14 KiB
Scikit-learnを用いた回帰モデルの構築: データの準備と可視化
Dasani Madipalli によるインフォグラフィック
講義前のクイズ
イントロダクション
Scikit-learnを使って機械学習モデルの構築を行うために必要なツールの用意ができたところで、データに対する問いかけを始める準備が整いました。データを扱いMLソリューションを適用する際には、データセットの潜在能力を適切に引き出すために正しい問いかけをすることが非常に重要です。
このレッスンでは、以下のことを学びます。
- モデルを構築するためのデータ処理方法について
- データの可視化におけるMatplotlibの使い方について
データに対して正しい問いかけをする
どのような質問に答えるかによって、どのようなMLアルゴリズムを活用するかが決まります。また、返ってくる回答の質は、データの性質に大きく依存します。
このレッスンのために用意されたデータを見てみましょう。この.csvファイルは、VS Codeで開くことができます。ざっと確認してみると、空欄があったり、文字列や数値データが混在していることがわかります。また、「Package」という奇妙な列では「sacks」や 「bins」などの異なる単位の値が混在しています。このように、データはちょっとした混乱状態にあります。
実際のところ、MLモデルの作成にすぐに使えるような整ったデータセットをそのまま受け取ることはあまりありません。このレッスンでは、Pythonの標準ライブラリを使って生のデータセットを準備する方法を学びます。また、データを可視化するための様々なテクニックを学びます。
ケーススタディ: カボチャの市場
ルートのdateフォルダの中に US-pumpkins.csv という名前の.csvファイルがあります。このファイルには、カボチャの市場に関する1757行のデータが、都市ごとにグループ分けされて入っています。これは、米国農務省が配布している Specialty Crops Terminal Markets Standard Reports から抽出した生データです。
データの準備
このデータはパブリックドメインです。米国農務省のウェブサイトから、都市ごとに個別ファイルをダウンロードすることができます。ファイルが多くなりすぎないように、すべての都市のデータを1つのスプレッドシートに連結しました。次に、データを詳しく見てみましょう。
カボチャのデータ - 初期の結論
このデータについて何か気付いたことはありますか?文字列、数字、空白、奇妙な値が混在していて、意味を理解しなければならないこと気付いたと思います。
回帰を使って、このデータにどのような問いかけができますか?「ある月に販売されるカボチャの価格を予測する」というのはどうでしょうか?データをもう一度見てみると、この課題に必要なデータ構造を作るために、いくつかの変更が必要です。
エクササイズ - カボチャのデータを分析
データを整形するのに非常に便利な Pandas (Python Data Analysisの略) を使って、このカボチャのデータを分析したり整えてみましょう。
最初に、日付が欠損していないか確認する
日付が欠損していないか確認するために、いくつかのステップがあります:
- 日付を月の形式に変換する(これは米国の日付なので、形式は
MM/DD/YYYYとなる)。 - 新しい列として月を抽出する。
Visual Studio Codeで notebook.ipynb ファイルを開き、スプレッドシートを Pandas DataFrame としてインポートします。
-
head()関数を使って最初の5行を確認します。import pandas as pd pumpkins = pd.read_csv('../data/US-pumpkins.csv') pumpkins.head()✅ 最後の5行を表示するには、どのような関数を使用しますか?
-
現在のデータフレームに欠損データがあるかどうかをチェックします。
pumpkins.isnull().sum()欠損データがありましたが、今回のタスクには影響がなさそうです。
-
データフレームを扱いやすくするために、
drop()関数を使っていくつかの列を削除し、必要な列だけを残すようにします。new_columns = ['Package', 'Month', 'Low Price', 'High Price', 'Date'] pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
次に、カボチャの平均価格を決定します。
ある月のかぼちゃの平均価格を決定する方法を考えてみましょう。このタスクのために、どの列が必要ですか?ヒント:3つの列が必要になります。
解決策:「最低価格」と「最高価格」の平均値を取って新しい「price」列を作成し、「日付」列を月のみ表示するように変換します。幸いなことに、上記で確認した結果によると日付や価格に欠損データはありませんでした。
-
平均値を算出するために、以下のコードを追加します。
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2 month = pd.DatetimeIndex(pumpkins['Date']).month✅
print(month)などを使って自由にデータを確認してみてください。 -
変換したデータをPandasの新しいデータフレームにコピーします。
new_pumpkins = pd.DataFrame({'Month': month, 'Package': pumpkins['Package'], 'Low Price': pumpkins['Low Price'],'High Price': pumpkins['High Price'], 'Price': price})データフレームを出力すると、新しい回帰モデルを構築するための綺麗に整頓されたデータセットが表示されます。
でも、待ってください!なにかおかしいです。
Package 列をみると、カボチャは様々な形で販売されています。「1 1/9ブッシェル」で売られているもの、「1/2ブッシェル」で売られているもの、かぼちゃ1個単位で売られているもの、1ポンド単位で売られているもの、幅の違う大きな箱で売られているものなど様々です。
かぼちゃの重さを一定にするのはとても難しいようです。
元のデータを調べてみると、「Unit of Sale」が「EACH」または「PER BIN」となっているものは、「Package」が「per inch」、「per bin」、「each」となっているのが興味深いです。カボチャの計量単位に一貫性を持たせるのが非常に難しいようなので、Package列に「bushel」という文字列を持つカボチャだけを選択してフィルタリングしてみましょう。
-
ファイルの一番上にフィルタを追加します。
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]今、データを出力してみると、ブッシェル単位のカボチャを含む415行ほどのデータしか得られていないことがわかります。
でも、待ってください!もうひとつ、やるべきことがあります。
行ごとにブッシェルの量が異なることに気付きましたか?1ブッシェルあたりの価格を表示するためには、計算して価格を標準化する必要があります。
-
new_pumpkinsデータフレームを作成するブロックの後に以下の行を追加します。
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/(1 + 1/9) new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price/(1/2)
✅ The Spruce Eats によると、ブッシェルの重さは体積を測るものなので、農産物の種類によって異なります。例えば、トマトの1ブッシェルは、56ポンドの重さになるとされています。葉っぱや野菜は重量が少なくてもスペースを取るので、ほうれん草の1ブッシェルはたったの20ポンドです。なんだか複雑ですね!ブッシェルからポンドへの換算は面倒なのでやめて、ブッシェル単位で価格を決めましょう。しかし、カボチャのブッシェルについての議論は、データの性質を理解することがいかに重要であるかを示しています。
これで、ブッシェルの測定値に基づいて、ユニットごとの価格を分析することができます。もう1度データを出力してみると、標準化されていることがわかります。
✅ ハーフブッシェルで売られているカボチャがとても高価なことに気付きましたか?なぜだかわかりますか?小さなカボチャは大きなカボチャよりもはるかに高価です。おそらく大きなカボチャ中身には、体積あたりで考えると空洞な部分が多く含まれると考えられます。
可視化戦略
データサイエンティストの役割の一つは、扱うデータの質や性質を示すことです。そのために、データのさまざまな側面を示す興味深いビジュアライゼーション(プロット、グラフ、チャート)を作成することがよくあります。そうすることで、他の方法では発見しにくい関係性やギャップを視覚的に示すことができます。
また、可視化することでデータに適した機械学習の手法を判断することができます。例えば、散布図が直線に沿っているように見える場合は、適用する手法の候補の一つとして線形回帰が考えられます。
Jupyter notebookでうまく利用できるテータ可視化ライブラリの一つに Matplotlib があります (前のレッスンでも紹介しています)。
こちらのチュートリアル でデータの可視化ついてより深く体験することができます。
エクササイズ - Matplotlibの実験
先ほど作成したデータフレームを表示するために、いくつか基本的なプロットを作成してみてください。折れ線グラフから何が読み取れるでしょうか?
-
ファイルの先頭、Pandasのインポートの下で Matplotlibをインポートします。
import matplotlib.pyplot as plt -
ノートブック全体を再実行してリフレッシュします。
-
ノートブックの下部に、データをプロットするためのセルを追加します。
price = new_pumpkins.Price month = new_pumpkins.Month plt.scatter(price, month) plt.show()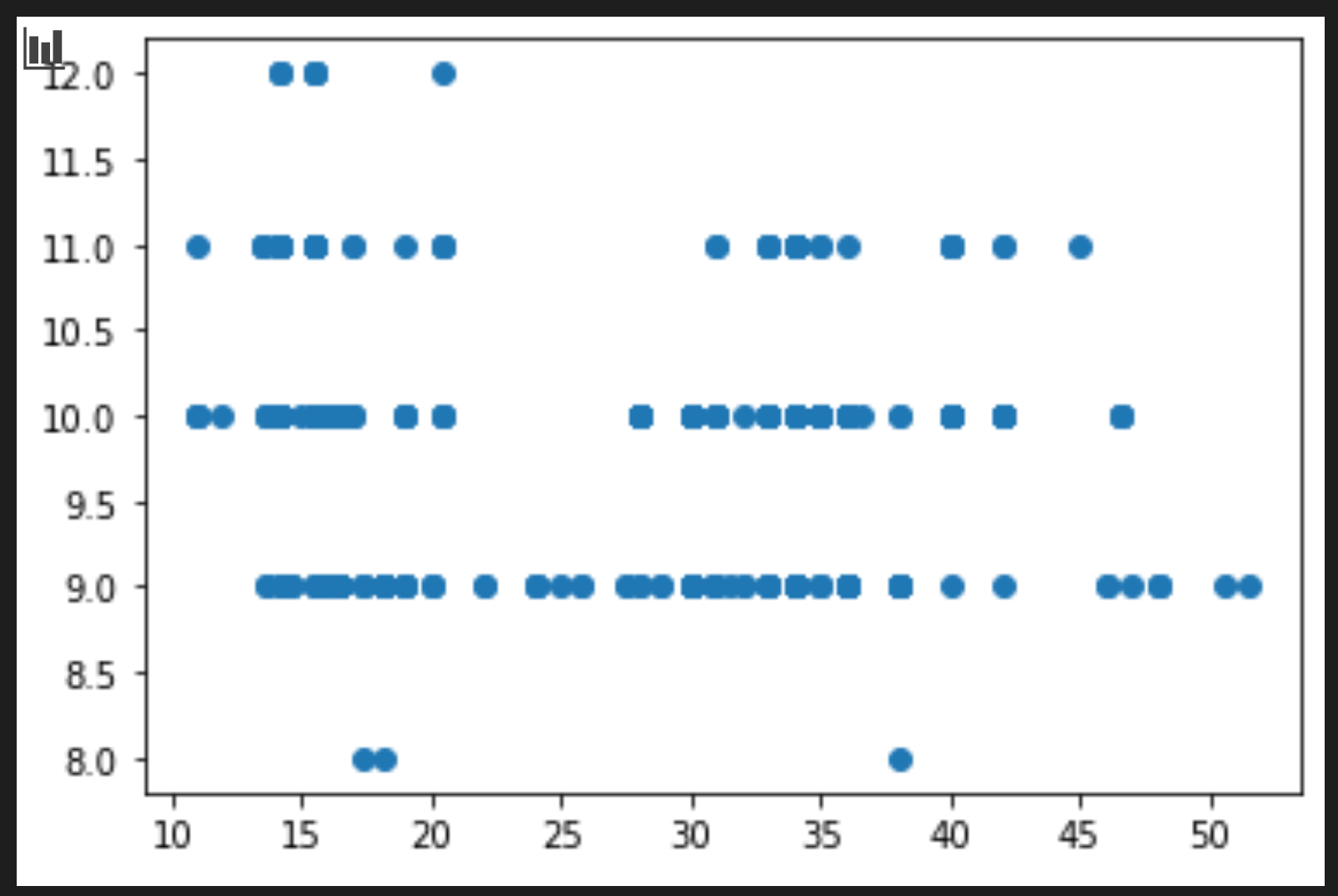
これは役に立つプロットですか?なにか驚いたことはありますか?
これはデータをある月について、データの広がりとして表示しているだけなので、特に役に立つものではありません。
活用できるようにする
グラフに有用なデータを表示するには、通常、データを何らかの方法でグループ化する必要があります。ここでは、X軸を月として、データの分布を示すようなプロットを作ってみましょう。
-
セルを追加してグループ化された棒グラフを作成します。
new_pumpkins.groupby(['Month'])['Price'].mean().plot(kind='bar') plt.ylabel("Pumpkin Price")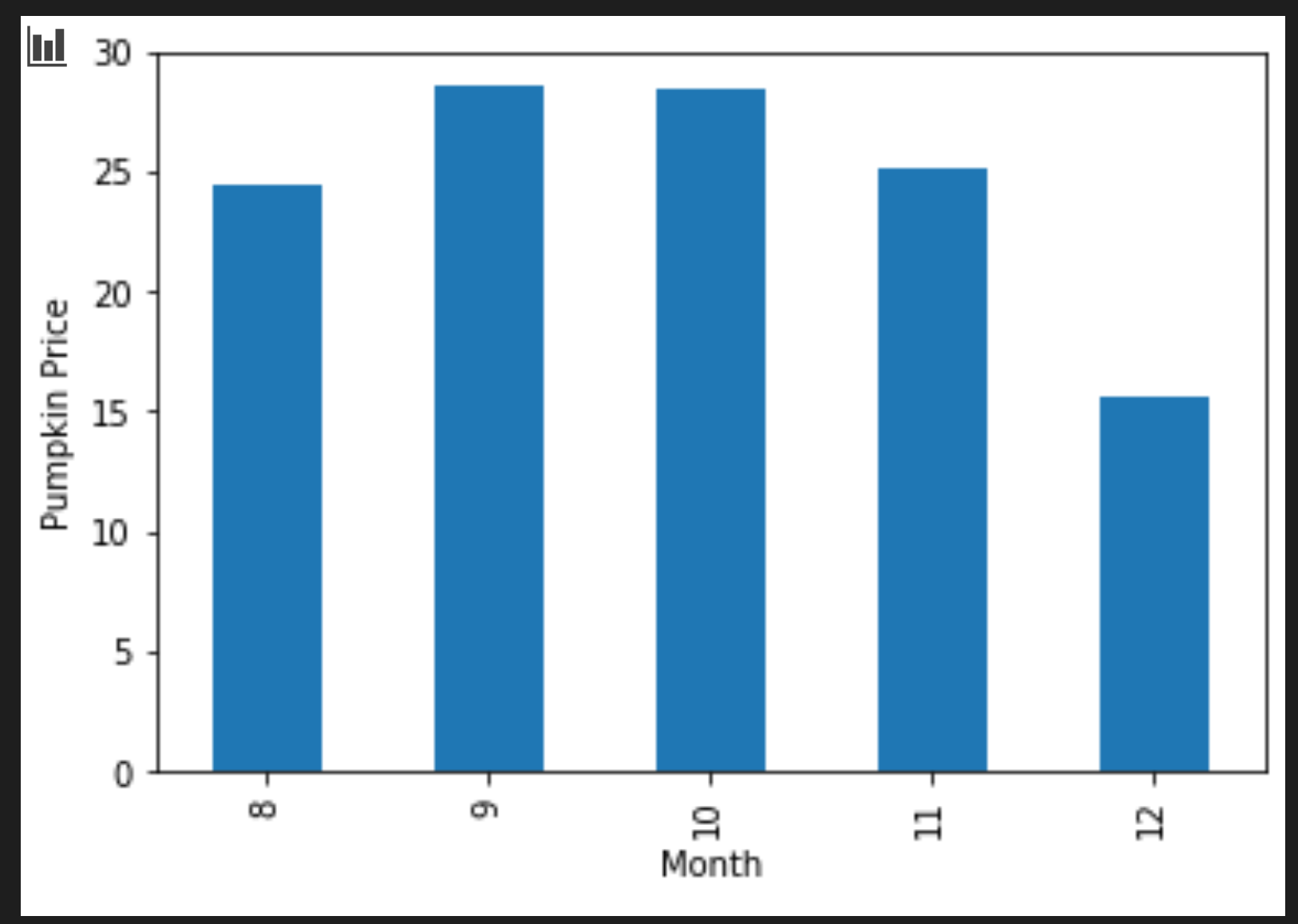
このプロットの方が、より有用なデータを可視化しています!カボチャの価格が最も高くなるのは、9月と10月であることを示しているようです。このプロットはあなたの期待に応えるものですか?どのような点で期待通りですか?また、どのような点で期待に答えられていませんか?
🚀チャレンジ
Matplotlibが提供する様々なタイプのビジュアライゼーションを探ってみましょう。回帰の問題にはどのタイプが最も適しているでしょうか?
講義後クイズ
レビュー & 自主学習
データを可視化するための様々な方法を見てみましょう。様々なライブラリをリストアップし、例えば2Dビジュアライゼーションと3Dビジュアライゼーションのように、特定のタイプのタスクに最適なものをメモします。どのような発見がありましたか?