14 KiB
機械学習の手法
機械学習モデルやそのモデルが使用するデータを構築・使用・管理するプロセスは、他の多くの開発ワークフローとは全く異なるものです。このレッスンでは、このプロセスを明快にして、知っておくべき主な手法の概要をまとめます。あなたは、
- 機械学習を支えるプロセスを高い水準で理解します。
- 「モデル」「予測」「訓練データ」などの基本的な概念を調べます。
講義前の小テスト
導入
大まかに言うと、機械学習 (Machine Learning: ML) プロセスを作成する技術はいくつかのステップで構成されています。
- 質問を決める。ほとんどの機械学習プロセスは、単純な条件のプログラムやルールベースのエンジンでは答えられないような質問をすることから始まります。このような質問は、データの集合を使った予測を中心にされることが多いです。
- データを集めて準備する。質問に答えるためにはデータが必要です。データの質と、ときには量が、最初の質問にどれだけうまく答えられるかを決めます。データの可視化がこのフェーズの重要な側面です。モデルを構築するためにデータを訓練グループとテストグループに分けることもこのフェーズに含みます。
- 学習方法を選ぶ。質問の内容やデータの性質に応じて、データを最も良く反映して正確に予測できるモデルを、どのように学習するかを選ぶ必要があります。これは機械学習プロセスの中でも、特定の専門知識と、多くの場合はかなりの試行回数が必要になる部分です。
- モデルを学習する。データのパターンを認識するモデルを学習するために、訓練データと様々なアルゴリズムを使います。モデルはより良いモデルを構築するために、データの特定の部分を優先するように調整できる内部の重みを活用するかもしれません。
- モデルを評価する。モデルがどのように動作しているかを確認するために、集めたデータの中からまだ見たことのないもの(テストデータ)を使います。
- パラメータチューニング。モデルの性能によっては、モデルを学習するために使われる、各アルゴリズムの挙動を制御するパラメータや変数を変更してプロセスをやり直すこともできます。
- 予測する。モデルの精度をテストするために新しい入力を使います。
どのような質問をすれば良いか
コンピュータはデータの中に隠れているパターンを見つけることがとても得意です。この有用性は、条件ベースのルールエンジンを作っても簡単には答えられないような、特定の領域に関する質問を持っている研究者にとって非常に役立ちます。たとえば、ある保険数理の問題があったとして、データサイエンティストは喫煙者と非喫煙者の死亡率に関する法則を自分の手だけでも作れるかもしれません。
しかし、他にも多くの変数が方程式に含まれる場合、過去の健康状態から将来の死亡率を予測する機械学習モデルの方が効率的かもしれません。もっと明るいテーマの例としては、緯度、経度、気候変動、海への近さ、ジェット気流のパターンなどのデータに基づいて、特定の場所における4月の天気を予測することができます。
✅ 気象モデルに関するこの スライド は、気象解析に機械学習を使う際の歴史的な考え方を示しています。
構築前のタスク
モデルの構築を始める前に、いくつかのタスクを完了させる必要があります。質問をテストしたりモデルの予測に基づいた仮説を立てたりするためには、いくつかの要素を特定して設定する必要があります。
データ
質問に確実に答えるためには、適切な種類のデータが大量に必要になります。ここではやるべきことが2つあります。
- データを集める。データ解析における公平性に関する前回の講義を思い出しながら、慎重にデータを集めてください。特定のバイアスを持っているかもしれないデータのソースに注意し、それを記録しておいてください。
- データを準備する。データを準備するプロセスにはいくつかのステップがあります。異なるソースからデータを集めた場合、照合と正規化が必要になるかもしれません。(クラスタリング で行っているように、)文字列を数値に変換するなどの様々な方法でデータの質と量を向上させることができます。(分類 で行っているように、)元のデータから新しいデータを生成することもできます。(Webアプリ の講義の前に行うように、)データをクリーニングしたり編集したりすることができます。最後に、学習の手法によっては、ランダムにしたりシャッフルしたりする必要もあるかもしれません。
✅ データを集めて処理した後は、その形で意図した質問に対応できるかどうかを確認してみましょう。クラスタリング の講義でわかるように、データは与えられたタスクに対して上手く機能しないかもしれません!
機能とターゲット
フィーチャは、データの測定可能なプロパティです。多くのデータセットでは、'日付' 'サイズ' や '色' のような列見出しとして表現されます。通常、コードでは X として表されるフィーチャ変数は、モデルのトレーニングに使用される入力変数を表します
ターゲットは、予測しようとしているものです。ターゲットは通常、コードでyとして表され、あなたのデータを尋ねようとしている質問に対する答えを表します:12月に、どの色のカボチャが最も安くなりますか?サンフランシスコでは、どの地域が最高の不動産価格を持つでしょうか?ターゲットはラベル属性とも呼ばれることもあります。
特徴量の選択
🎓 特徴選択と特徴抽出 モデルを構築する際にどの変数を選ぶべきかは、どうすればわかるでしょうか?最も性能の高いモデルのためには、適した変数を選択する特徴選択や特徴抽出のプロセスをたどることになるでしょう。しかし、これらは同じものではありません。「特徴抽出は元の特徴の機能から新しい特徴を作成するのに対し、特徴選択は特徴の一部を返すものです。」 (出典)
データを可視化する
データサイエンティストの道具に関する重要な側面は、Seaborn や MatPlotLib などの優れたライブラリを使ってデータを可視化する力です。データを視覚的に表現することで、隠れた相関関係を見つけて活用できるかもしれません。また、(分類 でわかるように、)視覚化することで、バイアスやバランシングされていないデータを見つけられるかもしれません。
データセットを分割する
学習の前にデータセットを2つ以上に分割して、それぞれがデータを表すのに十分かつ不均等な大きさにする必要があります。
- 学習。データセットのこの部分は、モデルを学習するために適合させます。これは元のデータセットの大部分を占めます。
- テスト。テストデータセットとは、構築したモデルの性能を確認するために使用する独立したデータグループのことで、多くの場合は元のデータから集められます。
- 検証。検証セットとは、さらに小さくて独立したサンプルの集合のことで、モデルを改善するためにハイパーパラメータや構造を調整する際に使用されます。(時系列予測 に記載しているように、)データの大きさや質問の内容によっては、この3つ目のセットを作る必要はありません。
モデルの構築
訓練データと様々なアルゴリズムを使った 学習 によって、モデルもしくはデータの統計的な表現を構築することが目標です。モデルを学習することで、データを扱えるようになったり、発見、検証、肯定または否定したパターンに関する仮説を立てることができたりします。
学習方法を決める
質問の内容やデータの性質に応じて、モデルを学習する方法を選択します。このコースで使用する Scikit-learn のドキュメント を見ると、モデルを学習する様々な方法を調べられます。経験次第では、最適なモデルを構築するためにいくつかの異なる方法を試す必要があるかもしれません。また、モデルが見たことのないデータを与えたり、質を下げている問題、精度、バイアスについて調べたり、タスクに対して最適な学習方法を選んだりすることで、データサイエンティストが行っている、モデルの性能を評価するプロセスを踏むことになるでしょう。
モデルを学習する
トレーニングデータを使用して、モデルを作成するために「フィット」する準備が整いました。多くの ML ライブラリでは、コード 'model.fit' が見つかります - この時点で、値の配列 (通常は X) とターゲット変数 (通常は y) として機能変数を送信します。
モデルを評価する
(大きなモデルを学習するには多くの反復(エポック)が必要になりますが、)学習プロセスが完了したら、テストデータを使ってモデルの質を評価することができます。このデータは元のデータのうち、モデルがそれまでに分析していないものです。モデルの質を表す指標の表を出力することができます。
🎓 モデルフィッティング
機械学習におけるモデルフィッティングは、モデルがまだ知らないデータを分析する際の根本的な機能の精度を参照します。
🎓 未学習 と 過学習 はモデルの質を下げる一般的な問題で、モデルが十分に適合していないか、または適合しすぎています。これによってモデルは訓練データに近すぎたり遠すぎたりする予測を行います。過学習モデルは、データの詳細やノイズもよく学習しているため、訓練データを上手く予測しすぎてしまいます。未学習モデルは、訓練データやまだ「見たことのない」データを正確に分析することができないため、精度が高くないです。
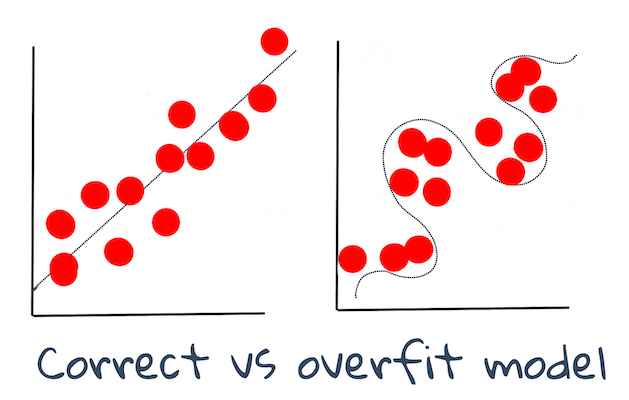
Jen Looper さんによる解説画像
パラメータチューニング
最初のトレーニングが完了したら、モデルの質を観察して、「ハイパーパラメータ」の調整によるモデルの改善を検討しましょう。このプロセスについては ドキュメント を読んでください。
予測
全く新しいデータを使ってモデルの精度をテストする瞬間です。本番環境でモデルを使用するためにWebアセットを構築するよう「適用された」機械学習の設定においては、推論や評価のためにモデルに渡したり、変数を設定したりするためにユーザの入力(ボタンの押下など)を収集することがこのプロセスに含まれるかもしれません。
この講義では、「フルスタック」の機械学習エンジニアになるための旅をしながら、準備・構築・テスト・評価・予測などのデータサイエンティストが行うすべてのステップの使い方を学びます。
🚀チャレンジ
機械学習の学習者のステップを反映したフローチャートを描いてください。今の自分はこのプロセスのどこにいると思いますか?どこに困難があると予想しますか?あなたにとって簡単そうなことは何ですか?
講義後の小テスト
振り返りと自主学習
データサイエンティストが日々の仕事について話しているインタビューをネットで検索してみましょう。ひとつは これ です。