14 KiB
classification 소개하기
4개 강의에서, classic 머신러닝의 기본 초점인 - classification 을 찾아 볼 예정입니다. 아시아와 인도의 모든 훌륭한 요리 데이터셋과 함께 다양한 classification 알고리즘을 사용할 예정입니다. 배고파보세요!

Celebrate pan-Asian cuisines in these lessons! Image by Jen Looper
Classification은 regression 기술과 공통점이 많은 supervised learning의 폼입니다. 만약 머신러닝이 데이터셋으로 사물의 값이나 이름을 예측한다면, 일반적으로 classification는 2가지 그룹으로 나누어집니다: binary classification 과 multiclass classification.

🎥 이미지를 누르면 영상 시청: MIT's John Guttag introduces classification
생각합니다:
- Linear regression 변수 사이 관계를 예측하고 새로운 데이터 포인트로 라인과 엮인 위치에 대한 정확한 예측을 하도록 도움을 줍니다. 예시로, what price a pumpkin would be in September vs. December 를 예측할 수 있습니다.
- Logistic regression "binary categories"를 찾을 때 도와줄 수 있습니다: at this price point, is this pumpkin orange or not-orange?
Classification은 다양한 알고리즘으로 데이터 포인트의 라벨 혹은 클래스를 결정할 다른 방식을 고릅니다. 요리 데이터로, 재료 그룹을 찾아서, 전통 요리로 결정할 수 있는지 알아보려 합니다.
강의 전 퀴즈
소개
Classification은 머신러닝 연구원과 데이터 사이언티스트의 기본 활동의 하나입니다. 바이너리 값("is this email spam or not?")의 기본 classification부터, 컴퓨터 비전으로 복잡한 이미지 classification과 segmentation까지, 데이터를 클래스로 정렬하고 물어보는 것은 항상 유용합니다.
보다 과학적인 방식으로 프로세스를 설명해보자면, classification 방식은 입력한 변수 사이 관계를 출력 변수에 맵핑할 수 있는 예측 모델을 만듭니다.
Binary vs. multiclass problems for classification algorithms to handle. Infographic by Jen Looper
데이터를 정리, 시각화, 그리고 ML 작업을 준비하는 프로세스를 시작하기 전, 데이터를 분류할 때 활용할 수 있는 머신러닝의 다양한 방식에 대하여 알아봅니다.
statistics에서 분리된, classic 머신러닝을 사용하는 classification은, smoker, weight, 그리고 age처럼 likelihood of developing X disease 에 대하여 결정합니다. 전에 수행한 regression 연습과 비슷한 supervised learning 기술로서, 데이터에 라벨링한 ML 알고리즘은 라벨로 데이터셋의 클래스(또는 'features')를 분류하고 예측해서 그룹 또는 결과에 할당합니다.
✅ 잠시 요리 데이터셋을 상상해봅니다. multiclass 모델은 어떻게 답변할까요? 바이너리 모델은 어떻게 답변할까요? 주어진 요리에 fenugreek를 사용할 지 어떻게 확인하나요? 만약 star anise, artichokes, cauliflower, 그리고 horseradish로 가득한 식품 가방을 선물해서, 전형적 인도 요리를 만들 수 있는지, 보고 싶다면 어떻게 하나요?

🎥 영상을 보려면 이미지 클릭합니다. The whole premise of the show 'Chopped' is the 'mystery basket' where chefs have to make some dish out of a random choice of ingredients. Surely a ML model would have helped!
안녕 'classifier'
요리 데이터셋에 물어보고 싶은 질문은, 여러 잠재적 국민 요리를 만들 수 있기 때문에 실제로 multiclass question입니다. 재료가 배치되었을 때, 많은 클래스 중에 어떤 데이터가 맞을까요?
Scikit-learn은 해결하고 싶은 문제의 타입에 따라서, 데이터를 분류하며 사용할 여러가지 알고리즘을 제공합니다. 다음 2가지 강의에서, 몇 알고리즘에 대하여 더 배울 예정입니다.
연습 - 데이터 정리하며 균형잡기
프로젝트를 시작하기 전, 첫번째로 해야 할 일은, 더 좋은 결과를 얻기 위해서 데이터를 정리하고 balance 하는 일입니다. 이 폴더의 최상단에 있는 빈 notebook.ipynb 파일에서 시작합니다.
먼저 설치할 것은 imblearn입니다. 데이터의 균형을 잘 잡아줄 Scikit-learn 패키지입니다 (몇 분동안 배우게 됩니다).
-
이렇게,
imblearn설치하고,pip install을 실행합니다:pip install imblearn -
데이터를 가져오고 시각화할 때 필요한 패키지를 Import 합니다,
imblearn의SMOTE도 import 합니다.import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl import numpy as np from imblearn.over_sampling import SMOTE지금부터 데이터를 가져와서 읽게 세팅되었습니다.
-
다음 작업으로 데이터를 가져옵니다:
df = pd.read_csv('../data/cuisines.csv')read_csv()를 사용하면 cusines.csv csv 파일의 컨텐츠를 읽고df변수에 놓습니다. -
데이터의 모양을 확인합니다:
df.head()다음은 처음 5개 행입니다:
| | Unnamed: 0 | cuisine | almond | angelica | anise | anise_seed | apple | apple_brandy | apricot | armagnac | ... | whiskey | white_bread | white_wine | whole_grain_wheat_flour | wine | wood | yam | yeast | yogurt | zucchini | | --- | ---------- | ------- | ------ | -------- | ----- | ---------- | ----- | ------------ | ------- | -------- | --- | ------- | ----------- | ---------- | ----------------------- | ---- | ---- | --- | ----- | ------ | -------- | | 0 | 65 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 1 | 66 | indian | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 2 | 67 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 3 | 68 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 4 | 69 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | -
info()를 불러서 데이터의 정보를 봅니다:df.info()출력됩니다:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 2448 entries, 0 to 2447 Columns: 385 entries, Unnamed: 0 to zucchini dtypes: int64(384), object(1) memory usage: 7.2+ MB
연습 - 요리에 대하여 배우기
지금부터 작업이 더 흥미로워집니다. 요리별, 데이터의 분포를 알아봅니다
-
barh()를 불러서 바 형태로 데이터를 Plot합니다:df.cuisine.value_counts().plot.barh()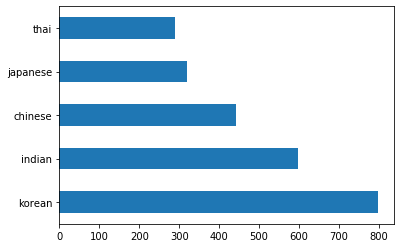
한정된 요리 갯수가 있지만, 데이터의 분포는 고르지 않습니다. 고칠 수 있습니다! 이전에, 조금 찾아봅니다.
-
요리별로 사용할 수 있는 데이터 크기를 보기 위해서 출력합니다:
thai_df = df[(df.cuisine == "thai")] japanese_df = df[(df.cuisine == "japanese")] chinese_df = df[(df.cuisine == "chinese")] indian_df = df[(df.cuisine == "indian")] korean_df = df[(df.cuisine == "korean")] print(f'thai df: {thai_df.shape}') print(f'japanese df: {japanese_df.shape}') print(f'chinese df: {chinese_df.shape}') print(f'indian df: {indian_df.shape}') print(f'korean df: {korean_df.shape}')이렇게 출력됩니다:
thai df: (289, 385) japanese df: (320, 385) chinese df: (442, 385) indian df: (598, 385) korean df: (799, 385)
성분 발견하기
지금부터 데이터를 깊게 파서 요리별 일반적인 재료가 무엇인지 배울 수 있습니다. 요리 사이의 혼동을 일으킬 중복 데이터를 정리할 필요가 있으므로, 문제에 대하여 배우겠습니다.
-
Python에서 성분 데이터프레임을 생성하기 위해서
create_ingredient()함수를 만듭니다. 함수는 도움이 안되는 열을 드랍하고 카운트로 재료를 정렬하게 됩니다:def create_ingredient_df(df): ingredient_df = df.T.drop(['cuisine','Unnamed: 0']).sum(axis=1).to_frame('value') ingredient_df = ingredient_df[(ingredient_df.T != 0).any()] ingredient_df = ingredient_df.sort_values(by='value', ascending=False, inplace=False) return ingredient_df지금부터 함수를 사용해서 요리별 가장 인기있는 10개 재료의 아이디어를 얻을 수 있습니다.
-
create_ingredient()부르고barh()을 부르면서 plot합니다:thai_ingredient_df = create_ingredient_df(thai_df) thai_ingredient_df.head(10).plot.barh()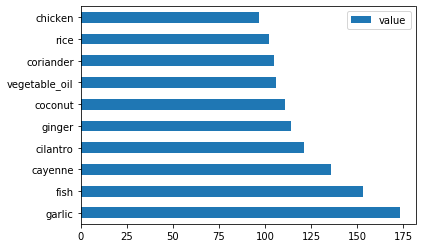
-
일본 데이터에서 똑같이 합니다:
japanese_ingredient_df = create_ingredient_df(japanese_df) japanese_ingredient_df.head(10).plot.barh()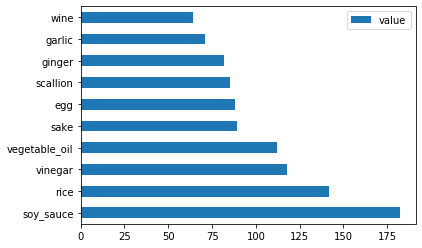
-
지금 중국 재료에서도 합니다:
chinese_ingredient_df = create_ingredient_df(chinese_df) chinese_ingredient_df.head(10).plot.barh()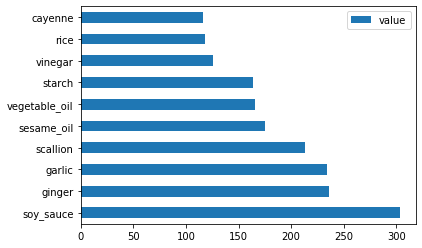
-
인도 재료에서도 Plot 합니다:
indian_ingredient_df = create_ingredient_df(indian_df) indian_ingredient_df.head(10).plot.barh()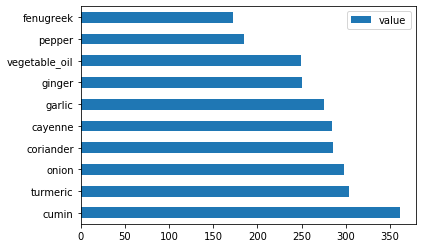
-
마지막으로, 한국 재료에도 plot 합니다:
korean_ingredient_df = create_ingredient_df(korean_df) korean_ingredient_df.head(10).plot.barh()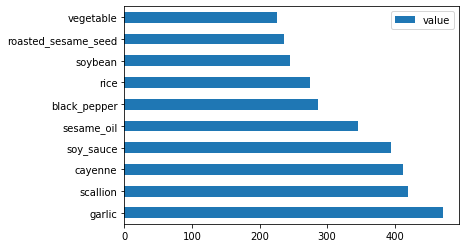
-
지금부터,
drop()을 불러서, 전통 요리 사이에 혼란을 주는 가장 공통적인 재료를 드랍합니다:모두 쌀, 마늘과 생강을 좋아합니다!
feature_df= df.drop(['cuisine','Unnamed: 0','rice','garlic','ginger'], axis=1) labels_df = df.cuisine #.unique() feature_df.head()
데이터셋 균형 맞추기
지금까지 SMOTE를 사용해서, 데이터를 정리했습니다. - "Synthetic Minority Over-sampling Technique" - to balance it.
-
fit_resample()을 부르는, 전략은 interpolation으로 새로운 샘플을 생성합니다.oversample = SMOTE() transformed_feature_df, transformed_label_df = oversample.fit_resample(feature_df, labels_df)데이터를 균형맞추면, 분류할 때 더 좋은 결과를 냅니다. binary classification에 대하여 생각해봅니다. 만약 대부분 데이터가 한 클래스라면, ML 모델은 단지 데이터가 많다는 이유로, 해당 클래스를 더 자주 예측합니다. 데이터 균형을 맞추면 왜곡된 데이터로 불균형을 제거하는 과정을 도와줍니다.
-
지금부터 성분별 라벨의 수를 확인할 수 있습니다:
print(f'new label count: {transformed_label_df.value_counts()}') print(f'old label count: {df.cuisine.value_counts()}')이렇게 출력됩니다:
new label count: korean 799 chinese 799 indian 799 japanese 799 thai 799 Name: cuisine, dtype: int64 old label count: korean 799 indian 598 chinese 442 japanese 320 thai 289 Name: cuisine, dtype: int64이 데이터는 훌륭하고 깔끔하고, 균형 잡히고, 그리고 매우 맛있습니다!
-
마지막 단계는 라벨과 features를 포함한, 밸런스 맞춘 데이터를 파일로 뽑을 수 있는 새로운 데이터프레임으로 저장합니다:
transformed_df = pd.concat([transformed_label_df,transformed_feature_df],axis=1, join='outer') -
transformed_df.head()와transformed_df.info()로 데이터를 다시 볼 수 있습니다. 다음 강의에서 쓸 수 있도록 데이터를 복사해서 저장합니다:transformed_df.head() transformed_df.info() transformed_df.to_csv("../data/cleaned_cuisines.csv")새로운 CSV는 최상단 데이터 폴더에서 찾을 수 있습니다.
🚀 도전
해당 커리큘럼은 여러 흥미로운 데이터셋을 포함하고 있습니다. data 폴더를 파보면서 binary 또는 multi-class classification에 적당한 데이터셋이 포함되어 있나요? 데이터셋에 어떻게 물어보나요?
강의 후 퀴즈
검토 & 자기주도 학습
SMOTE API를 찾아봅니다. 어떤 사용 케이스에 잘 사용하나요? 어떤 문제를 해결하나요?