18 KiB
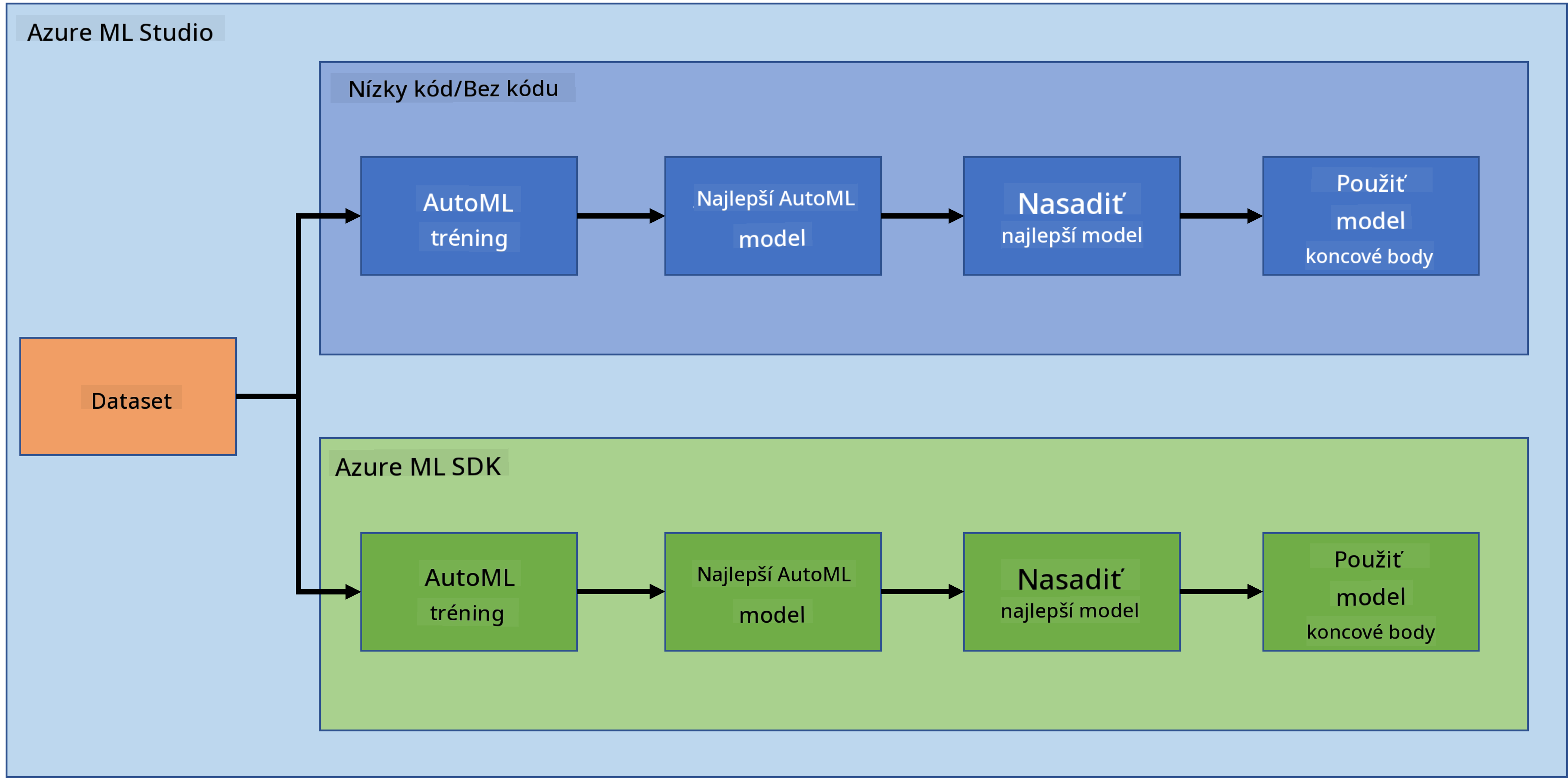
Data Science v cloude: Cesta "Azure ML SDK"
 |
|---|
| Data Science v cloude: Azure ML SDK - Sketchnote od @nitya |
Obsah:
- Data Science v cloude: Cesta "Azure ML SDK"
Kvíz pred prednáškou
1. Úvod
1.1 Čo je Azure ML SDK?
Data scientisti a vývojári AI používajú Azure Machine Learning SDK na vytváranie a spúšťanie workflowov strojového učenia pomocou služby Azure Machine Learning. So službou môžete pracovať v akomkoľvek prostredí Pythonu, vrátane Jupyter Notebookov, Visual Studio Code alebo vášho obľúbeného Python IDE.
Kľúčové oblasti SDK zahŕňajú:
- Preskúmanie, príprava a správa životného cyklu datasetov používaných v experimentoch strojového učenia.
- Správa cloudových zdrojov na monitorovanie, logovanie a organizovanie experimentov strojového učenia.
- Tréning modelov buď lokálne, alebo pomocou cloudových zdrojov, vrátane tréningu modelov akcelerovaných GPU.
- Použitie automatizovaného strojového učenia, ktoré prijíma konfiguračné parametre a tréningové dáta. Automaticky iteruje cez algoritmy a nastavenia hyperparametrov, aby našiel najlepší model na predikcie.
- Nasadenie webových služieb na konverziu vašich trénovaných modelov na RESTful služby, ktoré môžu byť využité v akejkoľvek aplikácii.
Viac informácií o Azure Machine Learning SDK
V predchádzajúcej lekcii sme videli, ako trénovať, nasadiť a využívať model pomocou prístupu Low code/No code. Použili sme dataset o zlyhaní srdca na generovanie modelu predikcie zlyhania srdca. V tejto lekcii urobíme presne to isté, ale pomocou Azure Machine Learning SDK.
1.2 Projekt predikcie zlyhania srdca a úvod do datasetu
Pozrite si tu úvod do projektu predikcie zlyhania srdca a datasetu.
2. Tréning modelu pomocou Azure ML SDK
2.1 Vytvorenie Azure ML pracovného priestoru
Pre jednoduchosť budeme pracovať v jupyter notebooku. To znamená, že už máte pracovný priestor a výpočtový uzol. Ak už máte pracovný priestor, môžete preskočiť priamo na sekciu 2.3 Vytváranie notebookov.
Ak nie, postupujte podľa pokynov v sekcii 2.1 Vytvorenie Azure ML pracovného priestoru v predchádzajúcej lekcii na vytvorenie pracovného priestoru.
2.2 Vytvorenie výpočtového uzla
V Azure ML pracovnom priestore, ktorý sme vytvorili skôr, prejdite do menu Compute a uvidíte rôzne dostupné výpočtové zdroje.
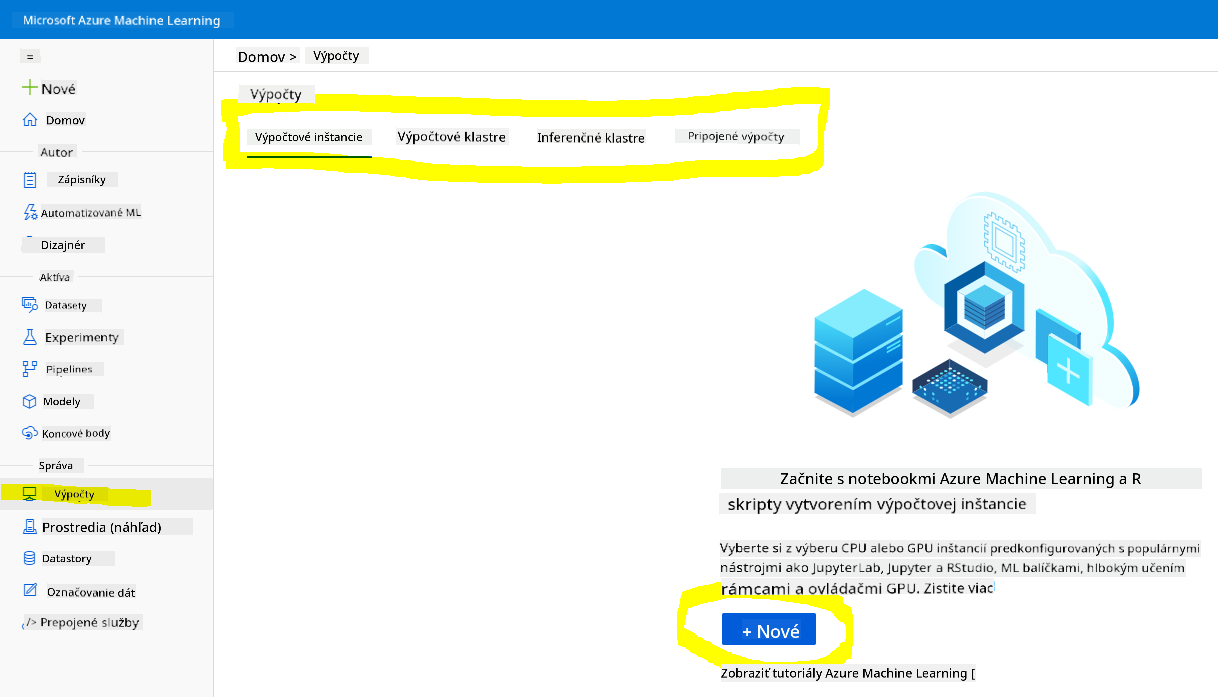
Vytvorme výpočtový uzol na zriadenie jupyter notebooku.
- Kliknite na tlačidlo + New.
- Dajte názov vášmu výpočtovému uzlu.
- Vyberte možnosti: CPU alebo GPU, veľkosť VM a počet jadier.
- Kliknite na tlačidlo Create.
Gratulujeme, práve ste vytvorili výpočtový uzol! Tento výpočtový uzol použijeme na vytvorenie notebooku v sekcii Vytváranie notebookov.
2.3 Načítanie datasetu
Ak ste dataset ešte nenahrali, pozrite si sekciu 2.3 Načítanie datasetu v predchádzajúcej lekcii.
2.4 Vytváranie notebookov
POZNÁMKA: Pre ďalší krok môžete buď vytvoriť nový notebook od začiatku, alebo nahrať notebook, ktorý sme vytvorili do vášho Azure ML Studio. Na jeho nahratie jednoducho kliknite na menu "Notebook" a nahrajte notebook.
Notebooky sú veľmi dôležitou súčasťou procesu data science. Môžu byť použité na vykonávanie prieskumných analýz dát (EDA), volanie výpočtového klastru na tréning modelu, alebo volanie inferenčného klastru na nasadenie endpointu.
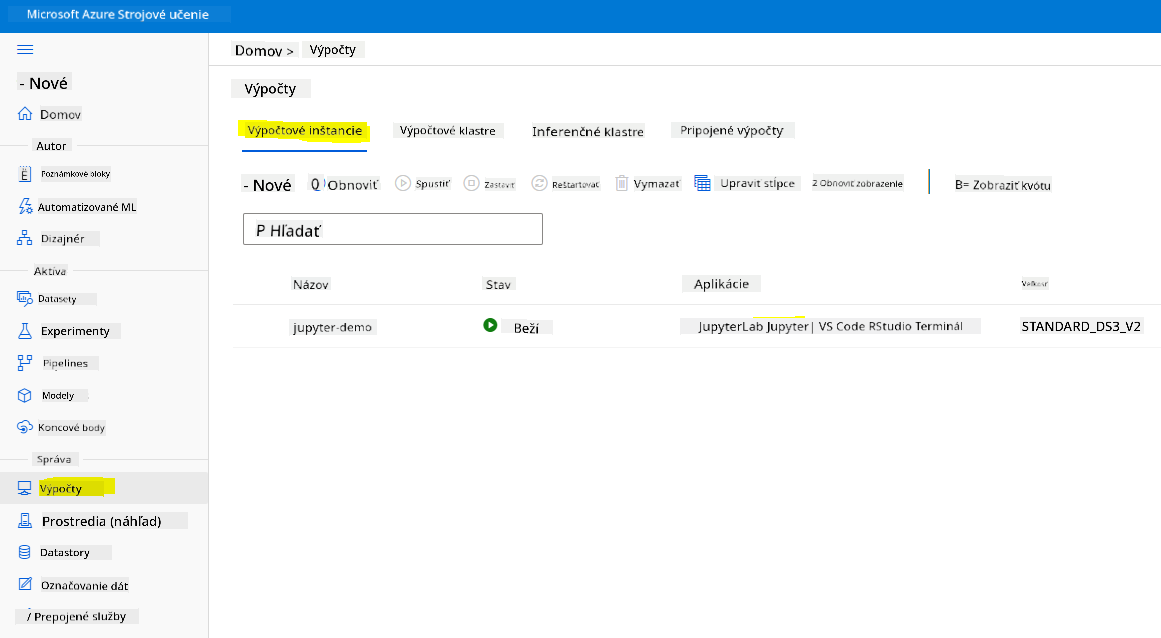
Na vytvorenie notebooku potrebujeme výpočtový uzol, ktorý poskytuje jupyter notebook. Vráťte sa do Azure ML pracovného priestoru a kliknite na Compute instances. V zozname výpočtových uzlov by ste mali vidieť výpočtový uzol, ktorý sme vytvorili skôr.
- V sekcii Applications kliknite na možnosť Jupyter.
- Zaškrtnite políčko "Yes, I understand" a kliknite na tlačidlo Continue.
- Toto by malo otvoriť nový prehliadačový tab s vaším jupyter notebookom. Kliknite na tlačidlo "New" na vytvorenie notebooku.
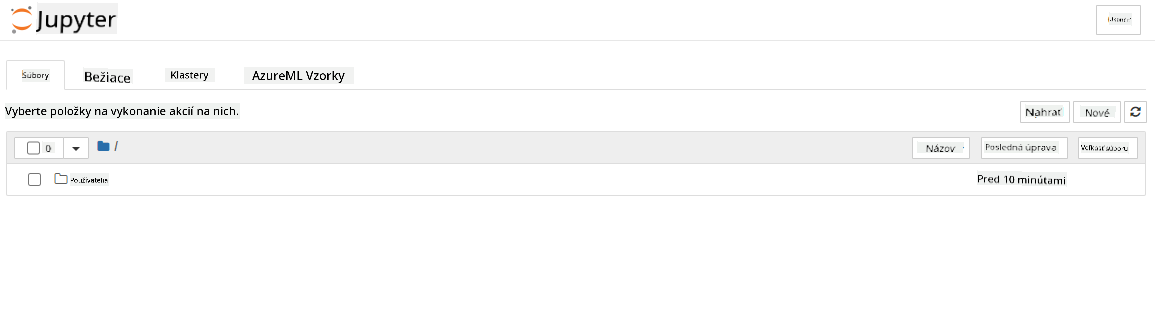
Teraz, keď máme notebook, môžeme začať trénovať model pomocou Azure ML SDK.
2.5 Tréning modelu
Ak máte akékoľvek pochybnosti, pozrite si dokumentáciu Azure ML SDK. Obsahuje všetky potrebné informácie na pochopenie modulov, ktoré uvidíme v tejto lekcii.
2.5.1 Nastavenie pracovného priestoru, experimentu, výpočtového klastru a datasetu
Pracovný priestor načítate z konfiguračného súboru pomocou nasledujúceho kódu:
from azureml.core import Workspace
ws = Workspace.from_config()
Toto vráti objekt typu Workspace, ktorý reprezentuje pracovný priestor. Potom musíte vytvoriť experiment pomocou nasledujúceho kódu:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Na získanie alebo vytvorenie experimentu z pracovného priestoru požiadate experiment pomocou jeho názvu. Názov experimentu musí mať 3-36 znakov, začínať písmenom alebo číslom a môže obsahovať iba písmená, čísla, podčiarkovníky a pomlčky. Ak experiment nie je nájdený v pracovnom priestore, vytvorí sa nový experiment.
Teraz musíte vytvoriť výpočtový klaster na tréning pomocou nasledujúceho kódu. Upozorňujeme, že tento krok môže trvať niekoľko minút.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Dataset môžete získať z pracovného priestoru pomocou názvu datasetu nasledujúcim spôsobom:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 Konfigurácia AutoML a tréning
Na nastavenie konfigurácie AutoML použite AutoMLConfig triedu.
Ako je popísané v dokumentácii, existuje veľa parametrov, s ktorými môžete pracovať. Pre tento projekt použijeme nasledujúce parametre:
experiment_timeout_minutes: Maximálny čas (v minútach), ktorý je experimentu povolený pred automatickým zastavením a sprístupnením výsledkov.max_concurrent_iterations: Maximálny počet súbežných tréningových iterácií povolených pre experiment.primary_metric: Primárna metrika používaná na určenie stavu experimentu.compute_target: Výpočtový cieľ Azure Machine Learning na spustenie experimentu automatizovaného strojového učenia.task: Typ úlohy na spustenie. Hodnoty môžu byť 'classification', 'regression' alebo 'forecasting' v závislosti od typu problému automatizovaného ML.training_data: Tréningové dáta, ktoré sa majú použiť v rámci experimentu. Mali by obsahovať tréningové vlastnosti a stĺpec s označením (voliteľne stĺpec s váhami vzoriek).label_column_name: Názov stĺpca s označením.path: Celá cesta k priečinku projektu Azure Machine Learning.enable_early_stopping: Či povoliť predčasné ukončenie, ak sa skóre krátkodobo nezlepšuje.featurization: Indikátor, či má byť krok featurizácie vykonaný automaticky alebo nie, alebo či má byť použitá prispôsobená featurizácia.debug_log: Súbor logov na zapisovanie informácií o ladení.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Teraz, keď máte nastavenú konfiguráciu, môžete model trénovať pomocou nasledujúceho kódu. Tento krok môže trvať až hodinu v závislosti od veľkosti vášho klastru.
remote_run = experiment.submit(automl_config)
Môžete spustiť widget RunDetails na zobrazenie rôznych experimentov.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Nasadenie modelu a využitie endpointu pomocou Azure ML SDK
3.1 Uloženie najlepšieho modelu
remote_run je objekt typu AutoMLRun. Tento objekt obsahuje metódu get_output(), ktorá vráti najlepší beh a zodpovedajúci trénovaný model.
best_run, fitted_model = remote_run.get_output()
Parametre použité pre najlepší model môžete vidieť jednoducho vytlačením fitted_model a vlastnosti najlepšieho modelu pomocou metódy get_properties().
best_run.get_properties()
Teraz zaregistrujte model pomocou metódy register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Nasadenie modelu
Keď je najlepší model uložený, môžeme ho nasadiť pomocou triedy InferenceConfig. InferenceConfig predstavuje konfiguračné nastavenia pre vlastné prostredie použité na nasadenie. Trieda AciWebservice predstavuje model strojového učenia nasadený ako endpoint webovej služby na Azure Container Instances. Nasadená služba je vyvážený HTTP endpoint s REST API. Môžete poslať dáta na toto API a získať predikciu vrátenú modelom.
Model je nasadený pomocou metódy deploy.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Tento krok by mal trvať niekoľko minút.
3.3 Využitie endpointu
Endpoint využijete vytvorením vzorového vstupu:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
A potom môžete tento vstup poslať vášmu modelu na predikciu:
response = aci_service.run(input_data=test_sample)
response
Toto by malo vrátiť '{"result": [false]}'. To znamená, že vstup pacienta, ktorý sme poslali na endpoint, vygeneroval predikciu false, čo znamená, že táto osoba pravdepodobne nedostane infarkt.
Gratulujeme! Práve ste použili model nasadený a trénovaný na Azure ML pomocou Azure ML SDK!
NOTE: Keď dokončíte projekt, nezabudnite vymazať všetky zdroje.
🚀 Výzva
Existuje mnoho ďalších vecí, ktoré môžete robiť prostredníctvom SDK, bohužiaľ, nemôžeme ich všetky prejsť v tejto lekcii. Dobrá správa je, že naučiť sa orientovať v dokumentácii SDK vám môže veľmi pomôcť. Pozrite si dokumentáciu Azure ML SDK a nájdite triedu Pipeline, ktorá vám umožňuje vytvárať pipeline. Pipeline je kolekcia krokov, ktoré môžu byť vykonané ako pracovný postup.
TIP: Prejdite na dokumentáciu SDK a zadajte kľúčové slová do vyhľadávacieho poľa, ako napríklad "Pipeline". Mali by ste mať triedu azureml.pipeline.core.Pipeline vo výsledkoch vyhľadávania.
Kvíz po prednáške
Prehľad & Samoštúdium
V tejto lekcii ste sa naučili, ako trénovať, nasadiť a používať model na predikciu rizika zlyhania srdca pomocou Azure ML SDK v cloude. Pozrite si túto dokumentáciu pre ďalšie informácie o Azure ML SDK. Skúste vytvoriť vlastný model pomocou Azure ML SDK.
Zadanie
Projekt Data Science pomocou Azure ML SDK
Upozornenie:
Tento dokument bol preložený pomocou služby AI prekladu Co-op Translator. Hoci sa snažíme o presnosť, prosím, berte na vedomie, že automatizované preklady môžu obsahovať chyby alebo nepresnosti. Pôvodný dokument v jeho pôvodnom jazyku by mal byť považovaný za autoritatívny zdroj. Pre kritické informácie sa odporúča profesionálny ľudský preklad. Nenesieme zodpovednosť za akékoľvek nedorozumenia alebo nesprávne interpretácie vyplývajúce z použitia tohto prekladu.