16 KiB
Keadilan dalam Machine Learning
Catatan sketsa oleh Tomomi Imura
Quiz Pra-Pelajaran
Pengantar
Dalam kurikulum ini, kamu akan mulai mengetahui bagaimana Machine Learning bisa memengaruhi kehidupan kita sehari-hari. Bahkan sekarang, sistem dan model terlibat dalam tugas pengambilan keputusan sehari-hari, seperti diagnosis kesehatan atau mendeteksi penipuan. Jadi, penting bahwa model-model ini bekerja dengan baik untuk memberikan hasil yang adil bagi semua orang.
Bayangkan apa yang bisa terjadi ketika data yang kamu gunakan untuk membangun model ini tidak memiliki demografi tertentu, seperti ras, jenis kelamin, pandangan politik, agama, atau secara tidak proporsional mewakili demografi tersebut. Bagaimana jika keluaran dari model diinterpretasikan lebih menyukai beberapa demografis tertentu? Apa konsekuensi untuk aplikasinya?
Dalam pelajaran ini, kamu akan:
- Meningkatkan kesadaran dari pentingnya keadilan dalam Machine Learning.
- Mempelajari tentang berbagai kerugian terkait keadilan.
- Learn about unfairness assessment and mitigation.
- Mempelajari tentang mitigasi dan penilaian ketidakadilan.
Prasyarat
Sebagai prasyarat, silakan ikuti jalur belajar "Prinsip AI yang Bertanggung Jawab" dan tonton video di bawah ini dengan topik:
Pelajari lebih lanjut tentang AI yang Bertanggung Jawab dengan mengikuti Jalur Belajar ini

🎥 Klik gambar diatas untuk menonton video: Pendekatan Microsoft untuk AI yang Bertanggung Jawab
Ketidakadilan dalam data dan algoritma
"Jika Anda menyiksa data cukup lama, data itu akan mengakui apa pun " - Ronald Coase
Pernyataan ini terdengar ekstrem, tetapi memang benar bahwa data dapat dimanipulasi untuk mendukung kesimpulan apa pun. Manipulasi semacam itu terkadang bisa terjadi secara tidak sengaja. Sebagai manusia, kita semua memiliki bias, dan seringkali sulit untuk secara sadar mengetahui kapan kamu memperkenalkan bias dalam data.
Menjamin keadilan dalam AI dan machine learning tetap menjadi tantangan sosioteknik yang kompleks. Artinya, hal itu tidak bisa ditangani baik dari perspektif sosial atau teknis semata.
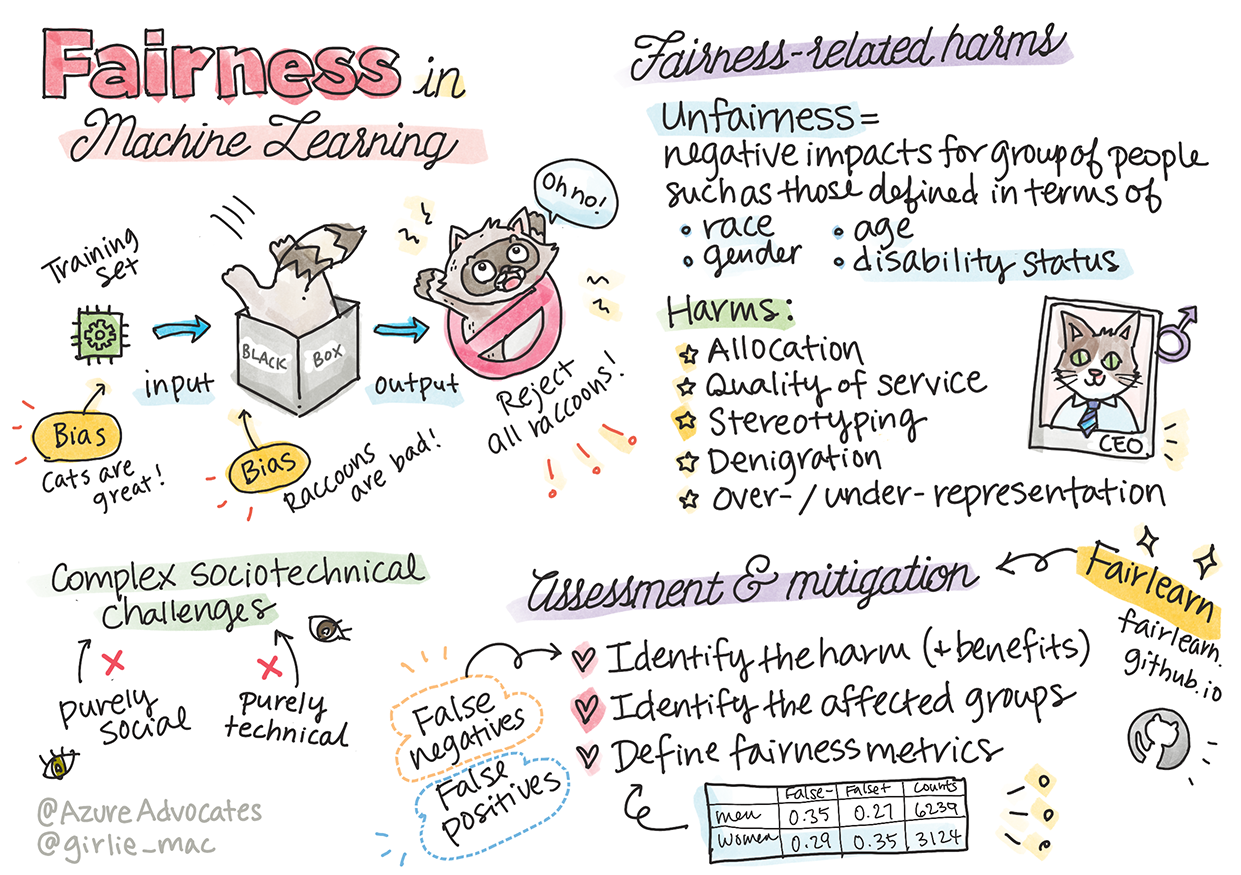
Kerugian Terkait Keadilan
Apa yang dimaksud dengan ketidakadilan? "Ketidakadilan" mencakup dampak negatif atau "bahaya" bagi sekelompok orang, seperti yang didefinisikan dalam hal ras, jenis kelamin, usia, atau status disabilitas.
Kerugian utama yang terkait dengan keadilan dapat diklasifikasikan sebagai:
- Alokasi, jika suatu jenis kelamin atau etnisitas misalkan lebih disukai daripada yang lain.
- Kualitas layanan. Jika kamu melatih data untuk satu skenario tertentu tetapi kenyataannya jauh lebih kompleks, hasilnya adalah layanan yang berkinerja buruk.
- Stereotip. Mengaitkan grup tertentu dengan atribut yang ditentukan sebelumnya.
- Fitnah. Untuk mengkritik dan melabeli sesuatu atau seseorang secara tidak adil.
- Representasi yang kurang atau berlebihan. Idenya adalah bahwa kelompok tertentu tidak terlihat dalam profesi tertentu, dan layanan atau fungsi apa pun yang terus dipromosikan yang menambah kerugian.
Mari kita lihat contoh-contohnya.
Alokasi
Bayangkan sebuah sistem untuk menyaring pengajuan pinjaman. Sistem cenderung memilih pria kulit putih sebagai kandidat yang lebih baik daripada kelompok lain. Akibatnya, pinjaman ditahan dari pemohon tertentu.
Contoh lain adalah alat perekrutan eksperimental yang dikembangkan oleh perusahaan besar untuk menyaring kandidat. Alat tersebut secara sistematis mendiskriminasi satu gender dengan menggunakan model yang dilatih untuk lebih memilih kata-kata yang terkait dengan gender lain. Hal ini mengakibatkan kandidat yang resumenya berisi kata-kata seperti "tim rugby wanita" tidak masuk kualifikasi.
✅ Lakukan sedikit riset untuk menemukan contoh dunia nyata dari sesuatu seperti ini
Kualitas Layanan
Para peneliti menemukan bahwa beberapa pengklasifikasi gender komersial memiliki tingkat kesalahan yang lebih tinggi di sekitar gambar wanita dengan warna kulit lebih gelap dibandingkan dengan gambar pria dengan warna kulit lebih terang. Referensi
Contoh terkenal lainnya adalah dispenser sabun tangan yang sepertinya tidak bisa mendeteksi orang dengan kulit gelap. Referensi
Stereotip
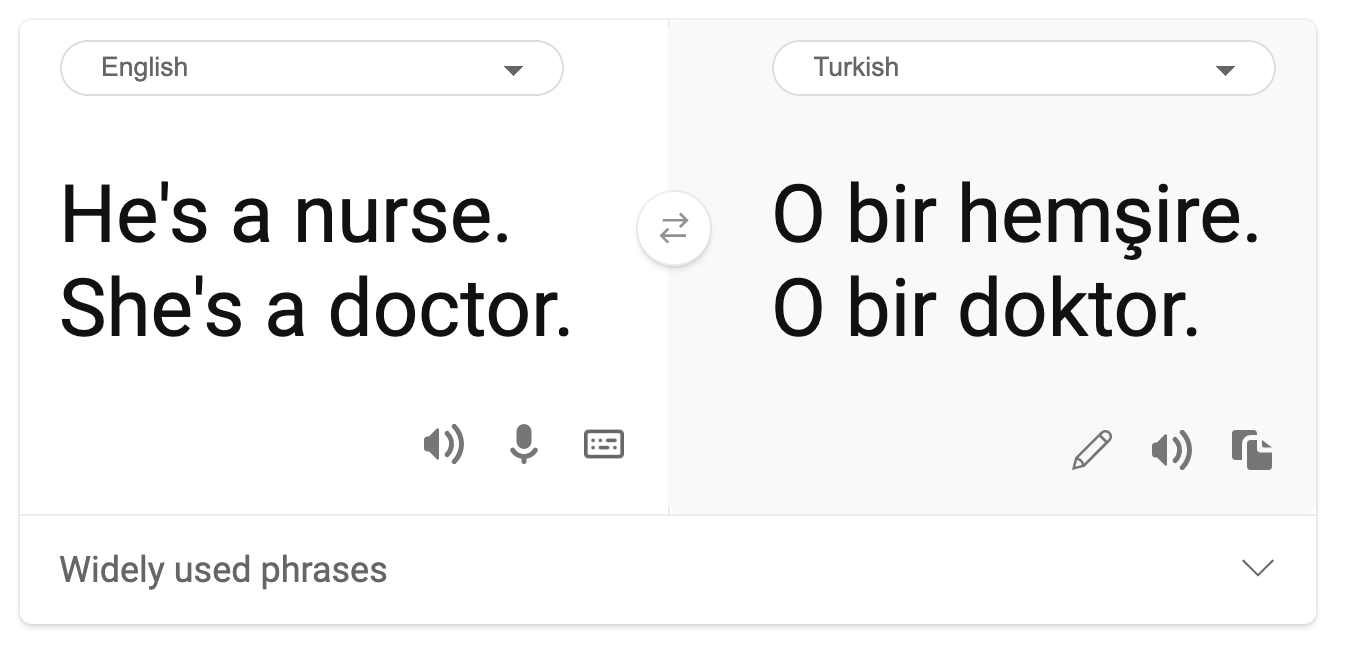
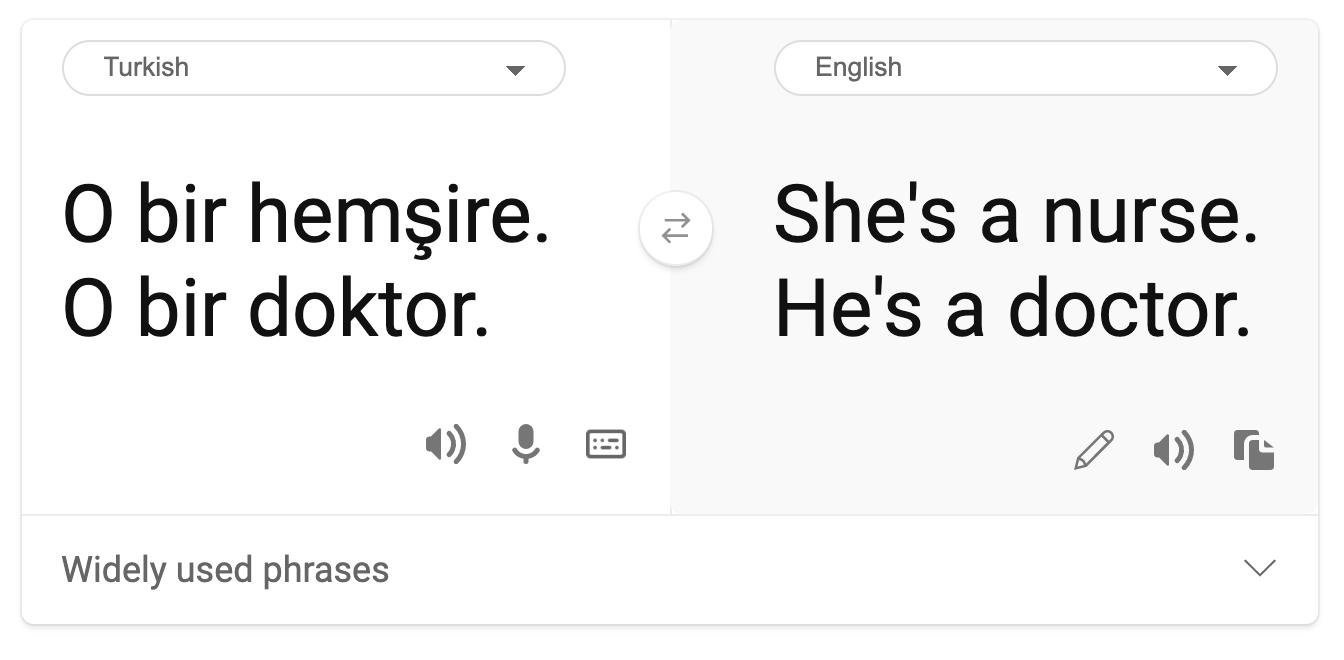
Pandangan gender stereotip ditemukan dalam terjemahan mesin. Ketika menerjemahkan "dia (laki-laki) adalah seorang perawat dan dia (perempuan) adalah seorang dokter" ke dalam bahasa Turki, masalah muncul. Turki adalah bahasa tanpa gender yang memiliki satu kata ganti, "o" untuk menyampaikan orang ketiga tunggal, tetapi menerjemahkan kalimat kembali dari Turki ke Inggris menghasilkan stereotip dan salah sebagai "dia (perempuan) adalah seorang perawat dan dia (laki-laki) adalah seorang dokter".
Fitnah
Sebuah teknologi pelabelan gambar yang terkenal salah memberi label gambar orang berkulit gelap sebagai gorila. Pelabelan yang salah berbahaya bukan hanya karena sistem membuat kesalahan karena secara khusus menerapkan label yang memiliki sejarah panjang yang sengaja digunakan untuk merendahkan orang kulit hitam.

🎥 Klik gambar diatas untuk sebuah video: AI, Bukankah Aku Seorang Wanita? - menunjukkan kerugian yang disebabkan oleh pencemaran nama baik yang menyinggung ras oleh AI
Representasi yang kurang atau berlebihan
Hasil pencarian gambar yang condong ke hal tertentu (skewed) dapat menjadi contoh yang bagus dari bahaya ini. Saat menelusuri gambar profesi dengan persentase pria yang sama atau lebih tinggi daripada wanita, seperti teknik, atau CEO, perhatikan hasil yang lebih condong ke jenis kelamin tertentu.

Pencarian di Bing untuk 'CEO' ini menghasilkan hasil yang cukup inklusif
Lima jenis bahaya utama ini tidak saling eksklusif, dan satu sistem dapat menunjukkan lebih dari satu jenis bahaya. Selain itu, setiap kasus bervariasi dalam tingkat keparahannya. Misalnya, memberi label yang tidak adil kepada seseorang sebagai penjahat adalah bahaya yang jauh lebih parah daripada memberi label yang salah pada gambar. Namun, penting untuk diingat bahwa bahkan kerugian yang relatif tidak parah dapat membuat orang merasa terasing atau diasingkan dan dampak kumulatifnya bisa sangat menekan.
✅ Diskusi: Tinjau kembali beberapa contoh dan lihat apakah mereka menunjukkan bahaya yang berbeda.
| Alokasi | Kualitas Layanan | Stereotip | Fitnah | Representasi yang kurang atau berlebihan | |
|---|---|---|---|---|---|
| Sistem perekrutan otomatis | x | x | x | x | |
| Terjemahan mesin | |||||
| Melabeli foto |
Mendeteksi Ketidakadilan
Ada banyak alasan mengapa sistem tertentu berperilaku tidak adil. Bias sosial, misalnya, mungkin tercermin dalam kumpulan data yang digunakan untuk melatih. Misalnya, ketidakadilan perekrutan mungkin telah diperburuk oleh ketergantungan yang berlebihan pada data historis. Dengan menggunakan pola dalam resume yang dikirimkan ke perusahaan selama periode 10 tahun, model tersebut menentukan bahwa pria lebih berkualitas karena mayoritas resume berasal dari pria, yang mencerminkan dominasi pria di masa lalu di industri teknologi.
Data yang tidak memadai tentang sekelompok orang tertentu dapat menjadi alasan ketidakadilan. Misalnya, pengklasifikasi gambar memiliki tingkat kesalahan yang lebih tinggi untuk gambar orang berkulit gelap karena warna kulit yang lebih gelap kurang terwakili dalam data.
Asumsi yang salah yang dibuat selama pengembangan menyebabkan ketidakadilan juga. Misalnya, sistem analisis wajah yang dimaksudkan untuk memprediksi siapa yang akan melakukan kejahatan berdasarkan gambar wajah orang dapat menyebabkan asumsi yang merusak. Hal ini dapat menyebabkan kerugian besar bagi orang-orang yang salah diklasifikasikan.
Pahami model kamu dan bangun dalam keadilan
Meskipun banyak aspek keadilan tidak tercakup dalam metrik keadilan kuantitatif, dan tidak mungkin menghilangkan bias sepenuhnya dari sistem untuk menjamin keadilan, Kamu tetap bertanggung jawab untuk mendeteksi dan mengurangi masalah keadilan sebanyak mungkin.
Saat Kamu bekerja dengan model pembelajaran mesin, penting untuk memahami model Kamu dengan cara memastikan interpretasinya dan dengan menilai serta mengurangi ketidakadilan.
Mari kita gunakan contoh pemilihan pinjaman untuk mengisolasi kasus untuk mengetahui tingkat dampak setiap faktor pada prediksi.
Metode Penilaian
-
Identifikasi bahaya (dan manfaat). Langkah pertama adalah mengidentifikasi bahaya dan manfaat. Pikirkan tentang bagaimana tindakan dan keputusan dapat memengaruhi calon pelanggan dan bisnis itu sendiri.
-
Identifikasi kelompok yang terkena dampak. Setelah Kamu memahami jenis kerugian atau manfaat apa yang dapat terjadi, identifikasi kelompok-kelompok yang mungkin terpengaruh. Apakah kelompok-kelompok ini ditentukan oleh jenis kelamin, etnis, atau kelompok sosial?
-
Tentukan metrik keadilan. Terakhir, tentukan metrik sehingga Kamu memiliki sesuatu untuk diukur dalam pekerjaan Kamu untuk memperbaiki situasi.
Identifikasi bahaya (dan manfaat)
Apa bahaya dan manfaat yang terkait dengan pinjaman? Pikirkan tentang skenario negatif palsu dan positif palsu:
False negatives (ditolak, tapi Y=1) - dalam hal ini, pemohon yang akan mampu membayar kembali pinjaman ditolak. Ini adalah peristiwa yang merugikan karena sumber pinjaman ditahan dari pemohon yang memenuhi syarat.
False positives (diterima, tapi Y=0) - dalam hal ini, pemohon memang mendapatkan pinjaman tetapi akhirnya wanprestasi. Akibatnya, kasus pemohon akan dikirim ke agen penagihan utang yang dapat mempengaruhi permohonan pinjaman mereka di masa depan.
Identifikasi kelompok yang terkena dampak
Langkah selanjutnya adalah menentukan kelompok mana yang kemungkinan akan terpengaruh. Misalnya, dalam kasus permohonan kartu kredit, sebuah model mungkin menentukan bahwa perempuan harus menerima batas kredit yang jauh lebih rendah dibandingkan dengan pasangan mereka yang berbagi aset rumah tangga. Dengan demikian, seluruh demografi yang ditentukan berdasarkan jenis kelamin menjadi terpengaruh.
Tentukan metrik keadilan
Kamu telah mengidentifikasi bahaya dan kelompok yang terpengaruh, dalam hal ini digambarkan berdasarkan jenis kelamin. Sekarang, gunakan faktor terukur (quantified factors) untuk memisahkan metriknya. Misalnya, dengan menggunakan data di bawah ini, Kamu dapat melihat bahwa wanita memiliki tingkat false positive terbesar dan pria memiliki yang terkecil, dan kebalikannya berlaku untuk false negative.
✅ Dalam pelajaran selanjutnya tentang Clustering, Kamu akan melihat bagaimana membangun 'confusion matrix' ini dalam kode
| False positive rate | False negative rate | count | |
|---|---|---|---|
| Women | 0.37 | 0.27 | 54032 |
| Men | 0.31 | 0.35 | 28620 |
| Non-binary | 0.33 | 0.31 | 1266 |
Tabel ini memberitahu kita beberapa hal. Pertama, kami mencatat bahwa ada sedikit orang non-biner dalam data. Datanya condong (skewed), jadi Kamu harus berhati-hati dalam menafsirkan angka-angka ini.
Dalam hal ini, kita memiliki 3 grup dan 2 metrik. Ketika kita memikirkan tentang bagaimana sistem kita memengaruhi kelompok pelanggan dengan permohonan pinjaman mereka, ini mungkin cukup, tetapi ketika Kamu ingin menentukan jumlah grup yang lebih besar, Kamu mungkin ingin menyaringnya menjadi kumpulan ringkasan yang lebih kecil. Untuk melakukannya, Kamu dapat menambahkan lebih banyak metrik, seperti perbedaan terbesar atau rasio terkecil dari setiap false negative dan false positive.
✅ Berhenti dan Pikirkan: Kelompok lain yang apa lagi yang mungkin terpengaruh untuk pengajuan pinjaman?
Mengurangi ketidakadilan
Untuk mengurangi ketidakadilan, jelajahi model untuk menghasilkan berbagai model yang dimitigasi dan bandingkan pengorbanan yang dibuat antara akurasi dan keadilan untuk memilih model yang paling adil.
Pelajaran pengantar ini tidak membahas secara mendalam mengenai detail mitigasi ketidakadilan algoritmik, seperti pendekatan pasca-pemrosesan dan pengurangan (post-processing and reductions approach), tetapi berikut adalah tool yang mungkin ingin Kamu coba.
Fairlearn
Fairlearn adalah sebuah package Python open-source yang memungkinkan Kamu untuk menilai keadilan sistem Kamu dan mengurangi ketidakadilan.
Tool ini membantu Kamu menilai bagaimana prediksi model memengaruhi kelompok yang berbeda, memungkinkan Kamu untuk membandingkan beberapa model dengan menggunakan metrik keadilan dan kinerja, dan menyediakan serangkaian algoritma untuk mengurangi ketidakadilan dalam klasifikasi dan regresi biner.
-
Pelajari bagaimana cara menggunakan komponen-komponen yang berbeda dengan mengunjungi GitHub Fairlearn
-
Jelajahi panduan pengguna, contoh-contoh
-
Coba beberapa sampel notebook.
-
Pelajari bagaimana cara mengaktifkan penilaian keadilan dari model machine learning di Azure Machine Learning.
-
Lihat sampel notebook ini untuk skenario penilaian keadilan yang lebih banyak di Azure Machine Learning.
🚀 Tantangan
Untuk mencegah kemunculan bias pada awalnya, kita harus:
- memiliki keragaman latar belakang dan perspektif di antara orang-orang yang bekerja pada sistem
- berinvestasi dalam dataset yang mencerminkan keragaman masyarakat kita
- mengembangkan metode yang lebih baik untuk mendeteksi dan mengoreksi bias ketika itu terjadi
Pikirkan tentang skenario kehidupan nyata di mana ketidakadilan terbukti dalam pembuatan dan penggunaan model. Apa lagi yang harus kita pertimbangkan?
Quiz Pasca-Pelajaran
Ulasan & Belajar Mandiri
Dalam pelajaran ini, Kamu telah mempelajari beberapa dasar konsep keadilan dan ketidakadilan dalam pembelajaran mesin.
Tonton workshop ini untuk menyelami lebih dalam kedalam topik:
- YouTube: Kerugian terkait keadilan dalam sistem AI: Contoh, penilaian, dan mitigasi oleh Hanna Wallach dan Miro Dudik Kerugian terkait keadilan dalam sistem AI: Contoh, penilaian, dan mitigasi - YouTube
Kamu juga dapat membaca:
-
Pusat sumber daya RAI Microsoft: Responsible AI Resources – Microsoft AI
-
Grup riset FATE Microsoft: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
Jelajahi toolkit Fairlearn
Baca mengenai tools Azure Machine Learning untuk memastikan keadilan