commit
2938d3e49b
@ -0,0 +1,74 @@
|
|||||||
|
([简体中文](./README_cn.md)|English)
|
||||||
|
# ACS (Audio Content Search)
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
ACS, or Audio Content Search, refers to the problem of getting the key word time stamp from automatically transcribe spoken language (speech-to-text).
|
||||||
|
|
||||||
|
This demo is an implementation of obtaining the keyword timestamp in the text from a given audio file. It can be done by a single command or a few lines in python using `PaddleSpeech`.
|
||||||
|
Now, the search word in demo is:
|
||||||
|
```
|
||||||
|
我
|
||||||
|
康
|
||||||
|
```
|
||||||
|
## Usage
|
||||||
|
### 1. Installation
|
||||||
|
see [installation](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install.md).
|
||||||
|
|
||||||
|
You can choose one way from meduim and hard to install paddlespeech.
|
||||||
|
|
||||||
|
The dependency refers to the requirements.txt
|
||||||
|
### 2. Prepare Input File
|
||||||
|
The input of this demo should be a WAV file(`.wav`), and the sample rate must be the same as the model.
|
||||||
|
|
||||||
|
Here are sample files for this demo that can be downloaded:
|
||||||
|
```bash
|
||||||
|
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3. Usage
|
||||||
|
- Command Line(Recommended)
|
||||||
|
```bash
|
||||||
|
# Chinese
|
||||||
|
paddlespeech_client acs --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
|
||||||
|
```
|
||||||
|
|
||||||
|
Usage:
|
||||||
|
```bash
|
||||||
|
paddlespeech asr --help
|
||||||
|
```
|
||||||
|
Arguments:
|
||||||
|
- `input`(required): Audio file to recognize.
|
||||||
|
- `server_ip`: the server ip.
|
||||||
|
- `port`: the server port.
|
||||||
|
- `lang`: the language type of the model. Default: `zh`.
|
||||||
|
- `sample_rate`: Sample rate of the model. Default: `16000`.
|
||||||
|
- `audio_format`: The audio format.
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```bash
|
||||||
|
[2022-05-15 15:00:58,185] [ INFO] - acs http client start
|
||||||
|
[2022-05-15 15:00:58,185] [ INFO] - endpoint: http://127.0.0.1:8490/paddlespeech/asr/search
|
||||||
|
[2022-05-15 15:01:03,220] [ INFO] - acs http client finished
|
||||||
|
[2022-05-15 15:01:03,221] [ INFO] - ACS result: {'transcription': '我认为跑步最重要的就是给我带来了身体健康', 'acs': [{'w': '我', 'bg': 0, 'ed': 1.6800000000000002}, {'w': '我', 'bg': 2.1, 'ed': 4.28}, {'w': '康', 'bg': 3.2, 'ed': 4.92}]}
|
||||||
|
[2022-05-15 15:01:03,221] [ INFO] - Response time 5.036084 s.
|
||||||
|
```
|
||||||
|
|
||||||
|
- Python API
|
||||||
|
```python
|
||||||
|
from paddlespeech.server.bin.paddlespeech_client import ACSClientExecutor
|
||||||
|
|
||||||
|
acs_executor = ACSClientExecutor()
|
||||||
|
res = acs_executor(
|
||||||
|
input='./zh.wav',
|
||||||
|
server_ip="127.0.0.1",
|
||||||
|
port=8490,)
|
||||||
|
print(res)
|
||||||
|
```
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```bash
|
||||||
|
[2022-05-15 15:08:13,955] [ INFO] - acs http client start
|
||||||
|
[2022-05-15 15:08:13,956] [ INFO] - endpoint: http://127.0.0.1:8490/paddlespeech/asr/search
|
||||||
|
[2022-05-15 15:08:19,026] [ INFO] - acs http client finished
|
||||||
|
{'transcription': '我认为跑步最重要的就是给我带来了身体健康', 'acs': [{'w': '我', 'bg': 0, 'ed': 1.6800000000000002}, {'w': '我', 'bg': 2.1, 'ed': 4.28}, {'w': '康', 'bg': 3.2, 'ed': 4.92}]}
|
||||||
|
```
|
||||||
@ -0,0 +1,49 @@
|
|||||||
|
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
from paddlespeech.cli.log import logger
|
||||||
|
from paddlespeech.server.utils.audio_handler import ASRHttpHandler
|
||||||
|
|
||||||
|
|
||||||
|
def main(args):
|
||||||
|
logger.info("asr http client start")
|
||||||
|
audio_format = "wav"
|
||||||
|
sample_rate = 16000
|
||||||
|
lang = "zh"
|
||||||
|
handler = ASRHttpHandler(
|
||||||
|
server_ip=args.server_ip, port=args.port, endpoint=args.endpoint)
|
||||||
|
res = handler.run(args.wavfile, audio_format, sample_rate, lang)
|
||||||
|
# res = res['result']
|
||||||
|
logger.info(f"the final result: {res}")
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
parser = argparse.ArgumentParser(description="audio content search client")
|
||||||
|
parser.add_argument(
|
||||||
|
'--server_ip', type=str, default='127.0.0.1', help='server ip')
|
||||||
|
parser.add_argument('--port', type=int, default=8090, help='server port')
|
||||||
|
parser.add_argument(
|
||||||
|
"--wavfile",
|
||||||
|
action="store",
|
||||||
|
help="wav file path ",
|
||||||
|
default="./16_audio.wav")
|
||||||
|
parser.add_argument(
|
||||||
|
'--endpoint',
|
||||||
|
type=str,
|
||||||
|
default='/paddlespeech/asr/search',
|
||||||
|
help='server endpoint')
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
main(args)
|
||||||
@ -0,0 +1,34 @@
|
|||||||
|
#################################################################################
|
||||||
|
# SERVER SETTING #
|
||||||
|
#################################################################################
|
||||||
|
host: 0.0.0.0
|
||||||
|
port: 8490
|
||||||
|
|
||||||
|
# The task format in the engin_list is: <speech task>_<engine type>
|
||||||
|
# task choices = ['acs_python']
|
||||||
|
# protocol = ['http'] (only one can be selected).
|
||||||
|
# http only support offline engine type.
|
||||||
|
protocol: 'http'
|
||||||
|
engine_list: ['acs_python']
|
||||||
|
|
||||||
|
|
||||||
|
#################################################################################
|
||||||
|
# ENGINE CONFIG #
|
||||||
|
#################################################################################
|
||||||
|
|
||||||
|
################################### ACS #########################################
|
||||||
|
################### acs task: engine_type: python ###############################
|
||||||
|
acs_python:
|
||||||
|
task: acs
|
||||||
|
asr_protocol: 'websocket' # 'websocket'
|
||||||
|
offset: 1.0 # second
|
||||||
|
asr_server_ip: 127.0.0.1
|
||||||
|
asr_server_port: 8390
|
||||||
|
lang: 'zh'
|
||||||
|
word_list: "./conf/words.txt"
|
||||||
|
sample_rate: 16000
|
||||||
|
device: 'cpu' # set 'gpu:id' or 'cpu'
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@ -0,0 +1,2 @@
|
|||||||
|
我
|
||||||
|
康
|
||||||
@ -0,0 +1,43 @@
|
|||||||
|
#################################################################################
|
||||||
|
# SERVER SETTING #
|
||||||
|
#################################################################################
|
||||||
|
host: 0.0.0.0
|
||||||
|
port: 8390
|
||||||
|
|
||||||
|
# The task format in the engin_list is: <speech task>_<engine type>
|
||||||
|
# task choices = ['asr_online']
|
||||||
|
# protocol = ['websocket'] (only one can be selected).
|
||||||
|
# websocket only support online engine type.
|
||||||
|
protocol: 'websocket'
|
||||||
|
engine_list: ['asr_online']
|
||||||
|
|
||||||
|
|
||||||
|
#################################################################################
|
||||||
|
# ENGINE CONFIG #
|
||||||
|
#################################################################################
|
||||||
|
|
||||||
|
################################### ASR #########################################
|
||||||
|
################### speech task: asr; engine_type: online #######################
|
||||||
|
asr_online:
|
||||||
|
model_type: 'conformer_online_multicn'
|
||||||
|
am_model: # the pdmodel file of am static model [optional]
|
||||||
|
am_params: # the pdiparams file of am static model [optional]
|
||||||
|
lang: 'zh'
|
||||||
|
sample_rate: 16000
|
||||||
|
cfg_path:
|
||||||
|
decode_method: 'attention_rescoring'
|
||||||
|
force_yes: True
|
||||||
|
device: 'cpu' # cpu or gpu:id
|
||||||
|
am_predictor_conf:
|
||||||
|
device: # set 'gpu:id' or 'cpu'
|
||||||
|
switch_ir_optim: True
|
||||||
|
glog_info: False # True -> print glog
|
||||||
|
summary: True # False -> do not show predictor config
|
||||||
|
|
||||||
|
chunk_buffer_conf:
|
||||||
|
window_n: 7 # frame
|
||||||
|
shift_n: 4 # frame
|
||||||
|
window_ms: 25 # ms
|
||||||
|
shift_ms: 10 # ms
|
||||||
|
sample_rate: 16000
|
||||||
|
sample_width: 2
|
||||||
@ -0,0 +1,46 @@
|
|||||||
|
# This is the parameter configuration file for PaddleSpeech Serving.
|
||||||
|
|
||||||
|
#################################################################################
|
||||||
|
# SERVER SETTING #
|
||||||
|
#################################################################################
|
||||||
|
host: 0.0.0.0
|
||||||
|
port: 8390
|
||||||
|
|
||||||
|
# The task format in the engin_list is: <speech task>_<engine type>
|
||||||
|
# task choices = ['asr_online']
|
||||||
|
# protocol = ['websocket'] (only one can be selected).
|
||||||
|
# websocket only support online engine type.
|
||||||
|
protocol: 'websocket'
|
||||||
|
engine_list: ['asr_online']
|
||||||
|
|
||||||
|
|
||||||
|
#################################################################################
|
||||||
|
# ENGINE CONFIG #
|
||||||
|
#################################################################################
|
||||||
|
|
||||||
|
################################### ASR #########################################
|
||||||
|
################### speech task: asr; engine_type: online #######################
|
||||||
|
asr_online:
|
||||||
|
model_type: 'conformer_online_wenetspeech'
|
||||||
|
am_model: # the pdmodel file of am static model [optional]
|
||||||
|
am_params: # the pdiparams file of am static model [optional]
|
||||||
|
lang: 'zh'
|
||||||
|
sample_rate: 16000
|
||||||
|
cfg_path:
|
||||||
|
decode_method:
|
||||||
|
force_yes: True
|
||||||
|
device: 'cpu' # cpu or gpu:id
|
||||||
|
decode_method: "attention_rescoring"
|
||||||
|
am_predictor_conf:
|
||||||
|
device: # set 'gpu:id' or 'cpu'
|
||||||
|
switch_ir_optim: True
|
||||||
|
glog_info: False # True -> print glog
|
||||||
|
summary: True # False -> do not show predictor config
|
||||||
|
|
||||||
|
chunk_buffer_conf:
|
||||||
|
window_n: 7 # frame
|
||||||
|
shift_n: 4 # frame
|
||||||
|
window_ms: 25 # ms
|
||||||
|
shift_ms: 10 # ms
|
||||||
|
sample_rate: 16000
|
||||||
|
sample_width: 2
|
||||||
@ -0,0 +1,7 @@
|
|||||||
|
export CUDA_VISIBLE_DEVICE=0,1,2,3
|
||||||
|
# we need the streaming asr server
|
||||||
|
nohup python3 streaming_asr_server.py --config_file conf/ws_conformer_application.yaml > streaming_asr.log 2>&1 &
|
||||||
|
|
||||||
|
# start the acs server
|
||||||
|
nohup paddlespeech_server start --config_file conf/acs_application.yaml > acs.log 2>&1 &
|
||||||
|
|
||||||
@ -0,0 +1,65 @@
|
|||||||
|
([简体中文](./README_cn.md)|English)
|
||||||
|
|
||||||
|
# Customized Auto Speech Recognition
|
||||||
|
|
||||||
|
## introduction
|
||||||
|
In some cases, we need to recognize the specific rare words with high accuracy. eg: address recognition in navigation apps. customized ASR can slove those issues.
|
||||||
|
|
||||||
|
this demo is customized for expense account, which need to recognize rare address.
|
||||||
|
|
||||||
|
* G with slot: 打车到 "address_slot"。
|
||||||
|

|
||||||
|
|
||||||
|
* this is address slot wfst, you can add the address which want to recognize.
|
||||||
|

|
||||||
|
|
||||||
|
* after replace operation, G = fstreplace(G_with_slot, address_slot), we will get the customized graph.
|
||||||
|

|
||||||
|
|
||||||
|
## Usage
|
||||||
|
### 1. Installation
|
||||||
|
install paddle:2.2.2 docker.
|
||||||
|
```
|
||||||
|
sudo docker pull registry.baidubce.com/paddlepaddle/paddle:2.2.2
|
||||||
|
|
||||||
|
sudo docker run --privileged --net=host --ipc=host -it --rm -v $PWD:/paddle --name=paddle_demo_docker registry.baidubce.com/paddlepaddle/paddle:2.2.2 /bin/bash
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2. demo
|
||||||
|
* run websocket_server.sh. This script will download resources and libs, and launch the service.
|
||||||
|
```
|
||||||
|
cd /paddle
|
||||||
|
bash websocket_server.sh
|
||||||
|
```
|
||||||
|
this script run in two steps:
|
||||||
|
1. download the resources.tar.gz, those direcotries will be found in resource directory.
|
||||||
|
model: acustic model
|
||||||
|
graph: the decoder graph (TLG.fst)
|
||||||
|
lib: some libs
|
||||||
|
bin: binary
|
||||||
|
data: audio and wav.scp
|
||||||
|
|
||||||
|
2. websocket_server_main launch the service.
|
||||||
|
some params:
|
||||||
|
port: the service port
|
||||||
|
graph_path: the decoder graph path
|
||||||
|
model_path: acustic model path
|
||||||
|
please refer other params in those files:
|
||||||
|
PaddleSpeech/speechx/speechx/decoder/param.h
|
||||||
|
PaddleSpeech/speechx/examples/ds2_ol/websocket/websocket_server_main.cc
|
||||||
|
|
||||||
|
* In other terminal, run script websocket_client.sh, the client will send data and get the results.
|
||||||
|
```
|
||||||
|
bash websocket_client.sh
|
||||||
|
```
|
||||||
|
websocket_client_main will launch the client, the wav_scp is the wav set, port is the server service port.
|
||||||
|
|
||||||
|
* result:
|
||||||
|
In the log of client, you will see the message below:
|
||||||
|
```
|
||||||
|
0513 10:58:13.827821 41768 recognizer_test_main.cc:56] wav len (sample): 70208
|
||||||
|
I0513 10:58:13.884493 41768 feature_cache.h:52] set finished
|
||||||
|
I0513 10:58:24.247171 41768 paddle_nnet.h:76] Tensor neml: 10240
|
||||||
|
I0513 10:58:24.247249 41768 paddle_nnet.h:76] Tensor neml: 10240
|
||||||
|
LOG ([5.5.544~2-f21d7]:main():decoder/recognizer_test_main.cc:90) the result of case_10 is 五月十二日二十二点三十六分加班打车回家四十一元
|
||||||
|
```
|
||||||
@ -0,0 +1,2 @@
|
|||||||
|
export LD_LIBRARY_PATH=$PWD/resource/lib
|
||||||
|
export PATH=$PATH:$PWD/resource/bin
|
||||||
@ -0,0 +1 @@
|
|||||||
|
sudo nvidia-docker run --privileged --net=host --ipc=host -it --rm -v $PWD:/paddle --name=paddle_demo_docker registry.baidubce.com/paddlepaddle/paddle:2.2.2 /bin/bash
|
||||||
@ -0,0 +1,18 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
set +x
|
||||||
|
set -e
|
||||||
|
|
||||||
|
. path.sh
|
||||||
|
# input
|
||||||
|
data=$PWD/data
|
||||||
|
|
||||||
|
# output
|
||||||
|
wav_scp=wav.scp
|
||||||
|
|
||||||
|
export GLOG_logtostderr=1
|
||||||
|
|
||||||
|
# websocket client
|
||||||
|
websocket_client_main \
|
||||||
|
--wav_rspecifier=scp:$data/$wav_scp \
|
||||||
|
--streaming_chunk=0.36 \
|
||||||
|
--port=8881
|
||||||
@ -0,0 +1,33 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
set +x
|
||||||
|
set -e
|
||||||
|
|
||||||
|
export GLOG_logtostderr=1
|
||||||
|
|
||||||
|
. path.sh
|
||||||
|
#test websocket server
|
||||||
|
|
||||||
|
model_dir=./resource/model
|
||||||
|
graph_dir=./resource/graph
|
||||||
|
cmvn=./data/cmvn.ark
|
||||||
|
|
||||||
|
|
||||||
|
#paddle_asr_online/resource.tar.gz
|
||||||
|
if [ ! -f $cmvn ]; then
|
||||||
|
wget -c https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/resource.tar.gz
|
||||||
|
tar xzfv resource.tar.gz
|
||||||
|
ln -s ./resource/data .
|
||||||
|
fi
|
||||||
|
|
||||||
|
websocket_server_main \
|
||||||
|
--cmvn_file=$cmvn \
|
||||||
|
--streaming_chunk=0.1 \
|
||||||
|
--use_fbank=true \
|
||||||
|
--model_path=$model_dir/avg_10.jit.pdmodel \
|
||||||
|
--param_path=$model_dir/avg_10.jit.pdiparams \
|
||||||
|
--model_cache_shapes="5-1-2048,5-1-2048" \
|
||||||
|
--model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
|
||||||
|
--word_symbol_table=$graph_dir/words.txt \
|
||||||
|
--graph_path=$graph_dir/TLG.fst --max_active=7500 \
|
||||||
|
--port=8881 \
|
||||||
|
--acoustic_scale=12
|
||||||
@ -1,4 +1,6 @@
|
|||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
|
|
||||||
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
|
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
|
||||||
|
|
||||||
|
# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
|
||||||
paddlespeech_client asr --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
|
paddlespeech_client asr --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
|
||||||
|
|||||||
@ -1,4 +1,6 @@
|
|||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
|
|
||||||
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
|
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
|
||||||
|
|
||||||
|
# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
|
||||||
paddlespeech_client cls --server_ip 127.0.0.1 --port 8090 --input ./zh.wav --topk 1
|
paddlespeech_client cls --server_ip 127.0.0.1 --port 8090 --input ./zh.wav --topk 1
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
|
|
||||||
|
# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
|
||||||
paddlespeech_client tts --server_ip 127.0.0.1 --port 8090 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
|
paddlespeech_client tts --server_ip 127.0.0.1 --port 8090 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
|
||||||
|
|||||||
@ -1,7 +1,9 @@
|
|||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
|
|
||||||
# http client test
|
# http client test
|
||||||
|
# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
|
||||||
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
|
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
|
||||||
|
|
||||||
# websocket client test
|
# websocket client test
|
||||||
#paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol websocket --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
|
# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
|
||||||
|
# paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol websocket --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
|
||||||
|
|||||||
@ -0,0 +1,10 @@
|
|||||||
|
Streaming ASR Demo Video
|
||||||
|
==================
|
||||||
|
|
||||||
|
.. raw:: html
|
||||||
|
|
||||||
|
<video controls width="1024">
|
||||||
|
|
||||||
|
<source src="https://paddlespeech.bj.bcebos.com/demos/asr_demos/streaming_ASR_slice.mp4" type="video/mp4">
|
||||||
|
Sorry, your browser doesn't support embedded videos.
|
||||||
|
</video>
|
||||||
@ -0,0 +1,78 @@
|
|||||||
|
([简体中文](./PPVPR_cn.md)|English)
|
||||||
|
# PP-VPR
|
||||||
|
|
||||||
|
## Catalogue
|
||||||
|
- [1. Introduction](#1)
|
||||||
|
- [2. Characteristic](#2)
|
||||||
|
- [3. Tutorials](#3)
|
||||||
|
- [3.1 Pre-trained Models](#31)
|
||||||
|
- [3.2 Training](#32)
|
||||||
|
- [3.3 Inference](#33)
|
||||||
|
- [3.4 Service Deployment](#33)
|
||||||
|
- [4. Quick Start](#4)
|
||||||
|
|
||||||
|
<a name="1"></a>
|
||||||
|
## 1. Introduction
|
||||||
|
|
||||||
|
PP-VPR is a tool that provides voice print feature extraction and retrieval functions. Provides a variety of quasi-industrial solutions, easy to solve the difficult problems in complex scenes, support the use of command line model reasoning. PP-VPR also supports interface operations and container deployment.
|
||||||
|
|
||||||
|
<a name="2"></a>
|
||||||
|
## 2. Characteristic
|
||||||
|
The basic process of VPR is shown in the figure below:
|
||||||
|
<center><img src=https://ai-studio-static-online.cdn.bcebos.com/3aed59b8c8874046ad19fe583d15a8dd53c5b33e68db4383b79706e5add5c2d0 width="800" ></center>
|
||||||
|
|
||||||
|
|
||||||
|
The main characteristics of PP-ASR are shown below:
|
||||||
|
- Provides pre-trained models on Chinese open source datasets: VoxCeleb(English). The models include ecapa-tdnn.
|
||||||
|
- Support model training/evaluation.
|
||||||
|
- Support model inference using the command line. You can use to use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do model inference.
|
||||||
|
- Support interface operations and container deployment.
|
||||||
|
|
||||||
|
<a name="3"></a>
|
||||||
|
## 3. Tutorials
|
||||||
|
|
||||||
|
<a name="31"></a>
|
||||||
|
## 3.1 Pre-trained Models
|
||||||
|
The support pre-trained model list: [released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md).
|
||||||
|
For more information about model design, you can refer to the aistudio tutorial:
|
||||||
|
- [ecapa-tdnn](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
|
||||||
|
|
||||||
|
<a name="32"></a>
|
||||||
|
## 3.2 Training
|
||||||
|
The referenced script for model training is stored in [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) and stored according to "examples/dataset/model". The dataset mainly supports VoxCeleb. The model supports ecapa-tdnn.
|
||||||
|
The specific steps of executing the script are recorded in `run.sh`.
|
||||||
|
|
||||||
|
For more information, you can refer to [sv0](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0)
|
||||||
|
|
||||||
|
|
||||||
|
<a name="33"></a>
|
||||||
|
## 3.3 Inference
|
||||||
|
|
||||||
|
PP-VPR supports use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do inference after install `paddlespeech` by `pip install paddlespeech`.
|
||||||
|
|
||||||
|
Specific supported functions include:
|
||||||
|
|
||||||
|
- Prediction of single audio
|
||||||
|
- Score the similarity between the two audios
|
||||||
|
- Support RTF calculation
|
||||||
|
|
||||||
|
For specific usage, please refer to: [speaker_verification](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md)
|
||||||
|
|
||||||
|
|
||||||
|
<a name="34"></a>
|
||||||
|
## 3.4 Service Deployment
|
||||||
|
|
||||||
|
PP-VPR supports Docker containerized service deployment. Through Milvus, MySQL performs high performance library building search.
|
||||||
|
|
||||||
|
Demo of VPR Server: [audio_searching](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/audio_searching)
|
||||||
|
|
||||||
|
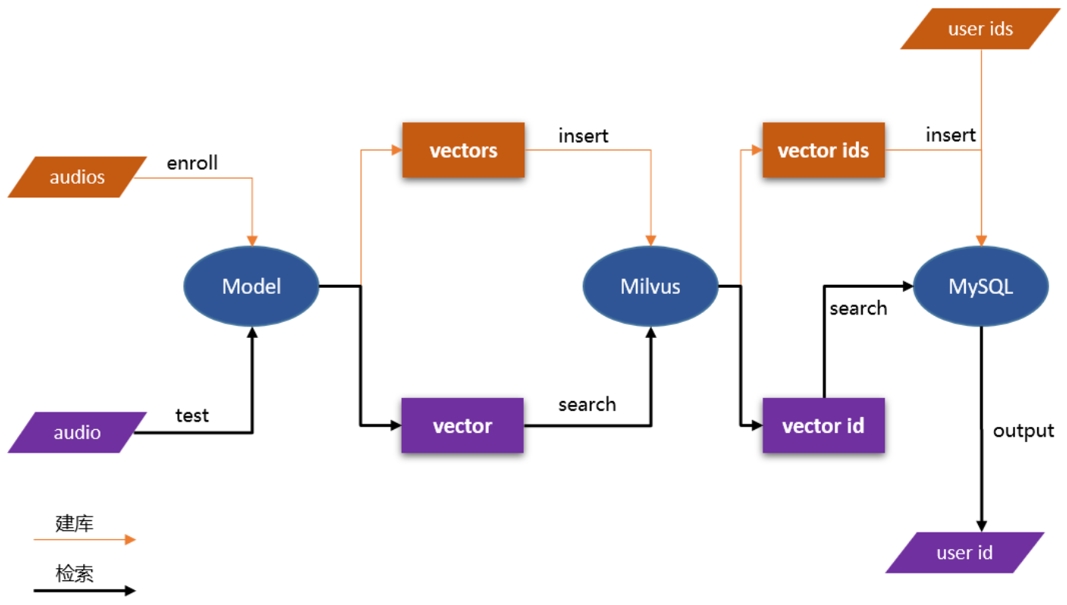
|
||||||
|
|
||||||
|
For more information about service deployment, you can refer to the aistudio tutorial:
|
||||||
|
- [speaker_recognition](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
|
||||||
|
|
||||||
|
<a name="4"></a>
|
||||||
|
|
||||||
|
## 4. Quick Start
|
||||||
|
|
||||||
|
To use PP-VPR, you can see here [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md), It supplies three methods to install `paddlespeech`, which are **Easy**, **Medium** and **Hard**. If you want to experience the inference function of paddlespeech, you can use **Easy** installation method.
|
||||||
@ -0,0 +1,188 @@
|
|||||||
|
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
import io
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
|
||||||
|
import paddle
|
||||||
|
import soundfile
|
||||||
|
import websocket
|
||||||
|
|
||||||
|
from paddlespeech.cli.log import logger
|
||||||
|
from paddlespeech.server.engine.base_engine import BaseEngine
|
||||||
|
|
||||||
|
|
||||||
|
class ACSEngine(BaseEngine):
|
||||||
|
def __init__(self):
|
||||||
|
"""The ACSEngine Engine
|
||||||
|
"""
|
||||||
|
super(ACSEngine, self).__init__()
|
||||||
|
logger.info("Create the ACSEngine Instance")
|
||||||
|
self.word_list = []
|
||||||
|
|
||||||
|
def init(self, config: dict):
|
||||||
|
"""Init the ACSEngine Engine
|
||||||
|
|
||||||
|
Args:
|
||||||
|
config (dict): The server configuation
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
bool: The engine instance flag
|
||||||
|
"""
|
||||||
|
logger.info("Init the acs engine")
|
||||||
|
try:
|
||||||
|
self.config = config
|
||||||
|
if self.config.device:
|
||||||
|
self.device = self.config.device
|
||||||
|
else:
|
||||||
|
self.device = paddle.get_device()
|
||||||
|
|
||||||
|
paddle.set_device(self.device)
|
||||||
|
logger.info(f"ACS Engine set the device: {self.device}")
|
||||||
|
|
||||||
|
except BaseException as e:
|
||||||
|
logger.error(
|
||||||
|
"Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
|
||||||
|
)
|
||||||
|
logger.error("Initialize Text server engine Failed on device: %s." %
|
||||||
|
(self.device))
|
||||||
|
return False
|
||||||
|
|
||||||
|
self.read_search_words()
|
||||||
|
|
||||||
|
# init the asr url
|
||||||
|
self.url = "ws://" + self.config.asr_server_ip + ":" + str(
|
||||||
|
self.config.asr_server_port) + "/paddlespeech/asr/streaming"
|
||||||
|
|
||||||
|
logger.info("Init the acs engine successfully")
|
||||||
|
return True
|
||||||
|
|
||||||
|
def read_search_words(self):
|
||||||
|
word_list = self.config.word_list
|
||||||
|
if word_list is None:
|
||||||
|
logger.error(
|
||||||
|
"No word list file in config, please set the word list parameter"
|
||||||
|
)
|
||||||
|
return
|
||||||
|
|
||||||
|
if not os.path.exists(word_list):
|
||||||
|
logger.error("Please input correct word list file")
|
||||||
|
return
|
||||||
|
|
||||||
|
with open(word_list, 'r') as fp:
|
||||||
|
self.word_list = [line.strip() for line in fp.readlines()]
|
||||||
|
|
||||||
|
logger.info(f"word list: {self.word_list}")
|
||||||
|
|
||||||
|
def get_asr_content(self, audio_data):
|
||||||
|
"""Get the streaming asr result
|
||||||
|
|
||||||
|
Args:
|
||||||
|
audio_data (_type_): _description_
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
_type_: _description_
|
||||||
|
"""
|
||||||
|
logger.info("send a message to the server")
|
||||||
|
if self.url is None:
|
||||||
|
logger.error("No asr server, please input valid ip and port")
|
||||||
|
return ""
|
||||||
|
ws = websocket.WebSocket()
|
||||||
|
ws.connect(self.url)
|
||||||
|
# with websocket.WebSocket.connect(self.url) as ws:
|
||||||
|
audio_info = json.dumps(
|
||||||
|
{
|
||||||
|
"name": "test.wav",
|
||||||
|
"signal": "start",
|
||||||
|
"nbest": 1
|
||||||
|
},
|
||||||
|
sort_keys=True,
|
||||||
|
indent=4,
|
||||||
|
separators=(',', ': '))
|
||||||
|
ws.send(audio_info)
|
||||||
|
msg = ws.recv()
|
||||||
|
logger.info("client receive msg={}".format(msg))
|
||||||
|
|
||||||
|
# send the total audio data
|
||||||
|
samples, sample_rate = soundfile.read(audio_data, dtype='int16')
|
||||||
|
ws.send_binary(samples.tobytes())
|
||||||
|
msg = ws.recv()
|
||||||
|
msg = json.loads(msg)
|
||||||
|
logger.info(f"audio result: {msg}")
|
||||||
|
|
||||||
|
# 3. send chunk audio data to engine
|
||||||
|
logger.info("send the end signal")
|
||||||
|
audio_info = json.dumps(
|
||||||
|
{
|
||||||
|
"name": "test.wav",
|
||||||
|
"signal": "end",
|
||||||
|
"nbest": 1
|
||||||
|
},
|
||||||
|
sort_keys=True,
|
||||||
|
indent=4,
|
||||||
|
separators=(',', ': '))
|
||||||
|
ws.send(audio_info)
|
||||||
|
msg = ws.recv()
|
||||||
|
msg = json.loads(msg)
|
||||||
|
|
||||||
|
logger.info(f"the final result: {msg}")
|
||||||
|
ws.close()
|
||||||
|
|
||||||
|
return msg
|
||||||
|
|
||||||
|
def get_macthed_word(self, msg):
|
||||||
|
"""Get the matched info in msg
|
||||||
|
|
||||||
|
Args:
|
||||||
|
msg (dict): the asr info, including the asr result and time stamp
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
acs_result, asr_result: the acs result and the asr result
|
||||||
|
"""
|
||||||
|
asr_result = msg['result']
|
||||||
|
time_stamp = msg['times']
|
||||||
|
acs_result = []
|
||||||
|
|
||||||
|
# search for each word in self.word_list
|
||||||
|
offset = self.config.offset
|
||||||
|
max_ed = time_stamp[-1]['ed']
|
||||||
|
for w in self.word_list:
|
||||||
|
# search the w in asr_result and the index in asr_result
|
||||||
|
for m in re.finditer(w, asr_result):
|
||||||
|
start = max(time_stamp[m.start(0)]['bg'] - offset, 0)
|
||||||
|
|
||||||
|
end = min(time_stamp[m.end(0) - 1]['ed'] + offset, max_ed)
|
||||||
|
logger.info(f'start: {start}, end: {end}')
|
||||||
|
acs_result.append({'w': w, 'bg': start, 'ed': end})
|
||||||
|
|
||||||
|
return acs_result, asr_result
|
||||||
|
|
||||||
|
def run(self, audio_data):
|
||||||
|
"""process the audio data in acs engine
|
||||||
|
the engine does not store any data, so all the request use the self.run api
|
||||||
|
|
||||||
|
Args:
|
||||||
|
audio_data (str): the audio data
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
acs_result, asr_result: the acs result and the asr result
|
||||||
|
"""
|
||||||
|
logger.info("start to process the audio content search")
|
||||||
|
msg = self.get_asr_content(io.BytesIO(audio_data))
|
||||||
|
|
||||||
|
acs_result, asr_result = self.get_macthed_word(msg)
|
||||||
|
logger.info(f'the asr result {asr_result}')
|
||||||
|
logger.info(f'the acs result: {acs_result}')
|
||||||
|
return acs_result, asr_result
|
||||||
@ -0,0 +1,101 @@
|
|||||||
|
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
import base64
|
||||||
|
from typing import Union
|
||||||
|
|
||||||
|
from fastapi import APIRouter
|
||||||
|
|
||||||
|
from paddlespeech.cli.log import logger
|
||||||
|
from paddlespeech.server.engine.engine_pool import get_engine_pool
|
||||||
|
from paddlespeech.server.restful.request import ASRRequest
|
||||||
|
from paddlespeech.server.restful.response import ACSResponse
|
||||||
|
from paddlespeech.server.restful.response import ErrorResponse
|
||||||
|
from paddlespeech.server.utils.errors import ErrorCode
|
||||||
|
from paddlespeech.server.utils.errors import failed_response
|
||||||
|
from paddlespeech.server.utils.exception import ServerBaseException
|
||||||
|
|
||||||
|
router = APIRouter()
|
||||||
|
|
||||||
|
|
||||||
|
@router.get('/paddlespeech/asr/search/help')
|
||||||
|
def help():
|
||||||
|
"""help
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
json: the audio content search result
|
||||||
|
"""
|
||||||
|
response = {
|
||||||
|
"success": "True",
|
||||||
|
"code": 200,
|
||||||
|
"message": {
|
||||||
|
"global": "success"
|
||||||
|
},
|
||||||
|
"result": {
|
||||||
|
"description": "acs server",
|
||||||
|
"input": "base64 string of wavfile",
|
||||||
|
"output": {
|
||||||
|
"asr_result": "你好",
|
||||||
|
"acs_result": [{
|
||||||
|
'w': '你',
|
||||||
|
'bg': 0.0,
|
||||||
|
'ed': 1.2
|
||||||
|
}]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return response
|
||||||
|
|
||||||
|
|
||||||
|
@router.post(
|
||||||
|
"/paddlespeech/asr/search",
|
||||||
|
response_model=Union[ACSResponse, ErrorResponse])
|
||||||
|
def acs(request_body: ASRRequest):
|
||||||
|
"""acs api
|
||||||
|
|
||||||
|
Args:
|
||||||
|
request_body (ASRRequest): the acs request, we reuse the http ASRRequest
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
json: the acs result
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
# 1. get the audio data via base64 decoding
|
||||||
|
audio_data = base64.b64decode(request_body.audio)
|
||||||
|
|
||||||
|
# 2. get single engine from engine pool
|
||||||
|
engine_pool = get_engine_pool()
|
||||||
|
acs_engine = engine_pool['acs']
|
||||||
|
|
||||||
|
# 3. no data stored in acs_engine, so we need to create the another instance process the data
|
||||||
|
acs_result, asr_result = acs_engine.run(audio_data)
|
||||||
|
|
||||||
|
response = {
|
||||||
|
"success": True,
|
||||||
|
"code": 200,
|
||||||
|
"message": {
|
||||||
|
"description": "success"
|
||||||
|
},
|
||||||
|
"result": {
|
||||||
|
"transcription": asr_result,
|
||||||
|
"acs": acs_result
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
except ServerBaseException as e:
|
||||||
|
response = failed_response(e.error_code, e.msg)
|
||||||
|
except BaseException as e:
|
||||||
|
response = failed_response(ErrorCode.SERVER_UNKOWN_ERR)
|
||||||
|
logger.error(e)
|
||||||
|
|
||||||
|
return response
|
||||||
@ -0,0 +1,11 @@
|
|||||||
|
export MAIN_ROOT=`realpath ${PWD}/../../../`
|
||||||
|
|
||||||
|
export PATH=${MAIN_ROOT}:${MAIN_ROOT}/utils:${PATH}
|
||||||
|
export LC_ALL=C
|
||||||
|
|
||||||
|
export PYTHONDONTWRITEBYTECODE=1
|
||||||
|
# Use UTF-8 in Python to avoid UnicodeDecodeError when LC_ALL=C
|
||||||
|
export PYTHONIOENCODING=UTF-8
|
||||||
|
export PYTHONPATH=${MAIN_ROOT}:${PYTHONPATH}
|
||||||
|
|
||||||
|
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/lib/
|
||||||
Loading…
Reference in new issue