19 KiB
Adattudomány a felhőben: Az "Azure ML SDK" módszer
 |
|---|
| Adattudomány a felhőben: Azure ML SDK - Sketchnote készítette: @nitya |
Tartalomjegyzék:
- Adattudomány a felhőben: Az "Azure ML SDK" módszer
Előadás előtti kvíz
1. Bevezetés
1.1 Mi az az Azure ML SDK?
Az adattudósok és mesterséges intelligencia fejlesztők az Azure Machine Learning SDK-t használják gépi tanulási munkafolyamatok létrehozására és futtatására az Azure Machine Learning szolgáltatással. A szolgáltatással bármilyen Python környezetben dolgozhatunk, beleértve a Jupyter Notebookokat, a Visual Studio Code-ot vagy a kedvenc Python IDE-nket.
Az SDK főbb területei:
- Az adathalmazok felfedezése, előkészítése és életciklusuk kezelése a gépi tanulási kísérletek során.
- Felhőalapú erőforrások kezelése a kísérletek monitorozásához, naplózásához és szervezéséhez.
- Modellek betanítása helyben vagy felhőalapú erőforrásokkal, beleértve a GPU-gyorsított modellbetanítást.
- Automatikus gépi tanulás használata, amely konfigurációs paramétereket és betanítási adatokat fogad. Ez automatikusan iterál az algoritmusok és hiperparaméterek beállításain, hogy megtalálja a legjobb modellt az előrejelzésekhez.
- Webszolgáltatások telepítése, amelyek a betanított modelleket RESTful szolgáltatásokként teszik elérhetővé bármely alkalmazás számára.
További információ az Azure Machine Learning SDK-ról
Az előző leckében megvizsgáltuk, hogyan lehet modellt betanítani, telepíteni és használni alacsony kódú/nem kódolt módon. A szívelégtelenség adathalmazt használtuk egy szívelégtelenség előrejelzési modell létrehozásához. Ebben a leckében ugyanezt fogjuk megtenni, de az Azure Machine Learning SDK használatával.
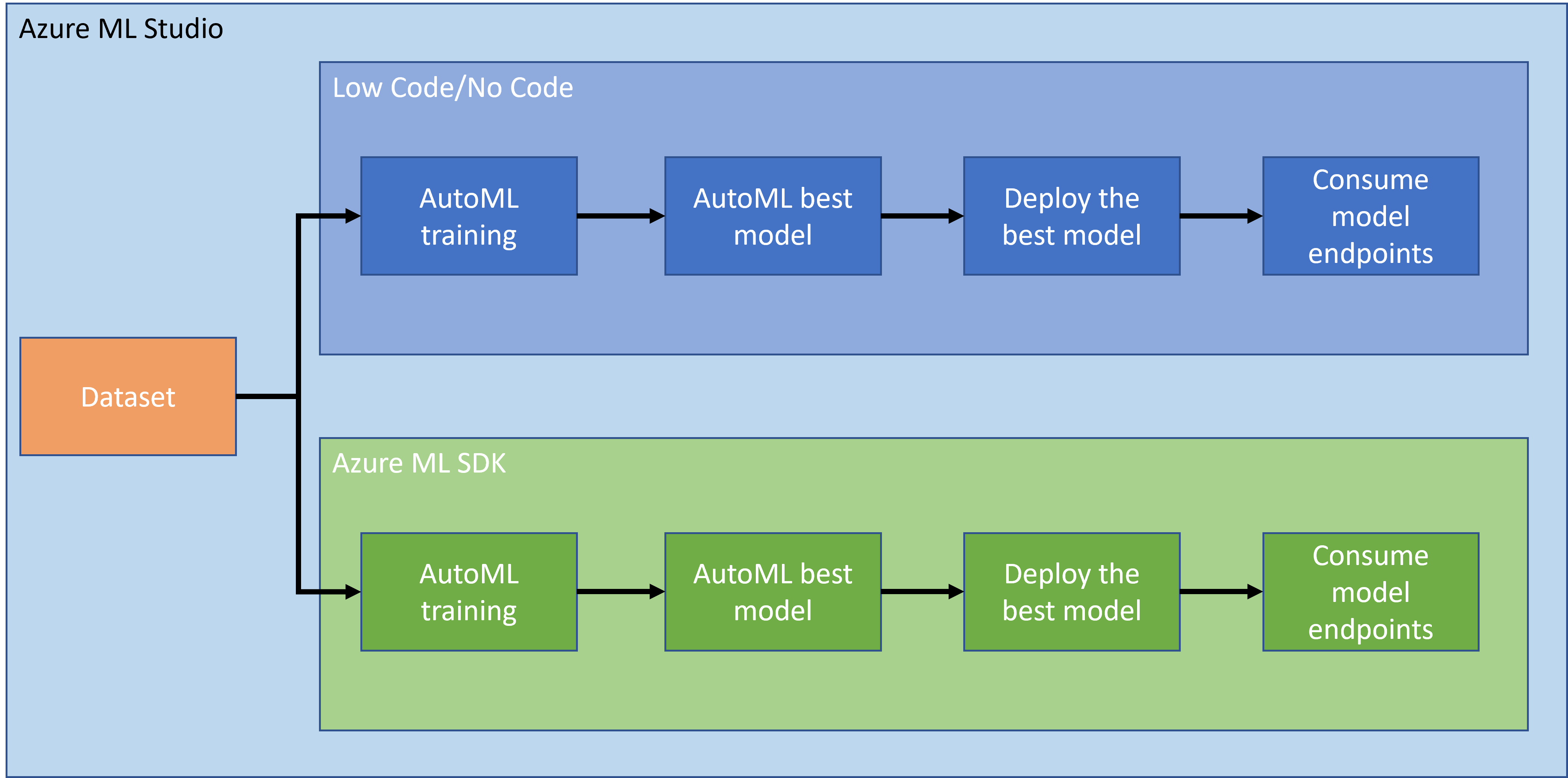
1.2 Szívelégtelenség előrejelzési projekt és adathalmaz bemutatása
A szívelégtelenség előrejelzési projekt és adathalmaz bemutatását itt találod.
2. Modell betanítása az Azure ML SDK-val
2.1 Azure ML munkaterület létrehozása
Egyszerűség kedvéért egy Jupyter notebookban fogunk dolgozni. Ez azt feltételezi, hogy már rendelkezel egy munkaterülettel és egy számítási példánnyal. Ha már van munkaterületed, közvetlenül a 2.3 Jegyzetfüzet létrehozása szakaszra ugorhatsz.
Ha még nincs, kövesd az utasításokat az Azure ML munkaterület létrehozása szakaszban az előző leckében.
2.2 Számítási példány létrehozása
Az Azure ML munkaterületen, amelyet korábban létrehoztunk, menj a Compute menüpontra, ahol láthatod a különböző számítási erőforrásokat.

Hozzunk létre egy számítási példányt egy Jupyter notebook biztosításához.
- Kattints az + Új gombra.
- Adj nevet a számítási példánynak.
- Válaszd ki az opciókat: CPU vagy GPU, VM méret és magok száma.
- Kattints a Létrehozás gombra.
Gratulálok, most létrehoztál egy számítási példányt! Ezt a példányt fogjuk használni a jegyzetfüzet létrehozásához a Jegyzetfüzetek létrehozása szakaszban.
2.3 Az adathalmaz betöltése
Ha még nem töltötted fel az adathalmazt, nézd meg az előző leckében a 2.3 Az adathalmaz betöltése szakaszt.
2.4 Jegyzetfüzetek létrehozása
MEGJEGYZÉS: A következő lépéshez létrehozhatsz egy új jegyzetfüzetet a semmiből, vagy feltöltheted az általunk létrehozott jegyzetfüzetet az Azure ML Stúdióba. A feltöltéshez egyszerűen kattints a "Jegyzetfüzet" menüpontra, és töltsd fel a jegyzetfüzetet.
A jegyzetfüzetek nagyon fontosak az adattudományi folyamatban. Használhatók feltáró adatelemzéshez (EDA), számítási fürt hívásához modell betanításához, vagy következtetési fürt hívásához végpont telepítéséhez.
Jegyzetfüzet létrehozásához szükségünk van egy számítási csomópontra, amely a Jupyter notebook példányt szolgáltatja. Térj vissza az Azure ML munkaterületre, és kattints a Számítási példányokra. A számítási példányok listájában látnod kell az előzőleg létrehozott példányt.
- Az Alkalmazások szakaszban kattints a Jupyter opcióra.
- Pipáld ki az "Igen, megértettem" négyzetet, majd kattints a Folytatás gombra.

- Ez egy új böngészőfület nyit meg a Jupyter notebook példányoddal. Kattints az "Új" gombra egy jegyzetfüzet létrehozásához.

Most, hogy van egy jegyzetfüzetünk, elkezdhetjük a modell betanítását az Azure ML SDK-val.
2.5 Modell betanítása
Először is, ha bármikor kétséged támad, nézd meg az Azure ML SDK dokumentációját. Ez tartalmazza az összes szükséges információt azokról a modulokról, amelyeket ebben a leckében látni fogunk.
2.5.1 Munkaterület, kísérlet, számítási fürt és adathalmaz beállítása
A workspace betöltéséhez a konfigurációs fájlból használd a következő kódot:
from azureml.core import Workspace
ws = Workspace.from_config()
Ez egy Workspace típusú objektumot ad vissza, amely a munkaterületet képviseli. Ezután létre kell hoznod egy experiment-et a következő kóddal:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Egy kísérlet lekéréséhez vagy létrehozásához a munkaterületen belül a kísérlet nevét kell megadnod. A kísérlet neve 3-36 karakter hosszú lehet, betűvel vagy számmal kell kezdődnie, és csak betűket, számokat, aláhúzásokat és kötőjeleket tartalmazhat. Ha a kísérlet nem található a munkaterületen, egy új kísérlet jön létre.
Most hozz létre egy számítási fürtöt a betanításhoz a következő kóddal. Ez a lépés néhány percet igénybe vehet.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Az adathalmazt a munkaterületből az adathalmaz nevének megadásával kérheted le az alábbi módon:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 AutoML konfiguráció és betanítás
Az AutoML konfiguráció beállításához használd az AutoMLConfig osztályt.
A dokumentáció szerint számos paraméterrel játszhatsz. Ehhez a projekthez a következő paramétereket fogjuk használni:
experiment_timeout_minutes: Az az időtartam (percben), amely alatt a kísérlet futtatható, mielőtt automatikusan leállna, és az eredmények elérhetővé válnának.max_concurrent_iterations: A kísérletben engedélyezett egyidejű betanítási iterációk maximális száma.primary_metric: Az elsődleges metrika, amely alapján a kísérlet állapota meghatározásra kerül.compute_target: Az Azure Machine Learning számítási cél, amelyen az Automatikus Gépi Tanulási kísérlet fut.task: A futtatandó feladat típusa. Értékei lehetnek 'classification', 'regression' vagy 'forecasting', a megoldandó automatikus ML probléma típusától függően.training_data: A kísérletben használt betanítási adatok. Tartalmaznia kell a betanítási jellemzőket és egy címkeoszlopot (opcionálisan egy mintasúly oszlopot).label_column_name: A címkeoszlop neve.path: Az Azure Machine Learning projekt mappájának teljes elérési útja.enable_early_stopping: Korai leállítás engedélyezése, ha a pontszám rövid távon nem javul.featurization: Jelzi, hogy az automatikus jellemzőképzés engedélyezett-e, vagy egyedi jellemzőképzést kell használni.debug_log: A hibakeresési információk írására szolgáló naplófájl.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Most, hogy a konfiguráció be van állítva, betaníthatod a modellt a következő kóddal. Ez a lépés akár egy órát is igénybe vehet a fürt méretétől függően.
remote_run = experiment.submit(automl_config)
A RunDetails widget segítségével megjelenítheted a különböző kísérleteket.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Modell telepítése és végpont fogyasztása az Azure ML SDK-val
3.1 A legjobb modell mentése
A remote_run egy AutoMLRun típusú objektum. Ez az objektum tartalmazza a get_output() metódust, amely visszaadja a legjobb futtatást és a hozzá tartozó betanított modellt.
best_run, fitted_model = remote_run.get_output()
A legjobb modellhez használt paramétereket egyszerűen kiírhatod a fitted_model nyomtatásával, és a legjobb modell tulajdonságait a get_properties() metódus segítségével tekintheted meg.
best_run.get_properties()
Most regisztráld a modellt a register_model metódussal.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Modell telepítése
Miután a legjobb modellt elmentetted, telepítheted az InferenceConfig osztály segítségével. Az InferenceConfig a telepítéshez használt egyedi környezet konfigurációs beállításait képviseli. Az AciWebservice osztály egy gépi tanulási modellt képvisel, amely webszolgáltatási végpontként van telepítve az Azure Container Instances-en. A telepített szolgáltatás egy modellből, szkriptekből és kapcsolódó fájlokból létrehozott terheléselosztott HTTP végpont, amely REST API-val rendelkezik. Adatokat küldhetsz ennek az API-nak, és megkapod a modell által visszaadott előrejelzést.
A modellt a deploy metódussal telepítheted.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Ez a lépés néhány percet igénybe vehet.
3.3 Végpont fogyasztása
A végpontot egy minta bemenet létrehozásával használhatod:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Ezután elküld
response = aci_service.run(input_data=test_sample)
response
Ennek az eredménye '{"result": [false]}' lesz. Ez azt jelenti, hogy a végponthoz küldött betegadatok alapján a predikció false, vagyis ez a személy valószínűleg nem fog szívrohamot kapni.
Gratulálunk! Sikeresen felhasználtad az Azure ML-en keresztül telepített és betanított modellt az Azure ML SDK segítségével!
NOTE: Miután befejezted a projektet, ne felejtsd el törölni az összes erőforrást.
🚀 Kihívás
Az SDK-val még rengeteg más dolgot is meg lehet valósítani, sajnos nem tudunk mindent áttekinteni ebben a leckében. De van egy jó hír: ha megtanulod, hogyan böngészd az SDK dokumentációját, azzal önállóan is sokat elérhetsz. Nézd meg az Azure ML SDK dokumentációját, és keresd meg a Pipeline osztályt, amely lehetővé teszi, hogy folyamatokat hozz létre. A Pipeline egy lépésekből álló gyűjtemény, amelyeket munkafolyamatként lehet végrehajtani.
TIPP: Látogass el az SDK dokumentációjába, és írj be kulcsszavakat a keresősávba, például "Pipeline". A keresési eredmények között meg kell találnod az azureml.pipeline.core.Pipeline osztályt.
Utólagos kvíz
Áttekintés és önálló tanulás
Ebben a leckében megtanultad, hogyan kell betanítani, telepíteni és felhasználni egy modellt a szívelégtelenség kockázatának előrejelzésére az Azure ML SDK-val a felhőben. További információért nézd meg ezt a dokumentációt az Azure ML SDK-ról. Próbálj meg saját modellt létrehozni az Azure ML SDK-val.
Feladat
Adattudományi projekt az Azure ML SDK-val
Felelősség kizárása:
Ez a dokumentum az AI fordítási szolgáltatás, a Co-op Translator segítségével lett lefordítva. Bár törekszünk a pontosságra, kérjük, vegye figyelembe, hogy az automatikus fordítások hibákat vagy pontatlanságokat tartalmazhatnak. Az eredeti dokumentum az eredeti nyelvén tekintendő hiteles forrásnak. Kritikus információk esetén javasolt professzionális emberi fordítást igénybe venni. Nem vállalunk felelősséget semmilyen félreértésért vagy téves értelmezésért, amely a fordítás használatából eredhet.