местоположението, което сте използвали при създаването на Resource Group. -
Ще ви е необходим API ключ, за да получите достъп до ресурса за реч от вашия код. Изпълнете следната команда, за да получите ключа:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableНаправете копие на един от ключовете.
Задача - преобразуване на реч в текст
Работете по съответния наръчник за преобразуване на реч в текст на вашето IoT устройство:
- Arduino - Wio Terminal
- Едноплатков компютър - Raspberry Pi
- Едноплатков компютър - Виртуално устройство
🚀 Предизвикателство
Разпознаването на реч съществува от дълго време и непрекъснато се подобрява. Проучете текущите възможности и сравнете как те са се развили с времето, включително колко точни са машинните транскрипции в сравнение с човешките.
Какво според вас крие бъдещето за разпознаването на реч?
Тест след лекцията
Преглед и самостоятелно обучение
- Прочетете за различните типове микрофони и как работят в статията за разликата между динамични и кондензаторни микрофони на Musician's HQ.
- Прочетете повече за услугата за реч в Cognitive Services в документацията за услугата за реч на Microsoft Docs.
- Прочетете за разпознаването на ключова дума в документацията за разпознаване на ключова дума на Microsoft Docs.
Задание
Отказ от отговорност:
Този документ е преведен с помощта на AI услуга за превод Co-op Translator. Въпреки че се стремим към точност, моля, имайте предвид, че автоматичните преводи може да съдържат грешки или неточности. Оригиналният документ на неговия изходен език трябва да се счита за авторитетен източник. За критична информация се препоръчва професионален превод от човек. Ние не носим отговорност за каквито и да е недоразумения или погрешни интерпретации, произтичащи от използването на този превод.