32 KiB
کار با دادهها: پایتون و کتابخانه Pandas
 |
|---|
| کار با پایتون - طرح دستی توسط @nitya |
در حالی که پایگاههای داده روشهای بسیار کارآمدی برای ذخیرهسازی دادهها و جستجوی آنها با استفاده از زبانهای پرسوجو ارائه میدهند، انعطافپذیرترین روش پردازش دادهها نوشتن برنامهای است که دادهها را دستکاری کند. در بسیاری از موارد، انجام یک پرسوجوی پایگاه داده میتواند مؤثرتر باشد. اما در برخی موارد که پردازش دادههای پیچیدهتر مورد نیاز است، این کار به راحتی با SQL قابل انجام نیست.
پردازش دادهها را میتوان با هر زبان برنامهنویسی انجام داد، اما برخی زبانها سطح بالاتری برای کار با دادهها دارند. دانشمندان داده معمولاً یکی از زبانهای زیر را ترجیح میدهند:
- پایتون، یک زبان برنامهنویسی عمومی که به دلیل سادگی اغلب به عنوان یکی از بهترین گزینهها برای مبتدیان در نظر گرفته میشود. پایتون دارای کتابخانههای زیادی است که میتوانند به شما در حل بسیاری از مشکلات عملی کمک کنند، مانند استخراج دادهها از آرشیو ZIP یا تبدیل تصویر به حالت خاکستری. علاوه بر علم داده، پایتون اغلب برای توسعه وب نیز استفاده میشود.
- R یک ابزار سنتی است که با هدف پردازش دادههای آماری توسعه یافته است. این زبان همچنین دارای مخزن بزرگی از کتابخانهها (CRAN) است که آن را به گزینهای مناسب برای پردازش دادهها تبدیل میکند. با این حال، R یک زبان برنامهنویسی عمومی نیست و به ندرت خارج از حوزه علم داده استفاده میشود.
- Julia یک زبان دیگر است که به طور خاص برای علم داده توسعه یافته است. این زبان برای ارائه عملکرد بهتر نسبت به پایتون طراحی شده است و آن را به ابزاری عالی برای آزمایشهای علمی تبدیل میکند.
در این درس، ما بر استفاده از پایتون برای پردازش ساده دادهها تمرکز خواهیم کرد. فرض میکنیم که با اصول اولیه این زبان آشنا هستید. اگر میخواهید یک تور عمیقتر از پایتون داشته باشید، میتوانید به یکی از منابع زیر مراجعه کنید:
- یادگیری پایتون به روش سرگرمکننده با گرافیک لاکپشتی و فراکتالها - دوره مقدماتی سریع در GitHub برای برنامهنویسی پایتون
- اولین قدمهای خود را با پایتون بردارید مسیر یادگیری در Microsoft Learn
دادهها میتوانند اشکال مختلفی داشته باشند. در این درس، ما سه شکل داده را در نظر خواهیم گرفت - دادههای جدولی، متن و تصاویر.
ما بر چند مثال از پردازش دادهها تمرکز خواهیم کرد، به جای اینکه نمای کلی از همه کتابخانههای مرتبط ارائه دهیم. این به شما اجازه میدهد تا ایده اصلی از آنچه ممکن است را دریافت کنید و درک کنید که کجا میتوانید راهحلهایی برای مشکلات خود پیدا کنید.
مفیدترین توصیه. وقتی نیاز دارید عملیاتی خاص روی دادهها انجام دهید که نمیدانید چگونه انجام دهید، سعی کنید آن را در اینترنت جستجو کنید. Stackoverflow معمولاً شامل نمونههای کد مفید زیادی در پایتون برای بسیاری از وظایف معمول است.
پیشزمینه آزمون
دادههای جدولی و Dataframes
شما قبلاً با دادههای جدولی آشنا شدهاید وقتی درباره پایگاههای داده رابطهای صحبت کردیم. وقتی دادههای زیادی دارید و این دادهها در جداول مختلف مرتبط قرار دارند، قطعاً استفاده از SQL برای کار با آنها منطقی است. با این حال، موارد زیادی وجود دارد که ما یک جدول داده داریم و نیاز داریم تا برخی درک یا بینش درباره این دادهها کسب کنیم، مانند توزیع، همبستگی بین مقادیر و غیره. در علم داده، موارد زیادی وجود دارد که نیاز داریم برخی تغییرات در دادههای اصلی انجام دهیم و سپس آنها را بصریسازی کنیم. هر دو مرحله به راحتی با پایتون قابل انجام هستند.
دو کتابخانه بسیار مفید در پایتون وجود دارد که میتوانند به شما در کار با دادههای جدولی کمک کنند:
- Pandas به شما امکان میدهد تا با Dataframes کار کنید، که مشابه جداول رابطهای هستند. شما میتوانید ستونهای نامگذاری شده داشته باشید و عملیات مختلفی روی ردیفها، ستونها و Dataframes به طور کلی انجام دهید.
- Numpy یک کتابخانه برای کار با تنسورها، یعنی آرایههای چندبعدی است. آرایه دارای مقادیر از نوع پایه یکسان است و سادهتر از Dataframe است، اما عملیات ریاضی بیشتری ارائه میدهد و سربار کمتری ایجاد میکند.
چند کتابخانه دیگر نیز وجود دارد که باید با آنها آشنا باشید:
- Matplotlib یک کتابخانه برای بصریسازی دادهها و رسم نمودارها
- SciPy یک کتابخانه با برخی توابع علمی اضافی. ما قبلاً هنگام صحبت درباره احتمال و آمار با این کتابخانه آشنا شدهایم.
در اینجا یک قطعه کد آورده شده است که معمولاً برای وارد کردن این کتابخانهها در ابتدای برنامه پایتون خود استفاده میکنید:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas حول چند مفهوم اساسی متمرکز است.
Series
Series یک دنباله از مقادیر است، مشابه لیست یا آرایه numpy. تفاوت اصلی این است که Series همچنین دارای یک شاخص است و وقتی روی Series عملیات انجام میدهیم (مثلاً آنها را جمع میکنیم)، شاخص در نظر گرفته میشود. شاخص میتواند به سادگی شماره ردیف صحیح باشد (این شاخص به طور پیشفرض هنگام ایجاد یک Series از لیست یا آرایه استفاده میشود)، یا میتواند ساختار پیچیدهای مانند بازه زمانی داشته باشد.
توجه: برخی کدهای مقدماتی Pandas در دفترچه همراه
notebook.ipynbموجود است. ما فقط برخی از مثالها را اینجا بیان میکنیم و شما قطعاً میتوانید دفترچه کامل را بررسی کنید.
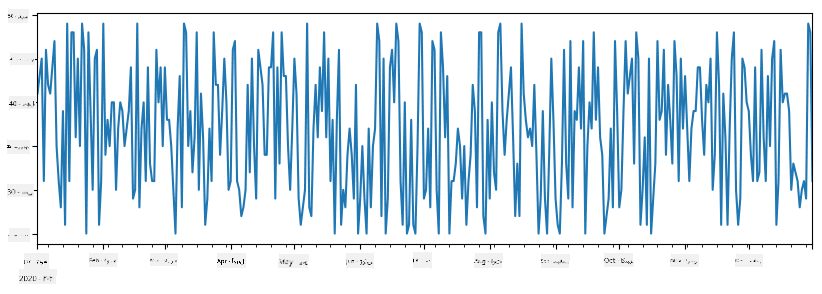
به عنوان مثال: ما میخواهیم فروش یک مغازه بستنیفروشی را تحلیل کنیم. بیایید یک سری از اعداد فروش (تعداد اقلام فروخته شده در هر روز) برای یک دوره زمانی ایجاد کنیم:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
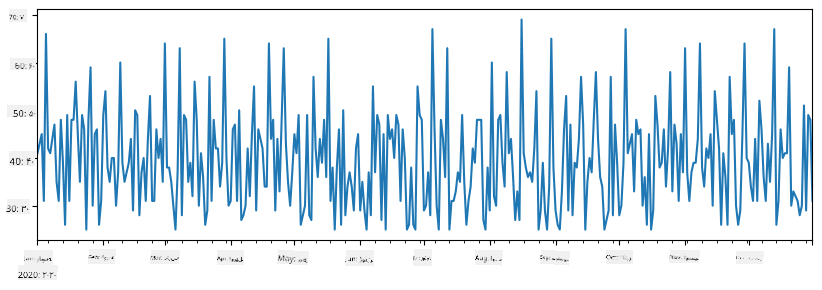
حالا فرض کنید که هر هفته یک مهمانی برای دوستان برگزار میکنیم و 10 بسته بستنی اضافی برای مهمانی میگیریم. میتوانیم یک سری دیگر، با شاخص هفته، برای نشان دادن این موضوع ایجاد کنیم:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
وقتی دو سری را با هم جمع میکنیم، تعداد کل را دریافت میکنیم:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
توجه که ما از نحو ساده
total_items+additional_itemsاستفاده نمیکنیم. اگر این کار را میکردیم، تعداد زیادی مقدارNaN(Not a Number) در سری حاصل دریافت میکردیم. این به این دلیل است که مقادیر گمشدهای برای برخی از نقاط شاخص در سریadditional_itemsوجود دارد و افزودنNaNبه هر چیزی نتیجهNaNمیدهد. بنابراین باید پارامترfill_valueرا هنگام جمع مشخص کنیم.
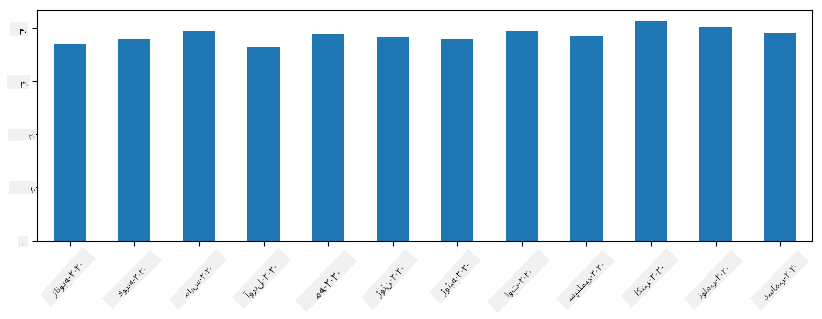
با سریهای زمانی، میتوانیم سری را با بازههای زمانی مختلف نمونهگیری مجدد کنیم. به عنوان مثال، فرض کنید میخواهیم حجم فروش متوسط ماهانه را محاسبه کنیم. میتوانیم از کد زیر استفاده کنیم:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
یک DataFrame اساساً مجموعهای از سریها با همان شاخص است. میتوانیم چند سری را با هم ترکیب کنیم تا یک DataFrame ایجاد کنیم:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
این یک جدول افقی مانند این ایجاد میکند:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
میتوانیم از سریها به عنوان ستونها استفاده کنیم و نام ستونها را با استفاده از دیکشنری مشخص کنیم:
df = pd.DataFrame({ 'A' : a, 'B' : b })
این جدول زیر را به ما میدهد:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
توجه که میتوانیم این طرح جدول را با ترانهاده کردن جدول قبلی نیز دریافت کنیم، مثلاً با نوشتن
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
اینجا .T به معنای عملیات ترانهاده کردن DataFrame است، یعنی تغییر ردیفها و ستونها، و عملیات rename به ما اجازه میدهد تا ستونها را برای مطابقت با مثال قبلی تغییر نام دهیم.
در اینجا چند عملیات مهم که میتوانیم روی DataFrames انجام دهیم آورده شده است:
انتخاب ستونها. میتوانیم ستونهای فردی را با نوشتن df['A'] انتخاب کنیم - این عملیات یک Series را برمیگرداند. همچنین میتوانیم زیرمجموعهای از ستونها را به یک DataFrame دیگر انتخاب کنیم با نوشتن df[['B','A']] - این یک DataFrame دیگر را برمیگرداند.
فیلتر کردن فقط ردیفهای خاص بر اساس معیارها. به عنوان مثال، برای نگه داشتن فقط ردیفهایی که ستون A بزرگتر از 5 است، میتوانیم بنویسیم df[df['A']>5].
توجه: نحوه کار فیلتر کردن به این صورت است. عبارت
df['A']<5یک سری بولی برمیگرداند که نشان میدهد آیا عبارت برای هر عنصر از سری اصلیdf['A']درست یا غلط است. وقتی سری بولی به عنوان شاخص استفاده میشود، زیرمجموعهای از ردیفها را در DataFrame برمیگرداند. بنابراین نمیتوان از عبارت بولی دلخواه پایتون استفاده کرد، به عنوان مثال، نوشتنdf[df['A']>5 and df['A']<7]اشتباه خواهد بود. در عوض، باید از عملیات خاص&روی سری بولی استفاده کنید، با نوشتنdf[(df['A']>5) & (df['A']<7)](پرانتزها اینجا مهم هستند).
ایجاد ستونهای محاسباتی جدید. میتوانیم به راحتی ستونهای محاسباتی جدیدی برای DataFrame خود ایجاد کنیم با استفاده از عبارتهای شهودی مانند این:
df['DivA'] = df['A']-df['A'].mean()
این مثال انحراف A از مقدار میانگین آن را محاسبه میکند. آنچه در واقع اینجا اتفاق میافتد این است که ما یک سری محاسبه میکنیم و سپس این سری را به سمت چپ اختصاص میدهیم، یک ستون جدید ایجاد میکنیم. بنابراین نمیتوانیم از هیچ عملیاتی که با سریها سازگار نیست استفاده کنیم، به عنوان مثال، کد زیر اشتباه است:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
مثال آخر، در حالی که از نظر نحوی صحیح است، نتیجه اشتباهی به ما میدهد، زیرا طول سری B را به همه مقادیر در ستون اختصاص میدهد، نه طول عناصر فردی همانطور که قصد داشتیم.
اگر نیاز به محاسبه عبارات پیچیده مانند این داریم، میتوانیم از تابع apply استفاده کنیم. مثال آخر را میتوان به صورت زیر نوشت:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
بعد از عملیاتهای بالا، ما به DataFrame زیر خواهیم رسید:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
انتخاب ردیفها بر اساس شمارهها را میتوان با استفاده از ساختار iloc انجام داد. به عنوان مثال، برای انتخاب 5 ردیف اول از DataFrame:
df.iloc[:5]
گروهبندی اغلب برای دریافت نتیجهای مشابه جدولهای محوری در Excel استفاده میشود. فرض کنید که میخواهیم مقدار میانگین ستون A را برای هر عدد داده شده از LenB محاسبه کنیم. سپس میتوانیم DataFrame خود را بر اساس LenB گروهبندی کنیم و mean را فراخوانی کنیم:
df.groupby(by='LenB')[['A','DivA']].mean()
اگر نیاز به محاسبه میانگین و تعداد عناصر در گروه داریم، میتوانیم از تابع پیچیدهتر aggregate استفاده کنیم:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
این جدول زیر را به ما میدهد:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
دریافت دادهها
ما دیدهایم که چقدر ساختن Series و DataFrames از اشیاء پایتون آسان است. با این حال، دادهها معمولاً به صورت یک فایل متنی یا جدول اکسل ارائه میشوند. خوشبختانه، Pandas راه سادهای برای بارگذاری دادهها از دیسک به ما ارائه میدهد. به عنوان مثال، خواندن فایل CSV به سادگی زیر است:
df = pd.read_csv('file.csv')
ما مثالهای بیشتری از بارگذاری دادهها، از جمله دریافت آن از وبسایتهای خارجی، در بخش "چالش" خواهیم دید.
چاپ و ترسیم
یک دانشمند داده اغلب باید دادهها را بررسی کند، بنابراین توانایی بصریسازی آنها بسیار مهم است. وقتی DataFrame بزرگ است، بسیاری مواقع فقط میخواهیم مطمئن شویم که همه چیز را درست انجام میدهیم، با چاپ چند ردیف اول. این کار با فراخوانی df.head() انجام میشود. اگر آن را از Jupyter Notebook اجرا کنید، DataFrame را به صورت یک جدول زیبا چاپ میکند.
ما همچنین استفاده از تابع plot را برای بصریسازی برخی ستونها دیدهایم. در حالی که plot برای بسیاری از وظایف بسیار مفید است و انواع مختلف نمودارها را از طریق پارامتر kind= پشتیبانی میکند، شما همیشه میتوانید از کتابخانه خام matplotlib برای ترسیم چیزی پیچیدهتر استفاده کنید. ما بصریسازی دادهها را به طور مفصل در درسهای جداگانه پوشش خواهیم داد.
این مرور کلی مهمترین مفاهیم Pandas را پوشش میدهد، اما این کتابخانه بسیار غنی است و هیچ محدودیتی برای کاری که میتوانید با آن انجام دهید وجود ندارد! حالا بیایید این دانش را برای حل یک مشکل خاص به کار ببریم.
🚀 چالش ۱: تحلیل گسترش COVID
اولین مشکلی که روی آن تمرکز خواهیم کرد مدلسازی گسترش اپیدمی COVID-19 است. برای این کار، از دادههای مربوط به تعداد افراد مبتلا در کشورهای مختلف استفاده خواهیم کرد که توسط مرکز علوم سیستمها و مهندسی (CSSE) در دانشگاه جانز هاپکینز ارائه شده است. مجموعه داده در این مخزن GitHub موجود است.
از آنجا که میخواهیم نشان دهیم چگونه با دادهها کار کنیم، از شما دعوت میکنیم notebook-covidspread.ipynb را باز کنید و از ابتدا تا انتها بخوانید. همچنین میتوانید سلولها را اجرا کنید و برخی چالشهایی که در انتها برای شما گذاشتهایم را انجام دهید.
اگر نمیدانید چگونه کد را در Jupyter Notebook اجرا کنید، به این مقاله نگاهی بیندازید.
کار با دادههای غیرساختاریافته
در حالی که دادهها اغلب به صورت جدولی ارائه میشوند، در برخی موارد باید با دادههای کمتر ساختاریافته مانند متن یا تصاویر کار کنیم. در این حالت، برای اعمال تکنیکهای پردازش داده که در بالا دیدهایم، باید به نوعی دادههای ساختاریافته را استخراج کنیم. در اینجا چند مثال آورده شده است:
- استخراج کلمات کلیدی از متن و بررسی اینکه این کلمات کلیدی چند بار ظاهر میشوند
- استفاده از شبکههای عصبی برای استخراج اطلاعات درباره اشیاء موجود در تصویر
- دریافت اطلاعات درباره احساسات افراد در فید دوربین ویدئویی
🚀 چالش ۲: تحلیل مقالات COVID
در این چالش، موضوع همهگیری COVID را ادامه میدهیم و بر پردازش مقالات علمی در این زمینه تمرکز میکنیم. مجموعه داده CORD-19 شامل بیش از ۷۰۰۰ مقاله (در زمان نگارش) درباره COVID است که با متادیتا و چکیدهها (و برای حدود نیمی از آنها متن کامل نیز ارائه شده) در دسترس است.
یک مثال کامل از تحلیل این مجموعه داده با استفاده از سرویس شناختی Text Analytics for Health در این پست وبلاگ توضیح داده شده است. ما نسخه سادهشدهای از این تحلیل را بررسی خواهیم کرد.
NOTE: ما نسخهای از مجموعه داده را به عنوان بخشی از این مخزن ارائه نمیدهیم. ممکن است ابتدا نیاز باشد فایل
metadata.csvرا از این مجموعه داده در Kaggle دانلود کنید. ممکن است ثبتنام در Kaggle لازم باشد. همچنین میتوانید مجموعه داده را بدون ثبتنام از اینجا دانلود کنید، اما شامل تمام متنهای کامل علاوه بر فایل متادیتا خواهد بود.
notebook-papers.ipynb را باز کنید و از ابتدا تا انتها بخوانید. همچنین میتوانید سلولها را اجرا کنید و برخی چالشهایی که در انتها برای شما گذاشتهایم را انجام دهید.
پردازش دادههای تصویری
اخیراً مدلهای هوش مصنوعی بسیار قدرتمندی توسعه یافتهاند که به ما امکان درک تصاویر را میدهند. بسیاری از وظایف را میتوان با استفاده از شبکههای عصبی از پیش آموزشدیده یا خدمات ابری حل کرد. برخی از مثالها شامل موارد زیر است:
- طبقهبندی تصویر، که میتواند به شما کمک کند تصویر را در یکی از کلاسهای از پیش تعریفشده دستهبندی کنید. شما میتوانید به راحتی طبقهبندیکنندههای تصویر خود را با استفاده از خدماتی مانند Custom Vision آموزش دهید.
- تشخیص اشیاء برای شناسایی اشیاء مختلف در تصویر. خدماتی مانند computer vision میتوانند تعداد زیادی از اشیاء رایج را شناسایی کنند و شما میتوانید مدل Custom Vision را برای شناسایی برخی اشیاء خاص مورد علاقه آموزش دهید.
- تشخیص چهره، شامل سن، جنسیت و تشخیص احساسات. این کار را میتوان از طریق Face API انجام داد.
تمام این خدمات ابری را میتوان با استفاده از Python SDKs فراخوانی کرد و بنابراین به راحتی میتوان آنها را در جریان کاری اکتشاف دادههای خود گنجاند.
در اینجا چند مثال از اکتشاف دادهها از منابع داده تصویری آورده شده است:
- در پست وبلاگ چگونه علم داده را بدون کدنویسی یاد بگیریم ما عکسهای اینستاگرام را بررسی میکنیم و سعی میکنیم بفهمیم چه چیزی باعث میشود افراد به یک عکس بیشتر لایک بدهند. ابتدا تا حد ممکن اطلاعات را از تصاویر با استفاده از computer vision استخراج میکنیم و سپس از Azure Machine Learning AutoML برای ساخت مدل قابل تفسیر استفاده میکنیم.
- در کارگاه مطالعات چهره ما از Face API برای استخراج احساسات افراد در عکسهای گرفتهشده از رویدادها استفاده میکنیم تا سعی کنیم بفهمیم چه چیزی باعث خوشحالی افراد میشود.
نتیجهگیری
چه دادههای ساختاریافته داشته باشید یا غیرساختاریافته، با استفاده از پایتون میتوانید تمام مراحل مربوط به پردازش و درک دادهها را انجام دهید. این احتمالاً انعطافپذیرترین روش پردازش دادهها است و به همین دلیل اکثر دانشمندان داده از پایتون به عنوان ابزار اصلی خود استفاده میکنند. یادگیری عمیق پایتون احتمالاً ایده خوبی است اگر در مسیر علم داده جدی هستید!
آزمون پس از درس
مرور و مطالعه خودآموز
کتابها
منابع آنلاین
یادگیری پایتون
- یادگیری پایتون به روشی سرگرمکننده با گرافیک Turtle و فراکتالها
- اولین قدمهای خود را با پایتون بردارید مسیر یادگیری در Microsoft Learn
تکلیف
مطالعه دقیقتر دادهها برای چالشهای بالا انجام دهید
اعتبارها
این درس با ♥️ توسط Dmitry Soshnikov نوشته شده است.
سلب مسئولیت:
این سند با استفاده از سرویس ترجمه هوش مصنوعی Co-op Translator ترجمه شده است. در حالی که ما تلاش میکنیم دقت را حفظ کنیم، لطفاً توجه داشته باشید که ترجمههای خودکار ممکن است شامل خطاها یا نادرستیها باشند. سند اصلی به زبان اصلی آن باید به عنوان منبع معتبر در نظر گرفته شود. برای اطلاعات حساس، توصیه میشود از ترجمه حرفهای انسانی استفاده کنید. ما مسئولیتی در قبال سوء تفاهمها یا تفسیرهای نادرست ناشی از استفاده از این ترجمه نداریم.