32 KiB
מדע הנתונים בענן: הדרך של "קוד מועט/ללא קוד"
 |
|---|
| מדע הנתונים בענן: קוד מועט - סקיצה מאת @nitya |
תוכן עניינים:
- מדע הנתונים בענן: הדרך של "קוד מועט/ללא קוד"
שאלון לפני ההרצאה
1. מבוא
1.1 מהו Azure Machine Learning?
פלטפורמת הענן Azure כוללת יותר מ-200 מוצרים ושירותי ענן שנועדו לעזור לך להביא פתרונות חדשים לחיים. מדעני נתונים משקיעים מאמצים רבים בחקר ועיבוד מקדים של נתונים, ובניסיון של סוגים שונים של אלגוריתמים לאימון מודלים כדי לייצר מודלים מדויקים. משימות אלו גוזלות זמן רב ולעיתים קרובות מנצלות בצורה לא יעילה חומרת מחשוב יקרה.
Azure ML היא פלטפורמה מבוססת ענן לבניית פתרונות למידת מכונה ותפעולם ב-Azure. היא כוללת מגוון רחב של תכונות ויכולות המסייעות למדעני נתונים להכין נתונים, לאמן מודלים, לפרסם שירותי חיזוי ולנטר את השימוש בהם. החשוב מכל, היא מסייעת להם להגדיל את היעילות על ידי אוטומציה של משימות רבות שגוזלות זמן רב בתהליך אימון המודלים; והיא מאפשרת להם להשתמש במשאבי מחשוב מבוססי ענן שמסוגלים להתמודד עם כמויות גדולות של נתונים תוך חיוב רק בעת השימוש בפועל.
Azure ML מספקת את כל הכלים שמפתחים ומדעני נתונים זקוקים להם עבור תהליכי העבודה של למידת מכונה. כלים אלו כוללים:
- Azure Machine Learning Studio: פורטל אינטרנטי ב-Azure Machine Learning המציע אפשרויות קוד מועט/ללא קוד לאימון מודלים, פריסה, אוטומציה, מעקב וניהול נכסים. הסטודיו משתלב עם Azure Machine Learning SDK לחוויית עבודה חלקה.
- Jupyter Notebooks: מאפשרים אבטיפוס מהיר ובדיקת מודלים.
- Azure Machine Learning Designer: מאפשר גרירה ושחרור של מודולים לבניית ניסויים ולאחר מכן פריסת צינורות עבודה בסביבת קוד מועט.
- ממשק AutoML: מבצע אוטומציה של משימות חוזרות בתהליך פיתוח מודלים, ומאפשר בניית מודלים בקנה מידה גבוה, ביעילות ובפרודוקטיביות, תוך שמירה על איכות המודל.
- תיוג נתונים: כלי עזר ללמידת מכונה שמבצע תיוג אוטומטי של נתונים.
- הרחבת למידת מכונה ל-Visual Studio Code: מספקת סביבת פיתוח מלאה לבניית וניהול פרויקטים של למידת מכונה.
- CLI ללמידת מכונה: מספק פקודות לניהול משאבי Azure ML משורת הפקודה.
- שילוב עם מסגרות קוד פתוח כמו PyTorch, TensorFlow, Scikit-learn ועוד רבות אחרות לאימון, פריסה וניהול תהליך למידת המכונה מקצה לקצה.
- MLflow: ספריית קוד פתוח לניהול מחזור החיים של ניסויי למידת מכונה. MLFlow Tracking הוא רכיב של MLflow שמבצע רישום ומעקב אחר מדדי האימון ופריטי המודל שלך, ללא תלות בסביבת הניסוי.
1.2 פרויקט חיזוי כשל לבבי:
אין ספק שיצירה ובנייה של פרויקטים היא הדרך הטובה ביותר לבחון את הכישורים והידע שלך. בשיעור זה, נחקור שתי דרכים שונות לבניית פרויקט מדע נתונים לחיזוי התקפי כשל לבבי ב-Azure ML Studio, דרך קוד מועט/ללא קוד ודרך Azure ML SDK, כפי שמוצג בתרשים הבא:
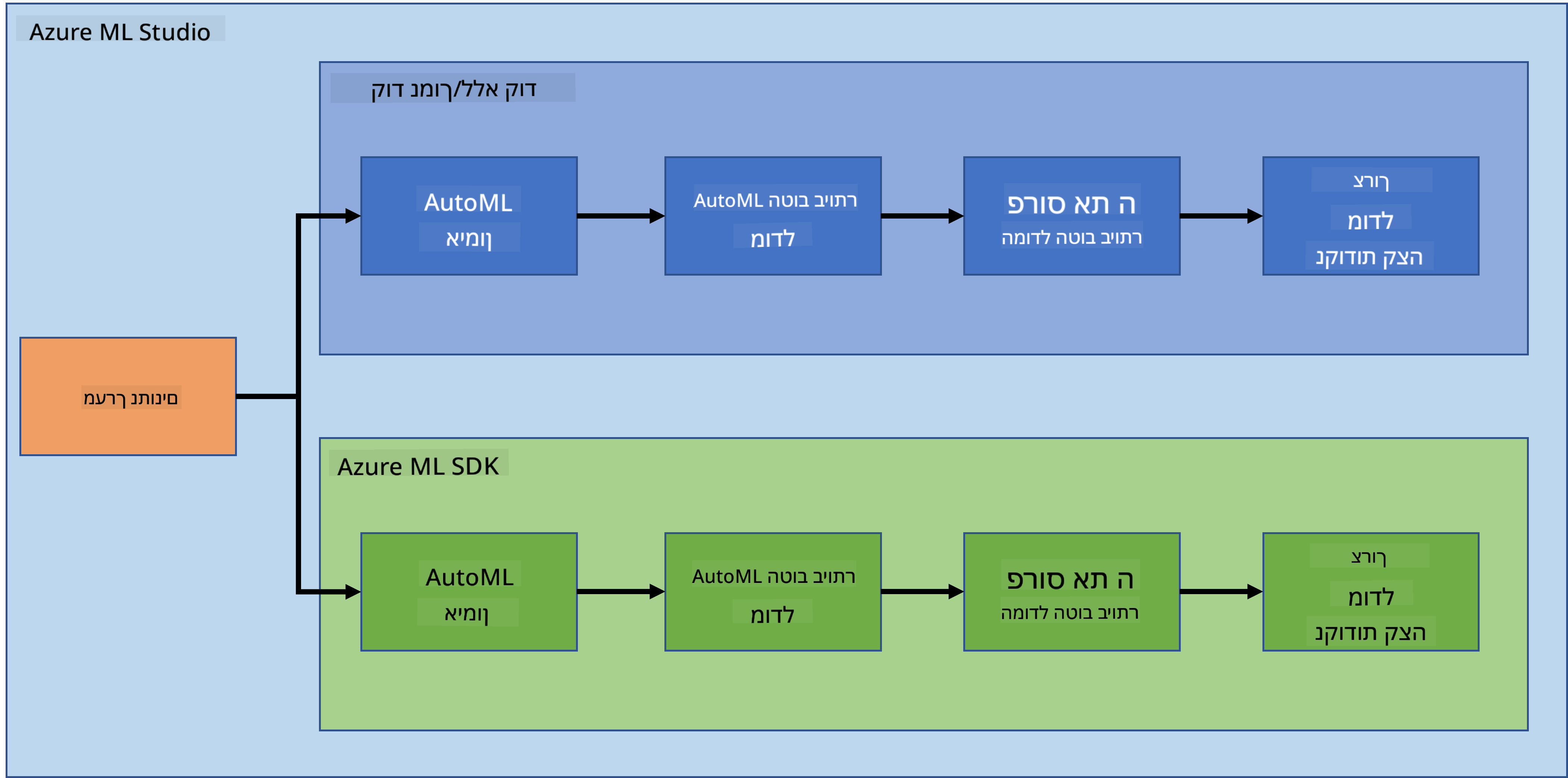
לכל דרך יש יתרונות וחסרונות משלה. הדרך של קוד מועט/ללא קוד קלה יותר להתחלה מכיוון שהיא כוללת אינטראקציה עם ממשק משתמש גרפי (GUI), ללא צורך בידע מוקדם בקוד. שיטה זו מאפשרת בדיקה מהירה של היתכנות הפרויקט ויצירת POC (הוכחת היתכנות). עם זאת, ככל שהפרויקט גדל ויש צורך בהכנה לייצור, לא ניתן ליצור משאבים דרך GUI בלבד. יש צורך באוטומציה תכנותית של כל התהליך, החל מיצירת משאבים ועד לפריסת מודל. כאן נכנס לתמונה הידע בשימוש ב-Azure ML SDK.
| קוד מועט/ללא קוד | Azure ML SDK | |
|---|---|---|
| ידע בקוד | לא נדרש | נדרש |
| זמן פיתוח | מהיר וקל | תלוי במומחיות בקוד |
| מוכן לייצור | לא | כן |
1.3 מערך הנתונים של כשל לבבי:
מחלות לב וכלי דם (CVDs) הן הגורם מספר 1 למוות ברחבי העולם, ומהוות 31% מכלל מקרי המוות. גורמי סיכון סביבתיים והתנהגותיים כמו עישון, תזונה לא בריאה והשמנת יתר, חוסר פעילות גופנית ושימוש מזיק באלכוהול יכולים לשמש כמאפיינים למודלים חיזויים. היכולת להעריך את הסבירות להתפתחות CVD יכולה להיות שימושית מאוד במניעת התקפים אצל אנשים בסיכון גבוה.
ב-Kaggle זמין מערך נתונים של כשל לבבי שנשתמש בו בפרויקט זה. ניתן להוריד את מערך הנתונים כעת. מדובר במערך נתונים טבלאי עם 13 עמודות (12 מאפיינים ועמודת יעד אחת) ו-299 שורות.
| שם משתנה | סוג | תיאור | דוגמה | |
|---|---|---|---|---|
| 1 | age | מספרי | גיל המטופל | 25 |
| 2 | anaemia | בוליאני | ירידה בתאי דם אדומים או בהמוגלובין | 0 או 1 |
| 3 | creatinine_phosphokinase | מספרי | רמת אנזים CPK בדם | 542 |
| 4 | diabetes | בוליאני | האם למטופל יש סוכרת | 0 או 1 |
| 5 | ejection_fraction | מספרי | אחוז הדם שיוצא מהלב בכל התכווצות | 45 |
| 6 | high_blood_pressure | בוליאני | האם למטופל יש יתר לחץ דם | 0 או 1 |
| 7 | platelets | מספרי | טסיות בדם | 149000 |
| 8 | serum_creatinine | מספרי | רמת קריאטינין בסרום בדם | 0.5 |
| 9 | serum_sodium | מספרי | רמת נתרן בסרום בדם | jun |
| 10 | sex | בוליאני | אישה או גבר | 0 או 1 |
| 11 | smoking | בוליאני | האם המטופל מעשן | 0 או 1 |
| 12 | time | מספרי | תקופת מעקב (ימים) | 4 |
| ---- | --------------------------- | ---------------- | ---------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [יעד] | בוליאני | האם המטופל נפטר במהלך תקופת המעקב | 0 או 1 |
לאחר שיש לך את מערך הנתונים, נוכל להתחיל את הפרויקט ב-Azure.
2. אימון מודל בקוד מועט/ללא קוד ב-Azure ML Studio
2.1 יצירת סביבת עבודה ב-Azure ML
כדי לאמן מודל ב-Azure ML, תחילה עליך ליצור סביבת עבודה ב-Azure ML. סביבת העבודה היא המשאב העליון ב-Azure Machine Learning, המספקת מקום מרכזי לעבודה עם כל הפריטים שאתה יוצר בעת השימוש ב-Azure Machine Learning. סביבת העבודה שומרת היסטוריה של כל ריצות האימון, כולל יומנים, מדדים, פלט ותמונת מצב של הסקריפטים שלך. מידע זה משמש לקביעת איזו ריצת אימון מייצרת את המודל הטוב ביותר. למידע נוסף
מומלץ להשתמש בדפדפן המעודכן ביותר התואם למערכת ההפעלה שלך. הדפדפנים הבאים נתמכים:
- Microsoft Edge (הגרסה החדשה, לא גרסת Microsoft Edge legacy)
- Safari (גרסה מעודכנת, למק בלבד)
- Chrome (גרסה מעודכנת)
- Firefox (גרסה מעודכנת)
כדי להשתמש ב-Azure Machine Learning, צור סביבת עבודה במנוי Azure שלך. לאחר מכן תוכל להשתמש בסביבת עבודה זו לניהול נתונים, משאבי מחשוב, קוד, מודלים ופריטים אחרים הקשורים לעומסי העבודה של למידת המכונה שלך.
הערה: המנוי שלך ב-Azure יחויב בסכום קטן עבור אחסון נתונים כל עוד סביבת העבודה של Azure Machine Learning קיימת במנוי שלך, ולכן אנו ממליצים למחוק את סביבת העבודה כאשר אינך משתמש בה יותר.
-
היכנס ל-פורטל Azure באמצעות האישורים של Microsoft המשויכים למנוי Azure שלך.
-
בחר +Create a resource
חפש "Machine Learning" ובחר את האריח של Machine Learning.
לחץ על כפתור "Create".
מלא את ההגדרות הבאות:
- מנוי: המנוי שלך ב-Azure
- קבוצת משאבים: צור או בחר קבוצת משאבים
- שם סביבת עבודה: הזן שם ייחודי לסביבת העבודה שלך
- אזור: בחר את האזור הגיאוגרפי הקרוב אליך
- חשבון אחסון: שים לב לחשבון האחסון החדש שיווצר עבור סביבת העבודה שלך
- Key vault: שים לב ל-Key Vault החדש שיווצר עבור סביבת העבודה שלך
- Application insights: שים לב למשאב Application Insights החדש שיווצר עבור סביבת העבודה שלך
- Container registry: אין (אחד ייווצר אוטומטית בפעם הראשונה שתפרוס מודל למיכל)
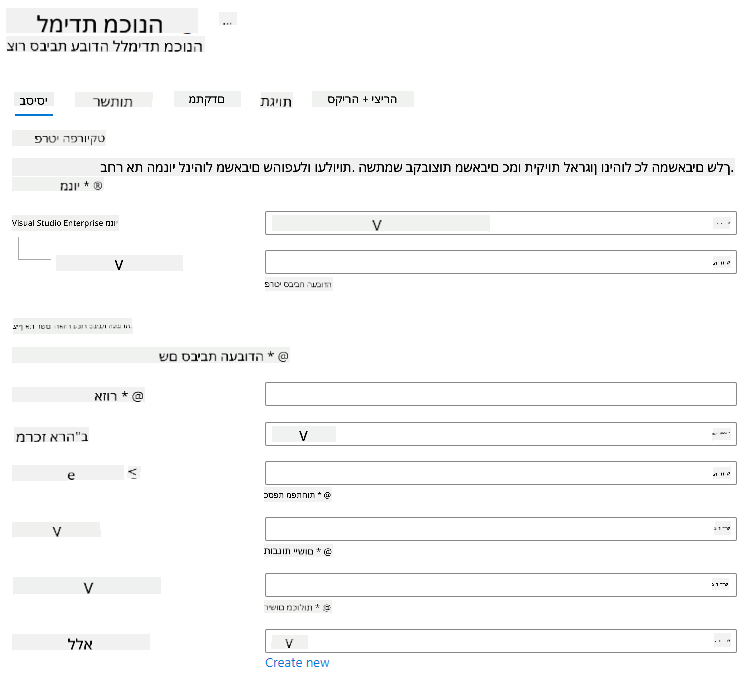
- לחץ על "Create + Review" ולאחר מכן על כפתור "Create".
-
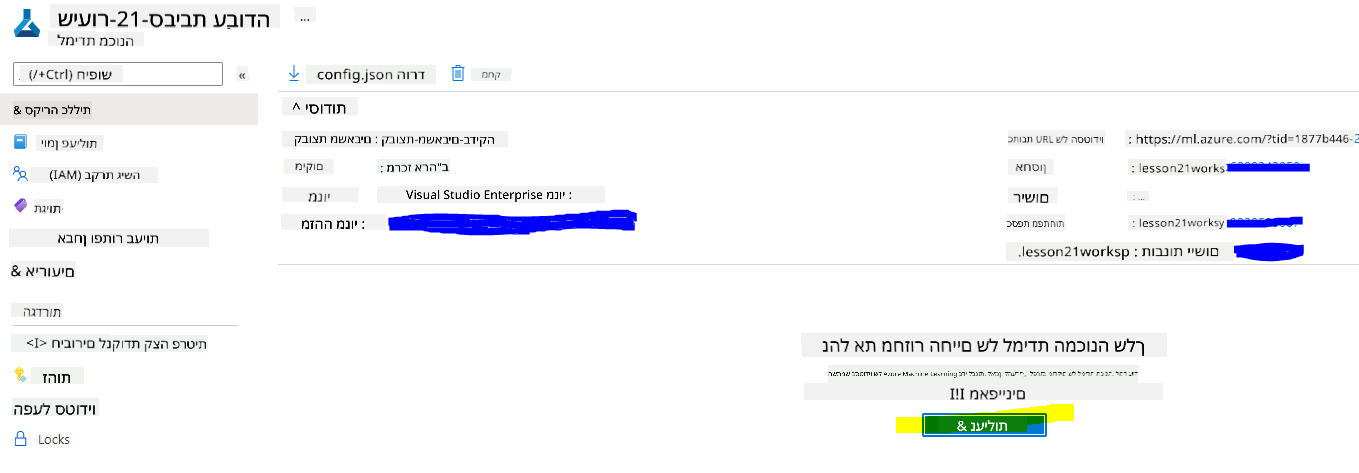
המתן ליצירת סביבת העבודה שלך (זה עשוי לקחת כמה דקות). לאחר מכן עבור אליה בפורטל. תוכל למצוא אותה דרך שירות Azure Machine Learning.
-
בעמוד "Overview" של סביבת העבודה שלך, הפעל את Azure Machine Learning Studio (או פתח כרטיסייה חדשה בדפדפן ונווט לכתובת https://ml.azure.com), והיכנס ל-Azure Machine Learning Studio באמצעות חשבון Microsoft שלך. אם תתבקש, בחר את המנוי וסביבת העבודה שלך ב-Azure Machine Learning.
- ב-Azure Machine Learning Studio, לחץ על סמל ☰ בפינה השמאלית העליונה כדי לצפות בדפים השונים בממשק. תוכל להשתמש בדפים אלו לניהול המשאבים בסביבת העבודה שלך.
תוכל לנהל את סביבת העבודה שלך באמצעות פורטל Azure, אך עבור מדעני נתונים ומהנדסי תפעול למידת מכונה, Azure Machine Learning Studio מספק ממשק משתמש ממוקד יותר לניהול משאבי סביבת העבודה.
2.2 משאבי מחשוב
משאבי מחשוב הם משאבים מבוססי ענן שעליהם ניתן להריץ תהליכי אימון מודלים וחקר נתונים. ישנם ארבעה סוגים של משאבי מחשוב שניתן ליצור:
- Compute Instances: תחנות עבודה לפיתוח שמדעני נתונים יכולים להשתמש בהן לעבודה עם נתונים ומודלים. זה כולל יצירת מכונה וירטואלית (VM) והפעלת מופע מחברת. לאחר מכן תוכל לאמן מודל על ידי קריאה לאשכול מחשוב מתוך המחברת.
- Compute Clusters: אשכולות ניתנים להרחבה של מכונות וירטואליות לעיבוד קוד ניסויים לפי דרישה. תזדקק להם בעת אימון מודל. אשכולות מחשוב יכולים גם להשתמש במשאבי GPU או CPU מיוחדים.
- Inference Clusters: יעדי פריסה לשירותי חיזוי המשתמשים במודלים שאומנו.
- מחשוב מצורף: קישורים למשאבי מחשוב קיימים ב-Azure, כמו מכונות וירטואליות או אשכולות Azure Databricks.
2.2.1 בחירת האפשרויות הנכונות עבור משאבי המחשוב שלך
ישנם גורמים מרכזיים שיש לקחת בחשבון בעת יצירת משאב מחשוב, והבחירות הללו יכולות להיות החלטות קריטיות.
האם אתה זקוק ל-CPU או GPU?
CPU (יחידת עיבוד מרכזית) היא המעגל האלקטרוני שמבצע הוראות של תוכנית מחשב. GPU (יחידת עיבוד גרפית) הוא מעגל אלקטרוני ייעודי שיכול לבצע קוד הקשור לגרפיקה בקצב גבוה מאוד.
ההבדל העיקרי בין ארכיטקטורת CPU ל-GPU הוא ש-CPU מיועד לטפל במגוון רחב של משימות במהירות (כפי שנמדד במהירות שעון ה-CPU), אך מוגבל בכמות המשימות שיכולות לפעול במקביל. GPUs מיועדים לעיבוד מקבילי ולכן הם טובים יותר למשימות של למידה עמוקה.
| CPU | GPU |
|---|---|
| זול יותר | יקר יותר |
| רמת מקביליות נמוכה יותר | רמת מקביליות גבוהה יותר |
| איטי יותר באימון מודלים של למידה עמוקה | אופטימלי ללמידה עמוקה |
גודל האשכול
אשכולות גדולים יותר יקרים יותר אך יובילו לתגובה מהירה יותר. לכן, אם יש לך זמן אך לא מספיק כסף, כדאי להתחיל עם אשכול קטן. לעומת זאת, אם יש לך כסף אך מעט זמן, כדאי להתחיל עם אשכול גדול יותר.
גודל VM
בהתאם למגבלות הזמן והתקציב שלך, תוכל לשנות את גודל ה-RAM, הדיסק, מספר הליבות ומהירות השעון. הגדלת כל הפרמטרים הללו תהיה יקרה יותר, אך תביא לביצועים טובים יותר.
מופעים ייעודיים או בעדיפות נמוכה?
מופע בעדיפות נמוכה פירושו שהוא ניתן לקטיעה: למעשה, Microsoft Azure יכולה לקחת את המשאבים הללו ולהקצות אותם למשימה אחרת, ובכך להפריע לעבודה. מופע ייעודי, או לא ניתן לקטיעה, פירושו שהעבודה לעולם לא תופסק ללא רשותך.
זו עוד שאלה של זמן מול כסף, שכן מופעים ניתנים לקטיעה זולים יותר ממופעים ייעודיים.
2.2.2 יצירת אשכול מחשוב
ב-Azure ML workspace שיצרנו קודם, עבור אל "מחשוב" ותוכל לראות את משאבי המחשוב השונים שדיברנו עליהם (כלומר מופעי מחשוב, אשכולות מחשוב, אשכולות חיזוי ומחשוב מצורף). עבור הפרויקט הזה, נצטרך אשכול מחשוב לאימון המודל. בסטודיו, לחץ על תפריט "מחשוב", לאחר מכן על לשונית "אשכול מחשוב" ולחץ על כפתור "+ חדש" כדי ליצור אשכול מחשוב.
- בחר את האפשרויות שלך: ייעודי מול עדיפות נמוכה, CPU או GPU, גודל VM ומספר ליבות (תוכל לשמור על ההגדרות המוגדרות כברירת מחדל לפרויקט זה).
- לחץ על כפתור "הבא".
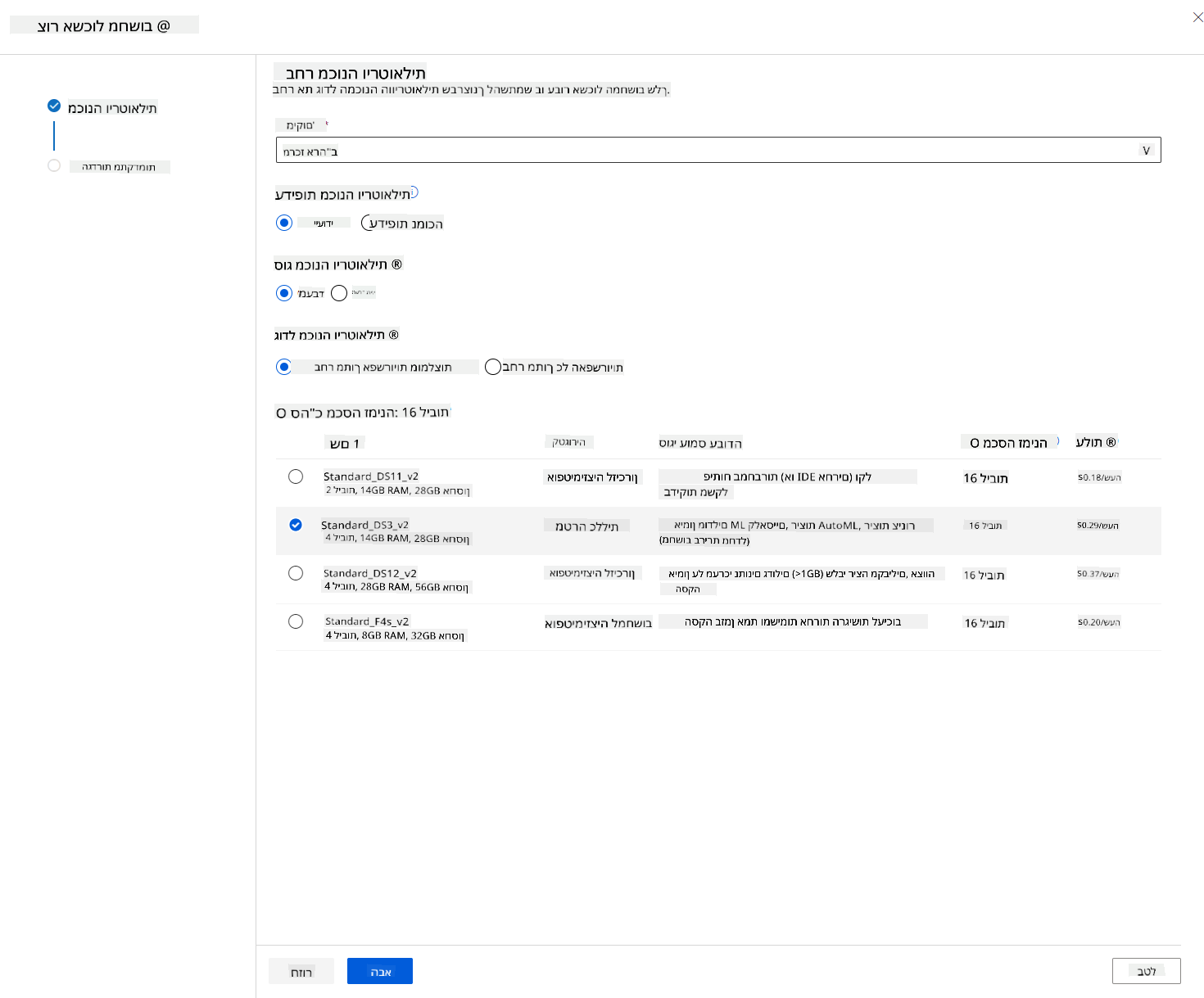
- תן לאשכול שם מחשוב.
- בחר את האפשרויות שלך: מספר מינימלי/מקסימלי של צמתים, שניות במצב סרק לפני הקטנה, גישת SSH. שים לב שאם מספר הצמתים המינימלי הוא 0, תחסוך כסף כשהאשכול במצב סרק. שים לב שככל שמספר הצמתים המקסימלי גבוה יותר, כך האימון יהיה קצר יותר. המספר המקסימלי המומלץ של צמתים הוא 3.
- לחץ על כפתור "צור". שלב זה עשוי להימשך מספר דקות.
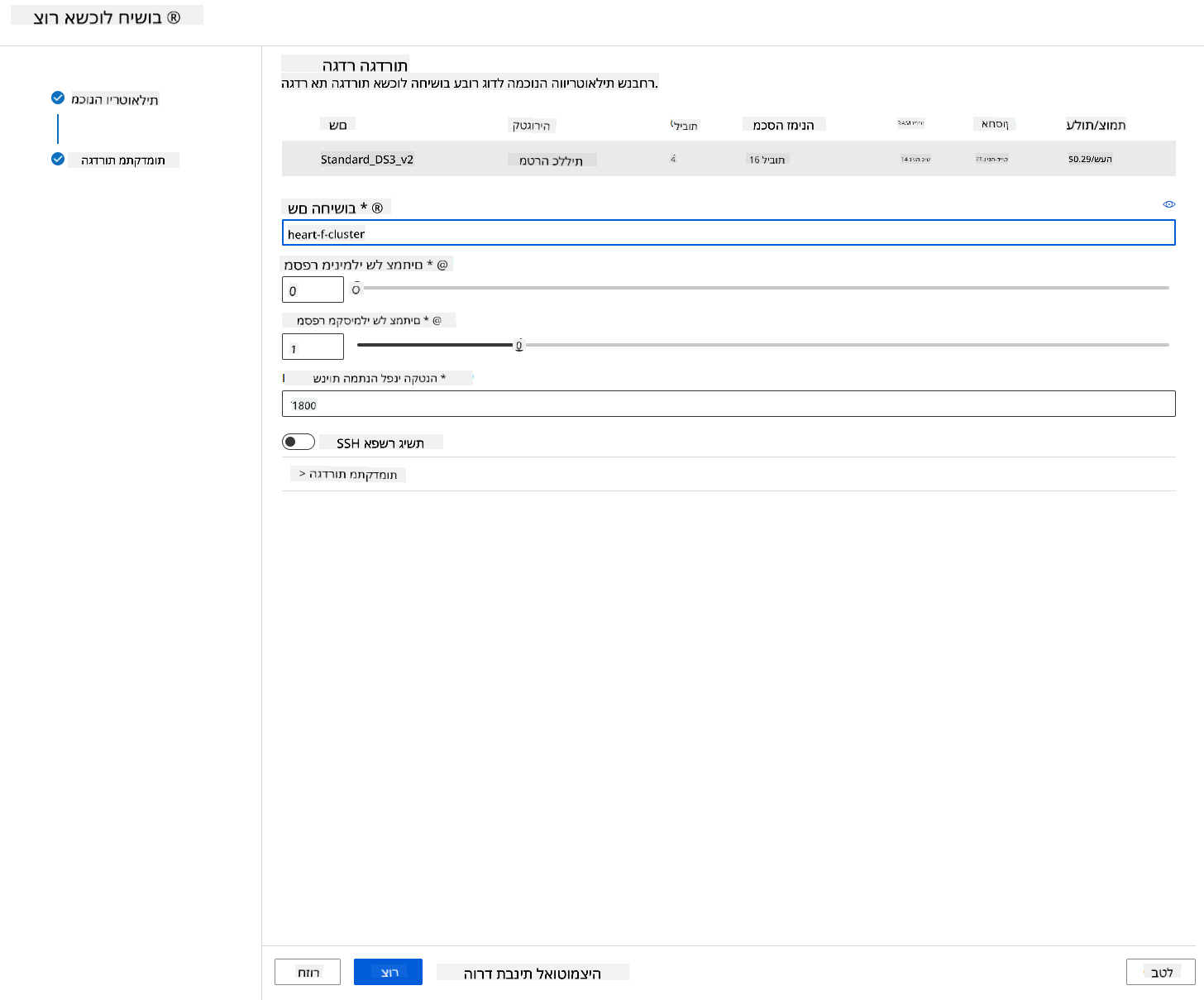
מעולה! עכשיו כשיש לנו אשכול מחשוב, נצטרך לטעון את הנתונים ל-Azure ML Studio.
2.3 טעינת מערך הנתונים
-
ב-Azure ML workspace שיצרנו קודם, לחץ על "Datasets" בתפריט השמאלי ולחץ על כפתור "+ Create dataset" כדי ליצור מערך נתונים. בחר באפשרות "From local files" ובחר את מערך הנתונים של Kaggle שהורדנו קודם.
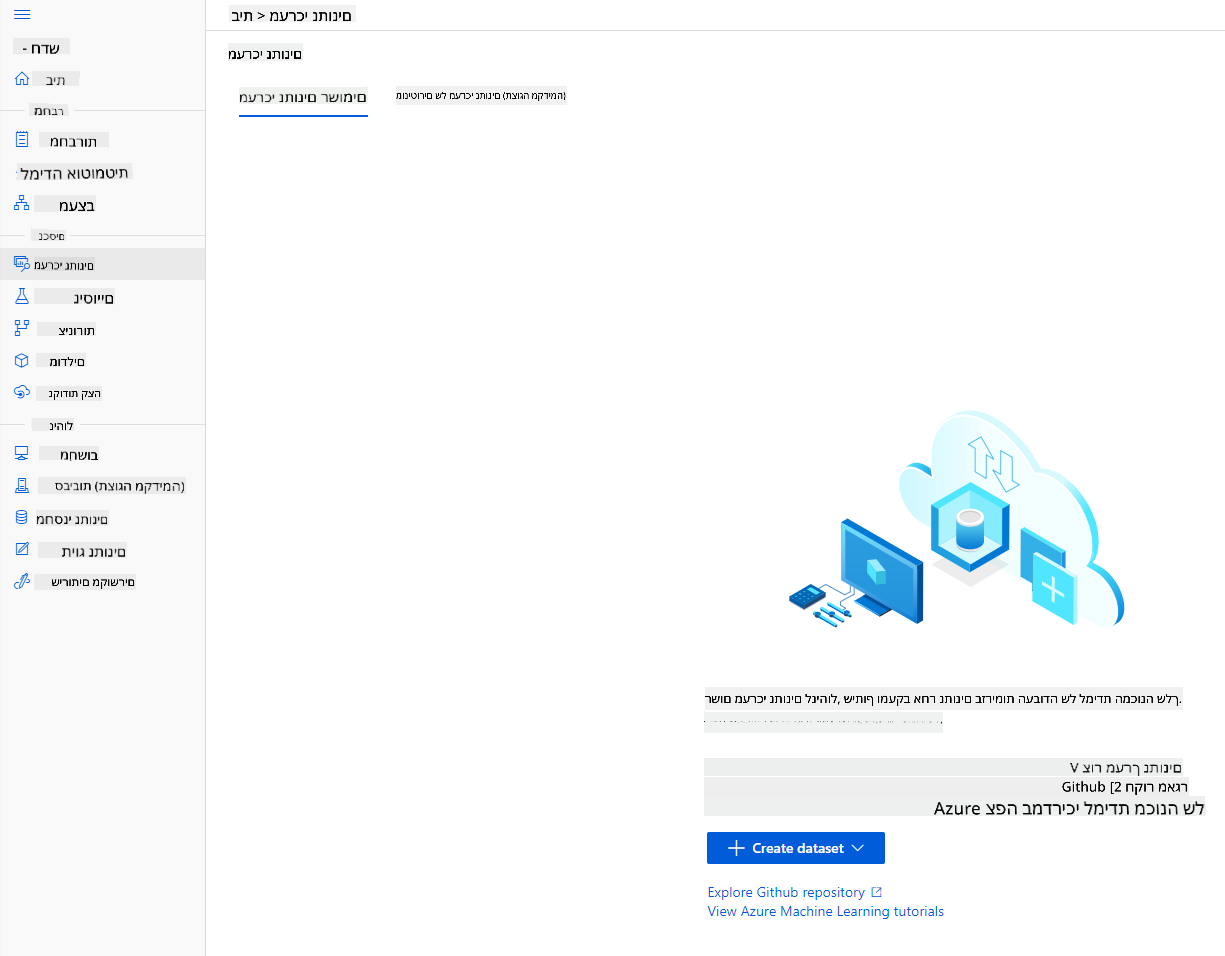
-
תן למערך הנתונים שלך שם, סוג ותיאור. לחץ על "הבא". העלה את הנתונים מהקבצים. לחץ על "הבא".
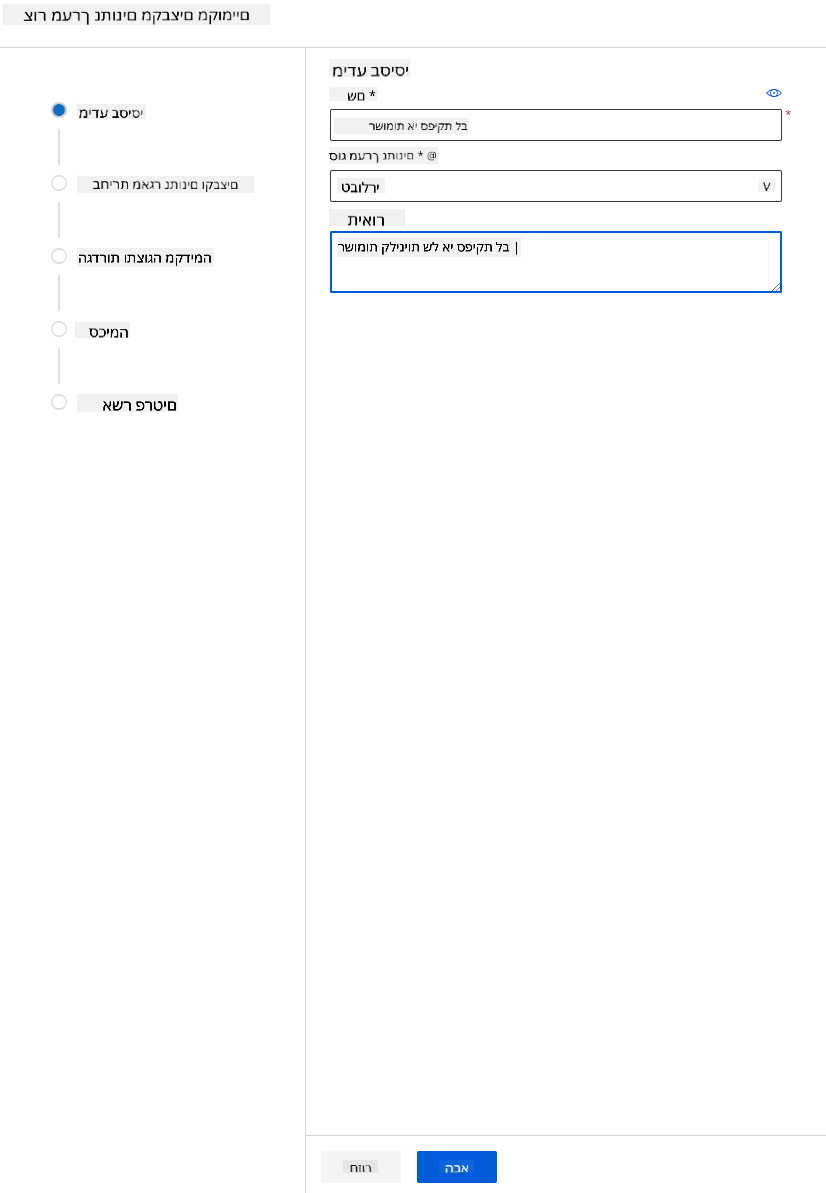
-
בסכימה, שנה את סוג הנתונים ל-Boolean עבור התכונות הבאות: anaemia, diabetes, high blood pressure, sex, smoking, ו-DEATH_EVENT. לחץ על "הבא" ולחץ על "צור".
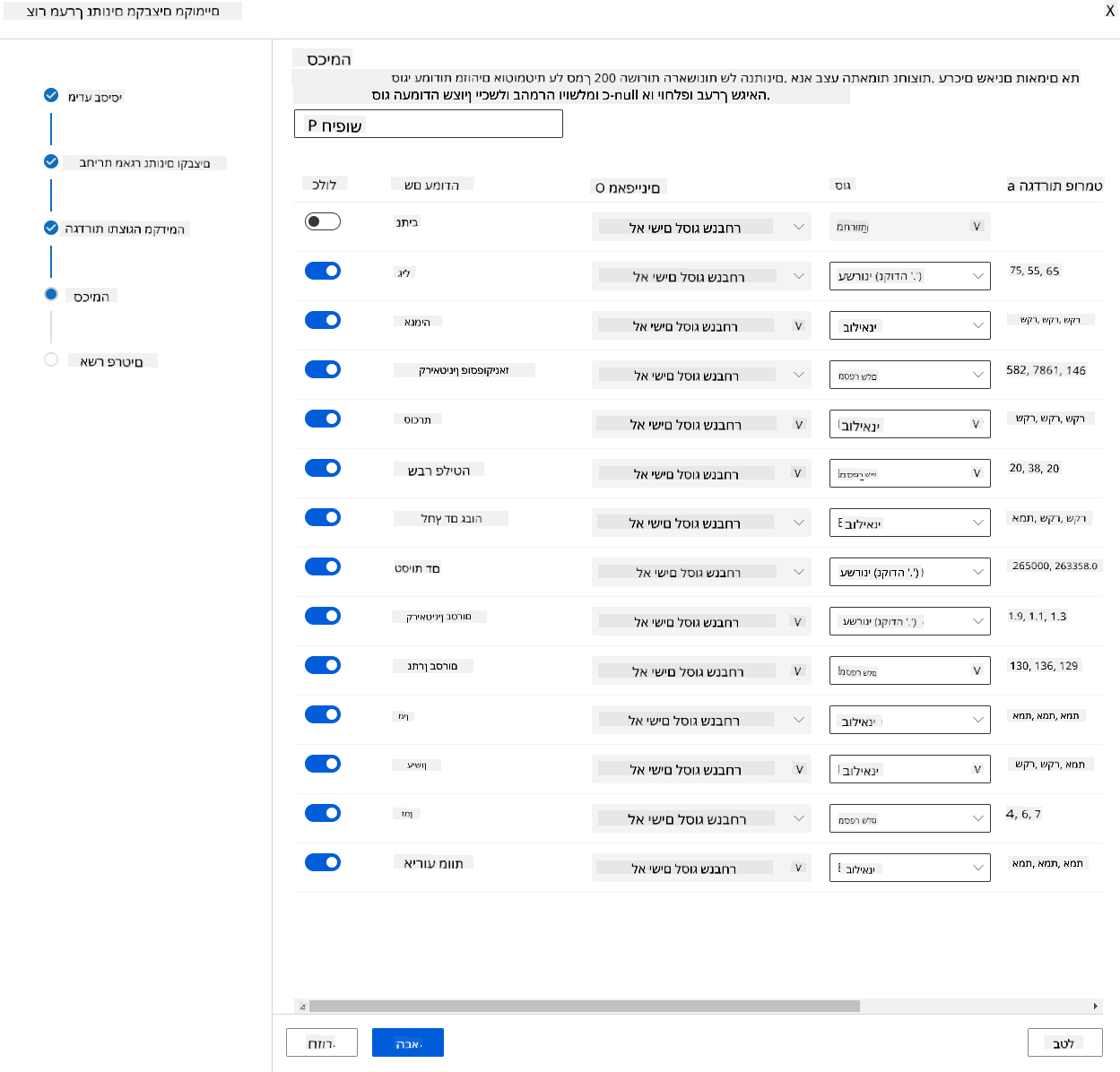
מעולה! עכשיו כשמערך הנתונים במקום ואשכול המחשוב נוצר, נוכל להתחיל באימון המודל!
2.4 אימון ללא קוד/עם מעט קוד באמצעות AutoML
פיתוח מסורתי של מודלים של למידת מכונה דורש משאבים רבים, ידע מקצועי וזמן רב להשוואת מודלים.
למידת מכונה אוטומטית (AutoML) היא תהליך שמפשט את המשימות החוזרות והזמן הנדרש לפיתוח מודלים. היא מאפשרת למדעני נתונים, אנליסטים ומפתחים לבנות מודלים ביעילות ובמהירות, תוך שמירה על איכות המודל. למידע נוסף
-
ב-Azure ML workspace שיצרנו קודם, לחץ על "Automated ML" בתפריט השמאלי ובחר את מערך הנתונים שהעלית זה עתה. לחץ על "הבא".
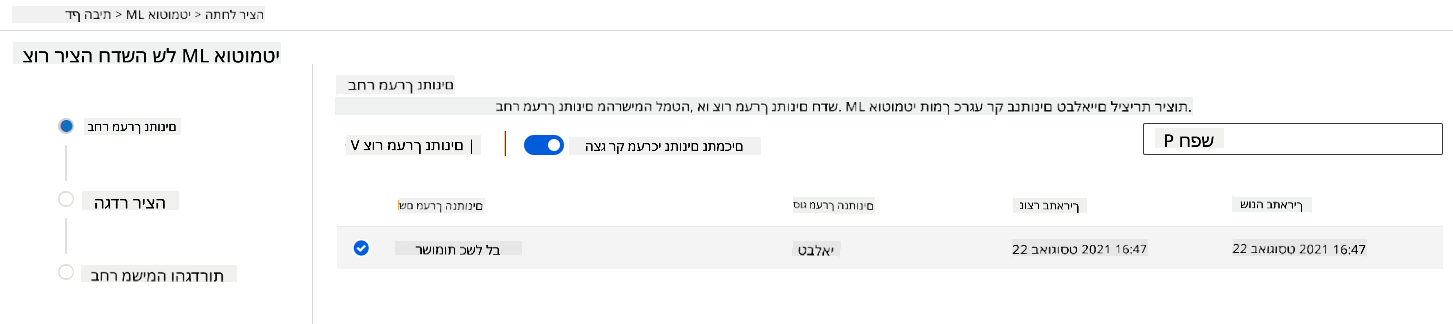
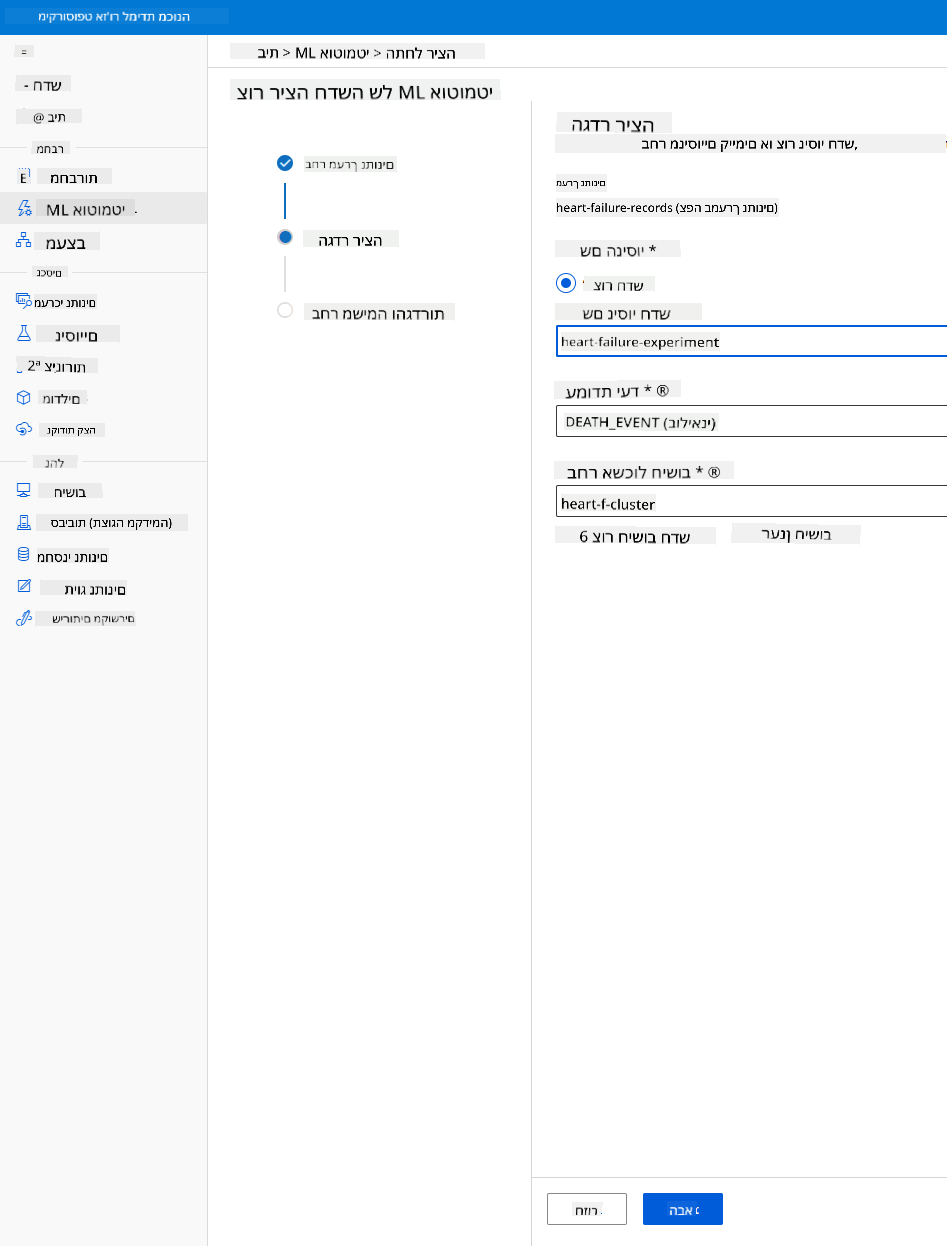
-
הזן שם ניסוי חדש, עמודת יעד (DEATH_EVENT) ואשכול המחשוב שיצרנו. לחץ על "הבא".
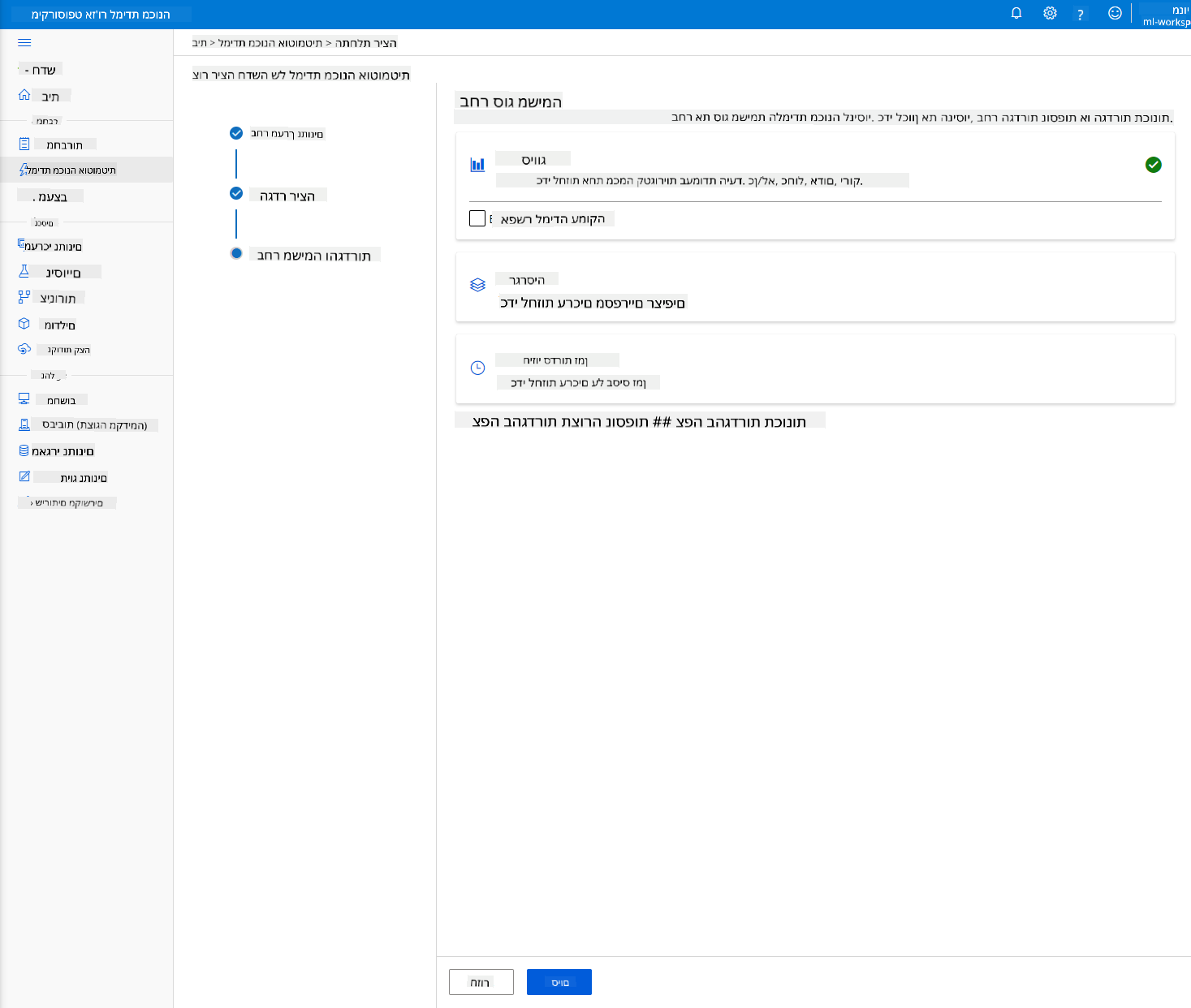
-
בחר "Classification" ולחץ על "סיום". שלב זה עשוי להימשך בין 30 דקות לשעה, בהתאם לגודל אשכול המחשוב שלך.
-
לאחר שהריצה הושלמה, לחץ על לשונית "Automated ML", לחץ על הריצה שלך, ולחץ על האלגוריתם בכרטיס "Best model summary".
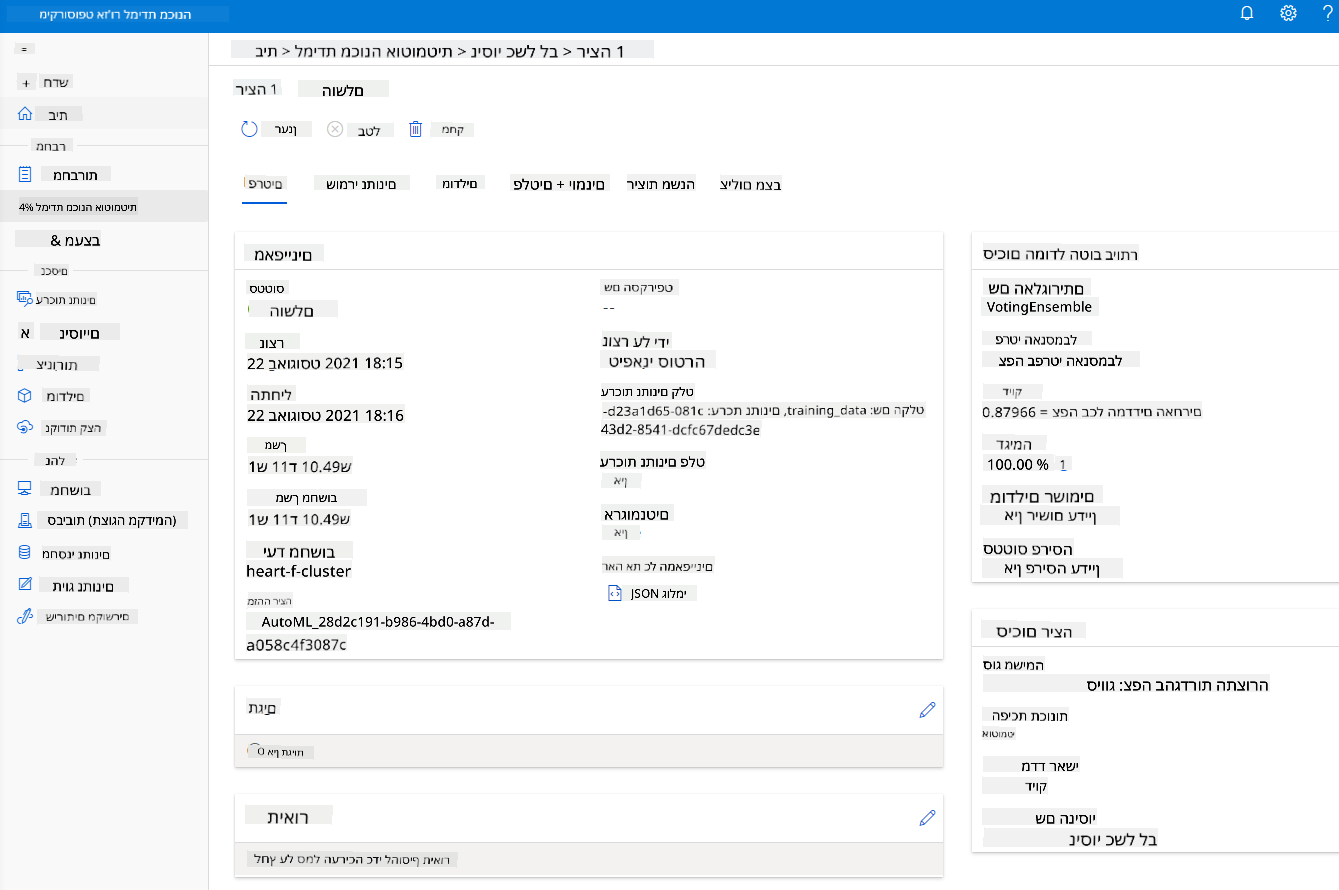
כאן תוכל לראות תיאור מפורט של המודל הטוב ביותר ש-AutoML יצר. תוכל גם לחקור מודלים אחרים בלשונית "Models". קח כמה דקות לחקור את המודלים בלשונית "Explanations". לאחר שבחרת את המודל שברצונך להשתמש בו (כאן נבחר במודל הטוב ביותר שנבחר על ידי AutoML), נראה כיצד ניתן לפרוס אותו.
3. פריסת מודל ללא קוד/עם מעט קוד וצריכת נקודת קצה
3.1 פריסת מודל
ממשק למידת המכונה האוטומטית מאפשר לפרוס את המודל הטוב ביותר כשירות אינטרנט בכמה שלבים פשוטים.
פריסה היא שילוב המודל כך שיוכל לבצע תחזיות על נתונים חדשים. עבור פרויקט זה, פריסה לשירות אינטרנט פירושה שאפליקציות רפואיות יוכלו להשתמש במודל כדי לבצע תחזיות חיות על סיכון התקף לב של מטופלים.
בתיאור המודל הטוב ביותר, לחץ על כפתור "Deploy".
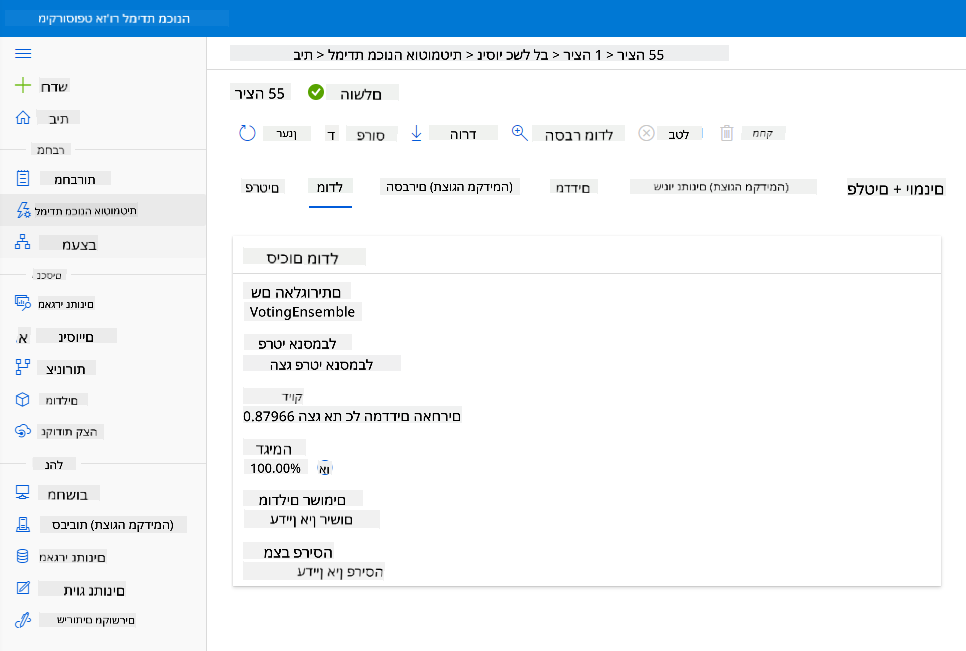
- תן שם, תיאור, סוג מחשוב (Azure Container Instance), הפעל אימות ולחץ על "Deploy". שלב זה עשוי להימשך כ-20 דקות. תהליך הפריסה כולל רישום המודל, יצירת משאבים והגדרתם לשירות האינטרנט. הודעת סטטוס תופיע תחת "Deploy status". לחץ על "רענן" מדי פעם כדי לבדוק את הסטטוס. המודל ייפרס ויפעל כאשר הסטטוס יהיה "Healthy".
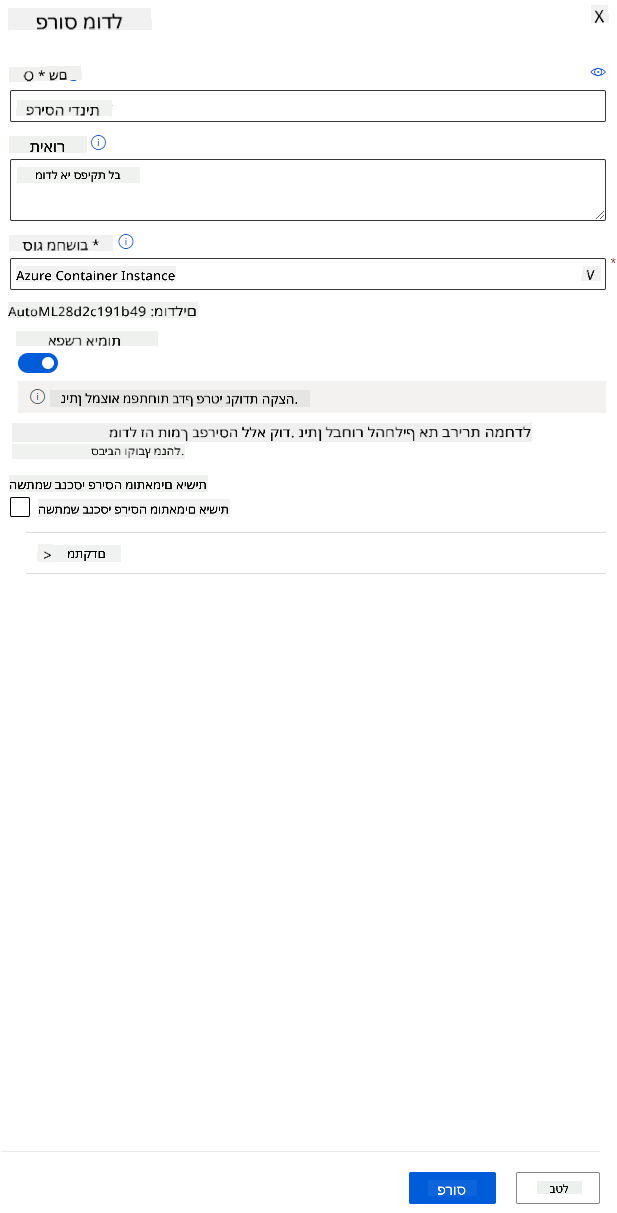
- לאחר שהמודל נפרס, לחץ על לשונית "Endpoint" ולחץ על נקודת הקצה שפרסת זה עתה. כאן תוכל למצוא את כל הפרטים על נקודת הקצה.
מדהים! עכשיו כשיש לנו מודל שפורס, נוכל להתחיל בצריכת נקודת הקצה.
3.2 צריכת נקודת קצה
לחץ על לשונית "Consume". כאן תוכל למצוא את נקודת הקצה של REST ואת סקריפט הפייתון באפשרות הצריכה. קח זמן לקרוא את קוד הפייתון.
סקריפט זה ניתן להרצה ישירות מהמחשב המקומי שלך ויצרוך את נקודת הקצה.
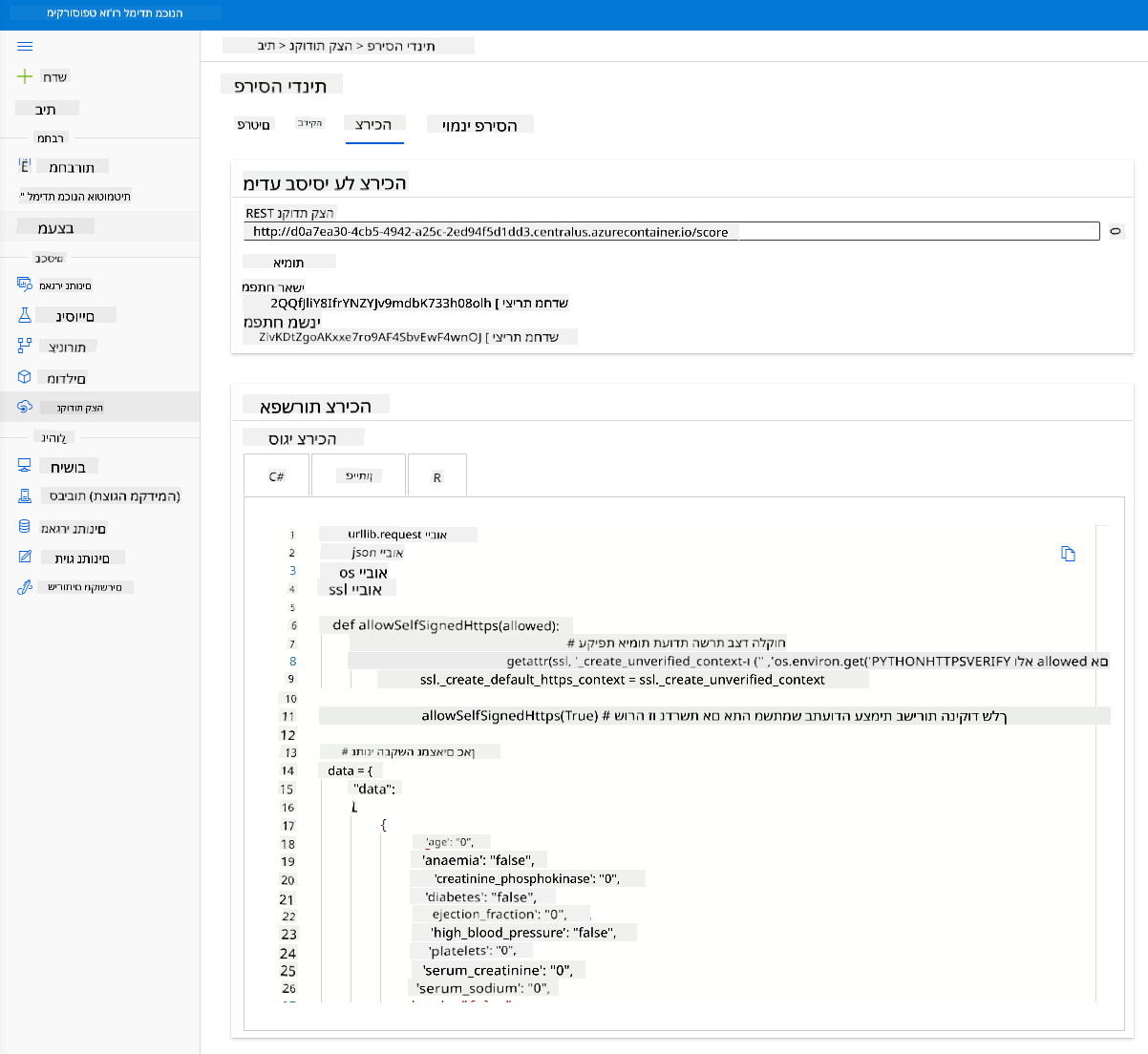
קח רגע לבדוק את שתי שורות הקוד הבאות:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
משתנה url הוא נקודת הקצה של REST שנמצאה בלשונית הצריכה, ומשתנה api_key הוא המפתח הראשי שנמצא גם הוא בלשונית הצריכה (רק במקרה שהפעלת אימות). כך הסקריפט יכול לצרוך את נקודת הקצה.
- בהרצת הסקריפט, תראה את הפלט הבא:
b'"{\\"result\\": [true]}"'
זה אומר שהתחזית לכשל לבבי עבור הנתונים שניתנו היא נכונה. זה הגיוני כי אם תסתכל מקרוב על הנתונים שנוצרו אוטומטית בסקריפט, הכל מוגדר ל-0 ו-false כברירת מחדל. תוכל לשנות את הנתונים לדוגמה הבאה:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
הסקריפט יחזיר:
python b'"{\\"result\\": [true, false]}"'
ברכות! צרכת את המודל שפורס ואימנת אותו ב-Azure ML!
הערה: לאחר שתסיים את הפרויקט, אל תשכח למחוק את כל המשאבים.
🚀 אתגר
בחן מקרוב את ההסברים והפרטים של המודלים המובילים ש-AutoML יצר. נסה להבין מדוע המודל הטוב ביותר טוב יותר מהאחרים. אילו אלגוריתמים הושוו? מה ההבדלים ביניהם? מדוע המודל הטוב ביותר מבצע טוב יותר במקרה זה?
שאלון לאחר ההרצאה
סקירה ולמידה עצמית
בשיעור זה למדת כיצד לאמן, לפרוס ולצרוך מודל לחיזוי סיכון לכשל לבבי בצורה ללא קוד/עם מעט קוד בענן. אם עדיין לא עשית זאת, העמק בהסברים של המודלים ש-AutoML יצר ונסה להבין מדוע המודל הטוב ביותר טוב יותר מאחרים.
תוכל להעמיק עוד בלמידת מכונה אוטומטית ללא קוד/עם מעט קוד על ידי קריאת התיעוד.
משימה
פרויקט מדעי נתונים ללא קוד/עם מעט קוד ב-Azure ML
כתב ויתור:
מסמך זה תורגם באמצעות שירות תרגום מבוסס בינה מלאכותית Co-op Translator. למרות שאנו שואפים לדיוק, יש לקחת בחשבון שתרגומים אוטומטיים עשויים להכיל שגיאות או אי דיוקים. המסמך המקורי בשפתו המקורית צריך להיחשב כמקור סמכותי. עבור מידע קריטי, מומלץ להשתמש בתרגום מקצועי על ידי אדם. איננו נושאים באחריות לאי הבנות או לפרשנויות שגויות הנובעות משימוש בתרגום זה.