|
|
5 months ago | |
|---|---|---|
| .. | ||
| README.md | 5 months ago | |
| assignment.md | 5 months ago | |
README.md
Khoa học Dữ liệu trên Đám mây: Phương pháp "Ít mã/Không mã"
 |
|---|
| Khoa học Dữ liệu trên Đám mây: Ít mã - Sketchnote của @nitya |
Mục lục:
- Khoa học Dữ liệu trên Đám mây: Phương pháp "Ít mã/Không mã"
Câu hỏi trước bài giảng
1. Giới thiệu
1.1 Azure Machine Learning là gì?
Nền tảng đám mây Azure bao gồm hơn 200 sản phẩm và dịch vụ đám mây được thiết kế để giúp bạn hiện thực hóa các giải pháp mới. Các nhà khoa học dữ liệu dành rất nhiều nỗ lực để khám phá và xử lý dữ liệu, thử nghiệm các thuật toán huấn luyện mô hình khác nhau để tạo ra các mô hình chính xác. Những công việc này tiêu tốn nhiều thời gian và thường sử dụng không hiệu quả phần cứng tính toán đắt đỏ.
Azure ML là một nền tảng dựa trên đám mây để xây dựng và vận hành các giải pháp học máy trên Azure. Nó bao gồm nhiều tính năng và khả năng giúp các nhà khoa học dữ liệu chuẩn bị dữ liệu, huấn luyện mô hình, xuất bản các dịch vụ dự đoán và giám sát việc sử dụng chúng. Quan trọng nhất, nó giúp tăng hiệu quả bằng cách tự động hóa nhiều công việc tốn thời gian liên quan đến huấn luyện mô hình; và cho phép sử dụng tài nguyên tính toán dựa trên đám mây có khả năng mở rộng hiệu quả, xử lý khối lượng dữ liệu lớn mà chỉ phát sinh chi phí khi thực sự sử dụng.
Azure ML cung cấp tất cả các công cụ mà các nhà phát triển và nhà khoa học dữ liệu cần cho quy trình làm việc học máy của họ. Bao gồm:
- Azure Machine Learning Studio: cổng web trong Azure Machine Learning cho các tùy chọn ít mã và không mã để huấn luyện mô hình, triển khai, tự động hóa, theo dõi và quản lý tài sản. Studio tích hợp với Azure Machine Learning SDK để mang lại trải nghiệm liền mạch.
- Jupyter Notebooks: nhanh chóng tạo mẫu và kiểm tra các mô hình học máy.
- Azure Machine Learning Designer: cho phép kéo-thả các module để xây dựng các thí nghiệm và triển khai pipeline trong môi trường ít mã.
- Giao diện học máy tự động (AutoML): tự động hóa các nhiệm vụ lặp lại trong phát triển mô hình học máy, cho phép xây dựng các mô hình với quy mô lớn, hiệu quả và năng suất cao, đồng thời duy trì chất lượng mô hình.
- Gắn nhãn dữ liệu: công cụ học máy hỗ trợ tự động gắn nhãn dữ liệu.
- Tiện ích mở rộng học máy cho Visual Studio Code: cung cấp môi trường phát triển đầy đủ tính năng để xây dựng và quản lý các dự án học máy.
- CLI học máy: cung cấp các lệnh để quản lý tài nguyên Azure ML từ dòng lệnh.
- Tích hợp với các framework mã nguồn mở như PyTorch, TensorFlow, Scikit-learn và nhiều hơn nữa để huấn luyện, triển khai và quản lý quy trình học máy từ đầu đến cuối.
- MLflow: thư viện mã nguồn mở để quản lý vòng đời của các thí nghiệm học máy. MLFlow Tracking là một thành phần của MLflow ghi lại và theo dõi các chỉ số huấn luyện và các artifact mô hình, bất kể môi trường thí nghiệm của bạn.
1.2 Dự án Dự đoán Suy tim:
Không còn nghi ngờ gì rằng việc thực hiện và xây dựng các dự án là cách tốt nhất để kiểm tra kỹ năng và kiến thức của bạn. Trong bài học này, chúng ta sẽ khám phá hai cách khác nhau để xây dựng một dự án khoa học dữ liệu nhằm dự đoán các cơn suy tim trong Azure ML Studio, thông qua phương pháp Ít mã/Không mã và thông qua Azure ML SDK như được minh họa trong sơ đồ sau:
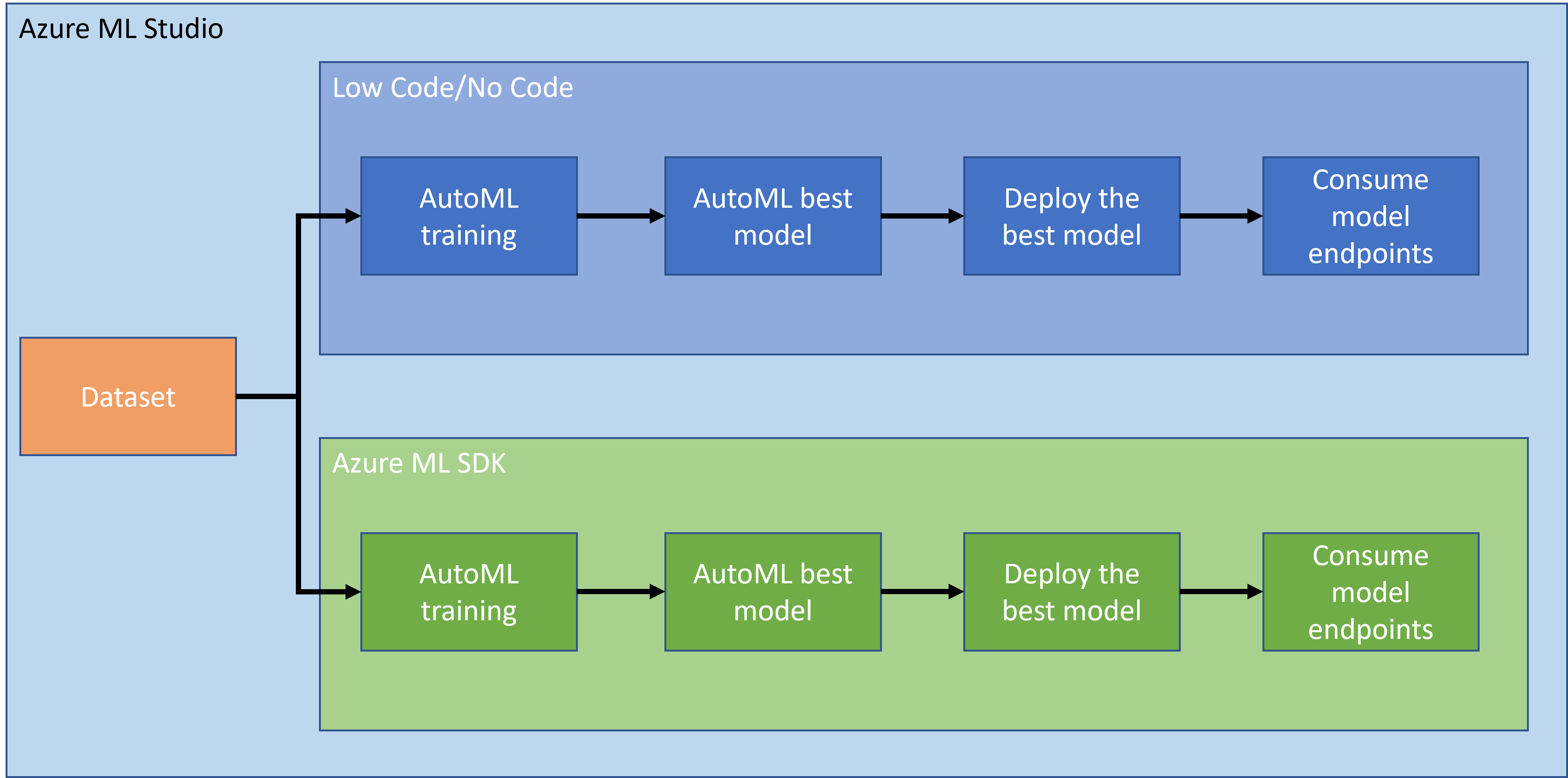
Mỗi cách đều có ưu và nhược điểm riêng. Phương pháp Ít mã/Không mã dễ bắt đầu hơn vì nó liên quan đến việc tương tác với giao diện đồ họa (GUI), không yêu cầu kiến thức lập trình trước. Phương pháp này cho phép kiểm tra nhanh tính khả thi của dự án và tạo POC (Bằng chứng về Khái niệm). Tuy nhiên, khi dự án phát triển và cần sẵn sàng cho sản xuất, việc tạo tài nguyên thông qua GUI không còn khả thi. Chúng ta cần tự động hóa mọi thứ bằng lập trình, từ việc tạo tài nguyên đến triển khai mô hình. Đây là lúc việc biết cách sử dụng Azure ML SDK trở nên quan trọng.
| Ít mã/Không mã | Azure ML SDK | |
|---|---|---|
| Kiến thức lập trình | Không cần thiết | Cần thiết |
| Thời gian phát triển | Nhanh và dễ dàng | Phụ thuộc vào kỹ năng lập trình |
| Sẵn sàng sản xuất | Không | Có |
1.3 Bộ dữ liệu Suy tim:
Các bệnh tim mạch (CVDs) là nguyên nhân gây tử vong hàng đầu trên toàn cầu, chiếm 31% tổng số ca tử vong trên thế giới. Các yếu tố nguy cơ môi trường và hành vi như sử dụng thuốc lá, chế độ ăn uống không lành mạnh và béo phì, ít vận động và sử dụng rượu bia có hại có thể được sử dụng làm đặc trưng cho các mô hình ước tính. Việc có thể ước tính xác suất phát triển CVD có thể rất hữu ích để ngăn ngừa các cơn suy tim ở những người có nguy cơ cao.
Kaggle đã cung cấp một bộ dữ liệu Suy tim công khai mà chúng ta sẽ sử dụng cho dự án này. Bạn có thể tải bộ dữ liệu ngay bây giờ. Đây là một bộ dữ liệu dạng bảng với 13 cột (12 đặc trưng và 1 biến mục tiêu) và 299 hàng.
| Tên biến | Loại dữ liệu | Mô tả | Ví dụ | |
|---|---|---|---|---|
| 1 | age | số | Tuổi của bệnh nhân | 25 |
| 2 | anaemia | boolean | Giảm số lượng hồng cầu hoặc hemoglobin | 0 hoặc 1 |
| 3 | creatinine_phosphokinase | số | Mức độ enzyme CPK trong máu | 542 |
| 4 | diabetes | boolean | Bệnh nhân có bị tiểu đường không | 0 hoặc 1 |
| 5 | ejection_fraction | số | Tỷ lệ phần trăm máu rời khỏi tim trong mỗi lần co bóp | 45 |
| 6 | high_blood_pressure | boolean | Bệnh nhân có bị cao huyết áp không | 0 hoặc 1 |
| 7 | platelets | số | Số lượng tiểu cầu trong máu | 149000 |
| 8 | serum_creatinine | số | Mức độ creatinine huyết thanh trong máu | 0.5 |
| 9 | serum_sodium | số | Mức độ natri huyết thanh trong máu | jun |
| 10 | sex | boolean | Giới tính (nữ hoặc nam) | 0 hoặc 1 |
| 11 | smoking | boolean | Bệnh nhân có hút thuốc không | 0 hoặc 1 |
| 12 | time | số | Thời gian theo dõi (ngày) | 4 |
| ---- | --------------------------- | ------------------ | --------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Mục tiêu] | boolean | Bệnh nhân có tử vong trong thời gian theo dõi không | 0 hoặc 1 |
Khi bạn đã có bộ dữ liệu, chúng ta có thể bắt đầu dự án trong Azure.
2. Huấn luyện mô hình Ít mã/Không mã trong Azure ML Studio
2.1 Tạo một không gian làm việc Azure ML
Để huấn luyện một mô hình trong Azure ML, trước tiên bạn cần tạo một không gian làm việc Azure ML. Không gian làm việc là tài nguyên cấp cao nhất cho Azure Machine Learning, cung cấp một nơi tập trung để làm việc với tất cả các artifact bạn tạo khi sử dụng Azure Machine Learning. Không gian làm việc lưu giữ lịch sử của tất cả các lần huấn luyện, bao gồm nhật ký, chỉ số, đầu ra và ảnh chụp nhanh của các script của bạn. Bạn sử dụng thông tin này để xác định lần huấn luyện nào tạo ra mô hình tốt nhất. Tìm hiểu thêm
Chúng tôi khuyến nghị bạn sử dụng trình duyệt mới nhất tương thích với hệ điều hành của bạn. Các trình duyệt sau được hỗ trợ:
- Microsoft Edge (Phiên bản mới nhất của Microsoft Edge, không phải Microsoft Edge cũ)
- Safari (phiên bản mới nhất, chỉ dành cho Mac)
- Chrome (phiên bản mới nhất)
- Firefox (phiên bản mới nhất)
Để sử dụng Azure Machine Learning, hãy tạo một không gian làm việc trong đăng ký Azure của bạn. Sau đó, bạn có thể sử dụng không gian làm việc này để quản lý dữ liệu, tài nguyên tính toán, mã, mô hình và các artifact khác liên quan đến khối lượng công việc học máy của bạn.
LƯU Ý: Đăng ký Azure của bạn sẽ bị tính một khoản phí nhỏ cho việc lưu trữ dữ liệu miễn là không gian làm việc Azure Machine Learning tồn tại trong đăng ký của bạn, vì vậy chúng tôi khuyến nghị bạn xóa không gian làm việc Azure Machine Learning khi không còn sử dụng.
-
Đăng nhập vào cổng Azure bằng thông tin đăng nhập Microsoft liên kết với đăng ký Azure của bạn.
-
Chọn +Tạo tài nguyên
Tìm kiếm Machine Learning và chọn ô Machine Learning
Nhấn nút tạo
Điền các cài đặt như sau:
- Đăng ký: Đăng ký Azure của bạn
- Nhóm tài nguyên: Tạo hoặc chọn một nhóm tài nguyên
- Tên không gian làm việc: Nhập một tên duy nhất cho không gian làm việc của bạn
- Khu vực: Chọn khu vực địa lý gần bạn nhất
- Tài khoản lưu trữ: Lưu ý tài khoản lưu trữ mới mặc định sẽ được tạo cho không gian làm việc của bạn
- Key vault: Lưu ý key vault mới mặc định sẽ được tạo cho không gian làm việc của bạn
- Application insights: Lưu ý tài nguyên application insights mới mặc định sẽ được tạo cho không gian làm việc của bạn
- Container registry: Không (một cái sẽ được tạo tự động lần đầu tiên bạn triển khai mô hình vào container)
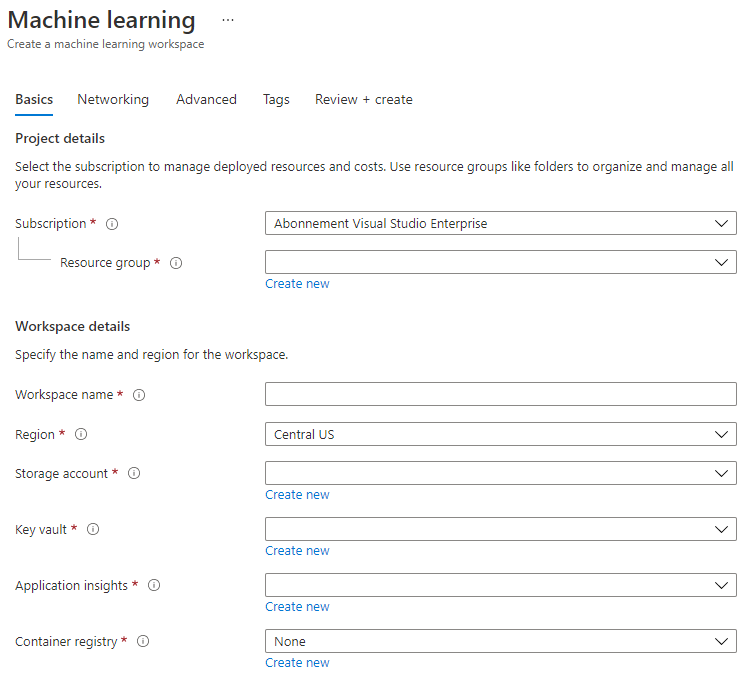
- Nhấn nút tạo + xem lại và sau đó nhấn nút tạo
-
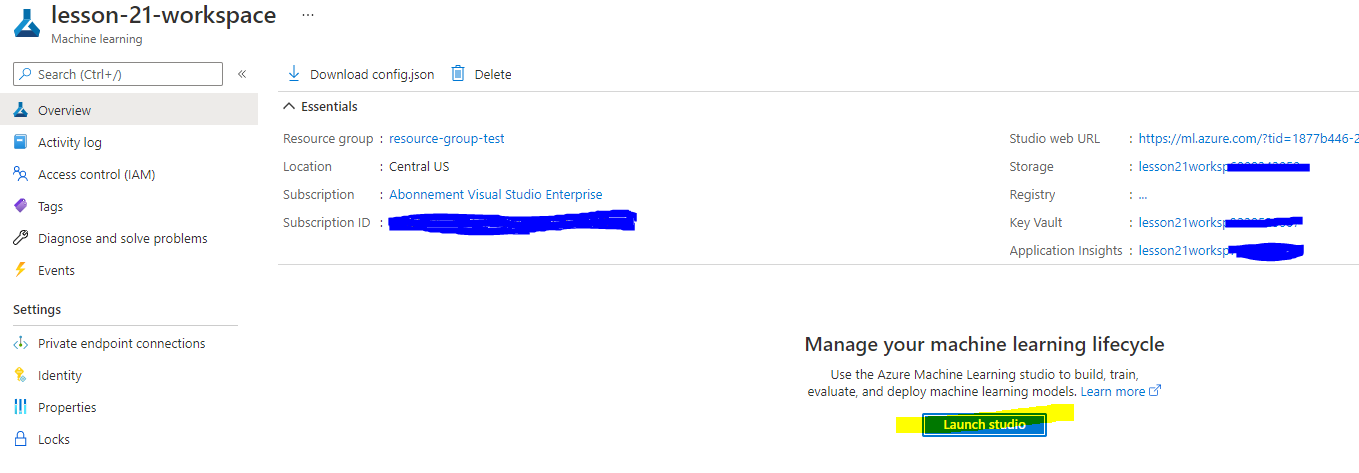
Chờ không gian làm việc của bạn được tạo (có thể mất vài phút). Sau đó, truy cập vào nó trong cổng. Bạn có thể tìm thấy nó thông qua dịch vụ Azure Machine Learning.
-
Trên trang Tổng quan của không gian làm việc của bạn, khởi chạy Azure Machine Learning studio (hoặc mở một tab trình duyệt mới và điều hướng đến https://ml.azure.com), và đăng nhập vào Azure Machine Learning studio bằng tài khoản Microsoft của bạn. Nếu được nhắc, chọn thư mục và đăng ký Azure của bạn, và không gian làm việc Azure Machine Learning của bạn.
- Trong Azure Machine Learning studio, bật biểu tượng ☰ ở góc trên bên trái để xem các trang khác nhau trong giao diện. Bạn có thể sử dụng các trang này để quản lý các tài nguyên trong không gian làm việc của mình.
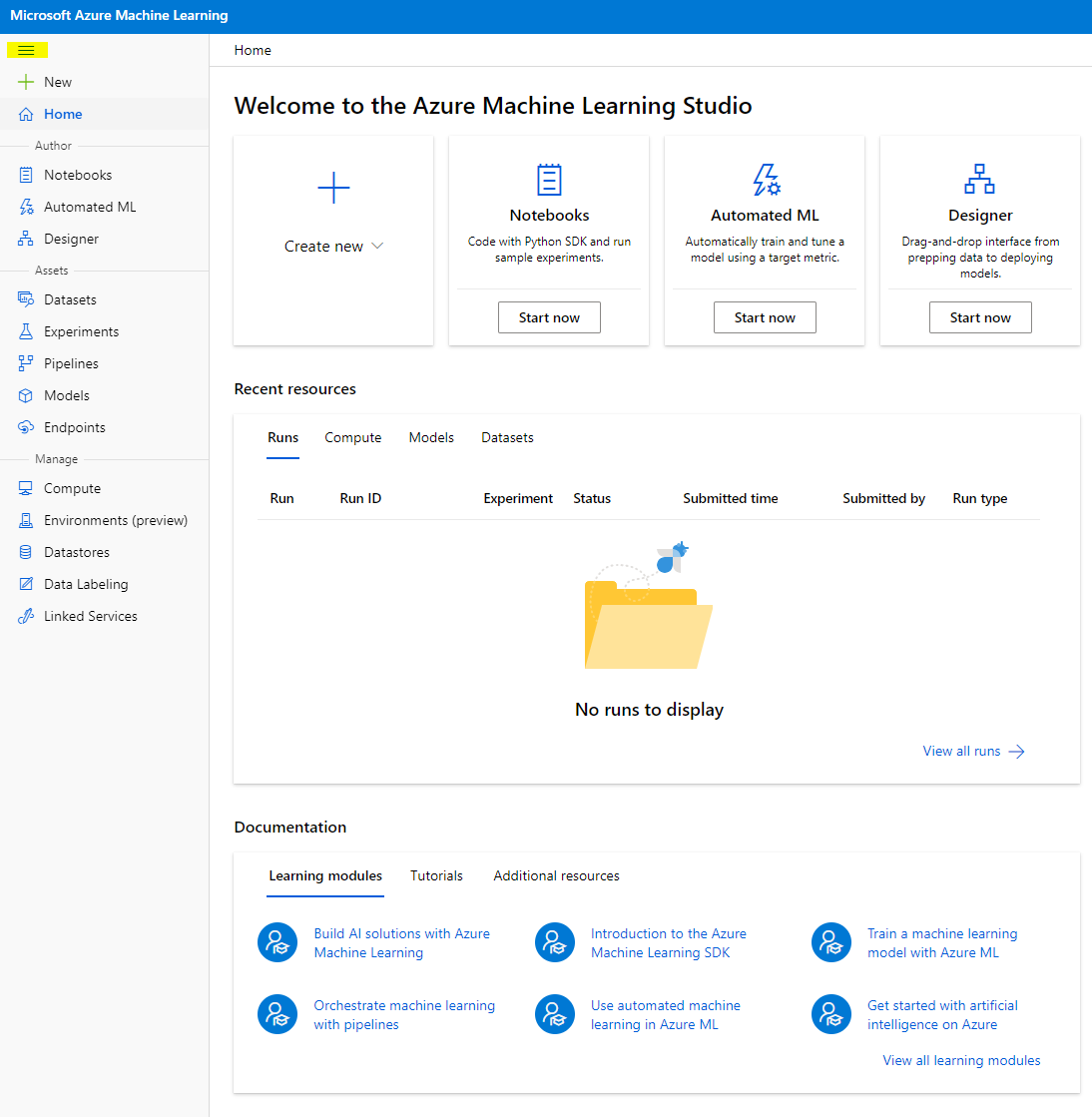
Bạn có thể quản lý không gian làm việc của mình bằng cổng Azure, nhưng đối với các nhà khoa học dữ liệu và kỹ sư vận hành học máy, Azure Machine Learning Studio cung cấp một giao diện người dùng tập trung hơn để quản lý các tài nguyên không gian làm việc.
2.2 Tài nguyên tính toán
Tài nguyên tính toán là các tài nguyên dựa trên đám mây mà bạn có thể sử dụng để chạy các quy trình huấn luyện mô hình và khám phá dữ liệu. Có bốn loại tài nguyên tính toán bạn có thể tạo:
- Compute Instances: Các máy trạm phát triển mà các nhà khoa học dữ liệu có thể sử dụng để làm việc với dữ liệu và mô hình. Điều này bao gồm việc tạo một Máy ảo (VM) và khởi chạy một phiên bản notebook. Bạn có thể huấn luyện mô hình bằng cách gọi một cụm tính toán từ notebook.
- Compute Clusters: Các cụm VM có khả năng mở rộng để xử lý mã thí nghiệm theo yêu cầu. Bạn sẽ cần nó khi huấn luyện mô hình. Các cụm tính toán cũng có thể sử dụng các tài nguyên GPU hoặc CPU chuyên dụng.
- Inference Clusters: Các mục tiêu triển khai cho các dịch vụ dự đoán sử dụng mô hình đã huấn luyện của bạn.
- Attached Compute: Liên kết với các tài nguyên tính toán Azure hiện có, chẳng hạn như Máy Ảo hoặc các cụm Azure Databricks.
2.2.1 Lựa chọn các tùy chọn phù hợp cho tài nguyên tính toán của bạn
Một số yếu tố quan trọng cần xem xét khi tạo tài nguyên tính toán, và những lựa chọn này có thể là các quyết định quan trọng.
Bạn cần CPU hay GPU?
CPU (Bộ xử lý trung tâm) là mạch điện tử thực hiện các lệnh trong một chương trình máy tính. GPU (Bộ xử lý đồ họa) là một mạch điện tử chuyên dụng có thể thực thi mã liên quan đến đồ họa với tốc độ rất cao.
Sự khác biệt chính giữa kiến trúc CPU và GPU là CPU được thiết kế để xử lý nhiều loại tác vụ nhanh chóng (được đo bằng tốc độ xung nhịp CPU), nhưng bị giới hạn về mức độ đồng thời của các tác vụ có thể chạy. GPU được thiết kế cho tính toán song song và do đó tốt hơn nhiều trong các tác vụ học sâu.
| CPU | GPU |
|---|---|
| Ít tốn kém hơn | Đắt đỏ hơn |
| Mức độ đồng thời thấp hơn | Mức độ đồng thời cao hơn |
| Chậm hơn trong việc huấn luyện mô hình học sâu | Tối ưu cho học sâu |
Kích thước cụm
Cụm lớn hơn sẽ đắt hơn nhưng sẽ mang lại khả năng phản hồi tốt hơn. Vì vậy, nếu bạn có thời gian nhưng không đủ tiền, bạn nên bắt đầu với một cụm nhỏ. Ngược lại, nếu bạn có tiền nhưng không có nhiều thời gian, bạn nên bắt đầu với một cụm lớn hơn.
Kích thước VM
Tùy thuộc vào các ràng buộc về thời gian và ngân sách, bạn có thể thay đổi kích thước RAM, ổ đĩa, số lõi và tốc độ xung nhịp. Tăng tất cả các thông số này sẽ tốn kém hơn, nhưng sẽ mang lại hiệu suất tốt hơn.
Phiên bản chuyên dụng hay ưu tiên thấp?
Phiên bản ưu tiên thấp có nghĩa là có thể bị gián đoạn: về cơ bản, Microsoft Azure có thể lấy các tài nguyên đó và gán chúng cho một tác vụ khác, do đó làm gián đoạn công việc. Phiên bản chuyên dụng, hoặc không bị gián đoạn, có nghĩa là công việc sẽ không bao giờ bị dừng mà không có sự cho phép của bạn. Đây là một yếu tố khác cần cân nhắc giữa thời gian và tiền bạc, vì các phiên bản có thể bị gián đoạn rẻ hơn so với các phiên bản chuyên dụng.
2.2.2 Tạo một cụm tính toán
Trong Azure ML workspace mà chúng ta đã tạo trước đó, vào phần Compute và bạn sẽ thấy các tài nguyên tính toán khác nhau mà chúng ta vừa thảo luận (ví dụ: compute instances, compute clusters, inference clusters và attached compute). Đối với dự án này, chúng ta sẽ cần một cụm tính toán để huấn luyện mô hình. Trong Studio, nhấp vào menu "Compute", sau đó tab "Compute cluster" và nhấp vào nút "+ New" để tạo một cụm tính toán.
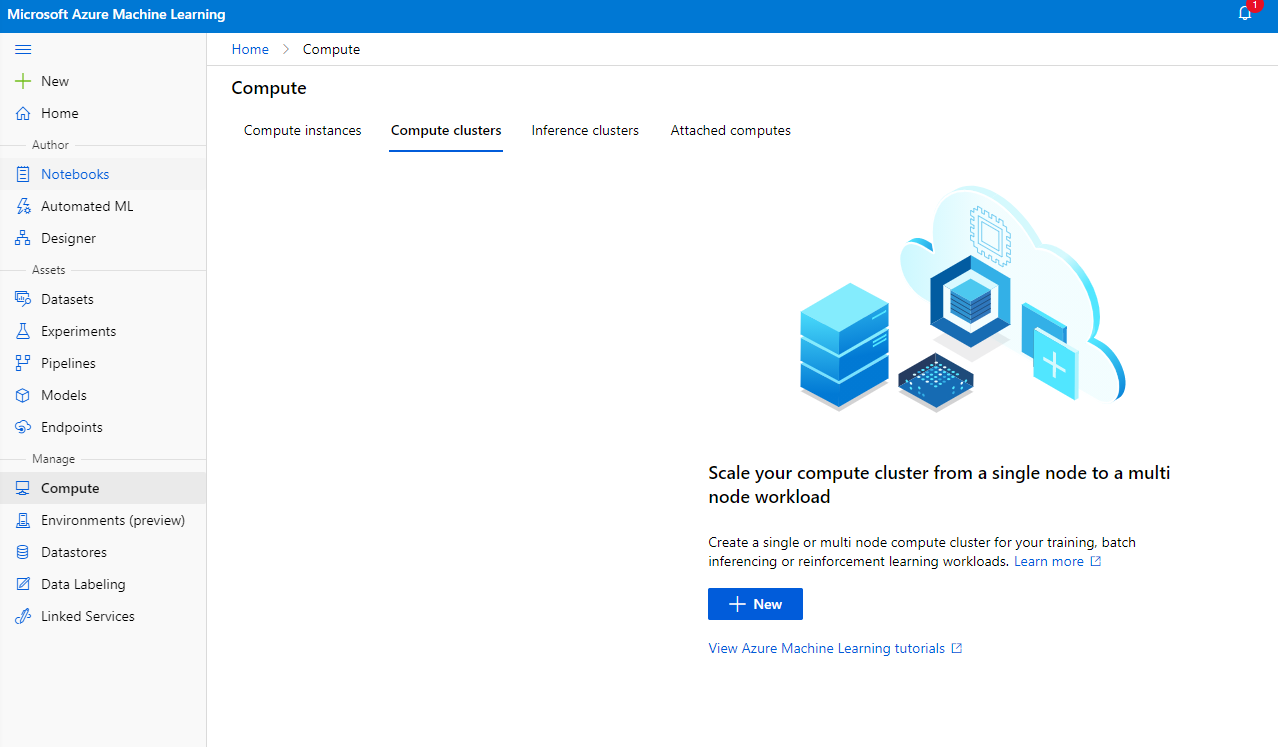
- Chọn các tùy chọn của bạn: Dedicated vs Low priority, CPU hoặc GPU, kích thước VM và số lõi (bạn có thể giữ các cài đặt mặc định cho dự án này).
- Nhấp vào nút Next.
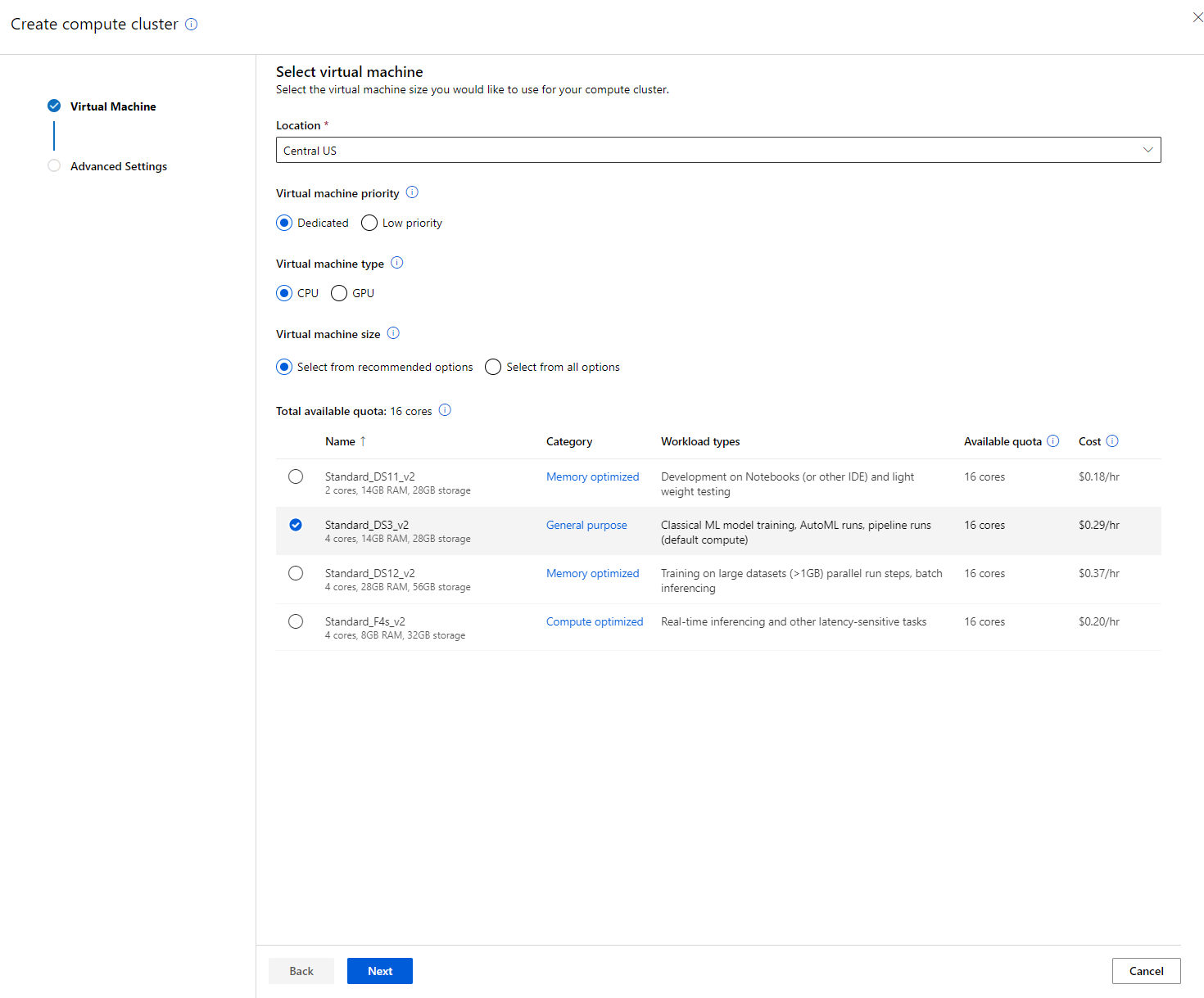
- Đặt tên cho cụm tính toán.
- Chọn các tùy chọn của bạn: Số lượng nút tối thiểu/tối đa, số giây không hoạt động trước khi giảm quy mô, truy cập SSH. Lưu ý rằng nếu số lượng nút tối thiểu là 0, bạn sẽ tiết kiệm tiền khi cụm không hoạt động. Lưu ý rằng số lượng nút tối đa càng cao, thời gian huấn luyện sẽ càng ngắn. Số lượng nút tối đa được khuyến nghị là 3.
- Nhấp vào nút "Create". Bước này có thể mất vài phút.
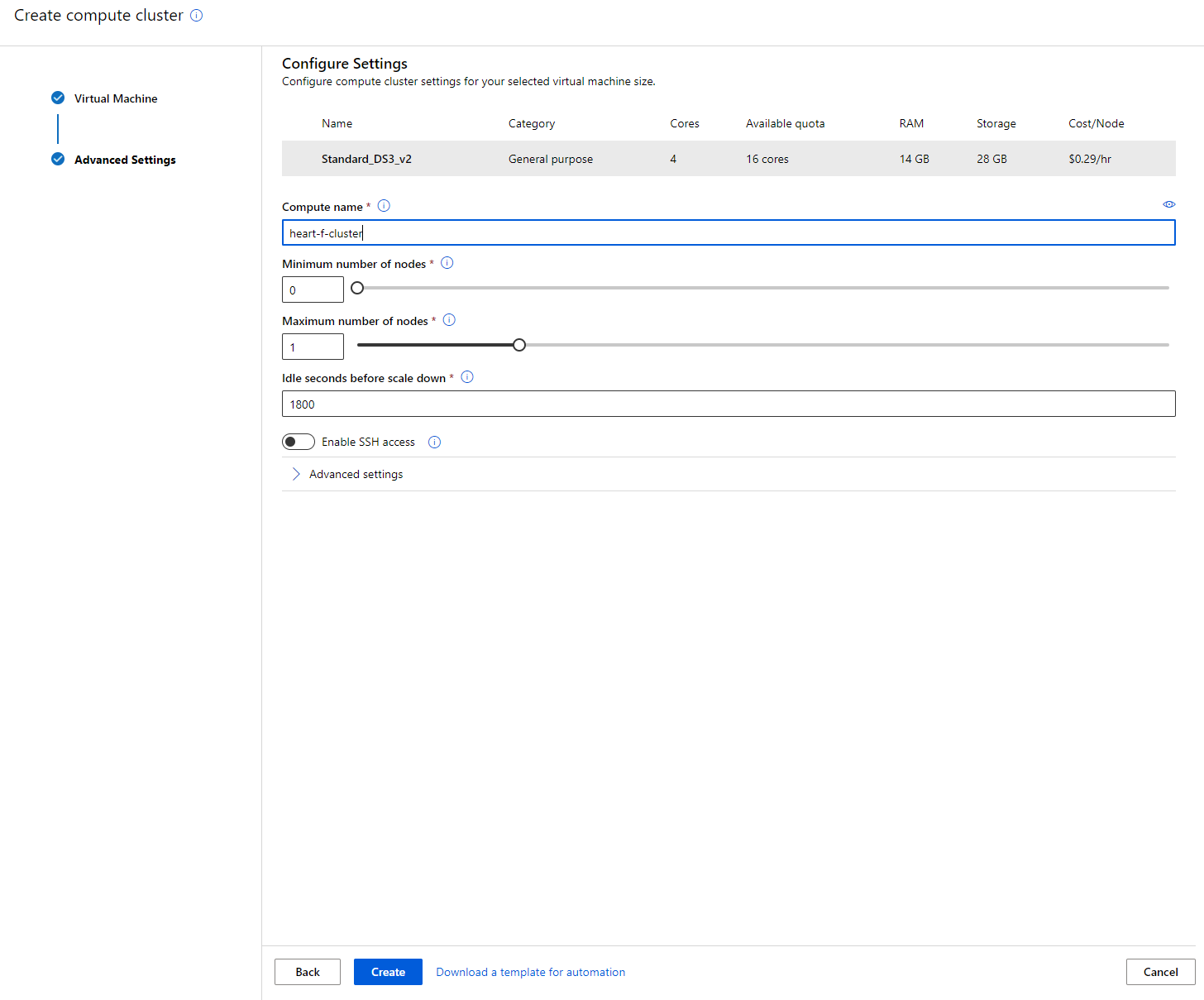
Tuyệt vời! Bây giờ chúng ta đã có một cụm tính toán, chúng ta cần tải dữ liệu lên Azure ML Studio.
2.3 Tải tập dữ liệu
-
Trong Azure ML workspace mà chúng ta đã tạo trước đó, nhấp vào "Datasets" trong menu bên trái và nhấp vào nút "+ Create dataset" để tạo một tập dữ liệu. Chọn tùy chọn "From local files" và chọn tập dữ liệu Kaggle mà chúng ta đã tải xuống trước đó.
-
Đặt tên, loại và mô tả cho tập dữ liệu của bạn. Nhấp vào Next. Tải dữ liệu từ các tệp. Nhấp vào Next.
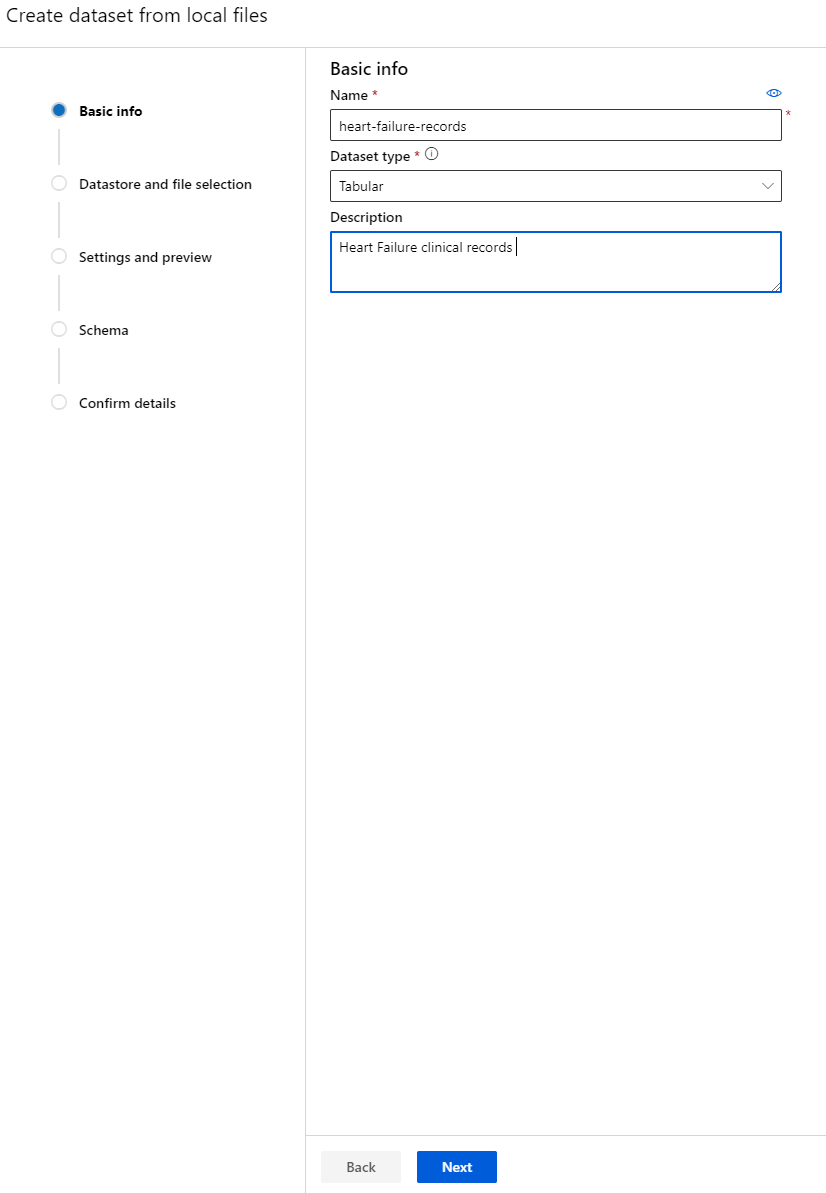
-
Trong Schema, thay đổi kiểu dữ liệu thành Boolean cho các đặc điểm sau: anaemia, diabetes, high blood pressure, sex, smoking, và DEATH_EVENT. Nhấp vào Next và nhấp vào Create.
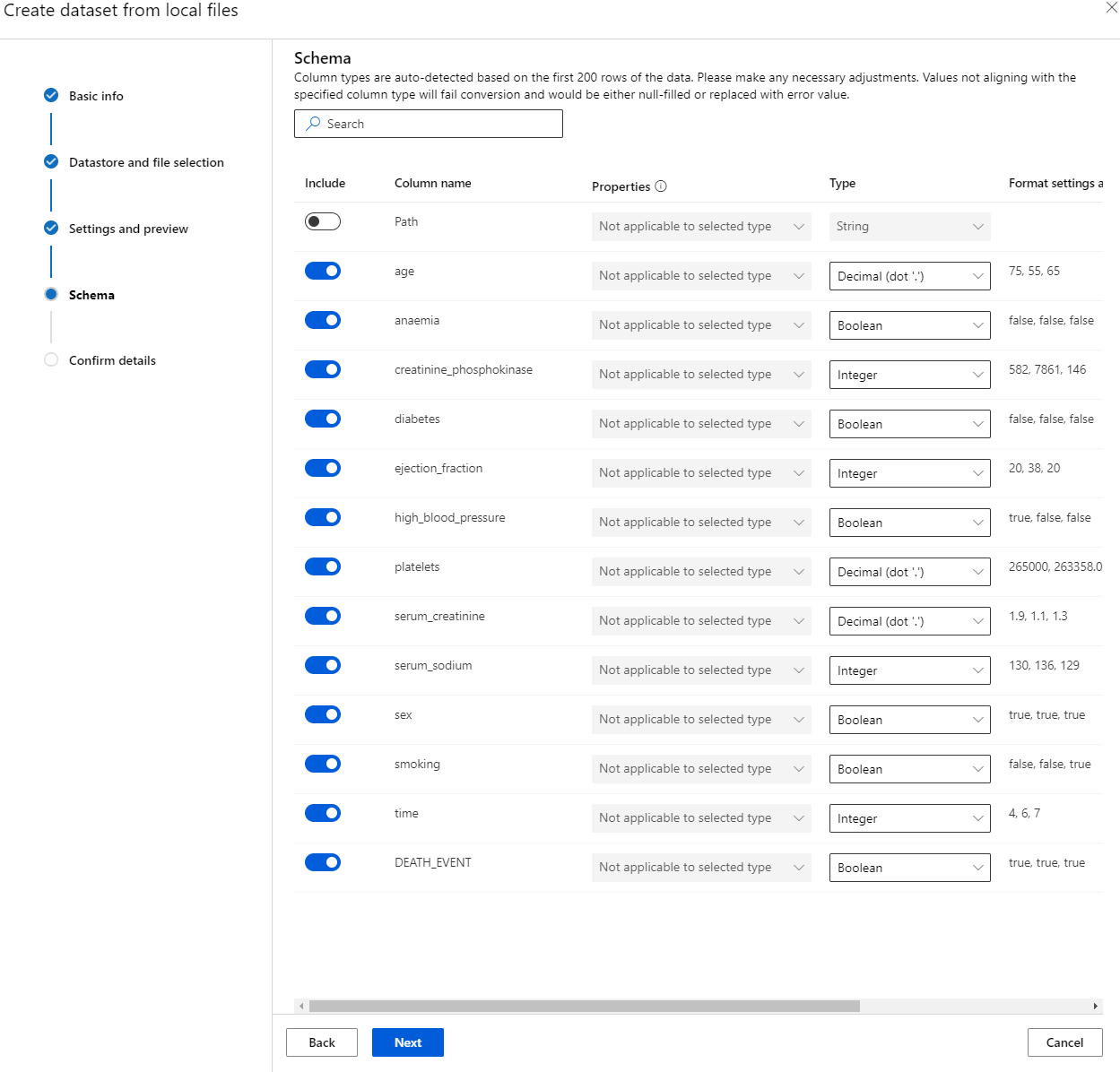
Tuyệt vời! Bây giờ tập dữ liệu đã sẵn sàng và cụm tính toán đã được tạo, chúng ta có thể bắt đầu huấn luyện mô hình!
2.4 Huấn luyện Low code/No code với AutoML
Phát triển mô hình học máy truyền thống tiêu tốn nhiều tài nguyên, đòi hỏi kiến thức chuyên môn đáng kể và thời gian để tạo và so sánh hàng chục mô hình. Học máy tự động (AutoML) là quá trình tự động hóa các tác vụ lặp đi lặp lại và tốn thời gian trong phát triển mô hình học máy. Nó cho phép các nhà khoa học dữ liệu, nhà phân tích và nhà phát triển xây dựng các mô hình ML với quy mô lớn, hiệu quả và năng suất cao, đồng thời duy trì chất lượng mô hình. Nó giảm thời gian để có được các mô hình ML sẵn sàng cho sản xuất, với sự dễ dàng và hiệu quả cao. Tìm hiểu thêm
-
Trong Azure ML workspace mà chúng ta đã tạo trước đó, nhấp vào "Automated ML" trong menu bên trái và chọn tập dữ liệu bạn vừa tải lên. Nhấp vào Next.
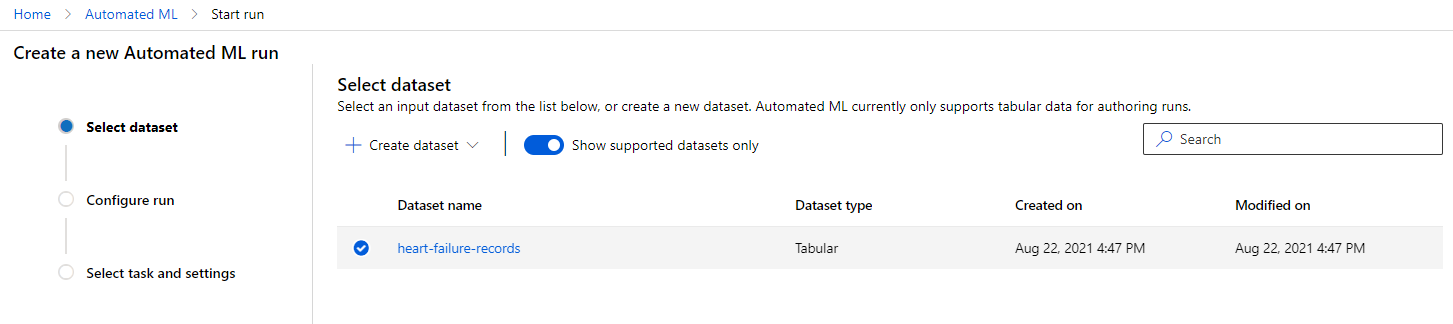
-
Nhập tên thử nghiệm mới, cột mục tiêu (DEATH_EVENT) và cụm tính toán mà chúng ta đã tạo. Nhấp vào Next.
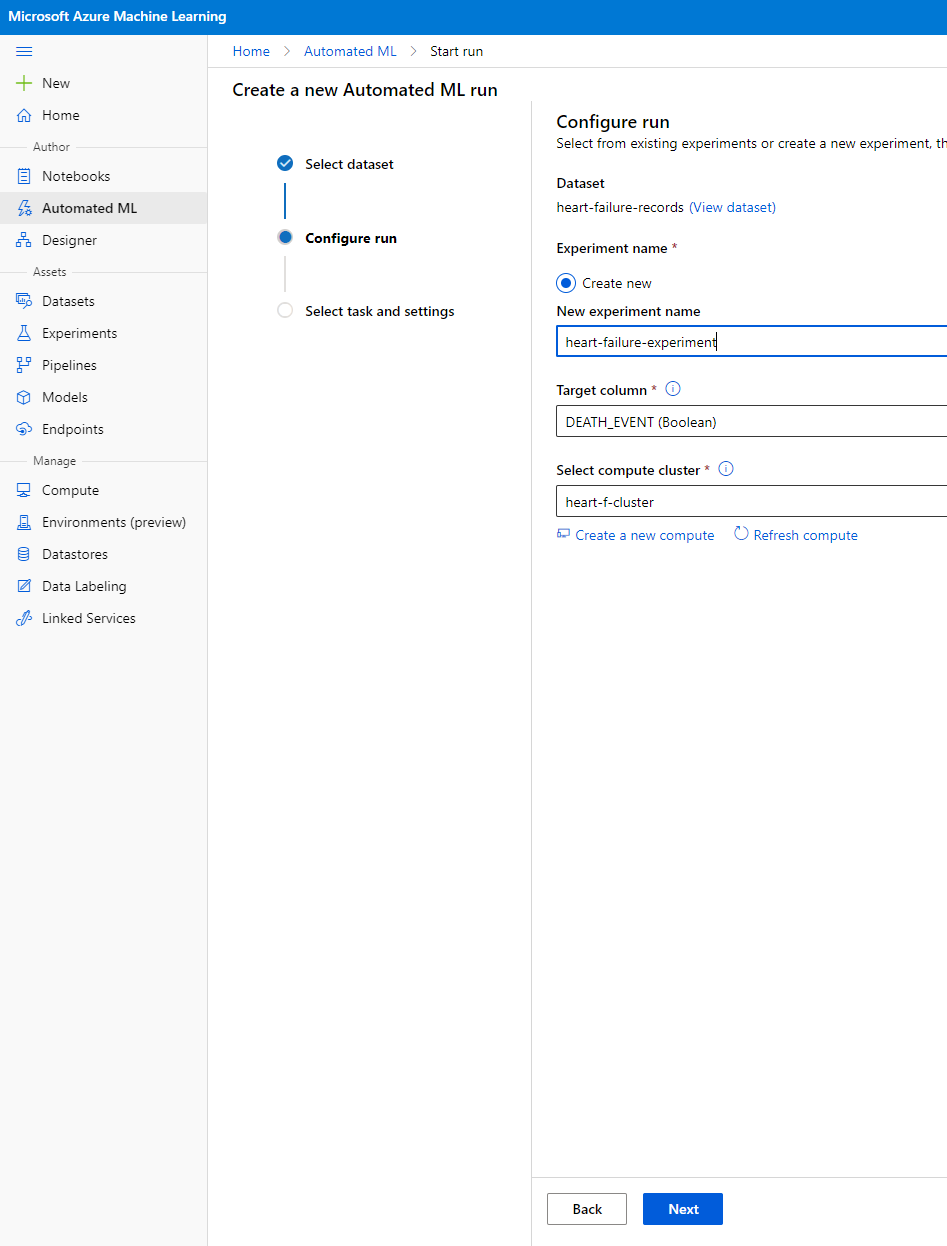
-
Chọn "Classification" và nhấp vào Finish. Bước này có thể mất từ 30 phút đến 1 giờ, tùy thuộc vào kích thước cụm tính toán của bạn.
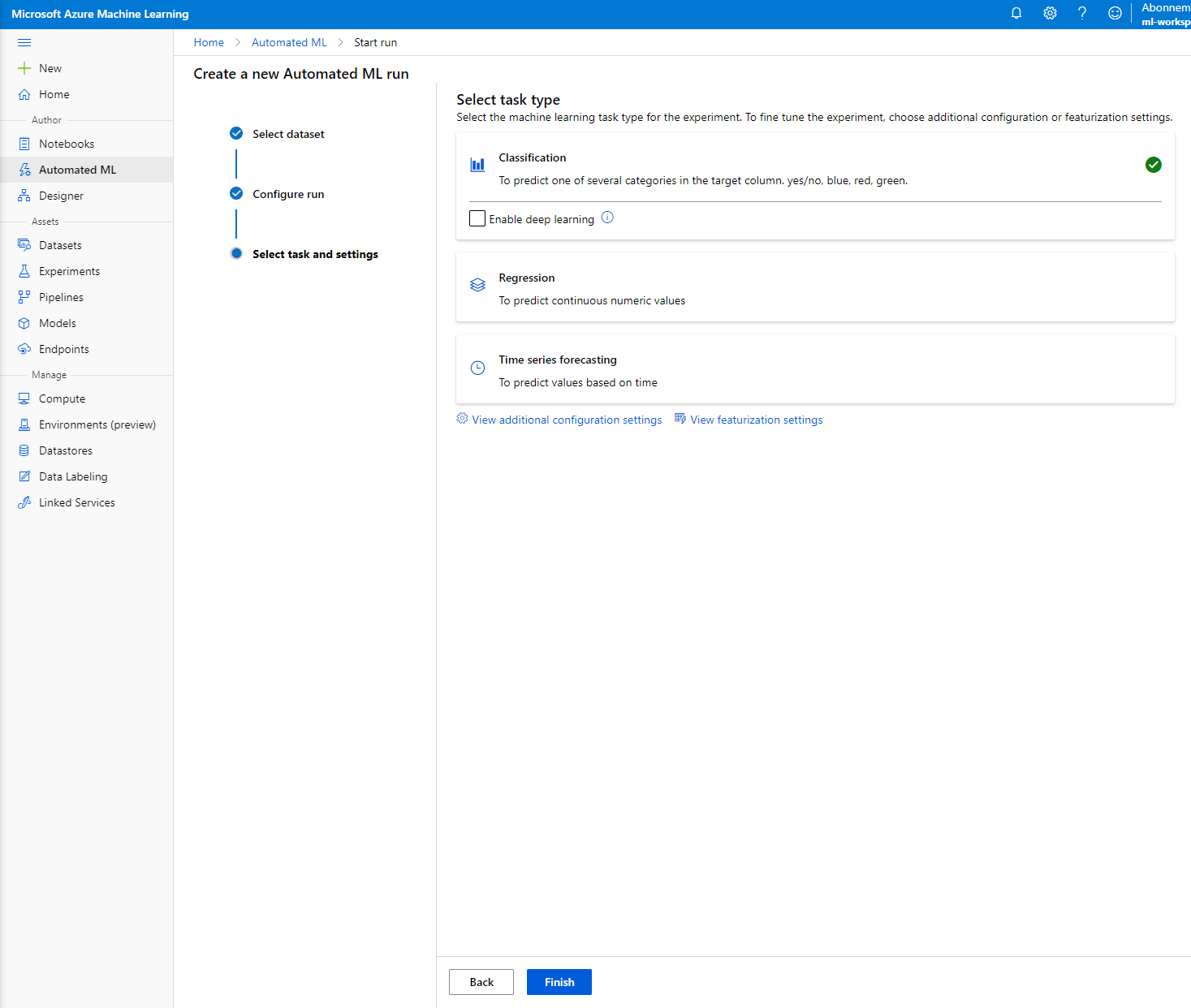
-
Khi quá trình chạy hoàn tất, nhấp vào tab "Automated ML", nhấp vào lần chạy của bạn và nhấp vào thuật toán trong thẻ "Best model summary".
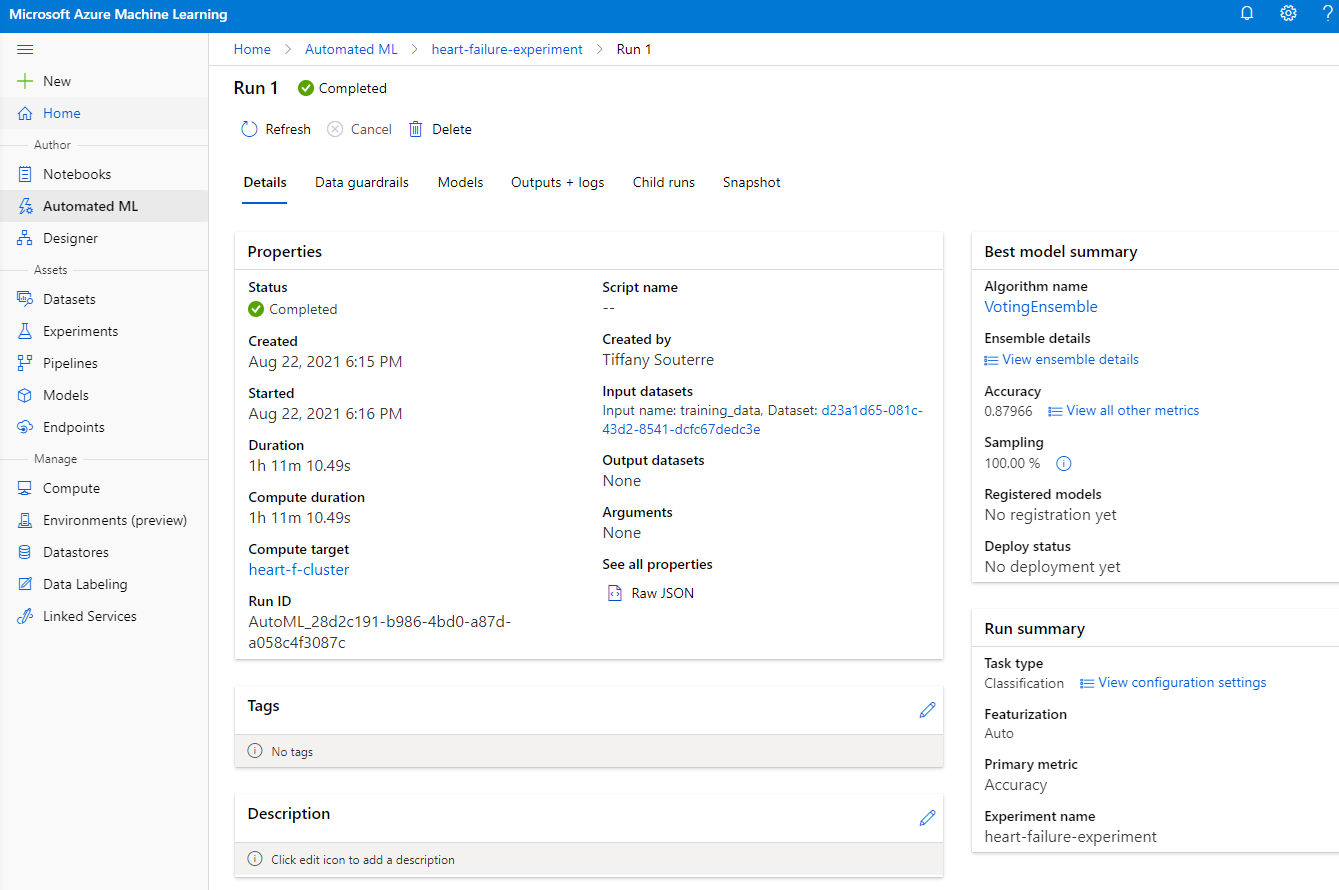
Tại đây, bạn có thể xem mô tả chi tiết về mô hình tốt nhất mà AutoML đã tạo ra. Bạn cũng có thể khám phá các mô hình khác được tạo trong tab Models. Dành vài phút để khám phá các mô hình trong nút Explanations (preview). Sau khi bạn đã chọn mô hình muốn sử dụng (ở đây chúng ta sẽ chọn mô hình tốt nhất được AutoML chọn), chúng ta sẽ xem cách triển khai nó.
3. Triển khai mô hình Low code/No code và tiêu thụ endpoint
3.1 Triển khai mô hình
Giao diện học máy tự động cho phép bạn triển khai mô hình tốt nhất dưới dạng dịch vụ web chỉ trong vài bước. Triển khai là tích hợp mô hình để nó có thể đưa ra dự đoán dựa trên dữ liệu mới và xác định các khu vực tiềm năng. Đối với dự án này, triển khai thành dịch vụ web có nghĩa là các ứng dụng y tế sẽ có thể sử dụng mô hình để đưa ra dự đoán trực tiếp về nguy cơ bệnh nhân bị đau tim.
Trong mô tả mô hình tốt nhất, nhấp vào nút "Deploy".
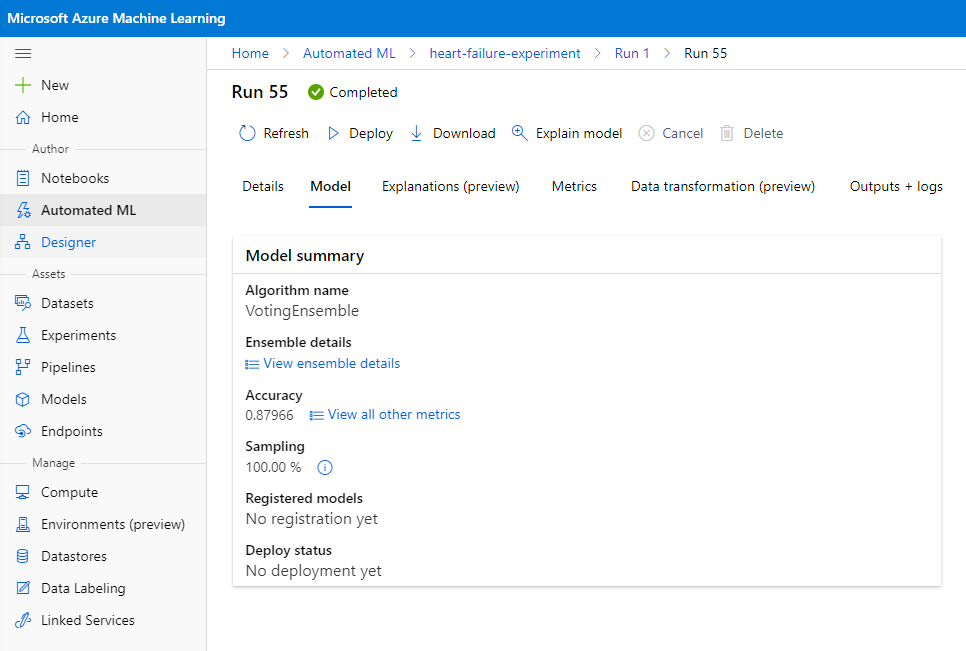
- Đặt tên, mô tả, loại tính toán (Azure Container Instance), bật xác thực và nhấp vào Deploy. Bước này có thể mất khoảng 20 phút để hoàn thành. Quá trình triển khai bao gồm nhiều bước như đăng ký mô hình, tạo tài nguyên và cấu hình chúng cho dịch vụ web. Một thông báo trạng thái xuất hiện dưới Deploy status. Chọn Refresh định kỳ để kiểm tra trạng thái triển khai. Khi trạng thái là "Healthy", nghĩa là đã triển khai và đang chạy.
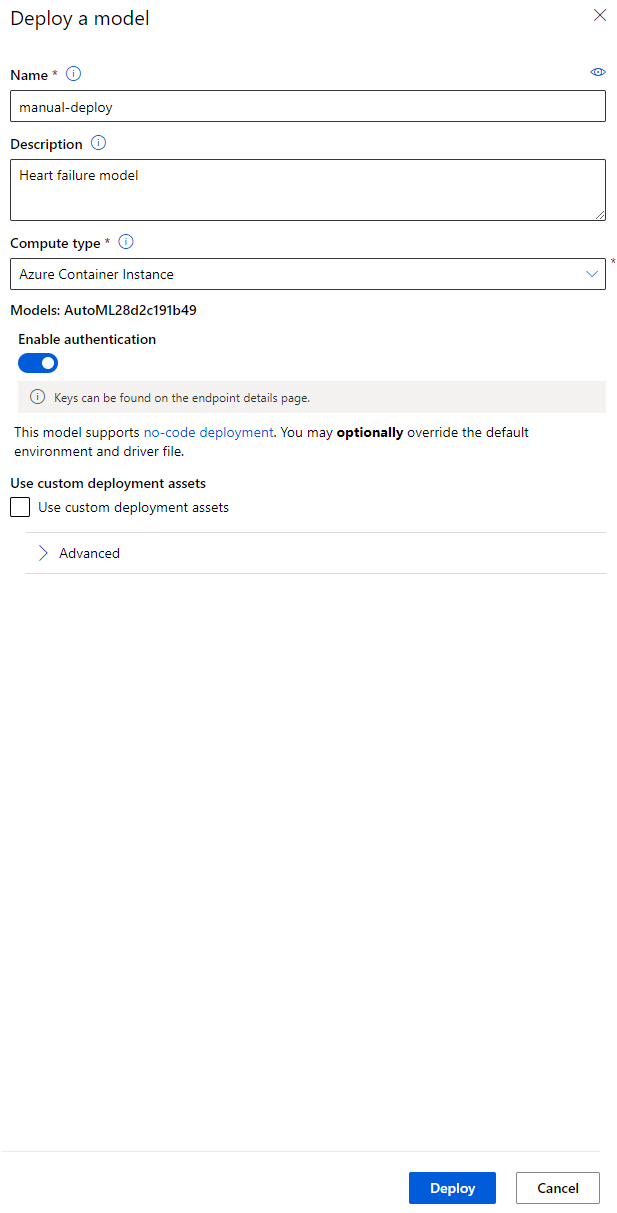
- Khi đã triển khai xong, nhấp vào tab Endpoint và nhấp vào endpoint bạn vừa triển khai. Tại đây, bạn có thể tìm thấy tất cả các chi tiết cần biết về endpoint.
Tuyệt vời! Bây giờ chúng ta đã có một mô hình được triển khai, chúng ta có thể bắt đầu tiêu thụ endpoint.
3.2 Tiêu thụ endpoint
Nhấp vào tab "Consume". Tại đây, bạn có thể tìm thấy REST endpoint và một tập lệnh Python trong tùy chọn tiêu thụ. Dành thời gian để đọc mã Python.
Tập lệnh này có thể được chạy trực tiếp từ máy cục bộ của bạn và sẽ tiêu thụ endpoint của bạn.
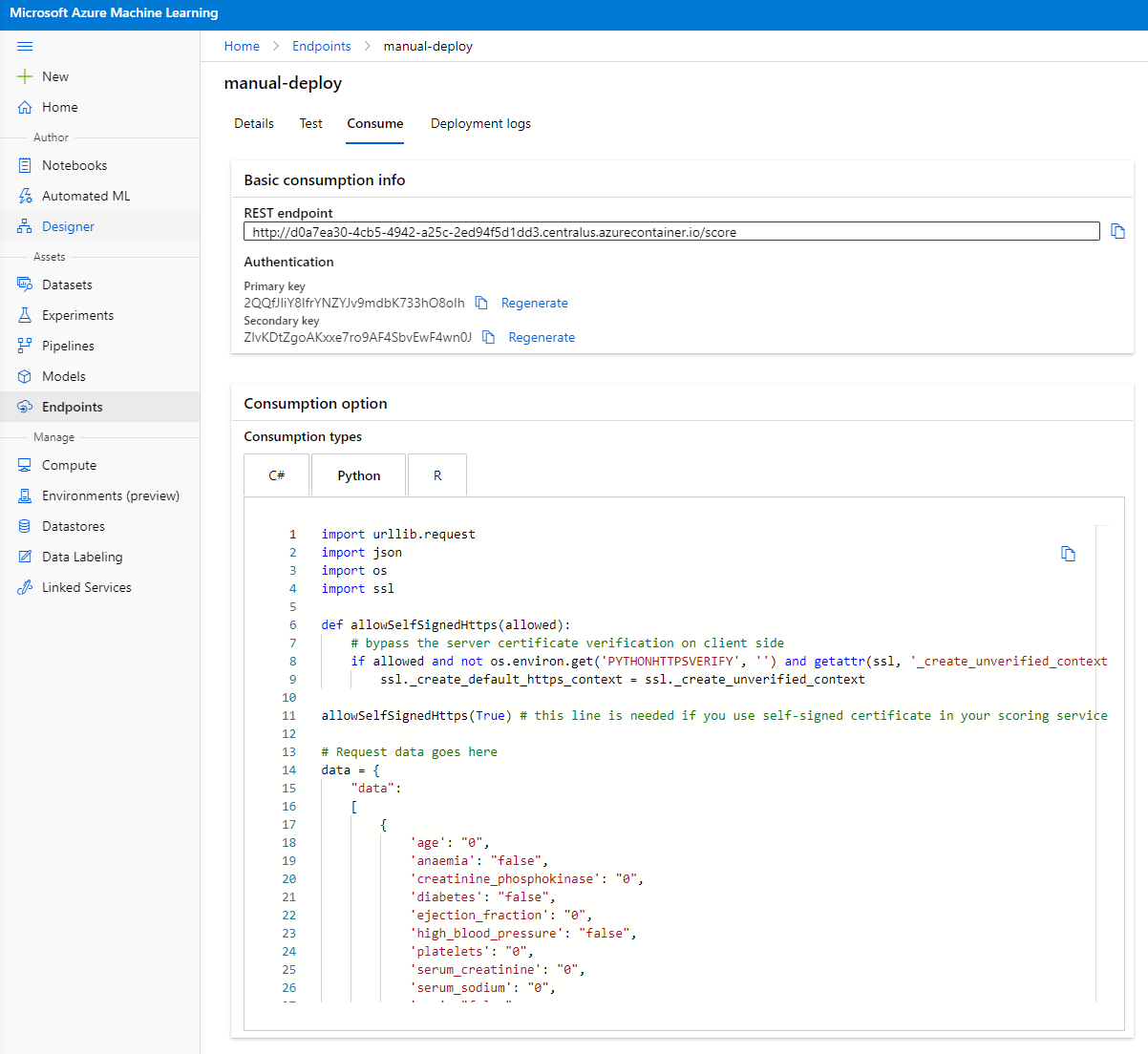
Dành một chút thời gian để kiểm tra hai dòng mã này:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
Biến url là REST endpoint được tìm thấy trong tab consume và biến api_key là khóa chính cũng được tìm thấy trong tab consume (chỉ trong trường hợp bạn đã bật xác thực). Đây là cách tập lệnh có thể tiêu thụ endpoint.
- Khi chạy tập lệnh, bạn sẽ thấy đầu ra sau:
b'"{\\"result\\": [true]}"'
Điều này có nghĩa là dự đoán về nguy cơ suy tim cho dữ liệu được cung cấp là đúng. Điều này hợp lý vì nếu bạn nhìn kỹ hơn vào dữ liệu được tạo tự động trong tập lệnh, mọi thứ đều ở mức 0 và sai theo mặc định. Bạn có thể thay đổi dữ liệu với mẫu đầu vào sau:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
Tập lệnh sẽ trả về:
python b'"{\\"result\\": [true, false]}"'
Chúc mừng! Bạn vừa tiêu thụ mô hình đã triển khai và huấn luyện nó trên Azure ML!
LƯU Ý: Sau khi hoàn thành dự án, đừng quên xóa tất cả các tài nguyên.
🚀 Thử thách
Hãy xem xét kỹ các giải thích và chi tiết mô hình mà AutoML đã tạo ra cho các mô hình hàng đầu. Cố gắng hiểu tại sao mô hình tốt nhất lại tốt hơn các mô hình khác. Những thuật toán nào đã được so sánh? Sự khác biệt giữa chúng là gì? Tại sao mô hình tốt nhất lại hoạt động tốt hơn trong trường hợp này?
Câu hỏi sau bài giảng
Ôn tập & Tự học
Trong bài học này, bạn đã học cách huấn luyện, triển khai và tiêu thụ một mô hình để dự đoán nguy cơ suy tim theo cách Low code/No code trên đám mây. Nếu bạn chưa làm, hãy đi sâu hơn vào các giải thích mô hình mà AutoML đã tạo ra cho các mô hình hàng đầu và cố gắng hiểu tại sao mô hình tốt nhất lại tốt hơn các mô hình khác.
Bạn có thể tìm hiểu thêm về AutoML Low code/No code bằng cách đọc tài liệu này.
Bài tập
Dự án Khoa học Dữ liệu Low code/No code trên Azure ML
Tuyên bố miễn trừ trách nhiệm:
Tài liệu này đã được dịch bằng dịch vụ dịch thuật AI Co-op Translator. Mặc dù chúng tôi cố gắng đảm bảo độ chính xác, xin lưu ý rằng các bản dịch tự động có thể chứa lỗi hoặc sự không chính xác. Tài liệu gốc bằng ngôn ngữ bản địa nên được coi là nguồn tham khảo chính thức. Đối với các thông tin quan trọng, nên sử dụng dịch vụ dịch thuật chuyên nghiệp từ con người. Chúng tôi không chịu trách nhiệm cho bất kỳ sự hiểu lầm hoặc diễn giải sai nào phát sinh từ việc sử dụng bản dịch này.