20 KiB
Datenwissenschaft in der Cloud: Der "Azure ML SDK"-Ansatz
 |
|---|
| Datenwissenschaft in der Cloud: Azure ML SDK - Sketchnote von @nitya |
Inhaltsverzeichnis:
- Datenwissenschaft in der Cloud: Der "Azure ML SDK"-Ansatz
Quiz vor der Vorlesung
1. Einführung
1.1 Was ist Azure ML SDK?
Datenwissenschaftler und KI-Entwickler nutzen das Azure Machine Learning SDK, um maschinelle Lern-Workflows mit dem Azure Machine Learning-Dienst zu erstellen und auszuführen. Sie können in jeder Python-Umgebung mit dem Dienst interagieren, einschließlich Jupyter Notebooks, Visual Studio Code oder Ihrer bevorzugten Python-IDE.
Wichtige Bereiche des SDK umfassen:
- Erkunden, Vorbereiten und Verwalten des Lebenszyklus Ihrer Datensätze, die in maschinellen Lernexperimenten verwendet werden.
- Verwalten von Cloud-Ressourcen für Überwachung, Protokollierung und Organisation Ihrer maschinellen Lernexperimente.
- Modelle entweder lokal oder mit Cloud-Ressourcen trainieren, einschließlich GPU-beschleunigtem Modelltraining.
- Automatisiertes maschinelles Lernen verwenden, das Konfigurationsparameter und Trainingsdaten akzeptiert. Es iteriert automatisch durch Algorithmen und Hyperparameter-Einstellungen, um das beste Modell für Vorhersagen zu finden.
- Webdienste bereitstellen, um Ihre trainierten Modelle in RESTful-Dienste umzuwandeln, die in jeder Anwendung genutzt werden können.
Erfahren Sie mehr über das Azure Machine Learning SDK
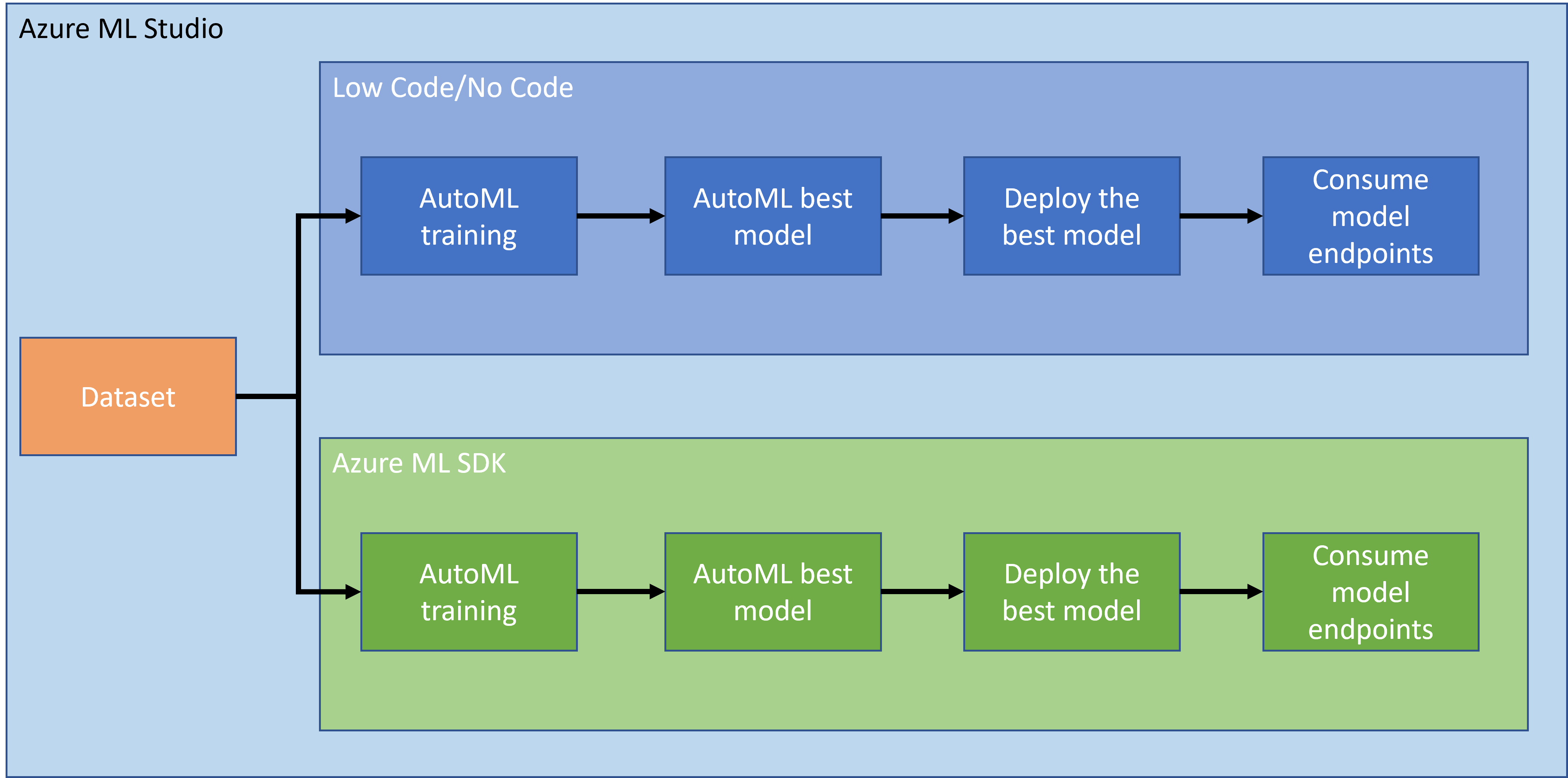
In der vorherigen Lektion haben wir gesehen, wie man ein Modell auf eine Low-Code/No-Code-Weise trainiert, bereitstellt und nutzt. Wir haben den Herzinsuffizienz-Datensatz verwendet, um ein Vorhersagemodell für Herzinsuffizienz zu erstellen. In dieser Lektion werden wir genau dasselbe tun, aber mit dem Azure Machine Learning SDK.
1.2 Einführung in das Projekt und den Datensatz zur Vorhersage von Herzinsuffizienz
Sehen Sie sich hier die Einführung in das Projekt und den Datensatz zur Vorhersage von Herzinsuffizienz an.
2. Training eines Modells mit dem Azure ML SDK
2.1 Erstellen eines Azure ML-Arbeitsbereichs
Der Einfachheit halber arbeiten wir in einem Jupyter Notebook. Dies setzt voraus, dass Sie bereits einen Arbeitsbereich und eine Compute-Instanz haben. Wenn Sie bereits einen Arbeitsbereich haben, können Sie direkt zum Abschnitt 2.3 Notebook-Erstellung springen.
Falls nicht, folgen Sie bitte den Anweisungen im Abschnitt 2.1 Erstellen eines Azure ML-Arbeitsbereichs in der vorherigen Lektion, um einen Arbeitsbereich zu erstellen.
2.2 Erstellen einer Compute-Instanz
Gehen Sie im Azure ML-Arbeitsbereich, den wir zuvor erstellt haben, zum Menü "Compute" und Sie sehen die verschiedenen verfügbaren Compute-Ressourcen.

Lassen Sie uns eine Compute-Instanz erstellen, um ein Jupyter Notebook bereitzustellen.
- Klicken Sie auf die Schaltfläche + Neu.
- Geben Sie Ihrer Compute-Instanz einen Namen.
- Wählen Sie Ihre Optionen: CPU oder GPU, VM-Größe und Anzahl der Kerne.
- Klicken Sie auf die Schaltfläche Erstellen.
Herzlichen Glückwunsch, Sie haben gerade eine Compute-Instanz erstellt! Wir werden diese Compute-Instanz verwenden, um ein Notebook im Abschnitt Erstellen von Notebooks zu erstellen.
2.3 Laden des Datensatzes
Falls Sie den Datensatz noch nicht hochgeladen haben, sehen Sie sich den Abschnitt 2.3 Laden des Datensatzes in der vorherigen Lektion an.
2.4 Erstellen von Notebooks
HINWEIS: Für den nächsten Schritt können Sie entweder ein neues Notebook von Grund auf neu erstellen oder das Notebook, das wir erstellt haben, in Ihrem Azure ML Studio hochladen. Um es hochzuladen, klicken Sie einfach auf das Menü "Notebook" und laden Sie das Notebook hoch.
Notebooks sind ein wirklich wichtiger Bestandteil des Datenwissenschaftsprozesses. Sie können verwendet werden, um Explorative Datenanalyse (EDA) durchzuführen, einen Compute-Cluster aufzurufen, um ein Modell zu trainieren, oder einen Inferenz-Cluster aufzurufen, um einen Endpunkt bereitzustellen.
Um ein Notebook zu erstellen, benötigen wir einen Compute-Knoten, der die Jupyter Notebook-Instanz bereitstellt. Gehen Sie zurück zum Azure ML-Arbeitsbereich und klicken Sie auf Compute-Instanzen. In der Liste der Compute-Instanzen sollten Sie die Compute-Instanz, die wir zuvor erstellt haben, sehen.
- Klicken Sie im Abschnitt Anwendungen auf die Option Jupyter.
- Aktivieren Sie das Kästchen "Ja, ich verstehe" und klicken Sie auf die Schaltfläche Weiter.

- Dies sollte eine neue Browser-Registerkarte mit Ihrer Jupyter Notebook-Instanz öffnen. Klicken Sie auf die Schaltfläche "Neu", um ein Notebook zu erstellen.

Jetzt, da wir ein Notebook haben, können wir mit dem Training des Modells mit Azure ML SDK beginnen.
2.5 Training eines Modells
Falls Sie jemals Zweifel haben, sehen Sie sich die Azure ML SDK-Dokumentation an. Sie enthält alle notwendigen Informationen, um die Module zu verstehen, die wir in dieser Lektion behandeln werden.
2.5.1 Einrichtung von Arbeitsbereich, Experiment, Compute-Cluster und Datensatz
Sie müssen den Arbeitsbereich aus der Konfigurationsdatei mit folgendem Code laden:
from azureml.core import Workspace
ws = Workspace.from_config()
Dies gibt ein Objekt vom Typ Workspace zurück, das den Arbeitsbereich darstellt. Anschließend müssen Sie ein Experiment mit folgendem Code erstellen:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Um ein Experiment aus einem Arbeitsbereich zu erhalten oder zu erstellen, fordern Sie das Experiment mit dem Experimentnamen an. Der Experimentname muss 3-36 Zeichen lang sein, mit einem Buchstaben oder einer Zahl beginnen und darf nur Buchstaben, Zahlen, Unterstriche und Bindestriche enthalten. Wenn das Experiment im Arbeitsbereich nicht gefunden wird, wird ein neues Experiment erstellt.
Nun müssen Sie einen Compute-Cluster für das Training erstellen, indem Sie den folgenden Code verwenden. Beachten Sie, dass dieser Schritt einige Minuten dauern kann.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Sie können den Datensatz aus dem Arbeitsbereich mit dem Datensatznamen auf folgende Weise abrufen:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 AutoML-Konfiguration und Training
Um die AutoML-Konfiguration festzulegen, verwenden Sie die AutoMLConfig-Klasse.
Wie in der Dokumentation beschrieben, gibt es viele Parameter, mit denen Sie spielen können. Für dieses Projekt verwenden wir die folgenden Parameter:
experiment_timeout_minutes: Die maximale Zeit (in Minuten), die das Experiment laufen darf, bevor es automatisch gestoppt wird und die Ergebnisse automatisch verfügbar gemacht werden.max_concurrent_iterations: Die maximale Anzahl gleichzeitiger Trainingsiterationen, die für das Experiment erlaubt sind.primary_metric: Die Hauptmetrik, die verwendet wird, um den Status des Experiments zu bestimmen.compute_target: Das Azure Machine Learning-Compute-Ziel, auf dem das automatisierte maschinelle Lernexperiment ausgeführt wird.task: Die Art der Aufgabe, die ausgeführt werden soll. Werte können 'classification', 'regression' oder 'forecasting' sein, je nach Art des zu lösenden automatisierten ML-Problems.training_data: Die Trainingsdaten, die innerhalb des Experiments verwendet werden sollen. Sie sollten sowohl Trainingsmerkmale als auch eine Label-Spalte (optional eine Spalte mit Gewichtungen) enthalten.label_column_name: Der Name der Label-Spalte.path: Der vollständige Pfad zum Azure Machine Learning-Projektordner.enable_early_stopping: Ob eine vorzeitige Beendigung aktiviert werden soll, wenn sich die Punktzahl kurzfristig nicht verbessert.featurization: Indikator dafür, ob der Featurization-Schritt automatisch durchgeführt werden soll oder nicht, oder ob eine benutzerdefinierte Featurization verwendet werden soll.debug_log: Die Protokolldatei, in die Debug-Informationen geschrieben werden sollen.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Jetzt, da Sie Ihre Konfiguration festgelegt haben, können Sie das Modell mit folgendem Code trainieren. Dieser Schritt kann je nach Clustergröße bis zu einer Stunde dauern.
remote_run = experiment.submit(automl_config)
Sie können das RunDetails-Widget ausführen, um die verschiedenen Experimente anzuzeigen.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Modellbereitstellung und Nutzung des Endpunkts mit dem Azure ML SDK
3.1 Speichern des besten Modells
Das remote_run ist ein Objekt vom Typ AutoMLRun. Dieses Objekt enthält die Methode get_output(), die den besten Lauf und das entsprechende angepasste Modell zurückgibt.
best_run, fitted_model = remote_run.get_output()
Sie können die Parameter des besten Modells anzeigen, indem Sie einfach das fitted_model ausgeben, und die Eigenschaften des besten Modells mit der Methode get_properties() anzeigen.
best_run.get_properties()
Registrieren Sie nun das Modell mit der Methode register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Modellbereitstellung
Sobald das beste Modell gespeichert ist, können wir es mit der Klasse InferenceConfig bereitstellen. InferenceConfig repräsentiert die Konfigurationseinstellungen für eine benutzerdefinierte Umgebung, die für die Bereitstellung verwendet wird. Die Klasse AciWebservice repräsentiert ein maschinelles Lernmodell, das als Webdienst-Endpunkt auf Azure Container Instances bereitgestellt wird. Ein bereitgestellter Dienst wird aus einem Modell, Skript und zugehörigen Dateien erstellt. Der resultierende Webdienst ist ein Lastenausgleichs-HTTP-Endpunkt mit einer REST-API. Sie können Daten an diese API senden und die Vorhersage des Modells erhalten.
Das Modell wird mit der Methode deploy bereitgestellt.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Dieser Schritt sollte einige Minuten dauern.
3.3 Nutzung des Endpunkts
Sie nutzen Ihren Endpunkt, indem Sie eine Beispiel-Eingabe erstellen:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Und dann können Sie diese Eingabe an Ihr Modell senden, um eine Vorhersage zu erhalten:
response = aci_service.run(input_data=test_sample)
response
Dies sollte '{"result": [false]}' ausgeben. Das bedeutet, dass die Patienteneingabe, die wir an den Endpunkt gesendet haben, die Vorhersage false erzeugt hat, was bedeutet, dass diese Person wahrscheinlich keinen Herzinfarkt erleiden wird.
Herzlichen Glückwunsch! Sie haben gerade das Modell konsumiert, das mit dem Azure ML SDK auf Azure ML bereitgestellt und trainiert wurde!
NOTE: Sobald Sie mit dem Projekt fertig sind, vergessen Sie nicht, alle Ressourcen zu löschen.
🚀 Herausforderung
Es gibt viele andere Dinge, die Sie mit dem SDK tun können. Leider können wir nicht alles in dieser Lektion behandeln. Aber gute Nachrichten: Wenn Sie lernen, wie Sie die SDK-Dokumentation durchforsten, können Sie auf eigene Faust viel erreichen. Schauen Sie sich die Azure ML SDK-Dokumentation an und finden Sie die Pipeline-Klasse, die es Ihnen ermöglicht, Pipelines zu erstellen. Eine Pipeline ist eine Sammlung von Schritten, die als Workflow ausgeführt werden können.
HINWEIS: Gehen Sie zur SDK-Dokumentation und geben Sie Schlüsselwörter wie "Pipeline" in die Suchleiste ein. Sie sollten die Klasse azureml.pipeline.core.Pipeline in den Suchergebnissen finden.
Quiz nach der Vorlesung
Rückblick & Selbststudium
In dieser Lektion haben Sie gelernt, wie Sie ein Modell trainieren, bereitstellen und konsumieren, um das Risiko eines Herzinfarkts mit dem Azure ML SDK in der Cloud vorherzusagen. Schauen Sie sich diese Dokumentation für weitere Informationen über das Azure ML SDK an. Versuchen Sie, Ihr eigenes Modell mit dem Azure ML SDK zu erstellen.
Aufgabe
Data Science Projekt mit Azure ML SDK
Haftungsausschluss:
Dieses Dokument wurde mithilfe des KI-Übersetzungsdienstes Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, weisen wir darauf hin, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die aus der Nutzung dieser Übersetzung entstehen.