15 KiB
Construye un modelo de regresión usando Scikit-learn: regresión de dos formas

Infografía de Dasani Madipalli
Examen previo a la lección
¡Esta lección está disponible en R!
Introducción
Hasta ahora has explorado qué es la regresión con datos obtenidos del conjunto de datos de los precios de las calabazas que usaremos en esta lección. También los has visualizado usando Matplotlib.
Ahora estás listo para profundizar en la regresión para el aprendizaje automático. En esta lección, aprenderás más acerca de dos tipos de regresión: regresión básica lineal y regresión polinomial, junto con algo de matemáticas fundamental a estas técnicas.
A lo largo de este plan de estudios, asumimos un conocimiento mínimo de matemáticas, y buscamos hacerlo accesible para los estudiantes provenientes de otros campos, así que pon atención a las notas, 🧮 llamados, diagramas, y otras herramientas de estudio para ayudar en la comprensión.
Prerrequisitos
Ahora, debes estar familiarizado con la estructura de los datos de las calabazas que ya examinamos. Puedes encontrarlos precargados y pre-limpiados en el archivo notebook.ipynb de esta lección. En el archivo, el precio de la calabaza se muestra por fanega en un nuevo dataframe. Asegúrate que puedas ejecutar estos notebooks en kernels en Visual Studio Code.
Preparación
Como recordatorio, estás cargando estos datos para hacer preguntas aceca de estos.
- ¿Cuándo es el mejor momento para comprar calabazas?
- ¿Qué precio puedo esperar para el caso de calabazas miniatura?
- ¿Debería comprarlas en cestos de media fanega o por caja de 1 1/9 de fanega?
Sigamos profundizando en estos datos.
En la lección anterior, creaste un dataframe de Pandas y lo poblaste con parte del conjunto de datos original, estandarizando el precio de la fanega. Haciéndolo, sólo fuiste capaz de reunir alrededor de 400 puntos de datos y sólo para los meses de otoño.
Da un vistazo a los datos que fueron precargados en el notebook que acompaña a esta lección. Los datos están precargados con un gráfico de dispersión inicial para mostrar datos mensuales. Quizá podamos obtener un poco más de detalle acerca de la naturaleza de los datos limpiándolos más.
Un línea de regresión lineal
Como aprendiste en la lección 1, el objetivo de un ejercicio de regresión lineal es ser capaz de graficar una línea para:
- Mostrar la relación de las variables. Mostrar la relación entre las variables
- Realizar predicciones. Hacer predicciones precisas en donde un nuevo punto de datos caería en relación a esa línea.
Es típico de la regresión de mínimos cuadrados el dibujar este tipo de línea. El término 'mínimos cuadrados' significa que todos los puntos de datos rodeando la línea de regresión se elevan al cuadrado y luego se suman. Idealmente, la suma final es tan pequeña como sea posible, porque queremos un número bajo de errores, o mínimos cuadrados.
Lo hacemos así ya que queremos modelar una línea que tiene la menor distancia acumulada de todos nuestros puntos de datos. También elevamos al cuadrado los términos antes de sumarlos ya que nos interesa su magnitud en lugar de su dirección.
🧮 Muéstrame las matemáticas
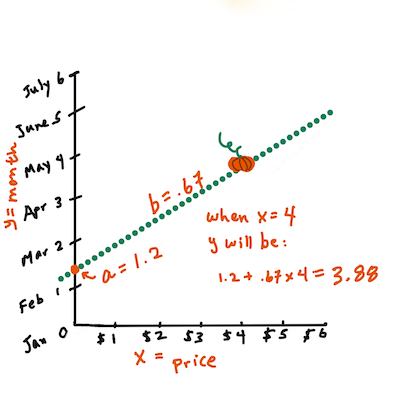
Esta línea, llamada la línea de mejor ajuste puede ser expresada por una ecuación:
Y = a + bX
Xes la 'variable explicativa'.Yes la 'variable dependiente'. La pendiente de la línea esbyaes la intercepción en y, la cual se refiere a el valor deYcuandoX = 0.
Primero, calcula la pendiente
b. Infografía de Jen LooperEn otras palabras, y refiriéndose a nuestra pregunta original de los datos de las calabazas: "predice el precio de una calabaza por fanega por mes",
Xse referiría al precio eYa el mes de venta.
Calcula el valor de Y. ¡Si estás pagando alrededor de $4, debe ser Abril! Infografía de Jen Looper
Las matemáticas que calculan la línea deben demostrar la pendiente de la línea, la cual también depende de la intercepción, o dónde
Yse sitúa cuandoX = 0.Puedes observar el método de cálculo para estos valores en el sitio web las matemáticas son divertidas. También visita esta calculadora de mínimos cuadrados para ver cómo los valores de los números impactan la línea.

Correlación
Un término más a entender es el coeficiente de correlación entre las variables dadas X e Y. Usando un gráfico de dispersión, puedes visualizar rápidamente este coeficiente. Un gráfico con puntos de datos dispersos en una línea ordenada tienen alta correlación, pero un gráfico con puntos de datos dispersos por todas partes entre X e Y tienen baja correlación.
Un buen modelo de regresión lineal será aquél que tenga un alto Coeficiente de Correlación (más cercano a 1 que a 0) usando el métro de regresión de mínimos cuadrados con una línea de regresión.
✅ Ejecuta el notebook que acompaña esta lección y mira el gráfico de Ciudad a Precio. ¿Los datos asociados de Ciudad a Precio para las ventas de calabaza parecen tener correlación alta o baja, de acuerdo a tu interpretación visual del gráfico de dispersión?
Prepara tus datos para la regresión
Ahora que tienes conocimiento de las matemáticas detrás de este ejercicio, crea un modelo de regresión para ver si puedes predecir cuál de los paquetes de calabazas tendrá los mejores precios. Alguien comprando calabazas para una parcela de calabazas en días festivos quisiera esta información para ser capaz de optimizar sus compras de paquetes de calabazas para la parcela.
Ya que usarás Scikit-learn, no hay razón para hacer esto a mano (¡aunque podrías!). En el bloque principal de procesamientos de datos de tu notebook de lección, agrega una biblioteca de Scikit-learn para convertir automáticamente todos los datos de cadena a números:
from sklearn.preprocessing import LabelEncoder
new_pumpkins.iloc[:, 0:-1] = new_pumpkins.iloc[:, 0:-1].apply(LabelEncoder().fit_transform)
Si ahora miras el nuevo dataframe new_pumpkins, ves que todas las cadenas ahora son numéricas. ¡Esto te dificulta el leer pero lo hace más comprensible para Scikit-learn!
Ahora puedes tomar decisiones más informadas (no sólo basado en un gráfico de dispersión) acerca de los datos que mejor se ajustan a la regresión.
Intenta encontrar una buena correlación entre dos puntos de tus datos para construir potencialmente un buen modelo predictivo. Como resultado, sólo hay correlación débil entre la Ciudad y el Precio.
print(new_pumpkins['City'].corr(new_pumpkins['Price']))
0.32363971816089226
Sin embargo, existe una correlación un poco mejor entre el Paquete y su Precio. Esto tiene sentido, ¿cierto? Normalmente, entre más grande sea la caja producida, mayor será el precio.
print(new_pumpkins['Package'].corr(new_pumpkins['Price']))
0.6061712937226021
Una buena pregunta a realizar de estos datos, sería: '¿Qué precio puedo esperar de un paquete de calabazas dado?'
Construyamos este modelo de regresión
Construyendo un modelo lineal
Antes de construir tu modelo, haz una limpieza más a tus datos. Elimina cualquier dato nulo y verifica una vez cómo lucen los datos.
new_pumpkins.dropna(inplace=True)
new_pumpkins.info()
Luego, crea un dataframe nuevo de este conjunto mínimo e imprímelo:
new_columns = ['Package', 'Price']
lin_pumpkins = new_pumpkins.drop([c for c in new_pumpkins.columns if c not in new_columns], axis='columns')
lin_pumpkins
Package Price
70 0 13.636364
71 0 16.363636
72 0 16.363636
73 0 15.454545
74 0 13.636364
... ... ...
1738 2 30.000000
1739 2 28.750000
1740 2 25.750000
1741 2 24.000000
1742 2 24.000000
415 rows × 2 columns
-
Ahora puedes asignar tus datos de coodenadas X e Y:
X = lin_pumpkins.values[:, :1] y = lin_pumpkins.values[:, 1:2]
✅ ¿Qué está pasando aquí? Estás usando notación slice de Python para crear arreglos y así poblar X e Y.
-
Lo siguiente es, iniciar las rutinas de construcción del modelo de regresión:
from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) lin_reg = LinearRegression() lin_reg.fit(X_train,y_train) pred = lin_reg.predict(X_test) accuracy_score = lin_reg.score(X_train,y_train) print('Model Accuracy: ', accuracy_score)Debido a que la correlación nos es particularmente buena, el modelo producido no es terriblemente preciso.
Model Accuracy: 0.3315342327998987 -
Puedes visualziar la línea dibujada en el proceso:
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, pred, color='blue', linewidth=3) plt.xlabel('Package') plt.ylabel('Price') plt.show()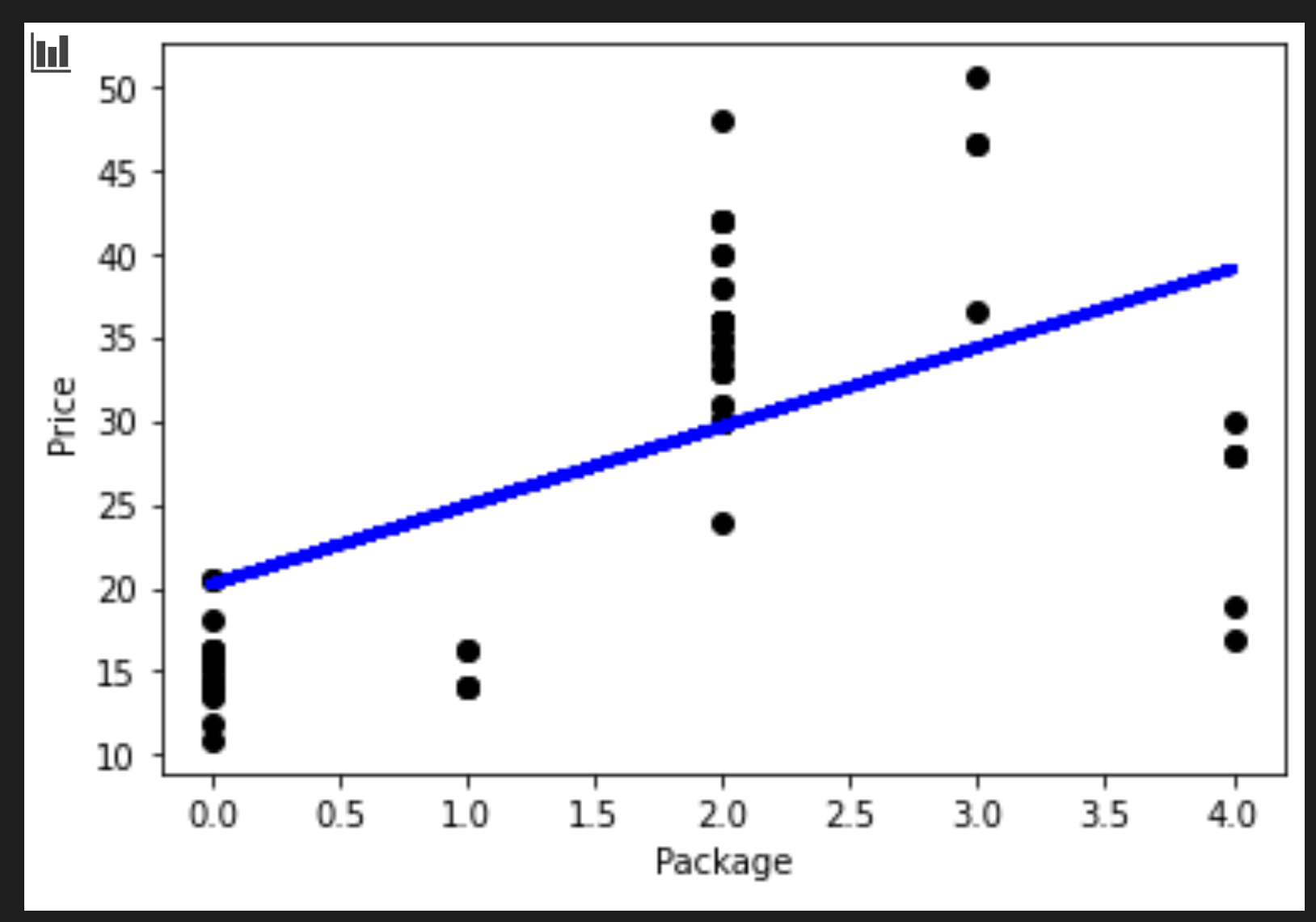
-
Prueba el modelo contra una variedad hipotética:
lin_reg.predict( np.array([ [2.75] ]) )El precio devuelto para esta Variedad mitológica es:
array([[33.15655975]])
Ese número hace sentido, si la lógica de la regresión lineal es cierta.
🎃 Felicidades, acabas de crear un modelo que puede ayudara predecir el precio de unas pocas variedades de calabazas. Tu parcela de calabazas de días festivos serán hermosas. ¡Pero probablemente puedes crear un mejor modelo!
Regresión polinomial
Otro tipo de regresión lineal es la regresión polinomial. Mientras algunas veces existe una relación lineal entre las variables - entre más grande el volumen de la calabaza, mayor el precio - algunas veces estas relaciones no pueden ser graficadas como un plano o línea recta.
✅ Aquí hay más ejemplos de los datos que podrían usar regresión polinomial.
Da un vistazo más a la relación entre Variedad a Precio en la gráfica anterior. ¿Parece que el gráfico de dispersión debería ser analizado necesariamente por una línea recta? Quizá no. En este caso, puedes probar la regresión polinomial.
✅ Los polinomios son expresiones matemáticas que pueden consistir en una o más variables y coeficientes.
La regresión polinomial crea una línea curva para ajustar mejor los datos no lineales.
-
Recreemos un dataframe poblado con un segmento de los datos originales de las calabazas:
new_columns = ['Variety', 'Package', 'City', 'Month', 'Price'] poly_pumpkins = new_pumpkins.drop([c for c in new_pumpkins.columns if c not in new_columns], axis='columns') poly_pumpkins
Una buena forma de visualizar las correlaciones entre los datos en los dataframes es mostrarlos en una gráfica 'coolwarm':
-
Usa el método
Background_gradient()concoolwarmcomo valor de su argumento:corr = poly_pumpkins.corr() corr.style.background_gradient(cmap='coolwarm')Este código crea un mapa de calor:
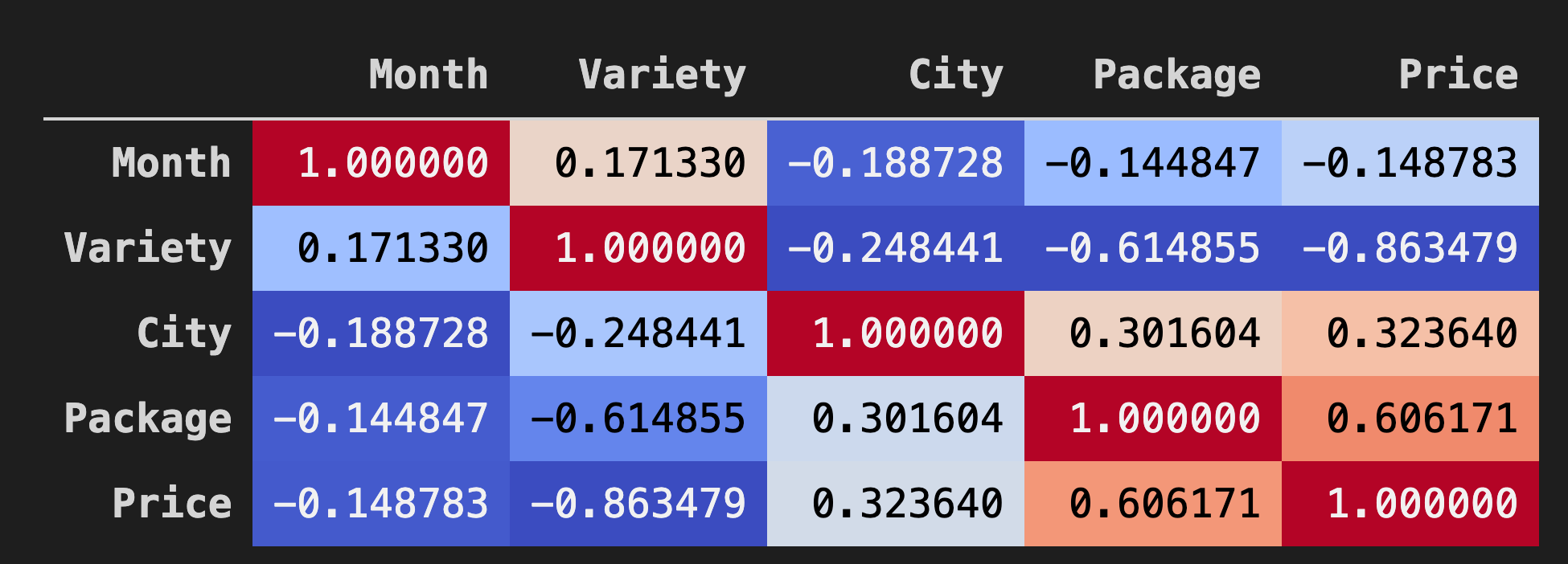
Viendo esta gráfica, puedes visualizar la buena correlación entre Paquete y Precio. Así que deberías ser capaz de crear un modelo algo mejor que el anterior.
Crea un pipeline
Scikit-learn incluye una API útil para crear modelos de regresión polinomail - la API make_pipeline. Se crea un 'pipeline' que es una cadena de estimadores. En este caso, el pipeline incluye características polinomiales, o predicciones que forman un camino no lineal.
-
Construye las columnas X e Y:
X=poly_pumpkins.iloc[:,3:4].values y=poly_pumpkins.iloc[:,4:5].values -
Crea el pipeline llamando al método
make_pipeline():from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import make_pipeline pipeline = make_pipeline(PolynomialFeatures(4), LinearRegression()) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) pipeline.fit(np.array(X_train), y_train) y_pred=pipeline.predict(X_test)
Crea una secuencia
En este punto, necesitas crear un nuevo dataframe con datos ordenados para que así el pipeline pueda crear una secuencia.
Agrega el siguiente código:
df = pd.DataFrame({'x': X_test[:,0], 'y': y_pred[:,0]})
df.sort_values(by='x',inplace = True)
points = pd.DataFrame(df).to_numpy()
plt.plot(points[:, 0], points[:, 1],color="blue", linewidth=3)
plt.xlabel('Package')
plt.ylabel('Price')
plt.scatter(X,y, color="black")
plt.show()
Creaste un nuevo dataframe llamando pd.DataFrame. Luego ordenaste los valores al llamar sort_values(). Finalmente creaste un gráfico polinomial:
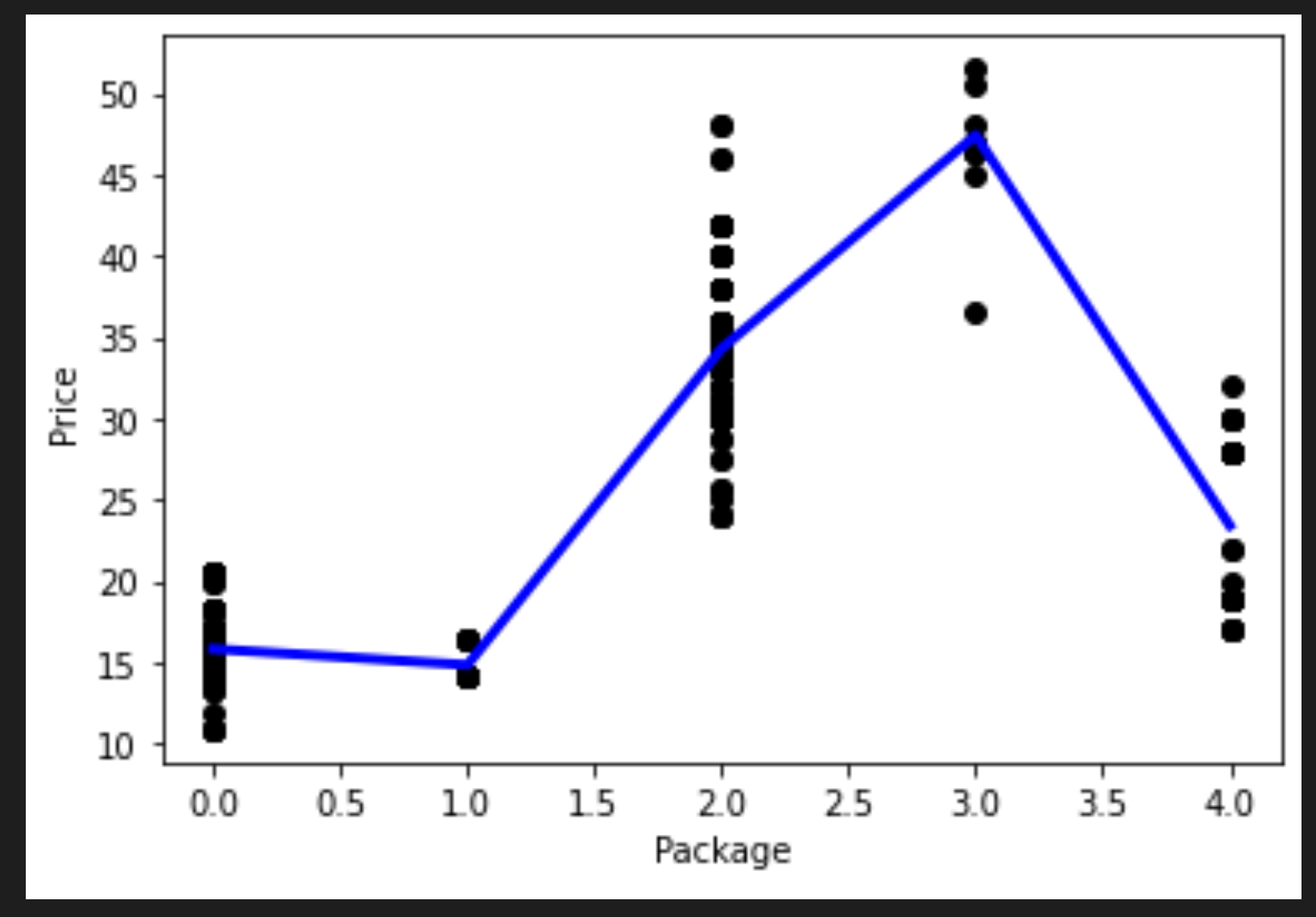
Puedes ver una línea curva que se ajusta mejor a tus datos.
Revisemos la precisión del modelo:
accuracy_score = pipeline.score(X_train,y_train)
print('Model Accuracy: ', accuracy_score)
¡Y voila!
Model Accuracy: 0.8537946517073784
¡Es mejor! Intenta predecir un precio:
Haz un predicción
¿Podemos ingresar un nuevo valor y obtener una predicción?
Llama a predict() para hacer una predicción:
pipeline.predict( np.array([ [2.75] ]) )
Se te presenta esta predicción:
array([[46.34509342]])
¡Hace sentido, dado el gráfico! Y, si este es un mejor modelo que el anterior, viendo los mismos datos, ¡necesitas presupuestar para estas calabazas más caras!
🏆 ¡Bien hecho! Creaste dos modelos de regresión en una lección. En la sección final de regresión, aprenderás acerca de la regresión logística para determinar categorías.
🚀Desafío
Prueba variables diferentes en este notebook para ver cómo la correlación corresponde a la precisión del modelo.
Examen posterior a la lección
Revisión y auto-estudio
En esta lección aprendimos acerca de la regresión lineal. Existen otros tipos importantes de regresión. Lee acerca de las técnicas paso a paso (Stepwise), cresta (Ridge), Lazo y red elástica (Lasso and Elasticnet). Un buen curso para estudiar para aprender más es el Curso de aprendizaje estadístico de Stanford