16 KiB
Visualiseren van hoeveelheden
 |
|---|
| Visualiseren van hoeveelheden - Sketchnote door @nitya |
In deze les leer je hoe je enkele van de vele beschikbare R-pakketten kunt gebruiken om interessante visualisaties te maken rondom het concept van hoeveelheden. Met behulp van een opgeschoonde dataset over de vogels van Minnesota kun je veel interessante feiten ontdekken over de lokale fauna.
Quiz voorafgaand aan de les
Observeer vleugelspanwijdte met ggplot2
Een uitstekende bibliotheek om zowel eenvoudige als geavanceerde grafieken en diagrammen te maken is ggplot2. Over het algemeen omvat het proces van het plotten van gegevens met deze bibliotheken het identificeren van de delen van je dataframe die je wilt gebruiken, het uitvoeren van eventuele noodzakelijke transformaties op die gegevens, het toewijzen van x- en y-aswaarden, het kiezen van het type plot, en vervolgens het weergeven van de plot.
ggplot2 is een systeem voor het declaratief maken van grafieken, gebaseerd op The Grammar of Graphics. De Grammar of Graphics is een algemeen schema voor datavisualisatie dat grafieken opdeelt in semantische componenten zoals schalen en lagen. Met andere woorden, de eenvoud waarmee je grafieken kunt maken voor univariate of multivariate gegevens met weinig code maakt ggplot2 het populairste pakket voor visualisaties in R. De gebruiker vertelt ggplot2 hoe de variabelen aan esthetiek moeten worden gekoppeld, welke grafische primitieve moet worden gebruikt, en ggplot2 regelt de rest.
✅ Plot = Data + Esthetiek + Geometrie
- Data verwijst naar de dataset
- Esthetiek geeft de variabelen aan die worden bestudeerd (x- en y-variabelen)
- Geometrie verwijst naar het type plot (lijnplot, staafdiagram, enz.)
Kies de beste geometrie (type plot) afhankelijk van je gegevens en het verhaal dat je wilt vertellen met de plot.
- Om trends te analyseren: lijn, kolom
- Om waarden te vergelijken: staaf, kolom, taartdiagram, spreidingsdiagram
- Om te laten zien hoe delen zich verhouden tot een geheel: taartdiagram
- Om de verdeling van gegevens te tonen: spreidingsdiagram, staafdiagram
- Om relaties tussen waarden te tonen: lijn, spreidingsdiagram, bubbel
✅ Bekijk ook deze beschrijvende cheatsheet voor ggplot2.
Maak een lijnplot over vleugelspanwijdte van vogels
Open de R-console en importeer de dataset.
Opmerking: De dataset is opgeslagen in de root van deze repo in de
/datamap.
Laten we de dataset importeren en de head (bovenste 5 rijen) van de gegevens bekijken.
birds <- read.csv("../../data/birds.csv",fileEncoding="UTF-8-BOM")
head(birds)
De head van de gegevens bevat een mix van tekst en cijfers:
| Naam | WetenschappelijkeNaam | Categorie | Orde | Familie | Geslacht | Beschermingsstatus | MinLengte | MaxLengte | MinLichaamsgewicht | MaxLichaamsgewicht | MinVleugelspan | MaxVleugelspan | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Zwartbuikfluiteend | Dendrocygna autumnalis | Eenden/Ganzen/Watervogels | Anseriformes | Anatidae | Dendrocygna | LC | 47 | 56 | 652 | 1020 | 76 | 94 |
| 1 | Bruine fluiteend | Dendrocygna bicolor | Eenden/Ganzen/Watervogels | Anseriformes | Anatidae | Dendrocygna | LC | 45 | 53 | 712 | 1050 | 85 | 93 |
| 2 | Sneeuwgans | Anser caerulescens | Eenden/Ganzen/Watervogels | Anseriformes | Anatidae | Anser | LC | 64 | 79 | 2050 | 4050 | 135 | 165 |
| 3 | Ross' gans | Anser rossii | Eenden/Ganzen/Watervogels | Anseriformes | Anatidae | Anser | LC | 57.3 | 64 | 1066 | 1567 | 113 | 116 |
| 4 | Grote rietgans | Anser albifrons | Eenden/Ganzen/Watervogels | Anseriformes | Anatidae | Anser | LC | 64 | 81 | 1930 | 3310 | 130 | 165 |
Laten we beginnen met het plotten van enkele numerieke gegevens met een eenvoudige lijnplot. Stel dat je een overzicht wilt van de maximale vleugelspanwijdte van deze interessante vogels.
install.packages("ggplot2")
library("ggplot2")
ggplot(data=birds, aes(x=Name, y=MaxWingspan,group=1)) +
geom_line()
Hier installeer je het ggplot2 pakket en importeer je het vervolgens in de werkruimte met het commando library("ggplot2"). Om een plot te maken in ggplot, gebruik je de functie ggplot() en specificeer je de dataset, x- en y-variabelen als attributen. In dit geval gebruiken we de functie geom_line() omdat we een lijnplot willen maken.
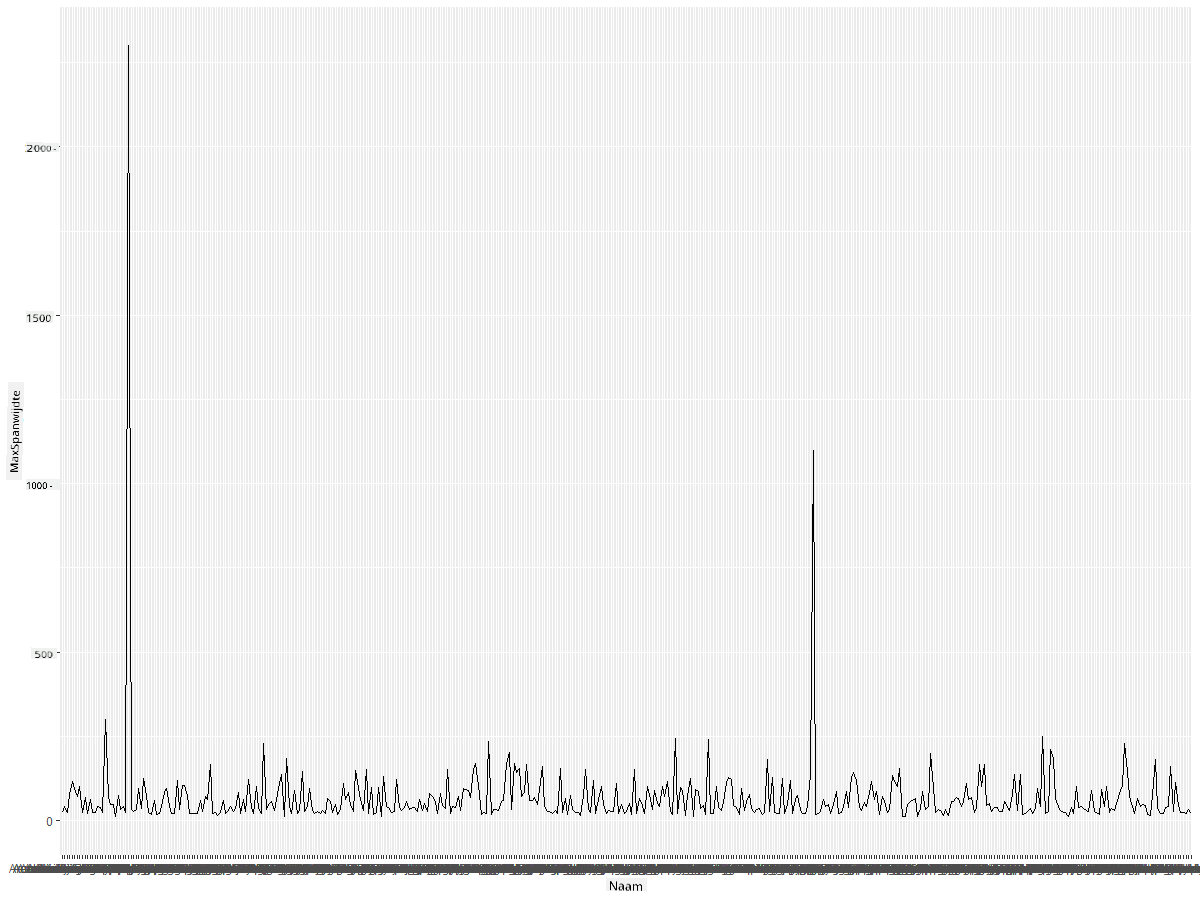
Wat valt je meteen op? Er lijkt minstens één uitschieter te zijn - dat is een behoorlijke vleugelspanwijdte! Een vleugelspanwijdte van meer dan 2000 centimeter komt overeen met meer dan 20 meter - zijn er Pterodactylen in Minnesota? Laten we dit onderzoeken.
Hoewel je snel zou kunnen sorteren in Excel om die uitschieters te vinden, die waarschijnlijk typfouten zijn, gaan we verder met het visualisatieproces vanuit de plot.
Voeg labels toe aan de x-as om te laten zien om welke soorten vogels het gaat:
ggplot(data=birds, aes(x=Name, y=MaxWingspan,group=1)) +
geom_line() +
theme(axis.text.x = element_text(angle = 45, hjust=1))+
xlab("Birds") +
ylab("Wingspan (CM)") +
ggtitle("Max Wingspan in Centimeters")
We specificeren de hoek in het theme en geven de x- en y-as labels met xlab() en ylab() respectievelijk. De ggtitle() geeft een naam aan de grafiek/plot.
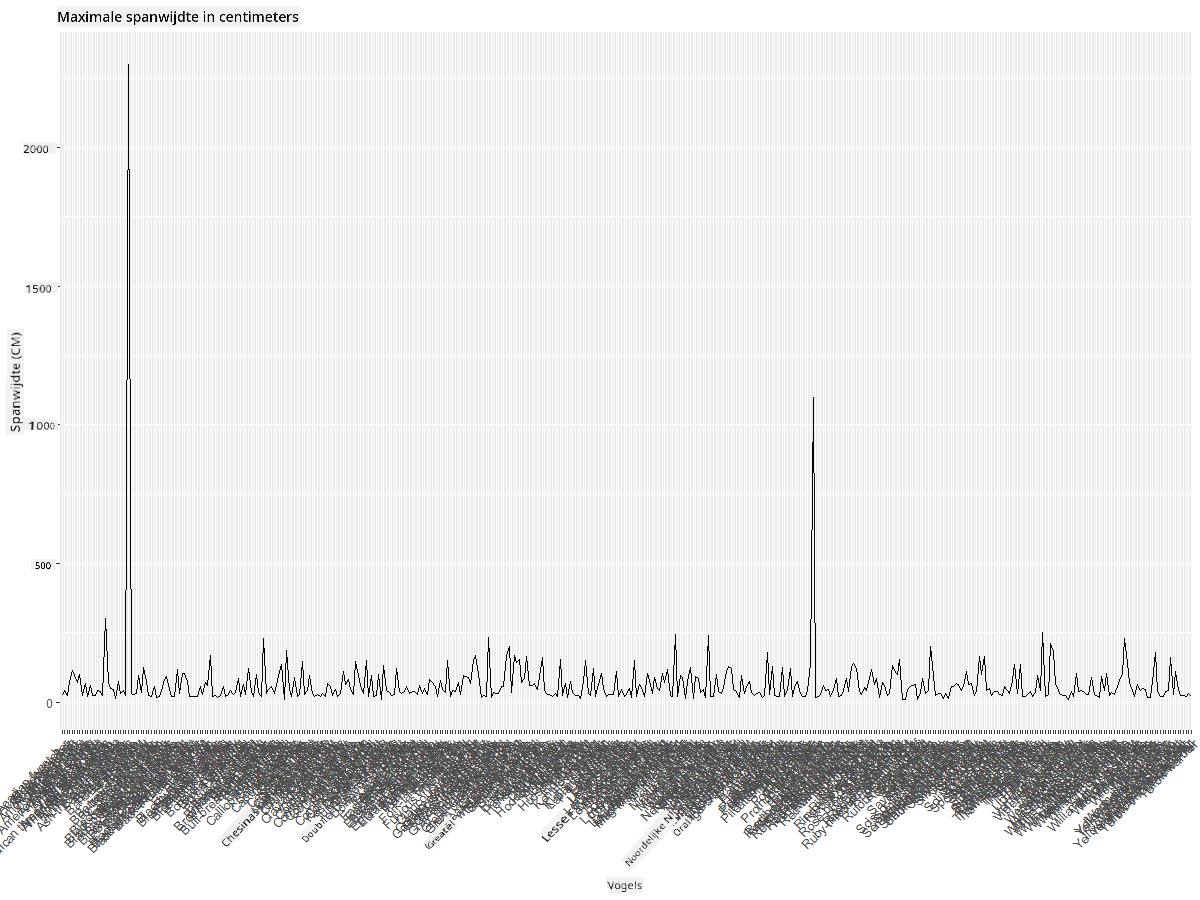
Zelfs met de rotatie van de labels ingesteld op 45 graden, zijn er te veel om te lezen. Laten we een andere strategie proberen: label alleen die uitschieters en plaats de labels binnen de grafiek. Je kunt een spreidingsdiagram gebruiken om meer ruimte te maken voor de labeling:
ggplot(data=birds, aes(x=Name, y=MaxWingspan,group=1)) +
geom_point() +
geom_text(aes(label=ifelse(MaxWingspan>500,as.character(Name),'')),hjust=0,vjust=0) +
theme(axis.title.x=element_blank(), axis.text.x=element_blank(), axis.ticks.x=element_blank())
ylab("Wingspan (CM)") +
ggtitle("Max Wingspan in Centimeters") +
Wat gebeurt hier? Je hebt de functie geom_point() gebruikt om spreidingspunten te plotten. Hiermee heb je labels toegevoegd voor vogels met een MaxWingspan > 500 en ook de labels op de x-as verborgen om de plot overzichtelijker te maken.
Wat ontdek je?
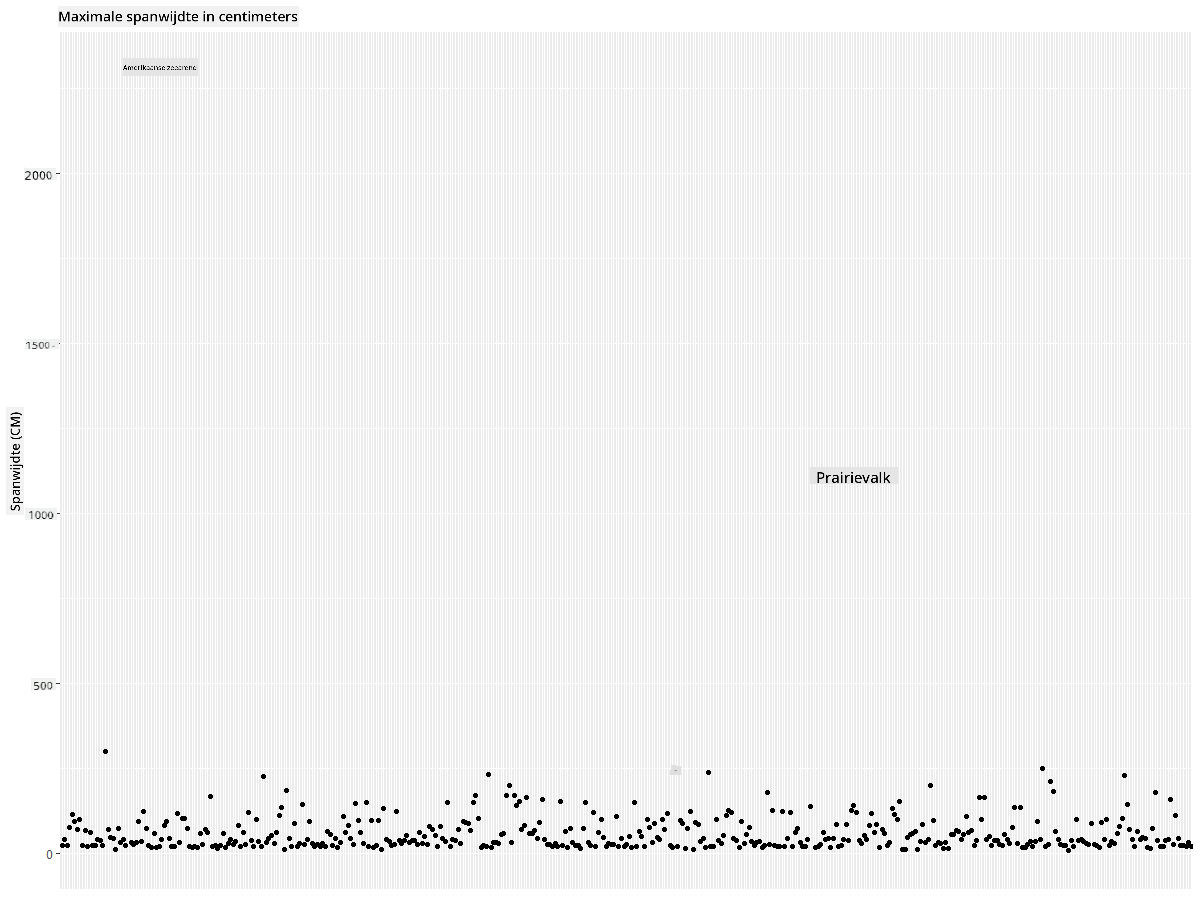
Filter je gegevens
Zowel de Amerikaanse zeearend als de Prairievalk lijken, hoewel waarschijnlijk zeer grote vogels, verkeerd gelabeld te zijn, met een extra 0 toegevoegd aan hun maximale vleugelspanwijdte. Het is onwaarschijnlijk dat je een Amerikaanse zeearend tegenkomt met een vleugelspanwijdte van 25 meter, maar als dat zo is, laat het ons dan weten! Laten we een nieuwe dataframe maken zonder die twee uitschieters:
birds_filtered <- subset(birds, MaxWingspan < 500)
ggplot(data=birds_filtered, aes(x=Name, y=MaxWingspan,group=1)) +
geom_point() +
ylab("Wingspan (CM)") +
xlab("Birds") +
ggtitle("Max Wingspan in Centimeters") +
geom_text(aes(label=ifelse(MaxWingspan>500,as.character(Name),'')),hjust=0,vjust=0) +
theme(axis.text.x=element_blank(), axis.ticks.x=element_blank())
We hebben een nieuwe dataframe birds_filtered gemaakt en vervolgens een spreidingsdiagram geplot. Door uitschieters te filteren, zijn je gegevens nu meer samenhangend en begrijpelijk.
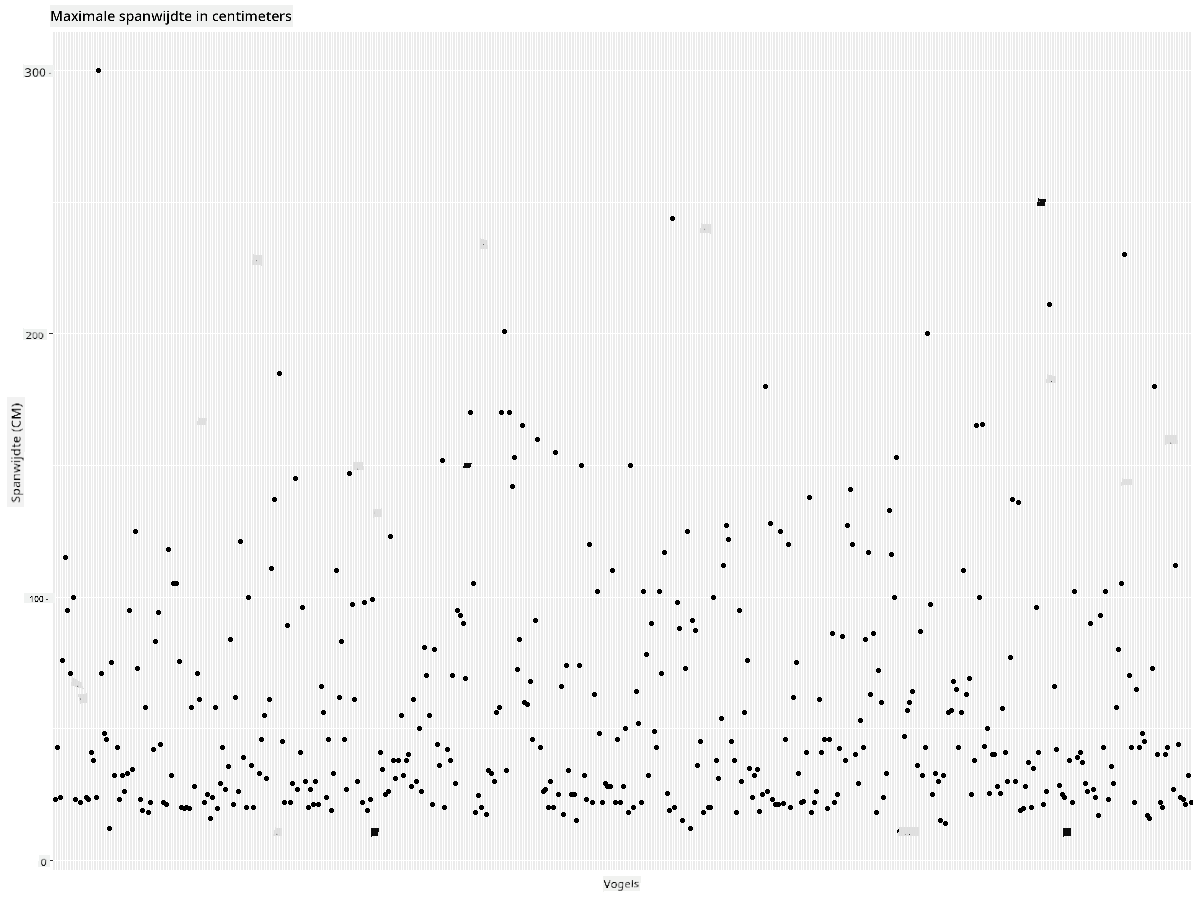
Nu we een schonere dataset hebben, althans wat betreft vleugelspanwijdte, laten we meer ontdekken over deze vogels.
Hoewel lijn- en spreidingsdiagrammen informatie kunnen tonen over gegevenswaarden en hun verdelingen, willen we nadenken over de waarden die inherent zijn aan deze dataset. Je zou visualisaties kunnen maken om de volgende vragen over hoeveelheden te beantwoorden:
Hoeveel categorieën vogels zijn er, en wat zijn hun aantallen?
Hoeveel vogels zijn uitgestorven, bedreigd, zeldzaam of algemeen?
Hoeveel zijn er van de verschillende geslachten en orden in de terminologie van Linnaeus?
Verken staafdiagrammen
Staafdiagrammen zijn praktisch wanneer je groeperingen van gegevens wilt tonen. Laten we de categorieën van vogels in deze dataset verkennen om te zien welke het meest voorkomt qua aantal.
Laten we een staafdiagram maken op gefilterde gegevens.
install.packages("dplyr")
install.packages("tidyverse")
library(lubridate)
library(scales)
library(dplyr)
library(ggplot2)
library(tidyverse)
birds_filtered %>% group_by(Category) %>%
summarise(n=n(),
MinLength = mean(MinLength),
MaxLength = mean(MaxLength),
MinBodyMass = mean(MinBodyMass),
MaxBodyMass = mean(MaxBodyMass),
MinWingspan=mean(MinWingspan),
MaxWingspan=mean(MaxWingspan)) %>%
gather("key", "value", - c(Category, n)) %>%
ggplot(aes(x = Category, y = value, group = key, fill = key)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = c("#D62728", "#FF7F0E", "#8C564B","#2CA02C", "#1F77B4", "#9467BD")) +
xlab("Category")+ggtitle("Birds of Minnesota")
In de volgende snippet installeren we de dplyr en lubridate pakketten om gegevens te manipuleren en te groeperen om een gestapeld staafdiagram te plotten. Eerst groepeer je de gegevens op de Category van de vogel en vat je de kolommen MinLength, MaxLength, MinBodyMass, MaxBodyMass, MinWingspan, MaxWingspan samen. Vervolgens plot je het staafdiagram met het ggplot2 pakket en specificeer je de kleuren voor de verschillende categorieën en de labels.
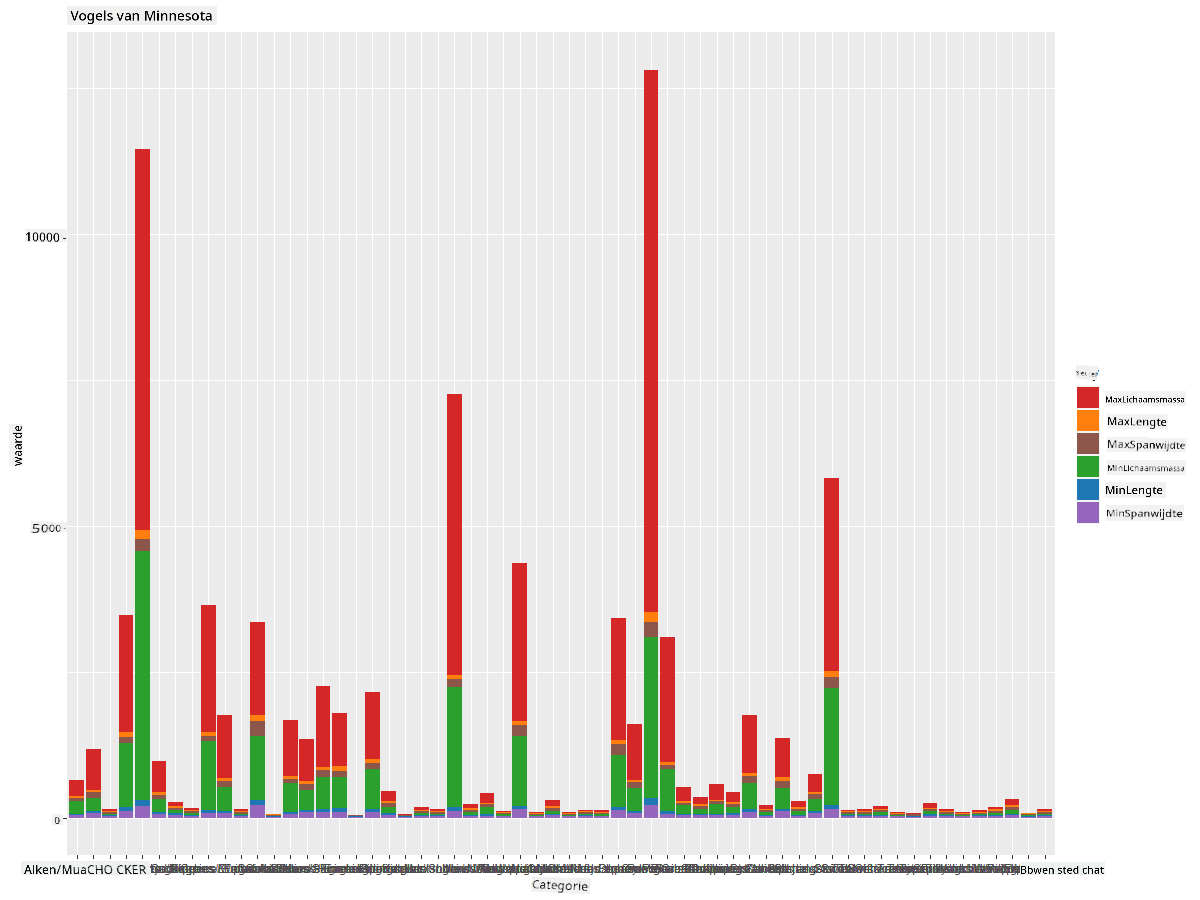
Dit staafdiagram is echter onleesbaar omdat er te veel niet-gegroepeerde gegevens zijn. Je moet alleen de gegevens selecteren die je wilt plotten, dus laten we kijken naar de lengte van vogels op basis van hun categorie.
Filter je gegevens om alleen de categorie van de vogel op te nemen.
Omdat er veel categorieën zijn, kun je deze grafiek verticaal weergeven en de hoogte aanpassen om rekening te houden met alle gegevens:
birds_count<-dplyr::count(birds_filtered, Category, sort = TRUE)
birds_count$Category <- factor(birds_count$Category, levels = birds_count$Category)
ggplot(birds_count,aes(Category,n))+geom_bar(stat="identity")+coord_flip()
Je telt eerst unieke waarden in de Category kolom en sorteert ze vervolgens in een nieuwe dataframe birds_count. Deze gesorteerde gegevens worden vervolgens op hetzelfde niveau gefactoreerd zodat ze op een gesorteerde manier worden geplot. Met ggplot2 plot je vervolgens de gegevens in een staafdiagram. De coord_flip() plot horizontale balken.
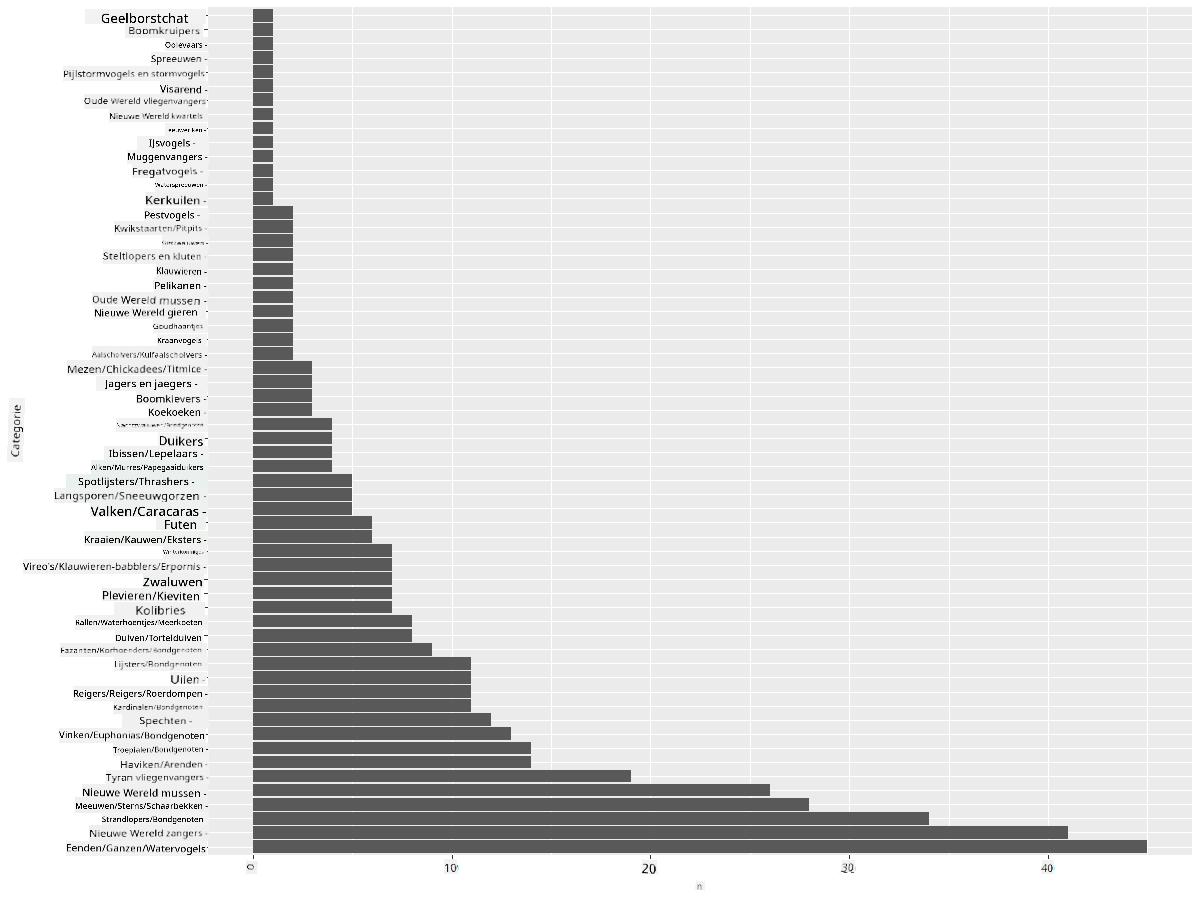
Dit staafdiagram geeft een goed overzicht van het aantal vogels in elke categorie. In één oogopslag zie je dat het grootste aantal vogels in deze regio behoort tot de categorie Eenden/Ganzen/Watervogels. Minnesota is het 'land van 10.000 meren', dus dit is niet verrassend!
✅ Probeer enkele andere tellingen op deze dataset. Verrast iets je?
Gegevens vergelijken
Je kunt verschillende vergelijkingen van gegroepeerde gegevens proberen door nieuwe assen te maken. Probeer een vergelijking van de MaxLength van een vogel, gebaseerd op zijn categorie:
birds_grouped <- birds_filtered %>%
group_by(Category) %>%
summarise(
MaxLength = max(MaxLength, na.rm = T),
MinLength = max(MinLength, na.rm = T)
) %>%
arrange(Category)
ggplot(birds_grouped,aes(Category,MaxLength))+geom_bar(stat="identity")+coord_flip()
We groeperen de birds_filtered gegevens op Category en plotten vervolgens een staafdiagram.
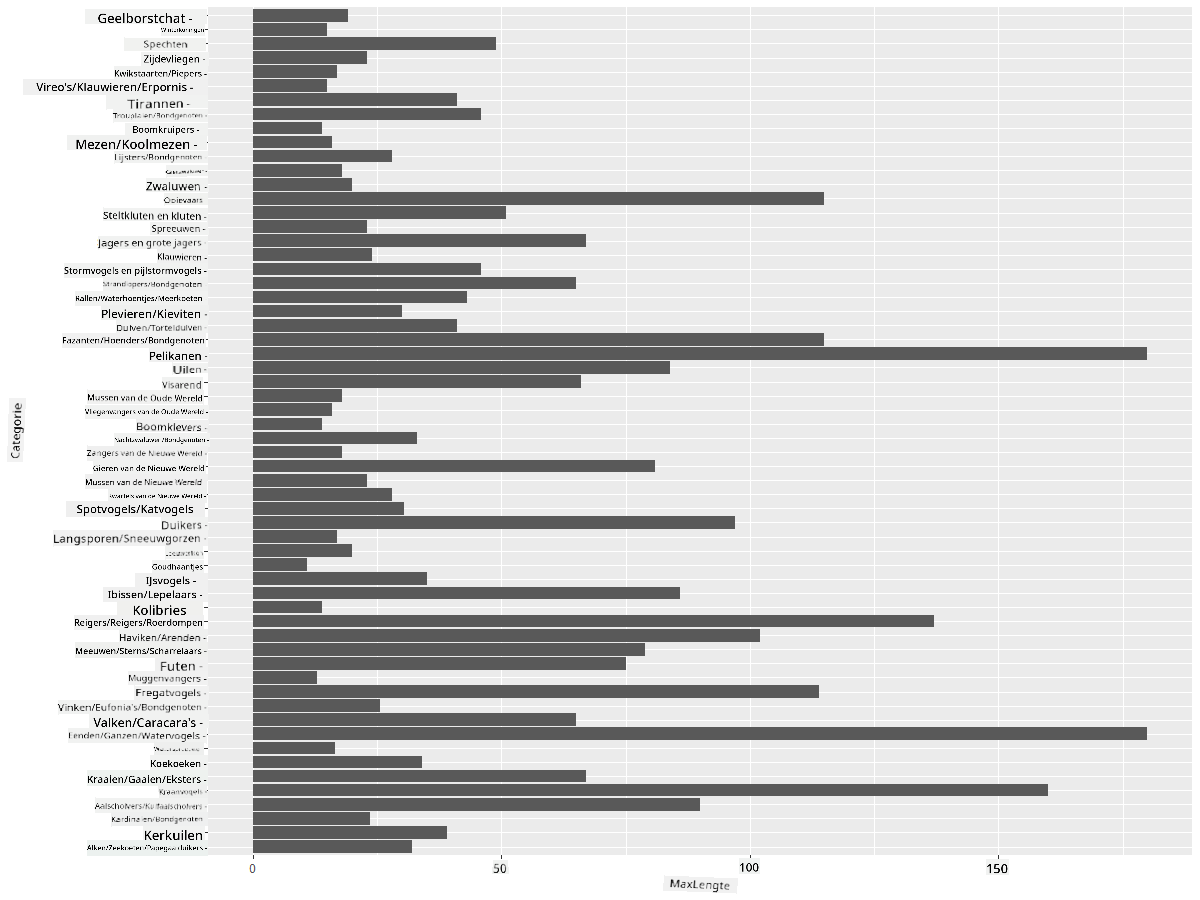
Hier is niets verrassends: kolibries hebben de minste MaxLength in vergelijking met pelikanen of ganzen. Het is goed wanneer gegevens logisch zijn!
Je kunt interessantere visualisaties van staafdiagrammen maken door gegevens te superponeren. Laten we Minimum en Maximum Lengte superponeren op een gegeven vogelcategorie:
ggplot(data=birds_grouped, aes(x=Category)) +
geom_bar(aes(y=MaxLength), stat="identity", position ="identity", fill='blue') +
geom_bar(aes(y=MinLength), stat="identity", position="identity", fill='orange')+
coord_flip()
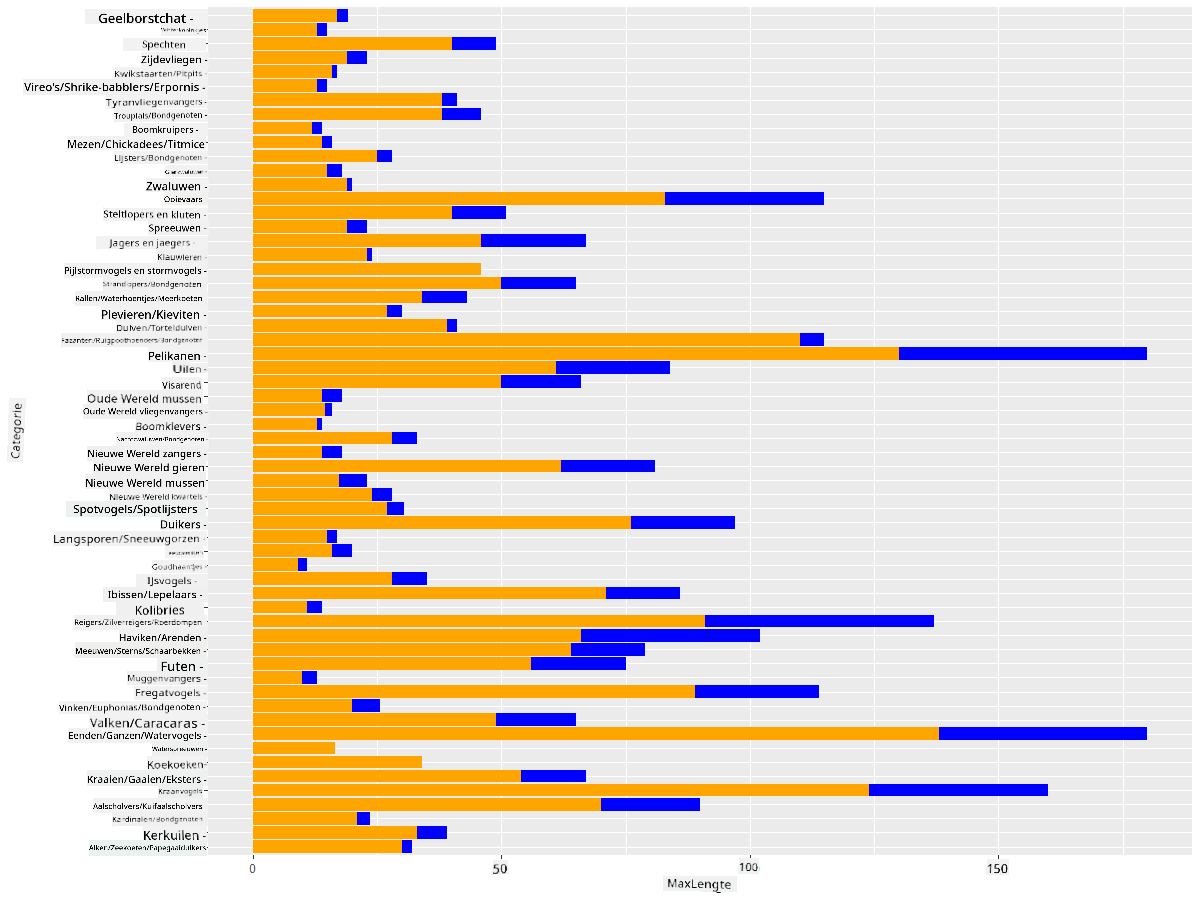
🚀 Uitdaging
Deze vogeldataset biedt een schat aan informatie over verschillende soorten vogels binnen een bepaald ecosysteem. Zoek op internet en kijk of je andere vogelgerichte datasets kunt vinden. Oefen met het maken van grafieken en diagrammen over deze vogels om feiten te ontdekken die je niet kende.
Quiz na de les
Review & Zelfstudie
Deze eerste les heeft je wat informatie gegeven over hoe je ggplot2 kunt gebruiken om hoeveelheden te visualiseren. Doe wat onderzoek naar andere manieren om met datasets te werken voor visualisatie. Zoek en onderzoek datasets die je zou kunnen visualiseren met andere pakketten zoals Lattice en Plotly.
Opdracht
Lijnen, Spreidingsdiagrammen en Staafdiagrammen
Disclaimer:
Dit document is vertaald met behulp van de AI-vertalingsservice Co-op Translator. Hoewel we streven naar nauwkeurigheid, dient u zich ervan bewust te zijn dat geautomatiseerde vertalingen fouten of onnauwkeurigheden kunnen bevatten. Het originele document in de oorspronkelijke taal moet worden beschouwd als de gezaghebbende bron. Voor kritieke informatie wordt professionele menselijke vertaling aanbevolen. Wij zijn niet aansprakelijk voor misverstanden of verkeerde interpretaties die voortvloeien uit het gebruik van deze vertaling.