14 KiB
Regression 모델을 위한 Python과 Scikit-learn 시작하기
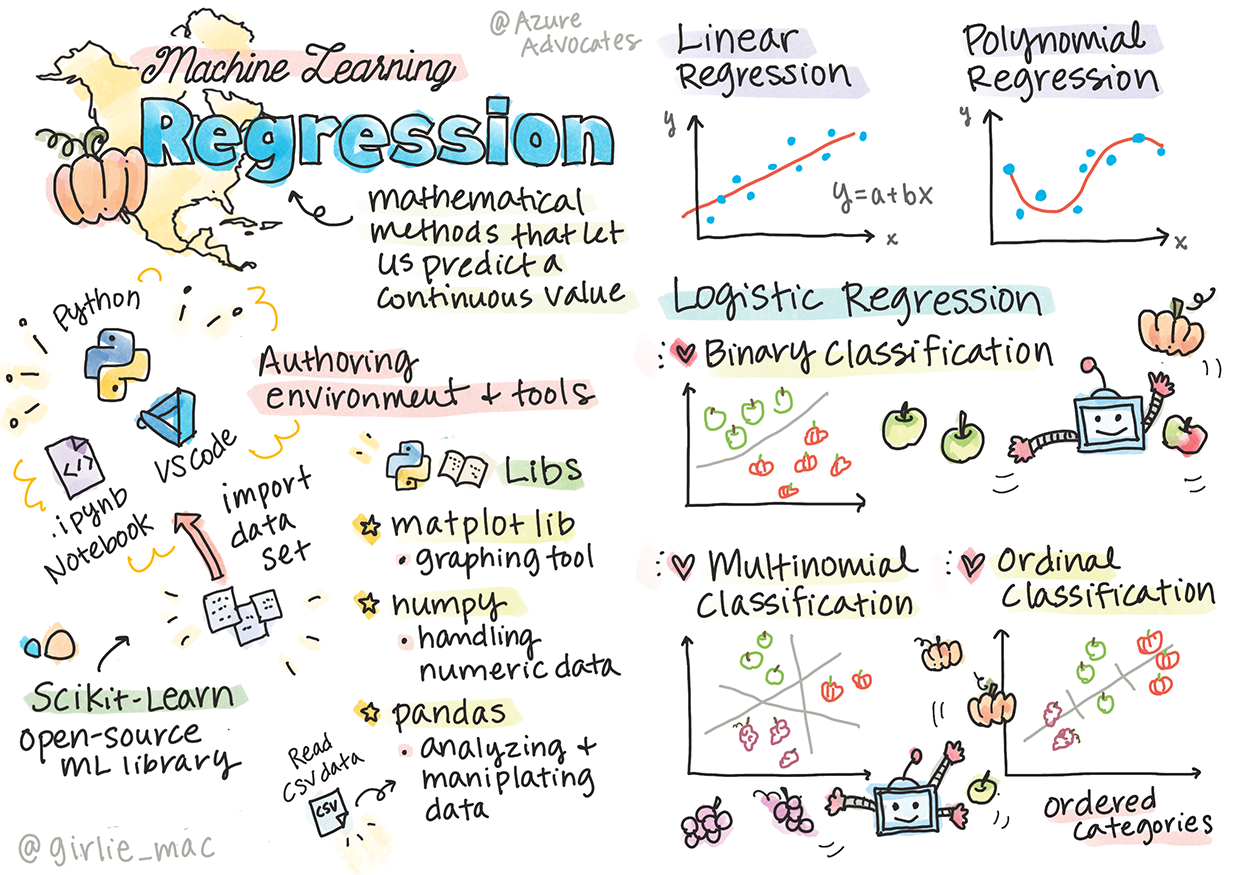
Sketchnote by Tomomi Imura
강의 전 퀴즈
소개
4개의 강의에서, regression 모델을 어떻게 만드는 지에 대하여 탐험합니다. 무엇인지 곧 이야기할 것 입니다. 하지만 모든 것을 하기 전에, 프로세스를 시작할 때 올바른 도구가 있는 지 확인합니다!
이 강의에서는, 이와 같은 내용을 배웁니다:
- 로컬 머신러닝 작업을 위해서 컴퓨터를 구성합니다.
- Jupyter notebooks으로 작업합니다.
- 설치 과정을 포함해서, Scikit-learn 사용합니다.
- 직접 연습해보며 linear regression을 알아봅니다.
설치하고 구성하기

🎥 영상 보려면 이미지 클릭: using Python within VS Code.
-
Python 설치하기. Python이 컴퓨터에 설치되었는 지 확인합니다. 많은 데이터 사이언스와 머신러닝 작업에서 Python을 사용하게 됩니다. 대부분 컴퓨터 시스템은 이미 Python 애플리케이션을 미리 포함하고 있습니다. 사용자가 설치를 쉽게하는, 유용한 Python Coding Packs이 존재합니다.
그러나, 일부 Python만 사용하면, 소프트웨어의 하나의 버전만 요구하지만, 다른 건 다른 버전을 요구합니다. 이런 이유로, virtual environment에서 작업하는 것이 유용합니다.
-
Visual Studio Code 설치하기. 컴퓨터에 Visual Studio Code가 설치되어 있는 지 확인합니다. 기본 설치로 install Visual Studio Code를 따라합니다. Visual Studio Code에서 Python을 사용하므로 Python 개발을 위한 configure Visual Studio Code를 살펴봅니다.
이 Learn modules의 모음을 통하여 Python에 익숙해집시다.
-
these instructions에 따라서, Scikit-learn 설치하기. Python 3을 사용하는 지 확인할 필요가 있습니다. 가상 환경으로 사용하는 것을 추천합니다. 참고로, M1 Mac에서 라이브러리를 설치하려면, 링크된 페이지에서 특별한 설치 방법을 따라합시다.
-
Jupyter Notebook 설치하기. install the Jupyter package가 필요합니다.
ML 작성 환경
notebooks으로 Python 코드를 개발하고 머신러닝 모델도 만드려고 합니다. 이 타입 파일은 데이터 사이언티스트의 일반적인 도구이고, 접미사 또는 확장자 .ipynb로 찾을 수 있습니다.
노트북은 개발자가 코드를 작성하고 노트를 추가하며 코드 사이에 문서를 작성할 수 있는 대화형 환경으로서 실험적이거나 연구-중심 프로젝트에 매우 도움이 됩니다.
연습 - notebook으로 작업하기
이 폴더에서, notebook.ipynb 파일을 찾을 수 있습니다.
-
Visual Studio Code에서 notebook.ipynb 엽니다.
Jupyter 서버는 Python 3+ 이상에서 시작됩니다. 코드 조각에서,
run할 수 있는 노트북 영역을 찾습니다. 재생 버튼처럼 보이는 아이콘을 선택해서, 코드 블록을 실핼할 수 있습니다. -
md아이콘을 선택하고 markdown을 살짝 추가합니다, 그리고 # Welcome to your notebook 텍스트를 넣습니다.다음으로, 약간의 Python 코드를 추가합니다.
-
코드 블록에서 print('hello notebook') 입력합니다.
-
코드를 실행하려면 화살표를 선택합니다.
출력된 구문이 보여야 합니다:
hello notebook
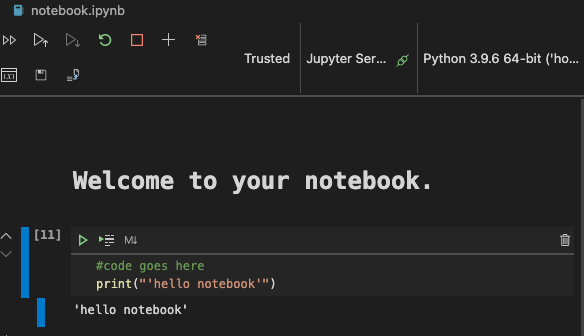
코드에 주석을 넣어서 노트북이 자체적으로 문서화 할 수 있게 할 수 있습니다.
✅ 웹 개발자의 작업 환경이 데이터 사이언티스트와 어떻게 다른 지 잠시 알아보세요.
Scikit-learn으로 시작하고 실행하기
이제 로컬 환경에 Python이 설정되었고, 그리고 Jupyter notebooks에 익숙해진 상태에서, Scikit-learn (science에서는 sci로 발음)도 익숙하게 하겠습니다. Scikit-learn은 ML 작업을 돕는 extensive API가 제공됩니다.
website에 따르면, "Scikit-learn is an open source machine learning library that supports supervised and unsupervised learning. It also provides various tools for model fitting, data preprocessing, model selection and evaluation, and many other utilities." 라고 언급되고 있습니다.
이 코스에서, Scikit-learn과 다른 도구를 사용하여 머신러닝 모델을 만들면서 'traditional machine learning' 작업이 진행됩니다. 곧 다가올 'AI for Beginners' 커리큘럼에서 더 잘 커버될 것이기 때문에, 신경망과 딥러닝은 제외했습니다.
Scikit-learn 사용하면 올바르게 모델을 만들고 사용하기 위해 평가할 수 있습니다. 주로 숫자 데이터에 포커스를 맞추고 학습 도구로 사용하기 위한 여러 ready-made 데이터셋이 포함됩니다. 또 학생들이 시도해볼 수 있도록 사전-제작된 모델을 포함합니다. 패키징된 데이터를 불러오고 기초 데이터와 Scikit-learn이 같이 있는 estimator first ML 모델로 프로세스를 찾아봅니다.
연습 - 첫 Scikit-learn notebook
이 튜토리얼은 Scikit-learn 웹사이트에 있는 linear regression example에서 영감 받았습니다.
이 강의에서 관련있는 notebook.ipynb 파일에서, 'trash can' 아이콘을 누르면 모든 셀이 지워집니다.
이 세션에서, 학습 목적의 Scikit-learn에서 만든 작은 당뇨 데이터셋으로 다룹니다. 당뇨 환자를 위한 치료 방법을 테스트하고 싶다고 생각해보세요. 머신러닝 모델은 변수 조합을 기반으로, 어떤 환자가 더 잘 치료될 지 결정할 때 도울 수 있습니다. 매우 기초적인 regression 모델도, 시각화하면, 이론적인 임상 시험을 구성하는 데에 도움이 될 변수 정보를 보여줄 수 있습니다.
✅ Regression 방식에는 많은 타입이 있고, 어떤 것을 선택하는 지에 따라 다릅니다. 만약 주어진 나이의 사람이 클 수 있는 키에 대하여 예측하려고, numeric value를 구할 때, linear regression을 사용합니다. 만약 어떤 타입의 요리를 비건으로 분류해야 하는 지 알고 싶다면, logistic regression으로 category assignment을 찾습니다. logistic regression은 나중에 자세히 알아봅시다. 데이터에 대하여 물어볼 수 있는 몇 가지 질문과, 이 방식 중 어느 것이 적당한 지 생각해봅니다.
작업을 시작하겠습니다.
라이브러리 Import
작업을 하기 위하여 일부 라이브러리를 import 합니다:
- matplotlib. 유용한 graphing tool이며 line plot을 만들 때 사용합니다.
- numpy. numpy는 Python애서 숫자를 핸들링할 때 유용한 라이브러리입니다.
- sklearn. Scikit-learn 라이브러리 입니다.
작업을 도움받으려면 라이브러리를 Import 합니다.
-
다음 코드를 타이핑해서 imports를 추가합니다:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionmatplottlib,numpy를 가져오고sklearn에서datasets,linear_model과model_selection을 가져옵니다.model_selection은 데이터를 학습하고 테스트 셋으로 나누기 위하여 사용합니다.
당뇨 데이터셋
빌트-인된 diabetes dataset은 당뇨에 대한 442개의 데이터 샘플이 있고, 10개의 feature 변수가 있으며, 그 일부는 아래와 같습니다:
age: age in years bmi: body mass index bp: average blood pressure s1 tc: T-Cells (a type of white blood cells)
✅ 이 데이터셋에는 당뇨를 연구할 때 중요한 feature 변수인 '성' 컨셉이 포함되어 있습니다. 많은 의학 데이터셋에는 binary classification의 타입이 포함됩니다. 이처럼 categorizations이 치료에서 인구의 특정 파트를 제외할 수 있는 방법에 대하여 조금 고민해보세요.
이제, X 와 y 데이터를 불러옵니다.
🎓 다시 언급하지만, 지도 학습이며, 이름이 붙은 'y' 타겟이 필요합니다.
새로운 코드 셀에서, load_diabetes()를 호출하여 당뇨 데이터셋을 불러옵니다. 입력 return_X_y=True는 X를 data matrix, y를 regression 타겟으로 나타냅니다.
-
data matrix와 첫 요소의 모양을 보여주는 출력 명령을 몇 개 추가합니다:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])응답하는 것은, tuple 입니다. 할 일은 tuple의 두 첫번째 값을
X와y에 각자 할당하는 것입니다. about tuples을 봅시다.데이터에 10개 요소의 배열로 이루어진 442개의 아이템이 보입니다:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ 데이터와 regression 타겟의 관계를 잠시 생각해보세요. Linear regression은 feature X와 타겟 변수 y 사이 관계를 예측합니다. 문서에서 당뇨 데이터셋의 target을 찾을 수 있나요? 타겟이 고려하면, 데이터셋은 무엇을 보여주나요?
-
다음은, numpy의
newaxis함수로 새로운 배열을 통해 플롯할 데이터셋의 일부를 선택합니다. 결정한 패턴에 맞춰서, 데이터의 값 사이에 라인을 생성하기 위하여 linear regression을 사용합니다.X = X[:, np.newaxis, 2]✅ 언제나, 모양 확인 차 데이터를 출력할 수 있습니다.
-
이제 데이터를 그릴 준비가 되었으므로, 머신이 데이터셋의 숫자 사이에서 논리적으로 판단하며 나누는 것을 도와주고 있는 지 확인할 수 있습니다. 그러면, 데이터 (X) 와 타겟 (y)를 테스트와 훈련 셋으로 나눌 필요가 있습니다. Scikit-learn에서는 간단한 방식이 존재합니다; 주어진 포인트에서 테스트 데이터를 나눌 수 있습니다.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
이제 모델을 훈련할 준비가 되었습니다! linear regression 모델을 부르고
model.fit()사용하여 X 와 y 훈련 셋으로 훈련합니다:model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()은 TensorFlow 처럼 많은 ML 라이브러리에서 볼 수 있는 함수입니다 -
그러면,
predict()함수를 사용하여, 테스트 데이터로 prediction을 만듭니다. 데이터 그룹 사이에 라인을 그릴 때 사용합니다y_pred = model.predict(X_test) -
이제 plot으로 데이터를 나타낼 시간입니다. Matplotlib은 이 작업에서 매우 유용한 도구입니다. 모든 X 와 y 테스트 데이터의 scatterplot (산점도)를 만들고, prediction을 사용해서 모델의 데이터 그룹 사이, 가장 적절한 장소에 라인을 그립니다.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()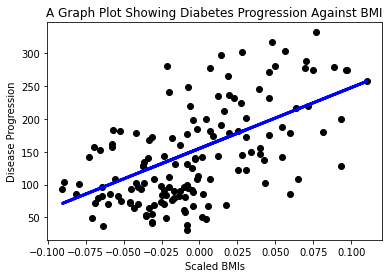
✅ 여기에 어떤 일이 생기는 지 생각합니다. 직선은 많은 데이터의 점을 지나지만, 무엇을 하고있나요? 라인으로 보이지 않는 데이터 포인트가 plot y 축으로 연관해서, 새롭게 맞출 지 예측하는 방식을 알 수 있을까요? 모델의 실제 사용 사례를 말 해봅니다.
축하드립니다. 첫 linear regression 모델을 만들고, 이를 통해서 prediction도 만들어서, plot에 보이게 했습니다!
🚀 도전
이 데이터셋은 다른 변수를 Plot 합니다. 힌트: 이 라인을 수정합니다: X = X[:, np.newaxis, 2]. 이 데이터셋의 타겟이 주어질 때, 질병으로 당뇨가 진행되면 어떤 것을 탐색할 수 있나요?
강의 후 퀴즈
검토 & 자기주도 학습
이 튜토리얼에서, univariate 또는 multiple linear regression이 아닌 simple linear regression으로 작업했습니다. 방식의 차이를 읽어보거나, this video를 봅니다.
regression의 개념에 대하여 더 읽고 기술로 답변할 수 있는 질문의 종류에 대하여 생각해봅니다. tutorial로 깊게 이해합니다.