|
|
## 01、安装MYSQL
|
|
|
|
|
|
**一**、下载并安装mysql:
|
|
|
|
|
|
```
|
|
|
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
|
|
|
yum -y install mysql57-community-release-el7-10.noarch.rpm
|
|
|
yum -y install mysql-community-server --nogpgcheck
|
|
|
```
|
|
|
|
|
|
**二**、启动并查看状态MySQL:
|
|
|
|
|
|
```
|
|
|
systemctl start mysqld.service
|
|
|
systemctl status mysqld.service
|
|
|
```
|
|
|
|
|
|
**三**、查看MySQL的默认密码:
|
|
|
|
|
|
```
|
|
|
grep "password" /var/log/mysqld.log
|
|
|
```
|
|
|
|
|
|
[](https://tva1.sinaimg.cn/large/008i3skNgy1gwg6eiwyqfj313402mgm8.jpg)
|
|
|
|
|
|
**四**、登录进MySQL
|
|
|
|
|
|
```
|
|
|
mysql -uroot -p
|
|
|
```
|
|
|
|
|
|
**五**、修改默认密码(设置密码需要有大小写符号组合—安全性),把下面的`my password`替换成自己的密码
|
|
|
|
|
|
```
|
|
|
ALTER USER 'root'@'localhost' IDENTIFIED BY 'my password';
|
|
|
```
|
|
|
|
|
|
**六**、开启远程访问 (把下面的`my password`替换成自己的密码)
|
|
|
|
|
|
```
|
|
|
grant all privileges on *.* to 'root'@'%' identified by 'my password' with grant option;
|
|
|
|
|
|
flush privileges;
|
|
|
|
|
|
exit
|
|
|
```
|
|
|
|
|
|
**七**、在云服务上增加MySQL的端口
|
|
|
|
|
|
## 02、安装DOCKER和DOCKER-COMPOSE
|
|
|
|
|
|
首先我们需要安装GCC相关的环境:
|
|
|
|
|
|
```
|
|
|
yum -y install gcc
|
|
|
|
|
|
yum -y install gcc-c++
|
|
|
```
|
|
|
|
|
|
安装Docker需要的依赖软件包:
|
|
|
|
|
|
```
|
|
|
yum install -y yum-utils device-mapper-persistent-data lvm2
|
|
|
```
|
|
|
|
|
|
设置国内的镜像(提高速度)
|
|
|
|
|
|
```
|
|
|
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
|
|
|
```
|
|
|
|
|
|
更新yum软件包索引:
|
|
|
|
|
|
```
|
|
|
yum makecache fast
|
|
|
```
|
|
|
|
|
|
安装DOCKER CE(注意:Docker分为CE版和EE版,一般我们用CE版就够用了.)
|
|
|
|
|
|
```
|
|
|
yum -y install docker-ce
|
|
|
```
|
|
|
|
|
|
启动Docker:
|
|
|
|
|
|
```
|
|
|
systemctl start docker
|
|
|
```
|
|
|
|
|
|
下载回来的Docker版本::
|
|
|
|
|
|
```
|
|
|
docker version
|
|
|
```
|
|
|
|
|
|
运行以下命令以下载 Docker Compose 的当前稳定版本:
|
|
|
|
|
|
```
|
|
|
sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
|
|
|
|
|
|
#慢的话可以用这个
|
|
|
sudo curl -L https://get.daocloud.io/docker/compose/releases/download/1.25.1/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
|
|
|
|
|
|
```
|
|
|
|
|
|
将可执行权限应用于二进制文件:
|
|
|
|
|
|
```
|
|
|
sudo chmod +x /usr/local/bin/docker-compose
|
|
|
```
|
|
|
|
|
|
创建软链:
|
|
|
|
|
|
```
|
|
|
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
|
|
|
```
|
|
|
|
|
|
测试是否安装成功:
|
|
|
|
|
|
```
|
|
|
docker-compose --version
|
|
|
```
|
|
|
|
|
|
|
|
|
(Austin项目的中间件使用docker进行部署,文件内容可以参考项目中`docker`文件夹)
|
|
|
|
|
|
## 03、安装KAFKA
|
|
|
|
|
|
新建搭建kafka环境的`docker-compose.yml`文件,内容如下:
|
|
|
|
|
|
```
|
|
|
version: '3'
|
|
|
services:
|
|
|
zookepper:
|
|
|
image: wurstmeister/zookeeper # 原镜像`wurstmeister/zookeeper`
|
|
|
container_name: zookeeper # 容器名为'zookeeper'
|
|
|
volumes: # 数据卷挂载路径设置,将本机目录映射到容器目录
|
|
|
- "/etc/localtime:/etc/localtime"
|
|
|
ports: # 映射端口
|
|
|
- "2181:2181"
|
|
|
|
|
|
kafka:
|
|
|
image: wurstmeister/kafka # 原镜像`wurstmeister/kafka`
|
|
|
container_name: kafka # 容器名为'kafka'
|
|
|
volumes: # 数据卷挂载路径设置,将本机目录映射到容器目录
|
|
|
- "/etc/localtime:/etc/localtime"
|
|
|
environment: # 设置环境变量,相当于docker run命令中的-e
|
|
|
KAFKA_BROKER_ID: 0 # 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
|
|
|
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://ip:9092 # TODO 将kafka的地址端口注册给zookeeper
|
|
|
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092 # 配置kafka的监听端口
|
|
|
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
|
|
|
KAFKA_CREATE_TOPICS: "hello_world"
|
|
|
KAFKA_HEAP_OPTS: -Xmx1G -Xms256M
|
|
|
ports: # 映射端口
|
|
|
- "9092:9092"
|
|
|
depends_on: # 解决容器依赖启动先后问题
|
|
|
- zookepper
|
|
|
|
|
|
kafka-manager:
|
|
|
image: sheepkiller/kafka-manager # 原镜像`sheepkiller/kafka-manager`
|
|
|
container_name: kafka-manager # 容器名为'kafka-manager'
|
|
|
environment: # 设置环境变量,相当于docker run命令中的-e
|
|
|
ZK_HOSTS: zookeeper:2181
|
|
|
APPLICATION_SECRET: xxxxx
|
|
|
KAFKA_MANAGER_AUTH_ENABLED: "true" # 开启kafka-manager权限校验
|
|
|
KAFKA_MANAGER_USERNAME: admin # 登陆账户
|
|
|
KAFKA_MANAGER_PASSWORD: 123456 # 登陆密码
|
|
|
ports: # 映射端口
|
|
|
- "9000:9000"
|
|
|
depends_on: # 解决容器依赖启动先后问题
|
|
|
- kafka
|
|
|
```
|
|
|
|
|
|
文件内 **// TODO 中的ip**需要改成自己的,并且如果你用的是云服务器,那需要把端口给打开。
|
|
|
|
|
|
在存放`docker-compose.yml`的目录下执行启动命令:
|
|
|
|
|
|
```
|
|
|
docker-compose up -d
|
|
|
```
|
|
|
|
|
|
可以查看下docker镜像运行的情况:
|
|
|
|
|
|
```
|
|
|
docker ps
|
|
|
```
|
|
|
|
|
|
进入kafka 的容器:
|
|
|
|
|
|
```
|
|
|
docker exec -it kafka sh
|
|
|
```
|
|
|
|
|
|
创建两个topic(这里我的**topicName**就叫austinBusiness、austinTraceLog、austinRecall,你们可以改成自己的)
|
|
|
|
|
|
```
|
|
|
$KAFKA_HOME/bin/kafka-topics.sh --create --topic austinBusiness --partitions 1 --zookeeper zookeeper:2181 --replication-factor 1
|
|
|
|
|
|
$KAFKA_HOME/bin/kafka-topics.sh --create --topic austinTraceLog --partitions 1 --zookeeper zookeeper:2181 --replication-factor 1
|
|
|
|
|
|
$KAFKA_HOME/bin/kafka-topics.sh --create --topic austinRecall --partitions 1 --zookeeper zookeeper:2181 --replication-factor 1
|
|
|
|
|
|
```
|
|
|
|
|
|
查看刚创建的topic信息:
|
|
|
|
|
|
```
|
|
|
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic austinBusiness
|
|
|
```
|
|
|
|
|
|
## 04、安装REDIS
|
|
|
|
|
|
首先,我们新建一个文件夹`redis`,然后在该目录下创建出`data`文件夹、`redis.conf`文件和`docker-compose.yaml`文件
|
|
|
|
|
|
`redis.conf`文件的内容如下(后面的配置可在这更改,比如requirepass 我指定的密码为`austin`)
|
|
|
|
|
|
```
|
|
|
protected-mode no
|
|
|
port 6379
|
|
|
timeout 0
|
|
|
save 900 1
|
|
|
save 300 10
|
|
|
save 60 10000
|
|
|
rdbcompression yes
|
|
|
dbfilename dump.rdb
|
|
|
dir /data
|
|
|
appendonly yes
|
|
|
appendfsync everysec
|
|
|
requirepass austin
|
|
|
|
|
|
```
|
|
|
|
|
|
`docker-compose.yaml`的文件内容如下:
|
|
|
|
|
|
```
|
|
|
version: '3'
|
|
|
services:
|
|
|
redis:
|
|
|
image: redis:latest
|
|
|
container_name: redis
|
|
|
restart: always
|
|
|
ports:
|
|
|
- 6379:6379
|
|
|
volumes:
|
|
|
- ./redis.conf:/usr/local/etc/redis/redis.conf:rw
|
|
|
- ./data:/data:rw
|
|
|
command:
|
|
|
/bin/bash -c "redis-server /usr/local/etc/redis/redis.conf "
|
|
|
```
|
|
|
|
|
|
配置的工作就完了,如果是云服务器,记得开redis端口**6379**
|
|
|
|
|
|
启动Redis跟之前安装Kafka的时候就差不多啦
|
|
|
|
|
|
```
|
|
|
docker-compose up -d
|
|
|
|
|
|
docker ps
|
|
|
|
|
|
docker exec -it redis redis-cli
|
|
|
|
|
|
auth austin
|
|
|
|
|
|
```
|
|
|
|
|
|
## 05、安装APOLLO
|
|
|
|
|
|
部署Apollo跟之前一样直接用`docker-compose`就完事了,在GitHub已经给出了对应的教程和`docker-compose.yml`以及相关的文件,直接复制粘贴就完事咯。
|
|
|
|
|
|
**PS: Apollo 的docker配置文件可以参考:docker/apollo/文件夹, 简单来说,在 docker/apollo/docker-quick-start/文件夹下执行docker-compose up -d 执行即可.**
|
|
|
|
|
|
目录结构最好保持一致:
|
|
|
|
|
|

|
|
|
|
|
|
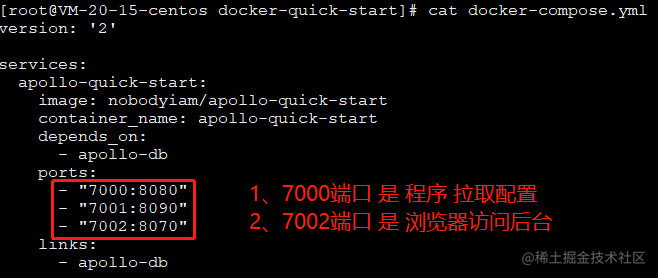
注:我的配置里更改过端口,所以我的程序`AustinApplication`写的端口为7000
|
|
|
|
|
|
|
|
|
|
|
|
**<https://www.apolloconfig.com/#/zh/deployment/quick-start-docker>**
|
|
|
|
|
|
**<https://github.com/apolloconfig/apollo/tree/master/scripts/docker-quick-start>**
|
|
|
|
|
|
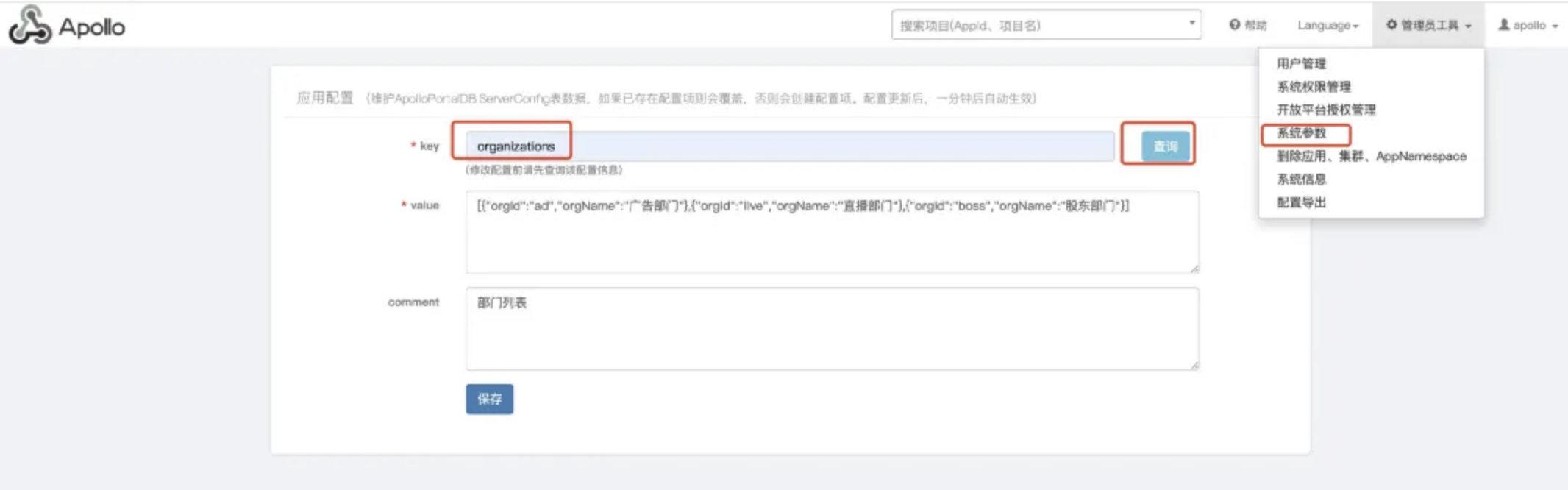
部门的创建其实也是一份"配置",输入`organizations`就能把现有的部门给改掉,我新增了`boss`股东部门,大家都是我的股东。
|
|
|
|
|
|
|
|
|
|
|
|
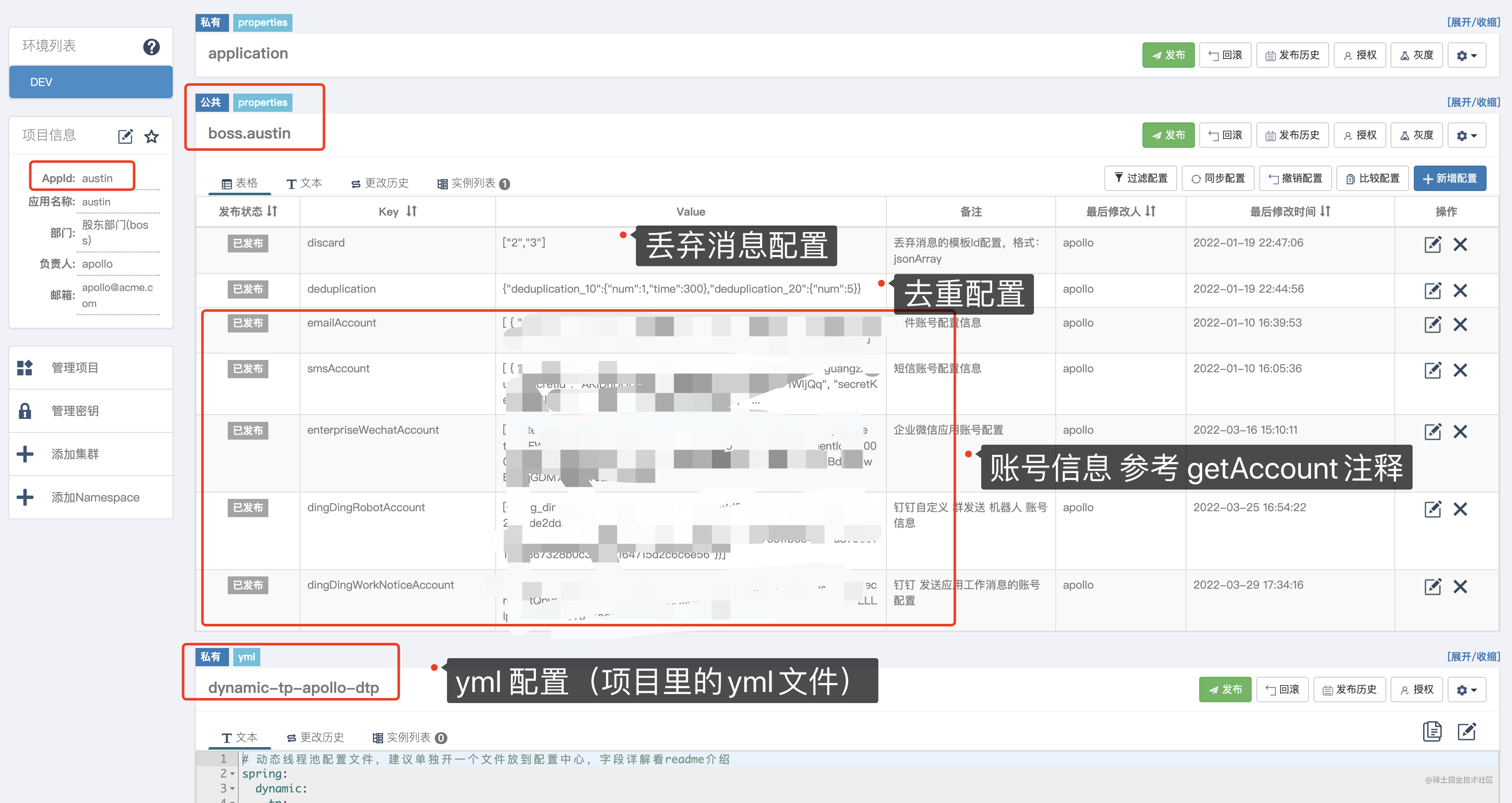
PS:我的namespace是`boss.austin`
|
|
|
|
|
|
|
|
|
|
|
|
apollo配置样例可看example/apollo.properties文件的内容
|
|
|
|
|
|
`dynamic-tp-apollo-dtp`它是一个apollo的namespace,存放着动态线程池的配置
|
|
|
|
|
|
动态线程池样例配置可看 dynamic-tp-apollo-dtp.yml 文件的内容
|
|
|
|
|
|
|
|
|
## 06、安装PROMETHEUS和GRAFANA(可选)
|
|
|
|
|
|
存放`docker-compose.yml`的信息:
|
|
|
|
|
|
```
|
|
|
version: '2'
|
|
|
|
|
|
networks:
|
|
|
monitor:
|
|
|
driver: bridge
|
|
|
|
|
|
services:
|
|
|
prometheus:
|
|
|
image: prom/prometheus
|
|
|
container_name: prometheus
|
|
|
hostname: prometheus
|
|
|
restart: always
|
|
|
volumes:
|
|
|
- ./prometheus.yml:/etc/prometheus/prometheus.yml
|
|
|
ports:
|
|
|
- "9090:9090"
|
|
|
networks:
|
|
|
- monitor
|
|
|
|
|
|
alertmanager:
|
|
|
image: prom/alertmanager
|
|
|
container_name: alertmanager
|
|
|
hostname: alertmanager
|
|
|
restart: always
|
|
|
ports:
|
|
|
- "9093:9093"
|
|
|
networks:
|
|
|
- monitor
|
|
|
|
|
|
grafana:
|
|
|
image: grafana/grafana
|
|
|
container_name: grafana
|
|
|
hostname: grafana
|
|
|
restart: always
|
|
|
ports:
|
|
|
- "3000:3000"
|
|
|
networks:
|
|
|
- monitor
|
|
|
|
|
|
node-exporter:
|
|
|
image: quay.io/prometheus/node-exporter
|
|
|
container_name: node-exporter
|
|
|
hostname: node-exporter
|
|
|
restart: always
|
|
|
ports:
|
|
|
- "9100:9100"
|
|
|
networks:
|
|
|
- monitor
|
|
|
|
|
|
cadvisor:
|
|
|
image: google/cadvisor:latest
|
|
|
container_name: cadvisor
|
|
|
hostname: cadvisor
|
|
|
restart: always
|
|
|
volumes:
|
|
|
- /:/rootfs:ro
|
|
|
- /var/run:/var/run:rw
|
|
|
- /sys:/sys:ro
|
|
|
- /var/lib/docker/:/var/lib/docker:ro
|
|
|
ports:
|
|
|
- "8899:8080"
|
|
|
networks:
|
|
|
- monitor
|
|
|
```
|
|
|
|
|
|
新建prometheus的配置文件`prometheus.yml`
|
|
|
|
|
|
```
|
|
|
global:
|
|
|
scrape_interval: 15s
|
|
|
evaluation_interval: 15s
|
|
|
scrape_configs:
|
|
|
- job_name: 'prometheus'
|
|
|
static_configs:
|
|
|
- targets: ['ip:9090']
|
|
|
- job_name: 'cadvisor'
|
|
|
static_configs:
|
|
|
- targets: ['ip:8899']
|
|
|
- job_name: 'node'
|
|
|
static_configs:
|
|
|
- targets: ['ip:9100']
|
|
|
```
|
|
|
|
|
|
(**这里要注意端口,按自己配置的来,ip也要填写为自己的**)
|
|
|
|
|
|
把这份`prometheus.yml`的配置往`/etc/prometheus/prometheus.yml` 路径下**复制**一份。随后在目录下`docker-compose up -d`启动,于是我们就可以分别访问:
|
|
|
|
|
|
- `http://ip:9100/metrics`( 查看服务器的指标)
|
|
|
- `http://ip:8899/metrics`(查看docker容器的指标)
|
|
|
- `http://ip:9090/`(prometheus的原生web-ui)
|
|
|
- `http://ip:3000/`(Grafana开源的监控可视化组件页面)
|
|
|
|
|
|
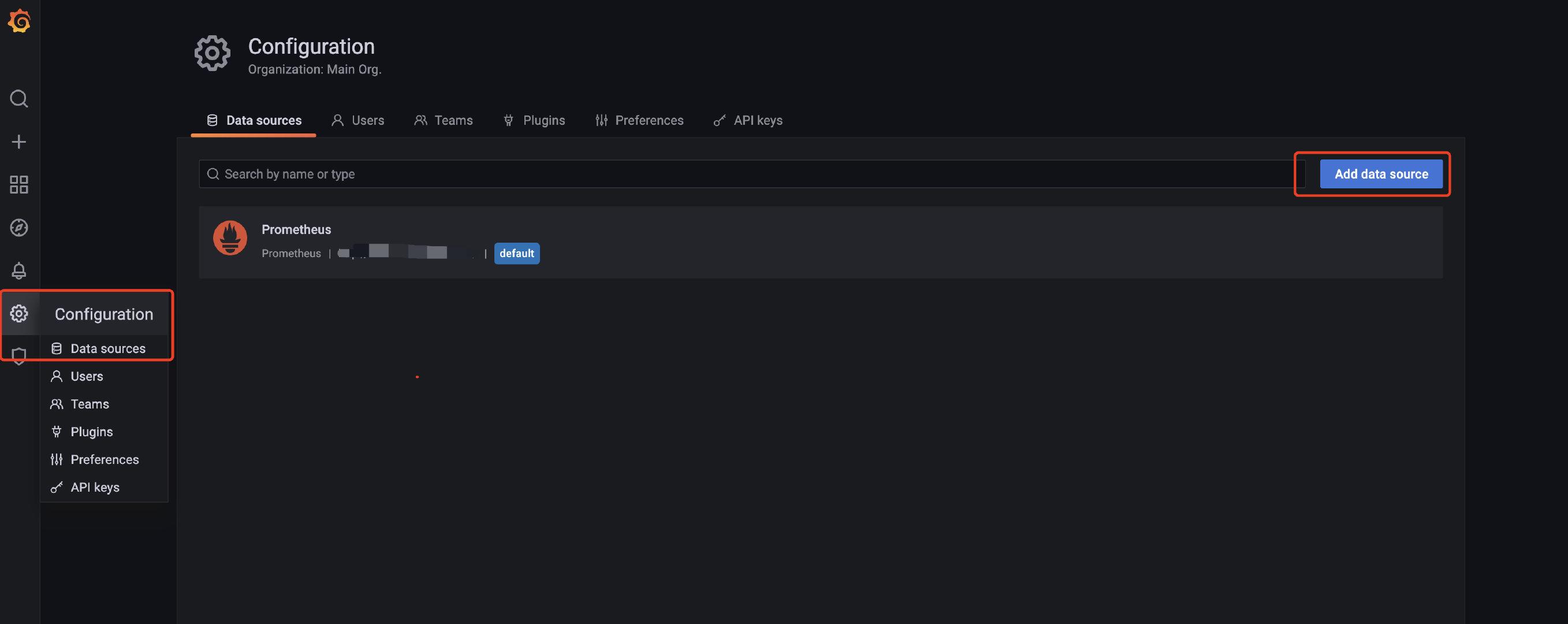
进到Grafana首页,配置prometheus作为数据源
|
|
|
|
|
|
|
|
|
|
|
|
进到配置页面,写下对应的URL,然后保存就好了。
|
|
|
|
|
|
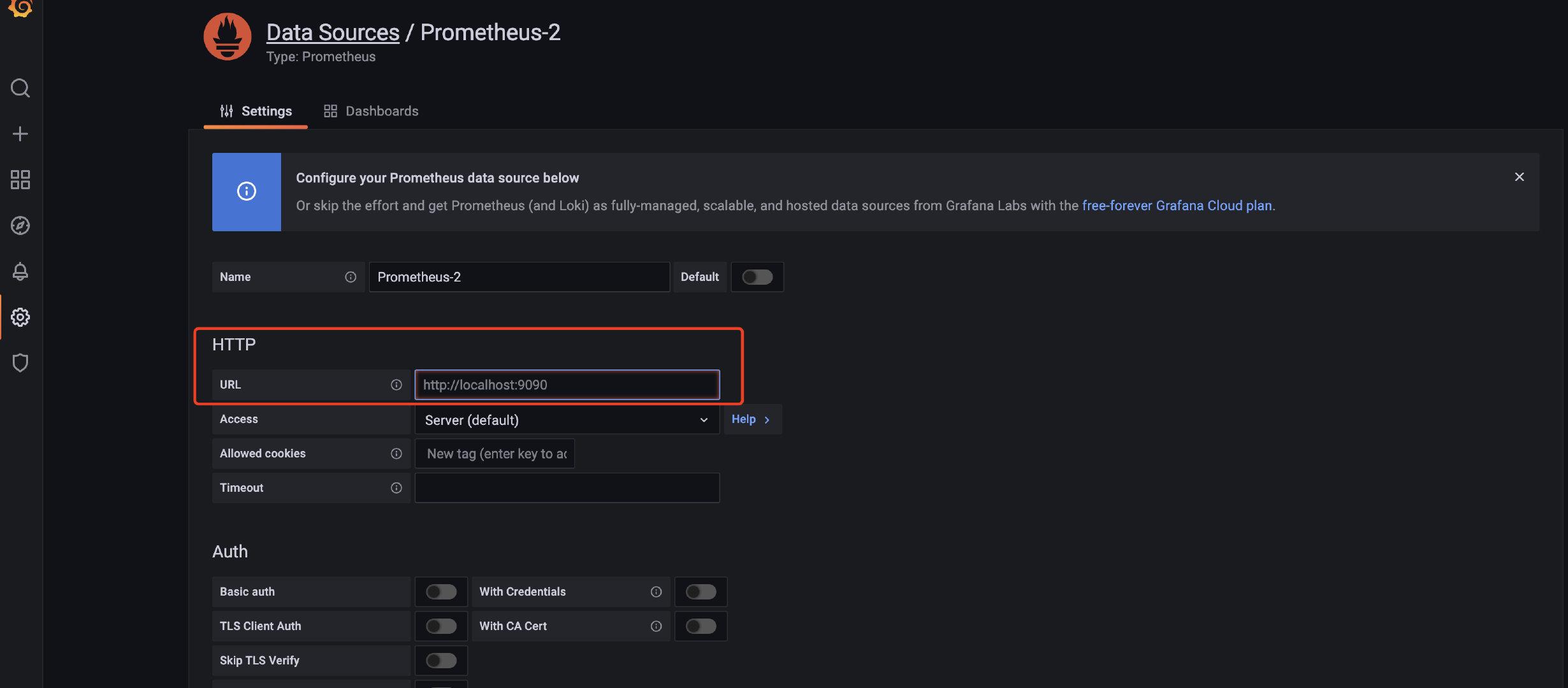
|
|
|
|
|
|
相关监控的模板可以在 <https://grafana.com/grafana/dashboards/> 这里查到。
|
|
|
|
|
|
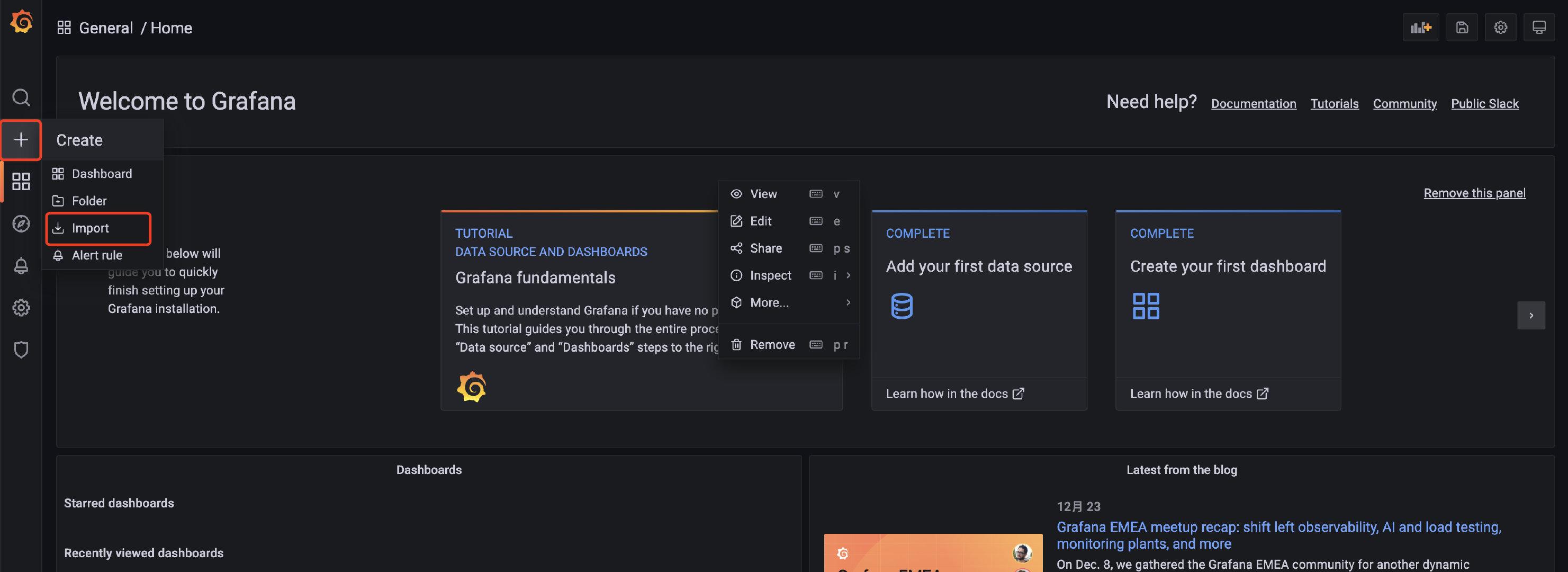
|
|
|
|
|
|
服务器的监控直接选用**8919**的就好了
|
|
|
|
|
|
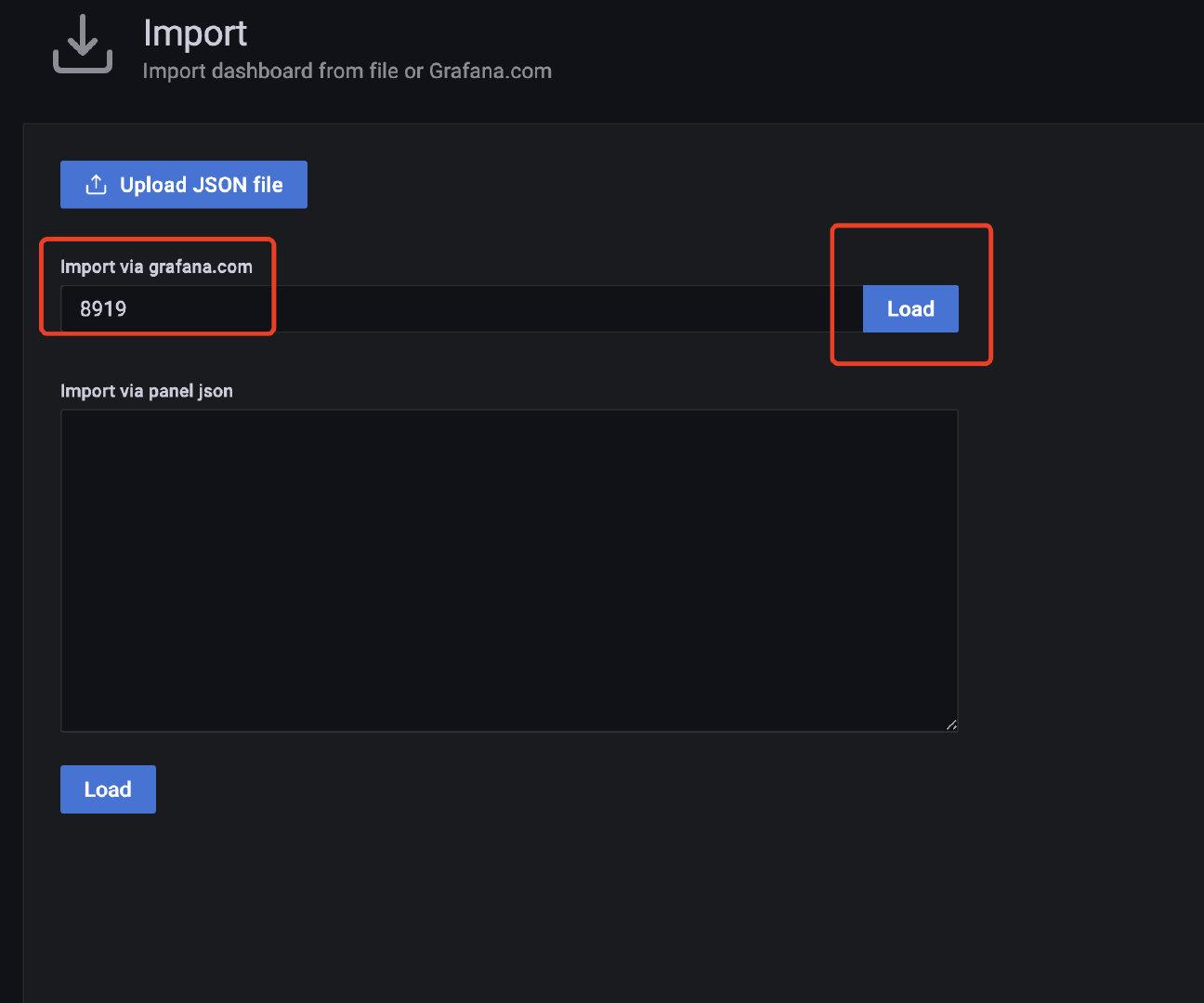
|
|
|
|
|
|
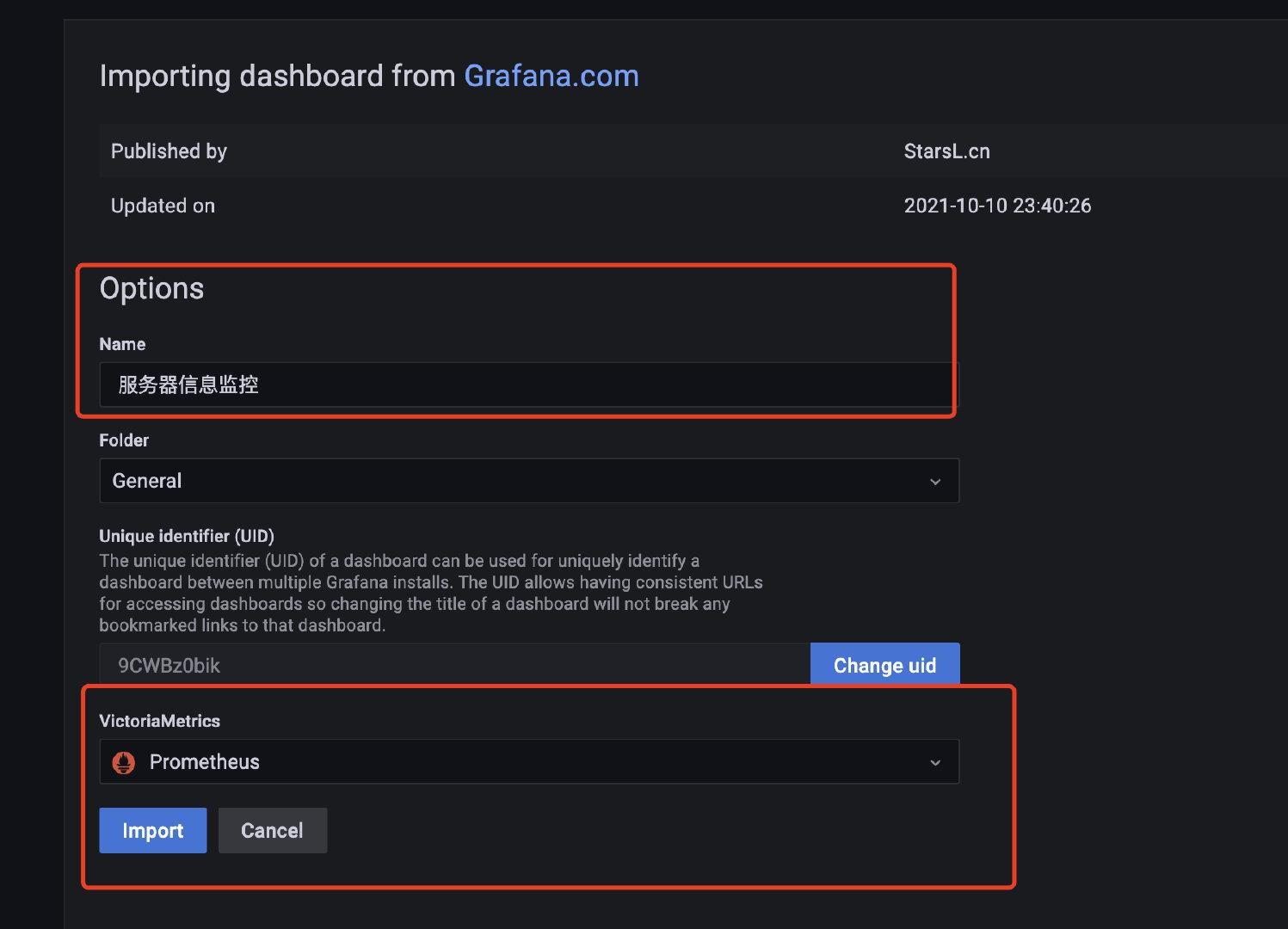
|
|
|
|
|
|
import后就能直接看到高大上的监控页面了:
|
|
|
|
|
|
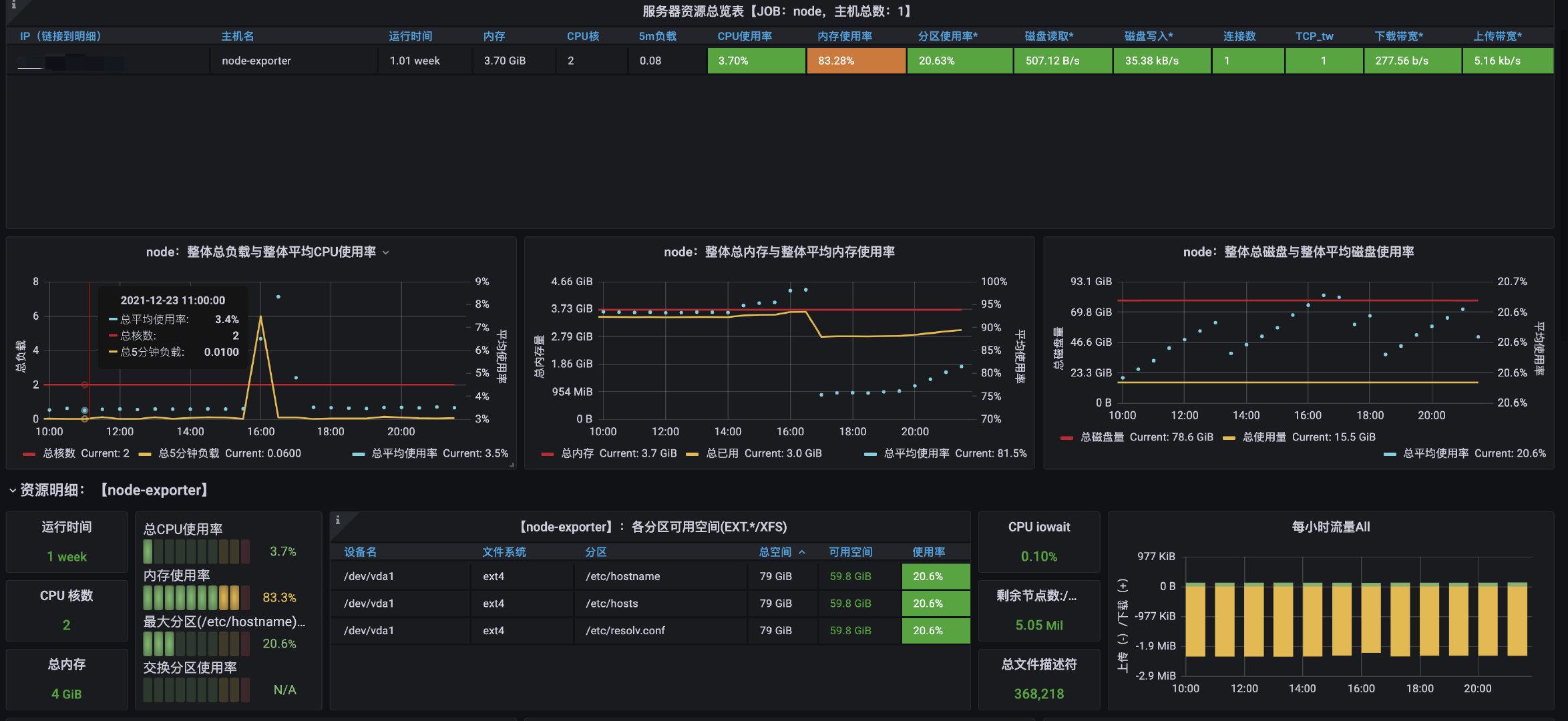
|
|
|
|
|
|
使用模板**893**来配置监控docker的信息:
|
|
|
|
|
|
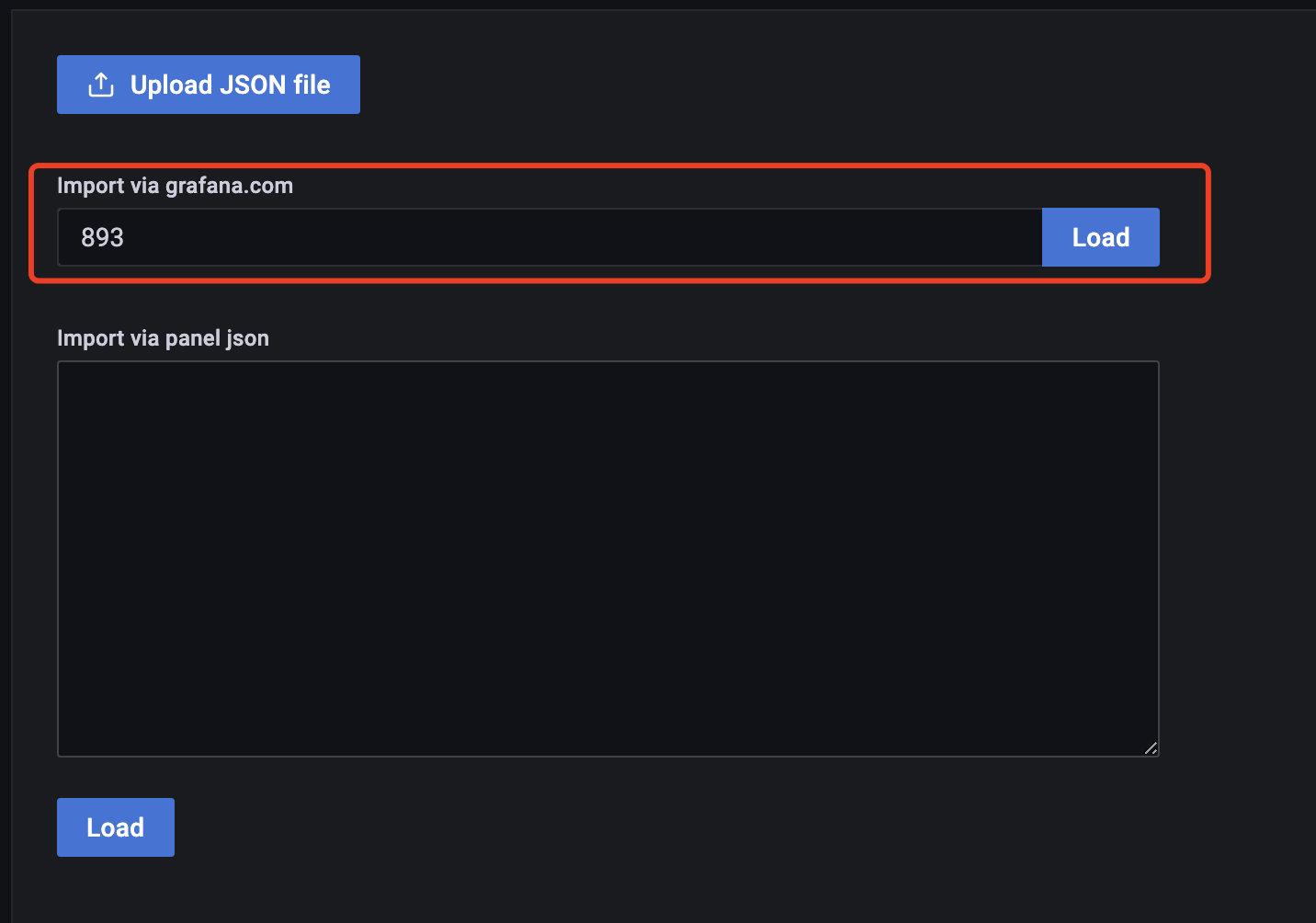
|
|
|
|
|
|
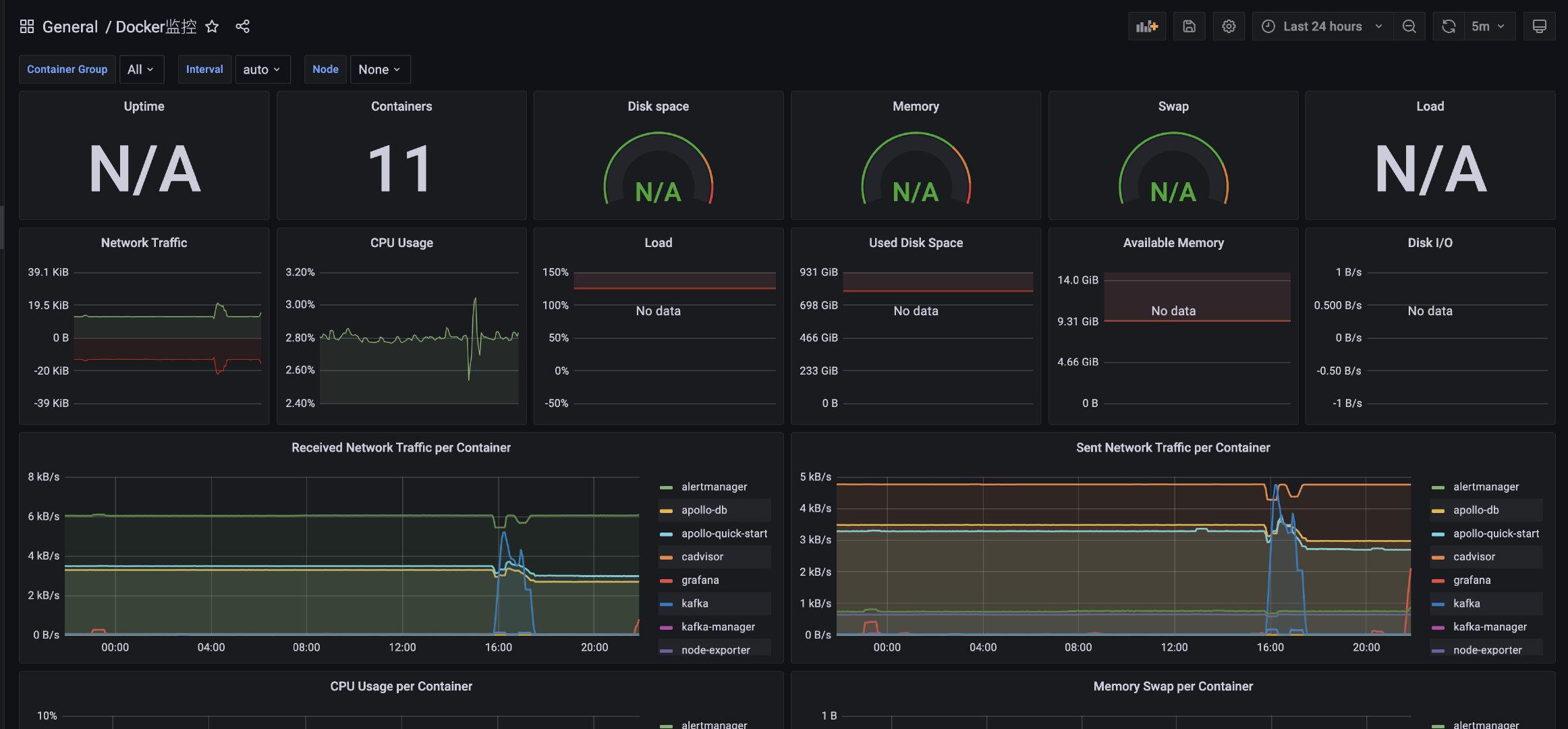
|
|
|
|
|
|
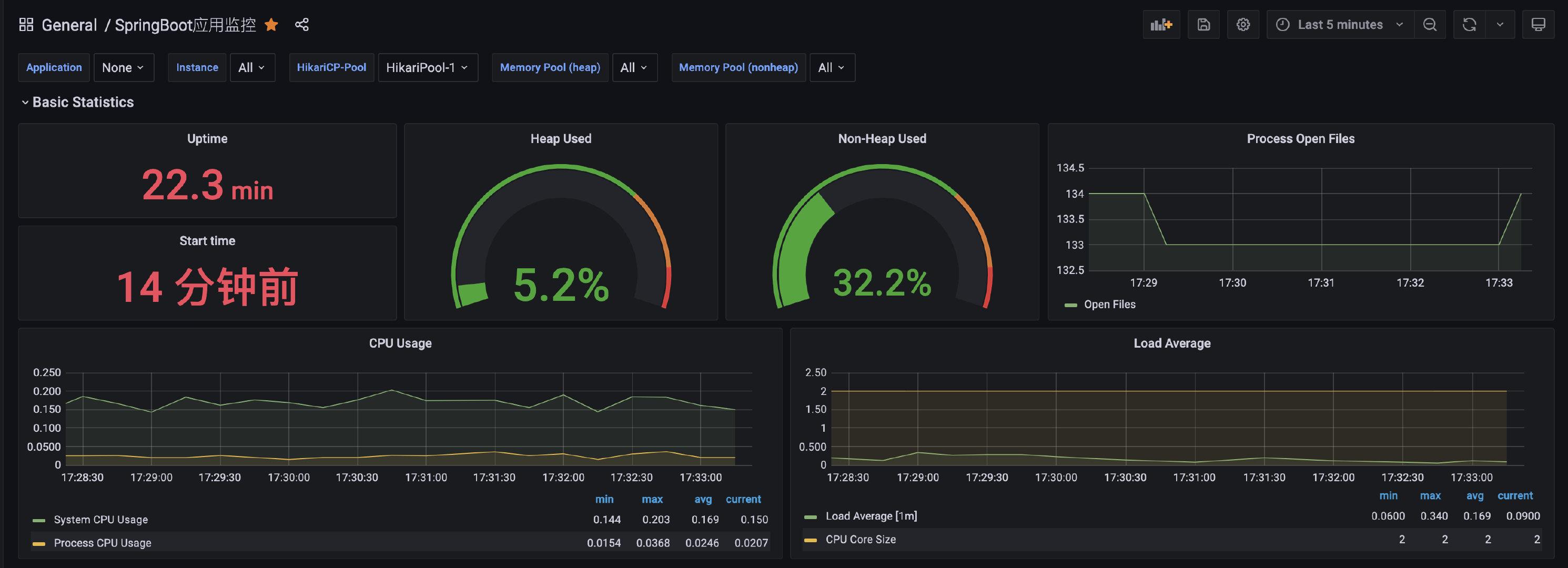
选用了`4701`模板的JVM监控和`12900`SpringBoot监控(**程序代码已经接入了actuator和prometheus**)。需要在`prometheus.yml`配置下新增暴露的服务地址:
|
|
|
|
|
|
```
|
|
|
- job_name: 'austin'
|
|
|
metrics_path: '/actuator/prometheus' # 采集的路径
|
|
|
static_configs:
|
|
|
- targets: ['ip:port'] # todo 这里的ip和端口写自己的应用下的
|
|
|
```
|
|
|
|
|
|
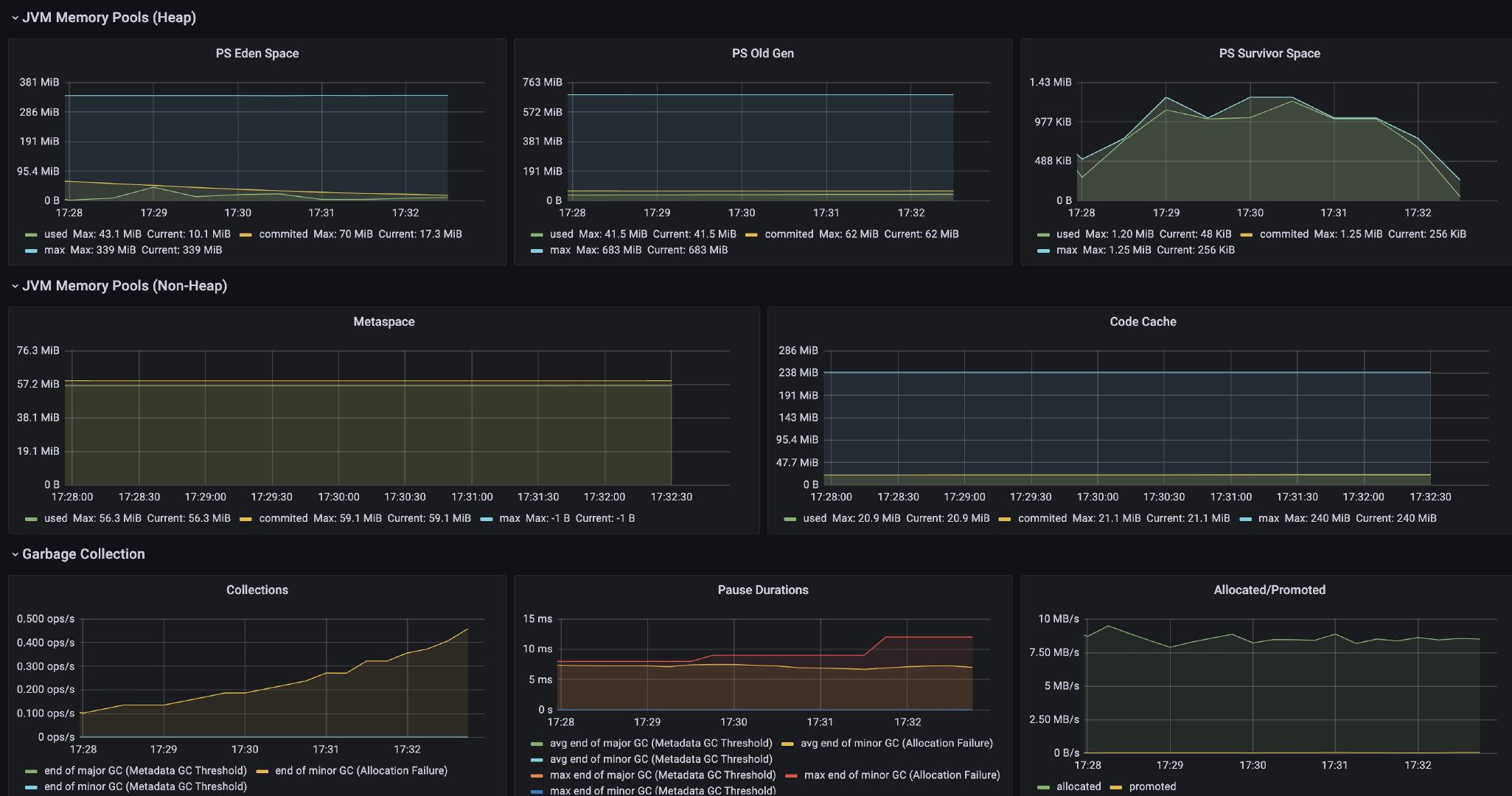
|
|
|
|
|
|
|
|
|
|
|
|
## 07、安装GRAYLOG(可选)-分布式日志收集框架
|
|
|
|
|
|
`docker-compose.yml`文件内容:
|
|
|
|
|
|
```
|
|
|
version: '3'
|
|
|
services:
|
|
|
mongo:
|
|
|
image: mongo:4.2
|
|
|
networks:
|
|
|
- graylog
|
|
|
elasticsearch:
|
|
|
image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2
|
|
|
environment:
|
|
|
- http.host=0.0.0.0
|
|
|
- transport.host=localhost
|
|
|
- network.host=0.0.0.0
|
|
|
- "ES_JAVA_OPTS=-Dlog4j2.formatMsgNoLookups=true -Xms512m -Xmx512m"
|
|
|
- GRAYLOG_ROOT_TIMEZONE=Asia/Shanghai
|
|
|
ulimits:
|
|
|
memlock:
|
|
|
soft: -1
|
|
|
hard: -1
|
|
|
deploy:
|
|
|
resources:
|
|
|
limits:
|
|
|
memory: 1g
|
|
|
networks:
|
|
|
- graylog
|
|
|
graylog:
|
|
|
image: graylog/graylog:4.2
|
|
|
environment:
|
|
|
- GRAYLOG_PASSWORD_SECRET=somepasswordpepper
|
|
|
- GRAYLOG_ROOT_PASSWORD_SHA2=8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
|
|
|
- GRAYLOG_HTTP_EXTERNAL_URI=http://ip:9009/ # 这里注意要改ip
|
|
|
- GRAYLOG_ROOT_TIMEZONE=Asia/Shanghai
|
|
|
entrypoint: /usr/bin/tini -- wait-for-it elasticsearch:9200 -- /docker-entrypoint.sh
|
|
|
networks:
|
|
|
- graylog
|
|
|
restart: always
|
|
|
depends_on:
|
|
|
- mongo
|
|
|
- elasticsearch
|
|
|
ports:
|
|
|
- 9009:9000
|
|
|
- 1514:1514
|
|
|
- 1514:1514/udp
|
|
|
- 12201:12201
|
|
|
- 12201:12201/udp
|
|
|
networks:
|
|
|
graylog:
|
|
|
driver: bridge
|
|
|
```
|
|
|
|
|
|
这个文件里唯一需要改动的就是`ip`(本来的端口是`9000`的,我由于已经占用了`9000`端口了,所以我这里把端口改成了`9009`,你们可以随意)
|
|
|
|
|
|
启动以后,我们就可以通过`ip:port`访问对应的Graylog后台地址了,默认的账号和密码是`admin/admin`
|
|
|
|
|
|
|
|
|
|
|
|
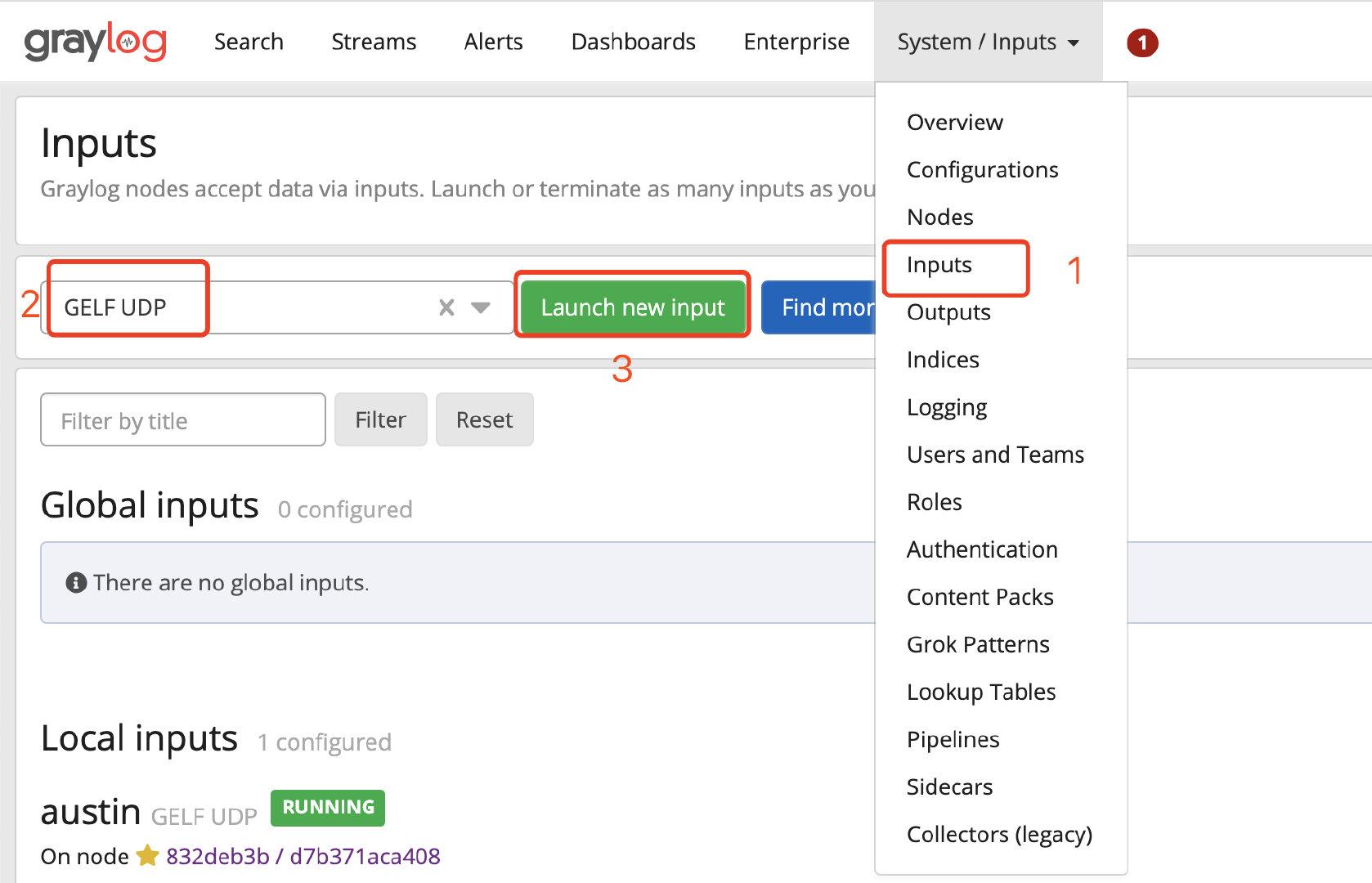
配置下`inputs`的配置,找到`GELF UDP`,然后点击`Launch new input`,只需要填写`Title`字段,保存就完事了(其他不用动)。
|
|
|
|
|
|
|
|
|
|
|
|
最后配置`austin.grayLogIp`的ip即可实现分布式日志收集
|
|
|
|
|
|
## 08、XXL-JOB
|
|
|
|
|
|
文档:[https://www.xuxueli.com/xxl-job/#2.1%20%E5%88%9D%E5%A7%8B%E5%8C%96%E2%80%9C%E8%B0%83%E5%BA%A6%E6%95%B0%E6%8D%AE%E5%BA%93%E2%80%9D](https://www.xuxueli.com/xxl-job/#2.1%20%E5%88%9D%E5%A7%8B%E5%8C%96%E2%80%9C%E8%B0%83%E5%BA%A6%E6%95%B0%E6%8D%AE%E5%BA%93%E2%80%9D)
|
|
|
|
|
|
xxl-job的部署我这边其实是依赖官网的文档的,步骤可以简单总结为:
|
|
|
|
|
|
**1**、把xxl-job的仓库拉下来
|
|
|
|
|
|
**2**、执行`/xxl-job/doc/db/tables_xxl_job.sql`的脚本(创建对应的库、创建表以及插入测试数据记录)
|
|
|
|
|
|
**3**、如果是**本地**启动「调度中心」则在`xxl-job-admin`的`application.properties`更改相应的数据库配置,改完启动即可
|
|
|
|
|
|
**4**、如果是**云服务**启动「调度中心」,则可以选择拉取`docker`镜像进行部署,我拉取的是`2.30`版本,随后执行以下命令即可:
|
|
|
|
|
|
```shell
|
|
|
docker pull xuxueli/xxl-job-admin:2.3.0
|
|
|
|
|
|
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://ip:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull --spring.datasource.username=root --spring.datasource.password=password " -p 6767:8080 --name xxl-job-admin -d xuxueli/xxl-job-admin:2.3.0
|
|
|
|
|
|
```
|
|
|
|
|
|
**注意**:第二条命令的**ip**和**password**需要更改为自己的,并且,我开的是**6767**端口
|
|
|
|
|
|

|
|
|
|
|
|
## 09、Flink
|
|
|
|
|
|
部署Flink也是直接上docker-compose就完事了,值得注意的是:我们在部署的时候需要在配置文件里**指定时区**
|
|
|
|
|
|
docker-compose.yml配置内容如下:
|
|
|
|
|
|
```yaml
|
|
|
version: "2.2"
|
|
|
services:
|
|
|
jobmanager:
|
|
|
image: flink:latest
|
|
|
ports:
|
|
|
- "8081:8081"
|
|
|
command: jobmanager
|
|
|
environment:
|
|
|
- |
|
|
|
FLINK_PROPERTIES=
|
|
|
jobmanager.rpc.address: jobmanager
|
|
|
- SET_CONTAINER_TIMEZONE=true
|
|
|
- CONTAINER_TIMEZONE=Asia/Shanghai
|
|
|
- TZ=Asia/Shanghai
|
|
|
taskmanager:
|
|
|
image: flink:latest
|
|
|
depends_on:
|
|
|
- jobmanager
|
|
|
command: taskmanager
|
|
|
environment:
|
|
|
- |
|
|
|
FLINK_PROPERTIES=
|
|
|
jobmanager.rpc.address: jobmanager
|
|
|
taskmanager.numberOfTaskSlots: 2
|
|
|
- SET_CONTAINER_TIMEZONE=true
|
|
|
- CONTAINER_TIMEZONE=Asia/Shanghai
|
|
|
- TZ=Asia/Shanghai
|
|
|
```
|
|
|
|
|
|
## 10、HIVE
|
|
|
|
|
|
部署Flink也是直接上docker-compose就完事了
|
|
|
|
|
|
1、把仓库拉到自己的服务器上
|
|
|
|
|
|
```shell
|
|
|
git clone git@github.com:big-data-europe/docker-hive.git
|
|
|
```
|
|
|
|
|
|
2、进入到项目的文件夹里
|
|
|
|
|
|
```shell
|
|
|
cd docker-hive
|
|
|
```
|
|
|
|
|
|
3、微调下docker-compose文件,内容如下(主要是增加了几个通信的端口)
|
|
|
|
|
|
```yml
|
|
|
version: "3"
|
|
|
|
|
|
services:
|
|
|
namenode:
|
|
|
image: bde2020/hadoop-namenode:2.0.0-hadoop2.7.4-java8
|
|
|
volumes:
|
|
|
- namenode:/hadoop/dfs/name
|
|
|
environment:
|
|
|
- CLUSTER_NAME=test
|
|
|
env_file:
|
|
|
- ./hadoop-hive.env
|
|
|
ports:
|
|
|
- "50070:50070"
|
|
|
- "9000:9000"
|
|
|
- "8020:8020"
|
|
|
datanode:
|
|
|
image: bde2020/hadoop-datanode:2.0.0-hadoop2.7.4-java8
|
|
|
volumes:
|
|
|
- datanode:/hadoop/dfs/data
|
|
|
env_file:
|
|
|
- ./hadoop-hive.env
|
|
|
environment:
|
|
|
SERVICE_PRECONDITION: "namenode:50070"
|
|
|
ports:
|
|
|
- "50075:50075"
|
|
|
- "50010:50010"
|
|
|
- "50020:50020"
|
|
|
hive-server:
|
|
|
image: bde2020/hive:2.3.2-postgresql-metastore
|
|
|
env_file:
|
|
|
- ./hadoop-hive.env
|
|
|
environment:
|
|
|
HIVE_CORE_CONF_javax_jdo_option_ConnectionURL: "jdbc:postgresql://hive-metastore/metastore"
|
|
|
SERVICE_PRECONDITION: "hive-metastore:9083"
|
|
|
ports:
|
|
|
- "10000:10000"
|
|
|
hive-metastore:
|
|
|
image: bde2020/hive:2.3.2-postgresql-metastore
|
|
|
env_file:
|
|
|
- ./hadoop-hive.env
|
|
|
command: /opt/hive/bin/hive --service metastore
|
|
|
environment:
|
|
|
SERVICE_PRECONDITION: "namenode:50070 datanode:50075 hive-metastore-postgresql:5432"
|
|
|
ports:
|
|
|
- "9083:9083"
|
|
|
hive-metastore-postgresql:
|
|
|
image: bde2020/hive-metastore-postgresql:2.3.0
|
|
|
ports:
|
|
|
- "5432:5432"
|
|
|
presto-coordinator:
|
|
|
image: shawnzhu/prestodb:0.181
|
|
|
ports:
|
|
|
- "8080:8080"
|
|
|
volumes:
|
|
|
namenode:
|
|
|
datanode:
|
|
|
```
|
|
|
|
|
|
4、最后,我们可以连上`hive`的客户端,感受下快速安装好`hive`的成功感。
|
|
|
|
|
|
```shell
|
|
|
# 进入bash
|
|
|
docker-compose exec hive-server bash
|
|
|
|
|
|
# 使用beeline客户端连接
|
|
|
/opt/hive/bin/beeline -u jdbc:hive2://localhost:10000
|
|
|
```
|
|
|
|
|
|
## 11、FLINK和HIVE融合
|
|
|
|
|
|
实时流处理的flink用的是docker-compose进行部署,而与hive融合的flink我这边是正常的姿势安装(主要是涉及的环境很多,用docker-compose就相对没那么方便了)
|
|
|
|
|
|
### 11.1 安装flink环境
|
|
|
|
|
|
1、下载`flink`压缩包
|
|
|
|
|
|
```shell
|
|
|
wget https://dlcdn.apache.org/flink/flink-1.16.0/flink-1.16.0-bin-scala_2.12.tgz
|
|
|
```
|
|
|
|
|
|
2、解压`flink`
|
|
|
|
|
|
```shell
|
|
|
tar -zxf flink-1.16.0-bin-scala_2.12.tgz
|
|
|
```
|
|
|
|
|
|
3、修改该目录下的`conf`下的`flink-conf.yaml`文件中`rest.bind-address`配置,不然**远程访问不到**`8081`端口,将其改为`0.0.0.0`
|
|
|
|
|
|
```shell
|
|
|
rest.bind-address: 0.0.0.0
|
|
|
```
|
|
|
|
|
|
4、将`flink`官网提到连接`hive`所需要的`jar`包下载到`flink`的`lib`目录下(一共4个)
|
|
|
|
|
|
```shell
|
|
|
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-2.3.9_2.12/1.16.0/flink-sql-connector-hive-2.3.9_2.12-1.16.0.jar
|
|
|
|
|
|
wget https://repo.maven.apache.org/maven2/org/apache/hive/hive-exec/2.3.4/hive-exec-2.3.4.jar
|
|
|
|
|
|
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-hive_2.12/1.16.0/flink-connector-hive_2.12-1.16.0.jar
|
|
|
|
|
|
wget https://repo.maven.apache.org/maven2/org/antlr/antlr-runtime/3.5.2/antlr-runtime-3.5.2.jar
|
|
|
```
|
|
|
|
|
|
5、按照官网指示把`flink-table-planner_2.12-1.16.0.jar`和`flink-table-planner-loader-1.16.0.jar` 这俩个`jar`包移动其目录;
|
|
|
|
|
|
```shell
|
|
|
mv $FLINK_HOME/opt/flink-table-planner_2.12-1.16.0.jar $FLINK_HOME/lib/flink-table-planner_2.12-1.16.0.jar
|
|
|
mv $FLINK_HOME/lib/flink-table-planner-loader-1.16.0.jar $FLINK_HOME/opt/flink-table-planner-loader-1.16.0.jar
|
|
|
```
|
|
|
|
|
|
6、把后续`kafka`所需要的依赖也下载到`lib`目录下
|
|
|
|
|
|
```shell
|
|
|
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka/1.16.0/flink-connector-kafka-1.16.0.jar
|
|
|
|
|
|
wget https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/3.3.1/kafka-clients-3.3.1.jar
|
|
|
```
|
|
|
|
|
|
7、把工程下的`hive-site.xml`文件拷贝到`$FLINK_HOME/conf`下,内容如下(**hive_ip**自己变动)
|
|
|
|
|
|
```xml
|
|
|
<?xml version="1.0"?>
|
|
|
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
|
|
|
|
|
|
|
|
|
<configuration>
|
|
|
<property>
|
|
|
<name>javax.jdo.option.ConnectionURL</name>
|
|
|
<value>jdbc:postgresql://hive_ip:5432/metastore?createDatabaseIfNotExist=true</value>
|
|
|
<description>JDBC connect string for a JDBC metastore</description>
|
|
|
</property>
|
|
|
|
|
|
<property>
|
|
|
<name>javax.jdo.option.ConnectionDriverName</name>
|
|
|
<value>org.postgresql.Driver</value>
|
|
|
<description>Driver class name for a JDBC metastore</description>
|
|
|
</property>
|
|
|
|
|
|
<property>
|
|
|
<name>javax.jdo.option.ConnectionUserName</name>
|
|
|
<value>hive</value>
|
|
|
<description>username to use against metastore database</description>
|
|
|
</property>
|
|
|
|
|
|
<property>
|
|
|
<name>javax.jdo.option.ConnectionPassword</name>
|
|
|
<value>hive</value>
|
|
|
<description>password to use against metastore database</description>
|
|
|
</property>
|
|
|
|
|
|
<property>
|
|
|
<name>hive.metastore.uris</name>
|
|
|
<value>thrift://hive_ip:9083</value>
|
|
|
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.
|
|
|
</description>
|
|
|
</property>
|
|
|
|
|
|
<property>
|
|
|
<name>datanucleus.schema.autoCreateAll</name>
|
|
|
<value>true</value>
|
|
|
</property>
|
|
|
|
|
|
</configuration>
|
|
|
```
|
|
|
|
|
|
### 11.2 安装hadoop环境
|
|
|
|
|
|
由于`hive`的镜像已经锁死了`hadoop`的版本为`2.7.4`,所以我这边`flink`所以来的`hadoop`也是下载`2.7.4`版本
|
|
|
|
|
|
1、下载`hadoop`压缩包
|
|
|
|
|
|
```shell
|
|
|
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
|
|
|
```
|
|
|
|
|
|
2、解压`hadoop`
|
|
|
|
|
|
```shell
|
|
|
tar -zxf hadoop-2.7.4.tar.gz
|
|
|
```
|
|
|
|
|
|
3、`hadoop`的配置文件`hdfs-site.xml`增加以下内容(我的目录在`/root/hadoop-2.7.4/etc/hadoop`)
|
|
|
|
|
|
```xml
|
|
|
<property>
|
|
|
<name>dfs.client.use.datanode.hostname</name>
|
|
|
<value>true</value>
|
|
|
<description>only cofig in clients</description>
|
|
|
</property>
|
|
|
```
|
|
|
|
|
|
### 11.3 安装jdk11
|
|
|
|
|
|
由于高版本的`flink`需要`jdk 11`,所以这边安装下该版本的`jdk`:
|
|
|
|
|
|
```shell
|
|
|
yum install java-11-openjdk.x86_64
|
|
|
yum install java-11-openjdk-devel.x86_64
|
|
|
```
|
|
|
|
|
|
### 11.4 配置jdk、hadoop的环境变量
|
|
|
|
|
|
这一步为了能让`flink`在启动的时候,加载到`jdk`和`hadoop`的环境。
|
|
|
|
|
|
1、编辑`/etc/profile`文件
|
|
|
|
|
|
```shell
|
|
|
vim /etc/profile
|
|
|
```
|
|
|
|
|
|
2、文件内容最底下增加以下配置:
|
|
|
|
|
|
```shell
|
|
|
JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.17.0.8-2.el7_9.x86_64
|
|
|
JRE_HOME=$JAVA_HOME/jre
|
|
|
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
|
|
|
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
|
|
|
export JAVA_HOME JRE_HOME CLASS_PATH PATH
|
|
|
export HADOOP_HOME=/root/hadoop-2.7.4
|
|
|
export PATH=$HADOOP_HOME/bin:$PATH
|
|
|
export HADOOP_CLASSPATH=`hadoop classpath`
|
|
|
```
|
|
|
|
|
|
3、让配置文件生效
|
|
|
|
|
|
```shell
|
|
|
source /etc/profile
|
|
|
```
|
|
|
|
|
|
### 11.5 增加hosts进行通信(flink和namenode/datanode之间)
|
|
|
|
|
|
在部署`flink`服务器上增加`hosts`,有以下(`ip`为部署`hive`的地址):
|
|
|
|
|
|
```shell
|
|
|
127.0.0.1 namenode
|
|
|
127.0.0.1 datanode
|
|
|
127.0.0.1 b2a0f0310722
|
|
|
```
|
|
|
|
|
|
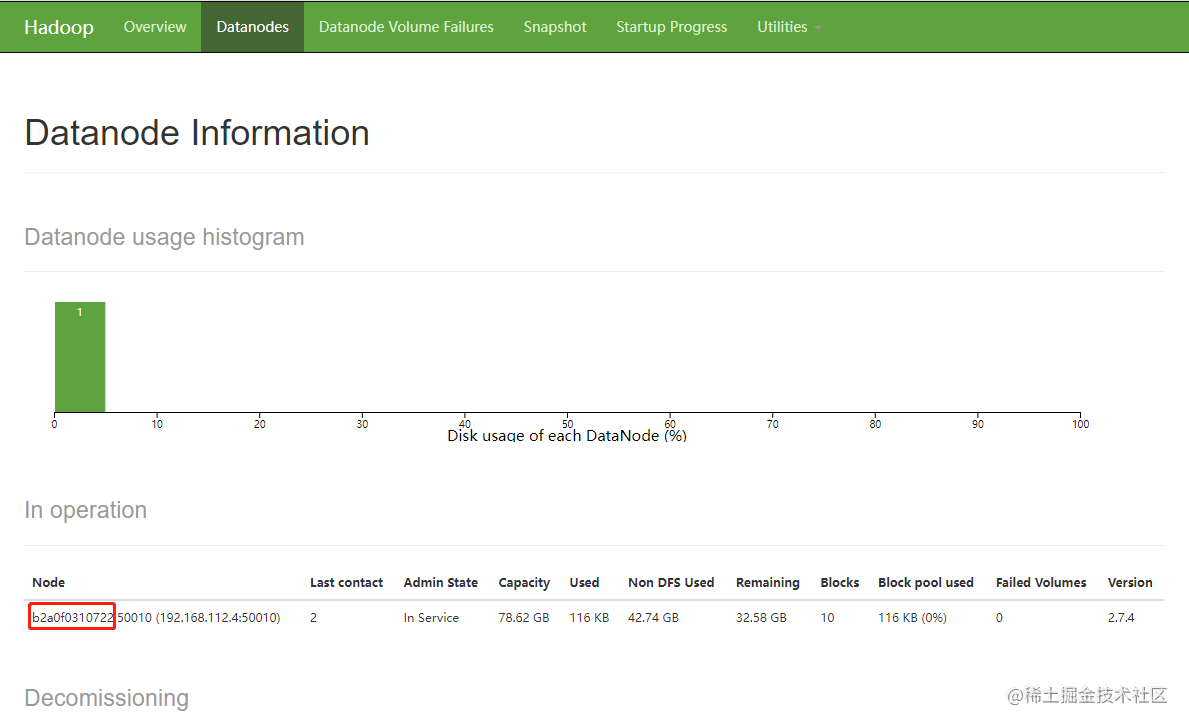
其中 `b2a0f0310722`是`datanode`的主机名,该主机名会随着`hive`的`docker`而变更,我们可以登录`namenode`的后台地址找到其主机名。而方法则是在部署`hive`的地址输入:
|
|
|
|
|
|
```
|
|
|
http://localhost:50070/dfshealth.html#tab-datanode
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
### 11.6 启动flink调试kafka数据到hive
|
|
|
|
|
|
启动`flink-sql`的客户端:
|
|
|
|
|
|
```shell
|
|
|
./sql-client.sh
|
|
|
```
|
|
|
|
|
|
在`sql`客户端下执行以下脚本命令,注:`hive-conf-dir`要放在`$FLINK_HOME/conf`下
|
|
|
|
|
|
```shell
|
|
|
CREATE CATALOG my_hive WITH (
|
|
|
'type' = 'hive',
|
|
|
'hive-conf-dir' = '/root/flink-1.16.0/conf'
|
|
|
);
|
|
|
```
|
|
|
|
|
|
```shell
|
|
|
use catalog my_hive;
|
|
|
```
|
|
|
|
|
|
```shell
|
|
|
create database austin;
|
|
|
```
|
|
|
|
|
|
重启`flink`集群
|
|
|
|
|
|
```shell
|
|
|
./stop-cluster.sh
|
|
|
```
|
|
|
|
|
|
```shell
|
|
|
./start-cluster.sh
|
|
|
```
|
|
|
|
|
|
重新提交执行`flink`任务
|
|
|
|
|
|
```shell
|
|
|
./flink run austin-data-house-0.0.1-SNAPSHOT.jar
|
|
|
```
|
|
|
|
|
|
启动消费者的命令(将`ip`和`port`改为自己服务器所部署的Kafka信息):
|
|
|
|
|
|
```shell
|
|
|
$KAFKA_HOME/bin/kafka-console-producer.sh --topic austinTraceLog --broker-list ip:port
|
|
|
```
|
|
|
|
|
|
输入测试数据:
|
|
|
|
|
|
```json
|
|
|
{"state":"1","businessId":"2","ids":[1,2,3],"logTimestamp":"123123"}
|
|
|
```
|
|
|
|
|
|
## 12、安装METABASE
|
|
|
|
|
|
部署`Metabase`很简单,也是使用`docker`进行安装部署,就两行命令(后续我会将其加入到`docker-compose`里面)。
|
|
|
|
|
|
```shell
|
|
|
docker pull metabase/metabase:latest
|
|
|
```
|
|
|
|
|
|
```shell
|
|
|
docker run -d -p 5001:3000 --name metabase metabase/metabase
|
|
|
```
|
|
|
|
|
|
完了之后,我们就可以打开`5001`端口到`Metabase`的后台了。
|
|
|
|
|
|
|
|
|
|
|
|
## 13、未完待续
|
|
|
|
|
|
安装更详细的过程以及整个文章系列的更新思路都在公众号**Java3y**连载哟!
|
|
|
|
|
|
如果你需要用这个项目写在简历上,**强烈建议关注公众号看实现细节的思路**。如果⽂档中有任何的不懂的问题,都可以直接来找我询问,我乐意帮助你们!公众号下有我的联系方式
|
|
|
|
|
|
<img align="center" src='https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/4e109cdb8d064c1e87541d7b6c17957d~tplv-k3u1fbpfcp-zoom-1.image' width=300px height=300px /> |