22 KiB
语音识别: DeepSpeech2
DeepSpeech2是一个采用PaddlePaddle平台的端到端自动语音识别(ASR)引擎的开源项目,具体原理参考这篇论文Baidu's Deep Speech 2 paper。 我们的愿景是为语音识别在工业应用和学术研究上,提供易于使用、高效和可扩展的工具,包括训练,推理,测试模块,以及 demo 部署。同时,我们还将发布一些预训练好的英语和普通话模型。
目录
安装
为了避免环境配置问题,强烈建议在Docker容器上运行,否则请按照下面的指南安装依赖项。
前提
- 只支持Python 2.7
- PaddlePaddle 1.6.0 版本及以上(请参考安装指南)
安装
- 请确保以下库或工具已安装完毕:
pkg-config,flac,ogg,vorbis,boost和swig, 如可以通过apt-get安装:
sudo apt-get install -y pkg-config libflac-dev libogg-dev libvorbis-dev libboost-dev swig
或者,也可以通过yum安装:
sudo yum install pkgconfig libogg-devel libvorbis-devel boost-devel
wget https://ftp.osuosl.org/pub/xiph/releases/flac/flac-1.3.1.tar.xz
xz -d flac-1.3.1.tar.xz
tar -xvf flac-1.3.1.tar
cd flac-1.3.1
./configure
make
make install
- 运行脚本安装其余的依赖项
git clone https://github.com/PaddlePaddle/DeepSpeech.git
cd DeepSpeech
sh setup.sh
开始
./examples里的一些 shell 脚本将帮助我们在一些公开数据集(比如:LibriSpeech, Aishell) 进行快速尝试,包括了数据准备,模型训练,案例推断和模型评价。阅读这些例子将帮助你理解如何使用你的数据集训练模型。
./examples目录中的一些脚本配置使用了 8 个 GPU。如果你没有 8 个可用的 GPU,请修改环境变量CUDA_VISIBLE_DEVICES。如果你没有可用的 GPU,请设置--use_gpu为 False,这样程序会用 CPU 代替 GPU。另外如果发生内存不足的问题,减小--batch_size即可。
让我们先看看LibriSpeech dataset小样本集的例子。
-
进入目录
cd examples/tiny注意这仅仅是 LibriSpeech 一个小数据集的例子。如果你想尝试完整的数据集(可能需要花好几天来训练模型),请使用这个路径
examples/librispeech。 -
准备数据
sh run_data.sh运行
run_data.sh脚本将会下载数据集,产出 manifests 文件,收集一些归一化需要的统计信息并建立词表。当数据准备完成之后,下载完的数据(仅有 LibriSpeech 一部分)在dataset/librispeech中;其对应的 manifest 文件,均值标准差和词表文件在./data/tiny中。在第一次执行的时候一定要执行这个脚本,在接下来所有的实验中我们都会用到这个数据集。 -
训练你自己的 ASR 模型
sh run_train.shrun_train.sh将会启动训练任务,训练日志会打印到终端,并且模型每个 epoch 的 checkpoint 都会保存到./checkpoints/tiny目录中。这些 checkpoint 可以用来恢复训练,推断,评价和部署。 -
用已有的模型进行案例推断
sh run_infer.shrun_infer.sh将会利用训练好的模型展现一些(默认 10 个)样本语音到文本的解码结果。由于当前模型只使用了 LibriSpeech 一部分数据集训练,因此性能可能不会太好。为了看到更好模型上的表现,你可以下载一个已训练好的模型(用完整的 LibriSpeech 训练了好几天)来做推断。sh run_infer_golden.sh -
评价一个已经存在的模型
sh run_test.shrun_test.sh能够利用误字率(或字符错误率)来评价模型。类似的,你可以下载一个完全训练好的模型来测试它的性能:sh run_test_golden.sh
更多细节会在接下来的章节中阐述。祝你在DeepSpeech2ASR引擎学习中过得愉快!
数据准备
生成Manifest
DeepSpeech2接受文本manifest文件作为数据接口。manifest 文件包含了一系列语音数据,其中每一行代表一个JSON格式的音频元数据(比如文件路径,描述,时长)。具体格式如下:
{"audio_filepath": "/home/work/.cache/paddle/Libri/134686/1089-134686-0001.flac", "duration": 3.275, "text": "stuff it into you his belly counselled him"}
{"audio_filepath": "/home/work/.cache/paddle/Libri/134686/1089-134686-0007.flac", "duration": 4.275, "text": "a cold lucid indifference reigned in his soul"}
如果你要使用自定义数据,你只需要按照以上格式生成自己的 manifest 文件即可。给定 manifest 文件,训练、推断以及其它所有模块都能够访问到音频数据以及对应的时长和标签数据。
关于如何生成 manifest 文件,请参考data/librispeech/librispeech.py。该脚本将会下载 LibriSpeech 数据集并生成 manifest 文件。
计算均值和标准差用于归一化
为了对音频特征进行 z-score 归一化(零均值,单位标准差),我们必须预估训练样本特征的均值和标准差:
python tools/compute_mean_std.py \
--num_samples 2000 \
--specgram_type linear \
--manifest_paths data/librispeech/manifest.train \
--output_path data/librispeech/mean_std.npz
以上这段代码会计算在data/librispeech/manifest.train路径中,2000 个随机采样的语音频谱特征的均值和标准差,并将结果保存在data/librispeech/mean_std.npz中,方便以后使用。
建立词表
我们需要一个包含可能会出现的字符集合的词表来在训练的时候将字符转换成索引,并在解码的时候将索引转换回文本。tools/build_vocab.py脚本将生成这种基于字符的词表。
python tools/build_vocab.py \
--count_threshold 0 \
--vocab_path data/librispeech/eng_vocab.txt \
--manifest_paths data/librispeech/manifest.train
它将data/librispeech/manifest.train目录中的所有录音文本写入词表文件data/librispeeech/eng_vocab.txt,并且没有词汇截断(--count_threshold 0)。
更多帮助
获得更多帮助:
python data/librispeech/librispeech.py --help
python tools/compute_mean_std.py --help
python tools/build_vocab.py --help
训练模型
train.py是训练模块的主要调用者。使用示例如下。
-
开始使用 8 片 GPU 训练:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python train.py -
开始使用 CPU 训练:
python train.py --use_gpu False -
从检查点恢复训练:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \ python train.py \ --init_from_pretrained_model CHECKPOINT_PATH_TO_RESUME_FROM
获得更多帮助:
python train.py --help
或参考 example/librispeech/run_train.sh.
数据增强流水线
数据增强是用来提升深度学习性能的非常有效的技术。我们通过在原始音频中添加小的随机扰动(标签不变转换)获得新音频来增强我们的语音数据。你不必自己合成,因为数据增强已经嵌入到数据生成器中并且能够即时完成,在训练模型的每个epoch中随机合成音频。
目前提供六个可选的增强组件供选择,配置并插入处理过程。
- 音量扰动
- 速度扰动
- 移动扰动
- 在线贝叶斯归一化
- 噪声干扰(需要背景噪音的音频文件)
- 脉冲响应(需要脉冲音频文件)
为了让训练模块知道需要哪些增强组件以及它们的处理顺序,我们需要事先准备一个JSON格式的扩展配置文件。例如:
[{
"type": "speed",
"params": {"min_speed_rate": 0.95,
"max_speed_rate": 1.05},
"prob": 0.6
},
{
"type": "shift",
"params": {"min_shift_ms": -5,
"max_shift_ms": 5},
"prob": 0.8
}]
当trainer.py的--augment_conf_file参数被设置为上述示例配置文件的路径时,每个 epoch 中的每个音频片段都将被处理。首先,均匀随机采样速率会有60%的概率在 0.95 和 1.05 之间对音频片段进行速度扰动。然后,音频片段有 80% 的概率在时间上被挪移,挪移偏差值是 -5 毫秒和 5 毫秒之间的随机采样。最后,这个新合成的音频片段将被传送给特征提取器,以用于接下来的训练。
有关其他配置实例,请参考conf/augmenatation.config.example.
使用数据增强技术时要小心,由于扩大了训练和测试集的差异,不恰当的增强会对训练模型不利,导致训练和预测的差距增大。
推断和评价
准备语言模型
提升解码器的性能需要准备语言模型。我们准备了两种语言模型(有损压缩)供用户下载和尝试。一个是英语模型,另一个是普通话模型。用户可以执行以下命令来下载已经训练好的语言模型:
cd models/lm
bash download_lm_en.sh
bash download_lm_ch.sh
如果你想训练自己更好的语言模型,请参考KenLM获取教程。在这里,我们提供一些技巧来展示我们如何准备我们的英语和普通话模型。当你训练自己的模型的时候,可以参考这些技巧。
英语语言模型
英语语料库来自Common Crawl Repository,你可以从statmt下载它。我们使用en.00部分来训练我们的英语语言模型。训练前有如下的一些预处理过程:
- 不在['A-Za-z0-9\s'](\s表示空白字符)中的字符将被删除,阿拉伯数字被转换为英文数字,比如“1000”转换为 one thousand。
- 重复的空白字符被压缩为一个,并且开始的空白字符将被删除。请注意,所有的录音都是小写字母,因此所有字符都转换为小写字母。
- 选择前 40 万个最常用的单词来建立词表,其余部分将被替换为“UNKNOWNWORD”。
现在预处理完成了,我们得到一个干净的语料库来训练语言模型。我们发布的语言模型版本使用了参数“-o 5 --prune 0 1 1 1 1”来训练。“-o 5”表示语言模型的最大order为 5。“--prune 0 1 1 1 1”表示每个 order 的计数阈值,更具体地说,它将第 2 个以及更高的 order 修剪为单个。为了节省磁盘存储空间,我们将使用参数“-a 22 -q 8 -b 8”将 arpa 文件转换为“trie”二进制文件。“-a”表示在“trie”中用于切分的指针的最高位数。“-q -b”是概率和退避的量化参数。
普通话语言模型
与英语语言模型不同的是,普通话语言模型是基于字符的,其中每一位都是中文汉字。我们使用内部语料库来训练发布的汉语语言模型。该语料库包含数十亿汉字。预处理阶段与英语语言模型有一些小的差别,主要步骤包括:
- 删除开始和结尾的空白字符。
- 删除英文标点和中文标点。
- 在两个字符之间插入空白字符。
请注意,发布的语言模型只包含中文简体字。预处理完成后,我们开始训练语言模型。这个小的语言模型训练关键参数是“-o 5 --prune 0 1 2 4 4”,“-o 5”是针对大语言模型。请参考上面的部分了解每个参数的含义。我们还使用默认设置将 arpa 文件转换为二进制文件。
语音到文本推断
推断模块使用infer.py进行调用,可以用来推断,解码,以及输出一些给定音频片段可视化到文本的结果。这有助于对ASR模型的性能进行直观和定性的评估。
-
GPU 版本的推断:
CUDA_VISIBLE_DEVICES=0 python infer.py -
CPU 版本的推断:
python infer.py --use_gpu False
我们提供两种类型的 CTC 解码器:CTC贪心解码器和CTC波束搜索解码器。CTC贪心解码器是简单的最佳路径解码算法的实现,在每个时间步选择最可能的字符,因此是贪心的并且是局部最优的。CTC波束搜索解码器另外使用了启发式广度优先图搜索以达到近似全局最优; 它也需要预先训练的KenLM语言模型以获得更好的评分和排名。解码器类型可以用参数--decoding_method设置。
获得更多帮助:
python infer.py --help
或参考example/librispeech/run_infer.sh.
评估模型
要定量评估模型的性能,请运行:
-
GPU 版本评估
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python test.py -
CPU 版本评估
python test.py --use_gpu False
错误率(默认:误字率;可以用--error_rate_type设置)将被打印出来。
获得更多帮助:
python test.py --help
或参考example/librispeech/run_test.sh.
超参数调整
CTC波束搜索解码器的超参数\alpha(语言模型权重)和\beta(单词插入权重)对解码器的性能有非常显著的影响。当声学模型更新时,最好在验证集上重新调整它们。
tools/tune.py会进行2维网格查找超参数\alpha和\beta。你必须提供\alpha和\beta的范围,以及尝试的次数。
-
GPU 版的调整:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \ python tools/tune.py \ --alpha_from 1.0 \ --alpha_to 3.2 \ --num_alphas 45 \ --beta_from 0.1 \ --beta_to 0.45 \ --num_betas 8 -
CPU 版的调整:
python tools/tune.py --use_gpu False
网格搜索将会在超参数空间的每个点处打印出 WER (误字率)或者 CER (字符错误率),并且可绘出误差曲面。一个合适的超参数范围应包括 WER/CER 误差表面的全局最小值,如下图所示。
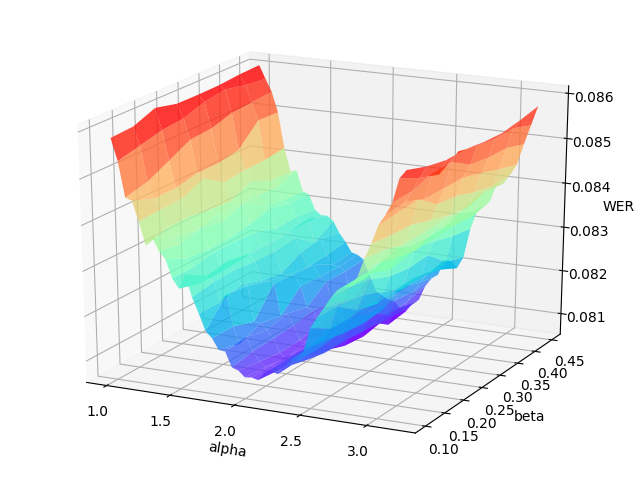
调整LibriSpeech的dev-clean集合的误差曲面示例
通常,如图所示,语言模型权重(\alpha)的变化显著影响 CTC波束搜索解码器的性能。更好的方法是首先调整多批数据(可指定数量)以找出适当的超参数范围,然后更改为完整的验证集以进行精确调整。
调整之后,您可以在推理和评价模块中重置\alpha和\beta,以检查它们是否真的有助于提高 ASR 性能。更多帮助如下:
python tune.py --help
或参考example/librispeech/run_tune.sh.
在Docker容器上运行
Docker 是一个开源工具,用于在孤立的环境中构建、发布和运行分布式应用程序。此项目的 Docker 镜像已在hub.docker.com中提供,并安装了所有依赖项,其中包括预先构建的PaddlePaddle,CTC解码器以及其他必要的 Python 和第三方库。这个 Docker 映像需要NVIDIA GPU的支持,所以请确保它的可用性并已完成nvidia-docker的安装。
采取以下步骤来启动 Docker 镜像:
- 下载 Docker 镜像
nvidia-docker pull hub.baidubce.com/paddlepaddle/deep_speech_fluid:latest-gpu
- git clone 这个资源库
git clone https://github.com/PaddlePaddle/DeepSpeech.git
- 运行 Docker 镜像
sudo nvidia-docker run -it -v $(pwd)/DeepSpeech:/DeepSpeech hub.baidubce.com/paddlepaddle/deep_speech_fluid:latest-gpu /bin/bash
现在返回并从开始部分开始,您可以在Docker容器中同样执行模型训练,推断和超参数调整。
训练普通话语言
普通话语言训练与英语训练的关键步骤相同,我们提供了一个使用 Aishell 进行普通话训练的例子examples/aishell。如上所述,请执行sh run_data.sh, sh run_train.sh, sh run_test.sh和sh run_infer.sh做相应的数据准备,训练,测试和推断。我们还准备了一个预训练过的模型(执行./models/aishell/download_model.sh下载)供用户使用run_infer_golden.sh和run_test_golden.sh来。请注意,与英语语言模型不同,普通话语言模型是基于汉字的,请运行tools/tune.py来查找最佳设置。
##用自己的声音尝试现场演示
到目前为止,一个 ASR 模型已经训练完毕,并且用现有的音频文件进行了定性测试(infer.py)和定量测试(test.py)。但目前还没有用你自己的声音进行测试。deploy/demo_english_server.py和deploy/demo_client.py能够快速构建一个利用已训练好的模型对ASR引擎进行实时演示的系统,使你能够用自己的语音测试和演示。
要启动演示服务,请在控制台中运行:
CUDA_VISIBLE_DEVICES=0 \
python deploy/demo_server.py \
--host_ip localhost \
--host_port 8086
对于运行 demo 客户端的机器(可能不是同一台机器),请在继续之前执行以下安装。
比如,对于 MAC OS X 机器:
brew install portaudio
pip install pyaudio
pip install keyboard
然后启动客户端,请在另一个控制台中运行:
CUDA_VISIBLE_DEVICES=0 \
python -u deploy/demo_client.py \
--host_ip 'localhost' \
--host_port 8086
现在,在客户端控制台中,按下空格键,按住并开始讲话。讲话完毕请释放该键以让控制台中显示语音的文本结果。要退出客户端,只需按ESC键。
请注意,deploy/demo_client.py必须在带麦克风设备的机器上运行,而deploy/demo_server.py可以在没有任何录音硬件的情况下运行,例如任何远程服务器机器。如果服务器和客户端使用两台独立的机器运行,只需要注意将host_ip和host_port参数设置为实际可访问的IP地址和端口。如果它们在单台机器上运行,则不用作任何处理。
请参考examples/deploy_demo/run_english_demo_server.sh,它将首先下载一个预先训练过的英语模型(用3000小时的内部语音数据训练),然后用模型启动演示服务器。通过运行examples/mandarin/run_demo_client.sh,你可以说英语来测试它。如果您想尝试其他模型,只需更新脚本中的--model_path参数即可。
获得更多帮助:
python deploy/demo_server.py --help
python deploy/demo_client.py --help
发布模型
语音模型发布
| 语种 | 模型名 | 训练数据 | 语音时长 |
|---|---|---|---|
| English | LibriSpeech Model | LibriSpeech Dataset | 960 h |
| English | BaiduEN8k Model | Baidu Internal English Dataset | 8628 h |
| Mandarin | Aishell Model | Aishell Dataset | 151 h |
| Mandarin | BaiduCN1.2k Model | Baidu Internal Mandarin Dataset | 1204 h |
语言模型发布
| 语言模型 | 训练数据 | 基于的字符 | 大小 | 描述 |
|---|---|---|---|---|
| English LM | CommonCrawl(en.00) | Word-based | 8.3 GB | Pruned with 0 1 1 1 1; About 1.85 billion n-grams; 'trie' binary with '-a 22 -q 8 -b 8' |
| Mandarin LM Small | Baidu Internal Corpus | Char-based | 2.8 GB | Pruned with 0 1 2 4 4; About 0.13 billion n-grams; 'probing' binary with default settings |
| Mandarin LM Large | Baidu Internal Corpus | Char-based | 70.4 GB | No Pruning; About 3.7 billion n-grams; 'probing' binary with default settings |
实验和baseline
英语模型的baseline测试结果(字错误率)
| 测试集 | LibriSpeech Model | BaiduEN8K Model |
|---|---|---|
| LibriSpeech Test-Clean | 6.85 | 5.41 |
| LibriSpeech Test-Other | 21.18 | 13.85 |
| VoxForge American-Canadian | 12.12 | 7.13 |
| VoxForge Commonwealth | 19.82 | 14.93 |
| VoxForge European | 30.15 | 18.64 |
| VoxForge Indian | 53.73 | 25.51 |
| Baidu Internal Testset | 40.75 | 8.48 |
为了在VoxForge数据上重现基准测试结果,我们提供了一个脚本来下载数据并生成VoxForge方言manifest文件。请到data/voxforge执行````run_data.sh```来获取VoxForge方言manifest文件。请注意,VoxForge数据可能会持续更新,生成的清单文件可能与我们评估的清单文件有所不同。
普通话模型的baseline测试结果(字符错误率)
| 测试集 | BaiduCN1.2k Model |
|---|---|
| Baidu Internal Testset | 12.64 |
多GPU加速
我们对1,2,4,8个Tesla V100 GPU的训练时间(LibriSpeech样本的子集,其音频持续时间介于6.0和7.0秒之间)进行比较。它表明,已经实现了具有多个GPU的近线性加速。在下图中,训练的时间(以秒为单位)显示在蓝色条上。
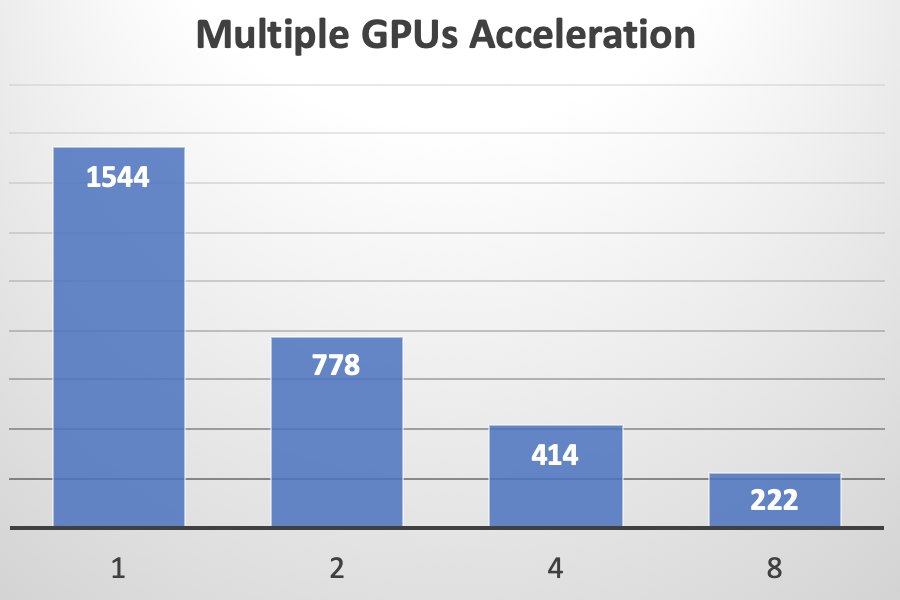
| # of GPU | 加速比 |
|---|---|
| 1 | 1.00 X |
| 2 | 1.98 X |
| 4 | 3.73 X |
| 8 | 6.95 X |
tools/profile.sh提供了上述分析工具.
问题和帮助
欢迎您在Github问题中提交问题和bug。也欢迎您为这个项目做出贡献。