15 KiB
Sınıflandırmaya giriş
Bu dört derste klasik makine öğreniminin temel bir odağı olan sınıflandırma konusunu keşfedeceksiniz. Asya ve Hindistan'ın nefis mutfağının tamamı üzerine hazırlanmış bir veri setiyle çeşitli sınıflandırma algoritmalarını kullanmanın üzerinden geçeceğiz. Umarız açsınızdır!

Bu derslerede Pan-Asya mutfağını kutlayın! Fotoğraf Jen Looper tarafından çekilmiştir.
Sınıflandırma, regresyon yöntemleriyle birçok ortak özelliği olan bir gözetimli öğrenme biçimidir. Eğer makine öğrenimi tamamen veri setleri kullanarak değerleri veya nesnelere verilecek isimleri öngörmekse, sınıflandırma genellikle iki gruba ayrılır: ikili sınıflandırma ve çok sınıflı sınıflandırma.

🎥 Video için yukarıdaki fotoğrafa tıklayın: MIT's John Guttag introduces classification (MIT'den John Guttag sınıflandırmayı tanıtıyor)
Hatırlayın:
- Doğrusal regresyon değişkenler arasındaki ilişkileri öngörmenize ve o doğruya ilişkili olarak yeni bir veri noktasının nereye düşeceğine dair doğru öngörülerde bulunmanıza yardımcı oluyordu. Yani, bir balkabağının fiyatının aralık ayına göre eylül ayında ne kadar olabileceğini öngörebilirsiniz örneğin.
- Lojistik regresyon "ikili kategoriler"i keşfetmenizi sağlamıştı: bu fiyat noktasında, bu balkabağı turuncu mudur, turuncu-değil midir?
Sınıflandırma, bir veri noktasının etiketini veya sınıfını belirlemek için farklı yollar belirlemek üzere çeşitli algoritmalar kullanır. Bir grup malzemeyi gözlemleyerek kökeninin hangi mutfak olduğunu belirleyip belirleyemeyeceğimizi görmek için bu mutfak verisiyle çalışalım.
Ders öncesi kısa sınavı
Giriş
Sınıflandırma, makine öğrenimi araştırmacısının ve veri bilimcisinin temel işlerinden biridir. İkili bir değerin temel sınıflandırmasından ("Bu e-posta gereksiz (spam) midir yoksa değil midir?") bilgisayarla görüden yararlanarak karmaşık görüntü sınıflandırma ve bölütlemeye kadar, veriyi sınıf sınıf sıralayabilmek ve soru sorabilmek daima faydalıdır.
Süreci daha bilimsel bir yolla ifade etmek gerekirse, sınıflandırma yönteminiz, girdi bilinmeyenlerinin arasındaki ilişkiyi çıktı bilinmeyenlerine eşlemenizi sağlayan öngörücü bir model oluşturur.
Sınıflandırma algoritmalarının başa çıkması gereken ikili ve çok sınıflı problemler. Bilgilendirme grafiği Jen Looper tarafından hazırlanmıştır.
Verimizi temizleme, görselleştirme ve makine öğrenimi görevleri için hazırlama süreçlerine başlamadan önce, veriyi sınıflandırmak için makine öğreniminin leveraj edilebileceği çeşitli yolları biraz öğrenelim.
İstatistikten türetilmiş olarak, klasik makine öğrenimi kullanarak sınıflandırma, X hastalığının gelişmesi ihtimalini belirlemek için smoker, weight, ve age gibi öznitelikler kullanır. Daha önce yaptığınız regresyon alıştırmalarına benzeyen bir gözetimli öğrenme yöntemi olarak, veriniz etiketlenir ve makine öğrenimi algoritmaları o etiketleri, sınıflandırmak ve veri setinin sınıflarını (veya 'özniteliklerini') öngörmek ve onları bir gruba veya bir sonuca atamak için kullanır.
✅ Mutfaklarla ilgili bir veri setini biraz düşünün. Çok sınıflı bir model neyi cevaplayabilir? İkili bir model neyi cevaplayabilir? Farz edelim ki verilen bir mutfağın çemen kullanmasının muhtemel olup olmadığını belirlemek istiyorsunuz. Farzedelim ki yıldız anason, enginar, karnabahar ve bayır turpu ile dolu bir alışveriş poşetinden tipik bir Hint yemeği yapıp yapamayacağınızı görmek istiyorsunuz.

🎥 Video için yukarıdaki fotoğrafa tıklayın. Aşçıların rastgele malzeme seçeneklerinden yemek yaptığı 'Chopped' programının tüm olayı 'gizem sepetleri'dir. Kuşkusuz, bir makine öğrenimi modeli onlara yardımcı olurdu!
Merhaba 'sınıflandırıcı'
Bu mutfak veri setiyle ilgili sormak istediğimiz soru aslında bir çok sınıflı sorudur çünkü elimizde farklı potansiyel ulusal mutfaklar var. Verilen bir grup malzeme için, veri bu sınıflardan hangisine uyacak?
Scikit-learn, veriyi sınıflandırmak için kullanmak üzere, çözmek istediğiniz problem çeşidine bağlı olarak, çeşitli farklı algoritmalar sunar. Önümüzdeki iki derste, bu algoritmalardan birkaçını öğreneceksiniz.
Alıştırma - verinizi temizleyip dengeleyin
Bu projeye başlamadan önce elinizdeki ilk görev, daha iyi sonuçlar almak için, verinizi temizlemek ve dengelemek. Üst klasördeki boş notebook.ipynb dosyasıyla başlayın.
Kurmanız gereken ilk şey imblearn. Bu, veriyi daha iyi dengelemenizi sağlayacak bir Scikit-learn paketidir. (Bu görev hakkında birazdan daha fazla bilgi göreceksiniz.)
-
imblearnkurun,pip installçalıştırın, şu şekilde:pip install imblearn -
Verinizi almak ve görselleştirmek için ihtiyaç duyacağınız paketleri alın (import edin), ayrıca
imblearnpaketindenSMOTEalın.import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl import numpy as np from imblearn.over_sampling import SMOTEŞimdi okumak için hazırsınız, sonra veriyi alın.
-
Sonraki görev veriyi almak olacak:
df = pd.read_csv('../data/cuisines.csv')read_csv()kullanmak cusines.csv csv dosyasının içeriğini okuyacak vedfdeğişkenine yerleştirecek. -
Verinin şeklini kontrol edin:
df.head()İlk beş satır şöyle görünüyor:
| | Unnamed: 0 | cuisine | almond | angelica | anise | anise_seed | apple | apple_brandy | apricot | armagnac | ... | whiskey | white_bread | white_wine | whole_grain_wheat_flour | wine | wood | yam | yeast | yogurt | zucchini | | --- | ---------- | ------- | ------ | -------- | ----- | ---------- | ----- | ------------ | ------- | -------- | --- | ------- | ----------- | ---------- | ----------------------- | ---- | ---- | --- | ----- | ------ | -------- | | 0 | 65 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 1 | 66 | indian | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 2 | 67 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 3 | 68 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 4 | 69 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | -
info()fonksiyonunu çağırarak bu veri hakkında bilgi edinin:df.info()Çıktınız şuna benzer:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 2448 entries, 0 to 2447 Columns: 385 entries, Unnamed: 0 to zucchini dtypes: int64(384), object(1) memory usage: 7.2+ MB
Alıştırma - mutfaklar hakkında bilgi edinmek
Şimdi, işimiz daha da ilginçleşmeye başlıyor. Mutfak mutfak verinin dağılımını keşfedelim
-
barh()fonksiyonunu çağırarak veriyi sütunlarla çizdirin:df.cuisine.value_counts().plot.barh()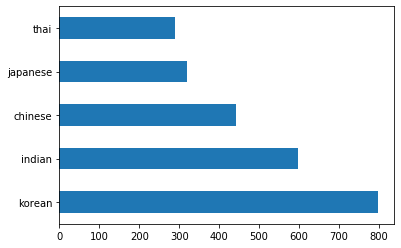
Sonlu sayıda mutfak var, ancak verinin dağılımı düzensiz. Bunu düzeltebilirsiniz! Bunu yapmadan önce, biraz daha keşfedelim.
-
Her mutfak için ne kadar verinin mevcut olduğunu bulun ve yazdırın:
thai_df = df[(df.cuisine == "thai")] japanese_df = df[(df.cuisine == "japanese")] chinese_df = df[(df.cuisine == "chinese")] indian_df = df[(df.cuisine == "indian")] korean_df = df[(df.cuisine == "korean")] print(f'thai df: {thai_df.shape}') print(f'japanese df: {japanese_df.shape}') print(f'chinese df: {chinese_df.shape}') print(f'indian df: {indian_df.shape}') print(f'korean df: {korean_df.shape}')çıktı şöyle görünür:
thai df: (289, 385) japanese df: (320, 385) chinese df: (442, 385) indian df: (598, 385) korean df: (799, 385)
Malzemeleri keşfetme
Şimdi veriyi daha derinlemesine inceleyebilirsiniz ve her mutfak için tipik malzemelerin neler olduğunu öğrenebilirsiniz. Mutfaklar arasında karışıklık yaratan tekrar eden veriyi temizlemelisiniz, dolayısıyla şimdi bu problemle ilgili bilgi edinelim.
-
Python'da, malzeme veri iskeleti yaratmak için
create_ingredient_df()diye bir fonksiyon oluşturun. Bu fonksiyon, yardımcı olmayan bir sütunu temizleyerek ve sayılarına göre malzemeleri sıralayarak başlar:def create_ingredient_df(df): ingredient_df = df.T.drop(['cuisine','Unnamed: 0']).sum(axis=1).to_frame('value') ingredient_df = ingredient_df[(ingredient_df.T != 0).any()] ingredient_df = ingredient_df.sort_values(by='value', ascending=False inplace=False) return ingredient_dfŞimdi bu fonksiyonu, her mutfağın en yaygın ilk on malzemesi hakkında hakkında fikir edinmek için kullanabilirsiniz.
-
create_ingredient_df()fonksiyonunu çağırın vebarh()fonksiyonunu çağırarak çizdirin:thai_ingredient_df = create_ingredient_df(thai_df) thai_ingredient_df.head(10).plot.barh()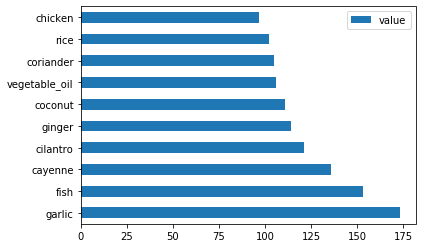
-
Japon verisi için de aynısını yapın:
japanese_ingredient_df = create_ingredient_df(japanese_df) japanese_ingredient_df.head(10).plot.barh()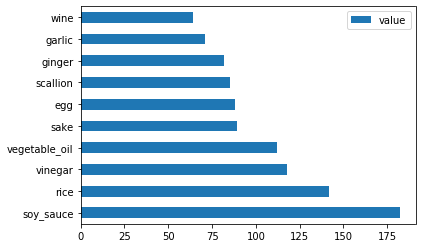
-
Şimdi Çin malzemeleri için yapın:
chinese_ingredient_df = create_ingredient_df(chinese_df) chinese_ingredient_df.head(10).plot.barh()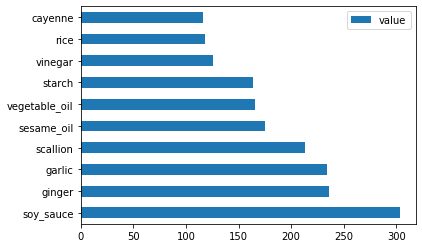
-
Hint malzemelerini çizdirin:
indian_ingredient_df = create_ingredient_df(indian_df) indian_ingredient_df.head(10).plot.barh()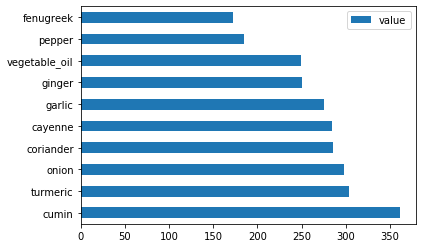
-
Son olarak, Kore malzemelerini çizdirin:
korean_ingredient_df = create_ingredient_df(korean_df) korean_ingredient_df.head(10).plot.barh()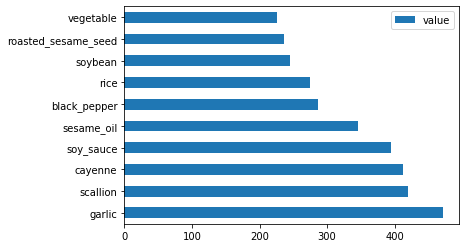
-
Şimdi,
drop()fonksiyonunu çağırarak, farklı mutfaklar arasında karışıklığa sebep olan en çok ortaklık taşıyan malzemeleri temizleyelim:Herkes pirinci, sarımsağı ve zencefili seviyor!
feature_df= df.drop(['cuisine','Unnamed: 0','rice','garlic','ginger'], axis=1) labels_df = df.cuisine #.unique() feature_df.head()
Veri setini dengeleyin
Veriyi temizlediniz, şimdi SMOTE - "Synthetic Minority Over-sampling Technique" ("Sentetik Azınlık Aşırı-Örnekleme/Örneklem-Artırma Tekniği") kullanarak dengeleyelim.
-
fit_resample()fonksiyonunu çağırın, bu strateji ara değerlemeyle yeni örnekler üretir.oversample = SMOTE() transformed_feature_df, transformed_label_df = oversample.fit_resample(feature_df, labels_df)Verinizi dengeleyerek, sınıflandırırken daha iyi sonuçlar alabileceksiniz. Bir ikili sınıflandırma düşünün. Eğer verimizin çoğu tek bir sınıfsa, bir makine öğrenimi modeli, sırf onun için daha fazla veri olduğundan o sınıfı daha sık tahmin edecektir. Veriyi dengelemek herhangi eğri veriyi alır ve bu dengesizliğin ortadan kaldırılmasına yardımcı olur.
-
Şimdi, her bir malzeme için etiket sayısını kontrol edebilirsiniz:
print(f'new label count: {transformed_label_df.value_counts()}') print(f'old label count: {df.cuisine.value_counts()}')Çıktınız şöyle görünür:
new label count: korean 799 chinese 799 indian 799 japanese 799 thai 799 Name: cuisine, dtype: int64 old label count: korean 799 indian 598 chinese 442 japanese 320 thai 289 Name: cuisine, dtype: int64Veri şimdi tertemiz, dengeli ve çok lezzetli!
-
Son adım, dengelenmiş verinizi, etiket ve özniteliklerle beraber, yeni bir dosyaya gönderilebilecek yeni bir veri iskeletine kaydetmek:
transformed_df = pd.concat([transformed_label_df,transformed_feature_df],axis=1, join='outer') -
transformed_df.head()vetransformed_df.info()fonksiyonlarını kullanarak verinize bir kez daha göz atabilirsiniz. Gelecek derslerde kullanabilmek için bu verinin bir kopyasını kaydedin:transformed_df.head() transformed_df.info() transformed_df.to_csv("../../data/cleaned_cuisines.csv")Bu yeni CSV şimdi kök data (veri) klasöründe görülebilir.
🚀 Meydan okuma
Bu öğretim programı farklı ilgi çekici veri setleri içermekte. data klasörlerini inceleyin ve ikili veya çok sınıflı sınıflandırma için uygun olabilecek veri setleri bulunduran var mı, bakın. Bu veri seti için hangi soruları sorabilirdiniz?
Ders sonrası kısa sınavı
Gözden Geçirme & Kendi Kendine Çalışma
SMOTE'nin API'ını keşfedin. En iyi hangi durumlar için kullanılıyor? Hangi problemleri çözüyor?