6.0 KiB
Introduction to Machine Learning
Sketchnote Placeholder
Pre-lecture quiz
Introduction
In this lesson, you will learn:
- How to configure your computer for local machine learning tasks
- Getting used to working with Jupyter notebooks
- An introduction to Scikit-Learn, including installation
Installations and Configurations

Click this image to watch a video on using Python within VS Code.
-
Ensure that Python is installed on your computer. You will use Python for many data science and machine learning tasks. Most computer systems already include a Python installation. There are useful Python Coding Packs available as well to ease the setup for some users. Some usages of Python, however, require one version of the software, whereas others require a different version. For this reason, it's useful to work within a virtual environment.
-
Make sure you have Visual Studio Code installed on your computer. Follow these instructions for the basic installation. You are going to use Python in Visual Studio Code in this course, so you might want to brush up on how to configure VS Code for Python development.
Get comfortable with Python by working through this collection of Learn modules
- Install Scikit-Learn by following these instructions. Since you need to ensure that you use Python 3, it's recommended that you use a virtual environment.
Jupyter Notebooks
You are going to use notebooks to develop your Python code and create machine learning models. This type of file is a common tool for data scientists, and they can be identified by their suffix .ipynb.
Notebooks are an interactive environment that allow the developer to both code and add notes and documentation around the code.
Work with A Notebook
In this folder, you will find the file notebook.ipynb. If you open it in VS Code, assuming VS Code is properly configured, a Jupyter server will start with Python 3+ started. You will find areas of the notebook that can be 'run' by pressing arrows next to code blocks, and other areas that contain text.
In your notebook, add a comment. To do this, click the 'md' icon and add a bit of markdown, like # Welcome to your notebook.
Next, add some Python code: Type print('hello notebook') and click the arrow to run the code. You should see the printed statement, 'hello notebook'.
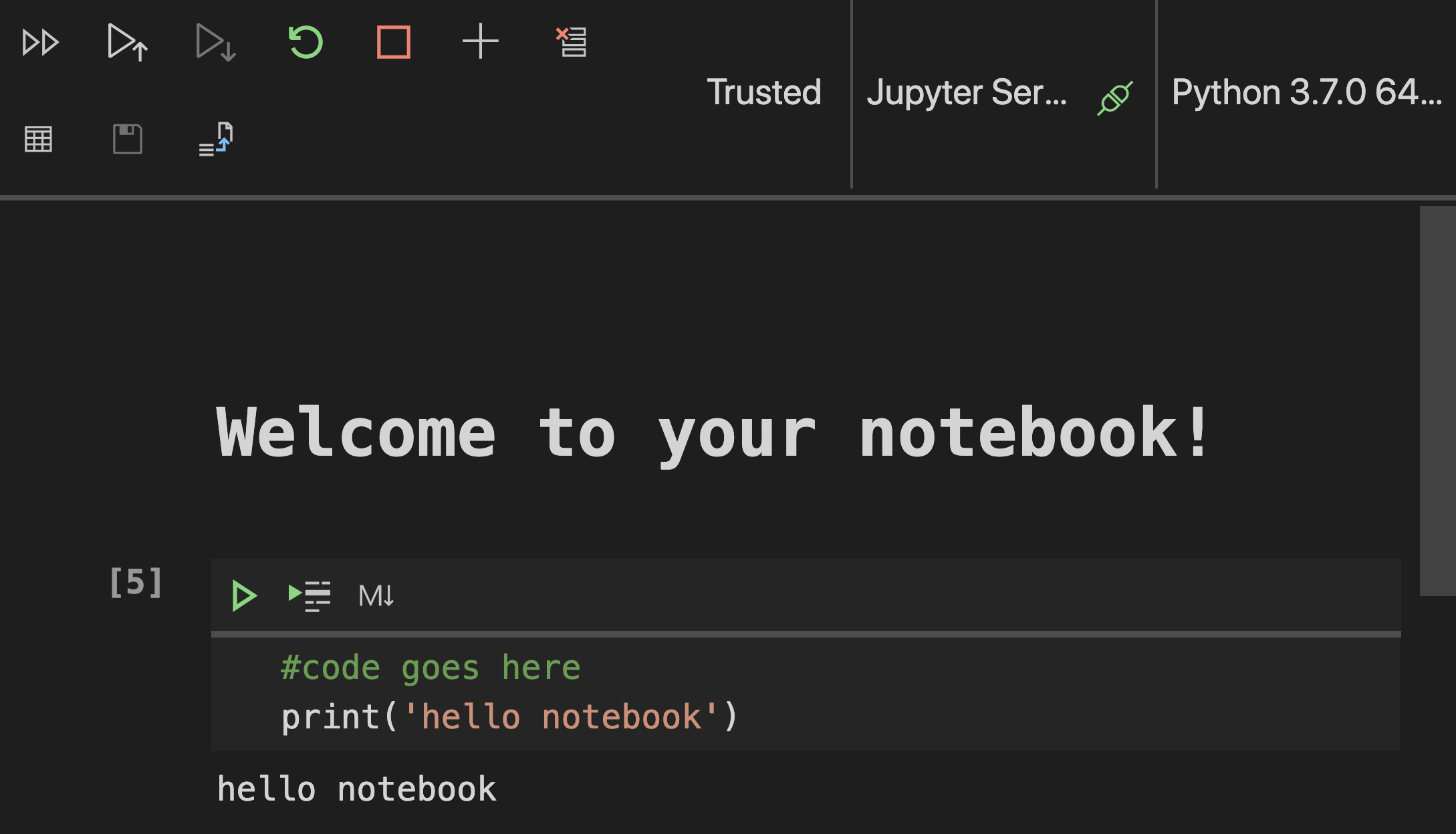
You can interleaf your code with comments to self-document the notebook.
✅ Think for a minute how different a web developer's working environment is versus that of a data scientist.
Up and Running with Scikit-Learn
Now that Python is set up in your local environment and you are comfortable with Jupyter notebooks, let's get equally comfortable with Scikit-Learn (pronounce it sci as in science).
According to their website, "Scikit-learn is an open source machine learning library that supports supervised and unsupervised learning. It also provides various tools for model fitting, data preprocessing, model selection and evaluation, and many other utilities."
Let's unpack some of this jargon:
🎓 A machine learning model
🎓 Supervised Learning works by mapping an input to an output based on example pairs. It uses labeled training data to build a function to make predictions. Download a printable Zine about Supervised Learning. Regression, which is covered in this group of lessons, is a type of supervised learning.
🎓 Unsupervised Learning works similarly but it maps pairs using unlabeled data. Download a printable Zine about Supervised Learning
🎓 Model Fitting in the context of machine learning refers to the accuracy of the model's underlying function as it attempts to analyze data with which it is not familiar. Underfitting and overfitting are common problems that degrade the quality of the model as the model fits either not well enough or too well. This causes the model to make predictions either too closely aligned or too loosely aligned with its training data. An overfit model predicts training data too well because it has learned the data's details and noise too well. An underfit model is not accurate as it can neither accurately analyze its training data nor data it has not yet 'seen'.
🎓 Data Preprocessing is the process whereby data scientists clean and convert data for use in the machine learning lifecycle.
🎓 Model Selection and Evaluation is the process whereby data scientists evaluate the accuracy of a model by feeding it unseen data, selecting the most appropriate model for the task at hand.
In this course, you will use Scikit-Learn and other tools to build machine learning models to perform what we call 'traditional machine learning' tasks. We have deliberately avoided neural networks and deep learning, as they are better covered in our forthcoming 'AI and ML' curriculum.
Scikit-Learn makes is straightforward to build models and evaluate them for use.
🚀 Challenge: Add a challenge for students to work on collaboratively in class to enhance the project
Optional: add a screenshot of the completed lesson's UI if appropriate
Post-lecture quiz
Review & Self Study
Assignment: Assignment Name