26 KiB
Επιστήμη Δεδομένων στο Cloud: Ο τρόπος του "Azure ML SDK"
 |
|---|
| Επιστήμη Δεδομένων στο Cloud: Azure ML SDK - Σκίτσο από @nitya |
Πίνακας περιεχομένων:
- Επιστήμη Δεδομένων στο Cloud: Ο τρόπος του "Azure ML SDK"
Προ-Διάλεξης Κουίζ
1. Εισαγωγή
1.1 Τι είναι το Azure ML SDK;
Οι επιστήμονες δεδομένων και οι προγραμματιστές AI χρησιμοποιούν το Azure Machine Learning SDK για να δημιουργήσουν και να εκτελέσουν ροές εργασίας μηχανικής μάθησης με την υπηρεσία Azure Machine Learning. Μπορείτε να αλληλεπιδράσετε με την υπηρεσία σε οποιοδήποτε περιβάλλον Python, όπως Jupyter Notebooks, Visual Studio Code ή το αγαπημένο σας IDE Python.
Κύριοι τομείς του SDK περιλαμβάνουν:
- Εξερεύνηση, προετοιμασία και διαχείριση του κύκλου ζωής των συνόλων δεδομένων που χρησιμοποιούνται σε πειράματα μηχανικής μάθησης.
- Διαχείριση πόρων cloud για παρακολούθηση, καταγραφή και οργάνωση των πειραμάτων μηχανικής μάθησης.
- Εκπαίδευση μοντέλων είτε τοπικά είτε χρησιμοποιώντας πόρους cloud, συμπεριλαμβανομένης της εκπαίδευσης μοντέλων με επιτάχυνση GPU.
- Χρήση αυτοματοποιημένης μηχανικής μάθησης, η οποία δέχεται παραμέτρους ρύθμισης και δεδομένα εκπαίδευσης. Επαναλαμβάνει αυτόματα αλγόριθμους και ρυθμίσεις υπερπαραμέτρων για να βρει το καλύτερο μοντέλο για προβλέψεις.
- Ανάπτυξη web services για τη μετατροπή των εκπαιδευμένων μοντέλων σας σε RESTful υπηρεσίες που μπορούν να καταναλωθούν σε οποιαδήποτε εφαρμογή.
Μάθετε περισσότερα για το Azure Machine Learning SDK
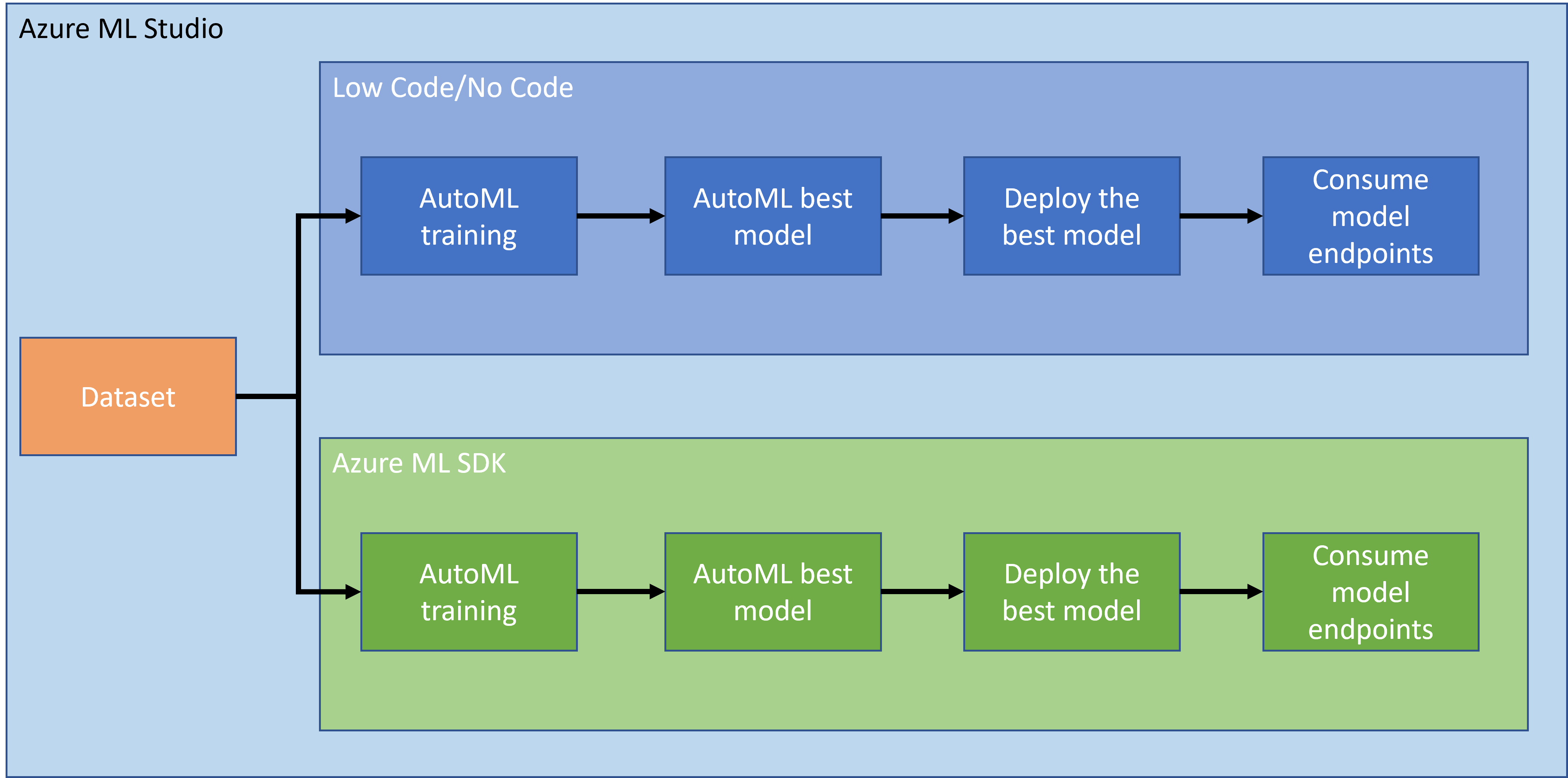
Στο προηγούμενο μάθημα, είδαμε πώς να εκπαιδεύσουμε, να αναπτύξουμε και να καταναλώσουμε ένα μοντέλο με τρόπο Low code/No code. Χρησιμοποιήσαμε το σύνολο δεδομένων καρδιακής ανεπάρκειας για να δημιουργήσουμε ένα μοντέλο πρόβλεψης καρδιακής ανεπάρκειας. Σε αυτό το μάθημα, θα κάνουμε ακριβώς το ίδιο πράγμα αλλά χρησιμοποιώντας το Azure Machine Learning SDK.
1.2 Εισαγωγή στο έργο πρόβλεψης καρδιακής ανεπάρκειας και το σύνολο δεδομένων
Δείτε εδώ την εισαγωγή στο έργο πρόβλεψης καρδιακής ανεπάρκειας και το σύνολο δεδομένων.
2. Εκπαίδευση μοντέλου με το Azure ML SDK
2.1 Δημιουργία ενός Azure ML workspace
Για απλότητα, θα εργαστούμε σε ένα jupyter notebook. Αυτό σημαίνει ότι έχετε ήδη ένα Workspace και μια υπολογιστική μονάδα. Εάν έχετε ήδη Workspace, μπορείτε να μεταβείτε απευθείας στην ενότητα 2.3 Δημιουργία Σημειωματάριων.
Εάν όχι, ακολουθήστε τις οδηγίες στην ενότητα 2.1 Δημιουργία ενός Azure ML workspace στο προηγούμενο μάθημα για να δημιουργήσετε ένα workspace.
2.2 Δημιουργία υπολογιστικής μονάδας
Στο Azure ML workspace που δημιουργήσαμε νωρίτερα, μεταβείτε στο μενού υπολογιστικών πόρων και θα δείτε τους διάφορους διαθέσιμους υπολογιστικούς πόρους.

Ας δημιουργήσουμε μια υπολογιστική μονάδα για να προμηθεύσουμε ένα jupyter notebook.
- Κάντε κλικ στο κουμπί + Νέο.
- Δώστε ένα όνομα στην υπολογιστική σας μονάδα.
- Επιλέξτε τις επιλογές σας: CPU ή GPU, μέγεθος VM και αριθμό πυρήνων.
- Κάντε κλικ στο κουμπί Δημιουργία.
Συγχαρητήρια, μόλις δημιουργήσατε μια υπολογιστική μονάδα! Θα χρησιμοποιήσουμε αυτήν την υπολογιστική μονάδα για να δημιουργήσουμε ένα Σημειωματάριο στην ενότητα Δημιουργία Σημειωματάριων.
2.3 Φόρτωση του συνόλου δεδομένων
Ανατρέξτε στο προηγούμενο μάθημα στην ενότητα 2.3 Φόρτωση του συνόλου δεδομένων εάν δεν έχετε ανεβάσει ακόμα το σύνολο δεδομένων.
2.4 Δημιουργία Σημειωματάριων
ΣΗΜΕΙΩΣΗ: Για το επόμενο βήμα μπορείτε είτε να δημιουργήσετε ένα νέο σημειωματάριο από την αρχή, είτε να ανεβάσετε το σημειωματάριο που δημιουργήσαμε στο Azure ML Studio σας. Για να το ανεβάσετε, απλώς κάντε κλικ στο μενού "Notebook" και ανεβάστε το σημειωματάριο.
Τα σημειωματάρια είναι ένα πολύ σημαντικό μέρος της διαδικασίας επιστήμης δεδομένων. Μπορούν να χρησιμοποιηθούν για την Εξερευνητική Ανάλυση Δεδομένων (EDA), την εκπαίδευση ενός μοντέλου σε υπολογιστικό cluster, ή την ανάπτυξη ενός endpoint σε cluster πρόβλεψης.
Για να δημιουργήσετε ένα Σημειωματάριο, χρειάζεστε έναν υπολογιστικό κόμβο που εξυπηρετεί την υποδομή του jupyter notebook. Επιστρέψτε στο Azure ML workspace και κάντε κλικ στις Υπολογιστικές Μονάδες. Στη λίστα των υπολογιστικών μονάδων θα πρέπει να δείτε την υπολογιστική μονάδα που δημιουργήσαμε νωρίτερα.
- Στην ενότητα Εφαρμογές, κάντε κλικ στην επιλογή Jupyter.
- Τσεκάρετε το κουτί "Ναι, καταλαβαίνω" και κάντε κλικ στο κουμπί Συνέχεια.

- Αυτό θα ανοίξει μια νέα καρτέλα του προγράμματος περιήγησης με την υποδομή του jupyter notebook σας όπως φαίνεται παρακάτω. Κάντε κλικ στο κουμπί "Νέο" για να δημιουργήσετε ένα σημειωματάριο.

Τώρα που έχουμε ένα Σημειωματάριο, μπορούμε να ξεκινήσουμε την εκπαίδευση του μοντέλου με το Azure ML SDK.
2.5 Εκπαίδευση μοντέλου
Πρώτα απ' όλα, αν έχετε οποιαδήποτε αμφιβολία, ανατρέξτε στην τεκμηρίωση του Azure ML SDK. Περιέχει όλες τις απαραίτητες πληροφορίες για να κατανοήσετε τις ενότητες που θα δούμε σε αυτό το μάθημα.
2.5.1 Ρύθμιση Workspace, πειράματος, υπολογιστικού cluster και συνόλου δεδομένων
Πρέπει να φορτώσετε το workspace από το αρχείο ρύθμισης χρησιμοποιώντας τον παρακάτω κώδικα:
from azureml.core import Workspace
ws = Workspace.from_config()
Αυτό επιστρέφει ένα αντικείμενο τύπου Workspace που αντιπροσωπεύει το workspace. Στη συνέχεια, πρέπει να δημιουργήσετε ένα experiment χρησιμοποιώντας τον παρακάτω κώδικα:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Για να αποκτήσετε ή να δημιουργήσετε ένα πείραμα από ένα workspace, ζητάτε το πείραμα χρησιμοποιώντας το όνομα του πειράματος. Το όνομα του πειράματος πρέπει να έχει 3-36 χαρακτήρες, να ξεκινά με γράμμα ή αριθμό και να περιέχει μόνο γράμματα, αριθμούς, υπογραμμίσεις και παύλες. Εάν το πείραμα δεν βρεθεί στο workspace, δημιουργείται ένα νέο πείραμα.
Τώρα πρέπει να δημιουργήσετε ένα υπολογιστικό cluster για την εκπαίδευση χρησιμοποιώντας τον παρακάτω κώδικα. Σημειώστε ότι αυτό το βήμα μπορεί να διαρκέσει λίγα λεπτά.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Μπορείτε να αποκτήσετε το σύνολο δεδομένων από το workspace χρησιμοποιώντας το όνομα του συνόλου δεδομένων με τον εξής τρόπο:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 Ρύθμιση AutoML και εκπαίδευση
Για να ρυθμίσετε τη διαμόρφωση AutoML, χρησιμοποιήστε την κλάση AutoMLConfig.
Όπως περιγράφεται στην τεκμηρίωση, υπάρχουν πολλές παράμετροι με τις οποίες μπορείτε να πειραματιστείτε. Για αυτό το έργο, θα χρησιμοποιήσουμε τις εξής παραμέτρους:
experiment_timeout_minutes: Ο μέγιστος χρόνος (σε λεπτά) που επιτρέπεται να εκτελεστεί το πείραμα πριν σταματήσει αυτόματα και γίνουν διαθέσιμα τα αποτελέσματα.max_concurrent_iterations: Ο μέγιστος αριθμός ταυτόχρονων επαναλήψεων εκπαίδευσης που επιτρέπονται για το πείραμα.primary_metric: Η κύρια μετρική που χρησιμοποιείται για τον καθορισμό της κατάστασης του πειράματος.compute_target: Ο υπολογιστικός στόχος του Azure Machine Learning για την εκτέλεση του πειράματος AutoML.task: Ο τύπος της εργασίας που θα εκτελεστεί. Οι τιμές μπορεί να είναι 'classification', 'regression' ή 'forecasting' ανάλογα με τον τύπο του προβλήματος AutoML που θα λυθεί.training_data: Τα δεδομένα εκπαίδευσης που θα χρησιμοποιηθούν στο πείραμα. Πρέπει να περιέχουν χαρακτηριστικά εκπαίδευσης και μια στήλη ετικετών (προαιρετικά μια στήλη βαρών δείγματος).label_column_name: Το όνομα της στήλης ετικετών.path: Η πλήρης διαδρομή προς τον φάκελο έργου του Azure Machine Learning.enable_early_stopping: Εάν θα ενεργοποιηθεί η πρόωρη διακοπή εάν η βαθμολογία δεν βελτιώνεται βραχυπρόθεσμα.featurization: Δείκτης για το αν το βήμα χαρακτηριστικοποίησης πρέπει να γίνει αυτόματα ή όχι, ή αν πρέπει να χρησιμοποιηθεί προσαρμοσμένη χαρακτηριστικοποίηση.debug_log: Το αρχείο καταγραφής για την εγγραφή πληροφοριών αποσφαλμάτωσης.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Τώρα που έχετε ρυθμίσει τη διαμόρφωση σας, μπορείτε να εκπαιδεύσετε το μοντέλο χρησιμοποιώντας τον παρακάτω κώδικα. Αυτό το βήμα μπορεί να διαρκέσει έως και μία ώρα ανάλογα με το μέγεθος του cluster σας.
remote_run = experiment.submit(automl_config)
Μπορείτε να εκτελέσετε το widget RunDetails για να δείτε τα διάφορα πειράματα.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Ανάπτυξη μοντέλου και κατανάλωση endpoint με το Azure ML SDK
3.1 Αποθήκευση του καλύτερου μοντέλου
Το remote_run είναι ένα αντικείμενο τύπου AutoMLRun. Αυτό το αντικείμενο περιέχει τη μέθοδο get_output() που επιστρέφει την καλύτερη εκτέλεση και το αντίστοιχο εκπαιδευμένο μοντέλο.
best_run, fitted_model = remote_run.get_output()
Μπορείτε να δείτε τις παραμέτρους που χρησιμοποιήθηκαν για το καλύτερο μοντέλο απλώς εκτυπώνοντας το fitted_model και να δείτε τις ιδιότητες του καλύτερου μοντέλου χρησιμοποιώντας τη μέθοδο get_properties().
best_run.get_properties()
Τώρα καταχωρίστε το μοντέλο με τη μέθοδο register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Ανάπτυξη μοντέλου
Αφού αποθηκευτεί το καλύτερο μοντέλο, μπορούμε να το αναπτύξουμε με την κλάση InferenceConfig. Το InferenceConfig αντιπροσωπεύει τις ρυθμίσεις διαμόρφωσης για ένα προσαρμοσμένο περιβάλλον που χρησιμοποιείται για την ανάπτυξη. Η κλάση AciWebservice αντιπροσωπεύει ένα μοντέλο μηχανικής μάθησης που έχει αναπτυχθεί ως endpoint web service στο Azure Container Instances. Μια αναπτυγμένη υπηρεσία δημιουργείται από ένα μοντέλο, ένα script και σχετικά αρχεία. Το αποτέλεσμα είναι ένα web service με ισορροπημένο φορτίο, HTTP endpoint με REST API. Μπορείτε να
response = aci_service.run(input_data=test_sample)
response
Αυτό θα πρέπει να επιστρέψει '{"result": [false]}'. Αυτό σημαίνει ότι τα δεδομένα του ασθενούς που στείλαμε στο endpoint δημιούργησαν την πρόβλεψη false, που σημαίνει ότι αυτό το άτομο δεν είναι πιθανό να πάθει καρδιακή προσβολή.
Συγχαρητήρια! Μόλις καταναλώσατε το μοντέλο που αναπτύχθηκε και εκπαιδεύτηκε στο Azure ML με το Azure ML SDK!
NOTE: Μόλις ολοκληρώσετε το έργο, μην ξεχάσετε να διαγράψετε όλους τους πόρους.
🚀 Πρόκληση
Υπάρχουν πολλά άλλα πράγματα που μπορείτε να κάνετε μέσω του SDK, δυστυχώς, δεν μπορούμε να τα καλύψουμε όλα σε αυτό το μάθημα. Αλλά καλά νέα, η εκμάθηση του πώς να περιηγείστε στη τεκμηρίωση του SDK μπορεί να σας βοηθήσει πολύ. Ρίξτε μια ματιά στη τεκμηρίωση του Azure ML SDK και βρείτε την κλάση Pipeline που σας επιτρέπει να δημιουργείτε pipelines. Ένα Pipeline είναι μια συλλογή βημάτων που μπορούν να εκτελεστούν ως μια ροή εργασίας.
ΥΠΟΔΕΙΞΗ: Μεταβείτε στη τεκμηρίωση του SDK και πληκτρολογήστε λέξεις-κλειδιά στη γραμμή αναζήτησης όπως "Pipeline". Θα πρέπει να δείτε την κλάση azureml.pipeline.core.Pipeline στα αποτελέσματα αναζήτησης.
Κουίζ μετά το μάθημα
Ανασκόπηση & Αυτομελέτη
Σε αυτό το μάθημα, μάθατε πώς να εκπαιδεύετε, να αναπτύσσετε και να καταναλώνετε ένα μοντέλο για την πρόβλεψη του κινδύνου καρδιακής ανεπάρκειας με το Azure ML SDK στο cloud. Ελέγξτε αυτή τη τεκμηρίωση για περισσότερες πληροφορίες σχετικά με το Azure ML SDK. Προσπαθήστε να δημιουργήσετε το δικό σας μοντέλο με το Azure ML SDK.
Εργασία
Έργο Επιστήμης Δεδομένων χρησιμοποιώντας το Azure ML SDK
Αποποίηση Ευθύνης:
Αυτό το έγγραφο έχει μεταφραστεί χρησιμοποιώντας την υπηρεσία αυτόματης μετάφρασης AI Co-op Translator. Παρόλο που καταβάλλουμε κάθε προσπάθεια για ακρίβεια, παρακαλούμε να έχετε υπόψη ότι οι αυτόματες μεταφράσεις ενδέχεται να περιέχουν λάθη ή ανακρίβειες. Το πρωτότυπο έγγραφο στη μητρική του γλώσσα θα πρέπει να θεωρείται η αυθεντική πηγή. Για κρίσιμες πληροφορίες, συνιστάται επαγγελματική ανθρώπινη μετάφραση. Δεν φέρουμε ευθύνη για τυχόν παρεξηγήσεις ή εσφαλμένες ερμηνείες που προκύπτουν από τη χρήση αυτής της μετάφρασης.