|
|
5 months ago | |
|---|---|---|
| .. | ||
| README.md | 5 months ago | |
| assignment.md | 5 months ago | |
README.md
Podatkovna znanost v oblaku: Način "Low code/No code"
 |
|---|
| Podatkovna znanost v oblaku: Low Code - Sketchnote by @nitya |
Kazalo:
- Podatkovna znanost v oblaku: Način "Low code/No code"
Predhodni kviz
1. Uvod
1.1 Kaj je Azure Machine Learning?
Azure je oblačna platforma z več kot 200 izdelki in storitvami, zasnovanimi za pomoč pri ustvarjanju novih rešitev. Podatkovni znanstveniki porabijo veliko časa za raziskovanje in predobdelavo podatkov ter preizkušanje različnih algoritmov za usposabljanje modelov, da bi ustvarili natančne modele. Te naloge so časovno zahtevne in pogosto neučinkovito izkoriščajo drage računalniške vire.
Azure ML je oblačna platforma za gradnjo in upravljanje rešitev strojnega učenja v Azure. Ponuja širok nabor funkcij in zmogljivosti, ki pomagajo podatkovnim znanstvenikom pri pripravi podatkov, usposabljanju modelov, objavi napovednih storitev in spremljanju njihove uporabe. Najpomembneje je, da povečuje njihovo učinkovitost z avtomatizacijo številnih časovno zahtevnih nalog, povezanih z usposabljanjem modelov, ter omogoča uporabo oblačnih računalniških virov, ki se učinkovito prilagajajo za obdelavo velikih količin podatkov, pri čemer nastanejo stroški le ob dejanski uporabi.
Azure ML ponuja vsa orodja, ki jih razvijalci in podatkovni znanstveniki potrebujejo za svoje delovne procese strojnega učenja. Ta vključujejo:
- Azure Machine Learning Studio: spletni portal v Azure Machine Learning za možnosti z nizko kodo in brez kode za usposabljanje modelov, namestitev, avtomatizacijo, sledenje in upravljanje virov. Studio se integrira z Azure Machine Learning SDK za brezhibno izkušnjo.
- Jupyter Notebooks: hitro prototipiranje in testiranje modelov strojnega učenja.
- Azure Machine Learning Designer: omogoča povleci-in-spusti module za gradnjo eksperimentov in nato namestitev cevovodov v okolju z nizko kodo.
- Avtomatizirano strojno učenje (AutoML): avtomatizira iterativne naloge razvoja modelov strojnega učenja, kar omogoča gradnjo modelov z visoko učinkovitostjo in produktivnostjo, ob ohranjanju kakovosti modela.
- Označevanje podatkov: orodje za asistirano strojno učenje za samodejno označevanje podatkov.
- Razširitev strojnega učenja za Visual Studio Code: ponuja popolno razvojno okolje za gradnjo in upravljanje projektov strojnega učenja.
- CLI za strojno učenje: omogoča ukaze za upravljanje virov Azure ML iz ukazne vrstice.
- Integracija z odprtokodnimi ogrodji, kot so PyTorch, TensorFlow, Scikit-learn in mnogi drugi, za usposabljanje, namestitev in upravljanje celotnega procesa strojnega učenja.
- MLflow: odprtokodna knjižnica za upravljanje življenjskega cikla eksperimentov strojnega učenja. MLFlow Tracking je komponenta MLflow, ki beleži in spremlja metrike usposabljanja ter artefakte modela, ne glede na okolje eksperimenta.
1.2 Projekt napovedovanja srčnega popuščanja:
Ni dvoma, da je izdelava projektov najboljši način za preizkus vaših veščin in znanja. V tej lekciji bomo raziskali dva različna načina gradnje projekta podatkovne znanosti za napovedovanje srčnih napadov v Azure ML Studio, in sicer z nizko kodo/brez kode ter z uporabo Azure ML SDK, kot je prikazano v naslednji shemi:
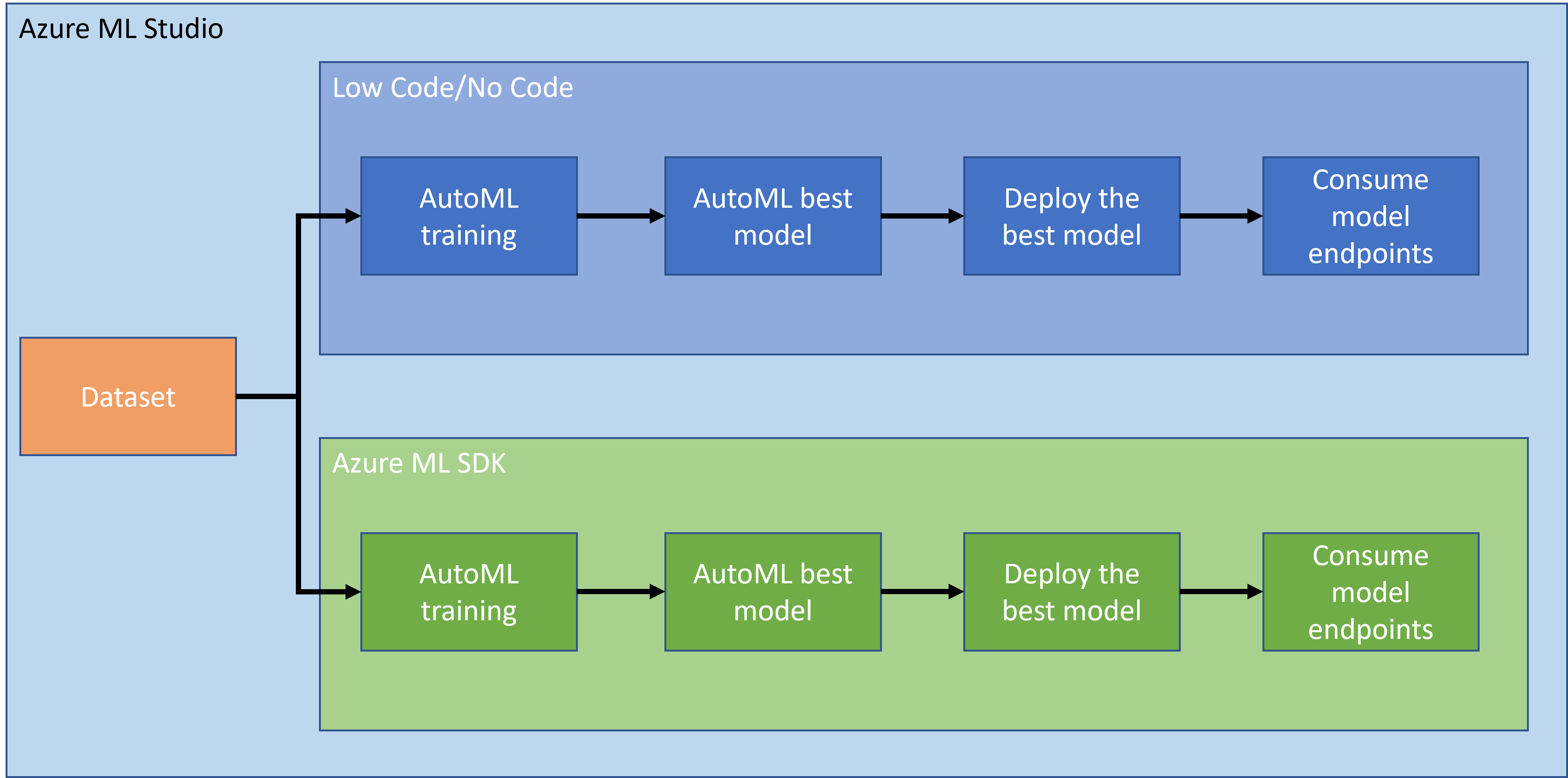
Vsak način ima svoje prednosti in slabosti. Način z nizko kodo/brez kode je lažji za začetek, saj vključuje interakcijo z grafičnim uporabniškim vmesnikom (GUI) in ne zahteva predhodnega znanja o kodiranju. Ta metoda omogoča hitro testiranje izvedljivosti projekta in ustvarjanje POC (Proof Of Concept). Vendar pa, ko projekt raste in je treba stvari pripraviti za produkcijo, ni izvedljivo ustvarjati virov prek GUI. Potrebno je programatično avtomatizirati vse, od ustvarjanja virov do namestitve modela. Tukaj postane ključnega pomena poznavanje uporabe Azure ML SDK.
| Nizka koda/Brez kode | Azure ML SDK | |
|---|---|---|
| Znanje kodiranja | Ni potrebno | Potrebno |
| Čas razvoja | Hiter in enostaven | Odvisno od znanja kodiranja |
| Pripravljenost za produkcijo | Ne | Da |
1.3 Podatkovni niz srčnega popuščanja:
Kardiovaskularne bolezni (CVD) so glavni vzrok smrti po vsem svetu, saj predstavljajo 31 % vseh smrti. Okoljski in vedenjski dejavniki tveganja, kot so uporaba tobaka, nezdrava prehrana in debelost, telesna neaktivnost ter škodljiva uporaba alkohola, bi lahko služili kot značilnosti za modele ocenjevanja. Sposobnost ocenjevanja verjetnosti razvoja CVD bi bila zelo koristna za preprečevanje napadov pri ljudeh z visokim tveganjem.
Kaggle je objavil podatkovni niz srčnega popuščanja, ki ga bomo uporabili za ta projekt. Podatkovni niz lahko prenesete zdaj. Gre za tabelarni podatkovni niz s 13 stolpci (12 značilnosti in 1 ciljno spremenljivko) ter 299 vrsticami.
| Ime spremenljivke | Tip | Opis | Primer | |
|---|---|---|---|---|
| 1 | age | numerični | starost pacienta | 25 |
| 2 | anaemia | logični | Zmanjšanje rdečih krvnih celic ali hemoglobina | 0 ali 1 |
| 3 | creatinine_phosphokinase | numerični | Raven encima CPK v krvi | 542 |
| 4 | diabetes | logični | Ali ima pacient sladkorno bolezen | 0 ali 1 |
| 5 | ejection_fraction | numerični | Odstotek krvi, ki zapusti srce ob vsakem krčenju | 45 |
| 6 | high_blood_pressure | logični | Ali ima pacient hipertenzijo | 0 ali 1 |
| 7 | platelets | numerični | Trombociti v krvi | 149000 |
| 8 | serum_creatinine | numerični | Raven serumske kreatinina v krvi | 0.5 |
| 9 | serum_sodium | numerični | Raven serumske natrija v krvi | jun |
| 10 | sex | logični | ženska ali moški | 0 ali 1 |
| 11 | smoking | logični | Ali pacient kadi | 0 ali 1 |
| 12 | time | numerični | obdobje spremljanja (dni) | 4 |
| ---- | --------------------------- | ----------------- | --------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Cilj] | logični | Ali pacient umre med obdobjem spremljanja | 0 ali 1 |
Ko imate podatkovni niz, lahko začnemo projekt v Azure.
2. Usposabljanje modela z nizko kodo/brez kode v Azure ML Studio
2.1 Ustvarjanje delovnega prostora Azure ML
Za usposabljanje modela v Azure ML morate najprej ustvariti delovni prostor Azure ML. Delovni prostor je najvišji vir za Azure Machine Learning, ki zagotavlja centralizirano mesto za delo z vsemi artefakti, ki jih ustvarite pri uporabi Azure Machine Learning. Delovni prostor vodi zgodovino vseh usposabljanj, vključno z dnevniki, metrikami, izhodom in posnetkom vaših skriptov. Te informacije uporabite za določitev, katero usposabljanje ustvari najboljši model. Več o tem
Priporočljivo je, da uporabljate najbolj posodobljen brskalnik, ki je združljiv z vašim operacijskim sistemom. Podprti so naslednji brskalniki:
- Microsoft Edge (novi Microsoft Edge, najnovejša različica. Ne Microsoft Edge legacy)
- Safari (najnovejša različica, samo Mac)
- Chrome (najnovejša različica)
- Firefox (najnovejša različica)
Za uporabo Azure Machine Learning ustvarite delovni prostor v svoji naročnini Azure. Nato lahko ta delovni prostor uporabite za upravljanje podatkov, računalniških virov, kode, modelov in drugih artefaktov, povezanih z vašimi delovnimi obremenitvami strojnega učenja.
OPOMBA: Vaša naročnina Azure bo zaračunana majhna količina za shranjevanje podatkov, dokler delovni prostor Azure Machine Learning obstaja v vaši naročnini, zato priporočamo, da izbrišete delovni prostor Azure Machine Learning, ko ga ne uporabljate več.
-
Prijavite se v Azure portal z Microsoftovimi poverilnicami, povezanimi z vašo naročnino Azure.
-
Izberite +Ustvari vir
Poiščite Machine Learning in izberite ploščico Machine Learning
Kliknite gumb za ustvarjanje
Izpolnite nastavitve, kot sledi:
- Naročnina: Vaša naročnina Azure
- Skupina virov: Ustvarite ali izberite skupino virov
- Ime delovnega prostora: Vnesite edinstveno ime za vaš delovni prostor
- Regija: Izberite geografsko regijo, ki je najbližja vam
- Račun za shranjevanje: Opomba o privzetem novem računu za shranjevanje, ki bo ustvarjen za vaš delovni prostor
- Ključni trezor: Opomba o privzetem novem ključnem trezorju, ki bo ustvarjen za vaš delovni prostor
- Aplikacijski vpogledi: Opomba o privzetem novem viru aplikacijskih vpogledov, ki bo ustvarjen za vaš delovni prostor
- Register vsebnikov: Noben (eden bo samodejno ustvarjen ob prvi namestitvi modela v vsebnik)
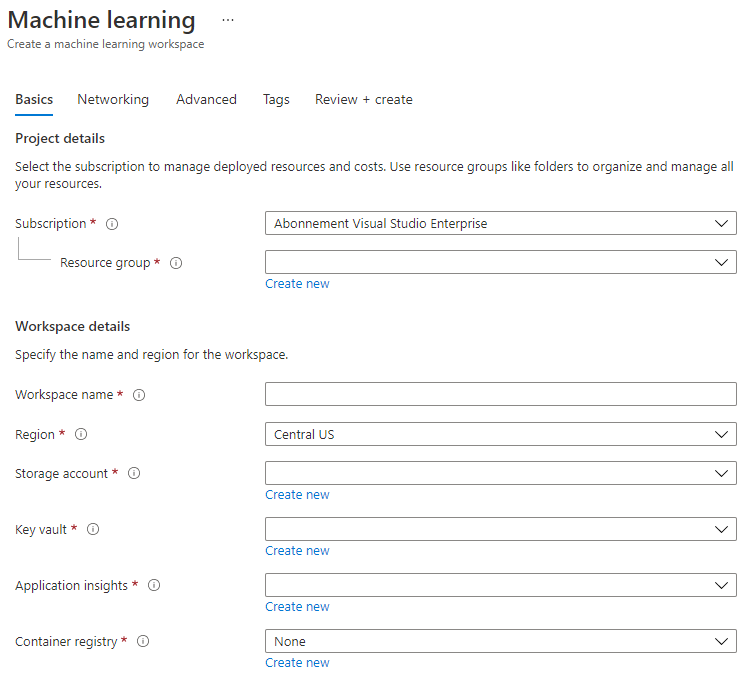
- Kliknite gumb za pregled in ustvarjanje ter nato gumb za ustvarjanje
-
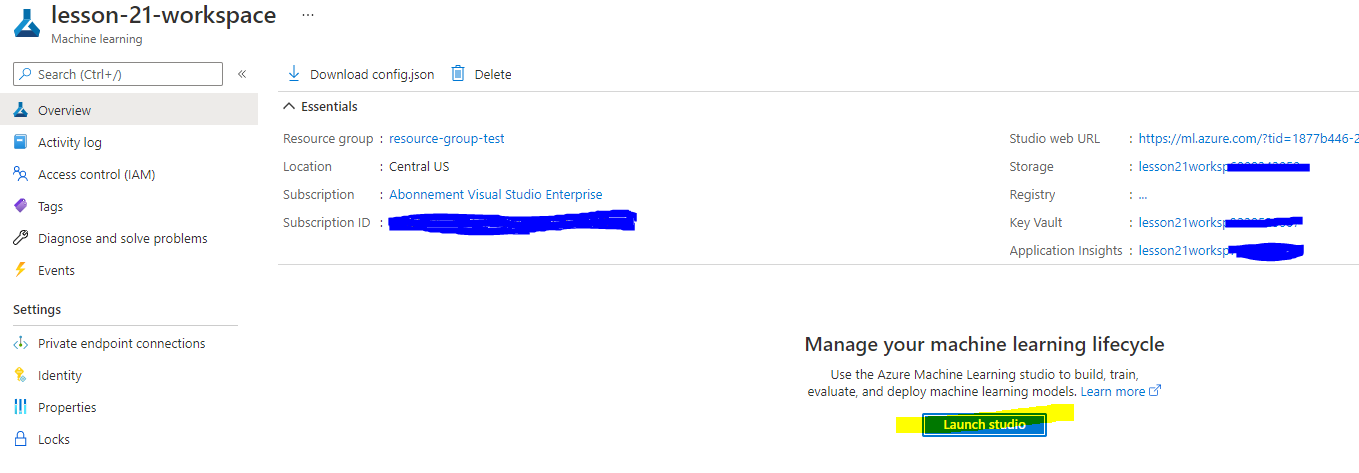
Počakajte, da se vaš delovni prostor ustvari (to lahko traja nekaj minut). Nato pojdite nanj v portalu. Najdete ga lahko prek storitve Machine Learning Azure.
-
Na strani Pregled za vaš delovni prostor zaženite Azure Machine Learning studio (ali odprite nov zavihek brskalnika in pojdite na https://ml.azure.com), ter se prijavite v Azure Machine Learning studio z vašim Microsoft računom. Če ste pozvani, izberite vaš Azure imenik in naročnino ter vaš delovni prostor Azure Machine Learning.
- V Azure Machine Learning studio preklopite ikono ☰ na vrhu levo, da si ogledate različne strani v vmesniku. Te strani lahko uporabite za upravljanje virov v vašem delovnem prostoru.
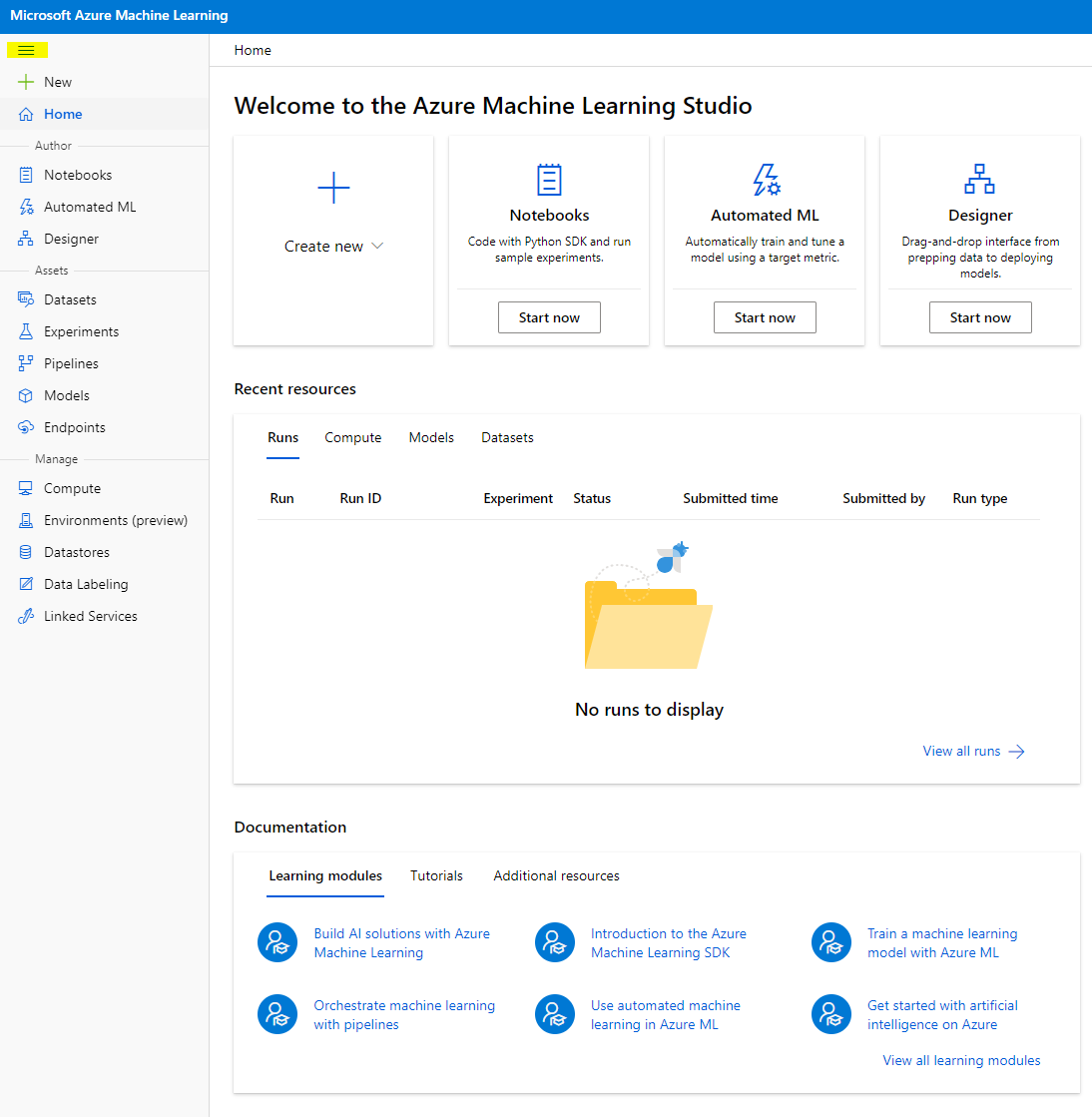
Delovni prostor lahko upravljate z Azure portalom, vendar za podatkovne znanstvenike in inženirje operacij strojnega učenja Azure Machine Learning Studio ponuja bolj osredotočen uporabniški vmesnik za upravljanje virov delovnega prostora.
2.2 Računalniški viri
Računalniški viri so oblačni viri, na katerih lahko izvajate procese usposabljanja modelov in raziskovanja podatkov. Obstajajo štiri vrste računalniških virov, ki jih lahko ustvarite:
- Računalniški primerki: Razvojne delovne postaje, ki jih podatkovni znanstveniki lahko uporabljajo za delo s podatki in modeli. To vključuje ustvarjanje virtualnega računalnika (VM) in zagon primerka beležke. Nato lahko model usposobite z uporabo računalniškega grozda iz beležke.
- Računalniški grozdi: Prilagodljivi grozdi VM za obdelavo eksperimentne kode na zahtevo. Potrebovali jih boste pri usposabljanju modela. Računalniški grozdi lahko uporabljajo tudi specializirane GPU ali CPU vire.
- Grozd za sklepanje: Cilji za namestitev napovednih storitev, ki uporabljajo vaše usposobljene modele.
- Priključeni računalniški viri: Povezave do obstoječih Azure računalniških virov, kot so virtualni stroji ali Azure Databricks grozdi.
2.2.1 Izbira pravih možnosti za vaše računalniške vire
Pri ustvarjanju računalniškega vira je treba upoštevati nekaj ključnih dejavnikov, saj so te odločitve lahko ključne.
Ali potrebujete CPU ali GPU?
CPU (Centralna procesna enota) je elektronsko vezje, ki izvaja ukaze računalniškega programa. GPU (Grafična procesna enota) je specializirano elektronsko vezje, ki lahko izvaja grafično povezano kodo z zelo visoko hitrostjo.
Glavna razlika med arhitekturo CPU in GPU je, da je CPU zasnovan za hitro obdelavo širokega spektra nalog (merjeno s hitrostjo ure CPU), vendar je omejen pri sočasnem izvajanju nalog. GPU-ji so zasnovani za paralelno računalništvo in so zato veliko boljši pri nalogah globokega učenja.
| CPU | GPU |
|---|---|
| Manj drago | Bolj drago |
| Nižja stopnja sočasnosti | Višja stopnja sočasnosti |
| Počasnejše pri treniranju modelov | Optimalno za globoko učenje |
Velikost grozda
Večji grozdi so dražji, vendar zagotavljajo boljšo odzivnost. Če imate čas, vendar omejena sredstva, začnite z majhnim grozdom. Če imate sredstva, vendar malo časa, začnite z večjim grozdom.
Velikost VM
Glede na vaše časovne in proračunske omejitve lahko prilagodite velikost RAM-a, diska, število jeder in hitrost ure. Povečanje teh parametrov bo dražje, vendar bo prineslo boljšo zmogljivost.
Namenske ali nizkoprioritetne instance?
Nizkoprioritetna instanca pomeni, da je prekinljiva: Microsoft Azure lahko te vire dodeli drugi nalogi, kar prekine trenutno opravilo. Namenska instanca, ki ni prekinljiva, pomeni, da opravilo ne bo nikoli prekinjeno brez vašega dovoljenja. To je še ena odločitev med časom in denarjem, saj so prekinljive instance cenejše od namenskih.
2.2.2 Ustvarjanje računalniškega grozda
V Azure ML delovnem prostoru, ki smo ga ustvarili prej, pojdite na "Compute" in videli boste različne računalniške vire, o katerih smo pravkar razpravljali (tj. računalniške instance, računalniške grozde, grozde za sklepanje in priključene računalniške vire). Za ta projekt bomo potrebovali računalniški grozd za treniranje modela. V Studio kliknite na meni "Compute", nato na zavihek "Compute cluster" in kliknite na gumb "+ New" za ustvarjanje računalniškega grozda.
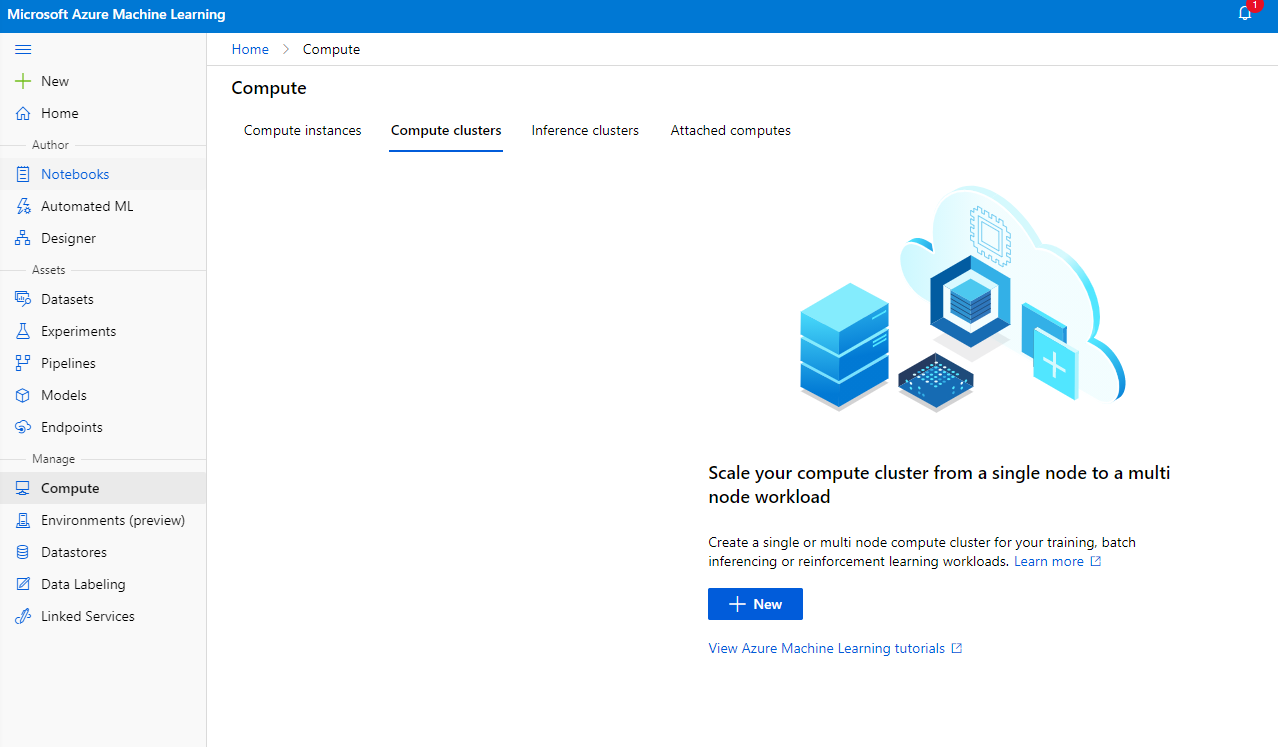
- Izberite svoje možnosti: Namensko ali nizkoprioritetno, CPU ali GPU, velikost VM in število jeder (za ta projekt lahko obdržite privzete nastavitve).
- Kliknite na gumb "Next".
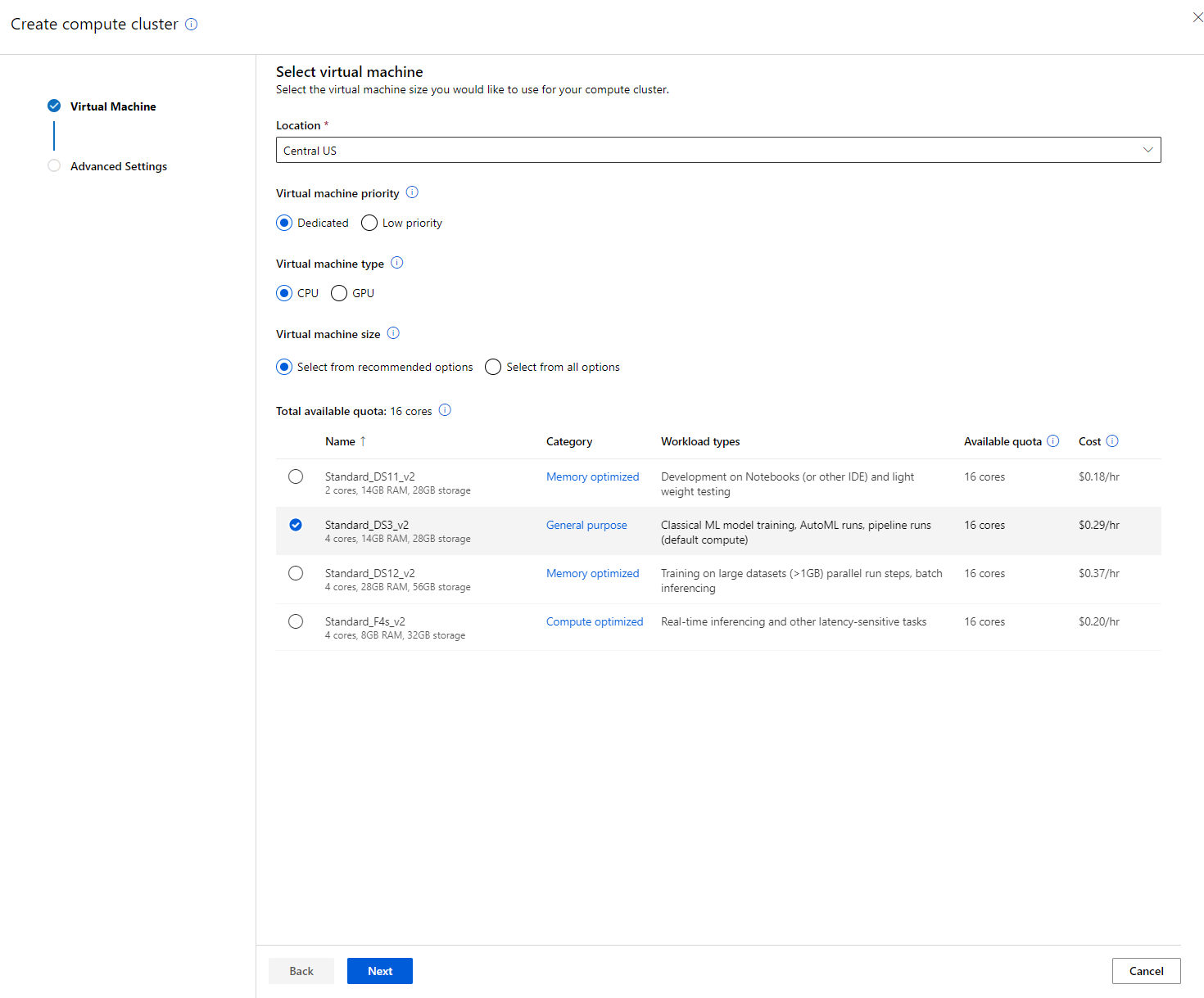
- Dajte grozdu ime.
- Izberite svoje možnosti: Minimalno/maksimalno število vozlišč, število sekund neaktivnosti pred zmanjšanjem obsega, SSH dostop. Upoštevajte, da če je minimalno število vozlišč 0, boste prihranili denar, ko je grozd neaktiven. Upoštevajte, da večje število maksimalnih vozlišč pomeni krajši čas treniranja. Priporočeno maksimalno število vozlišč je 3.
- Kliknite na gumb "Create". Ta korak lahko traja nekaj minut.
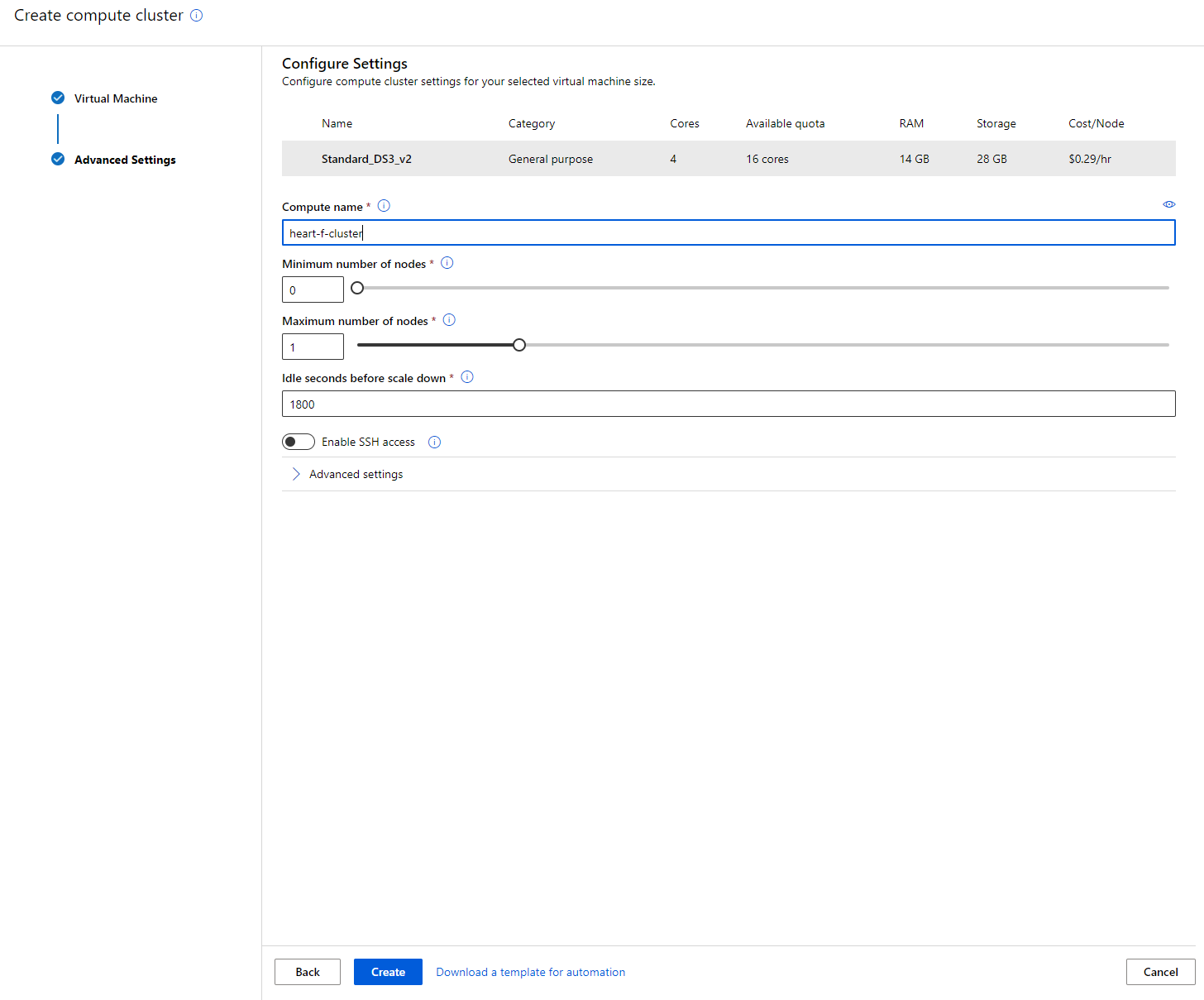
Odlično! Zdaj, ko imamo računalniški grozd, moramo naložiti podatke v Azure ML Studio.
2.3 Nalaganje podatkovne zbirke
-
V Azure ML delovnem prostoru, ki smo ga ustvarili prej, kliknite na "Datasets" v levem meniju in kliknite na gumb "+ Create dataset" za ustvarjanje podatkovne zbirke. Izberite možnost "From local files" in izberite Kaggle podatkovno zbirko, ki smo jo prej prenesli.
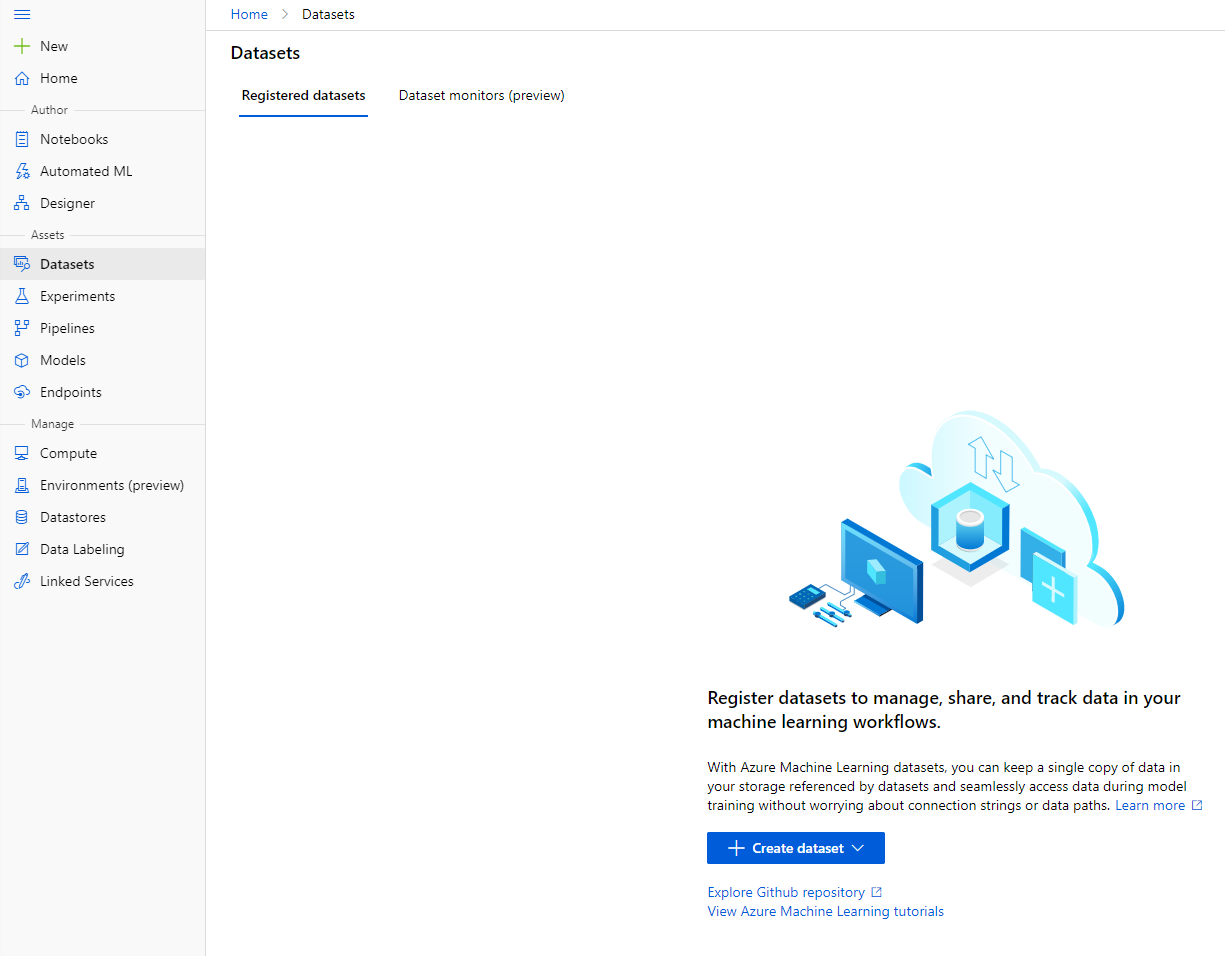
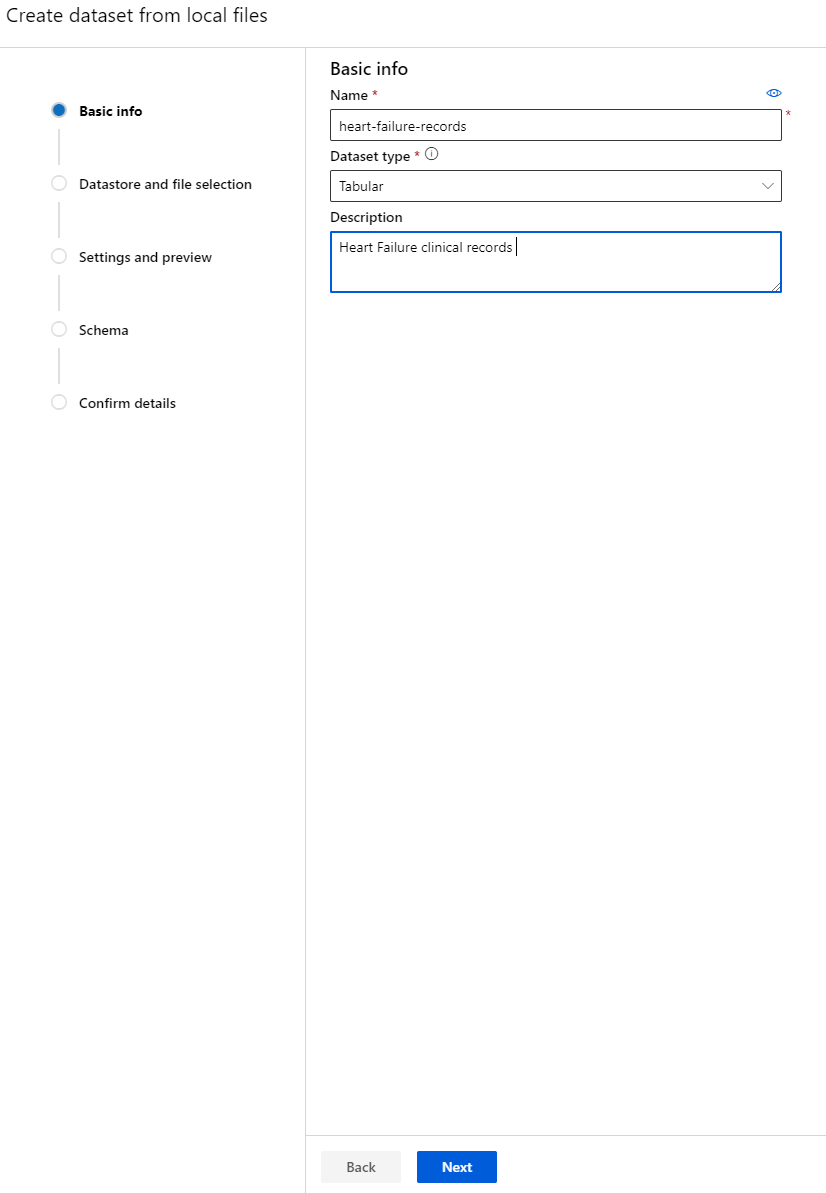
-
Dajte podatkovni zbirki ime, vrsto in opis. Kliknite "Next". Naložite podatke iz datotek. Kliknite "Next".
-
V shemi spremenite vrsto podatkov v Boolean za naslednje značilnosti: anemija, diabetes, visok krvni tlak, spol, kajenje in DEATH_EVENT. Kliknite "Next" in nato "Create".
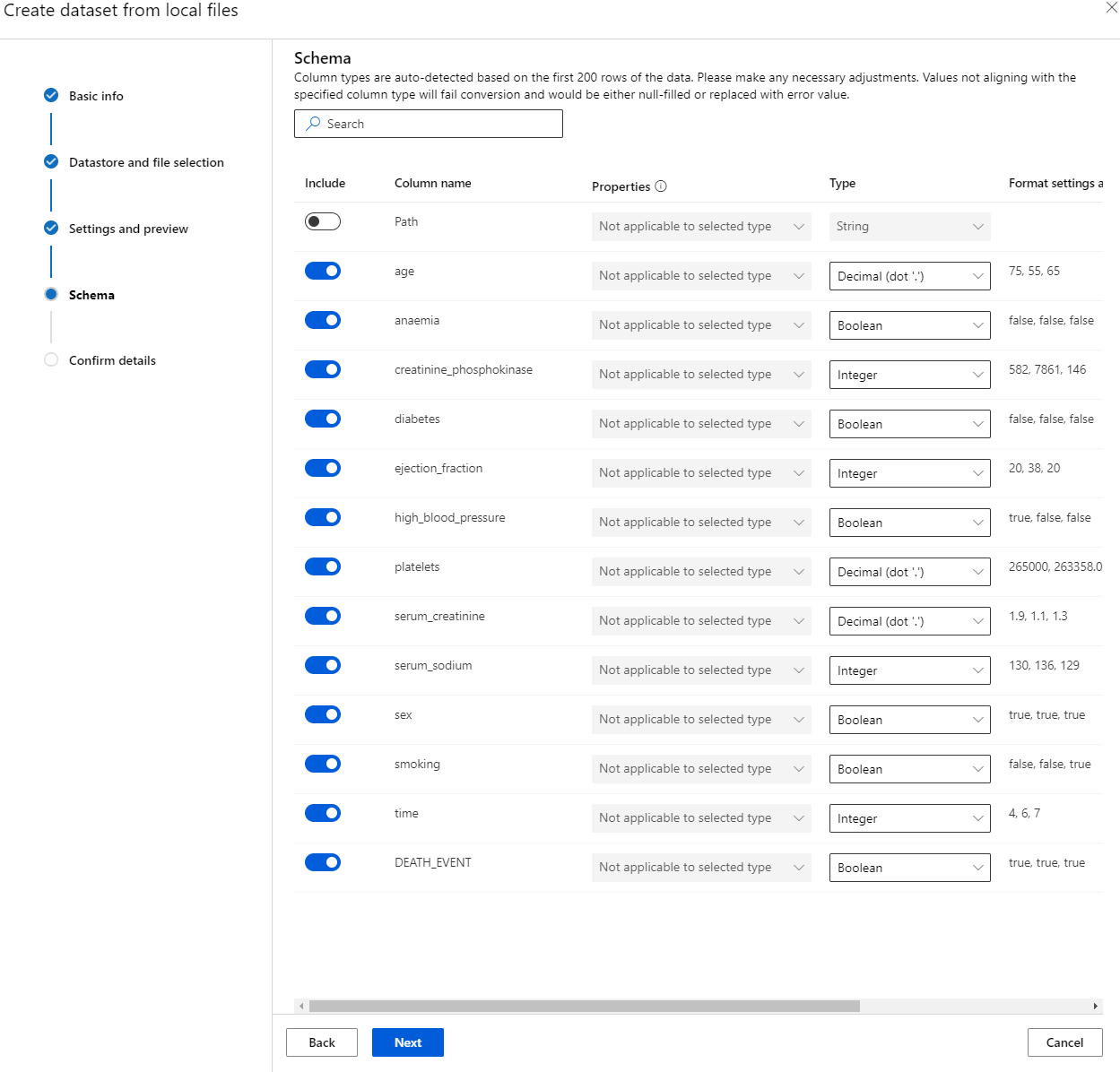
Odlično! Zdaj, ko je podatkovna zbirka na mestu in je računalniški grozd ustvarjen, lahko začnemo treniranje modela!
2.4 Treniranje z malo ali brez kode z AutoML
Tradicionalni razvoj modelov strojnega učenja je zahteven, zahteva veliko domenskega znanja in časa za izdelavo ter primerjavo več modelov. Avtomatizirano strojno učenje (AutoML) je proces avtomatizacije časovno zahtevnih, ponavljajočih se nalog razvoja modelov strojnega učenja. Omogoča podatkovnim znanstvenikom, analitikom in razvijalcem, da gradijo modele strojnega učenja z visoko učinkovitostjo in produktivnostjo, hkrati pa ohranjajo kakovost modelov. Zmanjšuje čas, potreben za pridobitev modelov, pripravljenih za produkcijo, z veliko lahkoto in učinkovitostjo. Več o tem
-
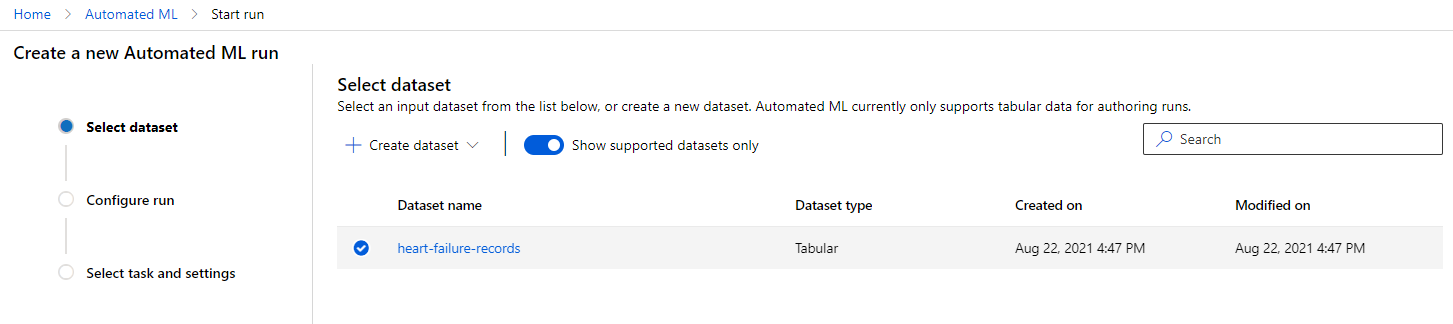
V Azure ML delovnem prostoru, ki smo ga ustvarili prej, kliknite na "Automated ML" v levem meniju in izberite podatkovno zbirko, ki ste jo pravkar naložili. Kliknite "Next".
-
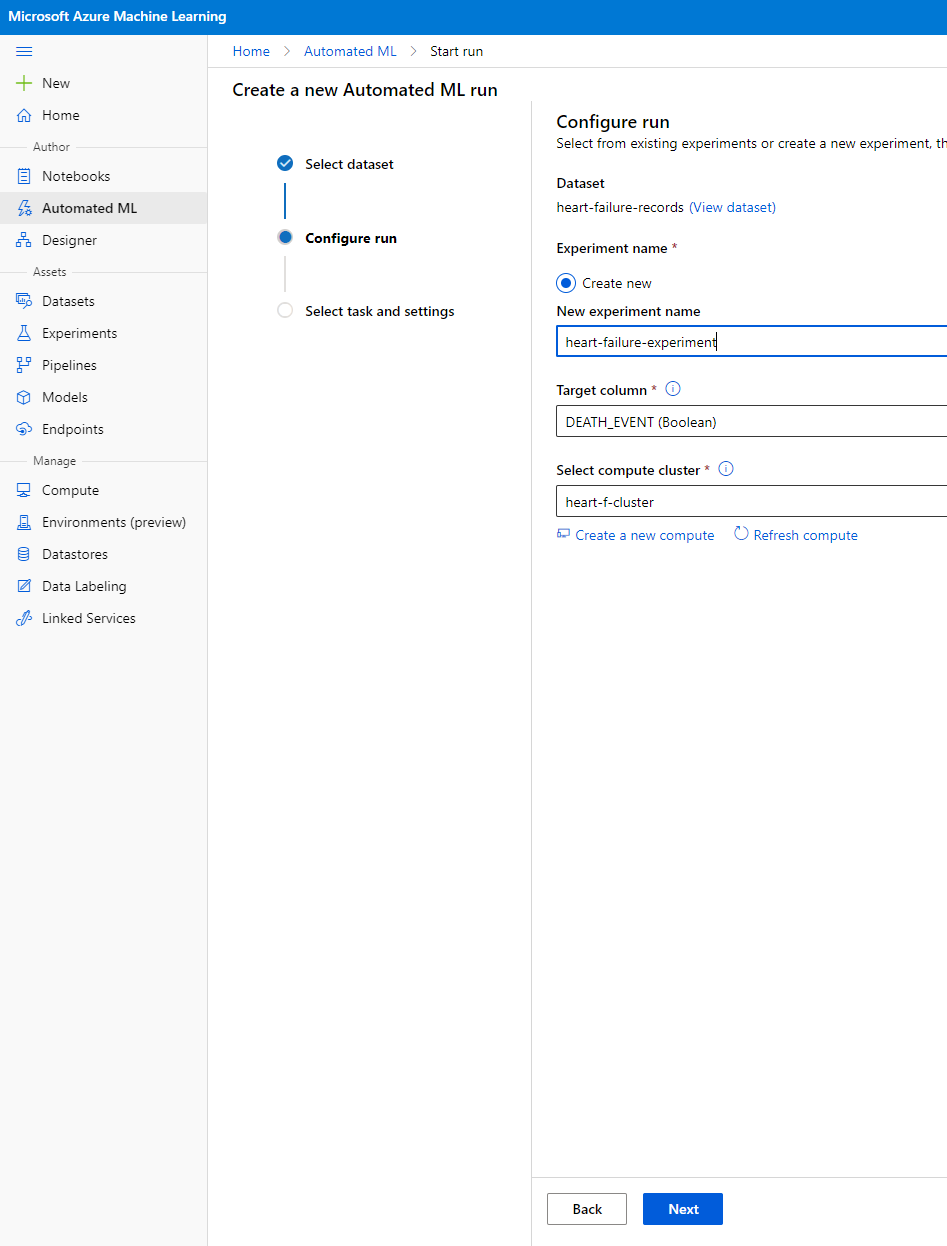
Vnesite ime novega eksperimenta, ciljni stolpec (DEATH_EVENT) in računalniški grozd, ki smo ga ustvarili. Kliknite "Next".
-
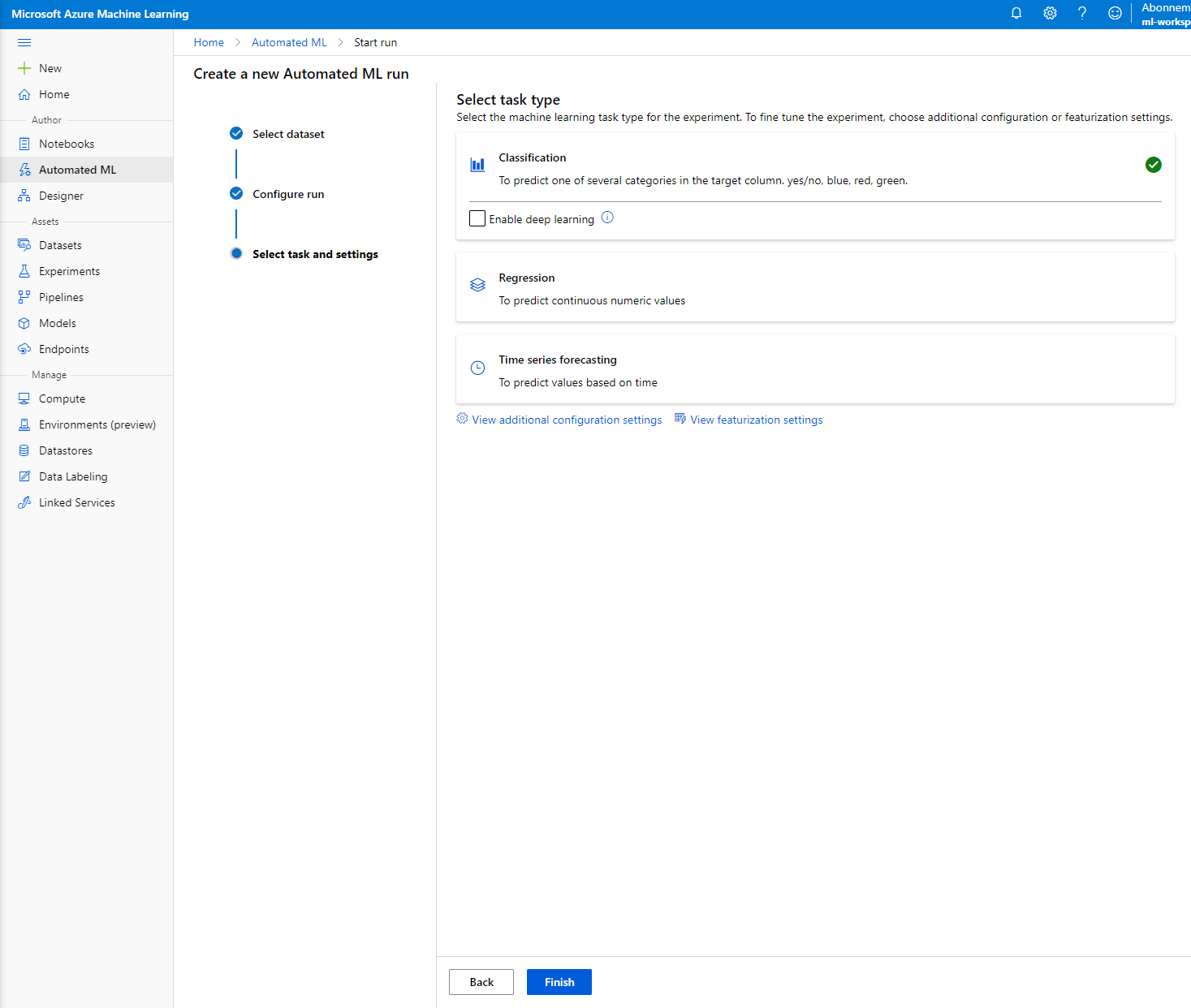
Izberite "Classification" in kliknite "Finish". Ta korak lahko traja med 30 minutami in 1 uro, odvisno od velikosti vašega računalniškega grozda.
-
Ko je izvajanje končano, kliknite na zavihek "Automated ML", kliknite na svoj izvajanje in nato na algoritem v kartici "Best model summary".
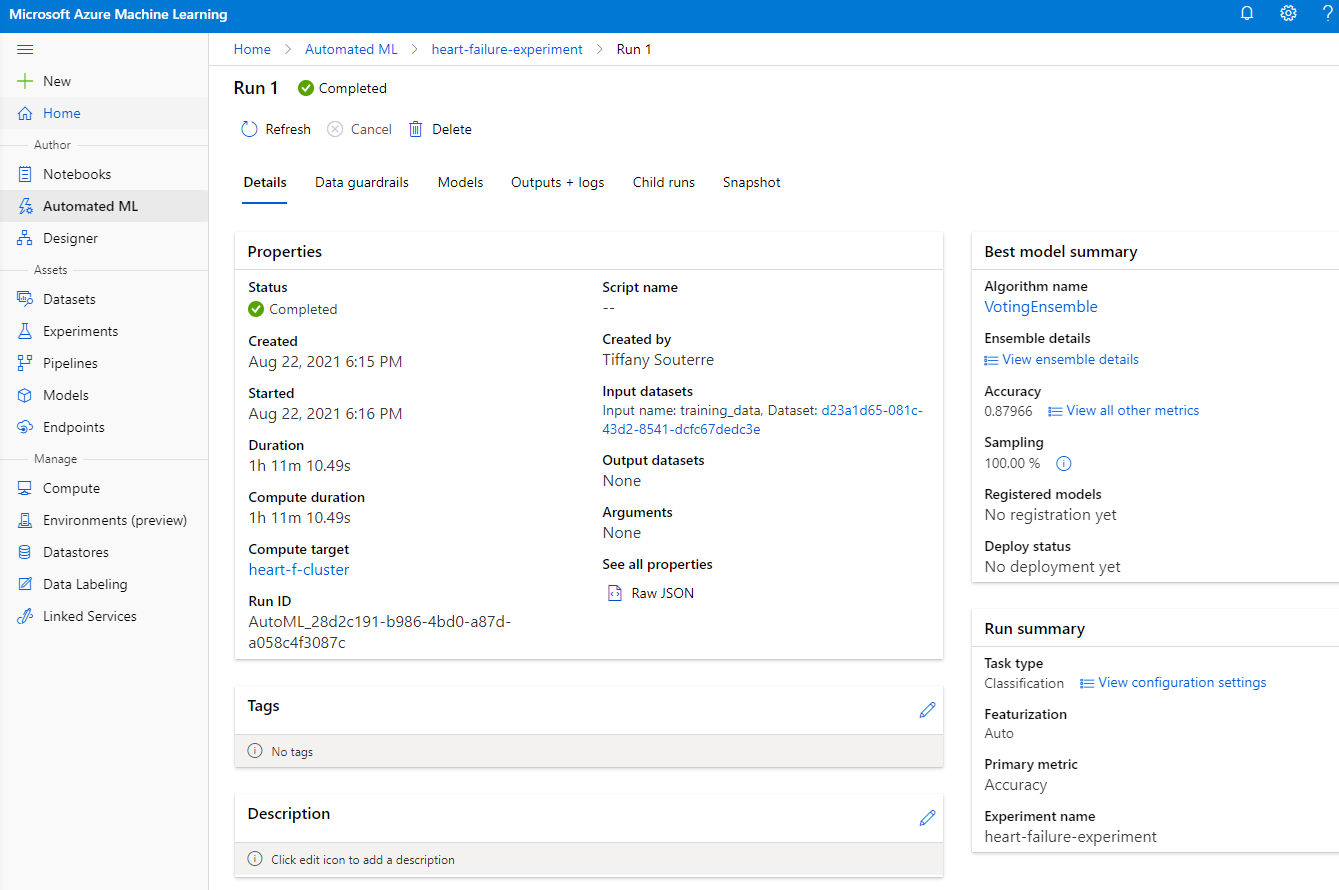
Tukaj lahko vidite podroben opis najboljšega modela, ki ga je AutoML ustvaril. Prav tako lahko raziščete druge modele v zavihku "Models". Vzemite si nekaj minut za raziskovanje modelov v razlagah (gumb za predogled). Ko izberete model, ki ga želite uporabiti (tukaj bomo izbrali najboljši model, ki ga je izbral AutoML), bomo videli, kako ga lahko namestimo.
3. Namestitev modela z malo ali brez kode in uporaba končne točke
3.1 Namestitev modela
Vmesnik avtomatiziranega strojnega učenja omogoča namestitev najboljšega modela kot spletne storitve v nekaj korakih. Namestitev je integracija modela, da lahko na podlagi novih podatkov napoveduje in identificira potencialna področja priložnosti. Za ta projekt namestitev v spletno storitev pomeni, da bodo medicinske aplikacije lahko uporabljale model za napovedovanje tveganja srčnega napada pri svojih pacientih.
V opisu najboljšega modela kliknite na gumb "Deploy".
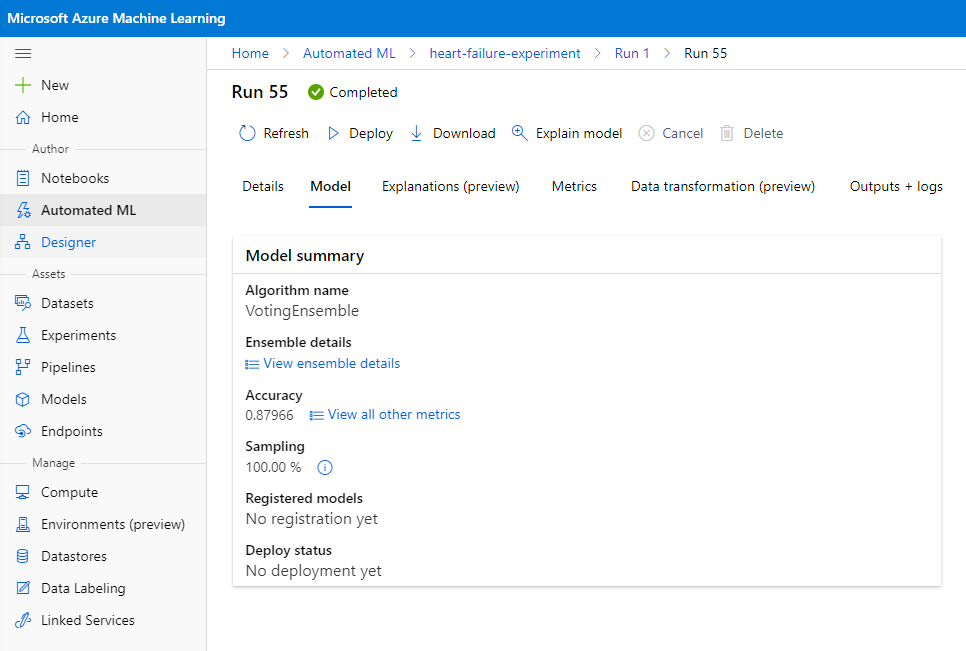
- Dajte mu ime, opis, vrsto računalnika (Azure Container Instance), omogočite avtentikacijo in kliknite na "Deploy". Ta korak lahko traja približno 20 minut. Proces namestitve vključuje več korakov, vključno z registracijo modela, ustvarjanjem virov in njihovo konfiguracijo za spletno storitev. Statusna sporočila se pojavijo pod "Deploy status". Občasno kliknite "Refresh", da preverite status namestitve. Ko je status "Healthy", je model nameščen in deluje.
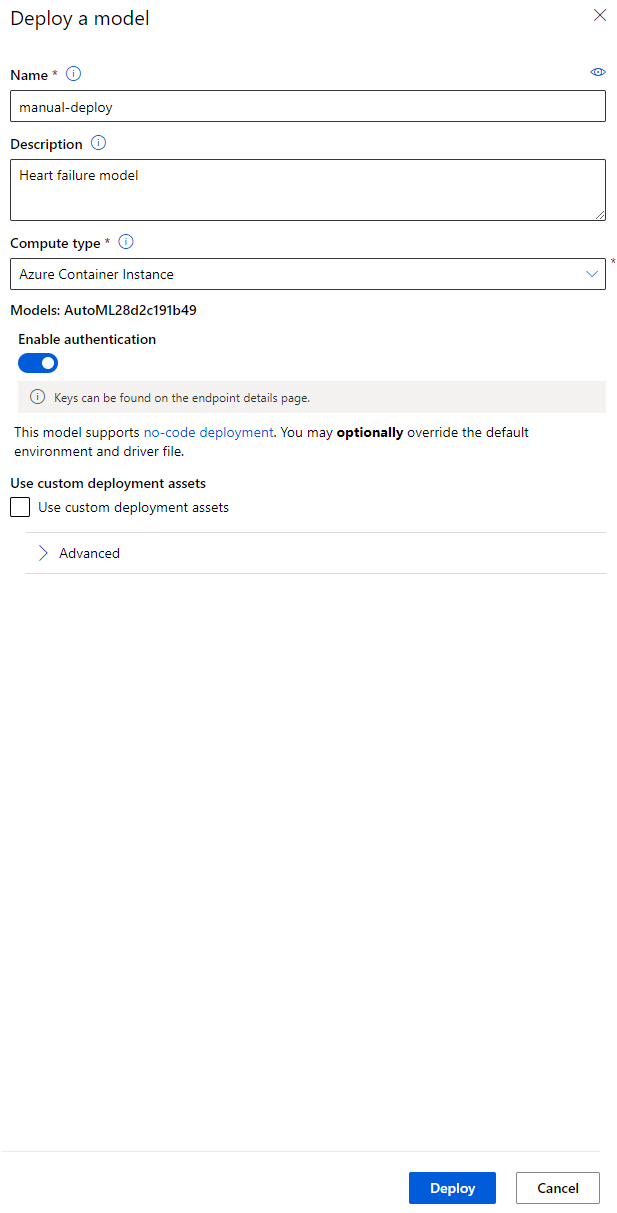
- Ko je nameščen, kliknite na zavihek "Endpoint" in nato na končno točko, ki ste jo pravkar namestili. Tukaj lahko najdete vse podrobnosti o končni točki.
Odlično! Zdaj, ko imamo nameščen model, lahko začnemo z uporabo končne točke.
3.2 Uporaba končne točke
Kliknite na zavihek "Consume". Tukaj lahko najdete REST končno točko in Python skripto v možnosti uporabe. Vzemite si čas za pregled Python kode.
Ta skripta se lahko zažene neposredno z vašega lokalnega računalnika in bo uporabila vašo končno točko.
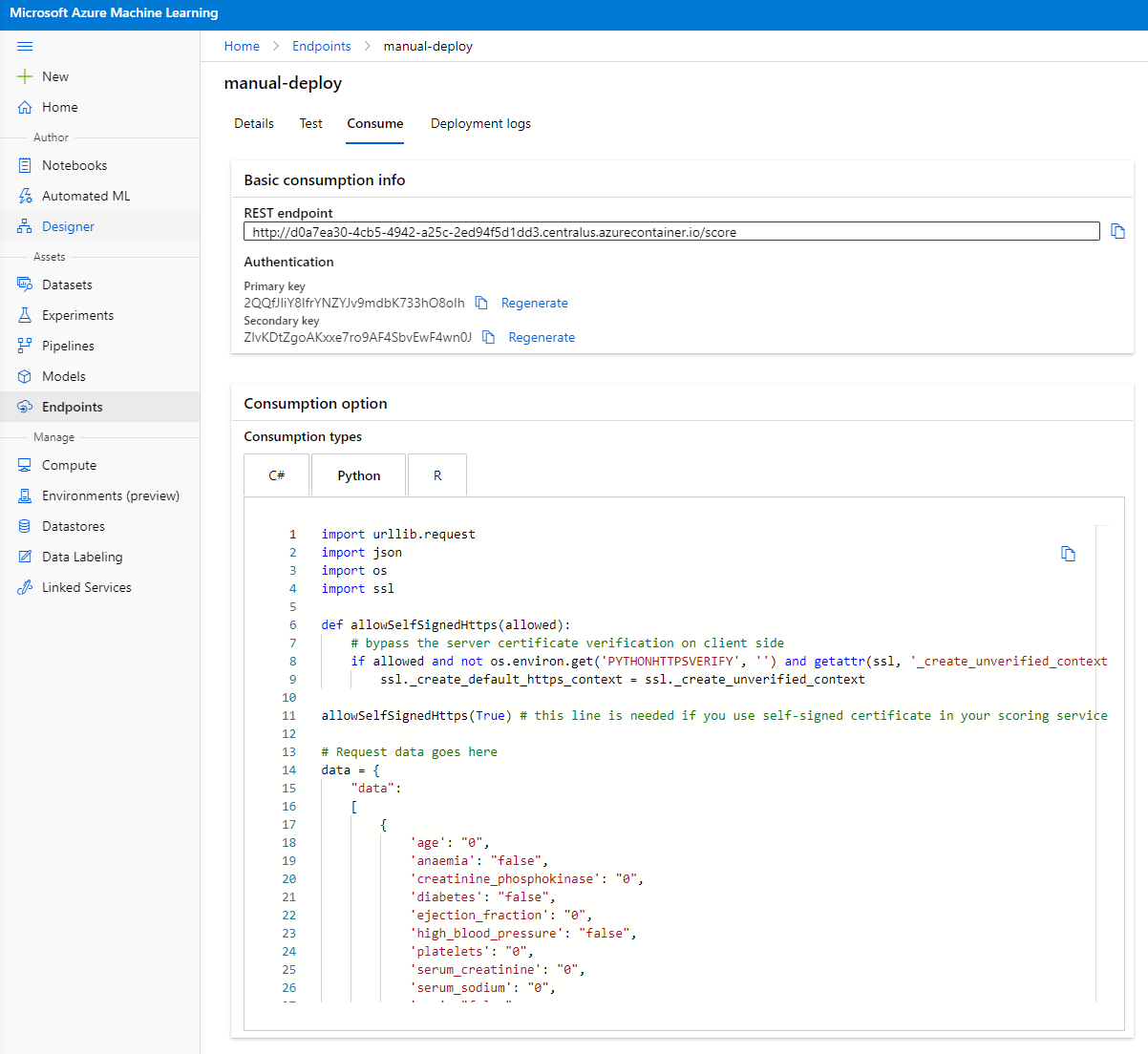
Vzemite si trenutek za pregled teh dveh vrstic kode:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
Spremenljivka url je REST končna točka, ki jo najdete v zavihku "Consume", in spremenljivka api_key je primarni ključ, ki ga prav tako najdete v zavihku "Consume" (samo v primeru, da ste omogočili avtentikacijo). Tako skripta lahko uporabi končno točko.
- Ko zaženete skripto, bi morali videti naslednji izhod:
b'"{\\"result\\": [true]}"'
To pomeni, da je napoved srčnega popuščanja za dane podatke resnična. To je smiselno, saj če podrobneje pogledate podatke, ki jih je skripta samodejno ustvarila, je vse privzeto nastavljeno na 0 in napačno. Podatke lahko spremenite z naslednjim vzorcem vnosa:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
Skripta bi morala vrniti:
python b'"{\\"result\\": [true, false]}"'
Čestitke! Pravkar ste uporabili nameščen model in ga trenirali na Azure ML!
OPOMBA: Ko končate projekt, ne pozabite izbrisati vseh virov.
🚀 Izziv
Podrobno preglejte razlage modelov in podrobnosti, ki jih je AutoML ustvaril za najboljše modele. Poskusite razumeti, zakaj je najboljši model boljši od drugih. Kateri algoritmi so bili primerjani? Kakšne so razlike med njimi? Zakaj je najboljši model v tem primeru boljši?
Kvizi po predavanju
Pregled in samostojno učenje
V tej lekciji ste se naučili, kako trenirati, namestiti in uporabiti model za napovedovanje tveganja srčnega popuščanja na način z malo ali brez kode v oblaku. Če tega še niste storili, se poglobite v razlage modelov, ki jih je AutoML ustvaril za najboljše modele, in poskusite razumeti, zakaj je najboljši model boljši od drugih.
Lahko se poglobite v AutoML z malo ali brez kode z branjem te dokumentacije.
Naloga
Projekt podatkovne znanosti z malo ali brez kode na Azure ML
Omejitev odgovornosti:
Ta dokument je bil preveden z uporabo storitve za prevajanje z umetno inteligenco Co-op Translator. Čeprav si prizadevamo za natančnost, vas prosimo, da upoštevate, da lahko avtomatizirani prevodi vsebujejo napake ali netočnosti. Izvirni dokument v njegovem maternem jeziku je treba obravnavati kot avtoritativni vir. Za ključne informacije priporočamo profesionalni človeški prevod. Ne prevzemamo odgovornosti za morebitna nesporazumevanja ali napačne razlage, ki bi nastale zaradi uporabe tega prevoda.