10 KiB
요리 classifiers 2
두번째 classification 강의에서, 숫자 데이터를 분류하는 더 많은 방식을 알아봅니다. 다른 것보다 하나의 classifier를 선택하는 파급효과도 배우게 됩니다.
강의 전 퀴즈
필요 조건
직전 강의를 완료하고 4강 폴더의 최상단 data 폴더에 cleaned_cuisines.csv 라고 불리는 정리된 데이터셋이 있다고 가정합니다.
준비하기
정리된 데이터셋과 notebook.ipynb 파일을 불러오고 X 와 y 데이터프레임으로 나누면, 모델 제작 프로세스를 준비하게 됩니다.
Classification map
이전에, Microsoft 치트 시트를 사용해서 데이터를 분류할 때 다양한 옵션을 배울 수 있었습니다. Scikit-learn은 estimators (classifiers)를 좁히는 데 더 도움을 받을 수 있었고, 보다 세분화된 치트 시트를 비슷하게 제공합니다:
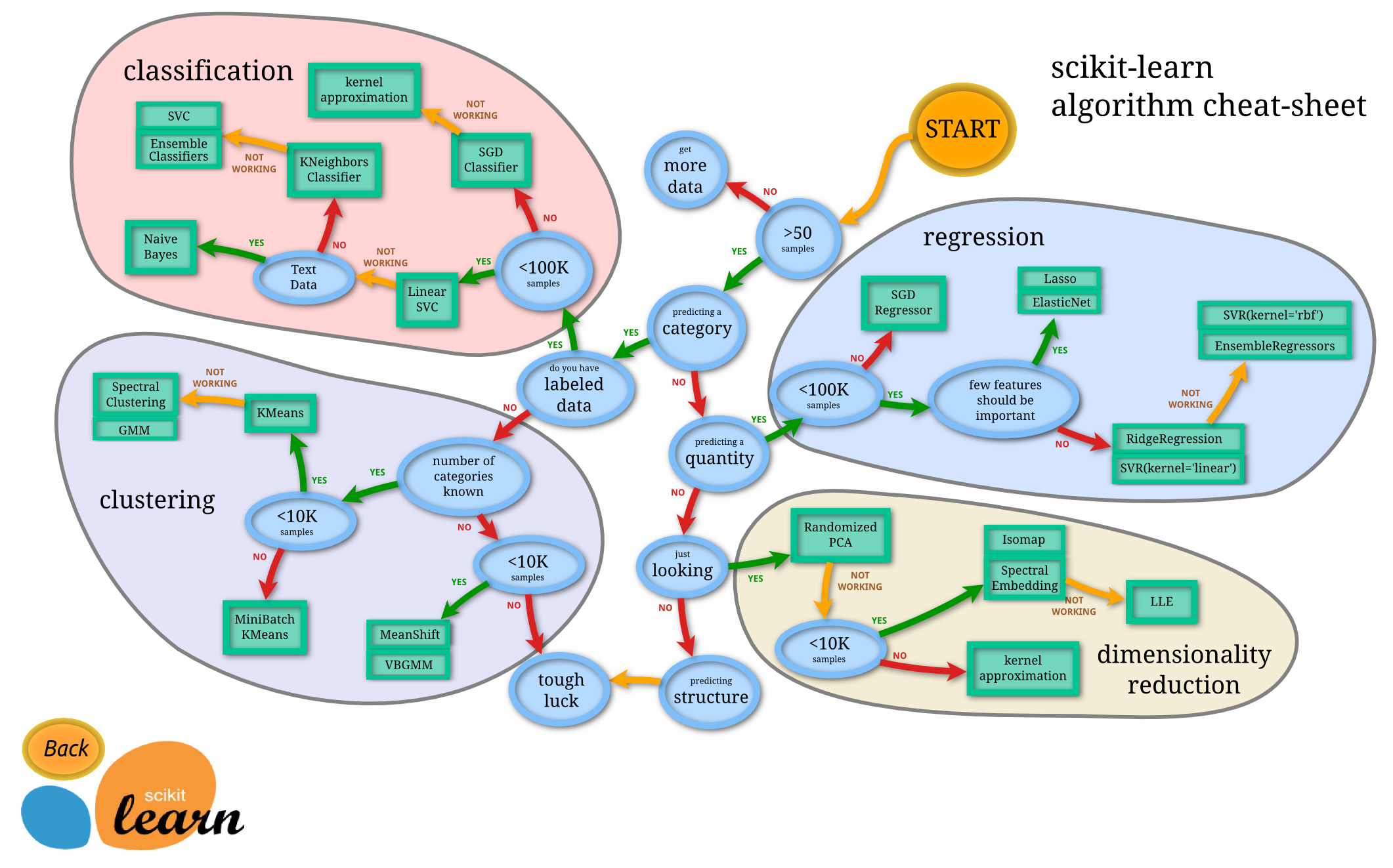
팁: visit this map online으로 경로를 따라 클릭해서 문서를 읽어봅니다.
계획
지도는 데이터를 명쾌하게 파악하면 정한 길을 따라 'walk'할 수 있으므르 매우 도움이 됩니다:
- 샘플을 >50개 가지고 있습니다
- 카테고리를 예측하고 싶습니다
- 라벨링된 데이터를 가지고 있습니다
- 100K개 보다 적은 샘플을 가지고 있습니다
- ✨ Linear SVC를 고를 수 있습니다
- 동작하지 않을 때, 숫자 데이터를 가지고 있으므로
- ✨ KNeighbors Classifier를 시도할 수 있습니다
- 만약 그것도 동작하지 않는다면, ✨ SVC 와 ✨ Ensemble Classifiers를 시도합니다.
- ✨ KNeighbors Classifier를 시도할 수 있습니다
따라가면 도움을 받을 수 있습니다.
연습 - 데이터 나누기
경로를 따라서, 사용할 라이브러리를 가져오기 시작해야 합니다.
-
필요한 라이브러리를 Import 합니다:
from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curve import numpy as np -
훈련과 테스트 데이터로 나눕니다:
X_train, X_test, y_train, y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)
Linear SVC classifier
Support-Vector clustering (SVC)는 ML 기술 중에서 Support-Vector machines의 하위입니다 (아래에서 자세히 알아봅니다). 이 메소드에서, 'kernel'을 선택하고 라벨을 클러스터하는 방식을 결정할 수 있습니다. 'C' 파라미터는 파라미터의 영향을 규제할 'regularization'을 나타냅니다. 커널은 several 중에서 있을 수 있습니다. 여기는 linear SVC를 활용하도록 'linear'로 설정합니다. 확률은 'false'가 기본입니다; 하지만 확률을 추정하기 위해서 'true'로 설정합니다. 확률을 얻으려면 데이터를 섞어서 랜덤 상태 '0'으로 설정합니다.
연습 - linear SVC 적용하기
classifiers의 배열을 만들기 시작합니다. 테스트하며 배열에 점차 추가할 예정입니다.
-
Linear SVC로 시작합니다:
C = 10 # Create different classifiers. classifiers = { 'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0) } -
Linear SVC로 모델을 훈련하고 리포트도 출력합니다:
n_classifiers = len(classifiers) for index, (name, classifier) in enumerate(classifiers.items()): classifier.fit(X_train, np.ravel(y_train)) y_pred = classifier.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100)) print(classification_report(y_test,y_pred))결과는 멋집니다:
Accuracy (train) for Linear SVC: 78.6% precision recall f1-score support chinese 0.71 0.67 0.69 242 indian 0.88 0.86 0.87 234 japanese 0.79 0.74 0.76 254 korean 0.85 0.81 0.83 242 thai 0.71 0.86 0.78 227 accuracy 0.79 1199 macro avg 0.79 0.79 0.79 1199 weighted avg 0.79 0.79 0.79 1199
K-Neighbors classifier
K-Neighbors는 supervised 와 unsupervised learning에서 사용하는 ML 방식 중 "neighbors" 계열의 일부분입니다. 이 메소드에서, 미리 정의한 수의 포인트를 만들고 포인트 주변의 데이터를 수집하면 데이터에 대한 일반화된 라벨을 예측할 수 있습니다.
연습 - K-Neighbors classifier 적용하기
이전 classifier는 좋았고, 데이터도 잘 동작했지만, 더 정확도를 높일 수 있을 수 있습니다. K-Neighbors classifier를 시도해봅니다.
-
classifier 배열에 라인을 추가합니다 (Linear SVC 아이템 뒤에 컴마를 추가합니다):
'KNN classifier': KNeighborsClassifier(C),결과는 조금 나쁩니다:
Accuracy (train) for KNN classifier: 73.8% precision recall f1-score support chinese 0.64 0.67 0.66 242 indian 0.86 0.78 0.82 234 japanese 0.66 0.83 0.74 254 korean 0.94 0.58 0.72 242 thai 0.71 0.82 0.76 227 accuracy 0.74 1199 macro avg 0.76 0.74 0.74 1199 weighted avg 0.76 0.74 0.74 1199✅ K-Neighbors에 대하여 알아봅니다
Support Vector Classifier
Support-Vector classifiers는 classification 과 regression 작업에 사용하는 ML 방식 중에서 Support-Vector Machine 계열의 일부분입니다. SVMs은 두 카테고리 사이의 거리를 최대로 하려고 "공간의 포인트에 훈련 예시를 맵핑"합니다. 차후 데이터는 카테고리를 예측할 수 있게 이 공간에 맵핑됩니다.
연습 - Support Vector Classifier 적용하기
Support Vector Classifier로 정확도를 조금 더 올립니다.
-
K-Neighbors 아이템 뒤로 컴마를 추가하고, 라인을 추가합니다:
'SVC': SVC(),결과는 꽤 좋습니다!
Accuracy (train) for SVC: 83.2% precision recall f1-score support chinese 0.79 0.74 0.76 242 indian 0.88 0.90 0.89 234 japanese 0.87 0.81 0.84 254 korean 0.91 0.82 0.86 242 thai 0.74 0.90 0.81 227 accuracy 0.83 1199 macro avg 0.84 0.83 0.83 1199 weighted avg 0.84 0.83 0.83 1199✅ Support-Vectors에 대하여 알아봅니다
Ensemble Classifiers
지난 테스트에서 꽤 좋았지만, 경로를 끝까지 따라갑니다. Ensemble Classifiers, 구체적으로 Random Forest 와 AdaBoost를 시도합니다:
'RFST': RandomForestClassifier(n_estimators=100),
'ADA': AdaBoostClassifier(n_estimators=100)
특별하게 Random Forest는, 결과가 매우 좋습니다:
Accuracy (train) for RFST: 84.5%
precision recall f1-score support
chinese 0.80 0.77 0.78 242
indian 0.89 0.92 0.90 234
japanese 0.86 0.84 0.85 254
korean 0.88 0.83 0.85 242
thai 0.80 0.87 0.83 227
accuracy 0.84 1199
macro avg 0.85 0.85 0.84 1199
weighted avg 0.85 0.84 0.84 1199
Accuracy (train) for ADA: 72.4%
precision recall f1-score support
chinese 0.64 0.49 0.56 242
indian 0.91 0.83 0.87 234
japanese 0.68 0.69 0.69 254
korean 0.73 0.79 0.76 242
thai 0.67 0.83 0.74 227
accuracy 0.72 1199
macro avg 0.73 0.73 0.72 1199
weighted avg 0.73 0.72 0.72 1199
✅ Ensemble Classifiers에 대해 배웁니다
머신러닝의 방식 "여러 기본 estimators의 에측을 합쳐"서 모델의 품질을 향상시킵니다. 예시로, Random Trees 와 AdaBoost를 사용합니다.
-
평균 방식인 Random Forest는, 오버피팅을 피하려 랜덤성이 들어간 'decision trees'의 'forest'를 만듭니다. n_estimators 파라미터는 트리의 수로 설정합니다.
-
AdaBoost는 데이터셋을 classifier로 맞추고 classifier의 카피를 같은 데이터셋에 맞춥니다.잘 못 분류된 아이템의 가중치에 집중하고 다음 classifier를 교정하도록 맞춥니다.
🚀 도전
각 기술에는 트윅할 수 있는 많은 수의 파라미터가 존재합니다. 각 기본 파라미터를 조사하고 파라미터를 조절헤서 모델 품질에 어떤 의미가 부여되는지 생각합니다.
강의 후 퀴즈
검토 & 자기주도 학습
강의에서 많은 특수 용어가 있어서, 잠시 시간을 투자해서 유용한 용어의 this list를 검토합니다!